Известно немало подходов к организации хранения сложных структур данных — массивов, списков, деревьев, сетей, графов и их комбинаций. Часто для этого требуется создавать собственное программное обеспечение, управляющее записью, чтением и поиском данных в файлах, либо использовать уже готовые средства. Альтернативный подход состоит в применении технологий СУБД, однако при этом возникает проблема отображения сложных структур данных в модель базы данных.

Программисты часто сталкиваются с проблемой организации хранения данных в долговременной памяти. Можно написать свои средства, управляющие записью, чтением и поиском данных в файлах, а можно воспользоваться для этого реляционными СУБД. Часто предметная область легко представляется в известных структурах, таких как графы, деревья, списки и массивы. Но реляционная модель рассматривает данные в виде отношений, отразить в которых сложные структуры, особенно начинающим проектировщикам, кажется почти невозможным.
Рассмотрим порядок отражения в реляционную базу данных таких структур, как массивы, списки, стеки, очереди, бинарные и M-арные деревья, а также графы [1]. Дополнительно разберем специфическую структуру — древовидную иерархию из элементов двух типов (файловая система из каталогов и файлов). Для работы с отраженными в реляционную базу данных структурами мы разработали хранимые процедуры на языке Transact-SQL, используя MS SQL Server. Этот базовый набор операций можно расширять для использования в конкретных проектах. Идея подобного отображения структур данных эксплуатируется чуть ли не с момента появления реляционных СУБД. Задача описания предметной области средствами реляционной модели встает перед многими проектировщиками, и каждый решает ее по-своему, тратя на это время и силы. Но насколько было бы легче и быстрее проектировать базу данных, опираясь на набор готовых решений! Описания альтернативных подходов к отображению структур данных можно найти в [2-4]. Возможность отображения в реляционную модель сколь угодно сложных объектов обосновывается в [5].
Списки
На принципах отображения списков в реляционную базу данных строятся отображения всех остальных структур.
Односвязный список
Односвязный список — динамическая структура данных, каждый элемент которой имеет ссылку на следующий (рис. 1a). У последнего элемента ссылка на следующий элемент равна нулю.
Для хранения односвязного списка достаточно одной таблицы из четырех полей.
- Номер элемента автоматически присваивается каждому элементу списка самой СУБД. В одной записи таблицы хранится один элемент списка. Номер элемента используется в дальнейшем для ссылки на него из других элементов. В C++ номеру элемента соответствует указатель в памяти на элемент списка. В MS Access этому полю соответствует тип Счетчик, а в MS SQL Server — тип int (IDENTITY) с начальным значением 1 и приращением 1.
- Тип (int) показывает, является ли данный элемент началом списка или нет. Поле принимает следующие значения: первый элемент списка — 1, последний элемент списка — 2, средний — 0; если же в списке всего один элемент, то значение данного поля равно 3.
- Указатель на следующий элемент (int) — числовое поле, в котором хранится ссылка на следующий элемент списка. В это поле записывается номер элемента, следующего за текущим. Если элемент единственный в списке или последний, то в этом поле пишется 0.
- Информационное поле. Одно или несколько полей представляют содержимое списка, то, ради чего он, собственно, и существует. Типы этих полей соответствуют информации, которую в них собираются хранить.
Подобная структура таблицы подразумевает, что в ней хранится один односвязный список, а в одной записи таблицы храниться один элемент списка. Если необходимо хранить в одной таблице несколько списков с одинаковыми информационными полями, то в схему необходимо добавить поле номер списка (int) — числовое поле, в котором для каждого элемента хранится номер списка, которому он принадлежит. Это поле может быть и строковым, чтобы хранить имена списков, но это не экономично.
При хранении в одной таблице нескольких списков удобно для поля номер элементаиспользовать тип данных Счетчик или int (IDENTITY). Это позволяет не задумываться о нумерации элементов списка, поскольку вновь добавляемому элементу любого списка будет присваиваться номер, отличный от всех существующих в таблице.
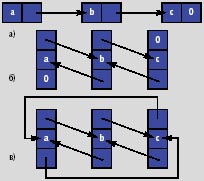
|
| Рис. 1. a) односвязный список, б) двусвязный список, в) циклический двусвязный список |
Рассмотрим отдельно поле тип. Помимо указанных значений в нем можно хранить индекс (номер) элемента в списке, но тогда придется при вставке и удалении элемента в начале и середине списка перестраивать индексы у всех следующих элементов списка. При такой схеме отношения легко определить последний элемент в списке: у соответствующей ему записи в поле указатель на следующий элемент хранится 0, а у всех остальных — какие-либо номера элементов списка. Если в таблице хранится всего один список и нужно, чтобы в списке не хранились элементы с одинаковыми информационными полями, можно задать уникальный индекс на эти поля; тогда СУБД сама будет следить, чтобы их значения были уникальны.
В таблице 1 отражены изменения, происходящие с реляционной таблицей списков при выполнении над списком последовательности операций. Новые элементы списка, вставляются ли они в начало списка, в конец или в середину, всегда добавляются в конец реляционной таблицы. Но использование полей номер элемента и указатель на следующий элемент позволяет не терять информацию о последовательности элементов в списке. При удалении из списка поле указатель на следующий элемент у элемента, предыдущего удаляемому, заменяется на значение из указателя на следующий элемент удаляемого элемента, что опять же позволяет сохранять семантику списка.
Хранимая процедура добавления элемента в конец списка на языке Transact-SQL может выглядеть так:
CREATE PROCEDURE ListAppendElem @NumList int, @Info nvarchar(50) AS DECLARE @i2 int, @i3 int SELECT @i2 = IDelem FROM tblList WHERE IDlist = @NumList AND Type = 2 SELECT @i3 = IDelem FROM tblList WHERE IDlist = @NumList AND Type = 3 - Вставка элементов списка, начиная с третьего IF @i2 IS NOT NULL BEGIN INSERT INTO tblList (IDlist, Type, IDnext, Info) VALUES (@NumList, 2, 0, @Info) UPDATE tblList SET Type = 0, IDnext = @@IDENTITY WHERE IDelem = @i2 END ELSE BEGIN - Вставка второго элемента списка IF @i3 IS NOT NULL BEGIN INSERT INTO tblList (IDlist, Type, IDnext, Info) VALUES (@NumList, 2, 0, @Info) UPDATE tblList SET Type = 1, IDnext = @@IDENTITY WHERE IDelem = @i3 END - Вставка первого элемента списка ELSE INSERT INTO tblList (IDlist, Type, IDnext, Info) VALUES (@NumList, 3, 0, @Info) END
При удалении элемента списка возникает вопрос: удалять по индексу или по значению информационного поля? Если по значению, то в случае наличия в списке нескольких элементов с одинаковым значением информационного поля, удалятся либо они все, либо первый найденный.
Двусвязный список
Двусвязный список (рис. 1б) отличается от односвязного наличием поля указатель на предыдущий элемент. Если элемент единственный или первый в списке, то в этом поле заносится 0.
Двусвязный список можно сделать циклическим (рис. 1в), указав в поле указатель на следующий элемент последнего элемента списка номер первого элемента, а в поле указатель на предыдущий элемент первого элемента — номер последнего элемента. (Отметим, что и односвязный список также можно сделать циклическим.)
Стеки и очереди
Стеки (рис. 2a) и очереди (рис. 2б) можно представить как односвязный список. Единственное отличие стеков и очередей от односвязного списка — набор операций для работы с ними (добавление и выборка элементов очереди и стека).
Операция добавления нового элемента в стек реализуется на основе операции добавления нового элемента в начало списка. Операция добавления нового элемента в очередь реализуется на основе операции добавления нового элемента в конец списка. Операции удаления верхнего элемента из стека и первого элемента в очереди реализуются на основе операции удаления первого элемента списка.
Массивы
Основное достоинство массива — прямой доступ к элементам; основное отличие от списка — сложность вставки и удаления элементов. Для представления массива достаточно одной таблицы со специальными полями.
- Индекс элемента массива. Его присвоение полностью лежит на хранимой процедуре добавления нового элемента массива.
- Информационное поле. Одно или несколько полей представляют содержимое элемента массива.
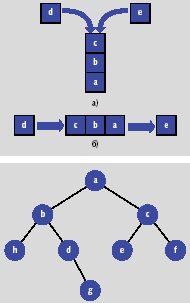
|
| Рис. 2.a) стек, б) очередь Рис. 3. Бинарное дерево |
В одной таблице можно хранить несколько массивов с одинаковой структурой элементов. Для этого в схему таблицы необходимо добавить числовое поле номер массива, в котором для каждого элемента хранится номер массива, которому он принадлежит.
Вместе с номером массива это поле должно образовывать уникальный индекс, чтобы СУБД не позволяла добавлять в один массив несколько элементов с одним индексом.
В реляционной базе данных легко выполнить сортировку массива или поиск элемента (множества элементов) массива по значению любого из информационных полей (группы полей) с помощью простейшего оператора SELECT.
Бинарные деревья
В бинарных деревьях каждый узел хранит указатели на левого и правого потомков. Структура таблицы для хранения бинарного дерева (рис. 3) такая же, как у двусвязного списка, только назначение ссылок иное: указатель на предыдущий элемент превращается в указатель на левого потомка, указатель на следующий элемент превращается в указатель на правого потомка.
Первый вариант допустимых значений для поля тип представляется следующим образом: 1 — корневой элемент, 0 — ветка, 2 — листовой элемент. Подобная организация дерева с рис. 6 представлена в таблице 2.
Второй вариант таков: в корневом элементе хранится количество элементов в дереве, в остальных 0. В корневом элементе также можно хранить число уровней дерева.
Можно организовать бинарное дерево иначе: вместо двух указателей на потомков хранить один указатель на предка. У корневой вершины указатель на предка будет равен 0. Подобная структура подходит для хранения деревьев с любым количеством потомков, а не только для бинарных деревьев. Можно объединить два способа и хранить в одной таблице указатели на левого и правого потомков и указатель на предка.
M-арные деревья
Если точно известно максимальное количество потомков для каждого элемента дерева, то в таблице можно сделать M полей, указывающих на потомков данной вершины. Но это не экономично в случае редкого дерева. Также можно хранить указатель на предка, как описывалось выше для бинарных деревьев.
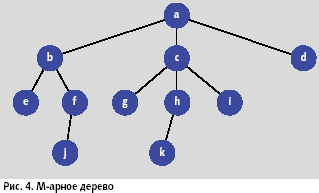
Существует более сложный способ представления M-арного дерева, требующий для хранения дерева две таблицы: вершин и связей. Таблица вершин состоит из четырех полей.
- Номер дерева. Числовое поле, в котором для каждой вершины хранится номер дерева, к которому она принадлежит.
- Номер вершины. Автоматически присваивается каждой вновь добавляемой записи таблицы самой СУБД. В MS Access этому полю соответствует тип Счетчик, а в MS SQL Server — тип IDENTITY с начальным значением 1 и приращением 1.
- Числовое поле тип может принимать следующие значения: 1 — корневой элемент, 0 — ветка, 2 — листовой элемент.
- Информационное поле. Одно или несколько полей представляют содержимое каждой отдельной вершины. Типы этих полей соответствуют информации, которую в них собираются хранить.
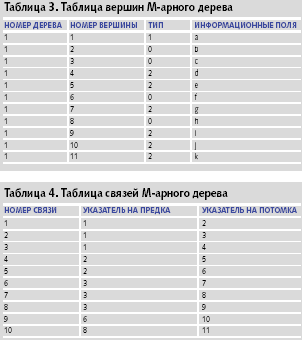
Таблица связей состоит из трех полей: номер предка; номер потомка; номер связи, уникальный номер, присваиваемый каждой вновь добавляемой связи самой СУБД, который необходим для связей с другими таблицами. Присутствие последнего поля сокращает размер SQL-запроса: вместо «t1.НомерПредка = t2.НомерПредка AND t1.НомерПотомка = t2.НомерПотомка» нужно будет написать «t1.НомерСвязи = t2.НомерСвязи».
В таблице связей есть ограничение: в поле номер потомка не бывает повторяющихся номеров. Рассмотрим дерево, изображенное на рис. 4, табличный вид которого представлен в таблице 3 (таблица вершин) и таблице 4 (таблица связей).
Графы
Если число вершин в графе известно, то можно хранить граф в одной таблице по аналогии с матрицей смежности. Но это не экономично: намного удобнее хранить граф в двух таблицах, используя тот же самый подход, что и при хранении M-арных деревьев. Только указатель на левого потомка и указатель на правого потомка нужно заменить на указатель на начальную вершину и указатель на конечную вершину.
Графы могут быть ориентированными, неориентированными и с петлями. Чтобы запретить петли, нужно при добавлении и обновлении вершин графа следить за тем, чтобы указатель на начальную вершину отличался от указателя на конечную вершину. Чтобы не добавлять одинаковые связи несколько раз, нужно создать уникальный индекс по полям указатель на начальную вершину и указатель на конечную вершину. Тогда добавление и обновление связи, которая уже существует, будет пресекаться самой СУБД.
Иерархия из элементов двух типов
С подобной структурой мы встречаемся каждый день, работая с файловой системой, состоящей из каталогов и файлов. Для представления этой структуры в реляционной базе данных можно воспользоваться структурой дерева с указателями на предка. Создается две таблицы вершин для элементов разного типа. В первой таблице вершин (каталоги) поле указатель на предка может принимать значения номеров элементов только из этой же таблицы, поскольку каталог может входить только в другой каталог и не может входить в файл. Во второй таблице вершин (файлы) поле указатель на предка может принимать значения номеров элементов только из первой таблицы, так как файл может входить в каталог и не может входить в другие файлы.
Подобная архитектура обладает рядом недостатков. Основным из них является дублирование номеров элементов в двух таблицах, кроме того, во второй таблице в поле указатель на предка указываются номера элементов из первой таблицы.
Рассмотрим вариант, когда все вершины можно поместить в одну таблицу. Эта таблица будет состоять из полей номер иерархии, номер элемента, тип элемента (1 — элемент первого типа, 0 — элемент второго типа), тип вершины(1 — корень иерархии, 0 — средний элемент, 2 — лист), информационное поле, указатель на предка. Так как в данном случае нет необходимости обходить дерево слева направо и сверху вниз, то достаточно указателей на предка. Однако если эти обходы понадобятся, или пользователь хранит у себя в приложении данные в виде дерева с указателями на потомков, то это потребуется удалить столбец указатель на предка и добавить таблицу связей. Таблица связей такая же, как и для M-арных деревьев. При такой организации иерархии легко ответить на вопросы, реализовав соответствующие запросы на языке SQL.
- Какие каталоги и файлы входят в такой-то каталог?
SELECT * FROM ТаблицаСвязей WHERE УказательНаПредка = НомерКаталога
- В каком каталоге находится заданный файл?
SELECT * FROM ТаблицаСвязей WHERE УказательНаПотомка = НомерФайла
Для минимизации поиска элементов по связям нужно создать индексы по полям указатель на предка и указатель на потомка. В этом случае поиск фактически будет происходить с прямым доступом к элементу.
Информационные поля двух типов элементов могут очень сильно отличаться; в таком случае одной таблицей вершин не обойтись. Удалим информационные поля из таблицы вершин и добавим две таблицы, по одной для каждого типа элементов иерархии. В первой будут поля номер элемента из таблицы вершин (Foreign Key) и информационное поле первого типа элементов; во второй таблице — номер элемента и информационное полевторого типа.
|
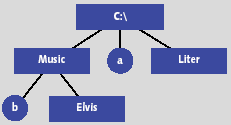
| Рис. 5.Файловая система |
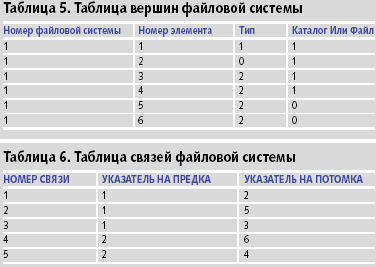
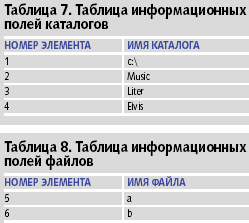
Рассмотрим пример файловой системы (рис. 5), отображаемой в таблицы реляционной базы данных: таблица вершин, таблица связей, таблица информационных полей каталогов и таблица информационных полей файлов (таблицы 5-8). На рис. 5 каталоги изображены прямоугольниками, а файлы кружками.
Заключение
Мы рассмотрели несколько структур данных и их отображение в реляционную базу данных. Полезно во все таблицы связей добавить поле с соответствующим названием: номер списка, номер дерева, номер графа или номер структуры. Это поле позволит сразу определять, к какой конкретно структуре относится данная связь, что может существенно сократить длину SQL-запросов, но создаст дополнительную нагрузку на процедуры добавления новых элементов и связей между ними. Также можно создать дополнительные таблицы, в которых будут описываться соответствующие структуры данных. Скажем, создать таблицу ФайловаяСистема, которая будет в каждой строчке описывать конкретную файловую систему (номер файловой системы; метка диска; имя компьютера, на котором находится файловая система; общий размер всех файлов и каталогов файловой системы и т.д.). С таблицей вершин файловой системы эта таблица будет связываться по полю номер файловой системы. Создание подобных таблиц позволяет хранить метаданные соответствующих структур данных. Для работы с каждой структурой имеются коды хранимых процедур на языке Transact-SQL.
Литература
- Седжвик Роберт. Фундаментальные алгоритмы на C. Анализ/Структуры данных/Сортировка/Поиск/Алгоритмы на графах: Пер. с англ./Роберт Седжвик. - СПб.: «ДиаСофтЮП», 2003.
- Л.Г. Блынский, В.Ю. Курганов. Моделирование иерархических структур в реляционных базах данных. Приборы и системы. Управление, контроль, диагностика. 2003, № 9.
- Максим Рябенко. Проектирование каталога. // Открытые системы. 2002, № 2.
- Дмитрий Палей. Моделирование квазиструктурированных данных. // Открытые системы. 2002, № 9.
- Евгений Григорьев. Представления идентифицируемых сложных объектов в реляционной базе данных. // Открытые системы. 2000, № 1-2.
Максим Гладков (max_gld@mail.ru) — аспирант Пензенского государственного университета, Сергей Шибанов (serega@stup.ac.ru) — доцент ПГУ.
