

С той самой поры, как люди начали пользоваться компьютерами, исследователи занимаются повышением уровня абстракции, на котором программисты пишут свои коды. Первый компилятор языка Фортран стал важной вехой в истории компьютерной науки, потому что с его появлением программисты получили возможность указывать, что именно должна делать машина, а не как она должна выполнять свои задачи. С того времени уровень абстракции в программировании постоянно повышается. Современные объектно-ориентированные языки позволяют программистам справляться со столь сложными задачами, что на заре программирования об их решении можно было только мечтать.

Метод разработки на базе моделей (Model-Driven Development, MDD) [1, 2] является естественным продолжением этой традиции. Ныне компиляторы автоматически решают такие проблемы, как размещение объектов, просмотр и поиск методов, а также обработку исключительных ситуаций — а ведь еще несколько лет назад все это приходилось делать вручную. Разработка на базе моделей, еще в большей степени повышающая уровень абстракции, применяется с целью автоматизации тех сложных (хотя и рутинных) задач программирования — таких, как надежность систем или интероперабельность, — которые до сих пор приходилось реализовывать вручную.
MDD может кардинально изменить ныне применяемые подходы к созданию приложений. Многие специалисты понимают это, и уже сегодня упорно работают над созданием спектра поддерживающих технологий. Однако общепринятых определений того, что, собственно, представляет собой метод разработки на базе моделей и в какого рода поддержке он нуждается, до сих пор не существует. В частности, многие требования к средствам поддержки MDD — в тех случаях, когда такие средства были определены, — до сих пор не нашли явного выражения.
Требования к MDD
Основная причина, побуждающая брать на вооружение метод MDD, — стремление повысить продуктивность разработчиков. В обеспечении этого результата MDD играет двоякую роль:
- он повышает продуктивность в краткосрочной перспективе, поскольку повышает ценность программы в том, что касается ее функциональных возможностей;
- он повышает продуктивность в долгосрочной перспективе, поскольку удлиняет сроки морального старения программы.
Уровень продуктивности в краткосрочной перспективе зависит от набора функций, которыми обладает программа. Чем шире этот набор, тем выше будет продуктивность. Сегодня именно на это нацелены почти все средства поддержки MDD; очень многие поставщики инструментальных средств сосредоточивают свои усилия на автоматическом генерировании кода на базе визуальных моделей. Но эти усилия могут способствовать совершенствованию лишь одного из двух главных аспектов MDD.
Уровень продуктивности в долгосрочной перспективе зависит от долговечности программного артефакта. Чем дольше период, в течение которого сохраняется ценность артефакта, тем большую прибыль на вложенные средства он принесет. Таким образом, второй — и стратегически более важный аспект MDD состоит в том, чтобы снизить чувствительность первичного артефакта к переменам. Особую важность имеют четыре фундаментальных фактора изменений.
1. Разработчики. До тех пор пока разработчики хранят важнейшие сведения, касающиеся проектирования новых изделий, в своих головах, их организации рискуют потерять эти сведения вследствие кадровой текучки. Значит, нужно сделать так, чтобы жизнь программных артефактов не обрывалась с переходом на другую работу их создателей, а для этого артефакты должны быть доступными и полезными как можно большему числу людей. Их нужно представлять не только в виде лаконичных описаний, но и в форме, легко доступной для понимания всех заинтересованных лиц, включая клиентов.
2. Требования. Изменения требований всегда были большой проблемой для программистов, но сегодня это справедливо как никогда прежде. Дело не только в том, что разработчикам приходится все быстрее реализовывать новые функции, но и в том, что воздействие этих изменений на уже созданные фрагменты системы должно быть минимальным. Во всяком случае, появление новых возможностей не должно быть сопряжено с необходимостью приложения дополнительных усилий со стороны обслуживающего персонала и не должно нарушать функциональность подключенных систем. «Достраивающие» систему разработчики не имеют права надолго выводить из эксплуатации приложения корпоративного уровня; они должны реализовывать необходимые изменения при функционирующей системе. На техническом уровне из этого следует, что необходимы средства, обеспечивающие динамическое добавление новых типов в «горячем» режиме.
3. Платформы разработки. Первичные программные артефакты, «привязанные» к одному инструментальному средству, будут полезны только на протяжении жизненного цикла этого средства. Но инструменты постоянно изменяются, поэтому очевидна необходимость «развести» артефакт и его среду разработки. Отсюда вытекает другое техническое требование: артефакты должны храниться в инструментарии в таких форматах, которые были бы «понятны» другим инструментам; иначе говоря, инструменты должны характеризоваться высокой степенью интероперабельности.
4. Платформы развертывания. Как только разработчики овладевают технологией одной новой платформы, место этой платформы занимает новая. Чтобы продлить жизненный цикл программных артефактов, разработчики должны защитить их от изменений на уровне платформы. В техническом смысле это означает необходимость максимальной автоматизации процесса получения характерных для той или иной платформы программных артефактов.
Итак, поддерживающая MDD инфраструктура должна определять:
- Имеющиеся концепции, на базе которых создаются модели и правила, регулирующие их использование.
- Нотацию, с помощью которой описываются модели.
- Способы, с помощью которых элементы модели представляют элементы реального мира, включая программные артефакты.
- Концепции, облегчающие создание динамических пользовательских расширений концепций модели, нотации модели и моделей, созданных на их основе.
- Концепции, облегчающие взаимообмен концепций моделей и нотации, а также моделей, созданных на их основе.
- Концепции, облегчающие создание определяемых пользователями соответствий между моделями и другими артефактами, включая программный код.
К инфраструктуре MDD
Анализ рассмотренных требований показывает, что одна из технологических основ поддержки MDD — это визуальное моделирование. Визуальное моделирование может обеспечить реализацию пунктов 1-3. Мало того, в различных инженерных дисциплинах, в том числе и в создании программного обеспечения, оно давно зарекомендовало себя как эффективный метод.
Самую высокую степень совместимости с гибкими языковыми расширениями продемонстрировали объектно-ориентированные технологии. Предоставляя разработчикам средства расширения набора имеющихся типов, объектно-ориентированные языки напрямую удовлетворяют требование 4, хотя и статически (т.е., путем отключения системы). Поэтому объектная ориентация повсеместно рассматривается в качестве еще одной ключевой основы метода MDD.
Наконец, подход, который оказался самым эффективным в удовлетворении описанных выше требований 5 и 6, состоит в использовании приемов описания метауровней. Они жизненно важны в обеспечении как динамических, так и статических средств удовлетворения требования 4. С помощью приемов описания метауровней конструкций моделей и пользовательских типов можно в полной мере настроить модели в соответствии с критериями определенных доменов или классов и динамически добавлять новые типы на этапе исполнения.
Следовательно, главная проблема, с которой мы сталкиваемся в процессе создания инфраструктуры MDD, состоит в оптимальной интеграции визуального моделирования, средств объектной ориентации и методов описания метауровней.
Традиционная инфраструктура MDD
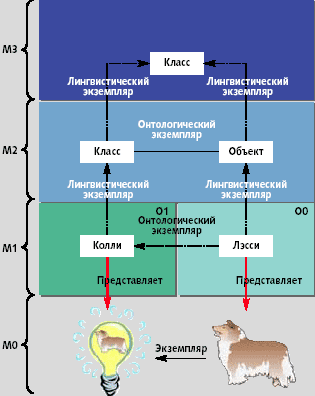
На рис. 1 показана традиционная четырехуровневая инфраструктура, которая лежит в основе первого поколения технологий MDD, а именно Unified Modeling Language [3] и Meta-Object Facility [4].

|
| Рис. 1. Традиционная инфраструктура моделирования от Object Management Group |
Данная инфраструктура состоит из иерархии уровней моделей, каждый из которых (кроме самого верхнего) характеризуется как экземпляр уровня, расположенного выше. Самый нижний уровень, M0, содержит пользовательские данные — фактические объекты «данные», которыми и должно манипулировать программное обеспечение. Следующий уровень, M1, определяют как уровень, содержащий модель пользовательских данных уровня M0. На этом уровне хранятся пользовательские модели. Уровень M2 содержит модель информации, хранимой на уровне M1. Поскольку в данном случае речь идет о «модели модели» — ее часто называют метамоделью. Наконец, уровень M3 содержит модель информации, хранимой на уровне M2, поэтому его часто называют мета-метамоделью. Исторически сложилось так, что наряду с этим его часто именуют Meta-Object Facility (MOF).
Преимущество этой почтенной четырехуровневой архитектуры состоит в том, что в нее легко встраиваются новые стандарты моделирования (например, Common Warehouse Metamodel) в качестве экземпляров MOF на уровне M2. Таким образом, наделенные средствами для работы с MOF инструменты дают возможность манипулировать новыми стандартами моделирования и могут обеспечивать обмен данными между MOF-совместимыми стандартами моделирования.
Эта традиционная инфраструктура с успехом сыграла роль основы MDD-технологий первого поколения, но она недостаточно хорошо масштабируется для того, чтобы обеспечить все описанные выше технические требования 1-6. В частности, мы можем указать на четыре основные проблемы.
- Не существует объяснения, раскрывающего отношения объектов данной инфраструктуры с элементами реального мира. Принимает ли инфраструктура элементы реального мира или они остаются вне нее?
- Данная инфраструктура предполагает, что фундаментальная природа всех отношений типа "объект A есть экземпляр объекта B" между элементами идентична. Такова ли ситуация на самом деле - или нам следует найти какой-то более тонкий подход?
- Не существует каких-либо явно выраженных принципов, позволяющих судить о том, на каком уровне располагать тот или иной элемент. Похоже, что использование единичного отношения "A есть экземпляр B" всегда порождает элементы несогласованности. Можем ли мы использовать порождение экземпляра (instantiation) для определения границ метауровней, и если да, то как?
- Когда необходимо ввести заранее определенные концепции, предпочтение обычно отдается описаниям метауровней. Как интегрировать в архитектуру иной способ введения заранее определенных концепций - библиотеки (супер)типов?
Для того чтобы решить эти проблемы, мы должны взглянуть на роль метамоделирования MDD с более современных позиций и углубить упрощенное представление о порождении экземпляра как о некоем заданном понятии, подходящем для всех случаев жизни. Представление об отношении «A есть экземпляр B» как о единой в сущности форме, играющей одну и ту же роль, плохо соотносится с требованиями 1-6. Полезно отказаться от такого представления и идентифицировать два отдельных ортогональных измерения метамоделирования, что позволит говорить о двух различных формах конкретизации [5, 6]. Одно измерение лежит в сфере определений языков и, следовательно, использует лингвистическое порождение экземпляра. Другое измерение лежит в сфере определений доменов и, следовательно, использует онтологическое порождение экземпляра. Обе формы возникают одновременно и служат для того, чтобы точно расположить элемент модели вместе с языково-онтологическим пространством.
Лингвистическое метамоделирование
В требованиях 1-3 в сущности выражена потребность в средствах определения языков (таблица 1). Поэтому при проведении недавно выполненных работ по совершенствованию инфраструктуры основные усилия исследователей были сосредоточены на использовании метамоделирования в качестве инструмента языкового моделирования. В таком контексте лингвистическое отношение «A есть экземпляр B» считается доминирующим, а уровни M2 и M3 рассматриваются как уровни языковых определений.
При подобном подходе к онтологическим отношениям «A есть экземпляр B», которые соотносят пользовательские концепции с их доменными типами, отводится второстепенная роль. Иными словами, если лингвистические отношения «A есть экземпляр B» пересекают лингвистические метауровни (и формируют основу для последних), то онтологические отношения «A есть экземпляр B» не пересекают этих уровней; они соотносят объекты внутри данного уровня. На рис. 2 представлена эта последняя интерпретация четырехуровневой архитектуры, реализованная в новых стандартах UML 2.0 и MOF 2.0. В последнем представлен по преимуществу лингвистический взгляд на вещи, тем не менее полезно допустить такую ситуацию, при которой онтологическое (внутриуровневое) порождение экземпляра обретает свои собственные онтологические (вертикальные) метауровневые границы.
|
| Рис. 2. Представление лингвистического метамоделирования |
Рис. 2 не только выявляет существование двух ортогональных метаизмерений, но и иллюстрирует отношение между элементами модели и соответствующими элементами реального мира. Пользовательские объекты уже не размещаются на уровне M0 — их место занимают элементы реального мира, моделируемые с помощью пользовательских объектов. Отметим, что реальная собака по кличке Лэсси представлена объектом «Лэсси»; т.е. отношение «A есть экземпляр B» уже не используется для характеристики реальной Лэсси как экземпляра Колли. Пользовательские объекты (т.е., используемые в модели представители объектов реального мира) теперь занимают уровень M1, где наряду с ними размещаются типы, онтологическими экземплярами которых они являются. (Пользовательские данные тоже рассматриваются как часть реального мира — даже при том, что они являются искусственными и могут даже представлять другие элементы реального мира). Каждый уровень от M1 и выше рассматривается как модель, которая выражена на языке, определенном на вышележащем уровне.
Онтологическое метамоделирование
Лингвистическое метамоделирование позволяет удовлетворять многие из перечисленных технических требований; но само по себе оно не дает решения задачи. К примеру, требование 4 предполагает возможность динамического расширения набора доменных типов, используемых при моделировании, а это, в свою очередь, предполагает возможность определения доменных метатипов, иначе говоря, типов типов. Мы называем это онтологическим метамоделированием, поскольку в нем предусматривается описание концепций, существующих в том или ином домене, и их свойств.
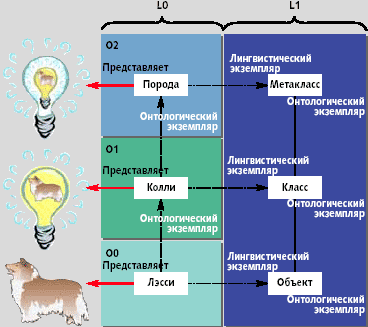
На рис. 2 представлен пример онтологического порождения экземпляров. Элемент модели Лэсси, являющийся онтологическим экземпляром колли, располагается соответственно на более низком, нежели Колли, онтологическом уровне. Этим выражается то обстоятельство, что в реальном мире идея колли является логическим типом Лэсси.
На рис. 2 представлены только два уровня онтологической модели — O0 и O1. Оба они размещаются на лингвистическом уровне M1, но мы, естественно, можем расширить это измерение и ввести дополнительные онтологические уровни. На рис. 3 показан еще один онтологический уровень — O2. Он показывает, что мы можем рассматривать объект «колли» как экземпляр объекта «порода». Онтологический метатип дает возможность не только отличать один тип от другого; его можно также использовать для определения свойств метатипа. К примеру, порода позволяет отличать такие типы, как колли и пудель от других типов (скажем, CD и DVD), но тип «порода» можно использовать для определения свойств породы — таких, как географический район, где была выведена та или иная порода, или другая порода, на основе которой она была выведена.
|
| Рис. 3. Представление онтологического метамоделирования |
Кроме того, рис. 3 иллюстрирует еще один важный момент, касающийся отношений между двумя метаизмерениями (лингвистическим и онтологическим). Дело в том, что этот рисунок представляет собой повернутый на 90 градусов рисунок 2 с добавлением уровня O2. В дополнение к этому мы изменили обозначения уровней MO и M1 на LO и L1, чтобы подчеркнуть их лингвистическую роль (L — первая буква английского слова language — «язык» — прим. пер.). Обе схемы имеют одинаковую силу, поскольку в традиционной инфраструктуре онтологическая или лингвистическая конкретизации не различаются и метауровням не присваиваются какие-либо значения.
Но дело не только в том, что обе схемы — или обе точки зрения в равной степени действительны. Плюс к этому они в равной степени полезны. Точно так же, как при использовании лингвистического подхода онтологическому метамоделированию отводится роль второго плана, на второй план отходит лингвистическое метамоделирование, если мы становимся на онтологическую точку зрения.

|
| Рис. 4. Онтологическое метамоделирование через стереотипы |
В стандартах UML 2.0 и MOF 2.0 лингвистическому измерению придается первоочередное значение. Уровни O0 и O1 присутствуют на уровне M1, но нет метауровневой границы, явно отделяющей эти уровни друг от друга. Как таковое онтологическое метамоделирование не исключается, но механизмы его реализации — профили и стереотипы — имеют известные ограничения. Возможность выразить отношение между объектами «колли» и «порода» (первый является экземпляром второго) существует (рис. 4), но при стереотипном моделировании уже нет возможности пользоваться полным арсеналом концепций моделирования M1 — к примеру, визуальная модель ассоциаций и отношений обобщения между метаконцепциями.
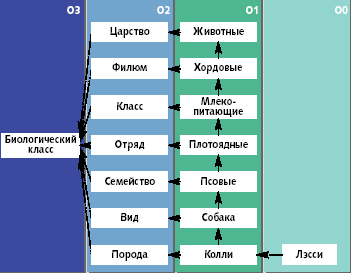
Однако исследователи давно уже признают полезной способность свободного построения моделей с помощью метаконцепций (т.е. полного использования потенциала уровня O2). Возможность использовать такие метаконцепции, как «Порода Дерева» [7] или «порода» дает большие преимущества. На рис. 5 представлены, возможно, самые зрелые и установившиеся примеры онтологического метамоделирования: биологическая систематика живых существ. Метаконцепции, такие, как «порода», «вид» и т.д. позволяют добавлять к систематике новые классы существ. В программной системе они облегчили бы динамическое добавление новых типов на этапе исполнения. Обратите внимание, что на уровне O1 нельзя использовать концепции «порода», «вид» и т.д. в качестве супертипов. Ведь при том, что утверждения «Лэсси — это колли», «Лэсси — это собака» имеют смысл, заявления о том, что Лэсси есть порода или вид, и т.д., явно бессмысленны. К тому же, размещение уровня O3 (см. рис. 5) в онтологическом метаизмерении не составляет проблемы, а стереотипы не предназначены для решения этой задачи.
|
| Рис. 5. Онтологическая метамодель биологической классификации |
Онтологическое метамоделирование имеет особую важность в контексте MDD, поскольку оно явно необходимо при реализации двух из основных стратегий преобразования моделей, описанных в руководстве пользователя MDA [8]. Во-первых, оно является основой для механизма маркировки, который предусмотрен в качестве одного из основных способов обеспечения управляемого пользователями определения преобразования моделей, иначе говоря, для обеспечения требования 6. Во-вторых, это основа для определения соответствий в той версии преобразования типов уровней, которая базируется на структуре.
Предстоящий пересмотр предлагаемой OMG инфраструктуры MDD в стандартах UML 2.0 и MOF 2.0 можно считать важным шагом вперед, поскольку он даст возможность использовать две различные формы конкретизации. При этом остаются неразрешенными две существенные проблемы.
Во-первых, хотя разграничение налицо, оно не выражено достаточно явно. Хотя инфраструктура признает границы лингвистических метауровней, онтологические границы остаются неявными. И если учесть при этом то обстоятельство, что стереотипы остаются предпочтительным механизмом пользовательского метамоделирования, ясно, что и новый стандарт имеет неоправданный уклон в сторону лингвистического метамоделирования.
Во-вторых, в нынешнем механизме профилирования все еще просматривается уклон в сторону размещения предопределенных концепций на метауровне, а не на уровне M1, где размещаются стандартные пользовательские типы. И это несмотря на тот факт, что библиотеки на уровне M1 давно предоставляют предопределенные концепции пользователям для непосредственного применения или для специализации. В сущности, в руководстве пользователя Model-Driven Architecture User Guide эта форма повторного использования и предопределения открыто рекламируется как средство определения соответствий повторно используемых типов.
Но несмотря на эту оговорку, новая инфраструктура MDD несомненно являет собою важный шаг вперед и обеспечивает почти все указанные технические возможности. n
Литература
- J. Mukerji, J. Miller, eds., "Model Driven Architecture", www.omg.org/cgi-bin/doc?ormsc/2001-07-01.
- D.S. Frankel, Model Driven Architecture: Applying MDA to Enterprise Computing, OMG Press, 2003.
- Unified Modeling Language Specification, Object Management Group, 2003, http://doc.omg.org/formal/03-03-01.
- Meta Object Facility (MOF) Specification, Object Management Group, 2003, http://doc.omg.org/formal/02-04-03.
- C. Atkinson, T. Kuhne, "Rearchitecting the UML Infrastructure", ACM Trans. Modeling and Computer Simulation, vol. 12, no. 4, Oct. 2002.
- J. Bezivin, R. Lemesle, "Ontology-Based Layered Semantics for Precise OA&D Modeling", Object-Oriented Technology, LNCS 1,357, Springer-Verlag, 1998.
- J. Odell, "Power Types", J. Object-Oriented Programming, vol. 7, no. 2, Mar./Apr. 1994.
- XMIVersion 1 Production of XML Schema Specification, Object Management Group, 2003, http://doc.omg.org/formal/03-05-01.
Колин Аткинсон (atkinson@informatik.uni-mannheim.de) руководит кафедрой программной инженерии в университете Мангейма. Томас Кюне (kuehne@informatik.tu-darmstadt.de) — ассистент профессора в Дартмундском технологическом университете.
Colin Atkinson, Thomas Kuhne, Model-Driven Development: A Me tamodeling Foundation. IEEE Software, September/October 2003. IEEE Computer Society, 2003, All rights reserved. Reprinted with permission.
