
Осознание того, что шины, в том числе шина между процессором и памятью, сдерживают рост пропускной способности между микропроцессором, оперативной и внешней памятью, сетевыми интерфейсами, привело к предложению объединять указанные компоненты каналами типа «точка-точка» с применением пространственных коммутаторов [1].
Основными вехами на этом пути служат стандарт SCI [2], спецификации Next Generation I/O, Future I/O. Развитие этих идей нашло отражение в появлении спецификаций InfiniBand и RapidIO [3, 4], основанных на модели распределенной обработки. В рамках этой модели вычислительные системы предлагается строить на соединениях «точка-точка», с массовым параллелизмом и коммутацией пакетов. Фактически, для объединения процессоров, памяти и внешних устройств предлагается использовать адаптеры с шиной процессора, коммутаторы и адаптеры терминальных устройств. Использование систем, созданных на базе этих спецификаций, остро ставит проблему построения распределенной разделяемой памяти (DSM — distributed shared memory), т.е. памяти с единым адресным пространством, доступ к которой выполняется посредством команд «чтение» и «запись». Рассмотрим разработанные в соответствии с требованиями различных классов систем подходы к организации DSM и оценим их применительно к спецификациям InfiniBand и RapidIO.
Основная проблема при создании разделяемой памяти в многопроцессорных системах состоит в том, как извещать другие процессоры об изменениях, вызванных выполнением команд записи. Типичным является наличие в процессоре нескольких уровней кэш-памяти [5]. Стремление к повышению производительности микропроцессоров стимулирует переход от кэша со сквозной записью к кэшу с буферизированной записью и к кэшу с обратной записью. При буферизации и обратной записи возрастает промежуток времени между изменением в локальной копии данных, размещенной в кэш-памяти и их появлением в шине памяти микропроцессора. Следовательно, доставка этих изменений в удаленные копии тех же данных из других блоков памяти, включая кэш-память других процессоров, также будет происходить с задержкой. Кроме того, при обратной записи модификации данных в кэше не появляется на шине памяти, кроме моментов смены кэш-строк.
Для модификации удаленных копий данных используются коммуникационный протокол и протокол согласованности (когерентности) состояния памяти [6]. Первый применяется для доставки изменений, а второй призван предотвращать использование копий данных, подвергшихся модификации в другом процессоре. В простейшем случае, например, при объединении процессоров и памяти, происходит «прослушивание» шины с целью обнаружения выполнения команд записи в адреса ячеек памяти, копии которых размещены в кэшах и в основной памяти. В этом случае коммуникационный протокол и протокол когерентности неразрывно связаны.
Для сохранения когерентности данных в соответствии с интуитивной моделью строгой состоятельности памяти [6, 7] операция чтения из разделяемой памяти должна возвращать последнее записанное значение. Поэтому, когда одна из множества копий модифицируется, остальные должны либо быть объявлены несостоятельными, либо модифицироваться. Выполнение этих действий требует специальных аппаратных средств быстрого распространения изменений. Однако какими бы быстрыми они не были, следование модели строгой состоятельности ведет к снижению производительности. Это обусловлено обеспечением непременной синхронности обращений процессоров к памяти и введением глобального времени, позволяющего упорядочить действия, выполняемые во всех процессорах системы. Поэтому для повышения производительности необходимы модели ослабленной состоятельности памяти, допускающие появление несогласованности копий данных в ходе их параллельной обработки с последующим обеспечением когерентности копий, чтобы результат исполнения программы был таким же, что и при строгой состоятельности.
Конкретную реализацию разделяемой памяти характеризуют [8]:
- уровень реализации (аппаратный, программный, аппаратно-программный);
- структура разделяемых данных (слово, кэш-строка, страница, сегмент, фрагмент, объект и т.д.);
- модель состоятельности памяти, определяющая допустимые последовательности доступа в память (SRSW — «один читатель/один писатель», MRSW — «много читателей/один писатель», MRMW — «много читателей/много писателей»);
- политика обеспечения когерентности данных (модификация, объявление несостоятельными);
- механизм управления распределением памяти и размещением данных (централизованный/распределенный, статический/динамический).
В данный момент используется несколько моделей состоятельности памяти [6-9].
Строгая (strict): каждая операция чтения возвращает последнее записанное значение.
Последовательная (sequential): все процессоры в системе наблюдают один и тот же порядок выполнения операций записи и чтения (процессор, выполняющий запись приостанавливается до получения подтверждений об объявлении несостоятельными всех копий модифицируемых данных или о модификации этих копий).
Процессорная (processor): наблюдаемый в двух процессорах порядок выполнения операций чтения/записи может не совпадать, но порядок выполнения записей, производимых каждым процессором, должен быть одним и тем же.
Cлабая (weak): вводящая разграничение между обычным и синхронизованным доступами в память при выполнении требования состоятельности памяти только при доступах в точках синхронизации и разрешением несогласованности данных вне этих точек.
Свободная (release): уточненная модель слабой состоятельности, требующая состоятельности памяти только между парой операций синхронизации acquire-release (acquire — открывает критический интервал и обеспечивает исключительный доступ процессора к разделяемым данным, release — закрывает критический интервал, разрешая всем процессорам доступ к разделяемым данным). При этом операции синхронизации, выполняемые в разных процессорах, должны удовлетворять модели последовательной или процессорной состоятельности памяти.
Неторопливо-свободная (lazy release): модель свободной состоятельности с отложенным до момента непосредственного обращения распространением модификаций разделяемой памяти так, что при операции acquire передаются все предшествующие результаты команд записи, которые выполнялись до наступившего момента синхронизации.
Нетерпеливо-свободная (eager release): модель свободной состоятельности с передачей изменений разделяемой памяти при реализации операции release, безотносительно к тому, когда эти изменения будут востребованы.
Интервально свободная (scope): модель свободной состоятельности с разбиением исполнения на глобальные и локальные интервалы и гарантированием состоятельности разделяемых данных для всех процессоров только в конце каждого глобального интервала, а также гарантированием состоятельности разделяемых данных для последовательных локальных интервалов внутри каждого процессора.
Последовательно-свободная (entry): вариант модели свободной состоятельности, который требует доступа к разделяемым данным, защищенного синхронизирующими переменными, значения которых должны модифицироваться согласно модели последовательной согласованности (все процессоры должны иметь одну и ту же последовательность обращений к каждой из этих переменных).
Аппаратная реализация разделяемой памяти
При аппаратной реализации разделяемой памяти размер разделяемых единиц данных, как правило, составляет кэш-строку. Это обусловлено привязкой к механизму когерентности внутрикристальной многоуровневой кэш-памяти микропроцессоров. Поэтому аппаратные реализации универсальны и не требуют наличия в программах дополнительного кода для организации разделяемой памяти. Аппаратные реализации имеют малую задержку при передаче данных и обеспечивают высокую пропускную способность. Однако применение специальных аппаратных средств существенно повышает стоимость таких реализаций. Реализованная таким образом разделяемая память, доступна всем программам: все ячейки памяти одинаково доступны, что создает единый системный образ. С достаточной долей условности системы с разделяемой памятью можно разбить на два класса:
- системы с физически единой памятью;
- системы с физически распределенной по вычислительным модулям разделяемой памятью.
Системы с единой разделяемой памятью в основном представлены симметричными многопроцессорными архитектурами (SMP — symmetrical multiprocessing).
Системы с распределенной разделяемой памятью в свою очередь подразделяются на:
- системы с архитектурой NUMA (Non-Uniform Memory Architecture);
- системы с архитектурой СОМА (Cache-Only Memory Architecture);
- системы с рефлексивной памятью (RM — Reflective Memory).
В NUMA и COMA используется объявление данных несостоятельными, а в системах с рефлективной памятью применяется модификация разделяемых данных. В системах SMP возможно как объявление модифицируемых данных несостоятельными, так и модификация разделяемых данных.
Аппаратные реализации применяются в микропроцессорах с высокой степенью интеграции типа Alpha 21364 и Power 4, включающих управление периферией и когерентностью распределенной разделяемой памяти. Такие системы будут строиться из кристаллов двух типов, микропроцессоров и памяти, с переходом в дальнейшем к микропроцессорам со встроенным блоком динамической памяти.
Программная реализация разделяемой памяти
Системы на базе передачи сообщений
Сегодня системы на базе коммерчески доступных материнских плат и сетевых интерфейсов широко используются как дешевая аппаратная альтернатива системам с аппаратной реализацией распределенной разделяемой памяти. Протоколы когерентности памяти при программной реализации служат надстройкой над аппаратными средствами передачи сообщений. Это заведомо создает проблемы с недостаточной пропускной способностью при создании удаленных копий данных, передаче изменений и миграции данных, однако ничем не ограничивает разнообразие протоколов согласованности состояния памяти, позволяя учитывать особенности прикладных программ.
Строгая когерентность требует, чтобы каждый вычислительный модуль видел все доступы в память в одном и том же порядке. Однако обычно в параллельных программах используются операции синхронизации для управления доступом к разделяемым переменным или для установления порядка выполнения операций. В первом случае используются операции синхронизации для установки критических интервалов, во втором — барьерная синхронизация. Программа может не учитывать изменения разделяемых переменных вне критического интервала, что позволяет использовать модели свободной состоятельности памяти, поэтому ослабленная модель состоятельности памяти различает нормальный и синхронизированный доступ в память.
Модели ослабленной состоятельности памяти позволяют повысить производительность и расширяют спектр аппаратных платформ с различными коммуникационными протоколами, допускающими программную организацию разделяемой памяти, например, при определенных ограничениях на последовательности команд записи/чтения в прикладных программах. Реализация этих ограничений возлагается на примитивы синхронизации, посредством которых программист формирует допустимые последовательности команд.
В большинстве программных реализаций наименьшими элементами разделяемой памяти служат страницы, что обусловлено использованием существующих аппаратных средств организации виртуальной памяти для обнаружения записи в разделяемые страницы (например, запись в страницу, доступную только для чтения, или несостоятельную страницу). Однако сравнительно большой размер разделяемых страниц создает проблему ложного разделения, при котором конфликтными признаются модификации разными процессорами различных ячеек памяти одной страницы, не конфликтующие между собой [6-10]. Решением служит либо введение логических разделяемых единиц (объектов, типов данных), либо отображение многих виртуальных страниц на одну физическую [11].
Программный уровень реализации разделяемой памяти может базироваться либо на компиляторе, который выявляет доступы к разделяемым переменным и вставляет в исполняемый код вызовы примитивов синхронизации и процедур обеспечения когерентности, либо на библиотеке процедур, статически или динамически связываемых с прикладной программой. В любом случае, обращение к разделяемым данным, расположенным в другом вычислительном модуле, вызывает пересылку через коммуникационную среду с обеспечением когерентности всех копий одних и тех же данных в разных модулях. Обнаружение модифицированных данных требует либо внесения в код программы дополнительных команд для установки флагов модификации с целью указания измененных данных, либо создания перед первой записью в страницу копии разделяемых данных, которая используется по завершении интервала вычислений процесса для сравнения текущего состояния данных страницы с их сохраненной копией [12]. Для выявления моментов модификации разделяемых данных вводятся отметки логического времени, привязывающие изменения к интервалам синхронизированного доступа к разделяемым данным [13].
Эффективность программных реализаций распределенной разделяемой памяти ограничивается большим размером разделяемых страниц, временем выполнения операций синхронизации, включая определение модифицированных данных, а также задержкой и пропускной способностью коммуникационной среды [10]. В программных реализациях задержка доступа в удаленную память на порядок и более превосходит задержку в аппаратных реализациях, поэтому сравнимая производительность может быть достигнута лишь на некоторых классах задач.
При программной реализации разделяемая память доступна только ограниченному спектру прикладных программ, написанных с использованием четко определенных языковых конструкций, ориентированных на поддержку выявления компилятором записей в разделяемые переменные или использование библиотек для доступа к ним. Не все ячейки памяти одинаково доступны, поэтому разделяемая память не может использоваться для реализации синхронизации. Для этого используется ограниченное число примитивов синхронизации, например, критические интервалы (lock) и барьеры (barrier), реализованные посредством передачи сообщений. Стремление к повышению эффективности ведет к применению моделей состоятельности памяти, значительно отличающихся от используемых в системах с аппаратной реализацией разделения памяти. Программы для систем с аппаратной разделяемой памятью трудно переносить на системы с программной разделяемой памятью.
Модель свободной состоятельности памяти
Для реализации модели свободной состоятельности могут быть использованы различные протоколы, в том числе неторопливой (lazy release consistency — LRC) [12] и нетерпеливой (eager release consistency — ERC) [14] свободной состоятельности. В их рамках задержки, вызванные передачей модифицируемых данных, скрываются за счет буферизации записей или их конвейеризации в пределах критических интервалов. При этом в критическом интервале возможно объединение групп записей в одну, что повышает эффективность их передачи.
Вычислительные модули выполняют обычные операции чтения/записи и операции синхронизации acquire и release. Согласно требованиям модели необходимо обеспечить, чтобы все модули видели один и тот же порядок выполнения операций синхронизации. Одним из механизмов реализации частичной упорядоченности этих операций служит введение в каждом модуле локальной отметки времени и вектора отметок времени [13]. При свободной состоятельности время протекания процесса в каждом модуле делится на интервалы. После выполнения каждой операции acquire или release начинается новый интервал, а локальная отметка времени модуля увеличивается на 1. Вектор отметок времени служит для поддержки временных зависимостей между всеми модулями: его компоненты однозначно сопоставляются модулям. Каждая модификация памяти описывается отметкой записи write-notice. Когда вычислительный модуль выполняет операцию записи в разделяемую страницу, он создает отметку записи для этой страницы, помещая в эту отметку значение локальной отметки времени интервала, адрес и значение изменяемого слова. Модули формируют список отметок записи для каждой страницы.
Реализация протокола LRC
При реализации модели LRC операция синхронизации acquire, открывающая критический интервал, обеспечивает состоятельность всех разделяемых страниц для продолжения выполнения критического интервала [12]. Критический интервал завершается операцией release, после чего всем вычислительным модулям становятся доступны переменные, модифицированные в этом критическом интервале. Однако отметки записи для модифицированных разделяемых данных завершаемого критического интервала, необходимые для поддержания состоятельности страниц, могут быть получены другим модулем только при выполнении им операции acquire (рис. 3.).
Когда вычислительный модуль выполняет операцию acquire, он посылает модулю, выполнившему перед ним операцию release, копию своего вектора отметок времени. Тот в ответ высылает отметки записей, отсутствующие в модуле, выполняющем операцию acquire. В пересылаемом списке отметок записи имеются сведения не только о записях, произведенных самим вычислительным модулем, но и о записях, о которых ему стало известно в результате выполнения им операций синхронизации с другими модулями.
После получения отметок записи вычислительный модуль запоминает присланные отметки записей и модифицирует вектор отметок времени, присваивая каждому компоненту максимум из собственного значения и из значений полученного вектора. Он также делает несостоятельными копии всех страниц, для которых получены отметки записей, так как эти отметки содержат сведения о модификации страниц после последнего предыдущего согласования копий. При первом доступе к несостоятельной копии страницы вырабатывается сигнал «промах», обозначающий необходимость модификации страницы. Возможны, по крайней мере, два варианта доставки состоятельной страницы. Первый вариант основан на распределенном хранении внесенных в страницу изменений, а второй — на поддержке резидентной копии каждой страницы и ее пересылке в затребовавший модуль [12, 14].
При распределенном хранении изменений при первом доступе к странице по записи создается копия этой страницы. Затем в течение интервала страница может многократно модифицироваться. При выполнении операции release текущее состояние страницы сопоставляется с копией и вычисляется «разность» diff, совокупность адресов и новых значений измененных ячеек. Модуль связывает diff с отметкой записи. Когда модуль нуждается в состоятельной копии страницы, он просматривает имеющийся у него список отметок записей и определяет какие diff ему необходимы. Далее он запрашивает из других модулей требуемые ему diff и после их получения создает состоятельную копию страницы, применяя diff в требуемом порядке.
При реализации протокола LRC разность diff формируется и передается по явному запросу, а в случае ERC отметки записи передаются сразу после своего формирования. Недостаток LRC состоит в необходимости «сборки мусора» для удаления невостребованных копий страниц и diff. Приходится решать, до каких пор хранить эти данные.
При поддержке резидентной копии каждой страницы в конце интервала при выполнении release вычисленные diff для модифицированных страниц высылаются в резидентные для них вычислительные модули. Резидентные модули, используя получаемые diff, модернизируют соответствующие страницы. Недостатком этого протокола служит то, что при обращении многих модулей с запросом копии страницы возникает «узкое горло» при последовательной отсылке страницы каждому модулю.
Реализация протокола ERC
При реализации протокола ERC записи буферизируются до тех пор, пока не потребуется сделать их доступными при очередном выполнении операции release; для этого используется трансляционная рассылка измененных данных. Основное отличие протокола ERC от LRC состоит в том, что состоятельность страниц поддерживается операцией release, а не acquire. При этом ERC может выполнять лишние передачи данных для поддержания состоятельности копий страниц, даже если в некоторых модулях в них не будет обращений. Поэтому недостаток протокола состоит в том, что после обращения к несостоятельной странице требуется ожидание, пока необходимая разность diff будет вычислена и передана этому модулю.
Автоматическое аппаратное распространение записей
Существенным недостатком рассмотренных реализаций распределенной разделяемой памяти на базе традиционных систем передачи сообщений является необходимость программного определения diff. Для преодоления этого недостатка предлагается использовать аппаратные средства удаленной записи в память и удаленного чтения из памяти другого модуля [15-17]. По сути, они являются ограниченной реализацией рефлексивной памяти.
Для эффективной реализации протокола свободной состоятельности важно быстро обнаруживать записи в разделяемые страницы, предотвращать использование несостоятельных данных, получать состоятельные страницы данных при возникновении потребности в них. Запись в разделяемую страницу обнаруживается механизмом страничной организации памяти при попытке записи в несостоятельную страницу или страницу, доступную только для чтения.
Предотвращение использования несостоятельных данных основывается на отметках логического времени. Получение состоятельных копий страниц вместо применения diff основано на механизме записей в удаленную память и чтения из удаленной памяти. В каждом вычислительном модуле каждой странице сопоставляется вектор отметок времени слива, где отмечаются все изменения страниц, наблюдаемых модулем. В каждом модуле разделяемым страницам памяти сопоставляется вектор отметок синхронизации, устанавливающий, какие преобразования конкретной страницы необходимы, прежде чем модуль может получить к ней доступ. Собственно, этот вектор имеет для каждой страницы смысл списка отметок записи протокола LRC. Для ускорения операции acquire каждый вычислительный модуль содержит отметку глобального времени синхронизации, имеющую максимальное значение логического времени из всех постраничных отметок этого модуля. Если элемент в векторе отметок времени слива страницы меньше, чем соответствующий элемент вектора отметок синхронизации, то страница эта уже не состоятельна. При обратной ситуации модуль имеет более новую копию страницы по сравнению с той, которая ему необходима в соответствии с моделью состоятельности памяти.
Протокол Copyset-2 поддерживает одновременно состоятельными разделяемые страницы не более чем в двух модулях [15]. Аппаратные средства удаленной записи в память копируют записи в память этих модулей; при обращении к разделяемой странице со стороны третьего модуля копия страницы в одном из разделявших ее ранее модулей, объявляется несостоятельной, а второй модуль создает копию страницы для третьего и устанавливает с ним взаимное удаленное копирование разделяемой страницы. При выполнении операции release модуль увеличивает значение своего логического времени и использует его значение для удаленного изменения соответствующих элементов векторов отметок времени слива для страниц, которые подверглись модификации в завершаемом интервале.
При инициации выполнения операции acquire вычислительный модуль посылает другому модулю, последним исполнившим операцию release, свой текущий глобальный вектор отметок времени синхронизации, как это делается в протоколе LRC. Последний, получив этот вектор, устанавливает какие страницы несостоятельны в запрашивающем модуле, и высылает отметки записи для всех этих страниц. По получении этих отметок первый модуль, продолжая выполнять acquire, модифицирует свой вектор отметок синхронизации, присваивая элементам, соответствующим страницам, для которых поступили отметки записи, максимальное значение логического времени из отметок записи и текущего значения этих элементов. Если каждый элемент вновь сформированного вектора отметок синхронизации не больше соответствующего элемента вектора отметок времени слива, то модуль узнает, что у него все страницы состоятельны. В противном случае, если не все страницы состоятельны, они помечаются как отсутствующие. Их модификация еще не завершена, но уже инициирована. Если модуль при доступе к странице обнаруживает ее несостоятельность, то вновь сравнивает элементы вектора отметок синхронизации с элементами вектора отметок времени слива. Если обнаруживается состоятельность соответствующей страницы, то она помечается как состоятельная, а модуль продолжает выполнение интервала. В противном случае модуль ожидает, пока страница станет состоятельной, сравнивая элементы названных векторов.
Протокол Copyset-N использует резидентное размещение разделяемых страниц в вычислительных модулях [15]. Другие модули, имеющие копию страницы, настраивают отображение копии этой страницы в резидентную страницу для автоматического изменения последней при модификации копии. При выполнении операции release модуль увеличивает значение своего логического времени и использует это значение для удаленного изменения соответствующих элементов векторов отметок времени слива в каждой из резидентных страниц, которые подверглись модификации в завершаемом интервале. При выполнении операции acquire модуль действует так же, как в протоколе Copyset-2, однако не ждет пока страницы станут состоятельными, а запрашивает их из резидентных модулей. При этом запрашивающий модуль получает также вектор отметок времени слива, что позволяет ему оценить состоятельность поступившей страницы. Протокол AURC [15] сочетает оба протокола, работая в случае двух копий как Copyset-2, а при большем числе копий — как Copyset-N.
Направления развития
В рамках технологии RapidIO, предназначаемой ее разработчиками для использования во встроенных системах, вводится передача сообщений на базе операций send/receive и разделяемая память с распределенным каталогом с архитектурой NUMA. Для передачи сообщений предлагаются два механизма: почтовый ящик (mailbox) и прерывание (doorbell). Прерывания используются для передачи специальных 16-разрядных сообщений с целью установки связи между устройствами.
При реализации NUMA с целью повышения эффективности предлагается ограничение каталогов в пределах 16-процессорных образований, называемых доменами когерентности. Построение систем с большим числом процессоров должно вестись на базе таких доменов как традиционных сетей. С позиций реализации распределенной разделяемой памяти технология RapidIO выглядит ориентированной на программную реализацию в стиле [12, 14]. На первый взгляд, не ясно можно ли использовать для повышения эффективности ее реализации предложенные в спецификации форматы транзакций, определяемые пользователем.
Технология InfiniBand вводит передачу сообщений на базе операций send/receive, а также операции удаленного доступа в память по записи и чтению RDMA Write, RDMA Read и атомарные операции Compare & Swap and Fetch & Add. Последние используются для синхронизации распределенного протекания процессов. Предлагаемые операции можно применить для реализации протокола AURC, однако отсутствие аппаратного выявления доступа к разделяемым данным потребует вставки операций RDMA Write, RDMA Read либо на стадии компиляции, либо на уровне библиотек. Эффективность реализации распределенной разделяемой памяти могло бы повысить введение в хостовые адаптеры InfiniBand таблиц трансляции адресов, позволяющих прозрачно активизировать операции RDMA Write, RDMA Read при выдаче на шину процессора адреса разделяемой переменной.
В целом, программные реализации разделяемой памяти, направленные на использование современных распределенных систем из серийных микропроцессоров, должны быть востребованы при построении систем на базе технологий InfiniBand и RapidIO и должны оказать влияние на развитие этих технологий.
Литература
[1] В. Корнеев. Параллельные вычислительные системы. М.: Нолидж, 1999
[2] D. Gustavson. The Scalable Coherent Interface and Related Standards Projects. IEEE Micro. February 1992
[3] InfiniBand Architecture Specification, Volume 1, Release 1.0. October 24, 2000 Final. InfiniBand Trade Association
[4] RapidIO: An Embedded System Component Network Architecture. Architecture and Systems Platforms Motorola Semiconductor Product Sector 7700 West Parmer Lane, MS: PL30 Austin, TX 78729
[5] В. Корнеев, А. Киселев. Современные микропроцессоры. 2-е издание. М.: Нолидж. 2000
[6] A. Bilas, L. Iftode, J. Singh. Evaluation of Hardware Write Propagation Support for Next-Generation Shared Virtual Memory Clusters. Proceedings of the ICS 98. Melbourne. Australia. 1998
[7] L. Iftode, J. Singh, K. Li. Scope Consistency: A Bridge Between RC and EC. Proceedings of the 8-th ACM Symposium on Parallel Algorithms and Architectures, USA, June, 1996
[8] J. Protic, M. Tomasevic, V. Milutinovic. Distributed Shared Memory: Concepts and Systems. IEEE Computer Society Press. Los Alamitos. California. 1996
[9] S. Adve, A. Cox, S. Dwarkadas, R. Rajamony, W. Zwaenopoel. A Comparison of Entry Consistency Implementations. Proceedings of the IEEE/HPCA-2, San Jose, California, Feb. 1996, pp. 26-37
[10] K. Gharhchorloo. The Plight of Software Distributed Shared Memory. Proc. of the 1st Workshop on Software Distributed Shared Memory (WSDSM?99) Rhodes, Greece, June 25, 1999
[11] A. Itzkovitz, A. Schuster. Distributed Shared Memory: Bridging the Granularity Gap. Proc. of the 1st Workshop on Software Distributed Shared Memory (WSDSM?99) Rhodes, Greece, June 25, 1999
[12] C. Amza, A. Cox, S. Dwarkadas, P. Keheler, H. Lu, R. Rajamony, W. Yu, W. Zwaenepoel. TreadMarks: shared memory computing on networks of workstations. IEEE Computer, 29, February 1996
[13] C. Fidge. Logical Time in Distributed Computing Systems. IEEE Computer, July 1991
[14] J. Bennet, J. Carter, W. Zwaenepoel. Munin: Distributed Shared Memory Using Multi-Protocol Release Consistency. Operating Systems of the 90s and Beyond. Spriger-Verlag Lecture Notes in Computer Science #563, July 1991
[15] L. Iftode, C. Dubnicki, E. Felten, K. Li. Improving Release-Consistent Shared Virtual Memory using Automatic Update. The Second International Symposium on High-Performance Computer Architecture. HPCA. February 1996
[16] Dolphin Interconnect Solutions Inc., 959 Concord St., Framingham, MA 01701-4682, PCI-SCI Adapter Programming Specification, 1997, Version 0.1
[17] D. Mentre, T. Priol. Noa: A Shared Virtual Memory over a SCI Cluster. The 3-th International Conference on SCI Based Technology and Research. August 29-30 2000. Munich, Germany
[18] F. Dahlgren, J. Torrellas. Cache-Only Memory Architectures. IEEE Computer, June 1999
[19] E. Hagersten, A. Landin, S. Haridi. DDM-A Cache-Only Memory Architecture. IEEE Computer, September 1992
[20] M. Jovanovic, V. Milutinovic. An Overview of Reflective Memory Systems. IEEE Concurrency. April-June 1999
Виктор Корнеев (korv@kiam.ru) — заместитель директора НИИ «Квант» (Москва)
Несколько определений
SMP
Симметричные многопроцессорные архитектуры обычно состоят из небольшого числа процессоров, объединенных с памятью коммуникационной средой (шиной или коммутатором типа crossbar), пропускная способность которой достаточна для поддержания быстрого доступа в память. Время обращения к физически единой общей памяти одинаково для всех процессоров; отсюда происходит еще одно из названий таких систем — UMA (Uniform Memory Architecture). Как правило, в SMP применяется протокол когерентности, основанный на «прослушивании» всеми процессорами коммуникационной среды и проведении согласованных изменений кэш-памяти и оперативной памяти. Модель состоятельности — строгая, последовательная, либо процессорная.
NUMA
Физически распределенная разделяемая память (DSM — distributed shared memory) образуется как совокупность памятей вычислительных модулей, которые могут включать один или несколько процессоров с подсоединенным к ним блоком локальной памяти. В случае использования нескольких процессоров каждый такой модуль имеет архитектуру SMP. Распределение памяти по вычислительным модулям позволяет рационально использовать процессоры и блоки памяти и эффективнее компоновать системы, в том числе, из коммерчески доступных модулей. В последнем случае в таком качестве могут, например, выступать серийные системные платы ПК.
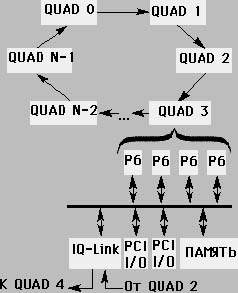 |
| Рис. 1. Архитектура NUMA-Q |
Основная идея архитектуры ccNUMA (cache coherent NUMA) — использование для построения многопроцессорных систем интерфейса между кэш-памятью и основной памятью; термин ccNUMA призван подчеркнуть увязку механизма работы кэш-памяти вычислительного модуля с доступом в удаленные блоки памяти других модулей. Протокол когерентности типа MESI обеспечивает механизм поддержки когерентности кэш-памяти и удаленной основной памяти. Время доступа процессора в собственную локальную память в несколько раз меньше, чем время доступа через коммуникационную сеть в память другого вычислительного модуля. Варианты построения таких систем достаточно разнообразны. Для конкретности можно рассмотреть реализацию NUMA Q2000 компании Sequent, которая построена из стандартных модулей, включающих до 4 процессоров Pentium Pro. Каждый вычислительный модуль помимо процессоров содержит память емкостью до 4 Гбайт, два моста «шина Р6 — шина PCI» и адаптер IQ-link, реализующий протокол когерентности, а также входной и выходной линки (рис. 1.).
Для построения архитектуры ccNUMA в адаптер IQ-link вводится дополнительный удаленный кэш третьего уровня, который содержит копии строк данных, загружаемых из удаленных блоков памяти других вычислительных модулей. Этот кэш, с одной стороны, обслуживает обращения к данным при отсутствии требуемой строки во внутрикристальной кэш-памяти и блоке локальной памяти, размещенном на той же плате. А с другой, при отсутствии в удаленном кэше строки, резидентной в блоке памяти другого вычислительного модуля, она доставляется в кэш в соответствии с протоколом когерентности SCI. Для обозначения архитектуры, предусматривающей наличие подобного удаленного кэша, употребляется также термин NUMA-RC.
Локальная память вычислительных модулей отображается в глобальное адресное пространство. Интерфейс адаптера IQ-link с шиной Р6 отслеживает адреса, появляющиеся в запросах на шине и определяет диапазон адресов, к которому принадлежит появившийся адрес. Каждый участок диапазона заранее приписан блоку памяти одного из ВМ. Тем самым, определяется идентификатор ВМ, в котором размещены данные, адрес которых появился на шине. Этот идентификатор используется для маршрутизации пакета, доставляющего в случае необходимости требуемую кэш-строку.
Для быстрого определения строк, расположенных в кэше третьего уровня, используется специальный каталог. В случае отсутствия в нем тэга строки, соответствующей адресу, появившемуся на шине Р6, шина переводится в состояние «незавершенная транзакция» и формируется пакет с командой доставки требуемой кэш-строки. Адаптер IQ-link реализует физический уровень когерентного подключения к шине. Контроллер линков принимает из вычислительного модуля пакеты для передачи в выходной линк, пропускает пакеты, не предназначенные модулю, и принимает адресованные модулю пакеты из входного линка.
СОМА
В системах с архитектурой СОМА память в вычислительном модуле строится как кэш-память; ее называют еще «притягивающей» памятью (attraction memory — AM) [18]. При запросе фрагмента памяти из другого вычислительного модуля поступивший фрагмент размещается как в кэш-памяти запрашивающего модуля, так и в принадлежащей ему АМ. Размещенный в АМ фрагмент может быть удален из нее, если нет места для вновь поступившего другого фрагмента.
АМ содержит для каждого фрагмента данных тег, включающий его адрес и состояние. При промахе в кэш контроллер памяти вычислительного модуля просматривает теги АМ для определения возможности извлечения требуемого фрагмента из локальной памяти АМ. При отсутствии фрагмента формируется запрос на его доставку. Для поиска фрагмента в системах наподобие KSR-1 и DDM [18, 19] используются специальные аппаратные средства сети межмодульных связей. В KSR-1 сеть строится как древовидная иерархия колец, в которой вычислительные модули служат листовыми элементами. В DDM сеть представляет собой древовидную иерархию шин. Эти системы называют также иерархическими СОМА. Каждый уровень древовидной структуры включает каталог, содержащий сведения о всех фрагментах, размещенных в нижележащих модулях-листьях, поэтому при поиске фрагмента необходимо просматривать каталоги вышележащих уровней древовидной структуры до тех пор, пока не будет обнаружен требуемый фрагмент.
 |
| Рис. 2. Структуры модулей Структуры вычислительных модулей для NUMA, иерархической и плоской COMA-архитектур |
В системах с так называемой плоской СОМА-архитектурой в каждом вычислительном модуле для указания местоположения резидентных в этом модуле фрагментов вводится каталог. В таких системах может применяться обычная высокоскоростная сеть, в отличие от специализированной сети, необходимой для иерархической СОМА-архитектуры. При промахе в АМ по адресу требуемого фрагмента определяется резидентный вычислительный модуль, в каталоге которого содержится информация о местонахождении требуемого фрагмента. В резидентный модуль направляется запрос фрагмента. Запрос вызывает передачу фрагмента или, при его отсутствии в резидентной памяти, перенаправляется согласно каталогу к месту нахождения фрагмента (рис. 2).
Притягивающая память АМ функционирует во многом подобно обычной кэш-памяти, однако для фрагментов АМ нет резидентного блока, в который помещается модифицированный фрагмент при его удалении из АМ. Поэтому фрагмент, удаляемый из АМ одного вычислительного модуля, должен быть помещен в АМ другого модуля. Поскольку возможно одновременное существование нескольких копий одного фрагмента, одна из копий объявляется основной; в отличие от прочих, которые могут быть затерты, если не модифицировались, основная обязательно должна быть перемещена в другую АМ. Перемещение фрагмента в АМ называют впрыскиванием; его можно сделать как в предварительно выбранный по специальному запросу вычислительный модуль, у которого есть место в АМ, так и в произвольно назначаемый модуль. В последнем случае возможно возникновение цепочки впрыскиваний, в том числе циклической, что потребует дополнительных механизмов для разрешения этих ситуаций. Еще одним решением может быть перемещение фрагмента в тот вычислительный модуль, из которого он поступил первоначально. Отношение объема памяти, используемого программой, к общему суммарному объему АМ всех модулей называется давлением [18]. Чем меньше давление, тем больше памяти остается для копий фрагментов данных и тем меньше нагрузка на сеть передачи данных, поскольку при этом уменьшается количество промахов в АМ.
Развитием идей СОМА служат архитектуры S-COMA (Simple COMA) и MS-COMA (Multiplexed Simple COMA) [18]. В системах с архитектурой S-COMA операционная система выделяет для поступающих фрагментов особую область АМ. Ее размер кратен размеру страницы памяти. Блок управления памятью вычислительного модуля отображает только страницы локальной памяти. При первом доступе в вычислительном модуле к разделяемой странице памяти вырабатывается ошибка доступа. Операционная система отображает страницу для размещения запрошенных данных в особой области. Затем аппаратура перемещает требуемый фрагмент (обычно строку кэш-памяти) в выделенную страницу. Оставшаяся часть страницы не используется, пока модуль не запросит соответствующие строки кэш-памяти. Так как физический адрес фрагмента устанавливается в вычислительном модуле, две копии одних и тех же данных в разных модулях имеют разные адреса. Для разделяемых данных используется глобальное адресное пространство, отображение в которое в каждом модуле выполняется специальной таблицей.
В системах с архитектурой S-COMA возможна фрагментация выделенной области памяти, вызванная неполным заполнением страниц. Поэтому может потребоваться излишнее число страниц, что приведет к возрастанию нагрузки на операционную систему. Эта проблема устранена в MS-COMA, где допускается одновременное отображение множества виртуальных страниц в одну физическую.
При работе с фрагментами данных используются две стратегии: копирование и миграция. Первая применяется, если несколько процессоров обращаются к одним и тем же данным в основном по чтению, для чего требуется размещение копий в нескольких АМ. Вторая — если фрагмент данных модифицируется в каждый момент только одним процессором, что требует размещения фрагмента только в одной АМ.
В зависимости от того, преобладает в прикладной программе копирование или миграция, более эффективной оказывается либо архитектура NUMA-RC, либо Flat-COMA. Сравнение делается в предположении о равенстве аппаратных средств: вычислительные модули системы с архитектурой NUMA-RC имеют кэш третьего уровня, емкость которого равна емкости памяти АМ в модулях сопоставляемой системы с архитектурой Flat-COMA.
Системы с рефлексивной памятью
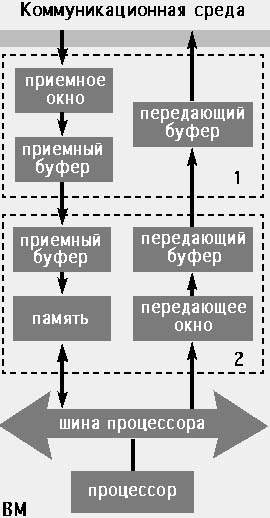 |
| Рис. 4. Архитектура с рефлексивной памятью Каждый вычислительный модуль содержит процессор, блок памяти, шину памяти и адаптер коммуникационной среды. Адаптер состоит из приемо-передающей части коммуникационной среды (1) и приемо-передающей части процессора (2) |
Основное свойство рефлексивной памяти состоит в том, что каждая копия разделяемого кванта данных в локальной памяти любого вычислительного модуля имеет одно и то же значение [20] (рис. 4).
Совокупность страниц локальной памяти модуля делится на две группы: локальные неразделяемые страницы и глобальные разделяемые. Рефлексивная память образуется из всех распределенных по различным блокам физической памяти глобально разделяемых страниц памяти, отображенных в глобальное разделяемое адресное пространство (рис. 5).
Вычислительный модуль, создающий входную страницу, выделяет страницу физической памяти и делает ее доступной для разделения с другими модулями. В разделяемом глобальном адресном пространстве эта страница получает адрес, который используется для доступа к ней из выходной страницы модуля. Указанное отображение адресов глобального адресного пространства в локальные адреса выполняется таблицей преобразования адресов, размещенной в приемном окне адаптера.
Вычислительный модуль, создающий выходную страницу, заполняет элемент таблицы преобразования адресов выходной страницы в адреса глобального адресного пространства, задавая в каждом элементе адрес модуля, в который будет производиться пересылка данных. После создания входных и выходных страниц доступ к виртуальной памяти выполняется командами load и store. При каждой записи в разделяемую переменную автоматически (прозрачно для исполняемой программы) изменяются все копии этой переменной. Чтение данных производится из локальной памяти модулей, и только записи в разделяемые переменные используют коммуникационную среду, объединяющую модули.
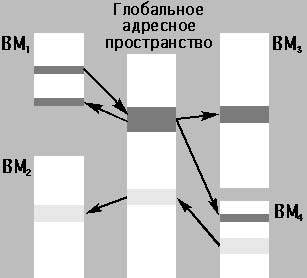 |
| Рис. 5. Схема работы систем с рефлексивной памятью Выделено два множества разделяемых страниц. ВМ1 имеет одну выходную страницу, глобальный адрес которой совпадает с глобальными адресами входных страниц в ВМ3, ВМ4 и в самом ВМ1. ВМ4 содержит одну выходную страницу, глобальный адрес которой равен глобальному адресу входной страницы ВМ2 |
Если модуль выполняет команду записи в переменную, расположенную в неразделяемой памяти, то эта команда изменяет содержимое только локальной памяти процессора. Однако команда записи в переменную, принадлежащую разделяемой выходной странице, помимо изменения переменной этой страницы, активизирует передающее окно адаптера. Передающее окно содержит таблицу трансляции адресов разделяемой выходной страницы в адреса глобального адресного пространства. Затем формируется пакет из измененного слова или измененной кэш-строки и полученного адреса глобального адресного пространства. Этот пакет передается в коммуникационную среду, обеспечивающую его доставку во все вычислительные модули, содержащие входные страницы, которые разделяют изменяемую выходную страницу.
В качестве яркого примера коммерческой системы с рефлексивной памятью можно упомянуть кластеры AlphaServer 8xxx на базе Memory Channel. К экспериментальным относятся системы Merlin, Sesame, Shrimp [20].
Особенностью систем с рефлексивной памятью, по сравнению с NUMA и COMA, является возможность со стороны пользователя управлять степенью разделения данных в системе, так как отображение областей памяти каждого вычислительного модуля в глобальное адресное пространство осуществляется путем заполнения таблиц трансляции адресов. Число строк этих таблиц равно числу разделяемых страниц памяти, каждой из которых однозначно соответствует строка. Содержимое таблиц либо задается статически при загрузке параллельной программы в совокупность модулей, либо устанавливается динамически в ходе исполнения программы. В любом случае средствами ОС должны быть решены вопросы проверки корректности заполнения этих таблиц. Таким образом, вместо фиксированной глобальной адресации всей памяти применяется выборочное отображение отдельных страниц в глобальное адресное пространство.
Недостатки, присущие системам с рефлексивной памятью, следующие:
- сложность модификации многих копий страниц, обусловленная большой нагрузкой на коммуникационную среду при широковещательных передачах пакетов или организацией «бездедлоковых» передач пакетов при последовательном обходе модулей с копиями модифицируемых страниц;
- избыточная нагрузка на коммуникационную среду при многократной модификации одной и той же глобальной переменной, сопровождаемой передачей пакета, в случае, если необходимо только конечное значение этой переменной;
- невозможность использовать в качестве разделяемых страницы, помещаемые во внутрикристальную кэш-память с обратной записью, так как модификация этих страниц внутри микропроцессора не может быть обнаружена на его шине (это позволяет строить рефлексивную память только на уровне некэшируемых страниц, например, адресного пространства шины PCI);
- длительная модификация всех копий страниц по сравнению с доступом в локальную память вычислительного модуля, требующая явного введения барьерной синхронизации при записи в глобальные переменные для поддержания когерентности памяти в рамках модели свободной состоятельности.
В системах с рефлексивной памятью могут использоваться различные модели состоятельности памяти — от строгой и процессорной до различных вариантов свободной состоятельности.
