

Многие разработчики не раз могли на собственном опыте убедиться в правильности этого изречения, поскольку, в отличие от известного афоризма «есть человек - есть проблема, нет человека - нет проблемы», «жизнь» системы приносит разработчику гораздо меньше проблем, чем ее внезапная «смерть». В данной статье пойдет речь об универсальных механизмах контроля и диагностики, предоставляемых QNX4 - операционной системой жесткого реального времени.
Грамотный специалист всегда осторожен - он всегда четко знает границы своей компетенции, но даже в ее пределах не исключает возможность ошибки. Поэтому, наряду с банальным (и обычно тщетным) старанием не допускать ошибок при проектировании, для него не менее важна возможность быстрого поиска и устранения неисправности. Встроить такую возможность в собственную разработку обычно не составляет труда, но цепочка событий, приведших к сбою, может быть очень длинной и вести далеко за ее пределы. Поэтому грамотный проектировщик всегда стремится увидеть систему «сверху», чтобы иметь представление об индивидуальном поведении и взаимодействии всех ее компонентов. Вот здесь и встает вопрос совершенства штатных средств диагностики, призванных упростить анализ прохождения информации между компонентами системы, их поведения в отдельности и в совокупности.
Структура и архитектурные особенности QNX4
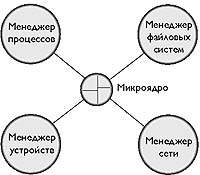 |
| Рис. 1. Архитектура операционной системы QNX4 |
QNX4 имеет модульную структуру [1] и состоит из микроядра и сгруппированных вокруг него взаимодействующих процессов, среди которых выделяют четыре специальных процесса - системные менеджеры (рис. 1).
Все системные службы QNX4, кроме предоставляемых микроядром, обеспечиваются процессами, и в частности, системными менеджерами. Особая роль менеджеров состоит в том, что через них осуществляется доступ к ключевым подсистемам:
- менеджер процессов (Process manager) отвечает за подсистему управления процессами QNX4, а также управляет таймерами, разделяемой памятью и другими ресурсами, предоставляя процессам службы POSIX 1003.1 и POSIX 1003.4;
- менеджер файловых систем (Filesystem manager) отвечает за файловую подсистему QNX4, предоставляя процессам доступ к файловым системам на различных носителях, контролируя доступ к файлам и обеспечивая кэширование данных и поддержку электронных дисков;
- менеджер устройств (Device manager) является центром подсистемы терминальных устройств QNX4, обеспечивая процессам интерфейс с терминальными устройствами;
- менеджер сети (Network manager) управляет сетевой подсистемой QNX4 и отвечает за сетевые коммуникации, предоставляя процессам службы уровней модели OSI от третьего (сетевого) и выше.
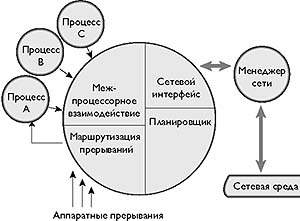 |
| Рис. 2. Микроядро QNX4 |
Микроядро отвечает за такие жизненно важные функции, как средства межпроцессного взаимодействия и низкоуровневый сетевой обмен, диспетчеризацию процессов и первичную обработку прерываний (рис. 2).
Все важнейшие системные события, будь то аппаратное прерывание, смена состояния процесса или передача/прием сообщения процессом, проходят через микроядро, которое обеспечивает их маршрутизацию и координирует действия системных компонентов. Такая реализация, очевидно, предоставляет широкие возможности централизованной диагностики.
Диагностика ключевых подсистем
Каждый из ключевых компонентов QNX4 - как микроядро, так и системные менеджеры - хранит информацию о работе соответствующей подсистемы.
Микроядро. Все системные события так или иначе проходят через микроядро [1, 6] и если заставить микроядро вести журнал этих событий, то можно будет наблюдать за поведением ОС на самом низком уровне, включая события диспетчеризации, аппаратные прерывания и обмен сообщениями между процессами. Для этого в стандартной поставке ОС существуют две специализированные утилиты. Утилита monitor перехватывает события микроядра и записывает их в заданный файл (журнал), чтение которого обеспечивает еще одна утилита, msgprint [2], которая расшифровывает коды событий и отображает их в читаемой текстовой форме. Для каждого события указывается временная метка, описание события, имена и идентификаторы ассоциируемых с ним процессов, например:
6.ed00033f active is 24(Net)
6.ed000426 proxy(59(Socklet))
triggers 59(Socklet)
6.ed00043a 24(Net) Triggers
proxy(59(Socklet))
6.ed000492 24(Net) recv (none) []
from {none}
6.ed0004a7 active is 59(Socklet)
6.ed0004ce 59(Socklet) recv (none)
[] from proxy(59(Socklet))
6.ed0005b4 proxy(19603(phrelay))
triggers 19603(phrelay)
6.ed0005c9 59(Socklet) Triggers
proxy(19603(phrelay))Для упрощения анализа журналов событий микроядра компанией QSSL был дополнительно разработан пакет Deja-View, работающий в графической оболочке Photon и представляющий события микроядра из заданного журнала в виде временных диаграмм (рис. 3).
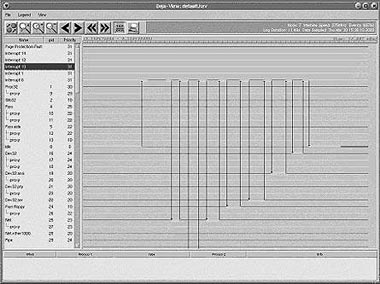 |
| Рис. 3 Временные диаграммы пакета Deja-View |
Подсистема управления процессами. Одним из самых «разговорчивых» в плане диагностики системных компонентов QNX4 является менеджер процессов. Информация, которую можно получить от менеджера процессов, делится на три категории: информация о процессах и ресурсах (системная информация), события трассировки и лицензионная информация. Для каждой из этих категорий диагностической информации в QNX4 предусмотрены отдельные средства протоколирования и отображения.
Системная информация может отображаться как в текстовом, так и в графическом режиме. Для текстового режима существуют утилиты sin (System INformation - информация о собственно процессах и ресурсах) и sac (System ACtivity - информация о системной активности на каждом уровне приоритета) [2], а также позаимствованная из среды Unix утилита ps (Process Status), по сути являющаяся подмножеством sin. В графической оболочке Photon роль sin и sac выполняют их «более визуальные» аналоги vsin (Visual sin) и phsac (Photon sac) [5]. Информация по каждому процессу, предоставляемая утилитой sin, включает в себя [2, 7]:
- аргументы, переданные процессу в командной строке при запуске, и его флаги;
- приоритет, дисциплина диспетчеризации и состояние (если процесс блокирован, то тип и причины блокировки);
- корень файловой системы и текущий каталог;
- окружение;
- иерархия, «родственные» отношения («отец» - «сын», и т.п.);
- открытые файлы и используемые описатели файлов;
- идентификаторы процесса (process ID - PID) и сеансы;
- версия и время создания исполняемого модуля, размер областей кода и данных;
- селектор и смещение «магических чисел»;
- таймеры и ассоциируемые с ними действия, время старта и время активности;
- реальный и эффективный идентификатор пользователя и группы;
- текущее значение регистров процессора;
- сведения по обработке сигналов.
Информация (по умолчанию это идентификаторы сессии и процесса, имя процесса, приоритет и дисциплина диспетчеризации, состояние, источник блокировки и размеры областей кода и данных) отображается в несколько колонок с соответствующими заголовками, например:
SID PID PROGRAM PRI STATE BLK CODE DATA — — Microkernel—-——- —- 104480 0 1 sys/Proc32 30f READY —- 118k 802k 0 2 sys/Slib32 10r RECV 0 53k 4096 0 4 /bin/Fsys 29r RECV 0 77k 1482k 0 5 /bin/Fsys.eide 22r RECV 0 61k 114k 0 8 idle 0r READY —- 0 40k 0 16 //11/bin/Dev32 24f RECV 0 32k 94k 0 21 //11/bin/Dev32.pty 20r RECV 0 12k 32k 0 22 //11/bin/Pipe 10r READY —- 16k 32k 0 24 //11/bin/Net 23r RECV 0 32k 73k 0 26 //11/bin/Net.ether1000 20r RECV 0 28k 28k 0 28 //11/bin/nameloc 20o RECV 0 6144 20k
Дополнительно утилитой sin предоставляется следующая общая информация по каждому узлу сети:
- аппаратная конфигурация (тип процессора и системной шины, индекс производительности, тип дисплея, объем оперативной памяти);
- разрешение системных таймеров и лимиты системных ресурсов (системные области «кучи» менеджера процессов, максимально допустимое количество процессов, таймеров, сеансов, символьных имен процессов, и т.п.);
- количество лицензированных узлов сети;
- дата, время и источник начальной загрузки;
- распределение серверов символьных имен (name locator) по узлам сети;
- текущий перечень виртуальных каналов.
Благодаря сетевой прозрачности QNX4, всю эту информацию можно получить не только с локальной машины, но и с любого узла сети.
Утилита vsin предоставляет аналогичную утилите sin функциональность, но в графической форме (рис. 4).
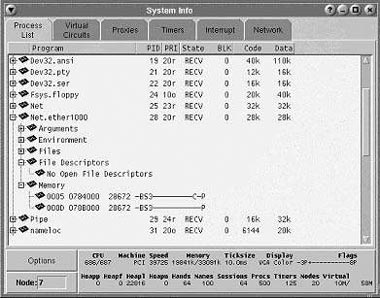 |
| Рис. 4. Пример вывода утилиты vsin |
Утилита sac отображает в динамике гистограмму активности системы на заданном узле сети по каждому уровню приоритета. Кроме приоритета, в качестве параметров ей можно задавать период опроса системной активности и постоянную интегрирования для управления сглаживанием. Утилита phsac функционально ничем не отличается от sac и является ее аналогом для графической оболочки Photon (рис. 5).
 |
| Рис. 5. Пример вывода утилиты phsac |
Здесь будет не лишним заметить, что корректность показаний утилит sin/vsin и sac/phsac может зависеть от приоритета их выполнения. Если просто запустить их из командной строки, они унаследуют от командного интерпретатора приоритет 10 и могут быть вытеснены более высокоприоритетными процессами. Чтобы этого не произошло, их приоритет можно увеличить утилитами nice/renice или slay [2].
События трассировки генерируются процессами для регистрации событий времени выполнения в системном буфере диспетчера процессов и обычно используются для низкоуровневой отладки (хотя такая отладка является, несомненно, более высокоуровневой, чем мониторинг событий микроядра). Эта функциональность доступна любому процессу QNX4 через семейство специальных системных вызовов Trace*() [4] и встроена во все системные компоненты ОС. Следует сразу отметить, что злоупотреблять этой ценной возможностью при разработке собственного ПО вряд ли стоит, поскольку такой буфер на каждой машине только один, и размер его строго фиксирован. Буфер организован по циклической схеме, поэтому после его заполнения вновь поступающие события будут записаны поверх самых старых; при этом ведется счетчик переполнений, что может помочь в выборе оптимального размера буфера.
Событие трассировки представляет собой структуру данных, содержащую информацию о дате, времени, важности, источнике и содержании события. Для экономии пространства буфера и увеличения скорости записи событий в буфер важность, источник и содержание событий представляются в структуре события трассировки системой числовых кодов. Важность представляет собой число от 0 (наибольшая важность) до 7 (наименьшая важность); источник и содержание событий кодируются парами чисел, называемых кодами событий.
Источники событий трассировки строго регламентированы, и каждому из них назначен индивидуальный номер (так называемый основной, или старший, код события). События, которые могут генерироваться каждым источником, также регламентированы и пронумерованы (их номера называются дополнительными, или младшими, кодами событий). Таким образом, пара «основной код - дополнительный код» полностью описывает, какой процесс и о каком событии сообщил. С дополнительным кодом могут также ассоциироваться некие данные; если они есть, они непосредственно следуют за ним в конце события трассировки.
Анализ событий трассировки в QNX4 выполняется при помощи утилит tracelogger и traceinfo; за контроль и управление параметрами трассировки отвечает утилита tracectrl [2].
Утилита traceinfo читает события трассировки из буфера менеджера процессов, расшифровывает их коды, если это возможно, в соответствии со своей внутренней базой данных (файлы /etc/config/traceinfo*) и выводит полученную расшифровку. Сначала отображаются дата и время, затем важность, а потом - либо расшифровка события в формате, указанном в базе данных, либо «сырые» данные, если расшифровка невозможна (например, если данный код события в базе отсутствует). Пример вывода утилиты traceinfo:
[//11:root] /home/root # traceinfo | tail -n 10 May 10 13:21:39 2 00004240 1 (576) 1000 (irq) out-of-window collision (bad hardware) May 10 13:21:40 2 000040f1 00000001 May 10 13:21:40 2 0000402c 1 (044) NET ( rx) Possible duplicate vid sequence number May 10 13:22:31 3 00006007 4 clusters allocated at 56964 May 10 13:24:22 2 00004240 1 (576) 1000 (irq) out-of-window collision (bad hardware) May 10 13:35:01 2 00004234 00000001 00000001 May 10 13:35:01 2 00004235 00000001 00000001 May 10 13:35:01 2 00004231 00000001 Warning! 5 overruns have occurred. Some trace events lost.
По умолчанию утилита traceinfo читает события трассировки непосредственно из буфера менеджера процессов. Чтобы избежать проблем, связанных с переполнением буфера, можно использовать утилиту tracelogger, которая периодически сохраняет содержимое буфера в дисковом файле, который можно будет впоследствии читать той же утилитой traceinfo.
Для управления процессом трассировки используется утилита tracectrl, которая позволяет просматривать текущие значения параметров трассировки, устанавливать уровень заполнения буфера, при достижении которого содержимое буфера должно быть записано на диск утилитой tracelogger, а также задавать менеджеру процессов минимальный уровень важности событий, которые следует сохранять.
Лицензионная информация в QNX4 влияет на запуск лицензированных процессов. Она считывается утилитой sinit из файловой системы при старте операционной системы, хранится во внутренней базе данных менеджера процессов на каждом узле сети и регулярно обновляется сервером символьных имен - утилитой nameloc. (Это не должно вызывать недоумения, поскольку реально лицензии являются разновидностью символьных имен.) Для любого программного обеспечения, использующего механизм лицензирования QNX, справедливо правило: нельзя запустить в сети больше копий, чем допускается лицензией. Каждому программному продукту соответствует буквенный шифр - префикс лицензии. Чтобы определить число разрешенных запусков процесса по каждому префиксу, используется утилита licinfo [2]. Она отображает список присутствующих в системе лицензий (реально - список префиксов лицензий), общее и израсходованное число копий соответствующих процессов в сети, а также список узлов, на которых эти процессы запущены.
Файловая подсистема. Файловая подсистема QNX4 состоит из менеджера файловых систем и набора драйверов физических носителей, подключаемых к менеджеру по мере необходимости. Диагностика ее мало чем отличается от таковой в других ОС и сводится к проверке целостности носителей, корректности структуры файловой системы, объема занятого и доступного дискового пространства, а также подразумевает ряд статистических оценок. Этот круг задач возложен на системные утилиты dcheck, chkfsys, du, df и fsysinfo [2].
Утилита dcheck работает с «сырыми» (то есть неформатированными) носителями и обеспечивает обнаружение на них сбойных блоков, а также блоков, находящихся в «предотказовом» состоянии. При этом возможны три варианта тестов (чтение, чтение/запись и чтение/запись/верификация) и два алгоритма перемещения головок (последовательный и случайный). Обнаруженные сбойные блоки можно исключать из дальнейшего использования файловой системой.
Утилита chkfsys рекурсивно обходит дерево каталогов указанной файловой системы, для каждого файла проверяя его элементы и составляющие его экстенты, и строит в памяти битовую карту использованных блоков. Карта впоследствии сравнивается с существующей (файл /.bitmap), что позволяет обнаружить блоки, помеченные как «занятые», но реально не принадлежащие никаким файлам. Такие блоки можно восстановить, перезаписав битовую карту заново. Если карты на диске и в памяти не идентичны, chkfsys запросит разрешения сделать это. В конце работы chkfsys отображает статистику по проверенным элементам файловой системы.
Утилиты df и du, предусмотренные стандартом POSIX, показывают, соответственно, объем свободного и занятого дискового пространства в блоках по 512 байт или килобайтах. При этом утилита df показывает степень использования всего раздела в целом, а утилита du сообщает объем, занимаемый конкретными объектами. Пример вывода утилит df и du в 512-байтовых блоках:
[//11:root] /home/root # df -h File system (Blks) TotalUser Used Free Used Mounted on //11/dev/hd0t77 2124801 2123987 865255 1258732 40% / [//11:root] /home/root # du -a /tmp 13 /tmp/cron.log 955 /tmp/system.log 10169 /tmp/uucp.debug 137 /tmp/uucp.stats 555 /tmp/uucp.log 1962 /tmp/system.log.old 8 /tmp/cron.log.old
Утилита fsysinfo отображает статистику файловой системы - информацию о ресурсах, статистике дискового кэша и обращений к функциям файловой системы. Ресурсами файловой системы, контроль за которыми осуществляет менеджер файловых систем, являются индексные описатели (inode), открытые файлы, блокировки (lock) и потоки управления (thread), которые менеджер может ответвлять для ускорения обработки запросов. Лимиты каждого из этих ресурсов задаются командно-строковыми параметрами менеджера файловых систем при его старте. Утилита fsysinfo позволяет просмотреть степень наличия каждого из ресурсов, в том числе динамически, что может сыграть весомую роль в диагностике проблем, связанных с нехваткой ресурсов при пиковых нагрузках. По каждому ресурсу отображаются следующие параметры:
- количество используемых в данный момент единиц ресурса;
- максимальное количество единиц ресурса, находившееся в использовании с момента последнего сброса внутренних счетчиков менеджера файловых систем (сброс осуществляется автоматически при перезапуске менеджера, но может быть произведен и вручную);
- количество единиц ресурса, не обязательно используемых, но под которые уже зарезервирована память;
- максимально допустимое количество единиц (лимит) данного ресурса.
Наряду с учетом ресурсов, утилита fsysinfo существенно облегчает подбор оптимального объема дискового кэша, отображая статистику обращений к кэшу и процент «попаданий» (hits) и «промахов» (misses) данных и метаданных. Пример вывода утилиты fsysinfo:
Used Max Alloc?d Limit Hits Misses Ratio —— —- —- —- —— inodes 11 31 1000 1000 391432 8080 97.98% names n/a n/a 1500 1500 267755 7872 94.94% files 8 27 27 500 locks 0 4 500 500 threads 0 3 4 4 data hits:delays:misses = 442121:0:4805 (98.92%) metadata hits:misses = 373312:2513 (99.33%) 929465 cache lookups (47/sec) 365824 cache writes (18/sec) 1279932 disk reads (65/sec) 679516 disk writes (34/sec) 73099 open calls (3/sec) 12566 stat calls (0/sec) 105097 namei calls (5/sec) 12072 fstat calls (0/sec) 96154 read calls (4/sec) 105894 write calls (5/sec)
К средствам диагностики файловой подсистемы можно также причислить утилиту spatch [2], позволяющую, среди прочего, выполнять низкоуровневое редактирование содержимого «сырых» дисков и дисковых разделов и производить поблочное восстановление файлов.
Дополнительные возможности диагностики файловой подсистемы на уровне процессов предоставляются менеджером процессов и микроядром через анализ событий микроядра и событий трассировки.
Подсистема терминальных устройств. Никаких специальных средств диагностики для подсистемы терминальных устройств не предусмотрено. События данной подсистемы на уровне процессов можно отслеживать путем мониторинга событий микроядра и событий трассировки.
Сетевая подсистема. Аналогично другим подсистемам, сетевая подсистема QNX4 состоит из менеджера сети, к которому подключаются необходимые драйверы сетевого оборудования. К средствам диагностики сетевой подсистемы QNX4 следует причислить утилиты alive, netmap, netpoll, netinfo и netsniff [2].
Сетевой протокол QNX4 подразумевает жесткую привязку логических идентификаторов машин в сети к физическим (MAC) адресам сетевого оборудования. Отображение физических адресов в логические идентификаторы машин называется картой сети; манипуляции с картой сети, включая ее загрузку и редактирование, производит утилита netmap [2]. В плане диагностики эта утилита может помочь для проверки корректности элементов карты, а также в том случае, если имеются несколько физических сетей, и хотя бы один узел сети коммутирует пакеты между ними (такая возможность для сети QNX4 является встроенной, если машина подключена к нескольким физическим сетям с одинаковым форматом кадра канального уровня - она автоматически становится коммутатором). Утилита netmap может показывать построенную менеджером сети по карте сети таблицу коммутации, в которой значится, через какой коммутатор можно получить доступ в нужную сеть. Это бывает полезно при отладке сетей сложной топологии.
Наряду с отображением карты сети и таблицы коммутации, в утилите netmap предусмотрена возможность просмотра информации о числе передач пакетов на заданный узел и времени последнего сбоя передачи. Эта информация указывается непосредственно в карте сети для каждого перечисленного в ней узла, например:
# Logical Lan Physical TX Count Last TX Fail Time 2 1 00200B 001AFE; 460 May 17 13:45:53 2 2 t0 ; 0 3 1 004005 38447F; 1822 May 17 13:45:57 3 2 t0 ; 0 7 1 0000E8 2123A2; 460 May 17 13:46:01 11 1 4854E8 289142; 0 13 1 0000E8 210D86; 3148 16 1 009027 982B7B; 460 May 17 13:46:08 18 1 484C00 0044B9; 460 May 17 13:46:12 19 1 0000B4 9FB5CD; 460 May 17 13:46:16
Каждая машина в сети QNX4 поддерживает и регулярно обновляет список доступных соседей. Отвечает за это, опять же, сервер символьных имен - утилита nameloc. Ее основная задача - опрос всех узлов сети на предмет изменения информации о символьных именах процессов и доступных лицензиях. Для этого ей необходимо создать и поддерживать виртуальные каналы со всеми удаленными менеджерами процессов. Отсюда автоматически вытекает поддержка списка доступных узлов: если удалось создать виртуальный канал, то узел доступен, иначе - нет. Если время простоя (время отсутствия активности - idle time) существующего виртуального канала превышает установленный порог, то начинается процедура опроса целостности - удаленному узлу с заданным интервалом посылается не более заданного числа опросных пакетов. Если узел не отвечает, он помечается в списке как недоступный (down), а виртуальный канал уничтожается. Если впоследствии удается попытка создать виртуальный канал с этим узлом, то узел снова помечается в списке как доступный (up). Параметры опроса (максимально допустимое время простоя, число опросных пакетов и интервал между ними) устанавливаются и отображаются утилитой netpoll [2].
Просмотреть текущий список доступных узлов можно утилитой alive [2]. Функция qnx_net_alive() [4], которой пользуется эта утилита для получения списка, есть в системной библиотеке и может использоваться разработчиками в своих приложениях. Впрочем, результаты ее работы зависят от настроек карты сети и распределении в сети серверов символьных имен, а также слишком редко обновляются, и поэтому не всегда оказываются достоверными. Более надежным способом проверки доступности узла является попытка явно создать виртуальный канал с его менеджером процессов; если попытка удалась, значит, узел доступен, и наоборот.
Самое информативное средство диагностики сетевой подсистемы QNX4 - это утилита netinfo [2]. Она отображает журнал событий сети (вплоть до канального уровня), который ведет во внутреннем циклическом буфере менеджер сети на каждом узле, по аналогии с журналом событий микроядра и журналом событий трассировки у менеджера процессов. По каждому событию отображается: время возникновения события; логическая сеть, на которой событие произошло; логический или физический идентификатор узла сети, с которым событие связано; числовой код события и его символьная расшифровка. С помощью журнала событий сети можно контролировать параметры сетевых соединений, диагностировать ошибки доставки пакетов, и многое другое.
С помощью утилиты netinfo можно также просматривать сетевую статистику канального уровня, поддерживаемую каждым сетевым драйвером (для различных драйверов и, соответственно, для разных типов сетевых адаптеров, перечень приводимых статистических оценок отличается):
[//11:root] /home/root
# netinfo -L 1
Driver Slot 0: Driver Pid 26
Logical Net 1 Network Card:
Ethernet/ne1000/2000 (or compatible)
Ethernet Physical Node ID
0x4854E8 289142
I/O Port Range 0x6000 -> 0x601F
Hardware Interrupt 5
RAM Size (KB) 16
Total Packets Txd OK 53791
Total Packets Txd Double Buffered 96
Total Packets Txd Bad 5
Tx Collision Errors (Txd OK) 81
Tx Collision Errors (Aborted) 5
Out-Of-Window Tx Collisions 12
Carrier Sense Lost on Tx 5
Carrier Detect Failed on Tx 0
8390 FIFO Underruns During Tx 0
Total Packets Rxd OK 48261
Total Rx Errors 9
Missed Packets (not Rxd) 0
Ringbuffer Overflows on Rx 0
Deferring Due To Jabbering 5
CRC Errors on Rx 9
Framing Errors on Rx 2
8390 FIFO Overruns During Rx 0Утилита netsniff [2] представляет собой простейший вариант анализатора сетевого протокола для сетей Ethernet или сетей, совместимых с ними по формату кадра канального уровня. При запуске утилита регистрируется у менеджера сети и подключается к «сырому» потоку сетевых данных, получая возможность перехватывать принимаемые пакеты в их исходной форме. Перехваченные пакеты затем проходят через систему логических фильтров. Критериями фильтрации могут быть:
- MAC-адрес источника и/или приемника;
- тип протокола в заголовке сетевого уровня (поле «Длина/Тип» кадра Ethernet);
- физическая сеть, с которой пакет был получен.
Содержимое пакетов, удовлетворяющих выбранным критериям, и их временная метка (timestamp) отображаются на экране, с расшифровкой или без нее. Доступные режимы отображения:
- «сырой» режим: пакеты отображаются в шестнадцатеричном коде с дублированием в ASCII;
- «ознакомительный» режим: содержимое пакетов частично расшифровывается, если это возможно;
- «отладочный» режим: содержимое пакетов расшифровывается полностью, если это возможно;
- «статистический» режим: выводится только статистика по пакетам от заданных узлов, обновляемая с заданным интервалом; содержимое пакетов не отображается.
С использованием утилиты netsniff связано две тонкости [2, 6], незнание которых может привести к тому, что эта утилита окажется практически бесполезной, поскольку «не увидит» в сети в лучшем случае ничего интересного, а в худшем - вообще ничего.
1. Коль скоро пакет перехватывается на уровне менеджера сети, надо сначала обеспечить его прием на канальном уровне. По умолчанию все сетевые драйверы QNX4 при старте переводят адаптеры в режим «разборчивого» приема. В этом режиме, если MAC-адрес приемника в заголовке принятого пакета не соответствует MAC-адресу адаптера, то пакет отвергается. В таком режиме адаптер будет принимать только «свои», а также широковещательные пакеты. Процесс приема выглядит так: сначала принимается заголовок, потом проверяется соответствие MAC-адресов, и только в случае совпадения принимается остаток пакета; таким образом, данные пакетов, не предназначенных данному адаптеру, даже не попадают в его внутренний буфер.
Чтобы получить возможность перехватывать любой пакет, необходимо перевести адаптер в режим «неразборчивого» (promiscuous) приема (обычно это делается указанием ключа -P в командной строке драйвера). В данном режиме проверка соответствия адресов не производится, и адаптер будет принимать все пакеты (лучше всего для этого режима подходят 16-разрядные сетевые адаптеры).
2. Менеджер сети не дублирует принятые пакеты: операции чтения очереди принятых пакетов удаляют пакеты из очереди. Иными словами, если пакет адресован некоторому процессу на данном узле, то он будет выбран из очереди и перемещен в соответствующий буфер виртуального канала, откуда его уже будет невозможно перехватить. Это лишает netsniff возможности перехвата QNX-пакетов, предназначенных данному узлу, а также всех IP-пакетов, если на данном узле запущен менеджер Sock(l)et.
Из этого положения есть лишь один выход - установить дополнительный сетевой адаптер, не описанный нигде в карте сети (для того чтобы менеджеры сети на других узлах не добавили его в свои копии карты автоматически, им надо задать при старте ключ -A, запрещающий динамическую модификацию карты) и запустить для него соответствующий драйвер в режиме «неразборчивого» приема. В такой конфигурации вы сможете наблюдать все, что происходит в сети; правда, следует при этом иметь в виду, что двойная нагрузка на сетевую подсистему может немного «притормозить» машину при больших интенсивностях сетевого обмена.
Итак, для корректной и полноценной работы анализатора сетевого протокола необходимо:
1. Установить дополнительный сетевой адаптер, не описанный нигде в картах сети;
2. Запретить всем менеджерам сети динамическую модификацию карты ключом -A;
3. Запустить драйвер дополнительного адаптера в режиме «неразборчивого» приема, указав ему ключ -P.
Впрочем, функциональности, предоставляемой утилитой netsniff, для диагностики серьезных сетевых неполадок зачастую оказывается мало. Поэтому не лишним будет упомянуть здесь «старших братьев» утилиты netsniff - анализаторы сетевого протокола NetSniff II компании Cynosure и Photon Network Probe компании JoHeR, работающих в графической оболочке Photon и предоставляющих расширенные возможности по перехвату, фильтрации, обработке и отображению сетевого трафика.
Перечисленные утилиты диагностики в основном относятся к штатному сетевому протоколу QNX4 (FLEET). Для сетей, использующих стек протоколов TCP/IP, основными средствами диагностики в QNX4 являются [3]: ping (эхо-запрос узла IP-сети пакетами ECHO_REQUEST протокола ICMP); if_up (проверка доступности IP-интерфейса); arp (отображение и настройка параметров протокола разрешения адресов ARP); nslookup (опрос службы доменных имен DNS); rpcinfo (отображение информации RPC); showmount (отображение точек монтирования сервера NFS); traceroute (трассировка таблиц маршрутизации IP); netstat (отображение состояния и статистики IP-сети); семейство утилит snmp* (функции протокола управления сетью SNMP).
Кроме специализированных средств диагностики сетевой подсистемы, возможна дополнительная диагностика на уровне процессов путем анализа событий микроядра и событий трассировки.
Универсальные средства диагностики
Системные журналы высокого уровня. К универсальным средствам диагностики, не привязанным к конкретным подсистемам ОС, в первую очередь можно причислить системные журналы высокого уровня, доступ к которым по записи может иметь абсолютно любой процесс. Средства ведения таких журналов позаимствованы в QNX4 из операционной системы Unix и могут сослужить очень хорошую службу на поле битвы с отказами.
Основным средством ведения системных журналов высокого уровня является «демон» syslogd [2], в задачу которого входит обслуживание запросов от процессов на запись событий в системный журнал. Журнал ведется в виде обычного текстового файла (реально файлом журнала может служить любой байт-ориентированный файл, включая консоли и последовательные порты), поэтому для его чтения не нужно никаких специальных средств. По каждому событию в журнале фиксируется:
- дата и время возникновения события;
- идентификатор узла сети, на котором событие произошло;
- имя и/или идентификатор процесса или пользователя, запросившего запись события;
- текстовое сообщение, содержавшееся в запросе.
Каждый запрос рассматривается syslogd по двум критериям: «устройство» (facility), или источник запроса, и уровень (level) запроса. Оба эти параметра передаются процессом «демону» syslogd вместе с самим запросом. В зависимости от сочетания источника и уровня запроса, syslogd может произвести над запросом следующие действия:
- сделать запись в указанном файле журнала (этот файл должен существовать и быть доступным по записи);
- перенаправить запрос «демону» syslogd на другом узле сети;
- отобразить сообщение на консоли указанных (или всех) пользователей, в данный момент зарегистрированных в системе.
Настройки syslogd хранятся в файле /etc/syslog.conf и описывают, какие действия syslogd должен предпринимать в зависимости от источника и уровня запросов.
Обращение к «демону» syslogd из программы возможно через специализированный системный вызов syslog() [4]. Для «ручной» записи события в журнал (например, из сценария командного интерпретатора) можно использовать утилиту logger [2]. Пример использования утилит syslogd и logger:
[//11:root] /home/root # logger «More work for syslogd to do» [//11:root] /home/root # tail -n 5 /tmp/system.log May 11 16:57:01 node<<11>> popper[23596]: (v2.2) Unable to get canonical name of client, err = 35 May 11 17:00:02 node<<11>> System: RUN_UUCICO [23772]: starting May 11 17:00:02 node<<11>> System: RMLOCK: UUCP lock file /usr/spool/uucp/LCK..wplus found May 11 17:00:02 node<<11>> System: RUN_UUCICO [23772]: done May 11 17:00:12 node<<11>> root: More work for syslogd to do
В данном случае «демону» syslogd было предписано вести журнал в файле /tmp/system.log и записывать туда события любого уровня от любого источника. Содержимое соответствующего данному примеру файла конфигурации /etc/syslog.conf было следующим:
[//11:root] /home/root # cat /etc/syslog.conf # # Node 11 system logger config file # /tmp/system.log must exist! # *.* /tmp/system.log
Недостатком журналов высокого уровня по сравнению, скажем, с журналом событий трассировки, является то, что события фиксируются в них в текстовой форме, а значит, медленно, что может оказаться недопустимым при больших потоках событий в системах реального времени. Поэтому такие журналы в основном используются приложениями, к которым не предъявляется жестких временных требований.
Низкоуровневая диагностика процессов
С точки зрения операционной системы, процесс может завершиться двояко: самостоятельно (этот вариант считается нормальным, даже если завершение произошло из-за внутренней ошибки) или принудительно по сигналу (этот вариант считается ненормальным). В QNX4 предусмотрен механизм сохранения образа процесса в памяти в случае его нормального или ненормального завершения. Этот механизм реализуется утилитой dumper [2], которая может работать в двух режимах: индивидуальном и групповом. В первом случае ей указывается идентификатор одного конкретного процесса, за которым следует наблюдать, и образ этого процесса в памяти на момент завершения будет записан на диск независимо от причины, по которой процесс завершился. В групповом режиме утилита следит за всеми процессами в системе одновременно и реагирует только на ненормальные (принудительные) завершения по следующим сигналам:
- SIGABRT (запрос на прерывание выполнения);
- SIGBUS (ошибка четности);
- SIGFPE (ошибка операции с плавающей запятой или деление на ноль);
- SIGILL (выполнение недопустимой инструкции);
- SIGSEGV (нарушение границ сегмента).
Если процесс игнорирует или по-своему обрабатывает посылаемый ему сигнал, то завершения не происходит, и файл с образом процесса не создается. Сформированный утилитой dumper файл образа можно впоследствии проанализировать с помощью отладчика.
Если утилита dumper - скорее вспомогательное средство низкоуровневой диагностики, то основным шедевром в данной области, несомненно, является низкоуровневый 32-разрядный системный отладчик Debugger32 [2], который встраивается в загружаемый образ ОС и выполняется ниже уровня ядра, что позволяет с его помощью отлаживать код самого ядра, а также обработчики прерываний и исключительных ситуаций. Debugger32 поддерживает все стандартные функции низкоуровневого отладчика, является резидентным в оперативной памяти процессом и может быть активизирован в любой момент нажатием комбинации клавиш Ctrl-Alt-Esc. Также поддерживается удаленная отладка через последовательный порт.
К средствам низкоуровневой диагностики процессов также можно косвенно причислить утилиту spatch [2], позволяющую выполнять низкоуровневое редактирование областей памяти указанного процесса с заданными селектором и смещением.
Диагностика оборудования
Настройка аппаратуры обычно сводится к обнаружению и устранению аппаратных конфликтов и подбору корректных драйверов. В данном аспекте большой интерес представляют утилиты-«ловушки», имена которых заканчиваются на «trap» (nettrap, disktrap, crttrap, и т.п.) и которые выполняют автоопределение оборудования и рекомендуют соответствующие драйверы [2, 5]. Они занимаются тем, что записывают тестовые последовательности в адресное пространство ввода-вывода, где предположительно могут размещаться регистры внешних устройств, и «слушают» ответную реакцию. Процесс автоопределения базируется на том, что для каждого типа и модели оборудования известно, где расположены его регистры, и как оно должно «отзываться».
Проблемы начинаются там, где нерадивый производитель решает не идти на поводу у скучных педантов, соблюдающих гласные и негласные стандарты, а располагает регистры в адресном пространстве совсем не там, где от него этого ждут, или делает механизм «отклика» похожим на таковой у устройства другого типа, либо, еще того хуже, использует комбинацию этих методов. Типичным примером такого «безобразия» является семейство AHA4-совместимых адаптеров SCSI, ведущих себя при автоопределении как сетевые карты (попробуйте nettrap -v query). Впрочем, обычно бывает достаточно включить у «ловушки» режим подробного вывода (указав ключ -v), чтобы сразу увидеть, по каким адресам есть подозрение на наличие оборудования того или иного типа, а потом уже самому принять правильное решение.
«Ловушки» могут сами запускать драйверы, которые сочтут нужными (для этого задается параметр start). Однако злоупотреблять этим не стоит, поскольку, во-первых, «ловушкам» свойственно ошибаться, а во-вторых, запись в адресное пространство ввода-вывода может нарушить работу других устройств. Наиболее корректным решением в данном ключе было бы однократное выполнение автоопределения с последующим явным заданием имен и параметров драйверов в файлах инициализации.
Для устройств PCI в QNX4 предусмотрены несколько более расширенные возможности диагностики, тем более что стандартным «ловушкам» эти устройства не всегда оказываются по зубам. Просмотреть список и параметры установленных устройств PCI можно утилитой show_pci [2], которая по каждому устройству отображает его тип, идентификаторы (vendor ID), наименование поставщика (device ID), индекс PCI, используемые порты ввода-вывода и аппаратные прерывания.
Для контроля за параметрами шины PCI и управления режимами ее работы существует утилита pci_write, работающая с контроллерами PCI на уровне регистров и позволяющая просматривать и изменять содержимое регистров задержки (latency register) и управления (control register). Эта утилита применяется крайне редко и не входит в стандартную поставку ОС QNX4, ее исходный текст можно найти на FTP-сервере компании.
Для диагностики проблем, связанных с VESA2-совместимыми графическими адаптерами (а точнее, для проверки поддерживаемых видеорежимов и, опять же, корректности драйверов), существует утилита test_vesa2 [5]. Применение ее имеет смысл в двух случаях: для проверки, поддерживает ли данная конкретная видеоплата тот или иной видеорежим вообще, а также для проверки корректности работы графического драйвера в подсистеме Photon. Смысл второй проверки в том, что test_vesa2 переключает режимы, используя VESA BIOS, и не обращается к регистрам видеоадаптера напрямую, а значит, если нужный видеорежим утилитой test_vesa2 включается нормально, а драйвером, рекомендованным утилитой crttrap (автоопределение видеоадаптера), - нет, то произошла ошибка автоопределения, и драйвер подобран неверно.
Заключение
Совершенство штатных средств диагностики операционной системы, и в особенности глубина их интеграции с ее внутренними механизмами, определяет очень важный для разработчика фактор - быстроту и точность локализации неисправности. В умелых руках штатные средства диагностики QNX4 могут практически все рассказать о состоянии системы. Редкая ОС способна похвастаться таким свойством. Мало того, это позволяет говорить об определенной степени открытости системы, пусть не на уровне исходного текста, но в достаточной степени для понимания принципов ее функционирования вплоть до самых низкоуровневых деталей. И именно это обстоятельство может сыграть - и играет - основополагающую роль при выборе операционной системы там, где применение ПО с открытым исходным текстом по тем или иным причинам недопустимо или нежелательно.
Об авторе
Николай Горбунов — сотрудник компании SWD Real-Time Systems (Санкт-Петербург). С ним можно связаться по электронной почте по адресу n.gorbunov@swd.ru
Литература
[1] QNX OS System Architecture. - QNX Software Systems Ltd., 1996
[2] QNX OS Utilities Reference. - QNX Software Systems Ltd., 1996
[3] TCP/IP for QNX4 Utilities Reference. - QNX Software Systems Ltd., 1996
[4] Watcom C Library Reference. - QNX Software Systems Ltd., 1996
[5] Photon microGUI Applications and Utilities. - QNX Software Systems Ltd., 1996
[6] Krten, Rob - Getting Started With QNX4: A Guide for Realtime Programmers. - PARSE Software Devices, 1998
[7] Kolick, Frank - The QNX4 Real-Time Operating System. - Basis Computer Systems Inc., 1998
