
Tamino — система управления XML-базами данных компании Software AG. В отличие от решений других производителей СУБД, Tamino — не просто еще один уровень в системе управления базами данных, предназначенной для поддержки реляционной или объектно-ориентированной модели. Напротив, Tamino изначально рассчитана именно на XML. В статье приводится краткое описание архитектуры Tamino, а затем рассматриваются некоторые особенности структуры этой СУБД. В частности, затрагиваются моменты, в силу которых ее проектирование стало нетривиальным, а также вопросы, которые пока остаются открытыми.
XML становится превалирующим форматом при решении многих задач обработки информации в Internet. Хотя XML изначально создавался с целью упростить обмен данными, он все чаще и чаще применяется для моделирования данных, связанных с бизнесом, для решения других исключительно практических задач. При этом требуется обеспечить надежное хранение XML-документов и эффективно обрабатывать запросы к таким документам. Все это классические задачи баз данных.
Общие вопросы поддержки XML в базах данных
XML во многих отношениях отличается от хорошо структурированного мира реляционных и объектно-ориентированных баз данных. Основные реляционные и объектно-реляционные СУБД в определенной мере поддерживают XML (например, [6-8]), их возможности лишь подтверждают его «кардинальное несоответствие» лежащим в их основе моделям. В этих системах до определенной степени возможны хранение XML-документов и обработка запросов к ним. Однако полная поддержка XML требует применения иных методик, которые выходят за рамки традиционных реализаций баз данных [5].
В статье обсуждается несколько областей, где хорошо известные методы баз данных оказываются не в состоянии поддержать весь диапазон функциональности XML.
XML сам по себе предлагает широкий спектр возможностей моделирования данных. Существует два подхода к моделированию, которые обычно противопоставляют [1]. Материалы, ориентированные на данные, обладают регулярной структурой, причем порядок элементов в них, как правило, не имеет значения, и в них отсутствует смешанное информационное наполнение. Информация такого типа обычно хранится в реляционных и объектно-ориентированных базах данных. Для материалов, ориентированных на документы, характерна менее регулярная структура, наличие смешанного информационного наполнения и значимость порядка элементов в документе. Конечно, это лишь две крайности, есть и масса других подходов, занимающих промежуточное положение.
XML-документы могут содержать ту или иную информацию о схеме данных (например, в виде DTD), однако это не обязательно. Даже если схема существует, комментарии и команды обработки могут появляться в любом месте документа без предварительной декларации в схеме. В силу этого классический подход, предусматривающий обработку объектов предопределенного типа, в XML-базах данных не применим.
XML — всего лишь язык разметки и сам по себе он не содержит никаких функций обработки. В частности, обращение с запросом к набору XML-документов выходит за рамки рекомендации XML [2].
Цель данной статьи — описать, каким образом в системе управления базами данных Tamino компании Software AG эти вопросы решаются, и в чем недостатки поддержки XML в реляционных и объектно-реляционных СУБД. Чтобы обсуждение было предметным, приводится краткое описание Tamino.
Архитектура Tamino
Tamino предназначена для поддержки XML-документов, т. е. для хранения XML-данных (и других типов данных, которые часто используются в Internet, например, файлов HTML, изображений GIF и т.д.) и извлечения их в наборах, а также реализации обширных возможностей выполнения запросов и полной поддержки транзакций.
На рис. 1 представлена общая схема архитектуры Tamino. Подразумевается, что в Tamino документы хранятся целиком. Метод хранения может выбрать администратор [4]. Чтобы предоставить доступ к имеющимся источникам данных и объединить данные, поступающие из различных источников (в том числе и из Tamino) в один XML-документ, Tamino поддерживает доступ к внешним источникам через компонент X-Node.
Для обработки или выборки частей XML-документов может применяться любой предоставленный пользователем код. Компонент X-Tension позволяет определять расширения для сервера Tamino. Серверные расширения могут передавать XML-документы или части этих документов в функции, предоставленные пользователем, или считывать данные из этих функций для добавления их в XML-документ.
Доступ к Tamino осуществляется посредством протокола HTTP. Документы и команды передаются на сервер Tamino через расширение Web-сервера, называемое X-Port. Ядро XML принимает эти команды и анализирует их с учетом метаданных, находящихся в репозитарии Tamino, который называют картой данных. Более подробное описание можно найти в [4].
Оставшаяся часть статьи посвящена тем аспектам, где для Tamino потребовалось найти решение, отличающееся от подходов, которые используются в «классических» базах данных.
Схемы XML-документов
В XML реализована концепция схемы, но она во многом отличается от своего аналога, хорошо известного по классическим базам данных. Определение типов документов (document type definition — DTD) используются в качестве способа описания XML-документа. С точки зрения баз данных, DTD имеют несколько ограничений; в частности, это довольно слабая концепция типизации данных. Чтобы преодолеть эти ограничения, предложено несколько языков описания схем. Рабочая группа Консорциума W3C готовит язык описания схем XML, который позволит создавать более детальное схематическое описание XML-документов. Однако пока единственное стандартное определение схемы для XML — это DTD. Поэтому системы управления базами данных должны учитывать его особенности.
XML-документ может включать в себя информацию о схеме: он может ссылаться на внешнее DTD-определение, может содержать локальное DTD-определение или может модифицировать внешнее определение с учетом локального. Более того, DTD может даже не использоваться.
В реляционных и объектно-ориентированных базах данных схема создается прежде, чем можно сохранить экземпляры данных, причем экземпляры должны точно соответствовать продекларированной схеме. Со своей стороны, система управления XML-базами данных должна учитывать тот факт, что каждый экземпляр декларирует свою собственную схему (или вообще не декларирует никакой схемы). Привычная группировка объектов гомогенной структуры в таблицы или классы предопределенного вида, в общем случае, к XML-документам неприменима.
Между тем базы данных используют поддержку наборов гомогенных данных: запросы действуют над множествами, а индексы определяются для данных на основе общей схемы. Чтобы выполнять обработку запросов, произвольные объекты могут быть сгруппированы в наборы (по крайней мере, таким набором является вся база данных), например, в соответствии с определением, данным пользователем. Гетерогенная структура объектов делает оптимизацию запросов почти невозможной. Определение индекса требует, по крайней мере, наличия общего подмножества в структуре объектов, для которых создается индекс.
Таким образом, мы столкнулись с проблемой, состоящей в том, что XML-документы не всегда легко группируются по своей структуре, но для базы данных определенная группировка необходима.
Поддержка схемы
Предложенное в Tamino решение предусматривает группировку по определению открытой модели информационного наполнения в сочетании с группировкой по указанию пользователя.
Документы, хранящиеся в Tamino, группируются в наборы (сразу при добавлении в базу данных). Внутри набора могут декларироваться несколько типов документов. Для каждого типа документа может быть определена общая схема, но как открытая модель информационного наполнения; каждому сохраняемому документу Tamino назначает один из типов документов. Это назначение происходит на основе типа корневого элемента документа. Документ должен соответствовать схеме присвоенного типа документа, но может иметь дополнительные элементы/атрибуты, которые не смоделированы в схеме (открытая модель информационного наполнения). Таким образом, структура документов, хранимых как документы определенного типа, может отличаться весьма существенно. Если тип документа, соответствующий типу корневого элемента, не найден, документ сохраняется без какой-либо проверки схемы.
В качестве иллюстрации открытой модели информационного наполнения рассмотрим пример. Схема Tamino декларирует следующую структуру документа.
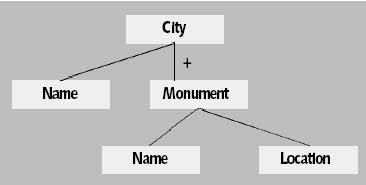
На основе этого определения в Tamino сохранен следующий документ.
Darmstart The city of art nouveau Langer Ludwig Luisenplatz M5
City имеет недекларированный атрибут Inhabitants и недекларированного потомка Addition. Monument имеет недекларированный атрибут Height, а Location — недекларированные подэлементы. Тем не менее, Tamino допускает этот документ. Если, однако в документе не будет представлен ни один элемент Monument, то такой документ будет отвергнут, поскольку определенная схема однозначно требует наличия, по крайней мере, одного такого элемента.
В связи с этим возникает вопрос, когда в схеме типов документов Tamino необходимо моделировать элемент или атрибут. Ответ таков: когда выполнено, по крайней мере, одно из следующих условий:
- на основе этого элемента/атрибута будет строиться индекс;
- данный элемент/атрибут должен отображаться на внешний источник данных или на серверное расширение;
- на основе этого элемента/атрибута будут определены эксклюзивные права доступа;
- наличие/множественность элемента являются вынужденными;
- одно из перечисленных выше условий выполняется для потомка элемента.
Модель информационного наполнения может быть объявлена «закрытой». Тогда схема Tamino должна полностью описывать структуру документов.
Как следствие использования открытой модели информационного наполнения, документы могут сохраняться, даже если в Tamino декларации схемы нет вообще.
Комментарии и команды обработки могут добавляться практически в любое место документа без предварительного декларирования в схеме. Они игнорируются при проверке соответствия схеме Tamino, но сохраняются в документе.
Методы индексации и хранения
Индексы абсолютно необходимы в системах управления базами данных, поскольку в противном случае невозможно приемлемым образом обрабатывать запросы, обращенные к огромным объемам информации. Какого рода индексы имеет смысл использовать при обработке запросов к XML-документам?
Во-первых, существуют индексы по значениям, хорошо известные по традиционным СУБД. Их можно использовать для ускорения поиска определенных значений атрибутов или информационного наполнения элементов. Определение этих индексов должно четко указывать объект данных, на который оно ссылается. Имена элементов и атрибутов в DDT не обязательно должны быть уникальными. Рассмотрим определения из DTD, которые могут быть сформулированы для путеводителя по достопримечательностям.
Элемент с именем Name («Название») встречается несколько раз, на разных уровнях иерархии и с различной семантикой: название города или название памятника. В данном примере определение индекса должно недвусмысленно указывать элемент Name, расположенный в иерархии ниже City («Город»).
Индекс по Inhabitants («Число жителей») может оказаться полезным для ускорения поиска в городах определенного размера или для сортировки городов в зависимости от числа жителей. Однако, как показывает пример, DTD не содержит информации о том, что Name — это цепочка символов, а Inhabitants — число. Эта информация, тем не менее, необходима для создания содержательного индекса.
«Классические» индексы полезны, в частности, для поддержки ориентированного на данные представления о XML-документах, однако индексация текста требует представления, ориентированного на документы. Имеет смысл ограничить сферу действия индексации текста конкретной частью документа, с другой стороны, сфера действия, как показывает следующий пример, может адекватно отражать информационное наполнение элементов. Рассмотрим следующую часть документа XML со смешанным информационным наполнением.
Harald> Schoning XML and XSL are very important
Индексация текста должна позволять находить цепочки «XML» и «XSL», а также фразу «very important» («очень важно»). Она также должна позволять определять текстовый индекс имени автора таким образом, чтобы можно было, к примеру, найти текст Harald Schoning («Харальд Шонинг«).
Наконец, структура XML-документа важна для определенных типов запросов. В частности, если множественность, определенная в DTD, разрешает пропускать элементы, или, если не известно DTD, запросы с учетом структуры имеют смысл. Например, в базе данных всех городов Европы, имеет смысл искать все такие города, в которых есть элемент, называемый beach («пляж»). Такого рода запросы поддерживаются с помощью выделенного структурного индекса в Tamino.
СУБД Tamino поддерживает три указанных типа индексации. Ее язык схем позволяет точно определить сферу действия индексации.
Запросы к XML-документам
Рекомендация XML [2] не рассматривает вопросы, связанные с одновременной обработкой нескольких XML-документов. Не существует стандартного языка запросов для XML (хотя есть немало предложений). Однако как часть рекомендации XSL определен язык XPath [3], который позволяет выполнять позиционирование в документе. Tamino расширяет семантику Xpath, делая возможным обработку наборов документов. Хотя «навигационный» подход XPath прекрасно соответствует требованиям извлечения информации в среде, ориентированной на данные, для среды, ориентированной на документы, необходимы инструменты извлечения, в большей степени рассчитанные на работу с информационным наполнением. Таким образом, Tamino также поддерживает полнотекстовый поиск по содержимому атрибутов и элементов (в том числе их потомков, игнорируя разметку).
Если запрос возвращает более одного документа (или фрагмента документа), их непосредственное объединение не позволит в результате получить корректный XML-документ, поскольку он должен иметь ровно один корень. В силу этого Tamino дополняет полученный набор «фиктивным» корневым элементом.
Организация хранения
Рекомендация [2] указывает, что процессор XML должен поддерживать работу с записями, комментариями и командами обработки. В случае Tamino, однако пользователям может потребоваться извлекать документы в том же виде, в каком они хранятся, например, с оставленными без изменения комментариями, без указания важности команд обработки и неопределенными ссылками на записи. С другой стороны, пользователи должны иметь основания рассчитывать на то, что результат обработки запросов в Tamino соответствует спецификации процессора XML. Так или иначе, необходимо предоставить пользователю возможность настраивать поведение системы.
Оставление записей неразрешенными (т.е. с неопределенными ссылками), может оказаться некорректным, если результатом запроса является набор (фрагментов) документов. Прежде всего, необходимо включить в результат фиктивное DTD-определение, порождаемое для результатов каждого запроса. В него должны входить все различные декларации записей исходного документа. При том что используется одна и та же ссылка на запись, определение записи от документа к документу может различаться (например, вследствие использования локального DTD). Таким образом, если существует несколько определений для одного и того же имени записи, то записи переименовываются, а ссылки на записи соответствующим образом меняются. Так что оставлять записи неразрешенными в результате запроса смысла не имеет.
Внешние записи, для которых выполнен синтаксический разбор, создают ряд дополнительных концептуальных проблем, если они не разрешены во время сохранения документа, но остаются неизменными в документе. Проблема заключается в том, что эти записи можно изменить так, что СУБД об этом не знает (поскольку они внешние). Поэтому, если результирующий документ все же должен содержать ссылку на внешнюю запись, значения таких записей не должны включаться в индекс. Как следствие, СУБД не может эффективно выполнять поиск значений, содержащих внешние записи. Рассмотрим следующие части XML-документа.
... Todays hot topic: &mysubject
При сохранении соответствующего документа URL-адрес, заданный в определении записи, может указывать на статью о XSLT, но когда документ извлекается, URL уже может указывать на анонс о приобретении компании. Таким образом, поиск документов, содержащих выражение «XSLT» не должен в качестве результата выдавать документ, а должен выполнять поиск слова acquisition («приобретение»). Для этого необходимо, чтобы СУБД проверяла текущее содержимое URL внешней записи для каждого запроса так, что в итоге подобный поиск может затянуться надолго.
Реляционные базы данных и XML
Сейчас все основные реляционные и объектно-реляционные СУБД так или иначе поддерживают XML [6-8]. Самая простая форма поддержки XML — генерирация формы XML-документов в существующих реляционных данных. Поддержка XML подразумевает, что XML-данные можно хранить и извлекать. В известных системах реализовано два подхода.
При первом подходе XML-документ отображается на реляционные таблицы и их столбцы. Спецификация отображения определенного вида сообщает СУБД, как создавать строки из XML-документов и наоборот. При сохранении разметка игнорируется и восстанавливается при извлечении. В IBM DB2 [8] этот подход называется XMLCollection. Преимущество такого подхода состоит в том, что информационное наполнение XML-документа может обрабатываться с помощью традиционного языка запросов SQL и может использоваться в приложениях на базе SQL. Однако у этого подхода есть свои недостатки.
При отображении XML-документа на множество строк информация о последовательности элементов в оригинальном XML-документе обычно утрачивается. Рассмотрим следующий документ.
Его содержимое можно отобразить на две таблицы — Order и Orderline. Спецификация этого отображения должна создавать значение внешнего ключа для всех строк Orderline. При этом обычно не генерируется никаких указаний, в какой из позиций запись Orderline находилась в исходном документе. Таким образом, при извлечении порядок в результате может быть следующим.
В ориентированных на данные материалах последовательность, как правило, не имеет значения, однако для материалов, ориентированных на документы, она может оказаться важной. Представьте себе пьесу Шекспира, в которой перепутаны строки. Более того, при таком подходе теряются все комментарии и команды обработки, которые могли содержаться в исходном документе. Кроме того, смешанное информационное наполнение в этой модели сохранить не так просто.
С помощью данного метода могут быть сохранены только те документы, чья структура известна заранее. Обобщенное отображение на таблицы и столбцы в том виде, как оно описано в [9], преодолевает это ограничение, но производительность в этом случае оказывается очень низкой. Кроме того, таблицы, применяемые для столь общего отображения, для пользователя реляционной системы бесполезны.
При втором подходе XML-документ остается нетронутым и сохраняется в большом текстовом поле (BLOB) или даже вне базы данных. В DB2 такой подход называется XMLColumn. В таких полях текстовый поиск возможен даже в случае, если СУБД не поддерживает все возможности XML. Как правило, можно указать определенное текстовое условие на контекст элемента, например, найти документы, где слово Hamlet («Гамлет») встречается в элементе Speakers («Выступающие»), но сочетание, учитывающее структуру, например, найти документы, где Гамлет говорит в сценах с заголовком, содержащим слово Polonius («Полоний»), невозможно.
Поиск по значению в этих текстовых полях не поддерживается. Рассмотрим приведенный выше документ и запрос «Найти все заказы, в которых требуется более 5 копий элемента». Текстовый поиск не даст ответа на этот вопрос. Чтобы преодолеть это ограничения, DB2 предлагает так называемые побочные таблицы, в которых хранятся значения, встречающиеся в документах. В спецификации отображения можно указать, какое содержимое элемента или значение атрибута передается в побочную таблицу. При этом необходимо знать, какие побочные таблицы существуют, чтобы задать указанный выше запрос; если же побочная таблица для атрибута quantity не была определена, пользователя ждет неудача. Более того, непосредственная работа с побочными таблицами разрушает согласованность базы данных.
Кроме того, защита может быть определена только на уровне документа — реляционная модель не позволяет задавать ограничения на отдельных элементах, но для SQL весь документ — суть один столбец.
Выводы
При проектировании СУБД Tamino особое внимание было уделено XML-функциям, которые плохо подходят миру классических баз данных. В частности, рассматривались вопросы поддержки схем и обработки запросов.
Поддержка схем для XML требует подхода, который отличается от того способа, который применяется для поддержки схем в реляционных базах данных. Нельзя рассчитывать на то, что всегда существует единообразная схема.
Как аспект поддержки DTD записи должны рассматриваться системой управления XML-базой данных. Внешние записи вызывают концептуальные проблемы.
Классические индексы на базе значений полезны для XML, но при этом необходимы и другие типы индексов (текстовый индекс, структурный индекс).
Комментарии и команды обработки могут появляться в любом месте документа. Хотя они не описываются в схеме, они должны фиксироваться при сохранении документа.
Результат запроса, обращенного к XML-базе данных, должен быть XML-документом, либо в виде полного документа, который сохраняется, либо в виде набора результатов, состоящего из фрагментов XML-документов.
Tamino, система управления XML-базами данных компании Software AG, реализует все эти методы, при этом избавлена от ограничений, присущих при поддержке XML классическими реляционными системами.
Литература
[1] R. Bourret, XML and Databases, 1999,2000: www.rpbourret.com/xml/XMLAndDatabases.htm
[2] Extensible Markup Language (XML) 1.0, W3C Recommendation 1998-10-February, www.w3.org/TR/1998/REC-xml-19980210
[3] XML Path Language (XPath) Version 1.0, W3C Recommendation 1999, 16 November www.w3.org/TR/xpath
[4] H. Schoning, J. Wasch: Tamino — An Internet Database System, in: Advances in Database Technologies — EDBT 2000, LNCS 1777, Springer Verlag
[5] J. Shanmugasundaram, et al: Relational Databases for Querying XML Documents: limitations and Opportunities, in: Proc. 25th VLDB Conference, Edinburgh, Scotland, 1999
[6] Oracle XML Developer?s Kit, technet.oracle.com/tech/xml
[7] SQL Server 2000, www.microsoft.com/SQL
[8] DB2 XML Extender, www-4.ibm.com/software/data/db2/extenders/xmlext
[9] D. Florescu, D. Kossmann: A Performance Evaluation of Alternative Mapping Schemes for Storing XML Data in a Relational Database, Rapport de Recherche No. 3680, INRIA, Rocquencourt, France, 1999 May
Харальд Шонинг (Harald.Schoening@softwareag.com) — сотрудник компании Software AG.
Harald Schoning. Tamino — a DBMS Designed for XML. Translated from the original English version and reprinted with permission, from Proceedings of the 17th International Conference on Data Engineering. Copyright 2001, IEEE.
