
Hewlett-Packard занимает сегодня особое положение на компьютерном рынке. Вобрав в себя не столь уж давно корпорацию Compaq, которая перед этим в свою очередь поглотила другую знаменитую фирму — DEC, в HP обеспечивают своим заказчикам многолетнюю преемственность, сохраняя тем самым их капиталовложения. Кроме вычислительных систем на базе собственных микропроцессоров архитектуры PA-RISC, HP выпускает компьютеры на базе RISC-процессоров Alpha, а знаменитые отказоустойчивые системы NonStop (преемники компьютеров компании Tandem) используют процессоры MIPS R14K/R16K.

Поддерживая совместимость аппаратных средств в течение многих лет, в HP стремятся заранее заботиться и об определенной унификации аппаратуры в будущем, чтобы снизить собственные расходы.
В планах компании — замена всех RISC-систем на компьютеры на базе Itanium 2 (компьютеры на платформе х86 будут при этом продолжать выпускаться). Серверы HP на базе Itanium 2 относятся к семейству Integrity; отсюда ясен и повышенный интерес к этим компьютерам.
В самом семействе Integrity представлены самые разные серверы — от серверов-лезвий Integrity Blade BL60p и небольших одно-двухпроцессорных серверов rx1620 и rx2620 до мощных многопроцесорных серверов Superdome. Остановимся подробнее на средних и старших моделях Integrity, которые основываются на новом наборе микросхем sx2000, сменившем sx1000.
Битва двух титанов
Новая архитектурная идея Itanium — пост-RISC архитектура EPIC, разработанная Intel и НР, и включающая элементы VLIW (very large instruction word — «cверхбольшое командное слово»), не смогла сломить всех RISC-конкурентов и доказать свое существенное преимущество для обеспечения высокой производительности. Так, на тестах SPECcpu2000 сегодня лидирует IBM Power5+. Собственно говоря, именно Intel Itanium 2 и IBM Power5+ и конкурируют сегодня на рынке высокопроизводительных Unix-серверов (если, конечно, не рассматривать х86-64). Sun Microsystems с процессорами UltraSPARC T1 пока ушла в сторону многоядерности и многопоточности с небольшой производительностью процессорных ядер [1].
Если смотреть на сегодняшнее состояние, то оба «титана» современного рынка микропроцессоров — Itanium 2 и Power5+ — отличаются большой площадью кристалла (около 230 кв. мм у Power5+/90 нм, у Itanium 2/Madison 9М, производимых по 130 нм технологии — соответственно гораздо больше, около 480 кв. мм), большой емкостью кэша третьего уровня (9 Мбайт у Madison, 36 Мбайт у Power5), во многом способствующей высоким показателям производительности на тестах SPECcpu2000, и соответственно большим числом транзисторов (порядка 300 млн. у Power5+, не считая внешний кэш третьего уровня; у будущего Itanium 2 Montecito с интегрированным кэшем третьего уровня ожидается уже фантастическое количество — 1720 млн. транзисторов) [2]. Ясно, что такие высокие показатели стоят денег, поэтому х86-совместимые конкуренты от Intel и AMD гораздо дешевле.
Power5+ изготавливается по более совершенной технологии, имеет более высокую тактовую частоту (2,2 ГГц против 1,6 ГГц у Madison) и в ряде случаев более высокую производительность (Табл. 1), является двухъядерным и имеет аппаратную поддержку работы с нитями (SMT), а также встроенный контроллер оперативной памяти. Поэтому главным конкурентом Power5+ станет, видимо, двухъядерный Itanium 2/Montecito, который вот-вот должен официально появиться на рынке, и который, как и Power5+, производится по технологии 90 нм.
Не менее определяющими в успехе процессора представляются не производительность, а ценовые характеристики. Преимуществом Itanium 2 здесь является, очевидно, большая массовость этой платформы: кроме HP, серверы на базе Itanium 2 производят такие гранды, как NEC, Unisys, Fujitsu Siemens и др. Хотя Power также является теперь «открытой» архитектурой (см. www.power.org), такого большого количества независимых производителей на платформе Power не имеется. А массовость производства, как известно, вызывает снижение цен.
Процессоры Montecito являются большим, чем просто интеграцией двух Itanium 2 в одной микросхеме. Подобно Power5, в них ожидается аппаратная поддержка двух нитей в «грубозернистом» варианте (CMT). «Грубозернистость» здесь означает, что переключение на другую нить происходит не на каждом такте, а, например, при возникновении события, дающего большую задержку, типа промаха в кэше третьего уровня. Переключение нитей, как ожидается, затребует порядка 15 тактов, что близко к полному перезаполнению конвейера; однако это время гораздо ниже задержки при промахе в кэше третьего уровня.
Применение SMT (например, в Power5, Intel NetBurst HyperThreading) считается более эффективным путем повышения пропускной способности процессора (в смысле числа завершаемых за заданный интервал времени нитей), чем CMT. Однако для статического планирования выполнения команд в соответствии с программным кодом в Montecito — в противовес внеочередному выполнению команд в суперскалярных RISC-процессоров — CMT вполне подходит. На такой важной рабочей нагрузке, как оперативная обработка транзакций, отличающейся плохой локализацией в кэше благодаря интенсивной работе с оперативной памятью с разделением данных между нитями и случайным обращениям к памяти, рост производительности за счет СMT может достигать порядка 20%. А реализация CMT в смысле сложности логики и площади на кристалле стоит очень дешево. В то же время для пропускной способности на тестах SPECrate2k ожидаемое увеличение за счет СMT может составить всего 2-5% [2].
Изменения в процессорных ядрах Montecito относительно Itanium 2-9M включают также новые функциональные устройства (в том числе для операции сдвига), новые команды IA-64, cредства виртуализации процессора и улучшение характеристик классической триады RAS (Reliability, Availability, Serviceability — «надежность, доступность, качество обслуживания»).
Интересно устроена иерархия кэш-памяти Montecito (это характерно и для Montvale, следующей за Montecito версии Itanium 2). В отличие от Power5, общего для ядер кэша здесь нет, каждое ядро имеет собственную трехуровневую иерархию кэша. По сравнению с Itanium 29M, имеющего общий для команд и данных кэш второго уровня, в Montecito кэш второго уровня расщеплен между командами и данными. D-кэш второго уровня имеет емкость 256 Кбайт, а появившийся I-кэш второго уровня имеет большую емкость, 1 Мбайт. Каждое ядро имеет I-кэш и D-кэш первого уровня, а общий для команд и данных кэш третьего уровня увеличился в емкости — до 12 Мбайт в каждом ядре.
В Montvale дополнительно планируется, в частности, поддержка нового размера страниц в буфере быстрой переадресации TLB, более быстрый интерфейс системной шины и улучшенная технология HyperThreading. Следующее поколение МП Itanium 2, Tukwilla, будет иметь не менее четырех ядер, уменьшенные задержки памяти и другие усовершенствования [4]. В их числе можно отметить, например, «ключи защиты», в том числе для безопасного разделения данных между операционной системой и приложениями (не исключено, что это связано с работой в Intel российской группы Бориса Бабаяна, в прошлом известного своей приверженностью к введению тегов, способствующих компьютерной безопасности). Вообще, думается, в Montecito основной упор делается на развитие средств обеспечения безопасности и повышение надежности и управляемости.
Но об одной из важнейших компонентов, определяющих производительность работы Montecito, нельзя не сказать особо. Это интерфейс системной шины, пропускная способность которой может ограничивать пропускную способность оперативной памяти. В Itanium 2/Madison два процессора обычно разделяют общую шину шириной 128 бит, работающую на частоте 400 МГц, что дает пропускную способность в 6,4 Гбайт/с. При использовании Montecito в корпусе, совместимом с Madison 9M (что обеспечивает совместимость Montecito c сегодняшними аппаратными платформами для Itanium 2), эта пропускная способность остается без изменений.
Это, конечно, весьма серьезное ограничение. Более совершенная версия Montecito имеет другой корпус и системную шину шириной уже 256 бит, работающую на частоте 667 МГц; соответствующая пропускная способность равна при этом 21,3 Гбайт/с [2].
Набор микросхем sx2000
C Itanium 2 Intel первоначально предлагала набор микросхем i870 [5], HP — zx1 [6]. Позднее у НР появился более современный набор микросхем sx1000, на смену которому ныне приходит sx2000.
Набор микросхем sx2000 обеспечивает работу с целым рядом процессоров — как PA-8900 архитектуры PA-RISC, так и Itanium 2 (Madison 9M, Montecito, Montvale). Применяется sx2000 в серверах Integrity среднего и старшего классов; такие серверы HP называет «ячеистыми», поскольку основные их «строительные блоки» называются ячейками. Возможности применения вместе с sx2000 различных процессоров наиболее ярко выражены в серверах старшего класса Superdome: в них в различных аппаратных разделах могут одновременно работать, например, PA-8900 и Madison 9M. Это дает высокую гибкость конфигураций и способствует защите инвестиций.
Общая структура набора микросхем sx2000, используемого в серверах Integrity rx7640, rx8640 и Superdome, дана на рис. 1. В HP применительно к своим высокопроизводительным компьютерам используют термин Central Electronics Chipset (СЕС); мы же для краткости будем называть его просто набором микросхем. CEC sx2000 служит для соединения процессоров, оперативной памяти и плат ввода/вывода между собой, что, собственно, и образует компьютер как единое целое.
В составе sx2000 имеется пять типов сверхбольших микросхем: контроллер ячейки (Сell Controller, CC), буфер памяти, координатный коммутатор (crossbar switch), адаптер шин PCI-X и мост PCI-X. На рис. 1 представлена ячейка (cell), реализованная в виде платы. Каждая ячейка содержит один контроллер ячейки и восемь буферов памяти. Кроме них, на плате ячейки размещаются собственно модули DIMM и несколько процессоров. Контроллер ячейки связывает локальные процессоры и оперативную память между собой, а также обеспечивает интерфейсы к подсистеме ввода/вывода и координатным коммутаторам.
Ячейка служит основой для аппаратных разделов (nPars), каждый из которых аппаратно изолирован, содержит одну или несколько ячеек со средствами ввода/вывода и работает с собственной оперативной памятью.
Координатные коммутаторы размещаются в традиционном месте — на задней панели серверов Integrity. Эти коммутаторы являются базой трех независимых «коммутаторных фабрик». Контроллер ячейки подсоединен ко всем трем. Поэтому при сбое одного из коммутаторов в соответствующих разделах произойдет перезагрузка, после которой работа будет продолжена с единственным ослаблением — уменьшением пропускной способности коммутаторного межсоединения ячеек. При нормальной работе потоки данных равномерно распределяются между всеми тремя коммутирующими фабриками, повышая тем самым общую производительность.
Если сопоставить sx2000 и sx1000, то оба набора микросхем обеспечивают подсоединение четырех процессорных разъемов на ячейку. К контроллеру ячейки в обоих наборах микросхем подсоединяется по две процессорные шины, на каждой из которых находится по два разъема (рис. 1). Однако в sx2000 пропускная способность процессорной шины выше в 1,33 раза (скорость передачи данных до 8,5 Гбайт/с), пропускная способность памяти — в 2,1 раза, пропускная способность коммутаторов — в 4,2 раза, пропускная способность ввода/вывода — в 4,4 раза.
Пути, соединяющие контроллер ячейки с процессором, оперативной памяти, ввода/вывода и межсоединением, защищены средствами коррекции ошибок. Характеристики пропускной способности различных каналов и шин в ячейке представлены в таблице 2.
Контроллер ячейки содержит интегрированный контроллер памяти, который вместе с четырьмя парами буферов оперативной памяти и собственно модулями DIMM образует четыре независимых квадранта памяти. Благодаря буферам оперативной памяти поддерживаются потоки данных между модулями DIMM и контроллером ячейки на скорости 533 млн. передач в секунду, чему отвечает частота 267 МГц. В буферах кэшируются строки кэш-памяти при их передаче в и из процессора. Доступ к смежным (последовательным) строкам памяти может осуществляться с перекрытием (расслоением) между квадрантами одной ячейки или между всеми квадрантами всех ячеек раздела. В одной ячейке поддерживаемая пропускная способность памяти равна 16 Гбайт/с.
Максимальная емкость оперативной памяти в sx2000 по сравнению с sx1000 возросла в четыре раза, а задержка уменьшилась на 23%. Контроллер оперативной памяти в контроллере ячейки поддерживает до 32 модулей DIMM SDRAM DDR2/267. При емкости 4 Гбайт на DIMM (с 1-гигабитными микросхемами) это дает максимум в 128 Гбайт на ячейку; в будущем после появления DIMM емкостью 8 Гбайт этот максимум составит уже 256 Гбайт.
Контроллер оперативной памяти обеспечивает также поддержку когерентности кэша в серверах, в том числе, содержащих несколько ячеек, используя механизм, основанный на каталогах (directory based), что характерно для ccNUMA-систем. Буферы оперативной памяти применяются также для ускорения изменения состояния когерентности в памяти. Для ускорения коммуникаций между аппаратными разделами sx2000 поддерживает так называемую глобальную разделяемую память с возможностью применения коммутаторного межсоединения для таких коммуникаций.
Для измерения задержек обычно используется, как известно, тест lmbench, а для пропускной способности оперативной памяти — тесты STREAM. В таблице 3 приведены соответствующие результаты для Integrity Superdome c процессорами Montecito по сравнению с сервером IBM p5/595 на базе Power5+/1,9 ГГц. Из этих данных видно, что пропускная способность памяти в Montecito чуть-чуть меньше, чем в сервере IBM, задержки оперативной памяти — заметно лучше, а задержки при обращении в кэш третьего уровня в Montecito гораздо ниже, чем у Power5+. Последнее обусловлено тем, что у IBM общий для ядер кэш третьего уровня является внешним.
Вообще, как известно, сложнее добиваться снижения задержек оперативной памяти, чем увеличения ее пропускной способности. Поэтому применение DDR2, а не суперсовременной технологии FB DIMM не является существенным недостатком sx2000. Что же касается задержек в системе, то к сказанному выше следует добавить поддержку в sx2000 прямой передачи данных между процессорами, без промежуточного задействования оперативной памяти. В результате данные из процессора, который только что создал или обновил эти данные, могут быть доставлены в любой другой запросивший процессор системы не более чем за три «коммутаторных прыжка» (hop).
Улучшения системных задержек при обращении в память и при передаче из кэша в кэш при переходе от sx1000 к sx2000 составляет от 12 до 44% (табл. 4). Низкие задержки, в частности, по обращению в память, особенно важны при обработке транзакций.
Вне ячеек
Вне плат ячеек расположены две базовые компоненты sx2000 — это подсистема ввода/вывода и системные коммутаторы.
Подсистема ввода/вывода формируется в sx2000 двумя типами микросхем — системным адаптером шин PCI-X и мостом PCI-X (рис. 1). Каждый контроллер ячейки имеет высокоскоростной канал к системному адаптеру PCI-X, и уже последний связан с 8-12 (в зависимости от модели сервера Integrity) микросхемами мостов PCI-X, каждая из которых дает собственную шину PCI-X и добавляет один ее слот в конфигурацию. Пропускная способность одного слота лежит в диапазоне от 0,5 Гбайт/с до 2 Гбайт/с, пиковая пропускная способность подсистемы ввода/вывода одной ячейки составляет 11,5 Гбайт/с (поддерживаемая величина — 8,2 Гбайт/с). Для увеличения производительности ввода/вывода в системном адаптере шин PCI-X имеются буферы для кэширования входящих и выходящих данных.
В sx2000 поддерживается стандарт PCI-X 2.0 с максимальной тактовой частотой 266 МГц, а не 133 МГц, как у большинства плат ввода/вывода на рынке. Кроме того, для плат с частотой 133 МГц или 266 МГц, поддерживающих корректирующие коды ЕСС, последние коды будут реально задействованы (поддержка ЕСС в PCI-X не так уж часта).
Среди адаптеров ввода/вывода, поддерживаемых sx2000 — 10-Gigabit Ethernet, 4 Gbit Fibre Channel, 4x Infiniband, SCSI и др.
Недостатком подсистемы ввода/вывода в sx2000 является отсутствие поддержки PCI-Express (PCI-E). Современные платы высокоскоростных сетевых межсоединений, например, Infiniband 4x DDR, уже используют этот стандарт. Однако поддержка PCI-E в sx2000 запланирована уже на 2006 год.
Микросхемы системного коммутатора имеют порты с пропускной способностью 11,5 Гбайт/с (поддерживаемая величина — 9,1 Гбайт/с), а на ячейку, соединенную с тремя коммутаторами, соответственно приходится пиковая пропускная способность 34,6 Гбайт/с (поддерживается 27,3 Гбайт/с). Каналы коммутаторов имеют ряд свойств, повышающих надежность, в том числе возможности повторения передачи при сбое данных и автоматического отключения сбойного канала.
В sx2000 имеется еще широкий спектр особенностей, направленных на повышение надежности и доступности. Кроме вышеупомянутых возможностей системных коммутаторов и соответствующих каналов, следует обратить внимание на подсистему оперативной памяти. Здесь можно отметить, например, защиту адресов памяти по четности. Интересной представляется появившаяся в sx2000 технология double chip-sparing, используемая при коррекции ошибок в оперативной памяти. Если соответствующая логика установила сбойную микросхему DRAM при ЕСС-коррекции, то прошивка удаляет соответствующие биты из расчетов ЕСС, и поэтому корректирующая логика может скорректировать второй сбой DRAM в том же кодовом слове ECC. Эта схема может применяться к одной микросхеме DRAM, или всем DRAM, разделяющим бит на одной шине, или на всех шинах подсистемы памяти.
Для обеспечения надежности (и решения задачи балансировки нагрузки) в серверах на базе sx2000 применяются возможности их парционирования (разбиения на разделы). Кроме аппаратных электрически изолированных разделов nPars можно применять виртуальные разделы vPars (при этом гранулярность снижается с уровня ячейки до ядра процессора) и средства виртуальных машин Integrity VM. В последнем случае возможно «тонкозернистое» распределение, с точностью до долей процессора. При использовании vPars и Integrity VМ задействуются средства операционной системы HP-UX 11i.
Конфигурации и производительность
В различных серверах компоненты sx2000 задействуются по-разному (рис. 2).
Integrity rx7640 имеют две связанные напрямую ячейки; координатные коммутаторы не используются. В rx8640 четыре ячейки соединены двумя коммутаторами. В старших моделях, Superdome, имеется восемь ячеек и шесть коммутаторов, расположенных в двух стойках.
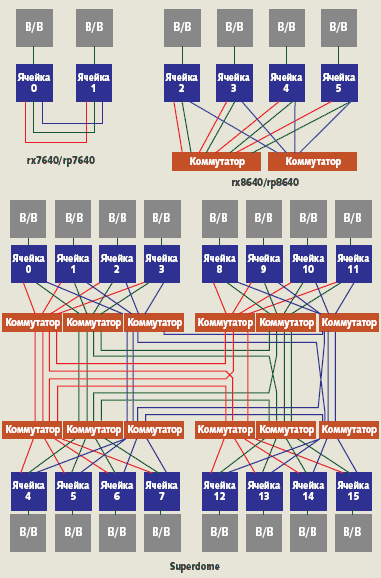
|
| Рис. 2. Топология серверов Integrity |
Естественно, сильно различаются и конфигурации различных моделей серверов. Серверы rx7640 имеют до восьми процессорных разъемов и размещаются в стойке высотой 10U; серверы rx8640 имеют до 16 процессорных разъемов и размещаются соответственно в стойке высотой 17U. Ячейки rx7640 и rx8640 поддерживают по 16 нестекированных модулей DIMM, а ячейки Superdome — 32 модуля DIMM. Максимальная емкость оперативной памяти ячейки в настоящее время равна 64 Гбайт для rx7640/8640 и 128 Гбайт — для ячейки Superdome.
В серверах Integrity среднего класса к ячейке подсоединяется до восьми мостов PCI-X и соответственно имеется восемь слотов на восьми шинах (всего — 16 слотов на сервер), а в HP Superdome на ячейку приходится по 12 мостов, слотов и шин (всего — 96 слотов на сервер, расширяется до 192 слотов).
И наконец, про производительность серверов. Безусловно, интерес представляют прежде всего новые данные для серверов с процессорами Montecito. На тестах TPC-C, где важна, в частности, задержка при обращении в оперативную память, двухпроцессорные четырехъядерные серверы Integrity rx4640 с Itanium 2/1,6 ГГц достигли показателя 200829 tpmC со стоимостью 2,75 долл. на tpmC. Результаты двухпроцессорного четырехъядерного сервера IBM p5570 чуть выше, 203439 единиц, но и транзакции у IBM стоят существенно больше — 3,93 долл. А вот восьмиядерный четырехпроцессорный сервер HP rx4640-8 с процессорами Itanium 29050/1,6 ГГц (очевидно, Мontecito) достиг уже показателя 290644 единиц при стоимости 2,71 долл. на tpmC (данные по тестам TPC-C взяты с официального сайта www.tpc.org). Это является хорошей иллюстрацией возможностей новых серверов HP Integrity на базе Itanium 2.
Литература
- Михаил Кузьминский, Асимметричный ответ «Ниагары». «Открытые системы», № 3, 2006.
- P. DeMone, Sizing up the Super Heavyweights. www.realworldtech.com/page.cfm?ArticleID=RWT100404214638, 2004.
- C. McNairy, A Technical Review of Montecito. Intel Development Forum, 2004.
- C. McNairy, Itanium Processor Family Technology Leadership. Intel Development Forum, Spring 2006.
- Ф.Бриггс, М.Цеклев, К.Крета и др., Intel 870: строительные блоки для недорогих масштабируемых серверов. «Открытые системы», № 12, 2002.
- Михаил Кузьминский, Система на базе Itanium 2. «Открытые системы», № 3, 2003.
