
Многие компании и программисты-одиночки пробуют себя на поприще бухгалтерских программ. Таких программ разработано великое множество, каждая из них обладает своими преимуществами, но все они имеют один крупный недостаток – пишутся от бухгалтерии. И в каждой из них прослеживается собственное понимание бухучета тем конкретным специалистом, который ставил задачу, при том, что официальная регламентация данной предметной области далека от совершенства. Цель статьи – попытаться предложить новые методы обработки бухгалтерской информации как технологической основы построения корпоративных информационных систем.
На складе учет материальных ценностей ведется просто: приход, расход, остаток – никакой двойной записи. Книга продаж – также пример учета с одиночной записью. Традиционная бухгалтерия предполагает двойную запись: дебет, кредит. Если бухгалтер оформляет приход на склад каких-то материальных ценностей, то сумма фиксируется дважды:
| Дебет | 10 счет - (материалы) | 100 руб. |
| Кредит | 60 счет - (поставщики) | 100 руб. |
Увеличивается остаток материалов на складе – сумма прибавляется в дебет одного счета и увеличивается задолженность перед поставщиком материалов, т.е. та же сумма еще прибавляется в кредит другого счета.
Можно предположить, что существуют системы учета с тройной, четырехкратной и т.д. записью. Действительно, такие системы используются на практике. При учете затрат по дебету 20 счета собирается себестоимость, например, Д20 – К10 (материальные затраты). В конце каждого месяца этот счет закрывается, например, Д46 – К20, и в следующем месяце себестоимость рассчитывается с нуля. Но по затратам, кроме того, ведется учет нарастающим итогом с начала года (несмотря на то, что в конце каждого месяца затраты списывались под ноль, в декабре бухгалтерия должна дать данные о затратах за весь год). Это достигается применением двух разных регистров. В одном учитывается обычная бухгалтерия, а в другом – затратная (то же самое, но без списания затрат. Получаем тройную запись:
| Дебет | 20 затратный | 100 руб. |
| Дебет | 20 балансовый | 100 руб. |
| Кредит | 10 счет | 100 руб. |
При списании затрат задействуется только 20 балансовый счет:
| Дебет | 46 счет | 100 руб. |
| Кредит | 20 балансовый | 100 руб. |
Четырехкратной записью фиксируются операции с материальными ценностями и фондами в бюджетной бухгалтерии (так называемые вторые проводки).
И, наконец, полное смешение всех типов проводок наблюдается в западной системе учета. Например, оприходование товаров для розничной торговли будет выглядеть следующим образом:
| Дебет | 41 счет - (товары) | 120 руб. |
| Кредит | 60 счет - (поставщики) | 100 руб. |
| Кредит | 42 счет - (наценка) | 20 руб. |
Все строки в операции называются полупроводками. Для сохранения баланса должен соблюдаться принцип равенства сумм дебетовых и кредитовых полупроводок.
Несмотря на существенную разницу в представленных системах учета, всех их обюединяют схожие принципы. Бухгалтерия же двойной записи – всего лишь подкласс обширного семейства систем учета.
Структура хранения данных
Любая система учета укладывается в единую схему хранения и обработки данных. Для хранения информации разрабатывается структура основной базы данных (основной таблицы). В общем случае поля базы имеют вид:
| Измерители (координаты) | Служебная информация | Значения |
Поля-измерители используются для сортировки, фильтрации и группировки данных, служебные поля несут идентификационную нагрузку, над полями-значениями выполняются различные арифметические действия. Например, для учета складских остатков в качестве измерителей задействуются поля:
ГОД
МЕСЯЦ
СКЛАД – код (номер) склада
МОЛ – шифр материально ответственного лица
ТМЦ – номенклатурный номер товара / материала.
Служебная информация:
ДВК – дата ввода / корректировки
Значения:
НОК – начальный остаток в количестве
НОС – начальный остаток в сумме
ПК – приход в количестве
ПС – приход в сумме
РК – расход в количестве
РС – расход в сумме
КОК – конечный остаток в количестве
КОС – конечный остаток в сумме
Здесь, чтобы вывести остатки материальных ценностей на конец года по складу N, применяется фильтр вида (ГОД=2000 and МЕС=12 and СКЛАД=N) и формируется таблица с полями (таблица 1).
Поля-измерители задействуются следующим образом: МОЛ для группировки данных и получения промежуточных итогов, ТМЦ участвует в сортировке. Графы «Наименование» и «Ед. изм.» заполняются из сопутствующей базы данных или связанной таблицы. Из полей-значений задействованы КОК и КОС. С ними производятся следующие арифметические действия: для получения цены выполняется деление, поле КОС в итоговых строках суммируется. Аналогично можно построить учет расчетов с поставщиками. Здесь в качестве значений будут фигурировать суммы проводок (в рублях и в валюте), а в качестве измерителей – год, месяц, день, дебет, кредит, код поставщика и т.п.
Подобным же образом в схему «измерители-значения» укладывается любая система учета: главное – не переусердствовать с измерителями и не закладывать туда несущественную информацию. Все прочие показатели, такие как наименование и единица измерения, выносятся в сопутствующие базы данных (связанные таблицы). Значений также должно быть ровно столько, сколько необходимо. Например, в приведенном примере КОК и КОС избыточны, их можно получить путем несложных вычислений:
КОК = НОК + ПК - РК;
КОС = НОС + ПС - РС.
Продолжив рассуждения, можно прийти к выводу, что поля для хранения начальных остатков (НОК и НОС) тоже излишни. Любой остаток – результат приходов и расходов за предыдущее время.
Математическая модель данных
В большинстве систем учета основным действием, выполняемым над полями-значениями, является суммирование. Например, чтобы получить журнал-ордер б№1, необходимо просуммировать все проводки по кассе за месяц в разбивке по дням и по корреспондирующим счетам. Чтобы получить записи для главной книги по кассе, необходимо просуммировать строки журнала-ордера б№1 в разбивке по коррсчетам за все дни.
В процессе суммирования система поочередно перебирает все записи в базе данных, что отнимает много времени. В основу предлагаемой автором модели данных положена классическая формула Ньютона-Лейбница:
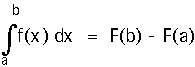
В основной базе данных помимо самой функции f(x) необходимо хранить значения ее интегральной функции F(x). Тогда суммирование f(x) заменяется на разность значений F(x), при этом для получения результата вместо сплошного перебора записей к базе данных достаточно обратиться всего дважды – к начальной записи и к конечной.
В реальных системах учет ведется одновременно по многим показателям, поэтому функция f(x) становится многомерной – f(a,b,c,...z), где a,b,c... – поля-измерители (счет, код материала, номер документа, дата проводки и т.п.). Выделим номер документа и дату проводки в отдельную ось координат – время t. Именно по времени часто отрабатываются запросы «с ... по ...», тогда как запросы типа «с 40 счета по 60» или «с третьего склада по восьмой» – большая редкость.
Для суммирования данных за определенный промежуток времени необходимо вычислить дифференциал F(a,b,c,...t) на отрезке н?t:
S(a,b,c,... н?t) = F(a,b,c,...t2) - F(a,b,c,...t1),
н?t = [t1; t2]
Для получения сводных данных по другим аналитическим показателям – a,b,c... – необходимо просуммировать значения S(a,b,c,...н?t). Таким образом все итоговые документы будут получены в результате дифференцирования и интегрирования данных из основной базы.
Структура основной базы данных
Структура основной базы данных приобретает вид, показанный в таблице 2.
Все поля-измерители можно разбить на три категории: учетный период, аналитика и время. Для обычных задач бухгалтерского учета вектор времени достаточно представить тремя показателями: ДЕНЬ (календарное число в месяце); ВД (вид документа); НД (номер документа). С их помощью однозначно идентифицируется хозяйственная операция при условии, что в течение одного дня нет повторяющихся номеров документов каждого вида.
Аналитика А1, А2 ... Аn может быть выражена как простым набором независимых аналитических показателей (например, СЧЕТ, СКЛАД, ТМЦ), так и набором ссылок к другим таблицам, отражающих более сложную аналитическую структуру.
В качестве значений используются четыре поля:
PD – сумма проводки по дебету (приход)
PK – сумма проводки по кредиту (расход)
ID – суммарные дебетовые обороты с начала отчетного периода
IK – суммарные кредитовые обороты с начала отчетного периода
Для обеспечения учета, как в валюте, так и в количестве и т.д. нет необходимости добавлять новые поля значений. С этой целью лучше задействовать служебное поле ТЗ – тип записи, например:
ТЗ=1 – значения в рублях
ТЗ=2 – значения в количестве
ТЗ=3 – значения в валюте
При помощи уникального номера записи, сохраняемого в поле НЗ, рублевые значения с количественными и/или с валютными.
Рассмотренный пример по учету ТМЦ преобразуется в вид, показанный в таблице 3.
Так задается сальдо на начало отчетного периода. В первой записи хранится сумма (тип записи ТЗ=1), во второй – количество (ТЗ=2). Записи с начальным сальдо отличаются от остальных записей нулевыми значениями в полях PD и PK (суммы проводок отсутствуют) и полем ДЕНЬ=0. В этом случае при сортировке по времени записи сальдо окажутся в самом начале. В таблице 4 приведены записи в базе данных, отображающие движение ТМЦ.
В записях с НЗ=15 зафиксирован расход рассматриваемого ТМЦ с кодом 100 в количестве 4 на сумму 40. При этом суммарные дебетовые обороты не изменились, а кредитовые достигли значений 40 в сумме и 4 в количестве. В записях с НЗ=180 зафиксирован приход в количестве 10 на сумму 100. При этом суммарные дебетовые обороты достигли значений 150 в сумме и 15 в количестве, а кредитовые обороты не изменились. В записях с НЗ=250 снова расход в количестве 7 на сумму 70. При этом суммарные кредитовые обороты достигли значений 110 в сумме и 11 в количестве.
Разность ID-IK дает текущее сальдо. Например, количественное сальдо за 5 декабря 5-4=1. Обороты за произвольный отрезок времени вычисляются путем дифференцирования основной базы:
дебетовые обороты :
OD = IDконечное - IDначальное
кредитовые обороты:
OK = IKконечное - IKначальное
Например, приход с 6 по 20 декабря составил OD=15-5=10, расход OK=11-4=7. Для контроля возьмем сальдо за 5 декабря (1), прибавим приход с 6 по 20 декабря (10) и вычтем расход (7), получается 1+10-7=4. Это текущий остаток за 20 декабря равный ID-IK (15-11=4).
Заметьте, вся информация об оборотах и сальдо берется всего из двух записей: конечной и начальной. Если бы от первой строки, где НЗ=15, и до последней, где НЗ=250, было бы не две операции, а сотня, то процедура вычисления оборотов и сальдо нисколько бы не увеличилась. Для получения сводных данных, например, о сумме расхода с 6 по 20 декабря по складу б№1 необходимо проинтегрировать полученные значения кредитовых оборотов OK по всем МОЛ и ТМЦ при условии СКЛАД=1.
База оперативно заполняется. При вводе новой проводки надо всего лишь проверить наличие в базе предыдущей строки с такой же аналитикой. При использовании соответствующей сортировки (в данном примере: Год, Месяц, Склад, МОЛ, ТМЦ, ДЕНЬ, ВД, НД) это выполняется практически моментально. Если предыдущая строка обнаружена, то вычисляемые поля примут значения:
IDтекущее = IDпредыдущее + PDтекущее
IKтекущее = IKпредыдущее + PKтекущее
Если предыдущей строки нет, то в ID вписывается значение PD, в IK значение PK. Никакой обработки дополнительных баз данных, например, пересчета оборотов и сальдо не требуется. Основная база содержит полную информацию.
В предложенную структуру основной базы данных легко вписываются как проводки с двойной записью, с тройной и т.д., так и полупроводки. База данных становится достаточно универсальной, чтобы не разрабатывать отдельные системы учета денежных средств, товарно-материальных ценностей, валютных операций и т.п. Все национальные, отраслевые и прочие различия закладываются не на уровне структуры базы данных, а на уровне обрабатывающих процедур.
База данных технологических процессов
В корпоративных информационных системах кроме бухгалтерского учета ведется и другой учет. Представим технологический процесс, как функцию нескольких переменных, непрерывную во времени. Для хранения информации используется база данных вида, показанного в таблице 5.
Автоматические датчики снимают множество показателей в разных цехах с различных агрегатов: температура, давление, напряжение питания, потребляемый ток и т.д. Тогда поле ПОКАЗАТЕЛЬ будет содержать код показателя из списка:
1 – температура рабочей зоны
2 – температура охлаждающей жидкости
3 – давление в рабочей зоне .и т.п.
В поля-значения будут вписываться только изменения показателей. Например, если показатели снимаются каждую минуту, но по давлению в рабочей зоне не было изменений в течение часа, то по этому показателю в базе данных будет не 60 записей, а только одна, фиксирующая либо прирост, либо уменьшение:
IDтекущее = IDпредыдущее + н?P при н?P>0
IKтекущее = IKпредыдущее + |н?P| при н?P<0
Таким образом, в ID будет храниться суммарная амплитуда всех положительных изменений, а в IK – отрицательных. Точкой отсчета служит значение показателя на начало отчетного периода, зафиксированное в поле ID (отрицательное – в IK) при пустом значении поля ВРЕМЯ. Разность ID-IK в любой момент времени равна абсолютному значению рассматриваемого показателя. Все данные фиксируются в хронологическом порядке, поэтому отпадает необходимость пересчета значений ID и IK.
На практике недостаточно знать просто значение показателя. Если рассматривать показатели как случайные величины, полезно зафиксировать их суммарные начальные моменты k-го порядка:
где н?ti – i-й отрезок времени t, на протяжении которого значение показателя p оставалось неизменным и равным pi.
Суммарный начальный момент 1-го порядка представляет собой сумму произведений значения показателя на время, в течение которого действовало данное значение, за отчетный период (p*н?t). Суммарный начальный момент 2-го порядка представляет собой сумму квадратов показателя, умноженных на время (p2*н?t). Моменты Ak фиксируются в базе данных при изменении показателя нарастающим итогом с начала отчетного периода.
От суммарных начальных моментов легко перейти к начальным моментам k-го порядка:
ak = Ak/t
Чтобы получить среднее значение показателя на любом промежутке времени [tначальное; tконечное], необходимо найти разность:
pср.= a1 = (A1 конечное - A1 начальное)/н?t,
где н?t = t конечное – t начальное
Аналогично вычисляется средний квадрат:
p2ср. = a2 = (A2 конечное – A2 начальное)/н?t
Через значения начальных моментов k-го порядка можно найти центральные моменты:
m2 = a2 - a12
m3 = a3 - 3 a2 a1 + 2 a13
m4 = a4 - 4 a3 a1 + 6 a2 a12 - 3 a14
Центральный момент 2-го порядка m2 является дисперсией, а его квадратный корень – средним квадратическим отклонением (СКО).
При нормальном распределении случайной величины среднее значение и среднее квадратическое отклонение являются исчерпывающей характеристикой исследуемого показателя. Так, среднее значение характеризует собственно значение показателя, а СКО – точность его оценки.
Предложенная структура базы данных обеспечивает максимальную производительность при вычислении статистических характеристик. Для получения среднего, дисперсии (а также асимметрии, эксцесса и т.п.) требуется всего два обращения в базу данных: к записи, в которой ВРЕМЯ Б?? tначальное и к записи, где ВРЕМЯ Б??tконечное.
Аналогично, как и в бухгалтерской базе данных, характеристики показателей на исследуемом промежутке времени получаются путем дифференцирования значений из основной базы. Для вычисления суммарных или усредненных показателей по агрегату, цеху, всему предприятию применяется процедура интегрирования полученных данных.
Сортировка основной базы данных
Для оперативной обработки информации база данных сортируется в определенном порядке. При использовании многопользовательского ввода данных для просмотра информации необходимо предусмотреть индекс с ключом: пользователь, учетный период, время, служебная информация. В примере с учетом ТМЦ ключ принимает вид:
Пользователь, Год, Месяц, День, ВД, НД, НЗ, ТЗ
Для добавления новой записи система должна уметь быстро обратиться к предыдущей записи с требуемой аналитикой. Для этого применяется индекс с ключом: учетный период, аналитика, время, служебная информация. В примере по учету ТМЦ используется ключ вида:
Год, Месяц, Склад, МОЛ, ТМЦ, День, ВД, НД, НЗ, ТЗ
В примере технологической базы данных используется ключ:
Месяц, День, Показатель, Цех, Агрегат, Минуты
Метод SEEK обеспечит практически моментальный переход к искомой записи.
При интегрировании значений могут потребоваться и другие индексы. (Сразу отбросим достаточно эффективные, но низкоскоростные методы обработки SELECT, SET FILTER и т.п. – самую высокую скорость обеспечивает комбинация методов SEEK и WHILE.) Например, чтобы получить остатки ТМЦ по всем складам, числящиеся на материально ответственных лицах, первоначальный ключ несколько видоизменяется:
Год, Месяц, МОЛ, ТМЦ, Склад, День, ВД, НД, НЗ, ТЗ
Для других заданий подобного рода могут потребоваться иные комбинации аналитических показателей Склад, МОЛ, ТМЦ. В рассмотренном примере их шесть. В технологической базе данных аналогичная ситуация с полями Показатель, Цех, Агрегат. Порядок – учетный период, аналитика, время, служебная информация – сохраняется, меняется только внутренний порядок аналитических полей. Для большинства современных СУБД шесть индексов проблемы не составляет, но в общем случае число возможных индексов равняется n!, где n – количество независимых аналитических показателей. При 5 показателях это уже 120 индексов.
Есть и другая проблема – хронологический порядок ведения базы данных. В отличие от технологических процессов бухгалтерская база данных может заполняться не в хронологическом порядке. Кроме того, в ней возможны исправления. Как в первом, так и во втором случае система будет вынуждена пересчитать значения полей ID и IK в записях с задействованной аналитикой, имеющих более позднюю хронологию. При массовом вводе данных это может привести к тому, что система «захлебнется».
Система обработки информации
Для построения несложной системы учета, в которой данные будут заполняться преимущественно в хронологическом порядке, и пересчеты будут редким явлением, с небольшим количеством независимых аналитических показателей выше изложенных рекомендаций вполне достаточно. В качестве платформы подойдет любая современная СУБД. Для построения более сложных систем, свободных от перечисленных ограничений, потребуются дополнительные решения.
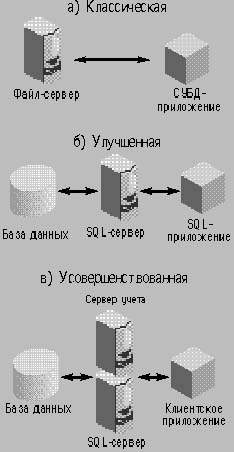 |
| Рис. 1. Cхемы работы многопользовательских систем обработки |
До сих пор типичной для отечественных многопользовательских систем обработки остается схема, основанная на использовании файл-сервера. Она изображена на рис. 1a, а ее улучшенный вариант – на рис. 1б.
Всю ответственность за ввод, обработку и представление информации несет на себе клиентское приложение – серверной части системы остается пассивная роль хранения, а в SQL-варианте еще и сортировки информации. В клиентской части необходимо предусмотреть все многообразие представления данных и методов их обработки. Как показывает практика, даже использование SQL-технологий не приводит к сколько-нибудь существенному сокращению сетевого трафика. При таком подходе о построении системы с разветвленной территориальной структурой не может быть и речи. Требования к аппаратной части клиента очень высоки.
Возможны два выхода. Первый предполагает отказ от универсального клиентского рабочего места в пользу разработки комплекта специализированных АРМов, связанных общей базой данных. Однако, продвижение по этому пути, на первый взгляд соблазнительно простому, грозит созданием неуправляемого монстра, если разработчик умышленно не ограничит масштаб и проектные возможности системы. Второй вариант – разгрузка клиентской части за счет переноса бизнес-логики на сервер. Он более предпочтителен с точки зрения универсальности и масштабируемости системы. Но и здесь нашим разработчикам похвастаться нечем. Это либо специализированные комплексы, разработанные на заказ, либо попытки создания универсальных систем, далеких от совершенства, не внедряемых и готовых к эксплуатации без участия разработчика, не балующих пользователей стабильностью работы.
Если базовую бизнес-логику сосредоточить в специальной программе – «сервере учета», то усовершенствованная схема будет выглядеть так, как показано на рис. 1в.
Сервер учета обслуживает основную базу данных, а SQL-сервер напрямую обслуживает вспомогательные таблицы, в которых хранятся списки, справочники и прочая сопутствующая информация. Физически сервер учета может быть вынесен на отдельный компьютер.
Идея трехзвенной архитектуры не нова. Различие между однозвенной архитектурой (файл-сервер), двухзвенной (SQL-сервер) и трехзвенной архитектурой заключается только в том, кто перебирает записи в базе данных – клиент, сервер или специализированный сервер приложений. Смысл авторской концепции состоит в том, что специализированный сервер для суммирования данных не будет производить сплошного перебора записей в базе. За счет использования предложенной модели данных серверу будет достаточно обратиться только к двум записям – конечной и начальной, что значительно повысит производительность системы.
Сервер учета
При вводе бухгалтерской проводки (получении информации с датчика) клиентское приложение взаимодействует с сервером учета, который выполняет необходимые вычисления над полями-значениями и регистрирует информацию в основной базе данных. Для получения информации из основной базы клиентское приложение посылает запрос не SQL-серверу, а серверу учета, который выполняет необходимые вычисления и трансформирует данные из полей-значений в соответствующее представление.
Сводные данные вычисляются путем дифференцирования и интегрирования основной базы и сохраняются в промежуточных таблицах. При внесении изменений в основную базу данных промежуточные таблицы своевременно обновляются и пополняются. Структура промежуточных таблиц и алгоритмы обработки полей-значений определяются комплектом периодической отчетности. Например, при заполнении бухгалтерской базы данных не в хронологическом порядке, чтобы избежать большого количества пересчетов, для хранения ID и IK применяется отдельная промежуточная таблица (рис. 2).
Необходимо выделить три режима вычислений: непрерывный, режим периодических вычислений и режим вычислений по требованию. Различные журналы-ордера, ведомости, главная книга, баланс формируются в режиме вычислений по требованию. Это единственный режим, который уже и так реализован в SQL-сервере и представляет собой обычный запрос SELECT, исходящий от клиентского приложения.
Режим периодических вычислений – это тот же SELECT, но запрашиваемый не клиентом, а сервером. Результат запроса сохраняется на диске в виде отдельной промежуточной таблицы для дальнейшей обработки. Таблица в автоматическом режиме периодически обновляется. Вычисления выполняются в фоновом режиме, причем необязательно по времени, а в зависимости, например, от обюема поступившей информации или от степени загрузки сервера. Всю отчетность, формируемую в режиме периодических вычислений, можно формировать по требованию.
Непрерывный режим отличается от двух предыдущих тем, что это не команда SELECT, которая всегда выполняется «вдогонку». Это процесс, который отслеживает состояние первичной базы данных и при внесении в нее изменений, немедленно реагируя. Например, рассматриваемую промежуточную таблицу, лучше заполнять в непрерывном режиме – при поступлении каждой новой проводки сервер автоматически выполнит дорасчет значений ID и IK. На рис. 2 представлена примерная схема работы сервера учета.
В подобной схеме снимается проблема большого количества индексов, число которых находится в факториальной зависимости от количества независимых аналитических показателей. Процедуры заполнения первичной и промежуточных таблиц могут быть разделены во времени, поэтому для формирования промежуточных таблиц необязательно применять методы SEEK и WHILE. Периодические вычисления можно осуществлять другими методами с частичным использованием индексов или вообще без них.
Индексы рекомендуется применять только для вычислений в непрерывном режиме: в этом случае формируется минимальное количество промежуточных таблиц, поэтому количество индексов первичной таблицы будет вполне допустимым.
Приведенная схема базовой бизнес-логики благодаря унификации хранения данных реализуется несложно. Все алгоритмы обработки информации сводятся к фильтрации записей и элементарному сложению (интегрированию) и вычитанию (дифференцированию) значений. В комбинации трех режимов вычислений заложены широчайшие возможности обработки данных. Одна промежуточная таблица может выступать источником данных для других промежуточных таблиц.
Если наделить сервер учета несколько большим уровнем интеллекта, он сам сможет динамически реорганизовать схему построения промежуточных таблиц, опираясь на накапливаемую статистику по характеру запрашиваемых отчетов. Для «особенных» пользователей, таких как главный бухгалтер и генеральный директор, которые обращаются к системе реже других пользователей, но при этом требуют высокой оперативности, необходимо сохранить априорный порядок формирования промежуточных таблиц.
Таким образом, клиентское приложение максимально освобождается от обработки данных, как при вводе информации, так и при получении сводной отчетности. Это снижает требования к аппаратуре клиентской части и открывает возможность работы по низкоскоростным каналам связи. Более того, сервер учета может выступать в качестве клиента другого сервера учета.
Корпоративная информационная система
На основе предлагаемой технологии строится корпоративная информационная система. Сервер учета первого уровня кроме обработки оперативных данных готовит сводные данные для сервера учета второго уровня. Например, на электростанции, вырабатывающей электроэнергию, регистрируется потребляемая мощность, обюем потребляемого топлива и т.п. Сервер учета суммирует показатели и сохраняет их в сводных таблицах. Сервер учета региональной организации «Регион-энерго», воспользовавшись подготовленными подчиненными электростанциями сводными таблицами, составляет свои таблицы, которыми, в свою очередь воспользуется сервер учета следующего уровня.
При этом если сервер учета каждой электростанции регистрирует потребление энергии ежеминутно, то региональный сервер будет учитывать в разбивке по электростанциям только среднесуточное энергопотребление. Корпоративный сервер, в свою очередь, консолидирует среднесуточные показатели в разбивке по регионам, по потребляемому виду топлива и т.п. Таким образом, корпоративный сервер выдаст руководству корпорации показатели потребления энергии, себестоимости и др. за сутки, за месяц, за квартал в разбивке по регионам, по видам топлива и т.д.(рис.3).
На каждом уровне данные интегрируются и укрупняются. Обработка данных может производиться как автоматически, так и с привлечением людей. При этом корпоративный сервер не будет перегружен обслуживанием общей базы данных, содержащей все подробные аналитические показатели, существенные для подчиненных региональных систем, но совершенно ненужные для руководства. (Здесь задача оперативного учета рассматривается отдельно от задачи создания корпоративного хранилища данных.)
Для обмена информацией между серверами необязательно иметь постоянный высокоскоростной канал связи. Достаточно наладить периодический обмен данными на уровне сводных таблиц. Для этого старшему серверу необходимо поочередно «обзванивать» подчиненные серверы и, «притворяясь» клиентом, забирать подготовленные сводные таблицы. Каждая региональная система в достаточной степени автономна, и в случае временного отсутствия связи общая работа существенно не пострадает. Используя иерархическую структуру, корпоративная система может наращиваться до транснациональных масштабов.
Заключение
Представленная модель данных обеспечивает высокое быстродействие как в однопользовательских, так и в многопользовательских системах. С применением специализированного сервера учета значительно сокращается сетевой трафик, снижаются требования к аппаратной части клиентских мест, упрощается администрирование. Предлагаемая схема корпоративной информационной системы легко масштабируется.
Сергей Тбёкотев – ведущий программист АО «Микроком». С ним можно связаться по адресу: microcom@kmtn.ru.
