

В данной статье показаны способы повышения производительности суперскалярных микропроцессоров на примере архитектур Alpha 21364 и Power4. Разбираются вопросы перехода к принципиально новой, так называемой мультитредовой архитектуре, позволяющей существенно изменить возможности нынешних микропроцессоров.
История развития микропроцессоров в полной мере подчиняется диалектике эволюционного усовершенствования архитектуры. Начиная от машины ENIAC, содержавшей 19 тыс. ламп, производительность компьютеров росла на порядок каждые пять лет [1,2]. Большое число транзисторов на современном кристалле делает возможным применить в одном микропроцессоре все известные способы повышения производительности, сообразуясь только с их совместимостью. Однако для полного использования возможностей аппаратуры уже недостаточно ограничиться только аппаратно реализованными алгоритмами управления, достаточно единообразно функционирующими во всех ситуациях. Поэтому при реализации усложненной логики управления используется программное обеспечение, для поддержки которого вводятся дополнительные команды и регистры управления микропроцессора. В свою очередь, формирование программ для потактного управления микропроцессором под силу только компилятору. Таким образом, в современных микропроцессорах возник симбиоз программных и аппаратных средств. Этот симбиоз представляет собой нечто большее, нежели эволюционный ход развития, а смену самого направления развития микропроцессоров, выражающуюся в переходе к мультитредовым и многопроцессорным архитектурам.
С позиции реализации такого симбиоза открываются следующие способы повышения производительности:
- увеличение емкости памяти внутри кристалла;
- увеличение количества арифметико-логических устройств;
- введение блоков обработки мультимедийных данных, ранее использовавшихся, например, в сигнальных микропроцессорах;
- интеграция на кристалле функций управления памятью и периферийными устройствами, для исполнения которых в традиционных микропроцессорах используются наборы микросхем («чипсеты»);
- интеграция на кристалле интерфейсов сетевых и телекоммуникационных систем, что позволяет соединять эти микропроцессоры друг с другом и телекоммуникационными и вычислительными сетями без дополнительных адаптеров.
Увеличение объема внутрикристальной памяти
Организация внутрикристальной памяти
Современное состояние микроэлектроники характеризуется растущим разрывом между скоростью обработки данных в микропроцессорах и быстродействием внекристальной оперативной памяти. Можно уже говорить о том, что время выполнения однотактной команды микропроцессора на порядок и более меньше времени доступа к памяти вне кристалла. В таких условиях прибегают к построению многоуровневой иерархической памяти с использованием внутрикристальной кэш-памяти и применению мультитредовой архитектуры МТА, в которой задержка доступа в память в одном процессе «скрывается» за временем выполнения других процессов [3].
Кроме того, для уменьшения разрыва в быстродействии между процессором и памятью развивается технология встроенной памяти DRAM, позволяющая в едином производственном цикле формировать на одном кристалле логические схемы и схемы динамической памяти. Следует отметить, что идея создания однокристального компьютера всегда была популярной, и сегодня проблема размещения на одном кристалле встраиваемого блока памяти EDRAM (embedded DRAM) достаточно большой емкости и микропроцессорного ядра близка к своему решению. Корпорация IBM объявила о создании компактной ячейки динамической памяти размером 0,62 мкм2, что всего в 1,5 раза превышает размер ячейки в 64-мегабитной микросхеме DRAM [4]. Блок EDRAM емкостью 16 Мбит занимает площадь 20,8 мм2. При этом пропускная способность EDRAM достигает 50 Гбайт/с.
Кэш-память с несколькими уровнями
Постоянный рост емкости кэш-памяти микропроцессора сопровождался усложнением процесса управления, что вылилось в переход от кэш-памяти со сквозной записью к кэш-памяти с буферизированной и обратной записями. При этом в микропроцессорах использовалось программное управление режимом записи кэш-строк путем установки бита, переключающего режимы сквозной и обратной записи кэш-строки [5]. Однако в случае промаха в кэш-памяти возрастающий разрыв между временем выполнения команды и временем доступа в память привел к недопустимо большим потерям производительности. Поэтому в микропроцессоры были введены команды управления кэшированием. Например, в Pentium III появились команды нового типа, обеспечивающие: запись данных из регистров в память, минуя кэш; чтение данных из памяти в регистры, минуя кэш; запись данных из памяти выборочно в кэш первого и второго уровня; запись данных из кэш-памяти и буферов записи в память.
Команды упреждающего кэширования позволяют заранее загружать в кэш нужные данные, обеспечивая возможность записи данных в кэш-память различных уровней, что уменьшает задержки, связанные с доступом к основной памяти. Команды записи данных из кэш-памяти и буферов записи позволяют поддерживать когерентность кэш-памяти и основной памяти при выполнении, например, команд упреждающего кэширования. Однако вряд ли прагматично требовать управления кэш-памятью при программировании на языках высокого уровня - распределение памяти всегда было одной из функций компилятора. Тем более логично потребовать чтобы компилятор выполнял управление кэш-памятью, сокращая простои процессора в ожидании данных.
Наборы регистров в мультитредовой архитектуре
Другой, по сравнению с организацией кэш-памяти, метод построения внутрикристальной памяти применяется в мультитредовой архитектуре [6], основная особенность которой - использование совокупности регистровых файлов. Эта архитектура решает проблему разрыва между скоростью обработки в процессоре и временем доступа в основную память за счет переключения в каждом такте процессора на работу с очередным регистровым файлом. Каждый регистровый файл обслуживает один вычислительный процесс - тред (поток). Всего в каждом процессоре имеется n регистровых файлов, поэтому запрос, выданный в основную память каждым из потоков, может обслуживаться в течение n-1 такта, вплоть до момента, когда процессор снова переключится на тот же регистровый файл. Выбор значения n определяется отношением времени доступа в память ко времени выполнения команды процессором. Конечно, задача формирования потоков из последовательной программы должна, по возможности, решаться компилятором. В противном случае будущее этой архитектуры окажется ограниченным узкой проблемной ориентацией.
Компания Tera объявила о разработке проекта мультитредового микропроцессора, реализующего процессор МТА [7]. Level One, приобретенная Intel, выпустила мультитредовый сетевой микропроцессор IXP1200, содержащий в своем составе 6 четырехтредовых процессоров [8]. IBM анонсировала проект компьютера Blue Gene, кристалл микропроцессора которого включает 32 восьмитредовых процессора. В кристалл встроена память EDRAM, организованная в 32 блока. Каждый блок соответствует одному из 32 процессоров и имеет шину доступа 256 разрядов. Поскольку EDRAM обладает высокой пропускной способностью и малой задержкой, то при восьмитредовой структуре процессора становится возможным отказаться от кэш-памяти, вместо которой между процессором и памятью используется небольшая буферная память [9].
Увеличение числа и состава функциональных устройств
Увеличение числа функциональных устройств
Память - ресурс, непосредственно не производящий вычислений. Увеличение емкости памяти на кристалле дает прирост производительности, но после достижения некоторой величины этот прирост оказывается существенно меньше, чем обеспечиваемый использованием того же ресурса транзисторов кристалла для построения дополнительной совокупности функциональных устройств. Основное препятствие на пути повышения производительности за счет увеличения числа функциональных устройств - это организация загрузки этих устройств полезной работой, которую можно проводить динамически путем исследования программного кода на стадии исполнения и статически на уровне компиляции программ. Первый подход используется в суперскалярных микропроцессорах, второй - в микропроцессорах с длинным командным словом [10].
Весьма привлекательно выглядит намерение возложить на компилятор выявление команд, допускающих параллельное исполнение на разных функциональных устройствах. Однако существуют проблемы, которые нельзя решить на уровне компиляции [11]. Поэтому наряду со статическим распараллеливанием компилятором на уровне команд должны развиваться аппаратные реализации методов динамического внеочередного исполнения команд микропроцессоров.
Во время компиляции трудно, а иногда и невозможно установить длительность исполнения отдельных команд, в связи с тем, что возникают промахи при обращении к кэш-памяти, арифметические переполнения, формирование недопустимых адресов и другие исключительные ситуации. Кроме того, определение зависимости между командами записи в память и чтения из памяти может быть выполнено только после вычисления адресных выражений, что возможно лишь в ходе исполнения программы. Команды, выбранные на исполнение, могут следовать друг за другом в неизменном порядке, определяемом при их выборке из памяти, либо их порядок может изменяться, позволяя исполнять команды, для которых готовы операнды. Внеочередное исполнение команд предполагает следующие механизмы:
- переименование регистров с целью устранения ресурсных зависимостей «запись после чтения» и «запись после записи»;
- предсказание переходов;
- динамическое назначение команд на исполнительные устройства, включая изменение порядка исполнения по сравнению с порядком, в котором эти команды были извлечены.
Динамическое назначение команд на исполнительные устройства реализуется резервирующей станцией, состоящей из совокупности элементов ассоциативной памяти. Каждый из элементов содержит позиции для размещения кода операции, наименования первого операнда, его значения, признака доступности первого операнда, наименования второго операнда, его значения, признака доступности второго операнда и наименования регистра результата. Когда команда завершает исполнение и вырабатывает результат, то наименование результата сравнивается с наименованиями операндов в резервирующей станции. Если в резервирующей станции обнаруживается команда, ждущая этого результата, то данные записываются в соответствующую позицию и устанавливается признак их доступности. Когда у команды доступны все операнды, инициируется ее исполнение. Резервирующая станция следит за доступностью операндов и при получении команды все готовые операнды из регистрового файла переписываются в поля этой команды. Когда все операнды готовы, команда исполняется.
Эффективность применения внеочередного исполнения команд демонстрируется таблицей 1.
Таблица 1. Эффективность применения внеочередного исполнения коман
| Микропроцессор | SPECint | Ускорение | |
| R5000/180 МГц | Mips R10000/180 МГц | 4,82/8,59 | 1,78 |
| Pentium/200 МГц | Pentium Pro/200 МГц | 5,47/8,09 | 1,48 |
| Alpha 21164/600 МГц | Alpha 21264/575 МГц | 19,3/30,3 | 1,57 |
Процесс функционирования процессора с внеочередным исполнением команд иллюстрирует рис. 1. В качестве примера на рис.2 приведена структура процессора Alpha 21264 с внеочередным исполнением команд.
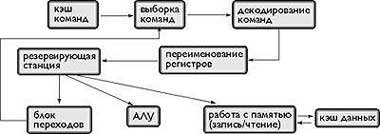 |
| Рис. 1. Процесс функционирования процессора с внеочередным исполнением команд |
Мультимедийные расширения
Многие производители расширяют сегодня функциональные возможности выпускаемых микропроцессоров за счет введения специализированных блоков для мультимедийных приложений. Подобный блок имелся уже в микропроцессоре второго поколения Intel 80860 [5], и на некоторых приложениях его использование давало существенный прирост производительности. Аналогичные блоки включены и в другие микропроцессоры Intel (ММХ-расширение системы команд Pentium и 70 новых SIMD-команд Pentium III), AMD (3D Now!), Sun (VIS SPARC), Compaq (Alpha MVI), HP (PA-RISC MAX2), SGI/Mips (MDMX), Motorola (PowerPC AltiVec) [12].
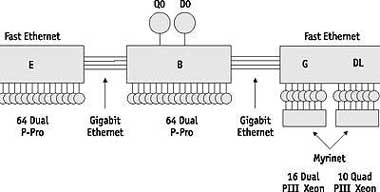
Рис. 2. Структура процессора Alpha 21264 с внеочередным исполнением команд
Возможны различные варианты встраивания команд мультимедийной обработки в систему команд микропроцессора: на уровне функционального блока, использующего общий с другими блоками файл регистров (Pentium MMX) или на уровне отдельного процессора со своим регистровым файлом, используя разнесенную (decoupled) архитектуру [10]. Последний вариант применен в Pentium III и PowerPC AltiVec.
Команды мультимедийной обработки задают в режиме SIMD-процессора параллельную обработку нескольких единиц данных, представленных, как правило, малоразрядными (8, 16, 32) числами в формате с фиксированной точкой. Однако это не исчерпывает всех текущих потребностей и, например, в Pentium III введена параллельная обработка в режиме SIMD-процессора четырех 32-разрядных операндов в формате с плавающей точкой.
Интеграция функций
Системы на одном кристалле
С ростом количества транзисторов на кристалле стало возможно построение микросхем, в которых микропроцессор вместе с памятью на кристалле выступает в роли одного из составных элементов (ядер) систем на одном кристалле (SOC — system on chip) [2,13]. В кристалле интегрируются функции, для исполнения которых обычно используются наборы микросхем, сетевые платы и другие специализированные микросхемы. Это, с одной стороны, позволяет существенно увеличить пропускную способность между компонентами кристалла по сравнению с пропускной способностью между разными кристаллами, реализующими по отдельности каждую функцию. И, как следствие, поднять производительность систем. С другой стороны, при уменьшении количества кристаллов резко упрощается изготовление и монтаж плат, что ведет к повышению надежности и снижению стоимости систем.
В кристалл интегрируются интерфейсы сетевых и телекоммуникационных систем, что позволяет без дополнительных адаптеров соединять микропроцессоры друг с другом, с телекоммуникационными и вычислительными сетями. Интеграция коммуникационных интерфейсов в кристалл микропроцессора была впервые проделана в транспьютерах [10]. Однако это были упрощенные интерфейсы, позволяющие связываться лишь с другими транспьютерами. В процессорах Motorola MPC8260 поддерживается уже множество телекоммуникационных протоколов, включающих, например, 10/100 Mбит/с Ethernet, 155 Mбит/с ATM, 256 каналов 64 Кбит/с HDLC. Компания Motorola предлагает два семейства кристаллов, в которых в качестве ядра используется PowerPC 603e - это семейство на основе технологий AltiVec и PowerQUICC [10].
Системы с распределенной разделяемой памятью
Ориентация разработчиков на создание систем с распределенной разделяемой памятью привела к интеграции в кристалл блока управления когерентностью многоуровневой памяти на кристалле и распределенной внешней памяти, доступ к блокам которой выполняется через интегрированную в тот же кристалл коммуникационную среду. В качестве примеров этого подхода можно назвать микропроцессоры Alpha 21364 [14,15], Power4 [16], а также Blue Gene[9]. В качестве ядра у микропроцессора Alpha 21364 используется Alpha 21264, но на кристалле интегрированы: шестивходовый частично ассоциативный кэш второго уровня емкостью 1,5 Мбайт; контроллер памяти, поддерживающий работу с динамической памятью Direct Rambus; сетевой интерфейс.
Для динамического исполнения в микропроцессоре Alpha 21364 (рис.3) рассматриваются сразу 80 команд - больше, чем у любого другого процессора. После декодирования команда помещается в очередь к устройствам с фиксированной или плавающей точкой. Команды, получившие все операнды, конкурируют за доступ к функциональным устройствам: двум блокам операций с плавающей точкой, выполняющим сложение, умножение, деление, извлечение квадратного корня и четырем целочисленным устройствам (двум общего назначения и двум адресной арифметики). Последние наряду с простыми арифметическими и логическими операциями выполняют все команды загрузки и сохранения как целочисленных данных, так и данных в формате с плавающей точкой. Целочисленные АЛУ общего назначения выполняют арифметические и логические операции, сдвиги и переходы. Одно из целочисленных АЛУ выполняет также умножение, а другое - новый набор команд обработки видеоданных. Для динамического переименования доступны 41 из 80 целочисленных регистров и 41 из 72 регистров с плавающей точкой.
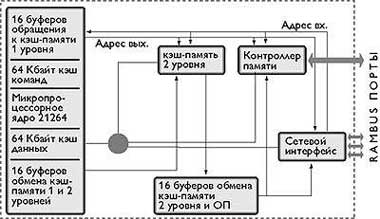 |
| Рис.3. Архитектура микропроцессора Alpha 21364 |
Обмен данными между кэшами первого и второго уровня, кэшем первого уровня и оперативной памятью буферизирован (по 16 буферов для каждого уровня памяти).
Интеграция компонентов в одном кристалле позволяет существенно упростить и удешевить системы, реализуемые на основе данного микропроцессора. Благодаря встроенному сетевому интерфейсу упрощается объединение микропроцессоров в высокопроизводительные многопроцессорные системы. Сетевой интерфейс поддерживает 4 межпроцессорных соединения типа «точка-точка» со скоростью передачи данных 10 Гбайт/с каждый при задержке 15 нс. Сетевой интерфейс обеспечивает когерентность кэшей в многопроцессорной системе и реализует асинхронный обмен данными с адаптивной маршрутизацией. Пример структуры многопроцессорной системы на основе микропроцессоров Alpha 21364 показан на рис. 4.
 |
| Рис. 4. Пример структуры многопроцессорной системы |
Микропроцессор имеет пятый порт - ввода-вывода, работающий на скорости обмена 3 Гбайт/с.
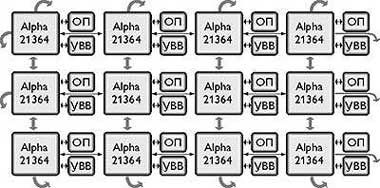
Процессоры Alpha 21364 и Power4 объединяет общность архитектурных решений: суперскалярная микроархитектура, внеочередное исполнение команд, большая кэш-память на кристалле, специализированный порт для основной памяти, а также высокоскоростные линки для объединения микропроцессоров в системы с архитектурой NUMA с распределенной разделяемой памятью (distributed shared memory — DSM).
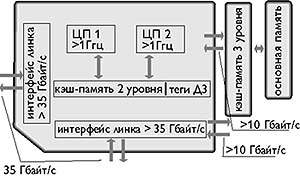 |
| Рис. 5. Архитектура Power4 |
Каждый процессор Power4 (рис. 5) подобен Power3 и имеет два конвейерных блока для работы с 64-разрядными операндами с плавающей точкой на частоте 1 ГГц, выбирающих на исполнение по 5 команд каждый и 2 блока для работы с памятью. В процессорах реализуется внеочередное исполнение команд. Микропроцессор реализован на кристалле, содержащем 170 млн. транзисторов. Для достижения тактовой частоты 1,1 ГГц стадии конвейеров имеют задержку 8-10 вентилей.
Процессоры содержат раздельные кэш-памяти команд и данных первого уровня емкостью по 64 Кбайт каждая. Кроме того, имеется разделяемая (общая) кэш-память на кристалле второго уровня и внешняя кэш-память третьего уровня. Для образования мультипроцессорных конфигураций имеются 3 линка с суммарной пропускной способностью 45 Гбайт/с.
Наряду с параллелизмом уровня команд (ILP), процессор использует параллелизм уровня тредов (TLP). Динамическое выявление параллелизма позволяет предотвращать простои процессора при трудно выявляемых статически исключительных ситуациях, например, промахе в кэш-памяти. Power4 изготавливается по 0,18-микронной технологии SOI («кремний на изоляторе») с медными проводниками и 5 слоями металла на кристалле площадью 400 мм2.
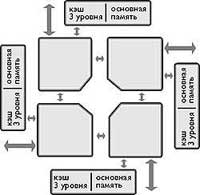 |
| Рис. 6. Пример объединения Power4 в фрагмент многопроцессорной системы |
Отличительная особенность Power4 - наличие кэш-памяти второго уровня, разделяемой двумя процессорами кристалла, а также внешними процессорами других кристаллов через линки шириной 16 байт, работающие на тактовой частоте более 500 МГц, что обеспечивает пропускную способность свыше 8 Гбайт/с. Суммарная пропускная способность 4 линков составляет более 35 Гбайт/с. При объединении 4 кристаллов и их размещении, как показано на рис. 6, проводники линков могут быть достаточно короткими и, что важно, прямыми.
Физически кэш-память второго уровня емкостью около 1,5 Мбайт состоит из трех одинаковых блоков, доступ к которым выполняется через коммутатор с пропускной способностью на уровне 100 Гбайт/с. Протокол когерентности обеспечивает размещение данных, поступивших по линкам, в том блоке кэш-памяти, который использовался для размещения данных последним.
Порт кристалла Power4, предназначенный для подключения кэш-памяти третьего уровня емкостью до 32 Мбайт имеет ширину 16 байт для каждого из двух направлений пересылки данных. Порт функционирует на 1/3 от тактовой частоты процессоров кристалла, что обеспечивает пропускную способность к памяти на уровне 10 Гбайт/с. Теги кэш-памяти третьего уровня расположены внутри кристалла, что ускоряет реализацию протокола когерентности. Для работы с основной памятью может быть использована восьмипоточная программная предвыборка данных непосредственно в кэш-память первого уровня на кристалле. Пересылать можно одновременно до 20 строк кэша.
Каждый из двух процессоров Power4 имеет систему команд IBM ISA, реализованную в RS/6000 и AS/400 и полностью совместимую с системой команд Power PC. Сохранение системы команд, вызванное поддержкой двоичного кода пользователей, потребовало применения как однотактных команд, так и микропрограмм и даже прерываний для программной реализации наиболее сложных команд ISA.
Однокристальные мультитредовые и мультискалярные системы
Современные микропроцессоры, например, Alpha 21264 и Pentium III, относятся к однотредовым, использующим параллелизм уровня команд, выявляемый либо статически (компилятором), либо динамически (аппаратурой микропроцессора), либо комбинацией этих двух методов. Параллелизм уровня тредов при использовании этих микропроцессоров может быть выявлен только статически. Динамическое выявление параллелизма уровня тредов в рамках архитектур однотредовых процессоров практически невозможно, так как требует просмотра большого количества команд на предмет их одновременного исполнения - расширения окна исполнения. Это влечет за собой усложнение логических схем управления внеочередным исполнением команд, что может привести к снижению тактовой частоты микропроцессора. Для разрешения данного противоречия предлагаются мультитредовые и мультискалярные микропроцессоры [17-19].
Основы мультитредовой архитектуры
При всем различии подходов к созданию мультитредовых микропроцессоров, общим для них является введение множества устройств выборки команд, каждое из которых организует окно исполнения для одного треда. В рамках одного треда выполняется предсказание переходов, переименование регистров, динамическая подготовка команд к исполнению. Тем самым, общее число команд, находящихся в обработке, значительно превышает размер окна исполнения однотредового процессора, с одной стороны, и тактовая частота не лимитируется размером окна исполнения, с другой стороны.
Выявление тредов может выполняться компилятором при анализе исходного кода на языке высокого уровня или исполняемого кода программы. Однако компиляторы не всегда могут разрешить проблемы зависимостей при использовании регистров и ячеек памяти между тредами, что требуется уже в ходе исполнения тредов. Для этого в микропроцессор вводится специальная аппаратура условного исполнения тредов, предусматривающая возврат с отбрасыванием наработанных результатов при обнаружении нарушения зависимостей между тредами. Нарушением зависимости, например, может служить запись по вычисляемому адресу в одном треде в ту же ячейку памяти, из которой выполняется чтение, которое должно следовать за этой записью, в другом треде. В случае, если адреса записи и чтения не совпадают, нарушение отсутствует. При совпадении адресов фиксируется нарушение, которое должно вернуть исполнение треда к команде чтения правильного значения.
Интерфейс между аппаратурой мультитредового процессора, поддерживающей протекание каждого отдельного треда и аппаратурой, общей для исполнения всех тредов, может быть установлен как сразу после устройств выборки команд тредов, так и на уровне доступа к разделяемой памяти. В первом случае все треды используют один регистровый файл и один набор функциональных устройств. Тесная связь по ресурсам позволяет эффективно исполнять последовательные программы с сильной зависимостью между тредами. В этом случае имеет место именно реализация мультискалярного мультитредового процессора.
Во втором случае для исполнения каждого треда, фактически, выделяется функционально законченный процессор. В целом эта структура ориентирована на исполнение независимых и слабо связанных тредов, порождаемых либо одной программой, либо их совокупностью. В этом случае скорее надо говорить не о процессоре, а о системе на одном кристалле. Возможно также промежуточное расположение интерфейса, соответствующее аппаратным средствам, ориентированным на реализацию определенного типа совокупности тредов.
По оценкам [11], при обработке транзакций мультитредовый микропроцессор Alpha 21464 будет в десять раз производительнее, чем Alpha 21264.
Развитие систем на одном кристалле
Среди тенденций, ведущих к появлению многопроцессорных систем на одном кристалле, можно отметить следующие.
1. Перенос на стадию компиляции решения проблем извлечения из последовательных программ команд, допускающих параллельное исполнение, и, в целом, ветвей параллельных программ. Если суперскалярный микропроцессор сам выделяет параллельно выполняемые команды, то уже в мультискалярном микропроцессоре на компилятор возлагаются дополнительные функции по выделению параллельных ветвей, а микропроцессоры с длинным командным словом возлагают на компилятор все проблемы загрузки параллельно функционирующих устройств. В этих условиях задача создания распараллеливающего компилятора для многопроцессорной системы не выглядит неразрешимой.
2. Объем оборудования, обеспечивающего загрузку функциональных устройств, микропроцессоров с суперскалярной и мультискалярной архитектурами достаточно велик и имеет квадратичный рост в зависимости от числа находящихся в обработке команд. При увеличении числа функциональных устройств должно увеличиваться и число выбираемых на исполнение команд, что приведет к возрастанию объема оборудования, не производящего непосредственно обработки данных. Суммарный объем схем управления в многопроцессорной системе, состоящей из простых процессоров, может быть существенно меньше, чем в микропроцессоре с суперскалярной или мультискалярной архитектурой при одном и том же суммарном числе функциональных устройств или, иными словами, при одинаковой производительности в случае полной загрузки устройств. Следует также отметить, что простые процессоры мультипроцессорной системы могут иметь более высокую тактовую частоту.
3. Многопроцессорная система, в силу присущей ей избыточности, способна функционировать при отказе части оборудования. Такие отказы могут быть как изначально присутствующими, вследствие дефектов кремниевой пластины или технологического процесса изготовления, так и появившимися в ходе функционирования. Многопроцессорные системы могут создаваться либо как однокристальные, либо как многокристальные микросборки. Реальность такова, что однокорпусная микросборка многопроцессорной системы из совокупности простых микропроцессоров может значительно превышать по показателю «производительность/стоимость» однокристальную систему, размер кристалла которой равен сумме площадей кристаллов микросборки [20,21]. Микросборки не отличаются от СБИС. Выбор однокристальной реализации или микросборки определяется достигаемыми технико-экономическими показателями, например, использование микросборок памяти. Возможности подобной технологии демонстрирует микропроцессор Pentium Pro. Однако среди наиболее интересных проектов, концентрирующих архитектурные и технологические достижения, включая однокристальные системы и микросборки, можно назвать микропроцессор Power4 [16].
4. В традиционных компьютерах, состоящих из микропроцессора и микросхем памяти, использующих в совокупности порядка 108 транзисторов в микропроцессоре и 109 транзисторов в памяти, в каждом такте задействовано по разным оценкам 104 - 105 транзисторов. Иначе говоря, имеет место простой значительной части оборудования, потенциально способного производить полезную работу. Конечно, при использовании КМОП-технологии простои имеют и определенный плюс: оборудование выделяет мало тепловой энергии. При существующих на сегодня конструкциях корпусов микросхем проблема теплоотвода может стать решающей при выборе архитектуры кристалла. Однако на кристалле может быть достаточно эффективно реализована многопроцессорная система из большого числа процессоров, каждый из которых имеет собственную небольшую встроенную память. Подобные вычислительные структуры обычно называют ассоциативными процессорами, памятью с обработкой, многофункциональной памятью или интеллектуальной памятью. К этому классу относятся однокристальные системы как с SIMD-архитектурой [3,10], например, Fuzion 150 [23], так и с MIMD-архитектурой, например, Blue Gene [9].
Направление эволюции архитектур микропроцессоров
Мультитредовые микропроцессоры и системы на одном кристалле вбирают в себя накопленные в ходе эволюции приемы повышения производительности микропроцессоров и используют симбиоз компиляторов и аппаратуры, соответственно для статического и динамического выявления параллелизма из исходных последовательных программ. Ориентация на исполнение совокупности тредов с определенной степенью межтредовых зависимостей обусловливает конкретные решения по совместному использованию тредами регистрового файла, аппаратуры внеочередного исполнения команд и функциональных устройств. Предстоят еще значительные исследования по оптимизации мультитредовых архитектур. Однако последовательность шагов в этом направлении эволюции микропроцессоров уже известна - это Alpha 21364 и Alpha 21464.
Виктор Корнеев (korv@kiam.ru) — заместитель директора НИИ «Квант» по научной работе, (Москва).
Литература
1. В. Левин. Некоторые вопросы реализации высокопроизводительных вычислительных систем. Кибернетика и вычислительная техника. М. Наука, 1991, стр.27-35
2. J. Hennessy. The Future of Systems Research. Computer. No. 8, 1999, pp. 27-33
3. В. Корнеев. Параллельные вычислительные системы. М. Нолидж, 1999
4. Р. Сайкс, К. Эссик. IBM объединяет память и логические устройства на одном кристалле. «Computerworld Россия», №9, 16 марта 1999
5. Overview of the i860 XP Supercomputing Microprocessor. Intel, 1991
6. Major System Characteristics of the Tera MTA. http://www.tera.com
7. Tera Computer Company Completes Design of Breakthrough Multiprocessor Chip.
8. Level One IXP1200 Network Processor. Advance Datasheet, Revision 278298-001 September 1999.
9. D. Clark. Blue Gene and the race toward petaflops capacity. IEEE Concurrency. January-March 2000, pp. 5-9
10. В. Корнеев, А. Киселев. Современные микропроцессоры. М. Нолидж, 2000
11. Alpha and IA-64. October 11, 1999. www. digital.com
12. K. Diefendorff, et. al. How Multimedia Workloads Will Change Processor Design. Computer. September, 1997. pp. 43-45
13. L. Goldberg. Vendors Are Counting on Appliance-on-Chip Technology. Computer, Vol. 32, No 11. 1999, pp. 13-16
14. P. Bannon. Alpha 21364: A Scalable Single-chip SMP. Compaq Computer Corporation, Microprocessor Forum, 13 October 1998
15. L. Barroso, K.Gharachorloo, A. Novatzyk, B. Verghese. Impact of Chip-Level Integration on Performance of OLTP Workloads. Proc. of The Sixth International Symposium on High-Performance Computer Architecture (HPCA), January, 2000
16. K. Diefendorff. Power 4 Focuses on Memory Banwidth. Microprocessor Report. Vol. 13, No. 13, October 6, 1999
17. G. Sohi, S. Breach, T. Vijaykumar. Multiscalar Processors. ISCA?95, Santa Margherita, Ligure, Italy. pp. 414-425
18. V. Krishnan, J. Torrellas. A Chip-Multiprocessor Architecture with Speculative Multithreading. IEEE Transactions on Computers. Vol. 48, No. 9, 1999
20. J. Tsai et. al. The Superthreaded Processor Architecture. IEEE Transactions on Computers. Vol. 48, No. 9, 1999
21. E. Davidson. Large Chip vs. MCM for a High-Performance System. IEEE Micro, July-August 1998.Vol. 18, No 4, pp. 33-41
22. M. Koyanagi, et. al. Future System-on-Silicon LSI Chips. IEEE Micro, July-August 1998.Vol. 18, No 4, pp. 17-22
23. P. Clarke. Pixelfusion SIMD engine processes 1.5 trillion operations/s. EE Times, May 12, 1999
