- 2.1. Дублирование функциональных узлов и режим пошаговой блокировки
- 2.2. Организация непрерывной обработки
- 2.3. Оперативная замена компонентов системы
- 2.4. Отказоустойчивый TCP/IP
- 4.1. Процессорный блок
- 4.2. Основание системы
- 4.3. Системная шина
- 4.4. Подсистема питания
- 4.5. Система охлаждения
- 4.6. Периферийные устройства
Для систем управления производственными процессами и приложений по оперативной обработке транзакций совершенно естественны повышенные требования к организации высоконадежных вычислений. Современные телекоммуникационные системы, системы управления воздушным и наземным транспортом, медицинские учреждения, фондовые биржи, банки и промышленные предприятия не могут приостановить свою работу из-за неисправности компьютерной системы. В подобных приложениях простой может привести к задержке выхода продукции, потере прибылей, поломке оборудования, а иногда и к человеческим жертвам.
Рынок высоконадежных систем начал формироваться в середине 70-х гг., и сегодня существует несколько специализирующихся в этой области компаний: Tandem Computer (1974), Stratus Computer (1980) и Sequoia Systems Inc. (1981). По мере роста потребностей этот рынок постояно расширялся: непрерывно повышался уровень надежности предлагаемых систем, расширялся их спектр и увеличивалось число поставщиков. В качестве примера можно привести отдельные изделия таких компаний как IBM, Digital/Compaq, HP, Sun.
В данной статье рассматриваются архитектурные решения Stratus Computers. Такой выбор обусловлен несколькими причинами. Во-первых, эта компания уже в течение многих лет является одним из "основных игроков" в данном секторе компьютерного рынка. Во-вторых, для нее характерна приверженность открытым стандартам. В-третьих, рассмотрение в одной статье сразу нескольких отказоустойчивых архитектур не позволяет уделить внимание ряду важных деталей. Более того, сосредоточимся главным образом на описании одной из серий продуктов непрерывной готовности - Continuum Series 400, в конструкции которой нашли отражение тенденции, характерные для современного компьютерного рынка в целом: применение основных компонентов (в основном микропроцессоров и периферийных устройств), выпускаемых массовым тиражом и обеспечивающих существенное снижение стоимости конечных изделий.
Введение
Одной из основных задач построения вычислительных систем остается обеспечение их продолжительного надежного функционирования. Эта задача имеет три составляющие: надежность, готовность и удобство обслуживания. Ее решение предполагает, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе.
Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечения тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Единицей измерения надежности является среднее время наработки на отказ (MTBF - Mean Time Between Failure).
Повышение готовности предполагает подавление, в определенных пределах, влияния отказов и сбоев на работу системы. Это осуществляется с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления вычислительного процесса после проявления неисправности, включая аппаратурную и программную избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Повышение готовности - способ сокращения времени простоя системы. Единицей измерения здесь является коэффициент готовности, который определяет вероятность пребывания системы в работоспособном состоянии в любой момент времени. Статистически коэффициент готовности неизбыточной системы при организованном ремонте определяется как MTBF/(MTBF+MTTR), где MTTR (Mean Time To Repair) - среднее время восстановления, иначе говоря, среднее время между моментом обнаружения неисправности и моментом возврата системы к полноценному функционированию. Очевидно, что основные эксплуатационные характеристики системы существенно зависят от удобства ее обслуживания, в частности, от ремонтопригодности и контролепригодности.
В литературе по вычислительной технике все чаще употребляются термины "системы высокой готовности", "устойчивые и эластичные к сбоям и отказам системы", "системы непрерывной и постоянной готовности". Однако как и многие термины в области ИТ, они трактуются по-разному отдельными поставщиками и потребителями. Прежде чем говорить о системах непрерывной готовности, следует определить их место среди систем, к надежности функционирования которых предъявляются повышенные требования. Сегодня для определения различных типов систем используется та или иная форма снижения планового и непланового времени простоя.
Высокая Готовность (High Availability). Конструкции с высоким коэффициентом готовности для минимизации планового и непланового времени простоя используют обычную компьютерную технологию. При этом конфигурация системы обеспечивает ее быстрое восстановление после обнаружения неисправности, для чего в ряде мест используются избыточные аппаратные и программные средства. Время, в течение которого программа, отдельный компонент или система простаивает, колеблется от нескольких секунд до нескольких часов, но чаще всего составляет от 2 до 20 минут. Обычно системы высокой готовности хорошо масштабируются.
Все системы высокой готовности обеспечивают устойчивость к отказам и сбоям в работе дисков и системы электропитания благодаря применению принципа избыточности: RAID, UPS и т.п. Следует отметить, что для современных систем высокой готовности характерно использование технологии "горячей" замены отказавшего узла.
Эластичность к сбоям (Fault Resiliency). Ряд поставщиков компьютерного оборудования делит весь диапазон систем высокой готовности на две части, при этом в верхней части оказываются системы, эластичные к сбоям. Эластичность к сбоям определяет более короткое время восстановления, которое позволяет системе быстро откатиться назад при обнаружении неисправности.
Устойчивость к сбоям (Fault Tolerance). Устойчивые к сбоям системы ("отказоустойчивые системы") имеют в своем составе избыточную аппаратуру для всех функциональных блоков, включая процессоры, источники питания, подсистемы ввода/вывода и подсистемы дисковой памяти. Если соответствующий функциональный блок неправильно работает, всегда имеется горячий резерв и неисправность в любом блоке не может вывести систему из строя. В ряде отказоустойчивых систем избыточные аппаратные средства можно использовать для распараллеливания обычных работ. Время восстановления после обнаружения неисправности для переключения отказавших компонентов на избыточные в таких системах обычно меньше одной секунды.
Непрерывная готовность (Continuous Availability). Лучшими среди отказоустойчивых систем являются системы, обеспечивающие непрерывную готовность. Продукт с непрерывной готовностью, если он работает корректно, позволяет ликвидировать как плановые, так и неплановые простои и проводить модернизацию (upgrade) и обслуживание системы в оперативном режиме (режиме on-line). Разработка подобной системы охватывает как аппаратные средства, так и программное обеспечение. Очень важным дополнительным требованием к таким системам является сохранение уровня производительности в случае отказа какого-либо компонента. Время восстановления после отказа не превышает одной секунды.
Следует отметить, что понятие непрерывная готовность все-таки подразумевает возможность сбоя в работе компьютера. Однако если типичное значение коэффициента готовности для обычной вычислительной системы составляет 99%, что эквивалентно примерно 80 часам простоя в год, то для систем непрерывной готовности этот параметр устанавливается на уровне 99.999% - 5 минут простоя в год.
Важно понимать, что системы высокой готовности вовсе не обязательно использовать для поддержки всех приложений. Однако если работа оперативного приложения жизненно важна для функционирования предприятия, именно непрерывная готовность обеспечивает наивысший возможный уровень гарантии того, что приложение будет спокойно поддерживаться в рабочем состоянии 24 часа в сутки, 365 дней в году. Помимо того, что непрерывная готовность является проверенной технологией, она представляет собой прямое, простое в использовании, прозрачное для приложений и базирующееся на стандартах решение, которое позволяет обойти ряд трудностей, связанных с реализацией кластерных систем.
Постоянная готовность (Permanent Availability). Это скорее теоретическое понятие. Коэффициент готовности для такого рода систем принимается равным 100%, т. е. предполагается отсутствие сбоев в работе, что практически недостижимо.
Все упомянутые типы систем высокой готовности предназначены для сокращения времени простоя. Существует два типа простоев: плановые и неплановые. Минимизация каждого из них требует различной стратегии и технологии. Плановое время простоя обычно включает время, отведенное на проведение работ по модернизации системы и на ее обслуживание. Неплановое время простоя является результатом отказа системы или компонента.
Высокая готовность не дается бесплатно. Общая стоимость подобных систем складывается из начальной стоимости системы, издержек планирования и реализации, а также системных накладных расходов. Выбор того или иного уровня готовности определяется также теми последствиями, которые будут иметь для конкретного предприятия простои информационной системы. Оценка стоимости простоя системы остается достаточно сложной задачей, поскольку она связана не только с потерей работоспособности системы, но существенно зависит и от организационной структуры конкретного предприятия и от места проявления неисправности.
1. Серия компьютеров Continuum 400 компании Stratus
Серия Continuum 400 представляет собой ряд серверов, разработанных с учетом требований обеспечения высокой готовности и производительности, необходимых для выполнения критически важных приложений оперативной обработки транзакций (OLTP). Системы серии Continuum 400 - это RISC-системы начального уровня, которые представляют собой небольшие компьютеры, работающие в режиме непрерывной готовности и предназначенные для создания надежной распределенной среды обработки. Помимо серии 400 компания выпускает системы среднего класса (Continuum 600) и высшего класса (Continuum 1200). Архитектура обработки данных всей линии Continuum базируется на микропроцессорах PA-RISC и работает под управлением двух операционных систем: FTX, HP-UX и VOS.
ОС FTX представляет собой собственную версию UNIX компании Stratus, предлагающую расширенные средства обеспечения надежности для поддержки критически важных приложений. FTX полностью соответствует спецификациям SVR4 MP, SVID, стандартам POSIX 1003.1, спецификациям XPG и UNIX 93 консорциума X/Open. ОС HP-UX, хотя и не обладает всеми средствами повышения надежности, заложенными в FTX, дает возможность запускать на системах Continuum большое число существующих для HP-UX 10.20 приложений. Эта ОС соответствует спецификациям UNIX 95 X/Open, стандартам XPG4, SVID3 Level 1 API и де-факто API BSD.
Системы Continuum 400 обеспечивают достаточно широкий диапазон производительности. Они могут оснащаться как микропроцессорами PA-8000/180 МГц (в однопроцессорном и двухпроцессорном (SMP) исполнении), так и микропроцессорами PA-7100/96 МГц (также в однопроцессорном и двухпроцессорном (SMP) исполнении). Подсистема ввода/вывода серии 400 базируется на шине PCI и использует стандартные карты PCI, выпускаемые массовым тиражом. Это первый продукт в серии Continuum, предлагающий технологию PCI.
Системы серии Continuum 400 работают в режиме непрерывной готовности и по параметрам надежности занимают верхнюю часть спектра предлагаемых сегодня на рынке систем высокой готовности. Их архитектура, специально разработанная с целью ликвидации всех неплановых и плановых простоев, обеспечивает коэффициент готовности на уровне 99,999%.
В таблице 1 представлены основные средства, обеспечивающие непрерывную готовность и устранение неплановых и плановых простоев системы.
| Таблица 1 | ||
| Неплановые простои | Плановые простои | |
| Надежность | Ремонтопригодность | Удобство обслуживания |
| Отказоустойчивые дуплексные компоненты TCP/IP | Проведение работ по модернизации системы в оперативном режиме | Уведомление о сбоях |
| Устойчивые к сбоям аппаратные средства | Переход на резервный ресурс в оперативном режиме | Диагностика в оперативном режиме |
| Надежное программное обеспечение | Поддержка целостности данных в оперативном режиме | Ремонт в оперативном режиме |
| Эластичная к отказам система электропитания | Модернизация фирменного ПО в оперативном режиме | Сеть удаленного обслуживания |
| Резервные аккумуляторные батареи | Загружаемые драйверы | |
2. Основные принципы построения систем непрерывной готовности
Реализация вычислений в режиме непрерывной готовности затрагивает практически все аспекты разработки системы - в ней не должно быть ни одного функционального узла, отказ которого может вывести из строя систему в целом. В основу серии Continuum положены следующие известные принципы построения отказоустойчивых систем:
Модульность. Каждый модуль системы является единицей обслуживания, ограничения распространения неисправности и ремонта. В случае отказа модуля он заменяется на другой.
Быстрое проявление неисправности. Каждый модуль должен либо работать правильно, либо немедленно останавливаться.
Независимость отказов. Модули и связи между ними должны быть разработаны так, что отказ одного из модулей никак не влият на работу остальных.
Избыточность и ремонт. В систему должны быть заранее установлены или сконфигурированы запасные модули, так что при отказе одного из модулей, запасной модуль может заменить его практически немедленно. Отказавший модуль может ремонтироваться автономно, в то время как система продолжает работать.
Принцип быстрого проявления неисправности обычно реализуется с помощью двух методов: самоконтроля и сравнения. Средства самоконтроля предполагают, что при выполнении некоторой операции модуль делает и некоторую дополнительную работу, позволяющую подтвердить правильность полученного состояния. Примерами этого метода являются коды обнаружения неисправности при хранении данных и передаче сообщений. Метод сравнения основывается на выполнении одной и той же операции двумя или большим числом модулей и сопоставлении результатов компаратором. В случае обнаружения несовпадения результатов работа приостанавливается.
Методы самоконтроля были основой построения отказоустойчивых систем в течение многих лет. Они требуют реализации дополнительных схем и времени разработки и вероятно будут доминировать в устройствах памяти и устройствах связи благодаря простоте и ясности логики. Однако для сложных устройств обработки данных экономические соображения, связанные с применением стандартных массовых компонентов, навязывают использование методов сравнения. Поскольку компараторы сравнительно просты, то их применение дает некоторое увеличение логических схем при существенном сокращении времени разработки. Следует отметить, что в более ранних отказоустойчивых конструкциях 30% логических схем процессоров и 30% времени разработки уходило на реализацию средств самоконтроля. С этой точки зрения схемы сравнения добавляют лишь универсальные схемы с простой логикой. В результате сокращаются общие расходы на разработку и логику.
Еще одним средством построения отказоустойчивой архитектуры, применяемым в системах Continuum, является принцип дублирования дуплексных модулей ("pair-and-spare" или "dual-dual"), который предполагает создание некоторого "супермодуля" - комбинации двух модулей, построенных на принципах быстрого проявления неисправности. Такой "супермодуль" продолжает работать даже когда отказывает один из субмодулей.
Дублирование дуплексных модулей требует большего объема оборудования, например, по сравнению со схемой троирования с мажоритарной логикой, но позволяет делать выбор одного из режимов работы: организацию либо двух независимых вычислений на принципах быстрого проявления неисправности, выполняющихся на двух парах модулей, либо одного высоконадежного вычисления, выполняющегося на всех четырех модулях.
Необходимо помнить, что сама по себе избыточность только снижает надежность в случае дублирования и троирования. Для существенного увеличения уровня готовности избыточная конструкция должна обеспечивать возможность ремонта и замены отказавших модулей. Таким образом, в основе систем непрерывной готовности компании Stratus лежит аппаратная отказоустойчивая архитектура, состоящая из дублированных функциональных узлов, причем большинство этих узлов работает в режиме пошаговой блокировки.
2.1. Дублирование функциональных узлов и режим пошаговой блокировки
Режим пошаговой блокировки предполагает, что все дублированные элементы некоторой подсистемы обрабатывают одну и ту же команду или данные в один и тот же момент времени. Например, в системах компании Stratus каждые два физических процессора (ЦП) объединяются парами и одновременно выполняют одну и ту же команду. При этом специальная схема сравнения в каждом такте проверяет, что оба ЦП вычислили тот же самый результат. Если ошибки отсутствуют, работа процессоров продолжается. Если обнаруживается ошибка, то работа останавливается, но простая схема сравнения не может сообщить, в каком ЦП произошел сбой. Именно поэтому работающие в режиме пошаговой блокировки пары ЦП также объединяются парами, образуя логический процессор из четырех физических ЦП. В этом случае, если в каком-либо одном физическом процессоре произойдет сбой, то логический ЦП будет продолжать работать без какой-либо потери производительности, что является важным аспектом обеспечения режима непрерывной готовности системы.
Режим пошаговой блокировки предполагает также, что неисправные компоненты аппаратуры автоматически изолируются от остальной части системы и выполняют цикл самотестирования. Если этот тест проходит успешно, то соответствующий функциональный узел автоматически возвращает себя в рабочий режим и продолжает обработку. Если тест самоконтроля не проходит, то в системный журнальный файл заносится соответствующая запись. Система с неисправными компонентами сама дозванивается по сети удаленного обслуживания (RSN - Remote Service Network) в сервисный центр компании Stratus и сообщает о неисправности. Это позволяет обслуживающему персоналу компании определить местоположение отказавшего узла и отправить подлежащий замене узел заказчику.
2.2. Организация непрерывной обработки
Концепция обеспечения непрерывной обработки компании Stratus затрагивает буквально все аспекты построения системы. В ее компьютерах применяются дуплексные аппаратные средства, построенные на принципах самоконтроля, осуществлено "усиление" ядра операционной системы с целью повышения устойчивости к сбоям и отказам отдельных компонентов, обеспечивается проведение работ по модернизации, обслуживанию и администрированию системы в оперативном режиме, что позволяет ликвидировать другие потенциальные источники простоев. Такой комплексный подход дает возможность поддерживать постоянный доступ к приложениям и данным и предохранять их от повреждений.
Работа системы начинается с диагностики всех компонентов при включении питания. В оперативном режиме все вычисления, операции с памятью и операции ввода/вывода выполняются параллельно на дуплексных аппаратных средствах. Каждая печатная плата проверяет себя на наличие аппаратных ошибок в каждом машинном такте. Если обнаруживается сбой в логике, система немедленно останавливает неисправную плату. Плата дуплексного партнера продолжает выполнять программу в обычном режиме и с нормальной скоростью.
Таким образом, даже если отказывает плата, никакого вмешательства операционной системы не требуется. Отказавшая плата просто больше не участвует в работе, о чем автоматически сообщается в центр поддержки пользователей (Customer Assistance Center). Такой подход имеет то преимущество, что позволяет обнаружить в работе оборудования не только "жесткие" отказы, но также и временные неисправности (сбои), что обеспечивает более высокий уровень готовности системы и повышает гарантию целостности данных.
Память системы дублируется и защищается ECC-кодами, а логика контроллера памяти построена на принципах самоконтроля. Усовершенствованные схемы поиска неисправностей проверяют память на наличие ошибок и гарантируют, что даже в редко используемых ячейках памяти не появятся некорректируемые ошибки. При этом работа этих схем поиска неисправностей скрыта от приложений и не влияет на производительность системы.
Дисковые накопители и контроллеры также дублируются, чтобы предотвратить появление неисправности, которая может повредить данные или прервать работу системы. При выполнении операций записи ОС записывает данные на два диска. При выполнении операций чтения данные поступают с того диска, для позиционирования головок чтения-записи которого требуется меньше времени, что минимизирует время доступа и обеспечивает повышение производительности в среде с большой нагрузкой по чтению. В случае отказа диска, все операции дискового ввода/вывода выполняются на исправном накопителе до тех пор, пока отказавшее устройство не будет заменено. После устранения неисправности система автоматически восстанавливает диск. В данном случае прикладное программное обеспечение даже не подозревает о возникновении неисправности, а также о наличии избыточной аппаратуры.
2.3. Оперативная замена компонентов системы
Все конструктивные компоненты системы могут заменяться в оперативном режиме - пользователи имеют возможность "горячей" замены неисправных компонентов без какого-либо простоя и приглашения персонала компании Stratus. Новый компонент автоматически сам переводит себя в оперативный режим. Сокращение плановых простоев является еще одним важным аспектом вычислений в режиме непрерывной готовности. Примером заменяемых заказчиком компонентов могут служить центральные процессоры. Однако и все остальные основные компоненты: модули памяти, диски, элементы системы питания и периферийные устройства защищены подобным способом.
Следует отметить, что компания Stratus предлагает уникальную технологию обслуживания заказчиков. Все системы заказчиков подсоединены к высоконадежной сервисной сети мирового масштаба, специально созданной для этих целей RSN. В случае, если средства самодиагностики обнаруживают неисправность, система автоматически посылает сообщение в центр поддержки заказчиков компании Stratus (Customer Assistance Center) или в собственный центр заказчика. При этом обработка приложений в системе не прерывается, а заказчик в течение одной ночи получает подлежащий замене узел, который может быть установлен в систему без выключения питания и приостановки выполнения приложения.
2.4. Отказоустойчивый TCP/IP
Помимо обеспечения устойчивости к сбоям на аппаратном уровне компания Stratus реализовала устойчивость к отказам для некоторых сетевых программных продуктов. В частности, дублированный сетевой интерфейс (RNI - Redundant Network Interface) TCP/IP позволяет рассматривать две карты сетевого интерфейса (основную и резервную) как один логический объект и обеспечивает защиту от отказа интерфейса. При этом требуется только один IP-адрес.
В случае появления неисправности в работе основной карты сетевого интерфейса RNI приостанавливает передачу через нее данных, переводит резервную карту (карту партнера) в оперативный режим и широковещательно рассылает по сети "ничем не вызванный" ARP-пакет, содержащий IP-адрес и новый MAC-адрес, позволяя тем самым всем мостам и коммутаторам модифицировать свои маршрутные таблицы. Отправляемые и принимаемые пакеты, которые были отброшены во время процесса выключения основного и включения резервного интерфейса, будут восстановлены протоколом более высокого уровня, а именно TCP.
Управление конфигурацией и переключением на резерв осуществляется с помощью работающего на уровне пользователя процесса-демона, который осуществляет разбор файла конфигурации во время инициализации интерфейса и проверяет, находится ли первичный порт локальной сети в рабочем состоянии. Если обнаруживается неисправность, в работу включается порт горячего резерва с использованием IP-адреса основного порта. Во всех случаях файлы конфигурации обновляются информацией о новом основном порте локальной сети. Это позволяет устранить ненужные колебания во время загрузки системы, которые могут появиться при попытках инициализировать неисправную плату первой.
3. Модели серии 400
Серия Continuum Series 400 включает шесть моделей, четыре из которых относятся к классу PA-7100 и две - к классу PA-8000 (таблица 2).
| Таблица 2. | ||||||
| Номер модели | 412 | 415 | 422 | 425 | 418 | 428 |
| Тип процессора | PA7100 | PA7100 | PA7100 | PA7100 | PA8000 | PA8000 |
| Тактовая частота | 96 МГц | 96 МГц | 96 | 96 МГц | 180 МГц | 180 МГц |
| Количество логических процессоров | 1 | 1 | 2 | 2 | 1 | 2 |
| Размер кэша | 512 Кбайт | 2 Мбайт | 512 Кбайт | 2 Мбайт | 2 Мбайт | 2Мбайт |
| Количество слотов PCI для пользователя | 12 | 12 | 12 | 12 | 12 | 12 |
| Макс. объем памяти | 512 Мбайт | 2 Гбайт | 512 Мбайт | 2 Гбайт | 4 Гбайт | 4 Гбайт |
4. Особенности архитектуры аппаратных средств
В состав компьютеров серии 400 входят следующие подсистемы:
- процессорные блоки;
- основание системы;
- системная шина;
- стойка расширения дисков;
- подсистема питания;
- подсистема охлаждения.
На рис. 1 приведена обобщенная схема системы Continuum Series 400.
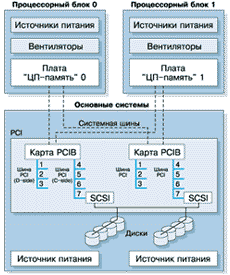
Обобщенная схема Continuum Series 400
4.1. Процессорный блок
Одним из двух главных конструктивных узлов системы Continuum Series 400 является процессорный блок, выполненный в виде небольшого "чемодана". В системе имеются два идентичных процессорных блока, монтирующиеся на основании и снабженные механизмом принудительного запирания, который выравнивает и фиксирует блоки на специальном основании. В процессорном блоке размещается плата "ЦП-память", вентиляторы системы охлаждения и источник питания.
Модуль платы "ЦП-память". Плата "ЦП-память" представляет собой материнскую плату, содержащую логическую секцию (оснащенные кэш-памятью модули ЦП PA-RISC, а также модули памяти), и модуль контроллера консоли (с последовательными интерфейсами для связи с консолью, RSN и источником бесперебойного питания).
Секция логики. Кристалл PA-RISC представляет собой высокопроизводительный ЦП, который обеспечивает выполнение функций целочисленной и плавающей арифметики и управления памятью на одной интегральной схеме. На кристалле реализована также логика управления раздельными внешними кэшами команд и данных большого объема.
Модули "ЦП/кэш" работают на частоте 96 МГц (PA-7100) и 180 МГц (PA-8000) и реализованы в однопроцессорном и двухпроцессорном исполнении. В каждом процессорном блоке при однопроцессорном исполнении размещается один логический (два физических) ЦП, а при двухпроцессорном исполнении - два логических (четыре физических) ЦП. При построении однопроцессорных и двухпроцессорных систем в зависимости от требований заказчика возможно формирование различных конфигураций:
- для PA-7100, с версией малого кэша 512 Кбайт (256 кэш команд и 256 кэш данных), либо с версией большого кэша 2 Мбайт (1 + 1);
- для PA-8000 кэш 2 Мбайт (1 + 1).
Каждая плата "ЦП-память" (рис. 2) содержит две работающие синхронно части (C-side и D-side), которые путем сравнения друг с другом обеспечивают обнаружение ошибок на плате. Расположенные в разных процессорных блоках платы-партнеры работают в режиме пошаговой блокировки. Появление неисправности на любой из плат вызывает переключение этой платы в нерабочее состояние. Подсистема ЦП и интерфейс системной шины полностью дублируются и сравниваются.
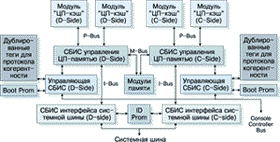 (1x1)
(1x1)В конструкции платы "ЦП-память" используется небольшое число СБИС, которые существенно сокращают общее количество устанавливаемых на нее компонентов. На одну материнскую плату могут устанавливаться разные типы модулей ЦП и динамической памяти.
Модуль контроллера консоли. Каждый модуль контроллера консоли работает независимо от остальной части платы "ЦП-память", на которой он расположен. Этот модуль выполняет функции центрального управления всей системы:
- поддерживает три асинхронных порта, размещенных на задней стороне процессорного блока: порт системной консоли, порт RSN и логический порт для связи с источником бесперебойного питания или с принтером консоли;
- плужит в качестве центральной точки сбора данных в процессе обслуживания и диагностики системы;
- управляет и наблюдает за работой основного источника питания;
- обеспечивает интерфейс консольных команд;
- содержит аппаратные схемы календаря/времени и память с батарейным питанием (NVRAM), в которой хранятся данные для загрузки системы;
- содержит постоянную память (ID PROM), которая хранит такую информацию, как номер модели, серийный номер и т.п.
Кроме того, в состав контроллера консоли входит постоянная память (PROM), организованная в виде нескольких разделов данных, которые содержат коды программ (фирменное программное обеспечение) диагностики платы, а также операций платы, выполняемых ею при работе в оперативном режиме и режиме горячего резерва. Эти коды программ диагностики и операций (как для оперативного режима, так и для режима горячего резерва) прожигаются на плате на заводе-изготовителе.
Контроллер консоли содержит также организованную в виде нескольких разделов данных постоянную память (PROM), в которой хранится информация о конфигурации порта консоли (количество бит в символе, скорость в бодах, стоповые биты и четность), а также определенные установки по ответам системы. Специальный раздел данных перепрограммируемого ПЗУ хранит информацию о том, где система должна искать загрузочное устройство, когда она пытается загрузиться автоматически. Заданные по умолчанию установки могут быть изменены путем ввода соответствующей информации и перепрограммирования этого раздела.
Контроллеры консоли логически образуют пару (но не работают в режиме пошаговой блокировки), так что в этом смысле одна из плат всегда находится в оперативном режиме, в то время как другая - в состоянии горячего резерва. Контроллер консоли, работающий в оперативном режиме, является активным на шине контроллера консоли и взаимодействует с другими компонентами системы. Резервный контроллер консоли также расматривается как активный на шине контроллера консоли, но не может взаимодействовать с остальной частью системы; он изолирован от всех внешних устройств за исключением шины контроллера консоли.
Если происходит отказ контроллера консоли, работающего в оперативном режиме, аппаратура автоматически выполняет операцию "переключения" на резервный. На новом оперативном контроллере консоли инициализируются все порты и операции ввода/вывода продолжаются. Переключение на горячий резерв может быть инициировано вручную путем объявления или удаления оперативного контроллера консоли.
Модули памяти. Модули памяти устанавливаются на материнскую плату. В моделях с PA-7100 и PA-8000 используются разные модули памяти, но для обоих типов систем предлагаются модули памяти емкостью по 128 или по 512 Мбайт. В один логический процессорный блок может быть установлено до четырех модулей памяти - максимально в системе может быть восемь модулей. При этом все используемые модули должны иметь одну и ту же емкость - совмещение модулей емкостью 128 и 512 Мбайт не допускается.
Надежность и устойчивость к сбоям подсистемы памяти.
В компьютерах компании Stratus реализованы действительно устойчивые к сбоям подсистемы памяти. Помимо использования метода дублирования, аппаратура способна обнаруживать многие сбои, которые не в состоянии выявить альтернативные конструкции, в основном полагающиеся только на определение четности данных, либо на ECC-коды.
Кроме того, как уже отмечалось, в серии Continuum используются мощные методы тестирования статических и динамических отказов памяти, что гарантирует обнаружение любых типов неисправностей.
Минимальный объем памяти системы, построенной на базе PA-7100 составляет 128 Мбайт. В моделях 412 и 422 поддерживается максимально 512 Мбайт памяти. Модели 415 и 425 поддерживают до 2 Гбайт памяти. Максимальная пропускная способность данных модуля памяти составляет 192 Мбайт/с, независимо от количества модулей, установленных в логическом процессорном блоке. Используется технология EDO DRAM емкостью 16-Мбит с временем доступа 60 нс. Шина данных имеет ширину 64 бита и работает на частоте 24 Мгц.
Системы на базе PA-8000 (модели 418/428) поддерживают от 128 Мбайт до 4 Гбайт памяти. Поскольку пока доступны модули только емкостью 128 и 512 Мбайт, максимальный объем памяти может достигать 2 Гбайт. После начала поставок в 1998 г. модулей памяти емкостью 1 Гбайт полная конфигурация памяти достигнет 4 Гбайт. Максимальная пропускная способность модуля памяти составляет 768 Мбайт/с. Если в логическом процессорном блоке установлено более одного модуля памяти, то общая максимальная пропускная способность увеличивается до 964 Мбайт/с. Такое увеличение максимальной пропускной способности достигается благодаря использованию механизма расслоения памяти. Задействуется технология EDO RAM емкостью 64-Мбит с временем доступа 50 нс. Шина данных имеет ширину 128 бит и работает на частоте 60 Мгц.
4.2. Основание системы
В основании системы находятся три основных компонента: подсистема ввода/вывода PCI, дисковые накопители (8 шт. максимум) и источники питания основания системы (2 шт.) На задней стенке основания системы размещаются четыре порта:
- шина стойки (Cabinet Bus);
- RSN (сеть удаленного обслуживания);
- консоль (Console);
- удаленная консоль/источник бесперебойного питания (Remote Console/ UPS).
Порт шины стойки (RS-485) зарезервирован для будущего использования. Другие три порта (RS-232) подсоединяются к контроллеру консоли. Подсистема ввода/вывода Continuum 400. Архитектура ввода/вывода Continuum 400 показана на рис. 3.
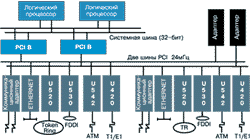 (1x1)
(1x1)Основные компоненты подсистемы ввода/вывода - это две карты мостов PCI (PCIB), двойные шины PCI, до 14 карт адаптеров PCI (12 могут конфигурироваться пользователем).
Карты мостов PCI. Две карты PCIB осуществляют интерфейс между системной шиной (Xbus) Continuum 400 и двумя 8-слотовыми шинами PCI. (В действительности имеются четыре 4-слотовые шины PCI, которые связаны вместе и образуют две логические 8-слотовые шины PCI). PCIB обеспечивают изоляцию карт адаптеров PCI от процессорных блоков, так что неисправность процессорного блока не может нарушить работу карты PCI. Каждая карта PCIB поддерживает дублированное соединение с системной шиной Continuum 400 и обычное соединение с физически отдельной двойной 8-слотовой шиной PCI, работающей на частоте 24 МГц.
Карты PCIB представляют собой устройства управления и интерфейса для карт адаптеров PCI. Каждая из них осуществляет интерфейс между ЦП и одной логической шиной PCI. Системная шина (Xbus) обеспечивает соединение между платами "ЦП-память" и картами PCIB. Последние содержат по одной СБИС, которая соединяет шину PCI с флэш-памятью.
На каждой карте PCIB размещается сменная флэш-карта PCMCIA емкостью 20 Мбайт. С этих перепрограммируемых ПЗУ (EEPROM) осуществляется загрузка системы. Система может загружаться с любой из флэш-карт до тех пор, пока она имеет текущую версию программы начальной загрузки. ПЗУ ЦП (CPU PROM) в процессе загрузки представляет флэш-карту в виде диска, доступного только в режиме чтения. При запуске системы ОС загружается с флэш-карты, при этом предполагается, что последняя содержит правильную версию ядра ОС. Если файл на флэш-карте не совпадает с файлом, существующим на корневом диске, на корневой диск переписывается файл с флэш-карты.
При выключении системы (по специальной команде) ОС снова сравнивает содержимое файла на флэш-карте с содержимым файла на корневом диске. Если содержимое этих файлов не идентично, ОС автоматически обновляет файл на флэш-карте, указанной с помощью символической ссылки, которая была создана во время запуска системы.
Шина PCI. Шина ввода/вывода систем Continuum 400 построена в соответствии с промышленным стандартом PCI. Это полностью синхронная 32-битовая шина с мультиплексированием адреса и данных, работающая на частоте 24 МГц. Шина имеет широкую полосу пропускания, малую задержку и работает с напряжением питания 5 В. Она поддерживает карты адаптеров PCI с размерами до 12.8"x4.2".
Соединение сигнальных линий, линий питания и земли между двумя логическими процессорными блоками и двумя секциями ввода/вывода осуществляется с помощью специальной монтажной панели. Каждая карта адаптера непосредственно доступна из любого процессорного блока через шину PCI. Специальная логика, реализованная в каждом процессорном блоке, обеспечивает устойчивость к сбоям при работе с шиной PCI и защищает их от неисправностей карт адаптеров.
Каждая из двух логических шин PCI имеет раздельную разводку питания, так что по крайней мере одна из карт дисковых контроллеров всегда этим питанием обеспечена. Когда открывается дверца доступа к конструктивным элементам подсистемы PCI, на соответствующей шине PCI автоматически отключается питание. (Имеется специальный внутренний замок, позволяющий одновременно открыть дверцу для доступа к элементам только одной логической шины). В тот момент, когда дверца доступа закрывается, соответствующая подсистема снова начинает работать в оперативном режиме и инициируется полная последовательность конфигурирования PCI.
PCIB занимает один из восьми слотов на каждой логической шине PCI, так что остается только семь свободных слотов. Но поскольку для размещения задублированных карт SCSI-адаптеров также требуется по одному слоту, для организации ввода/вывода остается максимально шесть дублированных слотов PCI, которые могут конфигурироваться пользователем. (Если используется симплексный режим работы адаптеров PCI, то для организации ввода/вывода в системе Continuum 400 оказываются доступными максимально 12 слотов PCI).
Каждая карта адаптера PCI может находиться в одном из четырех возможных состояний: выключена, автономный режим, оперативный симплексный режим и оперативный дуплексный режим
Состояние карты указывается с помощью линейки светодиодов. Выключенная плата изолируется от системы. Плата, находящаяся в этом состоянии, обычно указывает на аппаратную неисправность, требующую либо операции начальной установки, либо ремонта. Плата, находящаяся в автономном режиме - это исправная плата, которая не была переведена в оперативный режим. Обычно автономный режим - это переходное состояние, используемое платой, которая находится в процессе инициализации или выполнения диагностических процедур. Плата, находящаяся в оперативном симплексном или дуплексном режиме, считается полностью функционирующей.
Коммуникационные адаптеры PCI. Сейчас для систем Continuum 400 существует широкий спектр коммуникационных адаптеров PCI, поддерживающих различные сетевые технологии и стандарты (многопортовые синхронные интерфейсы в соответствии с V.35, V36, EIA232, EIA530, однопортовые интерфейсы T1/E1, ISDN PRI, многопортовые асинхронные интерфейсы, а также X10/100 Мбит/c Ethernet, 4/16 Мбит/с Token Ring, 100 Мбит/с FDDI, 155 Мбит/с ATM).
Отказоустойчивость подсистемы ввода/вывода Continuum 400. Хотя отдельные адаптеры PCI нельзя заменить, не выключая их питания, а мосты PCI построены в расчете на симплексную логику шины PCI, в целом подсистема в/в Continuum 400 обеспечивает устойчивость системы к отказам. Логические схемы, управляющие работой системной шины в мостах PCI, построены на принципах самоконтроля, поэтому интерфейс Continuum 400 с подсистемой в/в устойчив к отказам. Мосты PCIB управляют доступом адаптеров к шинам PCI, так что адаптеры PCI, в работе которых происходит сбой, не могут захватить шину. Двойные шины PCI позволяют устанавливать в них дублированные адаптеры, что минимизирует опасность выхода системы из строя в случае неисправности отдельного адаптера. На шинах PCI применяется внутренняя и внешняя проверка шлейфов.
В случае отказа PCIB, шины PCI, карты адаптера PCI или разъема для поддержки коннективности системы без прерывания ее работы могут использоваться программные средства переключения на горячий резерв, например, избыточный сетевой интерфейс (RNI). Конечно, возможность переключения на горячий резерв зависит от того, поддерживается ли она программным обеспечением соответствующих сетевых уровневых протоколов.
Дисковые накопители. В системах Continuum 400 поддерживаются три типа дисковых накопителей различной емкости (таблица 4), которые устанавливаются в дисковом отсеке основания системы или в специальных стойках расширения и поддерживают режим "горячей" замены. Они имеют интерфейс fast, wide SCSI-2, скорость вращения 7200 об/мин, форматируются с размером сектора 512 байт, реализуют уникальную для поставщика шину неисправностей и содержат светодиод активности (зеленый) и светодиод неисправного состояния (желтый).
| Таблица 4. | |||
| Название (ID) | D802 | D803 | D804 |
| Форматированная емкость | 2.15 Гбайт | 4.35 Гбайт | 9 Гбайт |
| Ротационное запаздывание | 4.17 мс | 4.17 мс | 4.17 мс |
| Среднее время позиционирования | Чтение: 8.8 мс Запись: 9.8 мс |
Чтение: 8.8 мс Запись: 9.8 мс |
Чтение: 8.0 мс Запись: 9.5 мс |
| Минимальная версия ОС | HP-UX 10.10 FTX 3.1.1 |
HP-UX 10.10 FTX 3.1.1 |
HP-UX 10.10 FTX 3.2 |
4.3. Системная шина
Системная шина Continuum 400 (Xbus) и ее интерфейсы выполняют следующие функции:
- передача информации между платами "ЦП-память" и картами мостов PCI (PCIB);
- передача информации между двумя платами "ЦП-память";
- обнаружение и изоляция сбоев как самой шины, так и расположенных на ней плат.
В действительности Xbus представляет собой четыре распределенных шины "точка-точка", которые не дублируются. Это основное отличие от системной шины Continuum Series 600/1200, представляющей собой логически единую дублированную шину с расщеплением транзакций и мультиплексированием адреса и данных, разделяемую всеми платами.
Хотя физическая реализация Xbus использует четыре шины "точка-точка", реализованный протокол обеспечивает о ней представление как о единой шине. В каждом конкретном цикле в системе межсоединений обрабатывается не более одной транзакции. Эта транзакция может выполняться всеми четырьмя шинами в случае дуплексного режима работы, или только двумя шинами в случае симплексного режима работы.
Шина XBus характеризуется 32-битовой шириной интерфейса, полностью синхронным режимом работы, поддержкой согласованного состояния кэш-памяти и единой СБИС логического интерфейса. Конфигурации устройств на этой шине ограничены двумя платами "ЦП-память" и двумя картами мостов PCI.
Сигналы шины можно разделить на две категории: сигналы данных и сигналы управления. Как показано на рис.4, сигналы данных реализуются посредством четырех двунаправленных шин "точка-точка", а сигналы управления передаются по отдельным однонаправленным шинам. Сигналы шины защищены картой памяти, четностью и проверкой шлейфа, причем сигналы управления защищены с помощью ECC-кода и проверкой шлейфа.
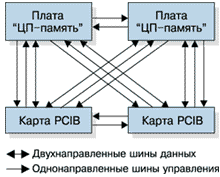
Транзакция ЦП-ЦП выполняется с помощью операции взаимодействия равноправных подсистем, при которой она разбивается на две отдельных транзакции, поскольку XBus не имеет полностью взаимосвязанных шин данных. В первой транзакции ЦП передает посылку PCIB. Во второй - PCIB передает информацию другому ЦП.
Новое свойство XBus - это протокол обнаружения ошибок. В отличие от системной шины серии 600/1200, XBus пытается не только обнаружить ошибки шины, но также диагностировать источник ошибок.
4.4. Подсистема питания
Подсистема питания включает три основных сборочных узла: дублированные модули ввода напряжения питания, источники питания процессорных блоков и источники питания основания системы.
Каждый процессорный блок содержит источник питания, на вход которого поступает обычное напряжение переменного тока, а на выходе формируются необходимые уровни постоянных питающих напряжений. Неисправность в источнике питания приводит к отказу всего процессорного блока, но не к прерыванию работы системы.
В основании системы имеются два источника питания подсистемы в/в. Каждый блок обеспечивает дублированное активное питание дисковым накопителям и не дублированное питание половине подсистемы в/в. В случае отказа источника половина слотов PCI оказываются в нерабочем состоянии, но система продолжает работать.
В системах Continuum 400 не поддерживается никаких встроенных систем бесперебойного питания. Для заказчиков, в помещениях которых отсутствуют соответствующие системы, поставляется внешний источник бесперебойного питания, изготовляющийся компанией APC. UPS обеспечивает переменное питающее напряжение и связан с системой с помощью последовательного интерфейса, подсоединяемого к одному из асинхронных портов контроллера консоли. Фирменное ПО контроллера консоли взаимодействует с UPS и обеспечивает как индикацию отказа питания, так и выключение питания системы.
4.5. Система охлаждения
Каждый процессорный блок системы на базе PA-7100 охлаждается с помощью трех вентиляторов, расположенных на его задней стенке. В процессорных блоках на базе PA-8000 используются два более мощных вентилятора. Отказ вентилятора в каком-либо процессорном блоке приводит к отключению последнего.
Карты PCI, расположенные в основании системы, охлаждаются путем выкачивания воздуха вентиляторами охлаждения процессорных блоков. Дисковые накопители охлаждаются двумя вентиляторами, расположенными на задней стенке источников питания основания системы. Информация о температуре снимается с помощью датчиков и используется для управления скоростью вентиляторов.
4.6. Периферийные устройства
Имеются шесть категорий периферийных устройств, которые могут подсоединяться к системе Continuum 400. Первая категория включает диски D80x, которые устанавливаются в основание системы. Другие пять категорий являются внешними по отношению к системе. Это стойки расширения дисков D800, ленточные накопители, CDROM, дисковые массивы RAID и терминал.
Заключение
В 1996 г. министерство торговли и промышленности Великобритании провело обследование около тысячи крупных компаний, в задачи которого входило выяснение степени влияния на их деятельность современных информационных технологий. Результаты этого обследования весьма поучительны. Например, оказалось, что средняя интенсивность отказов информационных систем составила: для 40% компаний - 1 отказ в год, для 29% - 1 отказ в месяц, для 15% - 1 отказ в неделю, для 7% - 1 отказ в день, для 5% - более одного отказа в день. Только у 4% компаний вообще не было проблем, связанных с отказами систем (за счет использования систем непрерывной готовности). Основными причинами простоев по результатам этого же исследования оказались: отказы аппаратуры (68% случаев), отказы и сбои программного обеспечения (24%), сбои при обработке файлов большого объема (38%), демонтаж и установка нового дополнительного оборудования (4%), установка нового и модернизация старого программного обеспечения (3%). В результате удалось также выяснить причины некоторых расходов, связанных с простоями информационных систем (таблица 5).
| Таблица 5 | |
| Причина простоя | Максимальная стоимость (тыс. долл.) |
| Отказ питания | 33 |
| Сбой локальной/глобальной сети | 66 |
| Отказ компьютера | 166 |
| Ошибка оператора | 20 |
| Ошибка пользователя | 33 |
Представленные цифры иллюстрируют важность обеспечения непрерывной готовности аппаратных средств и программного обеспечения для всех компаний и предприятий, где информационные технологии являются интегральной частью производственного процесса.
Однако наряду с использованием в качестве основных средств производства у современных информационных технологий имеется еще одна важная сфера применения. Речь идет о реализации так называемых оперативных услуг (on-line services): прямые банковские услуги, Web-серверы, системы приема заказов по телефону и электронная коммерция. В современных условиях, характеризующихся исключительно высоким уровнем конкуренции, любой простой системы, обеспечивающей такого рода услуги (неважно, насколько он короток), может привести к потере заказчика. Так в одной из статей "Computing Cost" за октябрь 1996 г. приводился пример того, как одноминутный сбой в работе Web-сервера повлек за собой потерю 66 тыс. долл., поскольку клиент не смог соединиться с сервером и разместить заказ. Что касается будущих заказов, то тот же самый клиент скорее всего будет контактировать с поставщиком, сервер которого оказался доступен с первой попытки.
Безусловно, достаточно трудно точно оценить ущерб, который может быть нанесен в результате простоя информационной системы. Однако очевидно, что предоставление различного рода оперативных услуг стало сегодня одним из наиболее важных элементов деятельности многих компаний, а это неизбежно приводит к росту спроса на системы непрерывной готовности.
