
Даже в случае частичных разрушений привычные средства обеспечения отказоустойчивости не помогут, поскольку рассчитаны только на отработку отказов отдельных компонентов локальной системы. Чтобы не потерять данные и быстро восстановить работоспособность организации, необходимо особое, катастрофоустойчивое решение.
Успешное существование многих организаций зависит от целостности данных, ими хранимых и обрабатываемых. Надежность компьютерной техники - критический фактор для бирж и банков, заводов и фабрик, предприятий связи (которые теперь называют провайдерами) и транспортных систем. Надежность отдельных компонентов современных компьютеров сравнительно велика (время наработки на отказ может составлять десятки и сотни тысяч часов), однако их количество в каждой системе постоянно растет. А потому борьба за предотвращение потери данных и прерывание работы критических приложений в случае отказа одного из тысяч компонентов сохраняет свою актуальность.
Отказоустойчивости сегодня посвящается много публикаций, однако некоторая путаница в терминологии и особенно в переводе англоязычных терминов может вызвать определенные трудности в понимании деталей. В данной статье под «отказоустойчивостью» понимается свойство системы сохранять работоспособность в случае случайного выхода из строя или сбоя отдельных компонентов. Под это определение попадают привычные англоязычные термины «High Availability» (HA), «Fault Resilient» (FR), «Fault Tolerance» (FT) и т.п., фактический смысл которых по существу заключается в количестве девяток после запятой в критерии надежности. Традиционно считается, что для обычной системы надежность достаточно 99%, для HA - 99,9%, для FR - 99,99%, для FT - 99,999% и т.д.
Под катастрофоустойчивостью будем понимать способность компьютерного комплекса, состоящего из нескольких систем, сохранить критически важные данные и продолжить выполнять свои функции после массового (возможно, целенаправленного) уничтожения его компонентов в результате различных катаклизмов как природного характера, так и инспирированных человеком. Этому определению точно соответствует англоязычный термин «Disaster Tolerance» (DT), однако в общем случае термин «Disaster Recovery» (DR) (дословно -«восстановление после катастрофы») можно также переводить как «катастрофоустойчивость». Отличие DR от DT состоит в том, что DR концентрирует внимание на сохранности данных (при строго контролируемых потерях, если они неизбежны), а средства для продолжения полноценной работы во многих случаях предполагаются внешними по отношению к собственно катастрофоустойчивой части комплекса.
Отказоустойчивость и катастрофоустойчивость: сходства и различия
Приведенные определения показывают разницу в подходах.
В понятии «отказоустойчивость» акцент делается на восстановление работоспособности после единичных, случайных, не связанных между собой отказов компонентов. Технология отработки таких отказов предполагает, как правило, что в работу вводятся резервные компоненты каждой подсистемы либо оставшиеся компоненты многократно дублированной подсистемы перераспределяют между собой работу независимо от того, что происходит в это время в других подсистемах.
В понятии «катастрофоустойчивость» главное — сохранение данных и продолжение работы в условиях массовых и, возможно, последовательных отказов систем и связанных между собой подсистем. Технология отработки отказов в этом случае требует учета взаимосвязанности подсистем и способности систем специфически реагировать на каждый вариант последовательности развития событий (так называемый сценарий катастрофы) с целью обеспечения максимально возможной сохранности защищаемых данных.
Второе различие кроется в распределении вероятностей отказов по подсистемам: в отказоустойчивых системах предполагается (хотя в большинстве случаев и неявно), что каналы связи между активными компонентами (например, медные или оптические кабели) гораздо надежнее самих активных компонентов, поскольку протяженность этих каналов ограничена и вероятность их повреждения в большинстве случаев относительно невелика. В территориально распределенных катастрофоустойчивых системах вероятность потери связи для каждого отдельного канала сравнима с вероятностью выхода из строя одного из активных компонентов. Это обстоятельство требует уделять повышенное внимание каналам связи и проблеме восстановления работоспособности после потери связи при проектировании и эксплуатации катастрофоустойчивой системы, причем сценарии отработки отказов и настройка всегда пишутся «по месту» - с учетом конкретных требований, как к комплексу в целом, так и к каждой площадке, принимая во внимание различные вероятности ожидаемых катастрофических событий. Потому просто «растянутая» в пространстве традиционная отказоустойчивая система без принятия дополнительных мер все же не может быть по-настоящему катастрофоустойчивой и в большинстве случаев не способна автоматически восстановить полную функциональность.
Катастрофоустойчивость предполагает в первую очередь обеспечение сохранности данных, а также возможность восстановить работу после крупной локальной аварии или глобального катаклизма, причем теми же средствами обеспечивается заодно и должная степень надежности (традиционная, «локальная», отказоустойчивость) всех или критически важных подсистем. Поскольку компоненты распределены, то в случае массовых отказов на одной площадке основную работу можно перенести на другую площадку.
Решения и уровни катастрофоустойчивости
Под катастрофоустойчивым решением понимается совокупность конфигурации программных и аппаратных средств, параметров настройки и организационных мер, которая обеспечивает сохранность жизненно важных данных и возможность продолжения работы вычислительного комплекса в случае различных катаклизмов, влекущих за собой выход из строя или уничтожение части комплекса. Как правило, это два или более вычислительных центра, соединенных каналами связи и разнесенных на большое расстояние, достаточное для того, чтобы возможная катастрофа не затронула сразу оба центра. Конфигурация и состав оборудования и программного обеспечения каждого центра, вообще говоря, могут отличаться друг от друга.
Катастрофоустойчивое решение, может защищать данные от большинства аппаратных и программных сбоев. Тем не менее, никакое решение не в состоянии защитить работоспособность комплекса в случае халатного администрирования и разгильдяйского подхода к настройке аппаратуры и программного обеспечения. Поэтому катастрофоустойчивое решение, во-первых, не может быть просто «вынуто из коробки», поскольку его всегда нужно проектировать (или как минимум, адаптировать) под конкретную ситуацию, а во-вторых, в подавляющем большинстве случаев оно не заменяет собой резервного копирования.
Очевидно, что существует отказоустойчивость без катастрофоустойчивости, однако катастрофоустойчивость без отказоустойчивости (в классическом понимании) тоже существует. К тому же катастрофоустойчивое решение вовсе не так дорого, как это принято считать - система может иметь разную степень катастрофоустойчивости и соответственно разную стоимость в зависимости от конфигурации, географической удаленности центров, требований к полноте и скорости восстановления работоспособности, периодичности проверок на соответствие требованиям к системе и процедурам.
Меры, направляемые на обеспечение отказо- и катастрофоустойчивости должны быть адекватны, во-первых, цене потерь из-за простоя в случае аварии или катастрофы, а во-вторых, ожидаемому типу и размеру бедствия. Так, если все центры и все пользователи, ими обслуживаемые, расположены в одной низине, вряд ли можно рассчитывать на продолжение работы в случае наводнения, но с другой стороны, при тотальном затоплении эффективность восстановления, возможно, уже некому будет оценить.
Допустим, объем критически важных данных относительно невелик, а изменения происходят достаточно редко и касаются небольшой части данных. Характерный пример - относительно небольшой, не очень критичный с точки зрения доступности и нечасто обновляемый Web-сервер. Предположим, для него допустимо достаточно продолжительное время восстановления работы, скажем, сутки, а потеря последних изменений не смертельна, поскольку их объем невелик и существует уверенность в том, что недостающие данные можно гарантированно восстановить за заданное время. Тогда приемлемым и самым дешевым способом обеспечения катастрофоустойчивости является регулярное дублированное резервное копирование с доставкой одной из резервных копий в удаленный вычислительный центр. В некоторых случаях такая доставка может осуществляться курьером, а при необходимости более оперативного копирования и восстановления и при наличии линии связи - посредством удаленного резервного копирования. Вообще говоря, центр резервного хранения даже не имеет компьютеров, а просто служит хранилищем кассет с резервными копиями. Иногда такое хранилище автоматизировано и снабжено емкой ленточной библиотекой, управляемой дистанционно из основного центра. Если рабочих центров несколько, можно переносить данные из резервного хранилища в любой из них и восстанавливать функциональность утраченного центра в сохранившемся, но классических средств отказоустойчивости может не быть ни в одном из центров, поскольку надежности обычных компьютеров вполне хватит для таких, весьма нетребовательных к времени восстановления условий.
При работе с базами данных относительно недорогим способом обеспечения восстановления после катастрофы является пересылка в удаленный центр журналов изменений, которые ведут большинство СУБД. Резервный центр при этом не обслуживает пользователей, однако обязан иметь комплект оборудования и ПО для поддержки соответствующей базы данных нужного объема, способный успевать вносить в нее изменения по мере поступления журналов из основного центра. Надо отдавать себе отчет в том, что резервная база всегда отстает по времени от основной и потому некоторая (контролируемая настройками СУБД и прикладных программ) потеря данных в случае выхода основного центра из строя практически неизбежна. Если, исходя из требований бизнеса, эта потеря может считаться несущественной или может быть восполнена из других источников за время, допустимое для возобновления работы, этот способ вполне удовлетворителен и потому довольно широко применяется. Одним из альтернативных способов спасения данных при работе с базами данных является регулярная репликация баз данных между центрами, однако, во-первых, не все СУБД поддерживают такой механизм, а во-вторых, как правило, для эффективности требуется довольно большая пиковая пропускная способность каналов связи. Репликацией часто пользуются при создании распределенных баз данных, в которых накопление изменений и анализ данных происходят в разных центрах.
Все приведенные примеры относятся к разновидностям решений класса DR, но если данные меняются быстро или потери недопустимы, то необходимо по-настоящему катастрофоустойчивое (DT) решение.
Нижним уровнем катастрофоустойчивости в смысле DT является удаленное копирование, при котором поддерживается синхронная зеркальная копия данных в удаленном центре. Компьютеры резервного центра при этом могут не принимать никакого участия в поддержании зеркальной копии и даже не знать о ее наличии; при этом для возобновления работы в случае гибели основного центра требуется существенное вмешательство человека, включая изменение конфигурации и перенастройку оборудования и программного обеспечения, а в редких случаях даже извлечение данных из сохранившейся копии вручную.
В этом случае восстановление работоспособности может потребовать значительного времени. Преимущество этого подхода заключается в универсальности - можно сохранять данные практически любых приложений, работающих под управлением любой операционной системой на любых компьютерах, даже не рассчитанных изначально на работу в распределенной среде или кластере - синхронность зеркальных копий данных обеспечивается специальным программным обеспечением контроллеров дисковых подсистем без участия самих приложений и ОС. Это решение также обеспечивает и отказоустойчивость дисковых массивов. Недостаток - принципиальная невозможность обеспечения полностью автоматической отработки отказа, поскольку операционная система и приложения ничего не знают об удаленном зеркалировании и не рассчитаны на обработку сложных отказов. В этом случае вмешательство человека необходимо.
Верхним уровнем DT является решение, поддерживающее как несколько удаленных копий данных, так и все необходимые серверные приложения в состоянии высокой готовности, и способное самостоятельно, без участия человека, отработать отказы без потерь данных. Тогда в случае гибели одного или нескольких центров работа продолжается автоматически, при этом конечный пользователь наблюдает лишь небольшую задержку. Такое решение обеспечивает также и полную «классическую» отказоустойчивость всего распределенного комплекса, причем время восстановления в случае катастрофы может быть относительно невелико и сравнимо со временем обработки единичного отказа, следовательно, достигается минимально возможное для конкретных условий время «недоступности» системы для пользователей. Это особенно важно, когда цена потери времени и тем более, потери части данных, чрезвычайно высока, например для финансовых и коммерческих организаций, работающих в интерактивном режиме (банки, биржи, расчетные центры, электронная торговля), а также для различных специфических организаций, постоянно собирающих и анализирующих текущую информацию.
Удаленное зеркалирование дисковых массивов
Если приложения или операционная система не в состоянии самостоятельно создавать удаленные копии, то для достижения катастрофоустойчивости следует использовать удаленное зеркалирование на уровне дисковых подсистем без участия ОС. Это не требует никаких изменений ни в приложениях, ни в ОС. Такой способ резервирования данных можно применять для любых операционных систем, однако для Windows NT и некоторых разновидностей Unix, не обладающих внутренними средствами для организации синхронного удаленного «зеркала», в большинстве случаев только он и гарантирует целостность и сохранность данных. Обработку данных можно вести с помощью имеющихся приложений, а хранилище данных следует организовать и настроить так, чтобы оно, с точки зрения приложений, принципиально не отличалось от «родного» хранилища.
Почему нельзя использовать обычный локальный дисковый массив RAID с «удаленной» половинкой зеркала? Большинство обычных RAID-контроллеров и программных средств зеркалирования дисков, разработанных для обеспечения локальной отказоустойчивости дисковых массивов, не могут обеспечить должной катастрофоустойчивости при попытке заставить их обеспечивать удаленное зеркало. Дело в том, что алгоритмы их работы ориентированы на концепцию «классической» отказоустойчивости, когда вероятность потери связи (обрыва проводов) пренебрежимо мала по сравнению с вероятностью выхода из строя диска. Поэтому для увеличения производительности здесь используются асинхронные механизмы записи.
В локальном варианте это не опасно: кэш-память так или иначе поддерживается батареями, и если вышел из строя один из дисков, измененные в этот момент данные остались либо на другом диске, либо в кэш-памяти значит они все равно будут записаны на сохранившийся диск. При таком алгоритме приложение узнает о том, что данные записаны, когда они попадут в кэш-память, а кэш-память может быть очищена, когда данные записаны на обе половины зеркала. При этом данные пишутся сначала на тот диск, который ответил первым, поскольку в локальном случае обе половины зеркала равноправны. Однако попытка разнести две половинки зеркала достаточно далеко друг от друга приводит к невозможности избежать потери данных (и даже контролировать потери) для многих сценариев развития серии последовательных отказов.
Представим, что у нас есть RAID 0+1, то есть массив из дисковых зеркал - такой набор дисков, где все данные записаны на разные диски по крайней мере дважды. В соответствии с описанным алгоритмом, диски массива получат свои данные по мере готовности к записи, а при обрыве связи в этот момент мы получим целостную копию только в первичном центре - том, который осуществлял запись. В другом центре будет часть дисков, успевших получить данные до обрыва связи и часть - неуспевших. Если в следующий момент рухнет здание первичного центра, то в нашем распоряжении останется копия, не обладающая целостностью.
В особо неудачных случаях эту копию не удастся даже прочитать - классическим примером является «неудачное» выдергивание диска при использовании файловой системы ufs. Файловая система с журналированием (например, Advanced File System - advfs в Tru64 UNIX) в этом случае прочитает оставшиеся целостными данные, но мы можем так и не узнать, что именно потеряно, поскольку нет возможности контроля последовательности записи на диски. К тому же в тяжелых случаях - например, при записи упакованного архива - мы рискуем потерять все данные при физическом отсутствии только некоторой их части.
Катастрофоустойчивая дисковая система
Если и приходится работать с асинхронным алгоритмом, как в описанных случаях восстановления после катастроф (DR), то потери должны быть строго контролируемыми, а данные, хранящиеся в резервном центре, должны всегда быть целостными. Вот почему для максимальной сохранности данных алгоритм должен быть синхронным - приложение получает сигнал о записи при свершившейся записи на все диски, а записывать нужно сначала на диски вторичного - удаленного центра. Значит контроллеры обоих центров или программное обеспечение должны соответствующим образом настраиваться, а системный администратор должен четко понимать, что первично, а что вторично!
На этот случай Compaq располагает решением на основе Fibre Channel с дисковыми подсистемами StorageWorks RAID Array 8000 или ESA12000, представляющими собой отказоустойчивые (Fault Tolerant) комплексы с возможностью полного (N+N) дублирования компонентов и зеркальными кэшами контроллеров. При удалении основного и резервного центра на расстояние до 10 км используются стандартные компоненты, а при расстояниях до 70 км - специальное оборудование, усиливающее сигнал без изменения протокола. При использовании оборудования, позволяющего передавать протоколы, используемые в Fibre Channel, через сети ATM, это предельное расстояние теоретически неограниченно.
При удаленном зеркалировании данных с помощью разнесенных дисковых массивов, необходимы следующие компоненты (рис. 1):
- две или четыре пары RAID-контроллеров HSG80 (основа дисковых подсистем StorageWorks RA8000 и ESA12000 ) и программное обеспечение Data Replication Manager Software, обеспечивающие взаимодействие удаленных RAID-контроллеров, создание зеркальных копий между центрами и отработку отказов компонент систем хранения информации;
- четыре коммутатора Fibre Channel с необходимым дополнительным оборудованием для подключения дисковых подсистем к основному и резервному каналам связи, а также подключения серверов к дисковым подсистемам;
- дополнительное ПО, поддерживающее альтернативные пути между сервером и дисковой подсистемой, если ОС сервера не поддерживает множественные пути к одному диску. Например, для NT и Sun Solaris используется программное обеспечение Secure Path;
- проработанные сценарии восстановления, воплощенные в специальных инструкциях для операторов конкретного центра, поскольку восстановление работоспособности требует вмешательства оператора.
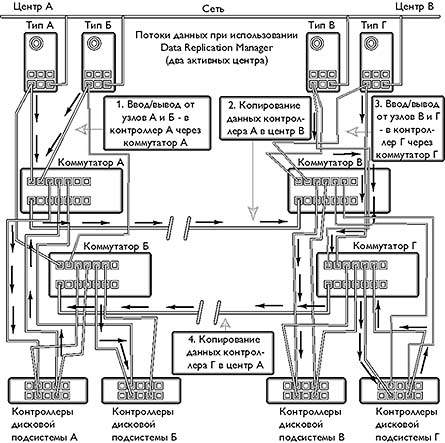 |
| Рис.1. Схема зеркалирования дисковых подсистем между основным и резервным центрами |
В качестве каналов связи, соединяющих центры, используются по одной паре одномодовых 9-микронных оптических жил из двух оптоволоконных кабелей, проложенных двумя различными путями между коммутаторами Fibre Channel основного и резервного центров. Возможно также использование коммутаторов Fibre Channel — ATM, что позволяет существенно увеличить расстояние, хотя и снизить производительность. Пропускная способность каждого канала в зависимости от требований ко времени отклика приложений и требуемой нагрузки может лежать в достаточно больших пределах - от 1,5 Мбит/с до 100 Мбайт/с.
Безопасность, сохранность данных и секретность обеспечиваются как свойствами контроллеров дисковых массивов, организацией дублированных связей и свойствами среды передачи, так и адекватно проработанными сценариями отработки отказов и инструкциями для оператора. Среда передачи - оптоволокно - не позволяет подключить постороннее оборудование в линию связи без разрыва кабеля и, соответственно, обрыва связи. Без подключения такого оборудования прочитать данные, передаваемые по оптоволоконным линиям связи невозможно. Значит использование канала, восстановившегося после обрыва связи, должно происходить только по команде оператора после соответствующей проверки.
Варианты организации работы центров
Решение на основе удаленного зеркалирования дисковых массивов позволяет организовать работу двух центров несколькими различными способами.
Первичный и вторичный центры
Главный (первичный) центр несет всю нагрузку по сбору и обработке информации, а вторичный только поддерживает удаленные зеркальные копии дисков первичного центра. В случае выхода из строя первичного центра, после вмешательства оператора, вторичный принимает на себя всю нагрузку. В этом случае достаточно двух пар контроллеров HSG80, а серверы резервного (вторичного) центра простаивают или хранят и обрабатывают информацию, не требующую удаленного резервирования.
Смешанная нагрузка
Приложения работают в обоих центрах, но это разные приложения, часто обслуживающие разных пользователей. Все или только некоторые диски зазеркалированы между центрами. При выходе из строя одного из центров вся обработка данных происходит в другом центре. На компьютерах сохранившегося центра осуществляется запуск (или активизация) приложений, работавших в вышедшем из строя центре. Этот вариант заметно эффективнее, но и дороже, чем предыдущий, поскольку требует четырех пар контроллеров HSG80 (две первичных и две вторичных - по одной первичной и одной вторичной паре контроллеров в каждом центре).
Поскольку решение на основе удаленного зеркалирования дисковых массивов почти не зависит от операционной системы и приложений, работающих на компьютерах обоих центров, оно потенциально способно поддерживать «зоопарк» из разных компьютеров и операционных систем - и это позволяет строить катастрофоустойчивые комплексы, работающие с Tru64 UNIX или, с Sun Solaris и Windows NT. С другой стороны, такая «независимость» не позволяет поддерживать распределенную работу, когда одно приложение работает одновременно и параллельно в обоих центрах с одними и теми же данными, хранящимися на одних и тех же зеркальных дисках. Такой функциональностью обладает только VMS-кластер.
Обработка единичных отказов
Решение на основе дисковых массивов StorageWorks обеспечивает резервирование всех компонентов, включая контроллеры, кэш-память, коммутаторы, линии связи, устанавливаемые в сервера адаптеры, диски и сами данные.
В нормальном режиме работы контроллеры каждой пары работают в режиме взаимного резервирования (dual-redundant mode), поддерживая зеркальную кэш-память и используя дублированные каналы Fibre Channel для доступа серверов к данным. Одновременно контроллеры первичной пары передают данные контроллерам вторичной пары для поддержки зеркальных копий на дисках вторичной пары. Серверы резервного центра не имеют доступа к дискам, которые доступны серверам основного центра, и наоборот, данные, обрабатываемые серверами резервного центра недоступны серверам основного центра. Запись на диски, входящие в состав зеркал происходит синхронно, то есть сервер получает от дискового массива сигнал о том, что данные записаны только после того, как они будут записаны на обе половинки зеркала, что гарантирует сохранность и целостность данных. Возможен и асинхронный режим, когда данные сначала записываются на основной диск, потом серверу сообщается, что запись произведена, и одновременно данные передаются в удаленный центр. Но этот режим следует использовать осторожно, поскольку он хотя и повышает производительность, но допускает потери данных при гибели главного центра.
Все компоненты, включая каналы передачи данных, задублированы. Поэтому в случае единичного отказа любого компонента нагрузка автоматически переносится на дублирующий, данные при этом не теряются. При обрыве основной линии связи нагрузка автоматически переносится на резервную линию.
Отработка полного отказа одного из центров
При полной потере связи между центрами или полном выходом из строя одного из них, с точки зрения контроллеров дисковых массивов наступает ситуация «катастрофы». При этом следует различать: истинные катастрофы, приводящие к полной неработоспособности одного из центров и полный обрыв связи с сохранением работоспособности обоих центров. Контроллеры не различают эти ситуации, поскольку общаются между собой только по каналам Fibre Channel. Именно поэтому каналы связи должны быть задублированы, а решение о переносе нагрузки в сохранившийся центр должен принимать человек на основе дополнительной информации.
В случае возникновения истинной катастрофы вся обработка должна быть переведена в сохранившийся центр. При этом потеря вторичных массивов не влечет за собой изменений в работе серверов и приложений, работающих с первичными массивами. Гибель первичных массивов требует изменения настроек коммутаторов и контроллеров таким образом, чтобы серверы сохранившегося центра смогли получить доступ к зеркальной копии данных выведенного из строя центра, сохранившейся в «выжившем» центре. При этом запускаются необходимые приложения, заранее установленные и сконфигурированные так, чтобы они смогли получить доступ к этим данным. В большинстве случаев для правильной работы приложений можно сконфигурировать и настроить компьютеры резервного центра так, чтобы они были полностью идентичны компьютерам основного центра. В этом случае потребуется минимальное вмешательство оператора, но тогда резервные компьютеры в нормальном режиме будут либо простаивать, либо будут заняты второстепенными задачами, не требующими отказо- и катастрофоустойчивости, иначе их придется переконфигурировать.
Во второй ситуации полная потеря связи может привести к рассинхронизации первичного и вторичного зеркал. Первичный центр может продолжать работу, но удаленные копии не будут поддерживаться до вмешательства оператора, даже если связь восстановится. Вторичный центр при этом «заморозит» свою копию. Если при полной потере связи оператор вторичного центра принял решение об отработке отказа как при катастрофе, то сначала требуется полная остановка первичного центра (если он еще работает), поскольку в противном случае слияние массивов данных, различных в обоих центрах, может стать неразрешимой задачей. Если же одна из копий сохраняет свое состояние на момент обрыва связи, то первичной может считаться более поздняя копия. После восстановления связи оператор принимает решение о том, какую копию считать истинной и запускает процесс восстановления зеркала.
Описанное решение теоретически позволяет создавать катастрофоустойчивое хранение данных для любой операционной системы без внесения каких-либо изменений в саму ОС и ее приложения. Однако для обеспечения гарантированной целостности данных и альтернативных путей доступа к ним, необходимо, чтобы конкретная операционная система могла общаться с контроллерами дисковых массивов, а не считать их просто диском. Для этого создаются наборы соответствующих драйверов устройств или агентов, взаимодействующих с централизованной системой управления дисковыми массивами, а в ряде случаев, дополнительное системное ПО, такое как Secure Path для NT, Windows 2000 и Solaris, обеспечивающее операционной системе возможность автоматического распознавания и использования альтернативных путей доступа к дискам. На сегодняшний день выпущены комплекты драйверов и другого вспомогательного программного обеспечения (platform kit) для NT, OpenVMS, а также разнообразных клонов Unix, работающих на платформах Compaq, Sun, HP и IBM. Такие комплекты дополняют возможности самих операционных систем.
О пользе третьей площадки
Для того чтобы преодолеть ограничения, присущие способу удаленного зеркалирования данных можно организовать хранение данных с помощью операционной системы, способной самостоятельно поддерживать удаленные зеркала на уровне операционной системы.
Единственным катастрофоустойчивым решением, способным поддерживать несколько удаленных на большое расстояние (до 800 км) центров и при этом автоматически производить отработку отказов, а также обеспечивать параллельную обработку одних и тех же данных во всех центрах одновременно, остается решение на основе проверенного реальными событиями кластера под управлением OpenVMS. При построении VMS-кластера, в общем случае, задействуются следующие компоненты:
- операционная система OpenVMS и программное обеспечение VMScluster, обеспечивающие функционирование компьютеров и систем хранения информации удаленных центров как единого целого;
- программное обеспечение Volume Shadowing for OpenVMS для создания зеркальных копий между центрами;
- проработанные сценарии восстановления, воплощенные в специальных процедурах восстановления, зависящих от конкретного центра, что позволяет существенно сократить время восстановления;
- станция, обеспечивающая эффективное управление катастрофоустойчивым комплексом из любого центра.
В качестве сети, соединяющей центры, наиболее эффективным является применение Gigabit Ethernet на небольших (до 2 км) и средних расстояниях (до 70 км). В серверы устанавливаются платы Gigabit Ethernet для подключения к маршрутизаторам и/или коммутаторам, обеспечивающим доступ к сети. В этом случае сеть является однородной и обладает наименьшими задержками. Использование ATM оправдано лишь на больших расстояниях (сотни километров).
Кластер с удаленными центрами
На рис. 2 показан типичный VMS-кластер, применяющийся для создания катастрофоустойчивого решения
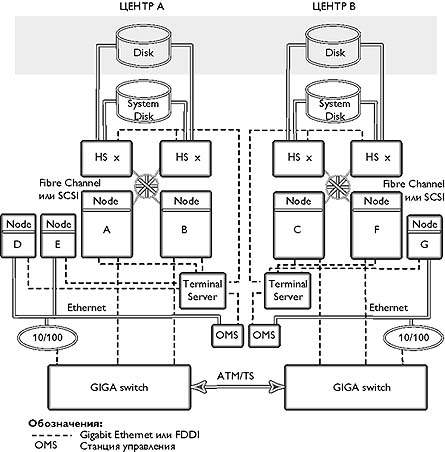 |
| Рис. 2. Типичный VMS-кластер |
Центры могут быть соединены каналами Gigabit Ethernet, FDDI, ATM/SONET или T3/SONET, в зависимости от требуемой пропускной способности и необходимого расстояния. Компьютеры соединены между собой через расширенную локальную сеть (ELAN) путем подключения к каналам, соединяющим центры, через маршрутизаторы или коммутаторы, например, GIGAswitch. Для подключения членов кластера к коммутаторам следует использовать Fast или Gigabit Ethernet, а также FDDI.
Сети ATM обладают большими накладными информационными расходами (полезная нагрузка составляет около 70% от полной пропускной способности), по сравнению с сетями FDDI и Gigabit Ethernet (полезная нагрузка может достигать 90% и даже 95% на FDDI от полной пропускной способности). Кроме того, поскольку адаптеры ATM, устанавливаемые в серверах, пока не поддерживают внутрикластерные коммуникации, к тому же стандартизация и интероперабельность устройств ATM разных производителей оставляют желать лучшего, в серверы приходится устанавливать карты FDDI или Gigabit Ethernet, что приводит к дополнительным задержкам на коммутаторах Gigabit Ethernet-to-ATM или FDDI-to-ATM. В то же время полная пропускная способность FDDI на порядок ниже, чем у Gigabit Ethernet. Поэтому, если позволяет расстояние, для наиболее эффективного использования проложенных оптических кабелей в качестве основы всей сети рекомендуется использовать оборудование Gigabit Ethernet, связывающее центры до 2 км на стандартном оборудовании или до 70 км на специальном оборудовании. На больших расстояниях, как правило, используются магистрали ATM с соответствующими коммутаторами.
Для повышения надежности и централизации управления рекомендуются консоли всех компьютеров и дисковых контроллеров подключить к сети через терминальные серверы. Это позволит управлять всеми устройствами любого из центров с единой станции управления. Подключение консолей через терминальный сервер позволяет управлять компьютерами удаленного центра даже при незагруженной операционной системе. Есть конечно и альтернативные способы: использовать модем для дозвона и подсоединения к удаленной консоли, или разместить в каждом центре по собственному системному администратору. Использование конкретных методов управления зависит от конкретных задач, а также от стратегии использования и развития кластера.
Как и в классическом, локальном VMS-кластере, отказ любого из компонентов не фатален. Путем настройки параметров, определяющих количество голосов, можно указать, какой из центров продолжит работу в случае обрыва связи (основной центр), а какой остановит работу (резервный).
Схемы с двумя и тремя центрами
На рис. 2 была представлена схема с двумя центрами, соединенными высокоскоростным каналом связи, обеспечивающим эффективное зеркалирование дисков. Если один из центров выходит из строя, то другой продолжает работу только после вмешательства оператора, поскольку автоматическая отработка отказа в этом случае может привести к потере данных или распаду кластера на две независимые части в случае полного нарушения связи между центрами при продолжении функционирования самих центров. Отметим, что дублирование линий связи разными путями все же не делает вероятность выхода из строя всех линий и/или коммуникационного оборудования равной нулю, особенно при глобальных катастрофах, поэтому опасность потери данных при автоматической отработке отказа в системе с двумя центрами сохраняется.
В общем случае, процедура возобновления работы резервного центра определяется политикой отработки такого отказа, требующего принятия человеком (например, руководством организации или отдела автоматизации) решения о возобновлении работы именно в резервном центре, поскольку кластерное программное обеспечение в этом случае не может определить, вышел ли сам основной центр из строя или просто оборвалась связь.
В VMS-кластере существует механизм голосов и кворума, позволяющий в случае недоступности (выход из строя или обрыв связи) одного или нескольких членов кластера автоматически определить, следует ли продолжать работу каждому из оставшихся. Поэтому можно поместить в третий, независимый от первых двух, центр небольшой компьютер, «наблюдающий» за основными центрами и обеспечивающий «кворум» (рис. 3). В этом случае вмешательство человека при отработке отказа, как правило, не требуется.
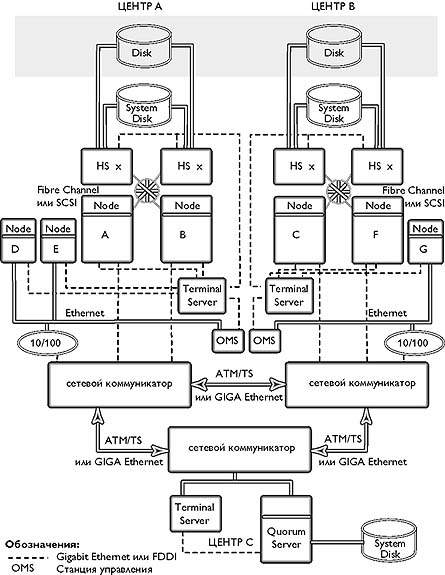 |
| Рис. 3. Схема кластера с тремя площадками |
Кворум-сервер должен находиться на третьей площадке, подключенной независимыми линиями связи к каждому из центров так, чтобы основные центры могли взаимодействовать между собой по этим линиям связи при выходе из строя основного канала. При этом кворум-сервер может не обрабатывать и не хранить данные, а только следить за доступностью основных членов кластера. Впрочем, можно организовать и третий полноценный центр - это повысит сохранность наиболее ценных данных и к тому же может дать некоторый выигрыш при распределенной работе.
Варианты организации работы центров
При использовании двух центров возможны следующие варианты организации их работы.
- Первичный и вторичный центры. Главный (первичный) центр несет всю нагрузку по сбору и обработке информации, а вторичный только поддерживает удаленные зеркальные копии дисков первичного. В случае выхода из строя первичного центра, вторичный принимает на себя всю нагрузку. Важно отметить, что нагрузка на сеть в этом случае относительно не велика. Через сеть осуществляется только запись на диски вторичного центра с помощью программного обеспечения зеркалирования Volume Shadowing. Чтение с дисков вторичного центра происходит только в случае сбоя диска или контроллера дисков в первичном центре.
- Смешанная нагрузка. Приложения работают в обоих центрах, но это разные приложения, часто обслуживающие разных пользователей. Все или только некоторые диски зазеркалированы между центрами. Нагрузка на сеть определяется, в основном, процессом зеркалирования при записи на диски. Она существенно выше, чем в предыдущем случае. При выходе из строя одного из центров вся обработка данных происходит в другом центре. На компьютерах сохранившегося центра осуществляется запуск (или активизация) приложений, работавших в вышедшем из строя центре.
- Распределенная работа. Одно или несколько приложений работают в обоих центрах одновременно и параллельно (например, Oracle Parallel Server), при этом диски центров зазеркалированы между собой. Нагрузка на сеть в этом случае наиболее велика, а задержки при установке программных «защелок», определяющиеся суммарными задержками в коммуникационной сети (минимальные задержки на сегодняшний день обеспечивают коммутируемые сети FDDI и Gigabit Ethernet), могут существенно повлиять на производительность. Однако при использовании грамотно написанного и настроенного приложения, способного минимизировать нагрузку на сеть (например, каждый центр в нормальном режиме обслуживает запросы только «своих» пользователей), можно получить выигрыш в суммарной производительности. Выход из строя одного из центров, естественно, уменьшает суммарную производительность, зато данные остаются в целости и сохранности.
Обработка отказов
VMS-кластеры обеспечивают резервирование (дублирование, утроение и т.д.) многих компонентов, включая собственно компьютеры, линии связи, адаптеры и контроллеры, устройства хранения данных и сами данные. В нормальном режиме работы большинство резервных компонентов используются параллельно с возможностью балансировки нагрузки, включая ее распределение по нескольким сетевым интерфейсам Ethernet и FDDI. В случае отказа одного из компонентов, остальные остаются доступными для пользователей и приложений, перераспределяя нагрузку между собой. VMS-кластеры обеспечивают также следующие варианты восстановления для разных механизмов отработки отказа.
Кластерное имя. Если член кластера выходит из строя, то программное обеспечение автоматически перераспределяет все новые входящие запросы между оставшимися членами кластера. Восстановление при этом может выполняться автоматически (для клиентских или серверных приложений, самостоятельно восстанавливающих связь и, используя кластерное имя, автоматически переадресующих запросы на один из оставшихся узлов), либо вручную. В последнем случае интерактивные пользователи, использовавшие терминальные сессии на отказавшем узле, должны переподсоединиться к кластеру, используя кластерное имя. ПО кластера решает, к какому именно узлу будет поключен тот или иной пользователь.
Альтернативные пути ввода/вывода. При наличии альтернативных путей к другим членам кластера и устройствам хранения данных используется работающий путь. Восстановление осуществляется прозрачно, при наличии альтернативного пути - в этом случае выбирается наиболее быстрый путь. Если связь нарушается, то выбирается наиболее быстрый из оставшихся. При наличии по крайней мере двух узлов, обеспечивающих дисковые и загрузочные сервисы, члены кластера и бездисковые станции могут продолжать использовать диски и загружать операционную систему при отказе одного из узлов. Отказ загрузочного сервера не влияет на работу уже загрузившихся компьютеров, при условии, что у них есть альтернативные пути к дисковым сервисам.
Общие (generic) очереди пакетной обработки и печати. Можно настроить общие очереди, пересылающие задания в обрабатывающие очереди на конкретном узле. При отказе узла такая очередь будет продолжать посылать задания на оставшиеся узлы. Кроме того, задание, помещенное в очередь с ключом /RESTART, будет автоматически запущено на одном из оставшихся узлов. Восстановление осуществляется прозрачно для заданий, ожидающих в очереди и автоматически или вручную (в зависимости от настройки и специфики приложений) для заданий, выполнявшихся на отказавшем узле.
Автоматически стартующие очереди. Можно настроить очереди обработки в качестве автоматически стартующих со списком отработки отказов. При отказе узла такая очередь и все ее задания автоматически перемещаются на следующий в списке узел и продолжают работать. Восстановление прозрачно.
Удаленное резервное копирование
Члены VMS-кластера, к которым подключены накопители на магнитных лентах, могут предоставлять другим членам удаленный доступ к этим ленточным накопителям. Таким образом, можно осуществлять удаленное резервное копирование одного из центров в другом. Можно также вести архивы, например, в специально выделенном для этого центре.
Заключение
Два описанных катастрофоустойчивых решения не являются взаимоисключающими, но органично дополняют друг друга. Если интерфейс Fibre Channel изначально ориентирован на работу с дисковыми подсистемами и позволяет разгрузить классические сетевые интерфейсы и во многих случаях ускорить доступ к данным (его можно использовать и в VMS-кластере), то решение, ориентированное только на классический сетевой кластер, позволяет обеспечить автоматическую обработку отказов и существенно уменьшить число сценариев различных отказов, а, значит, облегчить настройку и тестирование.
Об авторе
Кирилл Вахрамеев — менеджер по системам хранения информации российского представительства Compaq, «Посол» OpenVMS (OpenVMS Ambassador). С ним можно связаться по электронной почте по адресу: kirill.vakhrameev@compaq.com
