

Высокочастотная архитектура и параллелизм на уровне команд (ILP) - вот два основных компонента реализации высокопроизводительных микропроцессоров. Архитектура Binary-translation Optimized Architecture (BOA) - реализация семейства процессоров IBM PowerPC, сочетает двоичную трансляцию с динамической оптимизацией. Мы используем эти методики, чтобы упростить аппаратное обеспечение за счет ликвидации разрыва между набором команд PowerPC RISC и еще более простыми аппаратными примитивами.
Такие процессоры, как Pentium Pro и Power4 пытаются добиться высокой частоты и приемлемого уровня ILP за счет реализации четкой схемы в аппаратном обеспечении: декодер команд в конвейере генерирует множество микроопераций, выполнение которых затем может планироваться в произвольном порядке. BOA полагается на альтернативный программный подход к декомпозиции сложных операций и генерации планов выполнения.
Программное обеспечение позволяет осуществлять более тщательное планирование и оптимизацию, чем аппаратное обеспечение. Таким образом, программное обеспечение можно использовать для исключения сложности аппаратного управления, в силу чего реализация процессора на основе двоичной трансляции способна обеспечить максимальную производительность, позволяя создавать высокочастотные процессоры, и, в то же время, использовать доступный параллелизм в коде.
Стимулом для нашей работы над BOA послужили более ранние проекты по двоичной трансляции, такие как FX!32 [1], и, в первую очередь Daisy [2,3], где применялась двоичная трансляция для планирования выполнения кода PowerPC для процессоров, использующих сверхбольшое командное слово(VLIW). Однако машина, описанная в этой статье, существенно ограниченней, в ней приоритет отдан не минимизации числа циклов на команду (cycles per instruction, CPI), а максимальному увеличению частоты процессора. За счет ограничения размера каждого процессорного ядра увеличивается количество ядер, которые могут размещаться на одной микросхеме для реализации симметричной многопроцесорной обработки на плате.
Динамическая оптимизация BOA предлагает значительные преимущества по сравнению с чисто статическими подходами к компиляции, которые компании Intel и Hewlett-Packard предлагают сейчас для архитектуры IA-64. При чисто статическом профилировании невозможно адаптироваться к изменениям в использовании программы. Кроме того, статическое профилирование требует, чтобы независимые производители программного обеспечения сами выполняли тщательное профилирование и генерировали различные исполняемые модули, оптимизированные для конкретного поколения процессоров.
Учитывая нежелание независимых производителей ПО выпускать код, допускающий традиционную оптимизацию при компилировании, может оказаться весьма непросто убедить их согласиться на более радикальные изменения в подходе к профилированию. Ни одна из этих проблем не возникает при реализации динамического подхода, предлагаемого в BOA, который действует незаметно для пользователя.
Стратегия трансляции в архитектуре BOA
В BOA двоичная трансляция прозрачна. Как показано на рис. 1, при загрузке BOA управление передается менеджеру виртуальных машин (virtual machine manager - VMM), который реализует систему двоичной трансляции. VMM - это часть микропрограммы BOA, хотя и невидимая для программного обеспечения, которое работает на этой архитектуре.
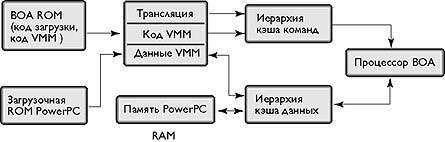 |
| Рис. 1. Компоненты системы BOA |
После инициализации BOA VMM интерпретатор BOA VMM вызывает загрузочную последовательность PowerPC. Более точно, система PowerPC, созданная на базе BOA, выполняет те же самые шаги, как и в случае «родной» реализации PowerPC. Реальное выполнение команд всегда остается под полным контролем BOA VMM, хотя центр управления не обязательно будет находиться в самом VMM, к компонентам которого относятся интерпретатор, транслятор, менеджер выполнения и менеджер памяти. Если центр управления находится не в самом VMM, он располагается в генерируемых VMM трассах (trace), при трансляции которых тщательно отслеживается, чтобы они передавали управление друг другу или обратно VMM.
Когда BOA VMM впервые видит фрагмент кода PowerPC, он интерпретирует его, чтобы реализовать семантику PowerPC. Во время этой интерпретации BOA собирает данные о профиле кода, которые позже будут использоваться для генерации кода. Интерпретация также позволяет отфильтровать редко выполняемый код, который не может существенно повлиять на стоимость трансляции.
Формирование трассы
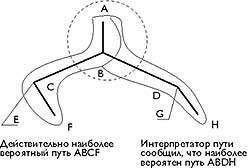 |
| Рис. 2. Формирование трассы вдоль пути ABDH. Эффективное окно операций может оказаться небольшим, если интерпретатор некорректно предскажет наиболее вероятный путь при выполнении группы операций PowerPC. Пунктирный круг показывает, как эффективное окно операций обрезается до пути AB из-за ошибочного предсказания пути, вместо того чтобы охватывать более длинный путь, такой как ABDH или ABCF |
После интерпретации точки входа последовательности операций PowerPC архитектура BOA «собирает» операции PowerPC, проходя вдоль одного пути выполнения кода PowerPC и размещает их в группе. Оттранслированный BOA код для трассы может располагаться в смежных ячейках памяти. В коде PowerPC компоновка кода - это функция программной структуры и решений, принимаемых на этапе компиляции. BOA, наоборот, использует динамическую информацию времени исполнения для генерации трасс, соответствующих наиболее вероятному пути выполнения программы. Эта последовательное размещение улучшает формирование кэша команд и дает возможность быстро выбирать нужные команды [4].
Рис. 2 показывает формирование трассы вдоль пути ABDH. BOA размещает этот путь в смежных ячейках памяти для того чтобы улучшить формирование кэша команд и выбор команд. Хотя формирование трасс весьма полезно, оно может привести к падению производительности, если BOA ошибочно предскажет путь. Рисунок 2 показывает, как может сократиться эффективный размер окна для обнаружения параллелизма из-за некорректного предсказания наиболее вероятного пути.
Код PowerPC может быть разделен на несколько трасс, причем часть трасс может перекрываться. Трассы имеют два типа выхода: краевой выход, представляет неверно предсказанный переход, и выходы по окончанию трассы, которые представляют точки останова (stopping points) трансляции. Разумный выбор точек останова может ограничить число транслируемых трасс и помочь увеличить производительность кэша.
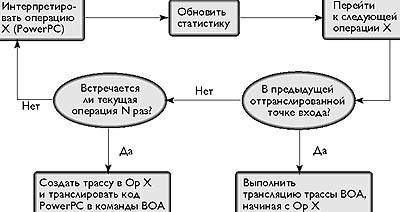 |
| Рис. 3. Как работает BOA |
Рис. 3 показывает, как работает BOA. Как только BOA видит, что трасса встречается большее число раз, чем предусмотрено пороговым значением, он ассемблирует код, начиная с точки входа в трассу PowerPC и транслирует его в трассу команд BOA для выполнения на базовом аппаратном обеспечении. В каждой точке перехода BOA следует по наиболее вероятному пути. Как только трасса во время трансляции достигает условного перехода, вероятность достижения каждой точки с начала трассы уменьшается. Когда вероятность опускается ниже порогового значения, BOA завершает трассу.
Оптимизация и планирование кода
Оптимизация, особенно полезная при работе с унаследованным кодом, может также увеличить производительность уже оптимизированного кода. В отличие от статического компилятора, динамический оптимизатор чтобы принять решения об оптимизации, не должен рассматривать всю управляющую логику программы. Вместо этого, из графа управляющей логики можно выделить короткие трассы, и, тем самым, отказаться от всех объединений управляющей логики. Отказ от объединений управляющей логики открывает широкие возможности для оптимизации, как показано на рис. 4.
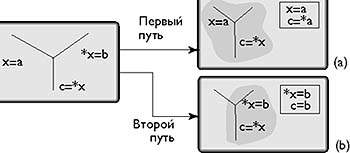 |
| Рис. 4. Динамическая оптимизация может открыть новые возможности оптимизации. На рисунке (a) создание копии порождает две независимых операции, которые могут быть запланированы в той же самой VLIW. На рисунке (b) наложение загрузки - сохранения удаляет зависимости через память. Создание копии c = b может открыть еще большие возможности |
Применение оптимизаций BOA в традиционном статическом компиляторе представляет собой особую сложность из-за трудности в выборе среди огромного множества путей выполнения имеющегося кода. Профилирование исполнения приложения и использование полученных результатов при последующей компиляции до некоторой степени снимают остроту проблемы. Помимо своих собственных преимуществ эти оптимизации сокращают число зависимостей и, тем самым, снижают глубину плана выполнения, что позволяет планировать в параллель большее число операций и более эффективно использовать устройства параллельного исполнения BOA.
Архитектура BOA планирует операции, чтобы максимально увеличить уровень ILP и использовать возможности спекулятивного исполнения, поддерживаемые базовой архитектурой. Современный подход к планированию предусматривает, что каждая операция выполняется как можно раньше после того, как получены все входные операнды, доступно функциональное устройство, на котором исполняется операция, а также есть свободный регистр, куда можно поместить результат операции.
Чтобы определить когда наступил приемлемый момент, BOA допускает применение нескольких методов оптимизации.
BOA одновременно выполняет планирование, оптимизацию и резервирование регистров. Подход неупорядоченного планирования, используемый транслятором BOA, затрудняет поддержку точных исключений, требуемую архитектурой PowerPC. Для решения этой задачи BOA использует смешанный аппаратно-программный подход, базирующийся на поддержке точных контрольных точек, когда трасса переходит границы, и возможности откатиться на более раннюю контрольную точку.
Чтобы инициировать процедуру контрольной точки BOA копирует все регистры в набор резервных регистров. В трассе BOA планирует команды неупорядоченно и переименовывает регистры, чтобы поддержать спекулятивное исполнение. BOA выполняет операции сохранения в том порядке, в каком они указаны в оригинальной программе, но помечает их как незавершенные, поэтому если возникает исключение, они могут быть аннулированы.
Когда трасса заканчивается при нормальном выполнении, регистры PowerPC передаются в регистры контрольной точки, незавершенные операции сохранения маркируются как завершенные, а выполнение переходит к следующей трассе. Когда возникает исключение, система очищает рабочие регистры, аннулирует все незавершенные операции сохранения и восстанавливает состояние процессора из регистров контрольной точки. Затем BOA VMM вводит режим интерпретации и выполняет упорядоченные команды до тех пор, пока не обнаруживается условие и место исключения.
Системные вопросы
Необходимо уделять особое внимание неупорядоченным операциям загрузки во время планирования и исполнения с тем, чтобы они соответствовали семантике PowerPC, предполагающей упорядоченное размещение в памяти. BOA присваивает каждой операции загрузки и сохранения в трассе число, указывающее ее порядок следования в трассе. Если аппаратное обеспечение обнаруживает, что операция загрузки с большим порядковым номером выполняется раньше, чем операция сохранения с меньшим порядковым номером, BOA сигнализирует об исключении, восстанавливает последнюю контрольную точку и входит в режим интерпретации. В результате BOA повторно выполняет сомнительную операцию загрузки, чтобы получить корректные значения.
Попытки обратиться к некэшируемой (noncacheable) памяти, такой как место ввода/вывода, также оказываются сомнительными. Выполнение таких операций не разрешается, поскольку они могут иметь побочные эффекты, такие как изменение содержимого жесткого диска. Чтобы избежать этой проблемы BOA использует аппаратное обеспечение для того чтобы запрещать и выявлять любые операции некэшируемой загрузки, требующие специальной программной обработки.
При переходе между трассами оттранслированных команд BOA размещает операции с реальными адресами загрузки (load real address - LRA) в начале каждой трассы, т. е. с помощью планировщика. При выполнении операции LRA проверяется что буфер преобразования адресов и таблицы страниц по-прежнему отображаются на виртуальный адрес начала трассы так же, как это было, когда трасса транслировалась изначально. Если изменения в таблице страниц могут повлиять на корректность трансляции, BOA инициирует прерывание, удаляет трассу и начинает интерпретацию по корректному адресу.
Архитектура и реализация
BOA создавалась как надежная архитектура с набором команд, специально предназначенных для поддержки двоичной трансляции. Мы не предполагали, что архитектура станет платформой для кода, написанного пользователем, а вместо этого предоставили несколько примитивов и ресурсов, которые позволяют ей выполнять качественную двоичную трансляцию.
Архитектура набора команд
В некотором смысле команды BOA эквивалентны микрокодовым операциям, которые представляют реальный машинных язык, используемый для реализации общедоступной архитектуры набора команд (ISA). Набор команд BOA не доступен в режиме супервизора или для пользователя PowerPC и может меняться от реализации к реализации.
Примитивы BOA напоминают примитивы PowerPC как по семантике, так и по функциональности. Однако не все операции PowerPC имеют эквивалентный примитив BOA. Предполагается, что многие операции PowerPC будут преобразовываться в последовательность более простых примитивов BOA, чтобы позволить создавать высокочастотные реализации. Семантика команд и формат данных BOA также напоминают семантику и формат данных PowerPC, что позволяет обойтись без дорогостоящих преобразований форматов данных. Чтобы поддержать планирование и спекулятивное исполнение кода, использующее переименование регистров, BOA предоставляет в два раза больше машинных регистров для каждого класса регистров PowerPC.
BOA использует статически планируемый, сжатый формат команд, аналогичный архитектуре IA-64. Параллельная команда может одновременно выдавать до шести операций за цикл, как показано на рис. 5. Чтобы гарантировать эффективную компоновку памяти BOA оформляет операции в 128-разрядные связки, каждая из которых содержит три операции. Каждая операция состоит из 39 разрядов и еще одного разряда остановки. Таким образом, три операции занимают 120 разрядов. Еще 8 разрядов остается под возможные в будущем усовершенствования системы.
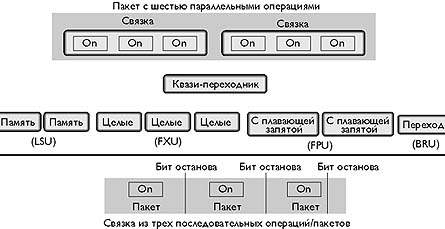 |
| Рис. 5. Формат команд BOA |
Как показано на рис. 5, генерация кода гарантирует, что между операциями в пакете нет никаких зависимостей, поэтому они могут без опасений выдаваться параллельно. Шесть слотов выдачи могут содержать операции, предназначенные для девяти различных устройств исполнения: два устройства памяти, два устройства для целочисленных операций, два для операций с плавающей запятой, и одно для переходов. В пакете может выдаваться любая комбинация операций, но чтобы упростить декодирование и рассылку команд, в пакете операции должны кодироваться в этом порядке.
Все операции, на самом деле, имеют дополнительный цикл задержки, поскольку BOA не предусматривает параллельных ветвей. Должен пройти как минимум один цикл, прежде чем результат может быть использован последующей операцией. Запрещение опережения результата позволяет сократить время за счет разрешения всему этапу конвейера рассылать результаты каждому из функциональных устройств.
Реализация
На рис. 6 показано содержимое процессорного модуля BOA, изображенного на рис. 1. Чтобы добиться высокой частоты, процессор предполагает простую аппаратную архитектуру с конвейером средней длины. Базовый процессор отвечает за обеспечение продолжения выполнения команды в случае промаха при обращении к кэш-памяти (cache miss). Это позволяет операциям обращения к памяти и независимым командам перекрываться до тех пор, пока зависимая операция не выдаст остановку (stall) или BOA не обратиться к данным из ROM. Процессор также обеспечивает динамическую поддержку неупорядоченных операций загрузки и сохранения, разъединенные конвейеры выбора и исполнения, а также схему подтвержденной рециркуляции для управления конвейером.
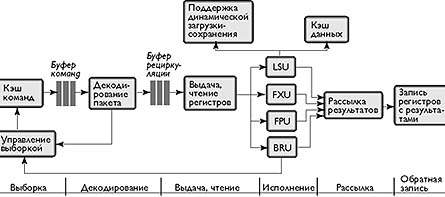 |
| Рис. 6. Процессор BOA выполняет команды одновременно в двух устройствах загрузки-сохранения (LSU), четырех устройствах для операций с целыми числами (FXU), двух устройствах для операций с числами с плавающей запятой (FPU) и устройстве выполнения перехода (BRU) |
Хотя динамическое планирование и предсказание переходов подтвердили свою ценность в реализациях суперскалярных процессоров, мы считаем, что при неумеренном использовании они могут ограничивать частоту. В аппаратном обеспечении BOA могут выполняться следующие четыре динамических процесса:
- демонстрация состояния регистров позволяет продолжать выдачи упорядоченных команд при наличии независимых остановок при доступе к памяти (memory stall);
- очереди команд загрузки и сохранения проверяются на наличие конфликта адресов между операциями загрузки и сохранения, переупорядоченных во время трансляции;
- буферы команд отделяют конвейер выбора от конвейера исполнения, чтобы скрыть некоторые остановки при выборе команд (instruction fetch stall);
- метод управления конвейером позволяет конвейеру продвигаться во время каждого цикла процессора, что упрощает его управление.
Если предположить, что планирование выполнения кода осуществляется корректно конвейер исполнения будет останавливаться только остановки при доступе к памяти. Вместо проверки существования остановки перед работой, конвейер продвигается на каждом цикле. Когда выдается пакет, он также копируется в буфер рециркуляции, показанный на рис. 6. Буфер цикла содержит копию каждого пакета, который исполняется в данный момент. Остановки должны игнорироваться до окончания процесса исполнения. К примеру, если случился промах при доступе к кэшу данных и значение не возвращается, пакет с соответствующей операцией загрузки будет помечен нулем, как и любой другой пакет, который был выдан после этого пакета с операцией загрузки. Затем буфер цикла повторно выдает пакет с операцией загрузки и все последующие пакеты. Если повторно выданный пакет также сталкивается с промахом при обращении к кэш-памяти, процесс повторяется. Эти повторения возникают до тех пор, пока все остановки не будут устранены.
Более новые технологии показывают, что задержки при передаче (wire delay) приходят на смену логическим задержкам (logic delay) в качестве фактора, ограничивающего тактовую частоту. Для BOA это значит, что следует особое внимание уделять логике управления процессом. Микроархитектура BOA адаптируется к предполагаемому относительному увеличению задержек при передаче в будущих усовершенствованных процессоров КМОП, позволяя передавать данные через ядро процессора в течение всего цикла.
Рис. 7 показывает производительность BOA в циклах на команду PowerPC в системных тестах SPECint95 и TPC-C и детализирует вклад всех системных компонентов.
Показатели производительности свидетельствуют, что двоичная трансляция заслуживает внимания в качестве возможной реализации в будущих высокопроизводительных системах. Как описано во врезке «Высокочастотная обработка», мы рассчитываем, что BOA вскоре достигнет тактовой частоты 2 ГГц.
Об авторах
Майкл Жвинд работает в группе высокопроизводительной архитектуры VLSI в исследовательском центре IBM им. Уотсона. К области его научных интересов относятся компиляторы, бинарная трансляция, компьютерная архитектура, аппаратно-программные решения и процессоры, адаптированные к работе конкретного приложения. С ним можно связаться по адресу mikeg@watson.ibm.com.
Эрик Олмен - работает в группе высокопроизводительной архитектуры VLSI в исследовательском центре IBM им. Т. Дж. Уотсона и был одним из создателей проекта DAISY. Степень доктора компьютерных наук он получил в университете МакГилла. С ним можно связаться по адресу erik@watson.ibm.com.
Сумедх Сатхаи - сотрудник исследовательского центра IBM им. Уотсона. Его интересуют вопросы, связанные с компьютерной архитектурой и микроархитектурой, параллелизм на уровне команд и бинарная трансляция. С ним можно связаться по адресу sathaye@watson.ibm.com.
Пол Ледак - вице-президент по вопросам разработки серверной архитектуры компании IBM. Большую часть своей карьеры он руководил и принимал непосредственное участие в создании микропроцессоров IBM для процессорных архитектур PowerPC и x86.
Дэвид Аппензеллер - менеджер по разработке микропроцессора PowerPC из центра IBM Burlington.
Литература
[1] R. Sites et al., «Binary Translation,» Digital Technical J., Dec. 1992, pp. 137-152
[2] K. Ebcioglu and E. Altman, «DAISY: Dynamic Compilation for 100 Percent Architectural Compatibility,» Proc. ISCA24, ACM Press, New York, 1997, pp. 26-37
[3] K. Ebcioglu et al., «Execution-Based Scheduling for VLIW Architectures,» Proc. Europar99, Lecture Notes in Computer Science 1685, Springer Verlag, Berlin, 1999, pp. 1269-1280
[4] K. Pettis and R.C. Hanson, «Profile Guided Code Posi-tioning,» Proc. 1990 SIGPLAN PLDI, ACM Press, New York, 1990, pp. 16-27
[5] S. Sathaye et al., «BOA: Targeting MultiGigahertz with Binary Translation,» IEEE TCCA Newsletter, Fall 1999, pp. 2-11
[6] E. Altman et al., BOA: The Architecture of a Binary Translation Processor, IBM Research Report RC21665, IBM, Yorktown Heights, N.Y., 2000
Высокочастотная обработка
Документ The 1999 International Technology Roadmap for Semiconductors () предусматривает создание высокопроизводительного микропроцессора с тактовой частотой 2 ГГц к середине этого десятилетия, в то время как технология КМОП обеспечит увеличение производительности Field Effect Transistor только на 190%. Число транзисторов на микросхему вырастет по сравнению с обычными в 1999 году возможностями КМОП на 0,18 мкм. Чтобы добиться и превзойти запланированные результаты по длительности цикла микроархитектура BOA допускает самое большее время цикла в 700 пикосекунд в современной технологии КМОП на 0,18 мкм при номинальных процессорных и температурных условиях. Эта длительность цикла более, чем на 50% меньше, чем для архитектуры на 0,25 мкм, масштабированной до 0,18 мкм и в ближайшие несколько лет позволит добиться тактовой частоты больше 2 ГГц.
Dynamic and Transparent Binary Translation, Michael Gscwind, Erik Altman, Sumedth Sathae, Paul Ledak, David Appenzeller. IEEE Computer, March 2000, pp. 54-59, Reprinted with permission, Copyright IEEE CS, 2000, All rights reserved.
