

Ресурсная модель (utility computing), важнейшей составляющей которой является управление сервисами, предоставляемыми прикладными системами, упорядочивает и делает более эффективными взаимоотношения бизнеса и ИТ. Однако неочевидной остается решение проблемы регламентации процедур прогнозирования, диагностики и мониторинга производительности прикладных систем, возникающей при реализации управляемого и предсказуемого процесса устранения отклонений от требований соглашения об уровне обслуживания.
Идея ресурсной модели подразумевает, что управлять ИТ-сервисами можно на основе прозрачных методик, аналогичных используемым телефонными, коммунальными и иными сервисами. При этом отношения с клиентами (т.е. с «бизнесом») также являются прозрачными и коммерчески определенными: конкретному объему и уровню качества обслуживания соответствует конкретный уровень оплаты. Уровень качества обслуживания регламентируется соответствующим соглашением (Service Level Agreement, SLA). Очевидно, что параметры, задающие производительность и доступность прикладных систем, всегда будут входить в число важнейших характеристик, определяемых в SLA.
Мониторинг и тюнинг
Требования SLA по своей сути не являются какими-то произвольными пожеланиями, а должны отражать обоснованные требования бизнеса, уровень которых сбалансирован со стоимостными характеристиками предоставляемых сервисов. Положительным следствием этого является то, что необходимые мероприятия и оснащение, обеспечивающие поддержание требуемого уровня обслуживания, получают твердое коммерческое обоснование. Но тем самым повышается ответственность разработчиков соответствующих методик. Как показывает практика, даже при эксплуатации тщательно спроектированных и оттестированных прикладных систем редко удается избегать неожиданных проблем. Два тесно связанных понятия — мониторинг и тюнинг объединяют методики и инструментарий, позволяющие минимизировать негативные последствия отклонений за счет своевременного реагирования и максимально быстрого приведения эксплуатационных параметров к требуемому уровню.
Под тюнингом, как правило, имеется в виду улучшение эксплуатационных характеристик системы за счет изменения настроечных параметров среды исполнения и за счет усовершенствований, вносимых в архитектуру и программный код. Первый вид тюнинга, «параметрический», состоит в конфигурировании, или изменении настроечных параметров среды исполнения. Он охватывает элементы архитектуры, относящиеся к различным уровням (сервер, СУБД, приложения, Web-серверы и прочие системные компоненты, а также компоненты клиентского уровня), и включает управление взаимодействием уровней, базовыми системными средствами, такими, как операционные системы, СУБД и т.д.
Второй вид тюнинга, «редизайн» системы, представляет собой определенное перепроектирование системы и включает весь спектр возможных изменений ее дизайна. Мероприятия по редизайну могут быть локальными: оптимизация запросов, создание более эффективных наборов индексов и планов запросов в базах данных, внесение изменений в код объектов или структур данных. Средний масштаб редизайна характеризуется перепроектированием, затрагивающим взаимодействие компонентов, включающим, например, устранение разнообразных конфликтов. Крупномасштабные изменения могут охватывать изменения логики и архитектуры системы в целом.
Отдельный вид тюнинга — масштабирование системы (замена аппаратной платформы на более мощную или расширение ее отдельных компонентов, усовершенствование сетевых решений, изменение базовых системных средств и т.д.).
В целом тюнинг может относиться к любым действиям, необходимым для доведения эксплуатационных параметров прикладной системы до заданного уровня. В частности, к тюнингу могут быть отнесены мероприятия, которые должны в принципе проводиться на этапе проектирования и построения, но по тем или иным причинам не были выполнены. Здесь и таится главная опасность. Если процессы тюнинга при эксплуатации не имеют надежных «точек опоры» и методических ориентиров, то они могут каждый раз выливаться в обширные комплексы работ, представляющие собой исследования и редизайн системы почти «с самого начала», что требует серьезных ресурсов и временных затрат, далеко выходящих за предусмотренные лимиты. Однако создание таких методических ориентиров должно осуществляться не в момент, когда проблема уже возникла, а стать организационной основой всего жизненного цикла прикладной системы.
Ориентир №1. Наличие результатов многосторонних функциональных и нагрузочных тестов, предшествующих вводу системы в эксплуатацию. Можно выделить несколько уровней «качества» подобной информации, связанных с качеством организации таких тестов.
Первый уровень характеризуется наличием определенной обобщенной информации о проведенных тестах и их результатах, не позволяющей, однако, сделать сравнительный анализ поведения системы, если аналогичные тесты будут повторены с измененными исходными данными. Уровень соответствует подходу к тестированию, при котором, независимо от собственно объема и полноты тестов, сами тесты и их результаты не документированы с максимальной степенью детализации.
Второй уровень характеризуется наличием полной документации по тестированию системы, включая архитектуру тестовых инсталляций, конфигурацию инструментальных средств, скрипты, генерирующие нагрузку, а также прочие параметры, определяющие условия тестирования. Сюда же входят детальные результаты тестовых прогонов, интегрированные средства анализа, позволяющие в любой момент вернуться к накопленным ранее данным и рассмотреть их под новым углом. Возможно детальное сравнение поведения системы в тестовых прогонах с работой в эксплуатационных режимах при наличии соответствующих результатов мониторинга.
Третий уровень отличается не только наличием полной документации, но и обладает полнотой и техническими средствами, позволяющими при необходимости воспроизвести проводившиеся ранее тесты. Возможно выполнение прогонов с новыми исходными параметрами, воспроизводящими характер реальной рабочей нагрузки системы на момент возникновения проблем и позволяющими с применением аналитических инструментов найти разницу в поведении системы, а, следовательно, установить причины возникших отклонений. Один из путей реализации подобного подхода описан в [1].
Ценность всей информации о проведенных ранее тестах практически теряется, если при изменении версий прикладной системы тесты не повторялись в полном объеме — уже нет возможности проводить какой-либо сравнительный анализ. Наличие подробной информации о результатах тестирования позволяет сузить и сфокусировать исследования поведения системы, осуществляемые с целью диагностики. Возможность повторного проведения тестов позволяет выполнить верификацию изменений, которые были осуществлены в процессе тюнинга, и создать надежную точку опоры для тех случаев, когда возникнет необходимость дальнейшей оптимизации системы.
Ориентир № 2. Наличие информации о поведении системы. Подобная информация накапливается в результате постоянного мониторинга в некоторой базе данных («репозиторий»): текущие значения функциональных характеристик и производившихся действиях (выполнявшиеся задачи, реконфигурации и пр.). Информация из репозитория позволяет выполнять статистический анализ с целью локализации возникающих отклонений (уровни архитектуры, компоненты, конкретные функции) и «обратное прослеживание» работы системы для нахождения начального момента отклонений, что существенно упрощает диагностику.
Оба ориентира помогают резко сузить область поиска причин возникающих отклонений, однако важным является также своевременное извещение обслуживающего персонала о возникающих отклонениях или тенденциях к их появлению. Для этой цели могут использоваться два вида механизмов.
Нотификация — мониторинг контроля соответствия эксплуатационных параметров допустимым интервалам, лежащим между заданными пороговыми значениями. При этом положение центральной точки интервала допустимых значений может задаваться «базовой» функцией или быть константой. При выходе контролируемых параметров за пределы допустимых значений система извещает персонал о возникших отклонениях. Если задать интервалы допустимых значений эксплуатационных параметров, предусмотренных SLA, то можно получить возможность генерации предварительных извещений, создающих основу для «проактивных», предупредительных мероприятий по устранению причин потенциальных нарушений.
Прогнозирование — мониторинг эксплуатационных параметров и потребляемых системой ресурсов (память, дисковое пространство, процессорное время и т.п.) с накоплением в репозитории данных на продолжительных временных интервалах. Важным инструментом системы прогнозирования является наличие средств статистического анализа, позволяющих отслеживать возникающие тренды, формировать прогнозы, находить корреляционные зависимости и выявлять скрытые закономерности в поведении системы. Целью подобного анализа является эффективное прогнозирование изменения характеристик системы, а выявленные тенденции позволяют своевременно принимать необходимые меры, например, заменить средства хранения данных или платформу.
Практические аспекты
Рассмотрим некоторые практические аспекты построения «методических ориентиров» для поддержания эксплуатационных параметров системы на требуемом уровне.
Вообще говоря, трудно представить себе реальную прикладную систему, при эксплуатации которой были бы предприняты все перечисленные меры для контроля функционирования и управления производительностью. Скажем, внедрение всего комплекса мероприятий и инструментов может быть слишком дорогим, поэтому приходится расставлять приоритеты и выбирать первоочередные подходы и методы из числа тех, применение которых вообще осуществимо. Рассмотрим некоторые распространенные типы прикладных систем.
Крупномасштабные ERP-системы, характеризующиеся многоуровневой архитектурой, очень большим масштабом и широким разнообразием функций. Достаточно типичная ситуация для крупных предприятий в данном случае состоит в том, что полное нагрузочное и функциональное тестирование крайне затруднено. Особенно нелегко выполнить условия второго и третьего уровней, учитывая, что поставщики подобных систем далеко не всегда предусматривают такую возможность. Облегчает ситуацию то, что с одной стороны, подобные системы являются тиражируемыми и тщательно оттестированы производителями, а с другой — нагрузка, как правило, меняется достаточно плавно и предсказуемо. Организация многоуровневого мониторинга со всеми упоминавшимися функциями (репозиторий для обратного прослеживания, средства статистического анализа эксплуатационных параметров, система нотификации) может во многом обезопасить ситуацию для этого случая. Эти средства существенно упрощают диагностику и практически могут компенсировать отсутствие мощной тестовой базы, а также позволяют своевременно реагировать на потенциальные опасности.
Internet-системы типа B2C и некоторые виды систем B2B, для которых характерен непредсказуемый, «взрывной» характер изменения нагрузки. В этом случае крайне уместно полнофункциональное тестирование, включая нагрузочное, проводимое с использованием самого совершенного инструментария («третий уровень»), причем как на этапе ввода в эксплуатацию, так и при внесении любых последующих изменений в систему, поскольку позволяет контролировать «запас» устойчивости к предельным нагрузкам. Этот же инструментарий может существенно облегчить поиск причин возникающих проблем. Мониторинг с накоплением репозитория, оперативными нотификациями и контролем трендов использования ресурсов также будут крайне полезны.
Среднего размера двухзвенные клиент-серверные системы или трехзвенные системы с основной функциональной нагрузкой, ложащейся на СУБД. В этом случае фокусирование всех упомянутых средств мониторинга в первую очередь на контроле базы данных позволяет получить максимальный эффект при минимальных затратах. Здесь можно упомянуть соответствующие инструментальные средства от производителей СУБД, например Oracle Diagnostic и Tuning Packs или программные продукты компании Quest.
***
Современные подходы к управлению производительностью прикладных систем позволяют обеспечить требуемый уровень защиты от случайностей и непредвиденных проблем на этапе эксплуатации, однако соответствующие мероприятия и инструментальные средства должны быть заранее запланированы и действовать на протяжении всего периода эксплуатации прикладной системы, а соответствующие затраты предусмотрены в ИТ-бюджете. Это является одним из важнейших аспектов внедрения ресурсного подхода в части управления сервисами.
Литература
- Даун Пол. Тестирование в условиях реального мира. «Открытые системы», № 2, 2004.
Владимир Дудченко (vdudchen@softbcom.ru) — генеральный директор компании SoftBCom (Москва).
Пример комплексного решения управления производительностью многоуровневых прикладных систем
Мониторинг осуществляется с помощью агентов, установленных на всех уровнях архитектуры целевой системы и передающих данные о текущих значениях контролируемых параметров в центральное хранилище.
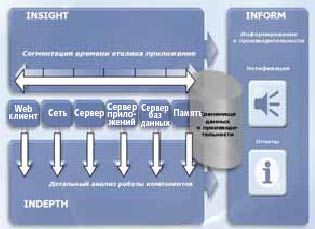
Модуль Insight позволяет сегментировать время реакции системы между уровнями архитектуры и тем самым сузить область возникновения проблем. Модуль Inform содержит средства нотификации и систему формирования отчетов, предназначенных для статистического анализа параметров прикладной системы, в том числе анализа трендов. Модуль Indepth служит для проведения детального анализа работы компонентов, осуществляемого на основе заложенных в систему знаний о принципах их работы. Он позволяет выявлять источники проблем, автоматически предлагать варианты коррекции ситуаций и моделировать вносимые изменения для оценки их эффективности.
Все модули используют информацию, накопленную в центральном хранилище, наличие которого позволяет осуществлять статистический анализ на всех этапах проведения диагностики, а также выполнять «обратное прослеживание» работы системы.
Система Veritas i3 имеет сложную архитектуру, охватывающую все аспекты диагностики многокомпонентных решений. Существуют версии, специально адаптированные для мониторинга таких сложных прикладных систем, как SAP R/3, Oracle e-Business Suite, Siebel, Amdocs и др.
Пример комплексного решения по мониторингу и управлению производительностью множества баз данных, реализованных в кросс-платформной среде
Информация собирается с помощью системных средств, предусмотренных производителями СУБД, через прямые SQL-запросы и хранимые процедуры. Активные агенты не используются. Оперативный мониторинг осуществляется на основе текущей информации, буферизуемой сервером Embarcadero Performance Center и отображаемой клиентским модулем (возможно использование «тонкого» клиента). В репозитории накапливается информация для отображения в отчетах, используемых при анализе поведения системы на предшествующих краткосрочных и среднесрочных интервалах времени.
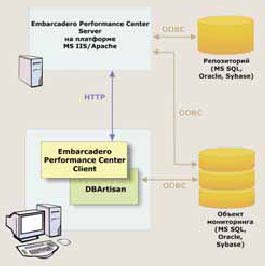
Архитектура решения Embarcadero Performance Center
Особенностью системы является ориентированность на мониторинг кросс-платформной среды СУБД и возможность интеграции с широким спектром специализированных средств, предназначенных для администрирования и реинжиниринга баз данных (инструментарий для администрирования DBArtisan, CASE-средства, инструменты управления изменениями и пр.), а также инструментов для специальных видов анализа поведения баз данных.
