 Когда-то компьютерные технологии служили исключительно для решения численных задач, о чем собственно и свидетельствует название, но постепенно превратились в универсальные технологии обработки данных. Поэтому при их оценке невольно напрашивается сравнение компьютерных технологий с технологиями, используемыми в материальном производстве, скажем, в машиностроении. Здесь за долгую историю перехода от ручного труда к автоматизированному сложилось два альтернативных способа современной организации производства — станки с числовым программным управлением (ЧПУ) и поточные линии. Первый предполагает, что заготовка находится на постоянном месте, а инструменты меняются и выполняют предписанный им цикл по заданной программе. Такой метод хорошо подходит для обработки сложных, но не слишком тиражируемых изделий. Во втором случае отдельные операции выполняются в своих фиксированных позициях на технологической цепочке или на карусели, а заготовка проходит по ним, это напоминает прокатный стан.
Когда-то компьютерные технологии служили исключительно для решения численных задач, о чем собственно и свидетельствует название, но постепенно превратились в универсальные технологии обработки данных. Поэтому при их оценке невольно напрашивается сравнение компьютерных технологий с технологиями, используемыми в материальном производстве, скажем, в машиностроении. Здесь за долгую историю перехода от ручного труда к автоматизированному сложилось два альтернативных способа современной организации производства — станки с числовым программным управлением (ЧПУ) и поточные линии. Первый предполагает, что заготовка находится на постоянном месте, а инструменты меняются и выполняют предписанный им цикл по заданной программе. Такой метод хорошо подходит для обработки сложных, но не слишком тиражируемых изделий. Во втором случае отдельные операции выполняются в своих фиксированных позициях на технологической цепочке или на карусели, а заготовка проходит по ним, это напоминает прокатный стан.
Провести прямую параллель между обработкой материальных предметов и обработкой данных, разумеется, невозможно — слишком разная у них природа. Но что-то общее все же есть. По мере роста объемов обрабатываемых данных становится очевидным: традиционным представлениям о том, как строить работу с данными, требуются альтернативы. В каких-то случаях это будут аналоги конвейерного производства, а в каких-то — аналоги ЧПУ.
«Метод ЧПУ» применим прежде всего в науке. На эту тему рассуждали два культовых персонажа современности, астроном и футуролог Алекс Шалаи и компьютерный гуру Джим Грей, в своей статье «Наука в экспоненциальном мире», опубликованной в журнале Nature в марте 2006 года. В ней они предложили рассматривать эволюцию соотношения научных методов с объемами экспериментальных данных. Они считают, что по объему используемых данных историю науки можно разделить на четыре периода.
-
Тысячу лет назад данных было совсем мало, наука была эмпирической. В античные времена наука ограничивалась описанием наблюдаемых феноменов и логическими выводами, сделанными на основе наблюдений.
-
В последние несколько сотен лет данных стало больше, появилась возможность для создания теорий, используя в качестве доказательств те или иные аналитические модели.
-
За последние несколько десятилетий наука стала вычислительной; компьютеры позволили использовать методы численного моделирования.
-
Сегодня, когда открылась возможность обрабатывать огромные объемы экспериментальных данных, складываются новые научные методы, основанные на их анализе (eScience), где станут доминировать синтезирующие теории, а статистические методы будут применяться к колоссальным объемам данных.
Согласно прогнозу Шалаи и Грея, лет через десять-пятнадцать наука вступит в свой четвертый этап развития. Во врезке к статье, озаглавленной «Компьютинг 2020», можно найти следующий пассаж, подтверждающий справедливость аналогии с ЧПУ: «В будущем работа с большими объемами данных будет предполагать пересылку вычислений (читай, инструментов) к данным, а не загрузку данных в компьютер для последующей обработки». Другими словами, не данные для вычислений, а вычисления для данных. Большие объемы данных статичнее, чем кажется; для работы с ними требуются альтернативные подходы. В данном случае перед нами прямая аналогия ЧПУ: данные стоят на месте, а инструменты направляются к ним по мере необходимости.
Но может быть и иной подход, назовем его «поточным». За последние годы мы узнали немало разновидностей моделей вычислений; одни из них ближе к практическому внедрению, другие следует рассматривать как гипотетические. Пока поточные вычисления (Stream Computing) относятся ко второй категории. Создание соответствующих технологий потребует заметной перестройки мышления. Все мы вышли из фон-неймановской модели. Одно из следствий всевластия этой модели заключается в том, что весь современный компьютинг ориентирован исключительно на вычисления?— потому-то он так и называется.
Вычисления и данные представляют собой две взаимодополняющие сущности, но до самого последнего времени вся компьютерная наука была сосредоточена на одной из них — на вычислениях. Однако на самом деле, как мы хорошо понимаем, собственно счетной работой занято предельное меньшинство компьютеров, остальные же так или иначе перерабатывают данные. И до тех пор, пока данные были не слишком сложны, а их объемы — относительно невелики, это обстоятельство не имело значения. Однако сейчас наблюдается очевидный разворот к компьютерным системам, ориентированным на работу с данными. Смена ориентации началась прежде всего там, где приходится иметь дело с большими объемами экспериментальных данных, в таких областях, как физика, астрономия, геология, биология или медицина. В последние же годы и в бизнесе по мере роста объемов данных, поступающих из автоматических систем (скажем, от устройств радиочастотной идентификации) происходит то же самое. Вместе с ростом объемов и сложности приходит осознание того, что не вычисления, а данные являются главной ценностью. Примером тому служит Web 2.0; придумавший это название Тим О’Рейли выразил свою мысль афористично: «Следующим Intel Inside станут данные».
В соответствии с общепринятой парадигмой сначала мэйнфреймы, а позже и серверы рассматривались и рассматриваются поныне как устройства, адаптированные для переработки данных. На первых этапах все процедуры работы с данными проходили через центральный процессор и оперативную память; сегодняшним специалистам это покажется наивным, но в системах команд машин второго поколения были специальные инструкции для работы с печатью, перфовводом и т.п. При таком подходе время процессора использовалось чрезвычайно нерационально, поэтому по мере развития архитектур и увеличения важности роли операционных систем появились специализированные контроллеры, исключающие центральные процессоры из процедур работы с памятью и обеспечивающие непосредственный обмен между ней и устройствами, используя концепцию «прямого доступа к памяти» (Direct Memory Access, DMA) и процессоры, или каналы, ввода/вывода. Во всех операционных системах существует подсистема управления вводом/выводом.
Конвейер для данных
Переориентация на «конвейерные вычисления» (как и все, что не привязано непосредственно к конкретным технологиям) требует весьма длительного времени. С тех пор, как возникли первые соображения на эту тему, прошло 20 лет, но готовые решения еще не появились. Все началось с того, что в 1988 году четверку «отцов Internet» в составе Винта Серфа, Роберта Кана, Леонарда Клейнрока и Роберта Тейлора выслушали в Конгрессе и создали специальную комиссию, которую возглавил Эл Гор, ставший впоследствии вице-президентом США. Подготовленный комиссией доклад «К созданию национальной исследовательской сети» (Toward a National Research Network) послужил основой для принятого в 1991 году акта High Performance Computing and Communication Act*. Своим нынешним уровнем развития Глобальная сеть обязана, в том числе, этому акту, но было и еще несколько побочных результатов.
Менее известно следующее обстоятельство: помимо нового поколения коммуникаций, деятельность комиссии стимулировала решения задач, связанных с работой с большими объемами данных. В частности, с использованием суперкомпьютеров СМ-2 компании Thinking Machines и Cray Y-MP была создана система для дистанционной обработки трехмерных медицинских изображений и система MAGIC Gigabit для больших сетей банкоматов.
На основе этих разработок была создана модель Data-Intensive Computing Model. Ее основным автором был Уильям Джонсон из отделения информационных и компьютерных наук Национальной лаборатории Лоуренса в Беркли. Устройство этой модели заставляет еще раз вспомнить лозунг компании Sun Microsystems «Сеть — это компьютер», — совсем не в том смысле, который она приобретает с ростом популярности идей Cloud Computing; не как обезличенный пул компьютерных ресурсов для решения множества различных задач, а как поточную линию из множества компьютеров, ориентированную на работу с потоками данных. На рис. 1 показана «архитектура» такого конвейера.
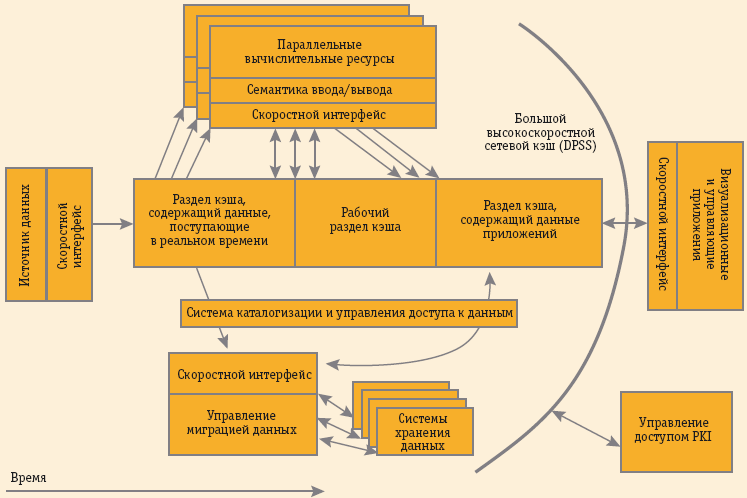
Рис. 1. Архитектура конвейерных вычислений
Ядром конвейера служит высокоскоростной распределенный кэш, являющийся одновременно и источником, и местом сбора данных. Он обеспечивает стандартизованные интерфейсы к данным, согласование поток данных, управление системами хранения и другие функции. В представленной модели каждое приложение использует стандартный интерфейс для доступа к данным. Источники данных размещают в нем данные, а потребители берут данные из кэша. Для каталогизации данных используются метаданные, а система миграции предназначена для перемещения данных между кэшем и системами хранения. Кэш выполняет функцию своеобразного окна для доступа к данным, расположенных на системах хранения.
Описанная модель является абстракцией различных конкретных потенциальных реализаций, которые могут появиться в будущем. Несмотря на то, что модель была предложена десять лет назад, она все еще остается гипотетической. Ее можно рассматривать как некоторую «скелетную» схему устройста высокопроизводительных компьютерных систем, предназначенных для обработки больших объемов данных (Data-Intensive Super Сomputing, DISC), заметно отличающихся от современных компьютеров. Мы привыкли к тому, что нынешние суперкомпьютеры способны предоставлять возможность для выполнения огромного числа арифметических операций в секунду, поэтому к ним применяется сообразная метрика — «флопсы». Но она полезна только в том случае, если требуется выполнить большие вычисления над хорошо структурированными данными. Между тем, мы прекрасно представляем себе, что в современных условиях большая часть данных не структурирована, и это накладывает ограничения на область приложения суперкомпьютеров. Кроме того, трудность распараллеливания приводит к тому, что их приходится программировать на низком уровне.
Можно сформулировать несколько основных принципов, отличающих системы категории DISC от существующих суперкомпьютеров.
Отношение к данным. Данные должны стать «органичными» компьютеру будущего (intrinsic data), а не как сейчас — внешними, или даже «посторонними» (extrinsic data). Это значит, что подготовкой данных должен заниматься не только пользователь, но и сама система. Она должна уметь собирать их, поддерживать в готовности, выделять новую информацию, обрабатывать в фоновом режиме.
Новые языки программирования и новые компиляторы. Средствами новых языков программирования должны описываться сложные и нерегулярные структуры данных и операции, которые над ними следует выполнить, а не то, как эти операции выполняются на определенной машине. Создание наиболее эффективных отражений этих описаний на реальных машинах входит в функцию компиляторов и систем, поддерживающих исполнение (runtime system).
Интерактивность и масштабируемость. Создание систем DISC, скорее всего, невозможно без включения человека в цикл управления потоком данных. Эта работа может быть похожа на альтернативу современному проектированию: пользователь сможет перераспределять вычислительные ресурсы и ресурсы хранения в соответствии с изменениями потоков данных.
Для организации потоков данных потребуется выполнять действия, которые назвали «размещением данных» (data placement), в том числе резервирование и освобождение пространства на устройствах хранения, управление на всех этапах прохождения данных от входа к выходу. В традиционных компьютерных системах этот вид деятельности непосредственно связан с вычислениями, операции ввода/вывода диспетчеризуются наравне с вычислениями. В то же время системы DISC отличаются слабой связанностью управления потоков данных с вычислениями. Можно предположить, что набор операций для работы с данными будет включать следующие примитивы:
-
transfer — передача файла из одного устройства в другое;
-
allocate — резервирование пространства хранения;
-
release — освобождение ресурсов;
-
remove — удаление файла;
-
locate — присвоение логического имени файлам и заданиям;
-
register/unregister — занесение и удаление в каталог метаданных.
ЧПУ для данных
Несмотря на свою долгую двадцатилетнюю историю, потоковые методы обработки данных так и не стали массовыми, а к методам, которые можно назвать аналогами ЧПУ, сейчас приковано очень серьезное внимание. Одно из свидетельств этому?— успех «каркаса программных систем» (Software Framework) MapReduce, предложенного Google. Известно, что MapReduce служит для поддержки параллельных вычислений, выполняемых кластерными системами над петабайтными массивами данных. Каркас состоит из функций двух типов, Map и Reduce, известных в функциональном программировании. Основная идея MapReduce достаточно проста (рис. 2).

На кластере работает не одна, как это бывает обычно, программа, а множество экземпляров Map и Reduce, плюс к тому есть объединяющий их каркас. Программа Map читает набор данных из входного файла, выполняет нужную фильтрацию и преобразования, а затем выдает набор выходных записей, состоящих из данных и приписанных им ключей. Каждая из программ Map работает независимо от других на своем узле в кластере. Ее задача состоит в умении работать с большими объемами, извлекать из этих данных то, что нам нужно обработать, «перетасовать» и отсортировать. У Reduce задача обратная — объединить, просуммировать, отфильтровать или изменить и записать результаты.
Надо заметить, что MapReduce не имеет ничего общего с базами данных, поэтому любые попытки сравнивать подход MapReduce с реляционными СУБД ошибочны. При работе с большими объемами данных MapReduce обходится дешевле и имеет большую масштабируемость, что доказано практикой работы Google. Кроме того, MapReduce обеспечивает автоматическое распараллеливание, балансировку нагрузки, оптимизацию загрузки сети и дисков. И еще одно важное преимущество, MapReduce имеет естественную отказоустойчивость, он позволяет построить надежную систему из ненадежных компонентов, что объясняет возможность работы Google на сотнях тысяч примитивных серверов.
Идеи MapReduce вдохновили представителей сообщества Open Source к созданию аналогов. Один из них — каркас Apache Hadoop, также позволяющий работать с петабайтными объемами данных на кластерах. Сегодня Hadoop активно используется в машинах Web-поиска и в системах контекстной рекламы. Hadoop изучается в университетских курсах по программированию распределенных систем.
Еще одно наследие MapReduce — свободно распространяемая, ориентированная на работу с документами СУБД Apache CouchDB. Ее основное отличие — в возможностях масштабирования. CouchDB хорошо адаптирована к многоядерным и многосерверным средам, что обеспечено не только использованием функций Map и Reduce, но и тем, что она написана на Erlang, функциональном языке программирования, позволяющем писать отказоустойчивые приложения для разного рода распределенных систем.
Адаптированная в приложении к Amazon Machine Image, CouchDB называется ElasticDB. На том же языке Erlang написана и аналогичная CouchDB система управления базами данных Amazon SimpleDB, которая используется в Amazon Elastic Compute Cloud (EC2) и Amazon S3. Для работы с распределенными системами хранения данных предназначен инструментарий Hypertable, имеющий преимущество при обработке больших объемов в режиме реального времени на кластерных конфигурациях. Технология Hypertable создана по мотивам технологии BigTable, разработанной Google с использованием файловой системы Google File System. Также по мотивам BigTable создана «колоночно-ориентированная» СУБД Hbase.
