 Канонические примеры: деревянный самолет «Еловый Гусь» Говарда Хьюза (Spruce Goose, Hughes H-4 Hercules) – самая большая когда-либо построенная летающая лодка с размахом крыльев 98 метров, что даже больше, чем у Ан-225; пятибашенный танк Т-35 и т.п. «Гусь» взлетел только один раз, преодолев два километра, Т-35 единожды попытались использовать во время финской войны, но тоже безуспешно. Причина неудач подобных конструкций – в несоблюдении баланса системных требований. На ошибках таких систем хорошо обучились современные конструкторы, которые больше не создают монстроподобных самолетов и танков, однако создатели гигантских компьютерных кластеров – исключение.
Канонические примеры: деревянный самолет «Еловый Гусь» Говарда Хьюза (Spruce Goose, Hughes H-4 Hercules) – самая большая когда-либо построенная летающая лодка с размахом крыльев 98 метров, что даже больше, чем у Ан-225; пятибашенный танк Т-35 и т.п. «Гусь» взлетел только один раз, преодолев два километра, Т-35 единожды попытались использовать во время финской войны, но тоже безуспешно. Причина неудач подобных конструкций – в несоблюдении баланса системных требований. На ошибках таких систем хорошо обучились современные конструкторы, которые больше не создают монстроподобных самолетов и танков, однако создатели гигантских компьютерных кластеров – исключение.
Понять трудности создателей нынешних суперкомпьютеров можно. Они должны пройти между Сциллой и Харибдой современного компьютерного мира, двумя закономерностями, одна дает возможность развиться, а другая тормозит. С одной стороны, надо что-то делать с количеством транзисторов, которое пока с неизбежностью растет по закону Мура, однако ничего более остроумного, чем сделать ставку на размножение числа ядер, придумать пока не удалось. Скорее всего, микропроцессор Itanium станет последним изделием с мощным ядром и, судя по спросу на него, доживает свои годы. Однако рост числа ядер имеет и обратную сторону – решаемые задачи нужно как-то распараллеливать, распределяя по ядрам, однако суммарное время выполнения программы на параллельной системе, как постулирует закон Амдала, не может быть меньше времени выполнения самого длинного фрагмента.
Теоретически развивать многоядерные суперкомпьютеры можно по одному из четырех направлений (рис. 1). Все многоядерные (Many Core) конструкции можно разделить на два основных класса: фиксированные (Fixed MC, FMC) и реконфигурируемые (Reconfigurable MC, RMC). Устройства типа FMC имеют неизменяемую структуру, а устройства типа RMC в процессе работы могут изменяться, адаптируясь к решаемой задаче. В свою очередь каждое из них может быть реализовано как гомогенное (x64, IBM Power, Sun UltraSPARC для FMC и Tile-64 для RMC), то есть состоящее из одинаковых ядер, или гетерогенное (Cell для FMC и Monarch для RMC), состоящее из ядер разной конструкции.
Итак, что же нас ждет, «гомо» или «гетеро»?
HPC и HPEC
Экспоненциальный рост производительности компьютеров из Top 500 может вызвать восторг у некоторых неподготовленных наблюдателей, однако цифры не должны скрывать очевидное технологическое вырождение огромных, пожирающих мегаватты ИТ-сооружений, на 99% попадающих в категорию гомогенных FMC-архитектур, – позиция того или иного кластера в этом рейтинге зависит лишь от размера капиталовложений, а не от искусства его авторов. Но ведь есть еще и другие пути (рис. 1), а поиск альтернативных решений приводит к существовавшим в стороне от столбовых путей встроенным компьютерам, которые и стали сегодня источником новых идей.
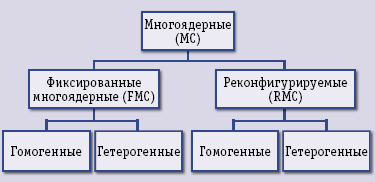
Рис.1.
Например документ, опубликованный корпорацией MITRE еще в 2002 году, содержит описание неизбежной «смены парадигмы» в области высокопроизводительных вычислительных систем (High Performance Computing, HPC), ставшей сегодня реальностью. Суть в том, что на протяжении последнего десятилетия XX века при создании наиболее критичных с точки зрения национальной безопасности высокопроизводительных встроенных систем (High Performance Embedded Computing, HPEC) руководствовались принципами, на которых строятся обычные универсальные высокопроизводительные машины, однако сегодня ситуация должна измениться. Раньше HPC диктовали то, как строить HPEC, теперь наоборот – принципы, заимствованные из HPEC, будут распространяться на HPC.
Нынешние HPC-кластеры признаны неперспективными, поскольку развивались экстенсивно, без каких-либо открытий, а при проектировании встроенных систем удалось получить новые знания. В числе основных каналов, по которым эти новые знания будут распространяться, называются DARPA Adaptive Computing, DARPA Data Intensive Systems, DARPA Polymorphic Computing Architectures и DARPA High Productivity Computing Systems. Чтобы помочь понять, насколько серьезно это утверждение, стоит напомнить, что MITRE является правительственной организацией (7 тыс. сотрудников), призванной управлять федеральными центрами исследований и разработок (Federally Funded Research and Development Center, FFRDC), в основном ее деятельность финансируется Пентагоном, Агентством национальной безопасности США, Федеральным управлением гражданской авиации США и рядом других силовых ведомств.
HPCS в интерпретации Cray
Финалистами в многолетнем конкурсе DARPA HPCS стали IBM и Cray, а другим участникам, в частности Sun Microsystems и SGI, достались роли второго плана. Детали проекта, реализуемого на финальной стадии, широкой огласке не подлежат, однако недавно появилось сообщение о частичном сокращении финансирования компании Cray со стороны Пентагона.
По программе DARPA HPCS инженеры Cray с 2003 года ведут проект Cascade создания гибридного суперкомпьютера с массовым параллелизмом на процессорах разных типов: x64, FPGA, векторные процессоры Cray, мультипотоковые процессоры Tera и ускорители ClearSpeed (рис. 2). Помимо них в проекте задействованы процессоры Power Cell и специализированные графические процессоры (GPU). Процессор Tera был разработан в компании Tera Computer, первой в 1997 году создавшей архитектуру, масштабируемую до 256 процессоров (Multithreaded Architecture, MTA). Впоследствии компания выкупила у SGI подразделение Cray и взяла себе это имя, дав вторую жизнь известному бренду. Компания ClearSpeed выпускает многоядерные 64-разрядные процессорные массивы обработки вещественных чисел (Multi-Threaded Array Processor, MTAP), предназначенные для встроенных систем, – на одном кристалле размещается 96 таких ускорителей.

Программное обеспечение Cascade включает традиционные программные модели MPI, OpenMP, POSIX Threads, а также языки, работающие с моделью PGAS (Parallel Global Address Space – «параллельное глобальное адресное пространство»), среди них Co-Array Fortran (CAF) и Unified Parallel C (UPC). В рамках проекта Cascade разработан новый язык программирования Chapel (Cascade High Productivity Language). Совокупность перечисленных средств обеспечивает высокую скорость выполнения последовательных вычислений (Single Instruction Single Data, SISD), работу в векторном режиме (Single Instruction Multiply Data, SIMD) и в режиме массового параллелизма (Multiple Instruction Multiple Data, MIMD).
Подобная гибкость оказалась возможной благодаря тому, что фундаментальной основой Cascade является «адаптивность» (adaptive supercomputing), смысл которой выражен в девизе Cray – адаптировать систему к приложениям, а не приложения к системе. Именно отсутствие способности к адаптации не позволило динозаврам как системе выжить на стыке мелового и третичного периодов, когда изменились приложения (внешние условия). В полном объеме такая адаптивность будет реализована в компьютере Granite MVP, где появится возможность программировать на классических языках Cи и Фортран, использовать унаследованные коды, написанные для других машин, автоматически векторизовать коды и делать их многопоточными, использовать большие объемы памяти и в конечном итоге концентрироваться не на программировании, а на задачах.
По плану в 2009 году должна была быть выпущена машина с модулями Baker, затем с интервалом в год следуют Granite и Marble. Производительность этих компьютеров на тесте Linpack будет находиться в диапазоне от 2 PFLOPS до 10 PFLOPS, что сегодня звучит уже не слишком сенсационно, но суть в другом – на тесте RandomAccess они будут показывать эффектность более 50 000 GUPS, в то время как у самых совершенных современных кластеров это значение не превышает 1 GUPS (GUPS – единица измерения производительности по тесту RandomAccess).
Разные подходы к кастомизации
На примере проекта Cascade можно убедиться в том, что технологии HPEC позволили вывести HPC на качественно новый уровень, однако почему традиционные подходы уже не работают? Создателям встроенных систем приходилось действовать в условиях серьезных ограничений, и они не могли позволить себе строить установки-динозавры, потребляющие мегаватты и занимающие тысячи квадратных метров. Эти условия диктовали необходимость в большей изобретательности при решении проблем того, что называют «кастомизацией» – адаптацией компьютера к задаче. В проекте Cascade нашел отражение почти весь спектр возможных кастомизационных решений (рис. 3).

Различные подходы к кастомизации обнаруживаются буквально с первых шагов в истории компьютеров, например, машины ENIAC и EDVAC отличаются в том числе и тем, что во второй была реализована схема, получившая название «хранимая в памяти программа», которая оказалась гораздо удобнее коммутации программы с помощью проводов-перемычек. Такой переход везде рассматривается как достижение, и при этом упускается, что уже тогда сложились два типа кастомизации: аппаратная и программная. При программной кастомизации аппаратное обеспечение включает в себя все физические части компьютера, но не включает данные и программы. Такое деление соблюдается во всех универсальных компьютерах, хотя в природе нет таких строгих делений, не может их быть и в компьютинге вообще.
С момента создания первых программируемых компьютеров и до конца семидесятых годов, за исключением простейших промышленных контроллеров, кастомизация оставалась исключительно программной, поскольку альтернативы машинам, построенным по фон-неймановской схеме с программой, хранимой в памяти, не было. Монополия была нарушена в 1980 году, когда компания Ferranti выпустила первую специализированную интегральную схему (Application-Specific Integrated Circuit, ASIC), которая содержала «зашитый» интерпретатор BASIC и послужила основой для предшественников современных ПК. Этот тип чипа назвали ULA (Uncommitted Logic Array), а чтобы получить готовый компьютер Sinclair, к нему добавили еще два чипа памяти RAM и ROM, а также процессор Z80A. С тех пор началось встречное движение от машины к антимашине, хотя теоретические работы появились гораздо раньше, их обзор можно найти в статье «Архитектура фон Неймана, реконфигурируемые компьютерные системы и антимашина».
Следующим практическим шагом после ASIC стали программируемые логические матрицы (Field-Programmable Gate Array, FPGA), в настоящее время они серийно выпускаются несколькими крупными компаниями. Самым крупным поставщиком FPGA является Xilinх, но разработаны и произведены первые программируемые массивы были в английской – а точнее, шотландской – компании Algotronix в 1989 году, она просуществовала самостоятельно всего до 1993 года, когда была приобретена компанией Xilinх. Основанием для появления на свет FPGA стали работы, выполненные ранее в Эдинбургском университете. А если быть совсем точным, то идею реконфигурируемого аппаратного обеспечения первым предложил Джеральд Эстрин, еще в 1960 году высказавший соображение о том, что компьютер может состоять из стандартного процессора, который управляет массивом, способным изменять свою конфигурацию.
Сегодня спектр кастомизации распространяется от микросхем ASIC до традиционных микропроцессоров, а в промежутке между этими полюсами находятся несколько возможных решений. Если идти от ASIC слева направо (рис. 3), то видно, как сокращаются затраты на кастомизацию, а если справа налево, то как возрастают затраты на «нерепродуцируемый инжиниринг» (nonrecurring engineering) и время вывода продукта на рынок. Крайне правую позицию занимают стандартные встроенные микропроцессоры, они, как настоящая фон-неймановская машина, имеют фиксированный набор команд (Instruction Set Architecture, ISA), их кастомизация является чисто программной и дешевле всех остальных, а высокий объем производства обеспечивает низкий уровень затрат на нерепродуцируемый инжиниринг и вывод продукта на рынок. В этом главное достоинство таких решений, однако они имеют низкие показатели SWEPT (Size, Weight, Energy, Performance, Time).
Комплексную оценку предложил Роберт Грэйбил, бывший руководитель программных разработок DARPA: «Системы будущего должны быть, с одной стороны, компактными, а с другой – обладать способностью адаптации к изменениям в их миссии и к появлению новых технологий... Архитектуры должны быть способны к поддержке широкого спектра функциональности и трансформации (morphing) по запросу». Отсюда еще один термин – полиморфные, или многообразные, компьютерные системы. Первый полиморфный процессор MONARCH (Morphable Networked MicroArchitecture) разработала компания Raytheon в 2007 году. Он собран из модулей FPGA, способных работать в трех режимах: MIMD, SIMD и Stream (потоковый). Из них можно собирать кластер, необходимый для решения конкретной задачи, а данные передаются по кольцевой магистрали со скоростью 43 Мбит/с. В режиме MIMD работают независимые RISC-процессоры, в режиме SIMD получается AltiVec-подобный процессор (AltiVec – система команд, разработанная совместно альянсом AIM, образованным компаниями Apple, IBM и Motorola).
Первым шагом от классических процессоров к полиморфным могут считаться процессоры с изменяемой системой команд. Такую схему реализовала компания Stretch в процессоре S6000, имеющем конструкцию для расширения системы команд Instruction Set Extension Fabric (ISEF) и включающем 4096 арифметико-логических микроустройств, каждое из которых способно выполнять операции над несколькими битами, и, комбинируя их, можно расширять возможности центрально процессора. Допустим, что есть часто повторяемая последовательность операторов на С/С++, в таком случае она компилируется не в последовательность стандартных команд, а в одну специальную. Реконфигурация занимает менее 30 микросекунд, то есть она может выполняться в реальном времени. Можно сказать, что исполняемый код управляет архитектурой процессора; последний может быть RISC, CISC и еще чем угодно, в зависимости от необходимости. Сейчас S6000 используются при работе с видео, в системах машинного зрения, системах видеонаблюдения и в станциях мобильной связи.
Продолжая движение справа налево (рис. 3), мы подойдем к крупнозернистым реконфигурируемым архитектурам (Coarse-Grained Reconfigurable Architecture, CGRA). Устройства, построенные по принципу CGRA, состоят из большого набора функциональных устройств (Function Unit, FU), объединенных в виде решетки. Весь набор регистров (Register File) распределен по множеству FU, входящих в CGRA, из них могут образовываться временные конфигурации, обеспечивающие наиболее быстрое выполнение тех или иных операций. В отличие от FPGA реконфигурация CGRA осуществляется на короткий промежуток времени, а в отличие от ISEF модули FU выполняют не только команды, но и одновременно осуществляют коммутационные функции, обеспечивая маршрутизацию в процессе выполнения команд.
Такой подход очень эффективен с точки зрения использования аппаратных ресурсов и экономии энергии. Пока процессоры на принципах CGRA предполагаются для мобильных устройств, но в перспективе вполне могут быть распространены и на обычные компьютеры. Архитектура CGRA предъявляет большие требования к компилятору, который должен совмещать управление вычислениями с управлением потоками операндов. На первых порах FPGA были исключительно статичными, и их рассматривали как альтернативу ASIC, но после появления решений, обеспечивающих динамическую реконфигурацию (Run-time Reconfiguration, RR), FPGA «сместились» вправо (рис. 3). Теоретически возможны два подхода к реконфигурации: частичная реконфигурация (Partial Reconfiguration, PR) и программно-программируемая реконфигурация (Software Programmable Reconfiguration, SPR). Основное достоинство первой в повышении гибкости и полноты использования, но расплатой является большая сложность проектирования.
Суть PR состоит в распределении во времени ресурсов FPGA: какая-то часть всего массива в нужный момент настраивается на решение одной задачи, а потом реконфигурируется под другую, таким образом общий потребляемый ресурс уменьшается, и, соответственно, меньше оказывается потребляемая мощность, цена и т.д. Методология PR впервые была реализована компанией Xilinx в семействе продуктов Virtex, для которых весь массив разделен на регионы, а перепрограммирование региона осуществляется путем пересылки в него определенной последовательности битов (partial bitstream), при этом изменение в состоянии одного раздела не влияет на работу остальных. Работа PR поддерживается инструментом упреждающего планирования PlanAhead.
Методология SPR отличается тем, что рассматривает весь массив «как систему на кристалле» (System on a Chip, SoC), включающую программируемый процессор (soft-core microprocessor), по определению обладающий таким качеством, как масштабируемость. В SPR нет отдельной процедуры реконфигурирования; в массив загружаются вместе и приложение, и запрограммированный процессор, на котором оно работает.
FPGA и университетские суперкластеры
Из всех доступных технологий реконфигурации наибольшей готовностью сегодня обладают массивы FPGA – их использование открывает возможность для создания экспериментальных гетерогенных кластеров на уровне университетских лабораторий. Это напоминает время, когда строились первые кластеры Beowulf, но на качественно новом техническом уровне. Известны проекты гибридных кластеров, разрабатываемые в американских и британских университетах: Spirit (Университет штата Северная Каролина), Maxwell (Эдинбургский университет, Шотландия), RAMP Blue (Университет штата Иллинойс) и Novo-G (Университет штата Флорида). В отличие от отечественных обладателей суперкомпьютеров-рекордсменов, в этих вузах не кичатся производительностью поставленных за государственный счет и собранных сторонними организациями вычислительных монстров, а собирают свои собственные конструкции. Все они представляют собой стандартные кластеры, поддерживаемые MPI, но при этом дополненные ресурсами FPGA, которые ускоряют работу приложений.
В качестве основы для Maxwell взят известный IBM BladeCentre Cluster, дополненный ускорителями FPGA. Каждое из 32 лезвий на базе Intel Xeon дополняется двумя массивам Xilinx Virtex-4 FPGA. Между собой они связаны через PCI-X Expansion Module. Вся конструкция собрана в двух стойках, а узлы связаны с использованием 48-портового коммутатора Netgear посредством каналов 40 Gigabit Ethernet. Массивы FPGA размещены на платах Nallatech и Alpha Data. Обе построены на устройствах Xilinx Virtex-4, но разной модификации, первая на XC4VFX100, а вторая на XC4VLX160. Такой выбор объясняется тем, что они взаимно дополняют друг друга – LX имеет больше логических ячеек (152064), чем FX (94896), но зато у нее на борту встроенные ядра PowerPC и приемопередатчик RocketIO для обмена между чипами.
Выбор двух типов FPGA продиктован желанием провести сравнительный эксперимент – в архитектуре Maxwell имеется две независимые сети, одна объединяет традиционные лезвия, вторая – массивы FPGA. Топологию объединения массивов можно назвать двухмерным тором, каждый из них связан с соседями; от более сложной, но более эффективной схемы, основанной на коммутации, на первых порах отказались. Сеть используется как управляющая, параллельные коммуникации обеспечивает RocketIO. Так же сеть Ethernet используется в случаях, когда для эксперимента кластер работает без ускорителей, под управлением MPI. В университете был разработан пакет PTK (Parallel Toolkit) для программирования FPGA. Для эксперимента было выбрано три типа задач: финансовое моделирование, обработка трехмерного изображения и геофизика. Ускорение, которое обеспечили FPGA на первой задаче, составило два порядка, на двух остальных от пяти до восьми раз. Показательно, что трудозатраты на программирование оказались обратно пропорционально скорости – на первую задачу ушло несколько человеко-недель, на остальные – от шести до двенадцати человеко-месяцев.
Компьютер Novo-G был специально построен для поиска областей схожести в протеиновых последовательностях – это одна из важнейших проблем вычислительной биологии. Задача решается с использованием методов динамического программирования, но обычно большой объем вычислений входит в противоречие с требуемой точностью, поэтому приходится применять упрощающие эвристики. Novo-G представляет собой кластер из 24 Linux-серверов с ускорителями ProcStar-III компании GiDEL и FPGA Stratix-III E260 компании Altera. В базовом варианте на один узел кластера приходится 512 вычислительных элементов (Processing Element, PE), каждый PE за один такт выполняет все необходимые действия для получения промежуточного результата. По оценкам, производительность на данной задаче одного узла Novo-G превышает производительность традиционного кластера с числом ядер 2500. Если бы задача решалась на обычном 24-узловом кластере, она потребовала бы девять дней, а с укорителями на нее уходит 12 секунд. Потребление энергии сокращается на один-два порядка.
Реинкарнация сопроцессоров
Первый промышленный гетерогенный компьютер HC-1 (Heterohegeous Computer) выпустила компания-стартап Сonvey Computer, имеющая корни в таких компаниях, как DEC, Data General и Convex. Этот компьютер объединяет в себе низкую стоимость и простоту программной модели обычных систем, представленных на массовом рынке, с высокой производительностью специализированного аппаратного обеспечения. Создатели Convey Стив Валлах, Брюс Тол и Боб Палак пришли к выводу о необходимости создания компьютера, сочетающего в себе универсальный процессор IA-64 и сопроцессор на базе FPGA.
Должно было получиться что-то вроде процессора 8086 с сопроцессором для вычислений с плавающей запятой 8087. Суть идеи состоит в том, что программа пишется на языке последовательного программирования, а выбор того, где выполнять команды, определяется компилятором, то есть программист освобождается от нагрузки, связанной с распараллеливанием кодов. Все 25 выпущенных осенью 2009 года HC-1 были разобраны десятью покупателями, некоторые остались неназванными, а те, кого назвали, внушают уважение: Центр вычислительных исследований Земли и окружающей среды Стэнфордского университета, Национальная лаборатория им. Лоуренса Университета Беркли, Национальная лаборатория в Окридже.
Из двух сокетов на стандартной плате со стандартным чипсетом ввода/вывода один занимает процессор Intel, а второй – сопроцессор, выполненный по технологии FPGA и способный динамически загружаться подсистемой команд, соответствующей типу текущей нагрузки. Процессоры объединяет общая память с когерентным кэшем. Скомпилированное приложение содержит команды из стандартного набора команд IA64 и специальные команды, адресованные сопроцессору, то есть их можно рассматривать как расширение. Ключевая идея состоит в том, что команды сопроцессора группируются в «наборы» (personalities) или классы, содержащие базовые (канонические) команды, характерные именно для него, и команды, общие для всех классов. В число базовых входят общие математические операции и команды управления.
Сопроцессор состоит из трех основных наборов компонентов: коммутатор прикладных движков (Application Engine Hub, AEH), контроллеры памяти (Memory Controller, MC) и прикладные движки (Application Engine, AE) (рис. 4). AEH включает интерфейс с хост-процессором и чипсетом ввода/вывода и обеспечивает выбор, декодирование, выполнение базовых команд и когерентность данных с хостом. Специфические для данного класса команды выполняются движками AE, которые являются центральной частью всей архитектуры Convey. К AEH подключаются по четыре AE, причем важно, что каждая из специфических для класса команд передается всем четырем AE, а то, как они выполняются, зависит от класса, поэтому, хотя тактовая частота FPGA заметно ниже, чем у обычных микропроцессоров, специализация и внутренний параллелизм дают возможность заметно повысить производительность. Набор классов, представленных в виде предварительно скомпилированных файлов FPGA, может храниться в НС-1, любой из них может динамически загружаться в процессе работы. При поставке HC-1 комплектуется готовым набором из трех десятков классов, а для разработки классов пользователем имеется инструментарий PDK (Personality Development Kit).

* * *
Динозавры вымерли на стыке мелового и третичного периодов, на смену им пришли млекопитающие, способные к адаптации, – нечто подобное сейчас происходит и в области HPC. Высокопроизводительные системы будущего, как и современные встроенные (бортовые) системы, должны быть компактны и, главное, обладать способностью к адаптации как к появлению новых аппаратных технологий, так и к изменению программных приложений.
Современные подходы к повышению производительности
Дальнейшее наращивание объема кэш-памяти и числа запускаемых на выполнение команд не дает прироста производительности процессоров, пропорционального затрачиваемым ресурсам и энергии. Сегодня требуются совершенно иные архитектурные подходы.
Оценка быстродействия нерегулярного доступа к памяти
Расширение пропасти между производительностью процессоров и скоростью доступа к памяти, появление приложений, интенсивно работающих с памятью, стимулировали создание вычислительных систем с новой архитектурой, однако для оценки таких систем традиционные тесты уже не подходят. Пришло время тестов анти-Linpack, например GUPS.
