

Статья содержит обзор современного состояния СУБД IBM DB2 с точки зрения интеграции классических и новых технологий в едином инструментарии управления данными. Особое внимание уделяется серверу баз данных DB2 Universal Database v.7 — ключевому программному продукту для хранения и обработки данных в решениях от IBM.
Когда в конце 70-х создавалась СУБД System R, ее разработчики из IBM в качестве главной своей цели определили простоту и удобство использования данных. Продумывая архитектуру системы, они одновременно ориентировались на поддержку запросов произвольного вида и на обработку потока многочисленных коротких стандартных изменений в базе данных. Иначе говоря, на те области применения, которые сегодня можно назвать «информационно-аналитические задачи и приложения оперативной обработки данных». Родоначальница современных серверов реляционных баз данных, System R стала источником языка SQL и предшественником современной СУБД DB2.
Рассматривая внутреннюю архитектуру современных серверов баз данных, легко заметить, что в них присутствуют все те же базовые элементы, заложенные когда-то в System R ее создателями. Среди них: механизмы исполнения транзакций, механизмы конкурентного доступа к данным, архитектурное разделение системы на подсистемы разбора непроцедурных запросов и подсистему непосредственного доступа к данным, разнообразные методы оптимизации запросов, индексирования данных и увеличения производительности. В то же время внешняя функциональность и внутренняя реализация современных серверов баз данных, в том числе и DB2, претерпели значительные усовершенствования.
Сегодняшние СУБД характеризуются новыми сферами применения, увеличением объемов данных, разнообразием их типов, многообразием источников и их распределенностью, усложнением самих методов обработки данных. Современные серверы баз данных вобрали в себя массу технологий. Что же стоит за подобным разнообразием: органичное ли это здание на фундаменте единой архитектуры или механическая упаковка компонентов?
Интеграция новых функций и компонентов может принимать форму различных архитектур с разной ролью, которая отводится серверу баз данных. Многозвенная архитектура серверов приложений предлагает пользователю свои специальные интерфейсы и оставляет СУБД роль системы ресурсов заднего плана. В других решениях сама СУБД берет на себя роль шлюза доступа к разнообразным ресурсам и предоставляет пользователям язык запросов SQL или его расширения, представляя внешние ресурсы, как свои собственные. Наконец, существует подход, предполагающий действительное встраивание новых функций в сервер баз данных.
Универсальный сервер баз данных
Ориентация на концепцию универсального инструментария хранения и обработки данных требует от сервера СУБД, во-первых, базовой архитектуры достаточно гибкой и мощной, чтобы отвечать постоянно растущим требованиям к производительности и функциональности, во-вторых, естественного и гармоничного расширения функциональных возможностей, добавления компонентов, интерфейсов, инструментов. Первое направление реализуется в DB2 в виде параллельной обработки данных, второе привело к развитию объектно-реляционных возможностей.
Объектно-реляционная архитектура DB2
Одна из основных особенностей DB2 Universal Database — расширяемость ее типов. Под расширяемостью в данном случае подразумевается способность хранить и оперировать не только традиционными реляционными таблицами с символами и числами, но и мультимедийными данными, комплексными объектами (документы, изображения, аудио, видео, пространственные данные, временные ряды и т.д.). Кроме того, можно манипулировать и специфическими для конкретной отрасли объектами. Основа для реализации такой функциональности — так называемая объектно-реляционная архитектура DB2, позволяющая добавлять собственные типы данных и деловые функции. IBM реализовала такую возможность еще в 1995 году в DB2 Common Server v.2.
Опыт эксплуатации реляционных баз данных привел в свое время к появлению поколения так называемых расширенных реляционных баз данных. К этой категории относятся системы, поддерживающие ряд дополнительных возможностей, выходящих за рамки реляционной алгебры: триггеры, хранимые процедуры, контроль целостности и т.д. Целью исследовательского проекта IBM Starburst в конце 80-х годов было создание расширяемой системы, где под расширяемостью понималась органическая возможность поддерживать новые методы хранения данных, добавлять новые методы доступа, предоставлять пользователям возможность определять свои операции над данными и встраивать новые методы оптимизации. Практическим результатом проекта Starburst и последующего проекта Starwings было появление в 1993 году СУБД DB2 Common Server для платформ Wintel и Unix. В DB2 Universal Database поддерживается целый ряд ключевых объектно-реляционных возможностей (все они соответствуют стандарту SQL3 и поэтому реализуют открытый, а не внутрикорпоративный подход).
Расширяемая система типов предполагает поддержку определяемых пользователями типов данных (UDT — user-defined type), включая структурированные типы с наследованием, с возможностями использовать строковые типы, идентификаторы объектов и ссылки. Определяемые пользователем типы данных, как и встроенные, могут использоваться в качестве столбцов таблиц или параметров функций.
Определяемые пользователем функции (UDF — user-defined function) позволяют включать в запросы вычислительные и поисковые методы. DB2 предлагает для реализации UDF на выбор языки программирования Cи, Java или механизм OLE. Кроме того, можно назначить исполнение UDF внутри или вне серверных процессов менеджера базы данных. Благодаря UDF можно создать наборы функций для работы с пользовательскими типами, определив их семантику. SQL-оптимизатор учитывает семантику и стоимость исполнения пользовательских функций, что позволяет работать с этими функциями абсолютно аналогично встроенным функциям. Механизм пользовательских функций DB2 достаточно мощный, особенно учитывая возможность исполнять функцию внутри серверного процесса, что позволяет встраивать в сервер баз данных так называемые тесносвязанные компоненты. По сравнению с компонентами, встраиваемыми при помощи стандартного SQL-доступа, тесносвязанные компоненты обеспечивают более высокую производительность.
Поддержка больших двоичных объектов (LOB) позволяет хранить в базе данных крупные двоичные или текстовые объекты размером в несколько гигабайт, что полезно для хранения мультимедийных данных. Кроме того, большие объекты можно использовать для хранения небольших структур, семантика которых задана с помощью пользовательских типов и функций. Для больших объектов имеется мощный набор встроенных функций выполнения поиска, выделения части объекта и конкатенации. С помощью механизма UDF в любое время можно определить дополнительные функции.
Определяемые пользователем табличные функции (Table UDF) позволяют включить данные из нереляционных источников в реляционную обработку. Табличная функция представляет собой внешнюю определяемую пользователем функцию, результатом исполнения которой является создание производной таблицы. Такая функция может включать в себя обращение к данным из различных источников и преобразование их в табличную форму. После создания Table UDF на нее можно указывать в запросах как на таблицу. Табличные функции могут применяться не только для включения внешних данных в обработку с помощью средств SQL, но и для постоянного ввода внешних данных в реляционные таблицы.
С помощью механизма деловых правил в базе данных можно определить комплексные правила для поддержки целостности данных. Ключевые возможности деловых правил: установка значений по умолчанию, проверка ограничений и ссылочной целостности и активный механизм триггеров. Эти правила дополнительно расширяют объектно-ориентированные возможности; с их помощью можно расширить функции, существующие только в виде неизменяемого кода.
Расширения DB2 Extenders
На основе объектно-реляционной инфраструктуры DB2 построены специализированные расширения DB2 Extenders. Каждое расширение представляет собой набор предопределенных пользовательских типов UDT, пользовательских функций UDF, триггеров, ограничений и хранимых процедур, решающих задачи определенной прикладной области. С помощью стандартных расширений пользователи могут хранить в таблицах DB2 текстовые документы, изображения, видео- и аудиоролики. Собственно данные могут храниться как внутри таблицы, так и вне нее во внешних файлах. Кроме того, новые типы данных имеют атрибуты, описывающие различные аспекты их внутренней структуры, такие как, например, «язык» и «формат» для текстовых данных. Каждое расширение включает необходимые функции для создания, обновления, удаления и поиска данных с новыми типами, определенными в расширении. Пользователи могут включать эти новые типы данных и функции в операторы SQL, обеспечивая интегрированный поиск по содержимому для всех типов. Серверы DB2 стандартно комплектуются расширениями для работы с текстом, изображениями, аудио и видео информацией, к которым в седьмой версии добавляются XML, Spatial, Intelligent Miner Scoring и Net.Search.
Текстовое расширение Text Extender позволяет использовать в SQL-запросах средства полнотекстового поиска. DB2 может хранить сами текстовые документы объемом до 2 Гбайт, а также ссылки на внешние файлы. Text Extender предоставляет метод поиска в таких документах. Технология TextExtender позволяет определить для текстовых столбцов баз данных различные типы индексов, в том числе для поиска по точному совпадению, для лингвистического поиска, для нечеткого поиска при помощи так называемых индексов Ngram. Среди словарей, стандартно входящих в Text Extender, есть словарь и для русского языка.
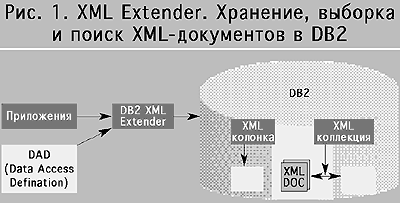
Использование XML становится все более важным для организации обмена данными между различными приложениями. Хотя текстовое расширение Text Extender поддерживает обработку XML-документов, целый ряд дополнительных функций предлагается новым расширением XML Extender, стандартно входящим теперь в состав сервера DB2. Это расширение позволяет хранить, искать и выбирать в базе данных XML-документы, которые могут быть сохранены в DB2, в одном столбце специального XML-типа или как коллекция элементов, распределенных между несколькими столбцами и таблицами (рис. 1). В XML Extender входит графический административный компонент для визуального определения соответствия между элементами XML-документа, таблицами и столбцами DB2. Специальные хранимые процедуры и триггеры XML Extender используются для преобразования XML-документов в коллекции данных в DB2 и, наоборот, при формировании таких документов. DB2 UDB также поддерживает специальную индексацию и функции поиска в XML-документах.
Для управления геоинформационными данными обычно используются специализированные системы, которые ограничены в возможностях интеграции геоинформационных данных с традиционными. В то же время существует значительное число прикладных задач, требующих подобной интеграции. Базы данных многих производителей могут поддерживать хранение геоинформационных данных в виде больших двоичных объектов (LOB), что позволяет использовать СУБД для хранения, но не позволяет эффективно применять поисковые средства СУБД. Кроме того, геоинформационные системы могут хранить часть своих данных стандартных типов в таблицах реляционной базы данных. Подход, который совместно с компанией ESRI реализован в DB2 Spatial Extender, предполагает, что геоинформационные данные становятся новыми типами в объектно-реляционной базе. Подход основан на использовании поддерживаемых DB2 абстрактных типов с подтипами и наследованием вместе с определяемыми пользователями функциями. Spatial Extender использует предопределенные геоинформационные типы данных, операции с этими данными, специальные механизмы индексирования и оптимизации запросов. При запросах к геоинформационным данным можно использовать все средства SQL, а также ряд специальных функций, реализующих операции преобразования, сравнения, измерения. Кроме объектно-реляционного подхода, Spatial Extender поддерживает хранение данных в соответствии со спецификацией Open GIS Consortium в текстовом и двоичном видах. DB2 Spatial Exender позволяет пополнять базу геоинформационных данных путем выборки из описательной информации, генерации новых сведений с помощью операций над уже имеющимися геоинформационными данными, импорта из внешних источников в различных форматах.
Параллельная база данных
Сегодняшняя индустриальная СУБД должна уметь разделять запрос на отдельные подзадачи и параллельно исполнять их на нескольких процессорах. Архитектура DB2 UDB поддерживает параллельное исполнение большинства операций, включая запросы, вставку, обновление и удаление данных, создание индексов, загрузку и экспорт данных. DB2 UDB была специально разработана для работы на параллельных системах архитектур MPP (массовый параллелизм) и SMP (симметричная многопроцессорность).
Концепцию параллельной базы данных реализует версия DB2 UDB Enterprise Extended Edition (EEE). В отличие от стандартной версии, EEE обладает возможностью распределения данных по разделам (узлам). В каждом разделе базы данных один менеджер базы является ответственным за свою порцию данных. Факт, что данные реально распределены между разделами, остается скрытым для пользователей и приложений. В каждой распределенной базе данных есть один раздел, на котором была выполнена команда на создание базы; этот раздел ведет системный каталог для всей базы и называется каталоговым узлом (catalog node). Взаимодействие пользователя с базой может происходить через любой раздел, к которому он подсоединен; этот раздел выступает для пользователя координирующим (coordinator node).
DB2 UDB EEE распараллеливает исполнение большей части своих команд; операторы SELECT, INSERT, UPDATE и DELETE исполняются параллельно на разделах базы данных. Все активности менеджера базы данных: сканирование данных, индексирование, соединения, создание и реорганизация данных и исполнение утилит — могут выполняться параллельно на всех разделах. В частности, загрузку очень больших объемов данных можно выполнить на параллельной базе намного быстрее, чем на обычной. При росте числа пользователей или объема данных, параллельная СУБД может быть расширена путем добавления к системе новых серверов и определения на них новых разделов. EEE предоставляет средства для автоматизированного перераспределения данных на новый узел и балансировки нагрузки.
Для распределения данных по разделам EEE использует технологию хеширования (hashing). Если необходимо распределить между несколькими узлами обработку большой таблицы, для этого выделяется группа разделов и определяется ключ распределения. Внутренне DB2 создает карту распределения, играющую основную роль при хешировании. При загрузке или вставке новых данных СУБД определяет, в какой раздел попадут записи в соответствии со значениями ключевых полей новых данных и картой распределения.
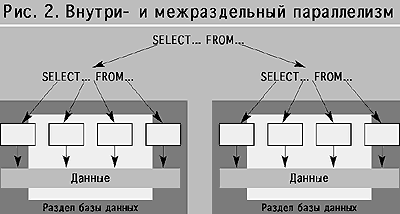
При исполнении запроса оптимизатор DB2 UDB решает, выполнять ли запрос параллельно и какие стадии исполнения будут распараллелены. Решение основывается на возможностях аппаратного обеспечения (числе процессоров, узлов, дисков), параметрах конфигурации, информации о распределении данных и сложности запроса. Внутрираздельный параллелизм (рис. 2) означает, что исполнение будет распределено между ресурсами одного экземпляра менеджера баз данных на разделе. Межраздельный параллелизм предполагает участие нескольких разделов, например, когда исполнение запроса требует данных из таблиц, расположенных на нескольких разделах. Тогда координирующий узел будет рассылать запрос на выполнение операций по разделам (function shiping). Менеджер данных на каждом разделе будет сканировать, сортировать, отбирать свои данные и, наконец, отсылать отобранные данные обратно координирующему узлу. На координирующем узле после окончательной обработки данные будут отправлены запросившему их приложению.
Федеративная база данных
Достаточно часто случается, что необходимая информация хранится в нескольких совершенно различных базах или часть информации находится в файловой системе, либо вообще недоступна для непосредственного доступа с сервера баз данных. Целый ряд технологий совместно позволяют реализовать на СУБД DB2 концепцию федеративной базы данных, работающую с разнообразными распределенными источниками данных многих типов. Эта концепция предусматривает и логическую интеграцию данных, когда пользователь имеет единый доступ ко всей совокупности данных, в том числе и внешних, и физическую интеграцию, предполагающую сбор и перемещение данных на платформу исполнения.
Общий подход к интеграции разнородных систем и приложений, предлагаемый технологиями IBM, предполагает использование промежуточного программного обеспечения, которое берет на себя разрешение проблем взаимодействия приложений. Среди разнообразных архитектур промежуточного слоя можно назвать MQSeries — систему управления очередями сообщений, предоставляющую механизмы гарантированной кроссплатформенной доставки данных и интеграции разнородных приложений. Промежуточное хранение передаваемых сообщений в очередях позволяет реализовать асинхронную промежуточную обработку. DB2 UDB обладает возможностями участия в распределенной транзакции между базой данных и очередями сообщений MQSeries, что позволяет координировать состояние внутренних ресурсов базы с данными, поступающими или отправляемыми в виде сообщений во внешние системы. Последний выпуск DB2 UDB v7.2 предоставляет новые расширения для пользователей DB2, позволяющие использовать в SQL-операторах пользовательские функции посылки и приема сообщений, функции групповой обработки сообщений, публикации сообщений по определенной теме и доступ к содержимому очередей сообщений с помощью специальных представлений.
Для доступа к гетерогенным базам данных разработана технология DB2 DataJoiner, обеспечивающая использование единого диалекта SQL при работе с СУБД разных производителей: Oracle, Informix, Microsoft SQL Server, Sybase и источниками ODBC. Эта технология, реализованная в виде компонента DB2 Relational Connect, обладает возможностями исполнения распределенного запроса, включающего таблицы из нескольких источников. Кроме того, DB2 UDB может выступать как OLE DB-источник данных, а также через свои скалярные и табличные функции и хранимые процедуры, предоставляя доступ к другим OLE DB-источникам. С помощью этих функций внешние данные из OLE-серверов могут использоваться в SQL-запросах к DB2.
Несмотря на широкое распространение серверов реляционных баз данных, большая часть данных по-прежнему хранится в виде файлов. Хотя эти данные могут быть перенесены в СУБД в форме больших двоичных объектов, часто есть много причин для их сохранения в виде файлов. Поскольку файловая система не обладает многими возможностями СУБД по исполнению транзакций, контролю целостности, восстановлению, для DB2 UDB была разработана технология DataLinks. Ее задача — предоставить приложениям, использующим работу с файловой системой доступ к поисковым возможностям СУБД и внешним данным для SQL-ориентированных приложений. DataLinks предоставляет несколько уровней контроля для внешних данных, включая контроль доступа, ссылочную целостность, координацию при сохранении и восстановлении данных и целостность транзакций.
Когда изначально DB2 появилась на мэйнфреймах в средах MVS, VM, VSE она была ориентирована на централизованные приложения для хостов. При этом поддержка обращений удаленных пользователей возлагалась на промежуточное ПО наподобие менеджера транзакций CICS. Впоследствии, в условиях популяризации архитектуры клиент-сервер, потребовалась дополнительная поддержка прямого удаленного доступа с ПК и Unix-станций к базам данных на мэйнфреймах и системах типа AS/400. Для этого была предложена открытая спецификация DRDA (Distributed Relational Database Architecture), описывающая протоколы взаимодействия удаленного клиента с базами данных. Реализация DRDA должна была позволить продуктам разных производителей баз данных прозрачно взаимодействовать, в частности, образуя единую распределенную базу. Подход DRDA позволяет решить многочисленные проблемы кросс-платформного взаимодействия, в частности, конвертацию данных ASCII и EBCDIC, различия в диалектах SQL, командах, типах данных и строении каталогов. Сегодня архитектуру DRDA поддерживают все серверы семейства DB2, а многие другие производители реализовали так называемые DRDA-реквесторы, которые позволяют прикладным программам-клиентам обращаться к базам DB2 на хостах, в частности, к DB2/390 и DB2/400. Типичный пример такого DRDA-реквестора производства IBM — DB2 Connect, работающий в средах OS/2, Linux, Windows NT/2000, IBM AIX, Sun Solaris, и который может служить многопользовательским шлюзом к DB2 на хостах для множества пользователей локальной сети, или, в случае однопользовательского варианта, работать на компьютере клиента.
Вывод в Internet корпоративного бизнеса приводит к формированию новой концепции базы данных. Современная СУБД должна предоставлять пользователям Internet доступ к существующим базам данных, а с другой стороны база данных может быть специально предназначена для обслуживания Internet-приложений. В составе DB2 UDB имеются два компонента для доступа через Сеть: Net.Data и WebSphere. Кроме того, поддерживаются интерфейсы и средства разработки для языка Java, а ряд расширений DB2 Extenders ориентированы на использование в Сети.
Net.Data — компонент для Web-сервера, поддерживающий взаимодействие между ним и СУБД DB2 (рис. 3). В основе программирования для Net.Data лежит создание макросов, которые получают через HTML-формы параметры для запроса от Web-сервера, динамически генерируют и передают запросы к DB2 UDB. Когда Net.Data получает результаты запросов, происходит формирование ответа в виде HTML-страницы, возвращаемой пользователю. Кроме очевидного преимущества ускорения процесса разработки приложений для Web-сервера, Net.Data может поддерживать пул постоянных соединений с DB2 и тем самым снизить затраты на переустановку соединений.
Потребность в использовании Java для Internet-приложений привела к целому ряду дополнений, интерфейсов и компонентов для серверов баз данных. Кроме ставшего обычным интерфейса JDBC, в DB2 UDB поддерживается язык SQLJ (т.е. встроенный в Java язык SQL-запросов), что позволяет использовать «настоящий» статический SQL, когда результаты предкомпиляции SQL-запросов хранятся в сервере баз данных, что обеспечивает более высокую производительность, чем при динамическом исполнении. DB2 UDB дает возможность также писать хранимые процедуры и пользовательские функции на Java.
Исполнение приложений на Internet-серверах увеличило роль серверов приложений. IBM WebSphere — группа инструментальных средств разработки и исполнения приложений на Web-сайтах. В основе лежит сервер приложений WebSphere Application Server, поддерживающий технологии Java Server Pages, сервлетов, Enterprise JavaBeans и CORBA и поставляемый вместе с IBM HTTP Server, созданным на базе Apache.
От хранилищ к раскопкам данных
На решение задачи детального анализа накопленных данных с последующим формированием решений на его основе нацелено целое направление современной программной индустрии, так называемые средства «бизнес-интеллекта» (BI — business intelligence).
Поддержка очень больших баз данных
Анализ данных требует использования консолидированных наборов из многочисленных оперативных источников, объединенных в хранилище, а поскольку хранилища призваны хранить большие и очень большие объемы данных, то для СУБД основными становятся требования высокой производительности и масштабирования. Кроме того, опыт применения хранилищ указывает на тенденцию использования очень сложных запросов для построения отчетов и анализа. В основе DB2 UDB лежат несколько ключевых технологий по поддержке хранилищ больших объемов: расширяемый оптимизатор запросов, технология распараллеливания операций, специальные функции для поддержки онлайновой аналитической обработки, а также инструментальные средства администрирования очень больших баз.
Существенная особенность DB2 UDB — создание и хранение промежуточных агрегаций. Администратор базы может предопределить наборы соединений и агрегаций в форме так называемых таблиц автоматических суммирований (AST — automatic summary table). Использование таблицы суммирований позволяет быстрее, часто в несколько раз, исполнять запросы. При этом для пользователя не требуется вносить изменения в форму запроса — оптимизатор знает и учитывает существование таблиц суммирований. Поддержание таблиц суммирований в актуальном состоянии может выполняться при использовании различных сценариев с немедленными или отложенными обновлениями.
Построение хранилища данных
В свое время в IBM был разработан специальный пакет для построения и администрирования хранилищ данных — VisualWarehouse, который в седьмой версии интегрирован в DB2 Universal Database. Сейчас в составе всех серверных продуктов семейства DB2 UDB включается Data Warehouse Center — облегченная версия DataWarehouse Manager, с помощью этого менеджера администратор имеет возможность шаг за шагом, с единой графической консоли выполнять операции с хранилищем.
DataWarehouse Manager может получать данные из DB2, других баз и файлов различных форматов (рис. 4). DataWarehouse Manager обладает рядом технологий, которые позволяют эффективно организовать управление хранилищем, в частности: архитектурой на базе распределенных агентов, использованием технологических и деловых метаданных, возможностями вызова написанные пользователем или третьими фирмами компонентов для дополнительной обработки данных. Архитектура DataWarehouse основана на использовании агентов, работающих на различных платформах и управляемых из единого центра DataWarehouse Manager. Агенты занимаются преобразованием и передачей данных. В отличие от альтернативных продуктов, DataWarehouse Manager не требует пересылки данных через центральный промежуточный сервер, что может быть причиной снижения производительности.
DataWarehouse Manager содержит административные компоненты, отвечающие за безопасность и авторизацию, процедуры сохранения и восстановления, мониторинг и настройку, планирование и выполнение операций, представляя полное решение для управления хранилищем данных. Интеграция DataWarehouse Center и компонента для OLAP-анализа DB2 OLAP Starter Kit в одном пакете позволяет через DataWarehouse Center загружать данные в многомерные базы и автоматически выполнять при загрузке предварительные вычисления и агрегации данных. Полнофункциональный DB2 Warehouse Manager по сравнению с DataWarehouse Center включает ряд дополнений, в том числе дополнительных агентов для ряда платформ, дополнительные программы-«трансформеры» — для очистки и закачки данных, и, наконец — Information Catalog, предназначенный для публикации информации о данных, содержащихся в хранилище.
Information Catalog представляет собой репозиторий метаданных, открытый для конечных пользователей, синхронизуемый с хранилищем и обладающий возможностями обмена метаданными с аналитическими средствами третьих фирм. Information Catalog предоставляет конечным пользователям возможность искать необходимую информацию в хранилище, получать описание данных в деловых терминах, получать доступ при помощи различных графических средств или через Internet.
DataWarehouse Manager поддерживает предложенную ассоциацией Metadata Coalition спецификацию Metadata Interchange Specification (MDIS) для обмена метаданными с другими программными средствами. Например, компания ETI предлагает набор инструментальных средств EXTRACT Tool Suite для создания приложений, занимающихся выборкой и преобразованием данных. IBM совместно с ETI интегрирует EXTRACT с DataWarehouse Manager путем обмена метаданными, исполнения программ EXTRACT под управлением DataWarehouse Manager и использования библиотек ETI для доступа к дополнительным источникам данных, таким как SAP R/3.
Система DB2 Query Patroller позволяет администратору управлять средой исполнения запросов. Query Patroller действует как агент в интересах конечного пользователя. Когда конечный пользователь через прикладную программу, например, генератор отчетов, отправляет запрос на исполнение, запрос попадает в среду Query Patroller, где происходит анализ стоимости исполнения запроса по ресурсам. Затем устанавливаются приоритеты и составляется расписание исполнения запросов наиболее эффективным образом (запрос может исполняться немедленно или сохраняется для последующего исполнения). Результаты могут храниться в виде промежуточной выборки для последующего возвращения пользователю.
OLAP-анализ и поиск закономерностей
Основным продуктом IBM в категории средств оперативной аналитической обработки является DB2 OLAP Server, в котором реализована трехзвенная архитектура клиент-сервер (рис. 5). На среднем уровне располагается собственно OLAP-сервер, разработанный совместно с Hyperion Solutions на базе продукта Essbase, и отвечающий за оперативную аналитическую обработку многомерных данных. В качестве менеджера хранения могут выступать реляционная СУБД DB2 или специализированная многомерная MD Essbase.
В качестве клиентских компонентов и API-интерфейса DB2 OLAP Server поддерживает те же модули, что и Hyperion Essbase, что расширяет для него базу инструментальных средств и готовых пакетов.
Одним из направлений развития СУБД является интеграция функций OLAP в ядро реляционной СУБД. При этом к данным могут применяться и средства OLAP, и SQL-запросы. DB2 UDB поддерживает ряд возможностей для функционирования OLAP-расширения, в том числе динамические битовые индексы, данные в звездообразной схеме, специальные классы cube и rollup, таблицы автоматических суммирований и агрегаций. Работая с DB2, можно группировать и агрегировать различными способами столбцы в результирующей выборке данных, используя в запросе классы ROLLUP и CUBE.
Направление раскопки данных (data mining) объединяет целый класс технологий для сложного анализа данных и поиска в них скрытых закономерностей. В системе IBM Intelligent Miner предусмотрено несколько технологий сложного анализа и поиска данных, в том числе статистические методы, кластеризация баз данных, генерация ассоциативных правил, выявление временных последовательностей, построение классифицирующих моделей на базе нейронных сетей и др. Многие алгоритмы Intelligent Miner обладают способностями для автоматической генерации гипотез о данных и получении качественных оценок. Средства визуализации позволяют представлять полученные результаты конечным пользователям, а система открытых API-интерфейсов позволяет интегрировать Intelligent Miner с другими средствами поддержки решений и создавать прикладные системы, использующие сложные алгоритмы поиска. Значительным шагом является интеграция алгоритмов раскопки данных непосредственно в сервер баз данных. Расширение DB2 Intelligent Miner Scoring позволяет стандартному серверу DB2 выполнять сложный анализ данных. В качестве стандартного сценария использования Intelligent Miner Scoring, предусматривается, что описание классифицирующей модели или процедуры кластеризации может быть сделано в IBM Intelligent Miner или в аналитическом пакете от третьей фирмы, а модели и поисковые процедуры задаются в виде языка PMML (Predictive Modeling Markup Language) на базе XML.
Особенности архитектуры DB2
Интеллектуальный оптимизатор запросов
Оптимизатор располагает информацией о среде и физическом распределении данных и должен принимать решение о способе исполнения запроса. В свое время IBM в рамках проекта Starburst сделала значительные инвестиции в теоретическую и практическую разработку стоимостного оптимизатора запросов к базам данных. Результатом стал расширяемый оптимизатор для DB2 UDB. Возможности расширять семантику оптимизатора позволяют дополнять его новыми функциями SQL, различными формами распараллеливания запросов или новыми индексными методами доступа к данным.
Оптимизатор DB2 использует несколько основных технологий, в том числе переписывание запроса, когда используя различные подстановки, исключения и преобразования происходит трансформация исходного запроса к более эффективной, но эквивалентной форме. В частности, при переписывании запроса учитываются преимущества технологии таблиц автоматических суммирований. Кроме того, оптимизатор учитывает семантику ограничений ссылочной целостности и триггеров при преобразовании запроса.
Оптимизатор выполняет анализ запросов с точки зрения оценки их стоимости, сравнивая различные методы доступа к данным и выбирая наиболее эффективный. Оптимизатор использует информацию о том, как базовые таблицы и таблицы промежуточных результатов распределены по системе, оценивает различные параллельные методы соединения таблиц и выбирает наилучшую стратегию исполнения. В результате оптимизатор определяет наилучший план доступа, который может быть визуализирован при помощи такого инструмента, как DB2 Explain.
Хранимые процедуры
Использование хранимых процедур повышает общую производительность СУБД при сокращении объема пересылаемых по сети данных и обеспечивает для пользователей среду исполнения программируемой логики на сервере. Хранимые процедуры для DB2 UDB могут быть написаны на многих языках программирования, в том числе на Java, процедурном варианте SQL, Кобол и Cи.
Графический инструментарий DB2 Stored Procedure Builder генерирует код хранимых процедур на языках Java и SQL и поддерживает полный цикл разработки хранимых процедур, включая создание, модификацию, исполнение и удаленное копирование хранимых процедур. В своих хранимых процедурах DB2 UDB поддерживает статический и динамический SQL, а начиная с седьмой версии для разработки хранимых процедур поддерживается SQL Procedure Language (использование языков программирования в хранимых процедурах обычно усложняет жизнь администраторам, более знакомым с самим SQL). SQL Procedure Language базируется на стандарте ANSI/ISO Persistent Stored Modules и обладает рядом возможностей, включая процедурные расширения к SQL, блочные структуры, обработку исключений и возможность хранить исходный код в базе данных.
Средства администрирования
Главным инструментом администрирования является DB2 Control Center, с помощью которого можно создавать, удалять, модифицировать базы данных, табличные пространства, таблицы, индексы и триггеры и получать информацию об их состоянии и параметрах. Кроме создания и администрирования объектов, Control Center интегрирован в единую среду со SmartGuides, помогающую начинающим администраторам шаг за шагом выполнять задачи сохранения и восстановления базы данных, создания базы, таблиц, табличных пространств и индексов, настройки производительности. Ряд компонентов (Performance Monitor, Event Monitor и Event Analyzer) позволяют выполнять тонкую настройку и мониторинг работы DB2, используются для мониторинга производительности и анализа активности различных объектов базы данных (таблицы, табличное пространство и др.). Visual Explain позволяет исследовать план исполнения запроса — анализировать, каким путем DB2 UDB обращается к данным и обрабатывает их.
Заключение
На сегодняшний день DB2 является одной из ведущих СУБД, позволяющей решать широкий спектр деловых задач. Основная же задача СУБД остается по сути прежней — обеспечение простого и удобного доступа к разнообразным данным. Интегрируя новые технологии с сервером баз данных, DB2 UDB реализует различные архитектурные решения. Происходит и непрерывное развитие функциональности сервера баз данных DB2 путем встраивания новых расширений.
Подход IBM к интеграции компонентов различает слабую и тесную связь с ядром сервера баз данных. Доступ к данным с помощью стандартных средств SQL (клиентский доступ или серверный доступ в форме хранимых процедур) является более надежным и менее производительным, нежели тесная серверная интеграция, например, реализуемая в виде так называемых «неогороженных от серверного процесса» пользовательских функций (non-fenced UDF), подхода более мощного по своим возможностям.
Важнейшим моментом является полнота и актуальность используемых данных; соответственно важно и решение задач интеграции данных. На создание единого логического представления для всего многообразия данных направлена концепция федеративной базы данных с такими компонентами СУБД, как DB2 Relational Connect (DataJoiner), DataLinks, табличные функции.
Николай Игнатович (ignatovich@ru.ibm.com) — эксперт компании IBM East Europe/Asia (Москва).
