
Необходимо признать, что нынешние процессоры при всей их немыслимой технологической изощренности с системной точки зрения остаются довольно примитивно организованными созданиями. Тому причиной— присущий им органический дефект, заключающийся в том, что за редчайшим исключением все известные процессоры построены на основе логически неполной двоичной булевой логики. Как следствие, они по определению синхронны; для срабатывания логических схем требуется специальный управляющий сигнал— строб— от тактового генератора, заставляющий все сотни миллионов триггеров менять свое состояние одновременно. Ясно, что для выполнения любой отдельно взятой команды требуется всего лишь некоторая часть процессорных ресурсов, и только принадлежащие этой части транзисторы должны участвовать в данной операции. Но незанятые в операции транзисторы получают питание наравне с работающими, а потому являются своего рода «паразитами», то есть непродуктивно используют энергию, избыточно потребляемые ватты.
Радикальным решением энергетических проблем, вызванных простаивающими транзисторами, мог бы стать переход к асинхронным процессорам, основанным на троичной или еще более сложной логике. Однако, если он и случится, то, как говорится, «не при нашей жизни»: багаж, накопленный более чем за полувековую компьютерную историю, огромен и изменить его практически невозможно. Поэтому, чтобы минимизировать количество потребляемой энергии, не остается ничего иного, как совершенствовать существующие принципы построения нынешних синхронных процессоров. Есть несколько подходов; можно снижать напряжение и частоту, но разумнее в каждом такте подавать напряжение только на модули, которые участвуют в логике выполняемой команды, а остальные временно обесточить. Этот подход известен, он реализован в ряде проектов, но наиболее полно на сегодняшний день он воплощен в процессоре PWRficient PA6T-1682M, который разработан компанией P.A. Semi и представляет собой оптимизированную с точки зрения использования энергию версию процессорной архитектуры IBM Power.
 P.A. Semi относится к распространенной ныне категории полупроводниковых «стартапов»— компаний, не имеющих собственного производства. Она насчитывает всего 150 сотрудников, большинство из них— специалисты высочайшего класса. Показательно то, что P.A. Semi причисляют к самым щедро финансируемым стартапам; значит, инвесторы возлагают на нее большие надежды. Это и не удивительно, ведь основал и возглавляет P.A. Semi Дэн Добберпул— один из наиболее именитых инженеров, обладающий множеством наград и званий, заслуженных еще в то время, когда он был главным проектировщиком DEC Alpha, самого производительного среди современных ему процессоров, а также первого процессора с пониженным потреблением StrongARM. Проект StrongARM после распада DEC был куплен Intel, и сегодня его пятая версия, известная под названием XScale, широко используется в мобильных устройствах. Позже, вплоть до 2000 года, в компании SiByte Добберпул участвовал в разработке исторически первого многоядерного процессора Mercurian-1250, где было четыре ядра с архитектурой MIPS. А в 2003 году в P.A. Semi Добберпул сформировал собственную инженерную команду, лидерами которой стали те, кто в свое время вместе с ним проектировал Alpha. На должность главного архитектора был приглашен Питер Баннон, перешедший в P.A. Semi с высокой должности из корпорации Intel, где за участие в разработке платформы Itanium удостоился почетного звания Intel Fellow. Баннон, как его коллеги, ветеран DEC, он проектировал несколько моделей мини-ЭВМ VAX, затем несколько версий Alpha 21164, а уже в Compaq— Alpha 21364.
P.A. Semi относится к распространенной ныне категории полупроводниковых «стартапов»— компаний, не имеющих собственного производства. Она насчитывает всего 150 сотрудников, большинство из них— специалисты высочайшего класса. Показательно то, что P.A. Semi причисляют к самым щедро финансируемым стартапам; значит, инвесторы возлагают на нее большие надежды. Это и не удивительно, ведь основал и возглавляет P.A. Semi Дэн Добберпул— один из наиболее именитых инженеров, обладающий множеством наград и званий, заслуженных еще в то время, когда он был главным проектировщиком DEC Alpha, самого производительного среди современных ему процессоров, а также первого процессора с пониженным потреблением StrongARM. Проект StrongARM после распада DEC был куплен Intel, и сегодня его пятая версия, известная под названием XScale, широко используется в мобильных устройствах. Позже, вплоть до 2000 года, в компании SiByte Добберпул участвовал в разработке исторически первого многоядерного процессора Mercurian-1250, где было четыре ядра с архитектурой MIPS. А в 2003 году в P.A. Semi Добберпул сформировал собственную инженерную команду, лидерами которой стали те, кто в свое время вместе с ним проектировал Alpha. На должность главного архитектора был приглашен Питер Баннон, перешедший в P.A. Semi с высокой должности из корпорации Intel, где за участие в разработке платформы Itanium удостоился почетного звания Intel Fellow. Баннон, как его коллеги, ветеран DEC, он проектировал несколько моделей мини-ЭВМ VAX, затем несколько версий Alpha 21164, а уже в Compaq— Alpha 21364.
Стратегия проектирования процессора со сверхнизким потреблением энергии, предложенная Добберпулом, отличается рациональностью. Ее суть в усовершенствовании известной и хорошо проверенной архитектуры. В качестве прототипа был лицензирована архитектура 64-разрядного процессора IBM Power; предпочтение было отдано именно ему, потому что IBM Power и без того отличается высокими показателями удельной производительности, кроме того, имеется значительная инсталляционная база. Проделанную под руководством Добберпула работу можно назвать «энергетическим тюнингом», в результате которого на базе IBM Power был создан двухъядерный процессор PWRficient PA6T-1628M, потребляющий в среднем режиме не более 13 ватт при работе на средней частоте 2 ГГц. Использованная технология, которая называется «тактируемая блокировка» (clock gating), позволяет временно отключать неработающие блоки; идея такой блокировки в ограниченных масштабах реализована, например, в Pentium 4. (Асинхронную архитектуру, где по определению нет простаивающих триггеров, иногда называют perfect clock gating, то есть «идеальной тактируемой блокировкой».) Для реальной синхронной архитектуры кроме блокировки придумать что-то иное, пожалуй, сложно; вопрос в том, насколько эффективно эта процедура реализована, каково соотношение активных и блокированных транзисторов. Эта величина напрямую зависит от степени грануляции блокировки, иначе говоря, от размеров блокируемых модулей. В тех процессорах, где реализована «грубая» (coarse-grain) блокировка, ее область действия распространяется на отдельные функциональные блоки, их количество измеряется максимум десятками. Она позволяет сократить расход энергии в пределе не более, чем на 40%. Мелкозернистая (fine-grain) технология, предлагаемая P.A. Semi, позволяет довести число блокируемых узлов до 25340, уменьшив расход энергии в разы, если не на порядок. Разумеется, фактический расход энергии зависит от исполняемой программы. Однако испытания показали, что даже при появлении так называемого «температурного вируса» (thermal virus), вызывающего наиболее тяжелый режим, способный перегреть и вывести из строя процессор, потребление не превышает 25 ватт, то есть ниже, чем при альтернативных технологиях оптимизации. Реализация мелкозернистого подхода не может быть механически распространена на существующую архитектуру; он включает ее расширение специализированными архитектурами и разбиение процессора на разделы, которые можно «отключать», используя механизм тактируемой блокировки.
В ближайшей перспективе созданный в P.A. Semi процессор будет использоваться во встроенных системах управления оборонного назначения, прежде всего в беспилотных летательных аппаратах и сетевых устройствах (видимо, именно таким образом можно быстрее отработать инвестиции). Но известно, что большинство современных разработок имеет двойное назначение, и главной целью создания PWRficient PA6T-1628M являются высокопроизводительные компьютерные системы (High Performance Computing, HPC). Если мы продолжим следовать автомобильной терминологии, тюнинг следует назвать глубоким. Процессор P.A. Semi задуман с целью создания специализированных серверов-лезвий, и этот замысел непосредственным образом отражается в его конструкции. Такая конструкция оптимизирована по шести основным требованиям, предъявляемым к процессорам, которые используются в высокопроизводительных кластерах.
1. Системная архитектура. С точки зрения системной архитектуры PWRficient— не голый процессор, а функционально законченное устройство, так называемый «автономный вычислительный элемент», где помимо процессоров есть и контроллер памяти, подсистема ввода/вывода и мощный процессор для вычислений с плавающей запятой. Показательно распределение транзисторов по функциональным устройствам. Из общего числа транзисторов, составляющего примерно 200 млн, на процессорные ядра приходится только по 21 млн, на память— 24 млн, все остальное ушло на системные устройства. Каждое из двух ядер PA6T имеет собственное устройство для вычислений с плавающей запятой, по 64 Кбайт кэш-памяти первого уровня для команд и данных, а также модуль VMX, который реализует систему команд AltiVec. (Данное расширение системы команд предложили в конце 90-х годов разработчики PowerPC, входившие в альянс Apple, IBM и полупроводникового подразделения Motorola, ныне компания Freescale Semiconductor.) Использование данного модуля ускоряет выполнение операций с плавающей точкой; кроме того, позволяет выполнять целочисленные операции в векторном режиме. Также в процессор заложены возможности, обеспечивающие его виртуализацию.
Отличительной особенностью PWRficient является то, что для связи между модулями в процессор встроен оригинальный внутренний коммутатор CONNEXIUM, объединяющий ядра, кэш-памяти второго уровня (2 Мбайт), управление памятью DDR2 и подсистемой управления вводом/выводом ENVOI; последняя поддерживает до 8 портов PCI Express, два порта 10-G Ethernet или порта Gigabit Ethernet. CONEXIUM обеспечивает скорость обмена данными до 64 Гбайт/с. Наличие такого мощного внутреннего коммутатора позволит в будущем выпускать версии процессора с числом ядер 4, 8 и 16.
Приведенная на рис. 1 блок-схема существенно упрощена, на самом деле по совокупности суммарное количество перечисленных узлов приближает PWRficient к статусу «системы на кристалле» (System-on-Chip, SoC)— в этом суть глубокого тюнинга. Для того чтобы построить на нем сервер-лезвие, достаточно установить на системную плату память. Из рис. 2 и 3 видно, что на таком сервере нет практически ничего, кроме процессора, памяти и еще адаптера InfiniBand. Компактность и низкое потребление позволяет строить многопроцессорные лезвия, например компания Extreme Engineering Solutions выпускает лезвия с девятью процессорами (18 ядер).

 |
Рис. 2. Сервер-лезвие XPedite8070 компании Extreme Engineering Solutions |
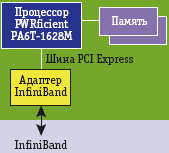 |
Рис. 3. Блок-схема сервера-лезвия на базе процессора PWRficient |
2. Производительность на операциях с плавающей запятой. Большинство приложений кластеров для высокопроизводительных вычислений так или иначе связано с численным моделированием и требует высокой скорости выполнения операций с плавающей точкой. В связи с этим PWRficient комплектуется конвейерным устройством вычислений с плавающей запятой, способным выполнять за один такт две операции— умножение и сложение, что эквивалентно двум операциям на цикл. Если же учесть, что в одном процессоре два таких устройства, работающих на частоте 2 ГГц, то это значит, что их суммарная производительность составляет 8 GFLOPS. Наличие двух модулей VMX теоретически увеличивает производительность до 32 GFLOPS на операциях с одинарной точностью.
3. Полоса пропускания и задержка на тракте между процессором и памятью. Производительность кластеров напрямую зависит от ширины полосы пропускания и задержки, поэтому при проектировании PWRficient этим показателям было уделено особое внимание. В результате время задержки при обращении к закрытым страницам не превышает 60 наносекунд (это лучше, чем, скажем, у процессора Intel Xeon, работающего на той же частоте), а канал «память-процессор» обеспечивает скорость передачи до 16 Гбайт/с.
4. Возможности ввода/вывода. Производительность на операциях ввода/вывода определяется тем, насколько полно процессор может использовать пропускную способность каналов ввода/вывода. Наличие в PWRficient встроенного контроллера обеспечивает работу в полном дуплексном режиме с максимальным использованием возможностей каналов. Процессор обеспечивает разгрузку приложений тем, что в нем реализована аппаратная поддержка коммуникационных протоколов.
5. Потребление энергии. С точки зрения потребления энергии PWRficient от трех до девяти раз эффективнее, чем его ближайший конкурент— низковольтный процессор Intel Sossaman.
6. Экономическая эффективность. По расчетам, стоимость эксплуатации равных по вычислительной мощности кластеров на 6400 процессорах Intel Sossaman и 4000 процессорах PWRficient составит соответственно 5,6 млн долл. и 1,1 млн долл., то есть соотношение 5:1 в пользу последнего.
***
О развернутых планах по внедрению PWRficient PA6T-1628M на будущее пока говорить сложно. P.A. Semi еще только выходит из «невидимого режима» и начинает осваивать рынок, но уже можно представить основные направления. В первую очередь необычные процессоры пойдут во встроенные сетевые устройства, в системы хранения данных и телекоммуникационные системы. Во вторую— в кластеры, стоечные серверы и grid-среды. Наконец, в третью— в специализированные устройства для высокопроизводительных вычислений.
Есть планы и по развитию самого процессора. В новых версиях будет снижаться напряжение питания, будут реализованы дополнительные режимы экономии энергии, увеличено число ядер, более эффективно предполагается использовать VMX. Для мобильных устройств планируется создать вариант процессора с одним ядром.
