

Большинство отраслевых аналитиков сходятся во мнении, что с периодом примерно в шесть лет суммарное количество данных, накапливаемых в компьютерных базах, увеличивается на три порядка, а это существенно выше прироста производительности компьютеров. С определенной натяжкой можно утверждать, что производительность процессоров увеличивается за те же шесть лет на один порядок – терабайтные диски позволяют создать петабайтное хранилище без особой сложности, но сдерживающим фактором становится скорость обработки.
Cкорость доступа к данным можно было бы поднять в сотни и более раз, если перейти от последовательных схем к параллельным, и предпосылки к таким решениям уже существуют: кластерные конфигурации, многоядерные процессоры (multicore и manycore). По некоторым прогнозам, именно базы данных окажутся «убийственным приложением» для многоядерных процессоров и расчистят дорогу новому поколению процессоров. В отличие от многих других приложений, работа с данными распараллеливается более естественным образом. Разделить базу на фрагменты, передать их обработку на узлы кластера или в ядра многоядерного процессора, а затем каким-то образом собрать полученные промежуточные результаты и сформулировать решение проще, чем решить традиционную для кластеров задачу распараллеливания сложной модели.
База данных без общих ресурсов
Если база данных построена на общем информационном ресурсе, то разделить ее на части для параллельной обработки невозможно, следовательно, предметом распараллеливания должна быть не классическая реляционная база, а база, изначально рассчитанная на архитектуру без разделения ресурсов (Shared Nothing, SN). До сих пор у специалистов по СУБД архитектура SN оставалась на периферии внимания, впрочем, иногда ее противопоставляют централизованным решениям, сравнивают с решениями на основе реляционных СУБД и серверов приложений, но не рассматривают в качестве реального конкурента им. Чаще всего представление о SN ограничивают различного рода Web-приложениями. Это покажется особенно удивительным, если вспомнить, что первым идею базы данных с архитектурой SN выдвинул сам Майкл Стоунбрейкер, один из первопроходцев реляционных СУБД, причем сделал это задолго до появления WWW. В 1986 году в статье The Case for Shared Nothing он выделил три категории систем, способных хранить данные: с разделяемой памятью (Shared Memory, SM), с разделяемыми дисками (Shared Disk, SD) и не разделяющими ничего (SN). Первым двум соответствовало множество различных систем, а архитектура SN была представлена только сетевыми по своей природе компьютерами Tandem (сегодня их наследниками являются HP NonStop Himalaya S-Series). И все же Стоунбрейкеру удалось показать, что гипотетически архитектура SN наиболее предпочтительна, в том числе и с экономической точки зрения. Но двадцать лет назад сетевые архитектуры не были достаточно развиты, а решения Tandem, несмотря на всю их изящность, оставались проприетарными и в силу этого слишком дорогими. Нет ничего удивительного, что эволюция серверов пошла иным путем. Но сегодня к SN возвращаются уже на другом витке развития технологий, и в данном случае приоритет возрождения принадлежит Google, архитектура SN воплощена в конструкции, называемой MapReduce.
Приложения, построенные на основе MapReduce, в принципе можно рассматривать и как базы данных, но не в том смысле, что в их основе обязательно лежит реляционная модель с доступом к данным с помощью языка SQL, а как опирающиеся на альтернативную модель и рассчитанные на очень большие хранилища данных.
Три архитектуры
При создании аппаратных систем, поддерживающих базы данных, возможен выбор между тремя архитектурными вариантами: share-everything, share-disk и share-nothing (рис. 1).
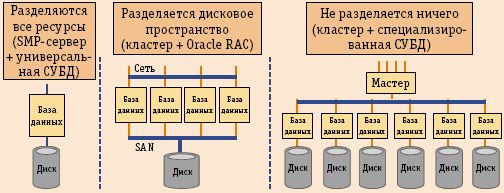
Рис. 1. Архитектуры хранилищ данных
Наиболее массовыми являются решения share-everything, где разделяются все ресурсы. Они предполагают использование универсальных серверов с множеством симметричных процессоров SMP (Symmetric Multi-Processing) в сочетании с реляционными, реже объектными или постреляционными СУБД. В этих решениях воплощены основные идеологические принципы, на которых строились компьютеры для корпоративных приложений, – с конца 60-х годов качество компьютеров оценивалось по их способности к распределению ресурсов. Реляционные базы создавались в расчете на транзакционную обработку данных (OLTP) на мощных SMP-серверах, обеспечивающих полное распределение всех ресурсов. Даже когда в девяностых годах стали постепенно осознавать достоинства систем с массовым параллелизмом (MPP), с точки зрения СУБД преимущество сохранялось за SMP, главным образом из-за преемственности и совместимости программного обеспечения. Но со временем с большей остротой стали проявляться два основных недостатка shared-everything. Каждый процессор должен быть осведомлен о деятельности остальных – часть мощности уходит на поддержку «коммунальной жизни», что в конечном итоге задает предел числа процессоров в одной системе, поскольку издержки растут экспоненциально. Пользование общим дисковым пространством ведет к перегрузке канала, связывающего процессоры с памятью, и серверы этого типа имеют врожденный предел роста.
В качестве одной из альтернатив SMP-серверам можно рассматривать кластерные архитектуры, в которых распределяемым является только дисковое пространство, системы этого класса поддерживаются, например, в Oracle RAC (Real application Cluster). Кластер с разделяемыми дисками, на котором работает хранилище данных, собирается из нескольких серверов и через SAN подключается к распределяемым системам хранения данных. Наиболее полно RAC реализован в продукте HP Oracle Database Machine. Эта машина баз данных состоит из программных компонентов от Oracle, серверов стандартной архитектуры от HP и структурно представляет собой две grid-системы – на одной (8 серверов Oracle Database Server на HP Proliant DL360 G5) работает СУБД, а вторая (14 серверов Oracle Exadata Storage на HP ProLiant DL180 G5) предназначена для хранения данных. Эти специализированные серверы отличаются от обычных Linux-серверов тем, что в них встроено программное обеспечение, позволяющее часть функций по обработке запросов выполнять в параллельном режиме, то есть некоторая часть работы с базой выполняется локально, что естественным образом ускоряет работу. Вместе две системы объединены через InfiniBand. Избранная архитектура и высокоскоростное межсоединение избавляют HP Oracle Database Machine от проблем, связанных с «бутылочным горлом».
Третье решение – использование стандартных серверов по принципу «никаких общих ресурсов» . Подобные архитектуры отлично зарекомендовали себя применительно к высокопроизводительным вычислениям, но их внедрение в других областях ограничивается сложностями, связанными с распараллеливанием приложений. Идея баз данных без общих ресурсов (shared-nothing database) в течение длительного срока жила в продуктах компании Teradata, выпускающей MPP-системы с собственной коммутационной инфраструктурой BYNET. До последнего времени единственной альтернативой изделиям от Teradata были специализированные серверы Netezza Performance Server (NPS). Верхний уровень этих серверов – хост на базе SMP-сервера, работающий под управлением Linux, а нижний уровень – сотни лезвий Snippet Processing Unit (SPU), образующих кластер. Задача хоста состоит в преобразовании пользовательских запросов в лоскутные SPU и возврате результатов пользователям. Каждый из SPU отвечает за выполнение отдельной части запроса. Эти системы ориентированы в основном на бизнес-аналитику.
Недавно к этой небольшой группе разработчиков присоединилась компания Greenplum, которая начала с нуля, но подошла к делу радикально, собрав команду высококвалифицированных специалистов и написав совершенно новую СУБД. Отличие альтернативной архитектуры в том, что каждый отдельный компонент этой СУБД играет роль законченной, самодостаточной мини-СУБД, которая сама владеет и оперирует отдельной порцией доверенных ей данных. Эта мини-СУБД автоматически распределяет данные и нагрузку по обработке запросов по доступным ей аппаратными ресурсам. Для своего старта компания Greenplum избрала удачный с точки зрения технической конъюнктуры момент – она решила стать первым поставщиком «убийственного приложения» многоядерных процессоров. Во главу угла ее стратегии поставлена идея сборки систем, аналогичных по своей функциональности продуктам компаний Teradata и Netezza, но отличающихся тем, что в них используется широко распространенное аппаратное обеспечение. Можно сказать, что Greenplum решила повторить Google, но применительно к базам данных. Иными словами, разработчики Greenplum решили обеспечить доступ к данным не только средствами поиска, но и через SQL. Поскольку Greenplum исключительно программная компания, основным моментом заимствования стала программная конструкция MapReduce, разработанная в Google.
Технологическое начинание Greenplum заслужило высокую оценку в экспертном сообществе – в отчете Gartner «Магический квадрант СУБД для хранилищ данных» от 24 января 2008 года лишь эта компания находится в части квадранта visionaries (провидцы), что свидетельствует о несомненной перспективности, но еще недостаточной массовости предлагаемых технологий или продуктов. В отчете о Greenplum подчеркивается как достоинство монопродуктовая ориентация – компания поставляет исключительно системы управления базами данных для хранилищ. Ее продукты ориентированы на системы с массовым параллелизмом, в них используется модернизированная версия PostgreSQL, объектно-реляционной СУБД с открытыми кодами, созданной в конце 90-х годов как логическое продолжение СУБД Ingress. Продукция Greenplum распространяется в комплекте со специализированными программируемыми устройствами (appliance). Поставщиком оборудования является Sun Microsystems – две компании выпускают Sun Data Warehouse Appliance, состоящие из специализированных серверов Sun Fire X4540 и Greenplum Dtabase.
Введение в MapReduce
Программная конструкция MapReduce пошла от Google, известной не только своими технологическими достижениями, но и способностью их скрывать. Именно в таком духе выдержана статья Джефри Дина и Санжая Чемавата «MapReduce: упрощенная обработка данных на больших кластерах» (MapReduce: Simplied Data Processing on Large Clusters), недосказанности которой компенсирует работа Ральфа Ламмеля из Исследовательского центра Microsoft в Редмонде «Модель программирования MapReduce компании Google» (Google’s MapReduce Programming Model). Во введении Ламмель заявляет, что он проанализировал статью Дина и Чемавата, которую он неоднократно и с почтением называет seminal (судьбоносной), используя метод, который называется «обратной инженерией» (reverse engineering). То есть, не выходя за рамки ограничений на авторские права, он постарался раскрыть смысл того, что же в ней на самом деле представлено. Ламмель увязывает MapReduce с функциональным программированием, языками Лисп и Haskell, что естественным образом вводит читателя в контекст.
Но работа Ламмеля ориентирована исключительно на программистов-разработчиков, поэтому, прежде чем изложить в адаптированной форме программную концепцию MapReduce, остановимся на том, что у Ламмеля не сказано, но что критически важно для понимания предпосылок. Дело в том, что MapReduce – это не просто программный каркас (framework), как ее предшественники в Лисп, а скорее инфраструктурное решение, способное эффективно использовать сегодня кластерные, а в будущем многоядерные архитектуры, своей перспективностью она и привлекает к себе повышенное внимание.
Почему же значимость MapReduce выходит за пределы тех приложений, для которых этот программный каркас используется в Google, и привлекает к себе всеобщее внимание? Те огромные кластеры, на которых она применяется, и поисковые задачи на самом деле всего лишь частный случай. По мнению одного из выдающихся умов современности, профессора Калифорнийского университета
в Беркли Дейва Паттерсона, MapReduce станет одним из основных инструментов программирования в будущем (см. презентацию The Parallel Revolution Has Started), когда жизнь будет подчиняться не только классическому, но и модифицированному закону Мура, утверждающему, что с определенной периодичностью будет удваиваться и число транзисторов на кристалле, и число ядер, при этом сложность ядер и тактовая частота останутся практически неизменными. Использование MapReduce позволит реализовывать архитектуры, попадающие в категорию SPMD (Single Program Multiple Data).
Одним из самых важных моментов предстоящей революции станет отказ от нынешней последовательной модели компьютинга, основанной на исходной редакции схемы фон Неймана, и переход к параллельной. Будет происходить постепенный отказ от SISD (Single Instruction Single Data – «один поток команд, один поток SPMD данных») и переход к SIMD (Single Instruction Multiple Data – «один поток команд, много потоков данных») и MIMD (Multiple Instruction Multiple Data – «много потоков команд, много потоков данных»). Такая классификация, делящая пространство возможностей на четыре части SISD, SIMD, MISD, Multiple Instruction Single Data – «много потоков команд, один поток данных», и MIMD – была предложена Майклом Флинном в начале 70-х годов, когда распараллеливание казалось возможным только на уровне машинных инструкций. Сегодня, с появлением компактных серверов и многоядерных процессоров можно, выполнять параллельно не только инструкции, но и фрагменты кодов, и она может быть уточ-нена – SIMD и MIMD превращаются в SPMD и MPMD (Multiple Program Multiple Data), в том и в другом случае инструкцию заменила программа.
Большинство современных параллельных компьютеров, том числе подавляющая часть супер компьютеров, входящих в список Tор500, принадлежит к категории MPMD. Каждый узел выполняет фрагмент общего задания, работая со своими собственными данными, а в дополнение существует сложная система обмена сообщениями, обеспечивающая согласование совместной работы. Такой вид параллелизма раньше называли параллелизмом на уровне команд (instruction-level parallelism, ILP), а сейчас параллелизмом на уровне задач (task level parallelism), но иногда его еще называют функциональным параллелизмом или параллелизмом по управлению. Его реализация сводится к распределению заданий по узлам и обеспечению синхронности происходящих процессов.
Альтернативный тип параллелизма называют параллелизмом данных (data parallelism), который по классификации Флинна попадает в категорию SIMD. Идея SIMD впервые была реализована еще в 70-е годы на компьютерах CDC Star-100 и Texas Instruments ASC, а популярность эта архитектура приобрела благодаря усилиям Сеймура Крея, особенно успешным оказался компьютер Cray X-MP, который называли векторным процессором за способность работать с одномерными массивами. Реализация SPMD предполагает, что сначала данные должны быть каким-то образом распределены между процессорами, обработаны, а затем собраны. Эту совокупность операций можно назвать map-reduce, как принято в функциональном программировании, хотя точнее было бы split-aggregate, то есть разбиение и сборка, но привилось первое. Возможно несколько способов реализации SPMD: языки высокого уровня, директивы типа loop directives и библиотеки OpenMP, что удобнее на многопроцессорных конфигурациях с общей памятью. На кластерах типа Beowulf можно использовать обмен сообщениями и библиотеку MPI.
Реализация SPMD требует выделения ведущей части кода, ее называют Master или Manager, и подчиненных ей частей Worker. Мастер «раздает» задания Рабочим и потом их собирает. До появления MapReduce эта модель рассматривалась как малоперспективная из-за наличия «бутылочного горла» на тракте обмена между множеством Рабочих и одним Мастером. Создание MapReduce разрешило эту проблему и открыло возможность для обработки огромных массивов данных с использованием архитектуры SPMD.
Допустим, что следует решить простейшую задачу: обработать массив, разбив его на подмассивы. В таком случае работа Мастера сводится к тому, что он делит этот массив на части, посылает каждому из Рабочих положенный ему подмассив, а затем получает результаты и объединяет их (рис.2). В функцию Рабочего входит получение данных, обработка и возврат результатов Мастеру. Распределение нагрузок может быть статическим (static load balancing) или динамическим (dynamic load balancing). Концепция создана по мотивам комбинации map и reduce в функциональном языке программирования Липс. В нем map использует в качестве входных параметров функцию и набор значений, применяя эту функцию по отношению к каждому из значений, а reduce комбинирует полученные результаты.
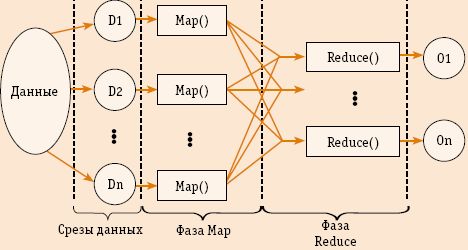
Рис. 2. Упрощенная схема потока данных в конструкции MapReduce
Созданная в Google конструкция MapReduce делает примерно то же, но по отношению к гигантским объемам данных. В этом случае map – это функция запроса от пользователя, помещенная в библиотеку MapReduce. Ее работа сводится к выбору входной пары, ее обработке и формированию результата в виде значения и некоторого промежуточного ключа, служащего указателем для reduce. Конструкция MapReduce собирает вместе все значения с одинаковыми промежуточными ключами и передает их в функцию reduce, также написанную пользователем. Эта функция воспринимает промежуточные значения, каким-то образом их собирает и воспроизводит результат, скорее всего выраженный меньшим количеством значений,
чем входное множество.
Теперь свяжем функциональную идею MapReduce со схемой SPMD. Вызовы map распределяются между множеством машин путем деления входного потока данных на М срезов (splits или shard), каждый срез обрабатывается на отдельной машине. Вызовы reduce распределены на R частей, количество которых определяется пользователем.
При вызове функции из библиотеки MapReduce выполняется примерно такая последовательность операций (рис. 3).
-
Входные файлы разбиваются на срезы размером от 16 до 64 Мбайт каждый, и на кластере запускаются копии программы. Одна из них Мастер, а остальные – Рабочие. Всего создается M задач map и R задач reduce. Поиском свободных узлов и назначением на них задач занимается Мастер.
-
В процессе исполнения Рабочие, назначенные на выполнение задачи map, считывают содержимое соответствующих срезов, осуществляют их грамматический разбор, выделяют отдельные пары «ключ и соответствующее ему значение», а потом передают эти пары в обрабатывающую их функцию map. Промежуточное значение в виде идентификатора и значения буферизуется в памяти.
-
Периодически буферизованные пары сбрасываются на локальный диск, разделенный на R областей. Расположение этих пар передается Мастеру, который отвечает за дальнейшую передачу этих адресов Рабочим, выполняющим reduce.
-
Рабочие, выполняющие задачу reduce, ждут сообщения от Мастера о местоположении промежуточных пар. По его получении они, используя процедуры удаленного вызова, считывают буферизованные данные с локальных дисков тех Рабочих, которые выполняют map. Загрузив все промежуточные данные, Рабочий сортирует их по промежуточным ключам и, если есть необходимость, группирует.
-
Рабочий обрабатывает данные по промежуточным ключам и передает их в соответствующую функцию reduce для вывода результатов.
-
Когда все задачи map и reduce завершаются, конструкция MapReduce возобновляет работу вызывающей программы и та продолжает выполнять пользовательский код.
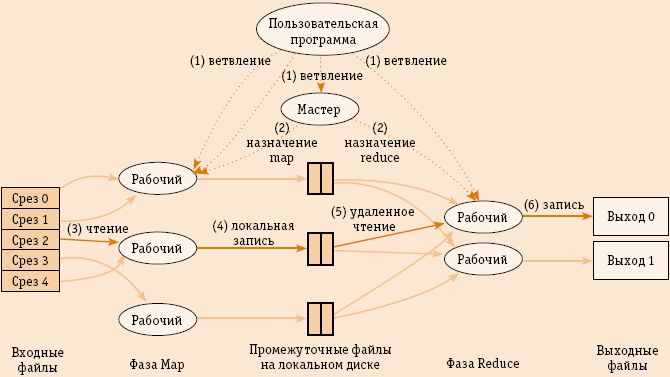
Рис. 3. Ход выполнения вызова MapReduce (цифры указывают порядок выполнения)
Одно из важнейших преимуществ этой, замысловатой на первый взгляд конструкции состоит в том, что она позволяет надежно работать на платформах с низкими показателями надежности. Для обнаружения потенциальных сбоев Мастер периодически опрашивает Рабочих, и, если какой-то из них задерживается с ответом сверх заданного норматива, Мастер считает его дефектным и передает исполнение на свободные узлы. Различие между задачами map и reduce в данном случае состоит в том, что map хранит промежуточные результаты на своем диске, и выход из строя такого узла приводит к их потере и требует повторного запуска, а reduce хранит свои данные в глобальном хранилище.
СУБД Greenplum Database
СУБД Greenplum Database 3.2 отличает возможность масштабирования до петабайтных значений с линейным ростом затрат, распараллеливание запросов, ускоряющее скорость работы на один-два порядка, и ряд других эксплуатационных преимуществ. С технологической точки зрения эту СУБД отличает использование программной структуры MapReduce, разработанной в Google, которая обеспечивает не только высокую производительность за счет применения большого числа процессоров, а в перспективе и ядер, но и высокую надежность, а также технологии компрессии, от 3 до 10 раз сокращающей объемы передаваемых и хранимых данных. Greenplum Database 3.2 имеет встроенные возможности для аналитики и статистической обработки средствами специализированного языка программирования R.
Пользовательские функции map и reduce могут быть написаны на различных скриптовых языках, например на Python и Perl: используя привычные средства, разработчик получает доступ к файлам и Web-сайтам непосредственно по месту их нахождения (where it lives), причем делается это проще и естественнее, чем при использовании технологий, связанных с реляционными СУБД. СУБД Greenplum является одновременно и коммерческой реализацией конструкции MapReduce, обеспечивающей работу с большими документами в разных форматах, и классической СУБД, ориентированной на работу с реляционными таблицами (рис. 4). Такого рода универсальность достигается за счет машины для работы с параллельными потоками данных – СУБД может не только независимо работать с каждым из двух источников, но и совмещать работу с ними двумя одновременно. В частности, средствами MapReduce можно оптимизировать доступ к большим СУБД либо обеспечить выполнение SQL-запросов к таблицам и к файлам.
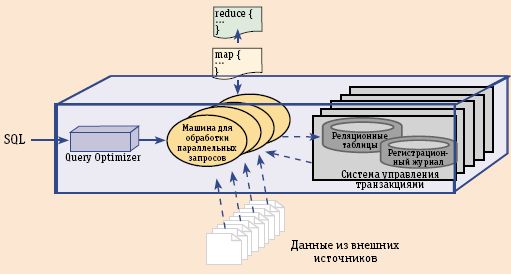
Рис. 4. Greenplum Database: два источника данных и два метода доступа
Ядро Greenplum Database – Parallel Dataflow Engine, машина для обработки параллельных потоков данных, которая может оптимизировать процессы, собирая данные из внешних источников (файлов и приложений) и работая с локальными дисками или дисками на сегментах, объединенных в общую сеть фирменным межсоединением gNet. Машина задумана так, что в перспективе может поддерживать системы, состоящие из многих тысяч процессорных ядер и при этом поддерживать SQL в характерной для нее параллельной манере.
Аппаратно-программные хранилища
Для поддержки оперативного доступа ко все большим объемам информации требуются новые архитектуры платформ хранилищ данных.
Многоядерные процессоры и грядущая параллельная революция
На протяжении длительного времени прогресс в области микропроцессоров отождествлялся с тактовой частотой, но правы оказались те, кто сделал ставку на многоядерные архитектуры.
Рис. 1. Архитектуры хранилищ данных
Рис. 2. Упрощенная схема потока данных в конструкции MapReduce
Рис. 3. Ход выполнения вызова MapReduce (цифры указывают порядок выполнения)
Рис. 4. Greenplum Database: два источника данных и два метода доступа
