
О «релевантности» и «пертинентности»
Существует множество определений релевантности. Например, ГОСТ 7.73-96 гласит: «релевантный: соответствие полученной информации информационному запросу». Таким образом, релевантность определяется исключительно алгоритмами поиска конкретной поисковой системы. В том же ГОСТе говорится, что «пертинентность; пертинентный: соответствие полученной информации информационной потребности», то есть пертинентность определяет степень соответствия между ожиданиями пользователя и результатами поиска. Вообще говоря, релевантность может сильно отличаться от пертинентности, однако данные понятия постоянно путают при толковании.
Например, в русской версии энциклопедии Wikipedia утверждается: «Релевантность (от английского relevant — уместный, относящийся к делу) применительно к результатам работы поисковой системы — степень соответствия искомого и найденного, уместность результата... Основным методом ранжирования является TF*IDF — метод ранжирования, который используется в большинстве поисковых систем... Его смысл сводится к тому, что чем больше локальная частота термина в документе (TF) и больше «редкость» (т.е. обратная встречаемость в документах) термина в коллекции (IDF), тем выше вес данного документа по отношению к термину — то есть документ будет выдаваться раньше в результатах поиска по данному термину». Если следовать определениям ГОСТа, то в первом из приведенных предложений речь идет о пертинентности, а далее обсуждается способ расчета ранга, т.е. один из механизмов определения релевантности.
Во времена Сэлтона* информационно-поисковых систем Internet еще не было, и предложенные им алгоритмы расчета весов терминов, индексирования документов и ранжирования результатов поиска предназначались для информационно-поисковых систем, работающих только с научно-технической информацией. Существенная особенность данной предметной области состояла в уникальности каждого документа. По этой причине было интуитивно понятно, что в идеальном случае при поиске конкретного документа релевантность и пертинентность должны совпадать.
Однако из-за субъективности пертинентности добиться точного совпадения нельзя: любая поисковая система настраивается на информационные нужды усредненного, а не конкретного пользователя. Для удовлетворения нужд конкретного пользователя и были придуманы разные способы коррекции результатов поиска по релевантности. Фактически, учет цитируемости документа в других документах является одним из них. Google PR (Page Rank) и ИЦ «Яндекса» — это методы достижения релевантности, основанные на цитируемости. Задолго до начала использования механизма цитируемости в Internet существовала база данных цитируемости научно-технических материалов, известная как «Индекс цитируемости Гарфилда». К слову, 15 июля исполнилось 50 лет с момента опубликования основополагающего труда Евгения Гарфилда Citation indexes for Science: A New Dimension in Documentation through Association of Ideas. Первый печатный индекс цитирования был выпущен в 1964 году, а два года спустя стал доступен на магнитных лентах.
Индекс Гарфилда использовали для неформальной оценки качества работы научных кадров. Естественно, как только цитируемость стала влиять на финансирование научных работ и зарплату ученых, у оцениваемых возникло желание «поправлять» свои показатели за счет влияния на этот индекс. Появились самоцитирование, перекрестное цитирование и ряд других способов повышения рейтинга. Однако все эти способы неминуемо приводили к ухудшению как релевантности поиска, так и пертинентности. Поначалу ситуация в Internet была идентична той, что наблюдалась в мире научно-технической информации, но с ростом коммерческой привлекательности Сети картина стала меняться.
Скажем, вы хотите купить книгу Дэна Брауна «Код да Винчи». В результате поиска вы получаете список Internet-магазинов, предлагающих эту книгу, причем цена везде примерно одинакова, а доставка является бесплатной. Вы удовлетворены? Безусловно. А вот по поводу релевантности ссылок на Internet магазины возникает масса вопросов. Для пользователя они все равны, а для системы — нет, поскольку для нее каждый магазин имеет свою оценку. Кроме того, для потребителя рекламная ссылка имеет ту же пертинентность, что и все остальные, а для системы, которая может получать вознаграждение за рекламу, она должна иметь гораздо больший вес. Собственно, именно поэтому рекламные ссылки и размещают во многих системах перед списком «нерекламных» или в тех местах, где пользователь обязательно обратит на них внимание.
Другой пример. По утверждению поисковой системы Lycos, запрос «Памела Андерсон» возглавляет список самых популярных запросов за последние десять лет. Очевидно, что знаменитое видео уникально, а вот количество сайтов, на которых оно размещено, даже трудно сосчитать. И хотя пользователь удовлетворится практически любым из них, владельцам сайтов далеко не безразлично, на какой из них придут потребители.
Как указывают исследователи из Корнельского университета [1], в подавляющем большинстве случаев пользователи выбирают из результатов поиска первые две позиции. А это означает: для того чтобы пользователь увидел ссылку и воспользовался ею, она должна попасть хотя бы на первую страницу поиска. Вот здесь-то и начинается то, что принято называть поисковой оптимизацией.
О регистрации доменных имен
После стремительного взлета Internet наступил неизбежный спад. Он нашел, в частности, свое отражение в общем количестве зарегистрированных доменных имен в зоне .com (рис. 1): за пиком 2002 года последовал провал 2003-го. В 2004 году, однако, был отмечен рост регистраций, приведший к достижению новых «рекордов». Более того, темпы прироста в 2005 году стали напоминать ситуацию, схожую с разрастанием Internet-«пузыря» в 2000 году. Если в 2004 году эксперты и специалисты рынка доменных имен говорили о возрождении интереса к Сети вообще, то со II квартала 2005 года все чаще в качестве одной из причин увеличения числа регистраций стали называть поисковую оптимизацию.
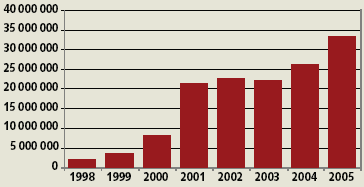 |
| Рис. 1. Изменение количества регистраций в домене .com в 1998-2005 гг. |
Так, компания VeriSign [2] указывает, что из 130 аккредитованных за последнее время ICANN регистраторов доменных имен в доменах .com и .net большинство составляют регистраторы, главная цель которых — получение доступа к списку удаляемых старых доменных имен. Эти имена либо выставляются на аукцион, либо используются для транспортировки рекламного трафика по принципу Pay Per Click (PPC), в соответствии с которым рекламодатель оплачивает переходы по гипертекстовым ссылкам.
Почему старые домены настолько востребованы? Одна из причин состоит в их истории. Такие доменные имена были связаны c сайтами, уже проиндексированными поисковыми системами, и у каждого из них есть рассчитанная под разные поисковые запросы релевантность. У сайтов, связанных с удаляемыми доменными именами, имеются разные характеристики, по которым рассчитывалась их релевантность: это ссылки с других сайтов, кэшированные поисковыми системами страницы, рассчитанные метрики релевантности типа Google PR. Даже если сайт будет на некоторое время удален из индекса поисковой системы, его след в Сети останется. При регистрации этого сайта и восстановлении его контента все старые характеристики снова начнут «работать», но уже на новый сайт и его новых владельцев.
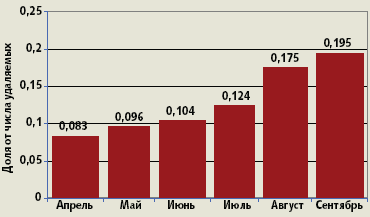 |
| Рис. 2. Доля вновь регистрируемых удаленных доменов в общем числе удаляемых доменов |
Аналогичные тенденции имеют место и в зоне .ru: процент повторной регистрации удаляемых доменов вырос с 8% в апреле нынешнего года до 19,5% сентябре (рис. 2). А о важности поисковых характеристик старых доменов свидетельствует следующее: величина Google PR сайта хорошо коррелирует с вероятностью регистрации доменного имени этого сайта — при условии, что оно попало в список удаленных (рис. 3). Аналогичная картина наблюдается и в индексе Яндекса (рис. 4).
Под PPC регистрируют не только удаленные домены, но и новые. По данным Сары Лонгстоун из VeriSign, до 20% новых регистраций в .com и .net (примерно 800 тыс. доменных имен, что в два раза больше количества доменов второго уровня в .ru) — это регистрация доменов под PPC. Как отметил Адам Дикер, директор High Impact Sites, если домен со стоимостью регистрации 7 долл. будет приносить более 2 центов в день, то к концу года он окупится. Если применить такую схему к .ru, где стоимость регистрации составляет 20 долл., то можно прийти к выводу, что домен должен приносить ежедневно порядка шести центов (или чуть меньше 2 долл. в месяц).
Информационный поиск и выгода
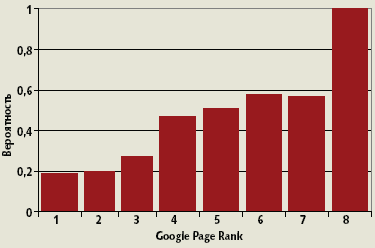 |
| Рис. 3. Вероятность регистрации удаляемого домена при наличии у него соответствующего Page Rank |
Исследователи Jupiter Research прогнозируют, что рынок PPC вырастет c 2,6 млрд. долл. в 2004 году до 5,5 млрд. долл. в 2009 году. И желающих поучаствовать в разделе этого пирога немало. Понятно, что львиная доля достанется сайтам с высокой посещаемостью, которые уже сейчас являются ведущими рекламными площадками, но и новичкам отчаиваться не стоит.
Ключевой момент для любого нового участника — выход на рынок. Для получения отчислений от рекламы сначала нужно ее разместить, но кто же станет делать это на сайтах с низкой посещаемостью! Для данных целей используются партнерские программы, при упоминании о которых обычно возникают ассоциации с баннерообменными сетями, заработком «на халяву», кликерами, трафиком «для взрослых» и т.п. Однако, во-первых, имеются программы типа Refer-it.com, а во-вторых, не стоит забывать, что в эту рыночную нишу активно вторгаются и более солидные игроки. Например, у Google есть партнерская программа AdSence, а у Yahoo! — Search Marketing`s Content Match. Корпорация Microsoft запустила свою программу в тестовую эксплуатацию в августе 2005 года, и даже «Яндекс» сообщил о намерении сделать что-то подобное, правда, с существенной оговоркой — в программу будут приниматься сайты с большой посещаемостью. Практически во всех перечисленных случаях речь идет о контекстной рекламе под ключевые слова, т.е. под результаты поиска по этим словам.
 |
| Рис. 4. Вероятность регистрации удаляемого домена при наличии у него определенного количества кэшированных страниц в «Яндексе» |
Обычно на сайт рекламодателя потребитель попадает либо с использованием закладки, либо со страницы результатов поиска, либо из каталога, либо при переходе по гипертекстовой ссылке с другого сайта. Согласно данным отчета «Дорожные указатели в киберпространстве: система доменных имен и навигация в Интернете» [3], при просмотре сайтов Internet-пользователи чаще всего прибегают к помощи закладок или к прямому вводу их имен (65,5%), затем — к услугам поисковых систем (13,4%) и лишь потом обращаются к каталогам, контекстным гипертекстовым ссылкам и прочим средствам навигации. Получается, что поисковые системы являются не самыми популярными источниками.
Однако в январе 2004 года компания NIELSEN/NETRATINGS опросила американских пользователей Сети и выяснила, что 76% респондентов прибегали к помощи поисковых систем и более половины из них были полностью удовлетворены полученными результатами. В том же исследовании приведен список десяти самых популярных на тот момент корпоративных порталов, в который попали все известные поисковые порталы. При этом речь идет о десятках миллионов уникальных сессий за месяц. Например, Google — это почти 60 млн аудиенций в месяц. К слову, сегодня Google является самой популярной поисковой системой. Доля запросов Google среди всех поисковых запросов американцев составляет 40.
При определении релевантности, как уже говорилось, Google использует PR, и чем он выше, тем лучше. У нового сайта высокого PR быть не может, а следовательно, не приходится рассчитывать на его хорошую позицию в результатах поиска. Здесь самое время вспомнить об удаляемых доменах. Они могут иметь высокие значения PR, а потому их можно попробовать зарегистрировать и конвертировать их PR в популярность нового сайта. Фактически, речь идет либо о размещении на этих доменах «зеркал», либо о создании «дорвеев» (door way). И с тем, и с другим поисковые системы борются, поскольку это приводит к снижению релевантности поиска. Но вот снижает ли это пертинентность — вопрос. Все зависит от того, кто и в каких целях такие методы применяет.
Google — лишь частный пример конвертирования абстрактной релевантности в реальный трафик и осязаемые доходы от него. Исследования показывают (Search vs. Yellow Pages: The Fight Continues; www.ypassociation.org/pdf/ in_the_news/eMarketer_comScoreRelease.pdf), что на локальных рынках с гораздо большим успехом можно конвертировать трафик каталогов и локальных поисковых систем.
При миллиардных оборотах кустарное хозяйство долго существовать не сможет — неизбежно начнется разделение труда. Регистраторы объединяются в пулы, специализирующиеся на перехвате удаляемых доменных имен (пул .com, например). Оптимизаторы разрабатывают схемы оптимизации сайтов и агрегирования трафика. Появляются компании, обеспечивающие услуги парковки доменов и инструменты размещения на страничках домена рекламных ссылок (скажем, sedo.com), а поисковые системы предлагают свои партнерские программы. Разработка «Клондайка оптимизации» началась не сегодня, но именно сегодня она вступила в индустриальную фазу. Всем, кто хочет испытать себя при возделывании нивы оптимизации, следует помнить, что самые большие прибыли от ажиотажа обычно получают изготовители шанцевого инструмента, а самые большие издержки несут оптимизаторы.
Литература
- Thorsten Joachims, Laura Granka, Bing Pan, Helene Hembrooke and Geri Gay. Accurately Interpreting Clickthrough Data as Implicit Feedback, Proceedings of the Conference on Research and Development in Information Retrieval (SIGIR). — 2005.
- Jassie Clark. Market Trends Seminar, ICANN Luxemburg. — July 2005.
- Signposts in Cyberspace: The Domain Name System and Internet Navigation (2005). — National Academies Press: Computer Science and Telecommunications Board (CSTB).
Павел Храмцов (paulkh@yandex.ru) — начальник группы РНЦ «Курчатовский Институт» (Москва).
*Герард Селтон (Gerard Salton, 1927-1995) — профессор Корнельского университета, автор системы SMART (System for the Mechanical Analysis and Retrieval of Text). На ее основе разработаны и протестированы многие современные алгоритмы автоматического индексирования и поиска информации. Наиболее значимые его работы: Automatic Information Organization and Retrieval (New York: McGraw-Hill. — 1968); A Theory of Indexing (Regional Conference Series in Applied Mathematics, №18. — Philadelphia, PA.: Society for Industrial and Applied Mathematics. — 1975); Introduction to Modern Information Retrieval (New York: McGraw-Hill, 1983).
