
Повышение производительности вычислительных установок обычно достигается за счет увеличения тактовой частоты работы элементов и количества этих элементов, позволяющего вводить параллелизм обработки и программируемость структуры [1]. Однако совершенствование вычислительных систем всегда сопровождал разрыв между быстродействием логических элементов и элементов памяти. Этот разрыв при возрастании степени интеграции и быстродействия больших интегральных схем (БИС) имеет тенденцию к увеличению. На каждом уровне развития элементной базы в силу обстоятельств, обусловленных необходимостью преодоления данного разрыва, ограничением на размер и количество выводов у корпусов микросхем, имеющимися средствами автоматизации программирования одни архитектуры становились предпочтительнее других — скажем, по показателю «производительность/стоимость».
Дискретная элементная база и интегральные схемы малой и средней интеграции позволяли изготовить процессор с произвольной архитектурой при существенном ограничении на общий объем используемого оборудования. Для обеспечения высокой производительности было необходимо соответствующее количество регистров и функциональных устройств, однако требуемый для их создания объем электронных компонентов, паяных и разъемных соединений определялся надежностью создаваемого процессора, стоимостью и энергопотреблением. В этих условиях конструкторы процессоров предложили разнообразные архитектуры, каждая из которых в своей проблемной области обеспечивала наивысшее значение показателя «производительность/стоимость». К числу таких архитектур следует отнести векторно-конвейерные процессоры и ассоциативные процессоры с SIMD-архитектурой, все обрабатывающие процессорные элементы которых выполняют команды одного потока, выдаваемого одним общим устройством управления. В период использования полупроводниковых схем малой и средней интеграции было создано несколько типов таких процессоров, например, STARAN [2], DAP [3], Connection Machine [4], состоящих из большого числа однобитных процессорных элементов со встроенной в каждый из них локальной памятью. Значительный рост степени интеграции при существенно меньшем росте количества выводов корпусов привел к ситуации, когда в одной БИС могло разместиться много процессорных элементов, однако их явно не хватало для создания полноценного SIMD-процессора. Объединению совокупности таких интегральных схем в один процессор препятствовало малое число выводов, не позволявшее подсоединить к процессорному элементу память и создать эффективную сеть связи между элементами. Та же проблема возникала и при попытке построения векторно-конвейерных процессоров: блоки, реализованные на БИС, имели бы количество соединений с другими БИС, намного превышающее число их выводов. Векторно-конвейерные процессоры, такие как CRAY-1 [5], венчали развитие процессоров, строящихся из дискретных компонентов. Архитектура векторно-конвейерных процессоров, по-видимому, оптимальна для дискретной элементной базы по критерию «производительность/размер».
В 80-х годах появились микропроцессоры, которые существенно превзошли по соотношению «производительность/стоимость» специально разрабатываемые многокристальные процессоры. Особенности проектирования и изготовления СБИС, в том числе и микропроцессоров, делают экономически оправданным только их массовое производство, что практически исключило возможность создания специализированных кристаллов для многокристальных процессоров. Сложилась ситуация, когда многокристальный процессор на момент начала проектирования, имеющий экстремальные оценки производительности, после своего изготовления, потребовавшего ряда лет, уже существенно уступал своим современникам — универсальным серийным микропроцессорам. Массово выпускаемые микропроцессоры стали использоваться для производства всех типов вычислительных систем [6].
Коль скоро микропроцессоры стали основной элементной базой, то единственное, что из них можно строить — параллельные вычислительные системы, образуемые путем объединения коммуникационной средой совокупности процессоров, блоков памяти и устройств ввода-вывода.
Параллельные системы по назначению и используемой элементной базе можно разбить на четыре класса:
- универсальные с фиксированной структурой, строящиеся из серийных универсальных микропроцессоров;
- специализированные с фиксированной структурой, строящиеся из микропроцессоров, ориентированных на исполнение определенных вычислений;
- универсальные с программируемой структурой, настраиваемые на аппаратурную реализацию исполняемых вычислений;
- специализированные с программируемой структурой, настраиваемые на аппаратно-программную реализацию исполняемых вычислений.
Универсальные системы с фиксированной структурой
Многопроцессорные серверы из серийных компонентов
Системы этого класса строятся из тех же микропроцессоров, на базе которых выпускаются ПК и рабочие станции. Этот подход разрешает проблему преодоления разрыва в быстродействии между обращением в память и обработкой за счет распределения памяти по процессорам, что позволяет одновременно всем процессорам работать с памятью. Универсальные вычислительные системы представлены сегодня двумя ветвями. Первая, наиболее массовая, состоит из многопроцессорных серверов. Все ведущие производители выпускают многопроцессорные серверы с разделяемой памятью, стремясь предоставить пользователям программное окружение, доступное в среде традиционных однопроцессорных компьютеров.
Вторая ветвь представлена параллельными суперкомпьютерами с большим количеством процессоров (MPP — massive parallel processing). Основным режимом их работы является исполнение трудоемких вычислений на базе распределенной памяти.
В первой ветви акцент делается на развитии параллельного программного обеспечения, во второй на разработке архитектур для получения наивысшей производительности. Само их существование определяется ограничением на количество процессоров в серверах, обусловленным пределами масштабируемости системных и прикладных программ.
Универсальные вычислительные системы можно подразделить на две группы: фирменные и собираемые пользователями из стандартных компонентов. В фирменных системах, как правило, используются специально разработанные коммутаторы и аппаратно-программные средства обеспечения отказоустойчивости и высокой готовности (резервирование, «горячая» замена). Системы, собираемые пользователями из серийных компонентов, используют в качестве вычислительных узлов коммерчески доступные рабочие станции или серверы. Коммуникационная подсистема строится из коммерчески доступных компонентов. Системное программное обеспечение может быть как свободно распространяемым, так и фирменным, но коммерчески доступным как самостоятельный продукт или в составе используемого сервера.
Для образования MPP-систем могут быть использованы интерфейсы микропроцессора, предназначенные для доступа к внекристальной памяти или внешним устройствам (шина PCI).
При построении параллельных систем с разделяемой памятью с архитектурами ccNUMA и COMA [7] используется интерфейс памяти. В этом случае по отношению к внутрикристальной кэш-памяти любого микропроцессора системы вся остальная память рассматривается как единая общая память, обмен с которой выполняется механизмом замещения кэш-строк в рамках реализации протокола когерентности. Архитектура систем с разделяемой памятью трактует память как единое адресное пространство, работа с ячейками которого выполняется командами чтения и записи. Построение таких систем предполагает использование серийных микросхем и изготовление достаточно сложных адаптеров, подключаемых к шине памяти процессора и поддерживающих протокол когерентности кэша.
При использовании для объединения микропроцессоров интерфейса внешних устройств, что характерно для вычислительных систем, создаваемых пользователями, возможно построение систем как с распределенной памятью с архитектурой на базе обмена сообщениями, так и с разделяемой памятью на основе технологии рефлексивной памяти, например, технологии memory channel [7]. Архитектура на базе обмена сообщениями использует отдельные наборы команд чтения и записи для работы с локальной памятью и специальные команды типа send, receive для управления адаптерами каналов ввода-вывода. Стандартизированные требования, предъявляемые шиной к адаптерам, позволяют строить системы из «крупных» блоков — системных плат рабочих станций и ПК, а также сетевых плат (Myrinet — www.myri.com, Quadrics — www.quadrics.com, Dolphin SCI — www.dolphinics.com, Fast Ethernet и др.) и коммутаторов коммуникационных сред. Для таких систем остро стоит проблема эффективности параллельных вычислений, так как они заведомо имеют ограничение пропускной способности обменов, обусловленные шиной PCI.
Направления развития микропроцессоров
Увеличение объема кэш-памяти на кристалле дает прирост производительности, но после достижения некоторого объема этот прирост существенно замедляется. Поэтому разумно использовать ресурс транзисторов кристалла для построения дополнительной совокупности функциональных устройств. Основное препятствие здесь — организация загрузки этих устройств полезной работой. Для выявления команд, которые можно одновременно загрузить в разные устройства процессора, в суперскалярных процессорах используется динамический анализ программного кода на стадии исполнения, а в процессорах с длинным командным словом — статический анализ на стадии компиляции. Однако в микропроцессорах с такими архитектурами имеются факторы, ограничивающие параллелизм уровня команд.
Дальнейшее повышение производительности микропроцессоров связывается сейчас со статическим и динамическим анализом кода с целью выявления параллелизма уровня программных сегментов с использованием информации о сегментах, предоставляемой процессору компилятором языка высокого уровня. Исследования в данном направлении привели к разработке многопотоковой архитектуры, использующей совокупность регистровых файлов в процессоре. Переключение процессора на другой регистровый файл выполняется либо по наступлению некоторого события, вызывающего приостанов процессора (промах в кэш-память, обращение к оперативной памяти, наступление прерывания), либо принудительно, например, в каждом такте как в системе Tera MTA (www.tera.com).
С ростом количества транзисторов на кристалле стало возможно построение микросхем, в которых микропроцессор вместе с памятью на кристалле выступает в роли одного из составных элементов «систем на кристалле» (SOC — System On Chip). В кристалл интегрируются функции, для исполнения которых обычно используются наборы микросхем. В кристалл интегрируются интерфейсы сетевых и телекоммуникационных систем, что позволяет без дополнительных адаптеров соединять микропроцессоры друг с другом и с различными сетями. Интеграция коммуникационных интерфейсов в кристалл микропроцессора была впервые сделана еще в транспьютерах. Ориентация разработчиков на создание систем с распределенной разделяемой памятью привела к интеграции в кристалл блока управления когерентностью многоуровневой памятью, доступ к блокам которой выполняется через интегрированную в тот же кристалл коммуникационную среду. В качестве примеров этого подхода можно назвать микропроцессоры Alpha 21364 и Power 4. Интеграция функций, с одной стороны, позволяет существенно увеличить пропускную способность между компонентами кристалла по сравнению с пропускной способностью между разными кристаллами, реализующими по отдельности каждую функцию. И, как следствие, поднять производительность систем. С другой стороны, при уменьшении количества кристаллов резко упрощается изготовление и монтаж плат, что ведет к повышению надежности и снижению стоимости систем.
Когда количество транзисторов на кристалле стало достаточным для реализации полноценного векторно-конвейерного процессора, появился яркий представитель систем этого класса — микропроцессор NEC SX-6 [18], который недолго оставался в одиночестве. Компания Cray применила в своем суперкомпьютере X1 с производительностью 52 TFLOPS векторно-конвейерные микропроцессоры собственной разработки.
В дальнейшем можно ожидать появление кристаллов с несколькими векторно-конвейерными процессорами, образующими однокристальную систему с общей памятью. Такие кристаллы могут быть объединены в MPP-систему. Тем самым, противостояние архитектур массово-параллельных и векторно-конвейерных систем получило логичное завершение.
Системы с фиксированной структурой из серийных микропроцессоров
MPP-системы из серийных микропроцессоров делают возможным сохранение традиционного стиля программирования. Принципиальным ограничением производительности этих вычислительных систем служит сам характер функционирования процессора. Фазы «выборка команды», «дешифрование команды», «выборка операндов» представляют собой «накладные расходы» на собственно необходимое пользователю действие — «исполнение команды». Производительность теряется либо прямо, если фазы выполнения команды реализуются последовательно с минимальными затратами оборудования, либо опосредованно путем увеличения затрат аппаратуры на совмещение фаз разных команд, как в современных микропроцессорах. Однако при этом возрастает объем оборудования микропроцессора, а, следовательно, уменьшается суммарное количество процессоров однокристальной вычислительной системы, вызывая соответствующее уменьшение производительности. В однокристальных векторно-конвейерных процессорах влияние рассматриваемого фактора ограничения производительности снижается, но не исключается полностью.
Специализированные системы с фиксированной структурой
Важность решения некоторых актуальных задач оправдывает построение специализированных вычислительных систем. В качестве яркого представителя этого класса систем можно указать систему GRAPE-6 [8], предназначенную для решения задачи взаимодействия N тел. Существующая конфигурация GRAPE-6 включает 2048 специализированных конвейерных микропроцессоров, каждый из которых имеет 6 конвейеров, используемых для вычисления гравитационного взаимодействия между частицами. GRAPE-6 представляет собой кластер, образованный из 16 узлов, объединенных коммутатором Gigabit Ethernet. Каждый узел состоит из ПК на базе микропроцессора AMD Athlon XP-1800+, функционирующего под управлением ОС Linux, и 4 специализированных плат, объединенных между собой и платами соседних узлов специальными каналами. На каждой плате устанавливается 32 специализированных кристалла GRAPE-6.
Теоретическая пиковая производительность GRAPE-6 — 63,4 трлн. оп./с. На реальной задаче по моделированию формирования внешних планет солнечной системы достигнута производительность 29,5 трлн. оп./с. Для сравнения, кластер Green Destiny, который при решении на 220 универсальных микропроцессорах задачи N тел, моделирующей формирование Галактики с использованием 200 млн. частиц, показывает производительность 38,9 млрд. оп./с.
Универсальные системы с программируемой структурой
Такие вычислительные системы строятся из программируемых логических интегральных схем (ПЛИС), содержащих одну или несколько матриц вентилей и позволяющих программно скомпоновать из этих вентилей в одном корпусе электронную схему, эквивалентную схеме, включающей от нескольких десятков до тысяч интегральных схем стандартной логики [9].
Основная идея архитектуры подобных вычислительных систем состоит в том, чтобы программно настроить схему, реализующую требуемое преобразование данных. В [10] приведено сравнение реализации фильтра на Alpha 21164 и Xilinx XC4085XL-09. Микропроцессор Alpha 21164 выполняет две 64 разрядных операции за такт при тактовой частоте 433 МГц, что эквивалентно производительности 55,7 бит/нс. XC4085XL-09 имеет 3136 программируемых логических блоков и минимальную длительность такта 4,6 наносекунд. Для корректного сравнения можно принять, что один программируемый логический блок реализует 1-битную арифметическую операцию. В этих предположениях производительность ПЛИС равна 682 бит/нс. Таким образом, при реализации фильтра на ПЛИС достигается производительность, в 12 раз большая, чем на микропроцессоре Alpha 21164.
Основная трудность в использовании реконфигурируемых вычислений состоит в подготовке для заданного алгоритма настроечной информации для создания в ПЛИС схемы, реализующей этот алгоритм. Естественно, поскольку ПЛИС создавались для построения электронной аппаратуры, то изготовители обеспечили, в первую очередь, системы подготовки настроечной информации на высокоуровневых языках электронного проектирования, таких, как Verilog и VHDL [11]. Однако эти языки непривычны для разработчиков алгоритмов. Сегодня в качестве языков программирования ПЛИС используются языки описания потоковых вычислений.
Компания Star Bridge Systems (www.starbridgesystems.com) производит семейство программно реконфигурируемых вычислителей Hypercomputer System HC-X и предлагает комплексное решение для организации реконфигурируемых вычислений (рис. 1). Старшая модель семейства, суперкомпьютер HC-98m, состоит из управляющего компьютера и двухплатного программно реконфигурируемого вычислителя, включающего 14 ПЛИС Virtex-II серии 6000 и 4 Virtex-II серии 4000. В совокупности это составляет 98 млн. вентилей. После включения питания первая ПЛИС программируется из постоянного запоминающего устройства на плате. В этой ПЛИС формируется порт шины PCI-X, через который управляющий компьютер будет, используя среду разработки программ Viva, программировать остальные ПЛИС.
 |
| Рис. 1. Структура узла универсальной вычислительной системы, построенного на ПЛИС |
Специализированные системы с программируемой структурой
Обладая способностью реализовать любую схему, ПЛИС имеют, по сравнению с жесткой логикой, большую площадь в пересчете на используемый вентиль. Комбинацией, сохраняющей программируемость при уменьшении, по сравнению с ПЛИС, затрат оборудования, служит создание однородных вычислительных сред из одного типа ячеек с учетом проблемной ориентации некоторой специфичной ячейки при ее реализации на жесткой логике и программируемости связей между множеством таких ячеек.
Идея однородных вычислительных сред была сформулирована в начале 60-х годов сотрудником Института математики СО АН СССР Э.В. Евреиновым [1]. Была показана возможность снятия ограничения на рост тактовой частоты в однородных средах за счет коротких связей между соседними ячейками среды и реализации взаимодействия между удаленными ячейками по принципу близкодействия через цепочку ячеек, расположенных между ними. В силу возможности различного направления специализации ячеек и установления различной пропорции между реализацией на жесткой логике и программируемостью, сегодня предложено много вариантов построения специализированных систем с программируемой структурой [12-16]. К этому классу вычислительных систем относятся также систолические и волновые процессоры [17], программируемые (raw) процессоры [15], ассоциативные процессоры с SIMD-архитектурой, примером которых может служить проект CAM2000 [16], и др.
Технологическая база развития современных архитектур
Развитие САПР микроэлектроники, с одной стороны, и стандартизация микроэлектронных производств, с другой, создали предпосылки для появления предприятий, не имеющих собственных фабрик по производству микросхем, но разрабатывающих микросхемы или их блоки, являющиеся интеллектуальной собственностью. Это создает предпосылки вовлечения в производство высокопроизводительных вычислительных систем разработчиков, результаты труда которых могут быть получены ими непосредственно без отторжения от них проекта для передачи исполнителям технологического профиля. Это новый этап в развитии вычислительных технологий, дающий уникальный шанс, в том числе, для России.
В качестве соответствующих примеров можно предложить проект по созданию однокристальной системы из многопотоковых процессоров для построения из этих кристаллов мощных суперкомпьютеров на основе опыта, полученного при создании МВС-1000М [18], микропроцессоры «Квант» [19], изготовленные на фабрике AMD в Дрездене, а также ряд других отечественных проектов, реализация которых осуществлялась на зарубежных производствах.
Литература
- Э.В. Евреинов, Ю.Г. Косарев. Однородные универсальные вычислительные системы высокой производительности. // Новосибирск: Наука, 1966.
- K. Batcher. STARAN Parallel Processor System Hardware. NCC, 1974.
- Reddaway. DAP - A Distributed Array Processor. Proc. of 1 st Annual Symposium on Computer Architecture, IEEE, 1973.
- W. Hillis. The Connection Machine. The MIT Press, 1985.
- Cray Research, CRAY-1 Computer System Hardware Reference Manual, Bloomington, Minn., pub. no. 2240004, 1977.
- G. Bell. Ultracomputers: A Teraflop Before Its Time. Communications of the ACM. Vol. 35, No. 8, August 1992.
- В. Корнеев. Архитектуры с распределенной разделяемой памятью. Открытые системы, № 3, 2001.
- J. Makino, E. Kokubo, T. Fukushige, H. Daisaka. A 29.5 Tops simulation of planetesimals in Uranus-Neptune region on GRAPE-6. Proc. of SC-2002.
- Programmable Logic Data Book. Xilinx, Xilinx, Inc. 1999.
- A. DeHon. The Density Advantage of Configurable Computing. Computer, No. 4. 2000.
- IEEE Std 1076-1993. VHDL'93. IEEE Standard VHDL Language Reference Manual.
- М.П. Богачев. Архитектура вычислительной системы с однородной структурой. В кн. Однородные вычислительные среды. Львов. ФМИ АН УССР. 1981.
- В.С. Седов. Матрица одноразрядных процессоров. Львов. НТЦ "Интеграл". 1991.
- L. Durbeck, N. Macias. The Cell Matrix: An Architecture for Nanocomputing, www.cellmatrix.com.
- M. Taylor, J. Kim, J. Miller at al. The Raw Microprocessor: A Computational Fabric for Software Circuits and General-Purpose Programs. IEEE Micro, 2002, Vol. 22, No. 2.
- Smith D., Hall J., Miyake K. The CAM2000 Chip Architecture. Rutgers University. http://www.cs.rugers.edu/pub/technical-reports.
- С. Кун. Матричные процессоры на СБИС. // М.: Мир. 1991.
- Фортов В.Е., Левин В.К., Савин Г.И., Забродин А.В., Каратанов В.В., Елизаров Г.С., Корнеев В.В., Шабанов Б.М. "Наука и промышленность России". Суперкомпьютер МВС-1000М и перспективы его применения. "Наука и промышленность России" 2001, № 11(55).
- Виксне П.Е., Каталов Ю.Т., Корнеев В.В., Панфилов А.П., Трубецкой А.В., Черников В.М. Транспьютероподобный 32-разрядный RISC-процессор с масштабируемой архитектурой. Вопросы радиоэлектроники. Серия ЭВТ. Выпуск 2, НИИЭИР, 1994.
Виктор Корнеев (korv@a5.kiam.ru) — сотрудник НИИ «Квант» (Москва).
Архитектуры многопотоковых процессоров
Каждый набор регистров Tera MTA обслуживает один вычислительный процесс, называемый потоком (thread). Всего в процессоре имеется n наборов регистров, а поэтому запрос, выданный в основную память процессом, может обслуживаться в течение n-1 тактов, вплоть до момента, когда процессор снова переключится на тот же набор регистров. Тем самым по отношению к одному потоку исполнение его команд замедляется в n раз. Значение n выбирается исходя из того, чтобы время доступа в память было меньше, чем длительность n-1 такта процессора. Задача формирования n потоков целиком возлагается на компилятор.
При всем различии подходов к созданию многопотоковых (multithread) микропроцессоров, общим в них является введение множества процессорных элементов, содержащих устройство выборки команд, которое организует окно исполнения для одного потока. В рамках потока может выполняться предсказание переходов, переименование регистров, динамическая подготовка команд к исполнению. Тем самым, общее количество команд, находящихся в обработке, значительно превышает размер одного окна исполнения суперскалярного процессора, с одной стороны, и тактовая частота не лимитируется размером окна исполнения, — с другой стороны. Выявление потоков может выполняться компилятором при анализе исходного кода на языке высокого уровня или исполняемого кода программы. Однако компиляторы не всегда могут разрешить проблемы зависимостей при использовании регистров и ячеек памяти между потоками, что требует разрешения этих зависимостей уже в ходе исполнения потоков. Для этого в микропроцессор вводится специальная аппаратура условного исполнения потоков, предусматривающая возврат с отбрасыванием наработанных результатов в случае обнаружения нарушения зависимостей между потоками. Нарушением зависимости, например, может служить запись по вычисляемому адресу в одном потоке в ту же ячейку памяти, из которой выполняется чтение, которое должно следовать за этой записью, в другом потоке. В этом случае, если адреса записи и чтения не совпадают, нарушение отсутствует. При совпадении адресов фиксируется нарушение, которое должно вернуть исполнение потока к команде чтения правильного значения.
Интерфейс между аппаратурой многопотокового процессора, поддерживающей протекание каждого отдельного потока и аппаратурой, общей для исполнения всех потоков, может быть установлен как сразу после устройств выборки команд потока, так и на уровне доступа к разделяемой памяти. В первом случае все потоки используют один набор функциональных устройств. Тесная связь по ресурсам позволяет эффективно исполнять последовательные программы с сильной зависимостью между потоками. В этом случае имеет место реализация SMT-процессора (simultaneous multithreading). Во втором случае для исполнения каждого потока, фактически, выделяется функционально законченный процессор. В целом, эта структура ориентирована на исполнение независимых и слабо связанных потоков, порождаемых либо одной программой, либо их совокупностью. В этом случае скорее надо говорить не о процессоре, а о CMP-системе (chip multiprocessing).
Возможно также промежуточное расположение интерфейса, при котором часть функциональных устройств, например, с плавающей точкой разделяется всеми потоками, а остальные устройства дублируются в каждом потоке. Количество и типы устройств, разделяемых всеми потоками, равно как и устройств дублированных во всех потоках, определяется исходя из представления о возможности их эффективной загрузки.
Многопотоковый процессор может исполнять потоки, принадлежащие одной или нескольким программам. Если процессор исполняет одну программу, то говорят о его производительности, если несколько — о пропускной способности.
Intel использовала 2-потоковую архитектуру в процессорах Pentium 4 и Xeon, однако еще предстоят значительные исследования по многопотоковым архитектурам. Компания Tera объявила о разработке проекта многопотокового микропроцессора Torrent, реализующего процессор МТА (www.tera.com). Компания Level One, образованная Intel, выпустила сетевой микропроцессор IXP1200 (www.level1.com), содержащий 6 четырехпотоковых процессоров. IBM анонсировала проект компьютера Blue Gene (D. Clark. Blue Gene and the race toward petaflops capacity. IEEE Concurrency, January-March 2000) с производительностью 1015 FLOPS, кристалл микропроцессора которого включает 32 восьмипотоковых процессора. В кристалл встроена память DRAM, реализованная как 32 блока. Каждый блок соответствует одному из 32 процессоров и имеет шину доступа 256 разрядов. Так как DRAM имеет высокую пропускную способность и малую задержку, то при восьмипотоковой структуре процессора становится возможным отказаться от кэш-памяти, вместо которой между процессором и памятью используется небольшая буферная память. IBM, Sony, Toshiba ведут совместный проект по разработке многопотокового процессора Cell («ячейка»), само название которого красноречиво свидетельствует о его предназначении.
Кластер Green Destiny
В Лос-Аламоской лаборатории в рамках реализации проекта малообъемных суперкомпьютеров построен кластер Green Destiny (M. Warren, E. Weigle, W. Feng. High-Density Computing: A 240-Processor Beowulf in One Cubic Meter, Proc. of SC-2002). Авторы проекта поставили целью создать 240-процессорный кластер в объеме 1 кубический метр. В качестве базового выбран конструктив RLX System 324 — 3U-блоки (высота — 5,25 дюйма, ширина — дюйма 17,25, глубина — 25,2 дюймов), вмещающие 24 серверов-лезвий. В блоке имеется два допускающих горячую замену источника питания мощностью 450 Вт и интерфейсы для доступа к вычислительным модулям.
Вычислительный модуль включает микропроцессор Transmeta TM5600/667 МГц, 128 Mбайт памяти DDR SDRAM, 512 Mбайт SDRAM, 20-гигабайтный диск и интерфейс Fast Ethernet. Имеется еще один порт Ethernet, позволяющий удвоить пропускную способность за счет агрегирования двух портов. Каждый из 24 вычислительных модулей одного блока подключен к коммутатору Fast Ethernet. Все 10 таких коммутаторов подключены, в свою очередь, к коммутатору Gigabit Ethernet, образуя одноуровневое дерево.
Кластер скомпонован в стандартную стойку размером 84x24x36 дюймов, использует систему питания APC Smart-UPS, управляемую ОС Linux. В ненагруженном состоянии кластер рассеивает 7 Вт. Под нагрузкой TM5600 выделяет приблизительно 15 Вт тепла, а кластер в целом с учетом всего оборудования — 5200 Вт, что в пересчете на один вычислительный модуль составляет 22 Вт.
Программируемый микропроцессор
Схемы для выполнения арифметических операций над 64-разрядными операндами с плавающей точкой, сформированные в однородной вычислительной среде с однобитными ячейками, используют значительно больший объем оборудования и уступают по быстродействию устройствам обработки операндов с плавающей точкой микропроцессоров с традиционной архитектурой. Проект программируемого (raw) микропроцессора преследует цель устранить этот недостаток, сохранив преимущества программируемости структуры вычислительных систем. Программируемый микропроцессор строится на кристалле как ячейка однородной решетки nxn (M. Taylor, J. Kim, J. Miller at al. The Raw Microprocessor: A Computational Fabric for Software Circuits and General-Purpose Programs. IEEE Micro, 2002, Vol. 22, No. 2). Авторы проекта используют термин tile. Ячейка содержит процессор и программируемый коммутатор, предназначенный для передачи и приема данных между соседними ячейками.
Процессор выполнен по 8-стадийной конвейерной схеме с промежуточной фиксацией результатов между стадиями конвейера в очереди с дисциплиной обслуживания FIFO. В процессоре реализовано много обходных путей (bypass), позволяющих использовать промежуточные результаты сразу после их получения на каждой стадии конвейера, в том числе, для передачи в другие ячейки. Предусматриваются также кэш-память данных (32 Кбайт) и кэш-память команд (96 Кбайт).
Для того чтобы ускорить межячеечные передачи данных, применен следующий подход. Регистры r24-r27 отображены на входные очереди межячеечных каналов с дисциплиной обслуживания FIFO. Обращение к регистру rj, j {24, ..., 27}, по чтению, в том числе при выборе этого регистра как операнда, влечет выборку элемента данных из соответствующей входной очереди. Если элемент в очереди отсутствует, то завершение выполнения обращения к регистру rj, j {24, ..., 27}, задерживается вплоть до поступления данных во входную очередь. При обращении к регистру rj, j {24, ..., 27}, по записи, реальная запись производится в выходную очередь межячеечных каналов. Если очередь заполнена, то завершение выполнения записи задерживается, вплоть до освобождения элемента очереди.
Решения по организации межячеечных связей и связей между обрабатывающими устройствами в конвейере идентичны и базируются на промежуточных FIFO-очередях, передающих данные по готовности приемника. Важным следствием такой организации является то, что протекание вычислений определяется событиями, в качестве которых выступают размещение данных в очередях. На ход вычислений не оказывают влияния прерывания, происходящие в процессорах, промахи в кэш-памяти и иные асинхронно наступающие события, непосредственно не связанные с вычислительным процессом.
Программируемый коммутатор ячейки содержит 2 интерфейсных процессора. Статический интерфейсный процессор управляет передачами слов данных по устанавливаемым при компиляции программы маршрутам. Для пересылки слова между двумя ячейками статические интерфейсные процессоры на маршруте между этими ячейками обязательно должны исполнить соответствующие команды, задающие путь передачи слова. Компилятор выполняет потактное совмещение преобразований в процессоре и статическом интерфейсном процессоре. Динамический интерфейсный процессор управляет передачей пакетов слов. Первое слово пакета содержит идентификатор ячейки-адресата, поле пользователя и количество слов в пакете (не более 31). Пакет передается по методу коммутации канала на время передачи. Динамический интерфейсный процессор служит для передач данных, выполнение которых нельзя предсказать во время компиляции, например, промахи в кэш-памяти, прерывания, передачи данных, выполнение которых зависит от значений предикатов.
Ячейки, находящиеся на границе поля ячеек, имеют свободные каналы, к которым подключаются контроллеры памяти, периферийных внешних устройств. Прерывания от контроллеров передаются в виде специальных однословных сообщений, в которых указывается, какая ячейка должна обрабатывать это прерывание
Экспериментальный кристалл программируемого процессора изготовлен по 0,15-микронной технологии с 6 слоями медных проводников на фабрике IBM. Кристалл содержит 16 (4х4) ячеек и функционирует на частоте 225 МГц, потребляя 25 Вт.
Разработаны компиляторы языков Си и Фортран, автоматически отображающие операторы программы в массив ячеек и формирующие команды статического интерфейсного процессора этой программы. Для одной из программ набора SPECfp на 16 ячейках получено уменьшение времени выполнения программы от 6 до 11 раз по сравнению с временем ее исполнения на одной ячейке. В другом эксперименте с использованием 32 ячеек соответствующее ускорение составило от 9 до 19 раз.
Однородные вычислительные среды
В разное время было предложено достаточно много проектов однородных вычислительных сред [1-5]. Какое-то схематичное представление о них дает Рисунок, на котором изображена структура ячейки гипотетической однородной среды. Ячейки находятся в узлах прямоугольной решетки и связаны двунаправленными информационными каналами. Кроме этого, ячейки связаны сетью для ввода программы в ячейку, задания режима ее функционирования «настройка/работа», тактирования. В режиме «настройка» каждая ячейка получает программу, возможно, состоящую из одной команды.
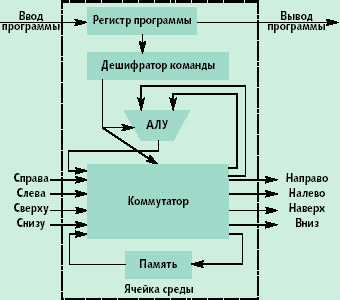 |
| Рис. Структура ячейки гипотетической однородной среды |
В режиме «работа» ячейка выполняет команды над операндами, поступающими из информационных каналов или из внутренней, как правило, однобитной памяти. То, какие операнды использовать, и какую операцию выполнять над ними определяется дешифратором команды, который управляет АЛУ и коммутатором ячейки. Эта же команда определяет, на какие информационные выходы, и что надо выдавать из ячейки. Ячейка, как правило, выполняет следующие команды: транзит данных через ячейку с ее входов с записью или без записи в память ячейки; нет операции; суммирование с учетом или без учета переноса; логическая операция (суммирование по модулю 2, или, и, не-и); генерирование константы.
Настройка ячеек может быть статической или динамической. В первом случае команды в регистр программы записываются извне. Во втором случае должен предусматриваться способ, как будет выполняться конфигурирование ячеек (т.е. выполняться загрузка регистров программы ячеек). Ячейки могут двояко воспринимать входную информацию. Когда ячейка формирует выходные сигналы сообразно с конфигурацией, она работает в «комбинационном» режиме или режиме обработки данных, как комбинационный логический блок. Может быть введен дополнительный режим работы ячейки, называемый «режимом модификации», позволяющий интерпретировать входные данные как новое содержимое регистра программы. Ячейки входят в этот режим и выходят из него через скоординированный обмен с соседними ячейками. Во время этого скоординированного обмена соседняя ячейка предоставляет новую программу (таблицу истинности) для модифицируемой ячейки. Конфигурирование ячейки является чисто локальной операцией, в которой участвуют только две ячейки — та, которая имеет новое содержимое, и та, в которую это содержимое записывается. Благодаря локальности, операции конфигурирования могут производиться одновременно во множестве различных областей матрицы ячеек.
Любая из ячеек матрицы может работать в любом из данных режимов. Не существует ячеек с заранее предопределенным режимом работы, он определяется данными от соседних ячеек на входах этой ячейки. В типовой сложной схеме матрица содержит ячейки, которые обрабатывают данные, и ячейки, которые участвуют в реконфигурации других ячеек. Функционирование системы включает тесную кооперацию, взаимодействие, обмен между комбинационными узлами и узлами модификации. Можно не только обрабатывать данные на наборе ячеек, но и заставлять ячейки считывать и записывать конфигурацию других ячеек, что позволяет создавать динамические самоконфигурируемые системы, чье поведение во время выполнения может изменяться в зависимости от локальных событий.
Литература
- Э.В. Евреинов, Ю.Г. Косарев. Однородные универсальные вычислительные системы высокой производительности. // Новосибирск: Наука, 1966.
- М.П. Богачев. Архитектура вычислительной системы с однородной структурой. В кн. однородные вычислительные среды. // Львов, ФМИ АН УССР, 1981.
- В.С. Седов. Матрица одноразрядных процессоров. Львов, НТЦ "Интеграл", 1991.
- L. Durbeck, N. Macias. The Cell Matrix: An Architecture for Nanocomputing, www.cellmatrix.com.
- С. Кун. Матричные процессоры на СБИС. // М.: Мир, 1991.
Однокристальный ассоциативный процессор САМ2000
На концептуальном уровне многие сегодняшние проблемы повышения эффективности параллельной обработки данных связаны с вопросами представления данных в адресных запоминающих устройствах и указанием способа их параллельной обработки. Данные должны быть представлены в виде ограниченного количества форматов (например, массивы, списки, записи). Также должна быть явно создана структура связей между элементами данных посредством указателей на адреса памяти элементов. В свою очередь, при обработке этих данных порождается совокупность операций, обеспечивающих доступ к данным по указателям. При подготовке и исполнении параллельных программ анализ этой совокупности операций составляет, в сущности, проблему, так называемого, распараллеливания по данным. Кроме того, указанные операции по доступу к данным часто образуют — в силу своей природы — неподдающиеся распараллеливанию блоки программного кода.
Сформировавшаяся триада — алгоритмы прикладных задач, общесистемное программное обеспечение и аппаратные средства — существенно ориентирована именно на традиционную адресную обработку данных. Помимо обусловленной этим подходом громоздкости операционных систем и систем программирования, адресный доступ к памяти служит препятствием к созданию вычислительных средств с архитектурой, ориентированной на более эффективное использование параллелизма обработки данных.
Преодоление ограничений, обусловленных адресным доступом к памяти, возможно за счет использования ассоциативного способа обработки данных, позволяющего выбирать все данные, удовлетворяющие некоторому задаваемому критерию поиска, и производить над всеми выбранными данными требуемые преобразования [1, 2]. Определенная подобным образом ассоциативная обработка включает возможность массовой параллельной выборки данных и массовой их обработки. Критерием поиска данных может быть совпадение с любым элементом данных, достаточным для выделения искомых данных из всех данных. Поиск данных может происходить по фрагменту, имеющему большую или меньшую корреляцию с заданным элементом данных.
Исследованы и в разной степени используются несколько подходов, различающихся полнотой реализации модели ассоциативной обработки. Если реализуется только ассоциативная выборка данных с последующим поочередным использованием найденных данных, то говорят об ассоциативной памяти или памяти, адресуемой по содержимому. При достаточно полной реализации всех свойств ассоциативной обработки, используется термин «ассоциативный процессор». Примером такого процессора может служить STARAN [2]. Кроме того, модель ассоциативной обработки может достаточно эффективно быть реализована на специализированных параллельных системах из большого числа процессоров, каждый из которых имеет собственную небольшую локальную память. Подобные вычислительные структуры обычно называют памятью с обработкой, многофункциональной памятью, интеллектуальной памятью и рядом других терминов.
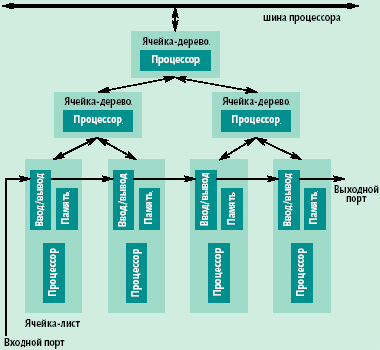 |
| Рис. Структура САМ 2000 — бинарное дерево |
Однако следует проанализировать возможности использования памяти с обработкой. Представляется, что переход от одной крайности (только хранение данных в традиционной памяти) к другой (вся обработка данных только в памяти) заведомо не продуктивен. Компромиссным решением может быть реализация в интеллектуальной памяти простой массово параллельной обработки данных и вычисление агрегированных значений типа сумма компонент вектора, определение минимальной или максимальной компоненты вектора и тому подобные. Сложная обработка данных производится в процессоре, к которому подключается рассматриваемая интеллектуальная память. Этот подход положен, например, в основу проекта контекстно-адресуемой (ассоциативной) памяти САМ 2000 [3].
САМ 2000 объединяет возможности ассоциативного процессора, ассоциативной памяти, динамической памяти в одном кристалле. Этот кристалл может выполнять просто функции динамической памяти, а также производить простую массово параллельную обработку содержимого, хранящегося в динамической памяти.
В основе САМ 2000 лежит концепция увеличения качества данных. Множество простых процессоров в кристалле памяти выполняют массово-параллельную обработку содержимого памяти прежде, чем отправить результаты этой обработки в процессор. Например, нахождение среднего k чисел в традиционном вычислительном модуле с кэш-памятью требует пересылки данных с последующим выполнением только одной операции с каждым данным. При этом создается большая нагрузка на интерфейс «процессор-память», определяющий фактически производительность обработки. В САМ 2000 среднее может быть вычислено так, что сумма чисел может быть получена в памяти и передана в процессор, где выполняется вычисление среднего.
Каждый кристалл САМ 2000 выполняет функцию микросхемы интеллектуальной памяти и имеет 4 шины: двунаправленную шину данных, подсоединяемую к основному процессору или процессорам, однонаправленную входную шину команд, по которой поступает выполняемая всеми кристаллами команда; однонаправленную входную шину ввода; однонаправленную выходную шину вывода.
Литература
- Т. Кохонен. Ассоциативная память. М.: Мир, 1980.
- Амамия М., Танака Ю. Архитектура ЭВМ и искусственный интеллект. М.: Мир, 1993.
- 3.Smith D., Hall J., Miyake K. The CAM2000 Chip Architecture. Rutgers University, http://www.cs.rugers.edu/pub/technical-reports.
Однокристальный векторно-конвейерный процессор SX-6
Микропроцессор создан по 0,15-микронной КМОП-технологии с медными проводниками и содержит приблизительно 57 млн. транзисторов. Основными компонентами микропроцессора являются скалярный процессор и 8 идентичных векторных устройств. Скалярный процессор имеет суперскалярную архитектуру с 4 результатами за такт и использует 128 64-разрядных регистров. При частоте 500 МГц пиковая производительность скалярного процессора составляет 1 GFLOPS. Каждое из 8 идентичных векторных устройств содержит 5 конвейеров обработки данных, выполняющих логические операции, маскирование, сложение/сдвиги, умножение и деление над операндами, размещенными в векторных регистрах, а также один конвейер обменов данными (загрузки-выгрузки) между векторными регистрами и основной памятью. Суммарный объем регистров в 8 векторных устройствах составляет 18 Кбайт (эквивалентно 288 64-разрядным регистрам).
В векторном устройстве операции умножения и сложения могут сцепляться, за счет чего пиковая производительность одного устройства при частоте 500 МГц может достигать 1 GFLOPS. Пропускная способность интерфейса с памятью равна 32 Гбайт/с, что позволяет каждому из 8 векторных устройств прочитать из памяти или записать в память один операнд в каждом такте. Производительность SX-6 составляет 8 GFLOPS.
