
В условиях, когда вся совокупность сведений о компании представлена в данных, их хранилища становятся едва ли не главным ее стратегическим активом: для поддержки и анализа результатов деятельности необходимо, чтобы оперативно было доступно все больше информации. Системы, построенные на основе универсальных технологий, оказываются перед этим вызовом, слишком жесткими и дорогостоящими, поэтому появление специализированных аппаратно-программных решений, которые предлагают как начинающие компании, так и лидеры рынка, указывает на зарождение новой архитектуры платформ хранилищ данных.
По данным Winter Corporation, в 1995 году размер самой крупной базы данных составил 1 Тбайт. За последующие десять лет этот показатель вырос на два порядка, и если прогнозы IDC и Gartner относительно ежегодного 10-процентного увеличения рынка бизнес-аналитики оправдаются, то мы станем свидетелями массового развертывания сверхбольших баз и хранилищ данных объемом в тысячи терабайтов. Компаниям необходимо быстро наращивать и надежно хранить огромные объемы данных, поскольку ежедневно и ежечасно регистрируется и обрабатывается все больше детальных данных, а необходимость выполнения нормативных требований увеличивает сроки хранения контрольных копий. Параллельно возрастает сложность запросов, а механизмы управления данными должны выдерживать смешанные и подчас противоречивые аналитические, операционные и транзакционные рабочие нагрузки (точечные выборки, полные просмотры таблиц, массовую загрузку, параллельную обработку транзакций и решение аналитических задач). По оценкам Gartner, к 2010 году более 20% аналитических задач должны будут работать с наборами данных, «возраст» которых не превышает 15 минут, поэтому одной из важнейших характеристик системы хранилища данных становится время, за которое может быть представлен результат.
Лавинообразное повышение требований к системам хранилищ данных происходит на фоне жесткой необходимости сбалансировать затраты на ИТ и реальную отдачу, которую они приносят бизнесу. Поэтому заказчики ждут от поставщиков не только абстрактного увеличения производительности и снижения пресловутой совокупной стоимости владения, но и вполне осязаемой способности предлагаемых конфигураций справляться с растущей нагрузкой, возможности масштабировать их по мере разрастания хранилищ, упрощения развертывания и администрирования систем и, конечно же, удешевления хранения каждого нового терабайта данных.
В течение многих лет на рынке «больших» решений почт не было конкуренции, и несколько поставщиков весьма дорогостоящих и прибыльных традиционных решений и консалтинговых услуг чувствовали себя достаточно уверенно*. Но консервативность, медленное внедрение новшеств и слабая конкуренция подготовили почву для технологического прорыва. Таким прорывным решением стала специализированная приставка хранилищ данных (data warehouse appliance) — интегрированный, предварительно сконфигурированный и подготовленный для развертывания комплекс, объединяющий серверы с установленной операционной системой, СУБД и средствами управления, сетевые межсоединения и дисковую память. Рынок специализированных приставок (по оценкам IDC, он составлял в 2006 году 50-75 млн. долл. и за пять лет может вырасти до полумиллиарда) созрел; сегодня многие поставщики программного обеспечения и оборудования для хранилищ данных предлагают предварительно сконфигурированные и оптимизированные решения.
Разработчики устройств для хранилищ данных стремятся развить и реализовать на стандартной компонентной базе архитектурные подходы, обеспечившие уникальные характеристики платформы Teradata — первой специализированной приставки хранилищ данных: распараллеливание обработки по схеме массивного мультипроцессирования и применение высокоскоростного сетевого межсоединения. Появление устройства Netezza Performance Server, разработанного компанией Netezza в 2003 году и последовавший выпуск устройств DATAllegro, Calpont, а также совместного решения Sun Microsystems и Greenplum (в них применялись открытые версии СУБД и OC Linux) обозначило новый сегмент рынка и подготовило почву для его формирования. Успех нескольких небольших компаний убедительно продемонстрировал, что существует спрос на предварительно сконфигурированные решения, и это было незамедлительно отмечено рядом крупнейших ИТ-поставщиков (HP, IBM, Microsoft, Oracle и Sun), предложивших решения этого класса для развертывания хранилищ данных.
Что же представляют собой готовые аппаратно-программные платформы хранилищ данных? Какова их архитектура и функциональные возможности?
Составляющие решения
Архитектура первых специализированных приставок была ориентирована на эффективное решение важных, но частных задач, и поэтому в них широко применялись нестандартные технические решения, например программируемые дисковые контроллеры, реализующие функции обработки данных Netezza, бездисковая машина Calpont [1]. Новые устройства должны поддерживать более широкий круг решений для бизнес-аналитики и быть при этом более надежными. Их поставщики теперь ориентируются преимущественно на применение массово выпускаемых стандартных аппаратно-программных компонентов и образуют альянсы, направленные на создание оптимальных конфигураций, которые можно предложить не только крупным заказчикам, но и среднему и малому бизнесу.
Традиционно для создания хранилищ данных в качестве основного механизма управления данными использовались мощные СУБД (IBM DB2, Oracle, Microsoft SQL Server и т.п.). Их дополняли специальными расширениями для решения аналитических задач, в том числе для агрегирования отношений, загрузки данных и распараллеливания обработки, адаптации к аппаратным платформам, разнообразным структурам таблиц и индексов, управления вводом/выводом на физическом уровне и т.д. Помимо самой СУБД пользователь должен был выбрать, приобрести, а после конфигурировать и поддерживать все аппаратные средства, дисковую память и операционные системы.
Для масштабирования производительности системы применялись мощные серверы SMP-архитектуры, кластеры с разделением дисков (например, Oracle Real Application Clusters) или системы с массовым параллелизмом.
Симметричная многопроцессорность (Symmetrical Multiprocessing, SMP) чаще всего применяется для транзакционных баз данных и небольших хранилищ и витрин данных; однако такие решения дороги, монолитны, а потому плохо масштабируются. Кластерные решения отличаются близкой к линейной масштабируемостью, но требуют тонкой настройки сегментирования баз данных и синхронизации серверов. Поэтому крупномасштабные хранилища данных строятся преимущественно на системах с массовым параллелизмом (Massive Parallel Processing, MPP), которые обеспечивают сегментирование данных и распараллеливание обработки запросов. Если удастся сократить высокие эксплуатационные расходы, связанные с конфигурированием и необходимостью постоянной настройки системы и поддержки со стороны администратора баз данных, то такое решение можно рассматривать как наиболее общее и перспективное. Именно поэтому в иерархической ассиметричной массивно-параллельной архитектуре Netezza на верхнем уровне имеется мощный SMP-сервер, а на втором — работающие параллельно периферийные узлы. Компания DATAllegro применяет MPP-схему распараллеливания.
Программное обеспечение устройств хранилищ данных базируется на открытых (например, PostgresSQL в решениях Netezza и Sun/GreenPlum, оптимизированная версия Ingres R3 в системе DATAllegro) или коммерческих версиях хорошо зарекомендовавших себя СУБД (DB2, Oracle, SQL Server). Целостность данных и отказоустойчивость системы обеспечивается средствами операционной и файловой систем (например, Sun Solaris 10) и развитыми механизмами управления данными (DB2, Oracle, SQL Server), располагающими средствами дублирования, резервного копирования и восстановления данных, а также за счет введения в конструкцию избыточных процессорных узлов, сетевого оборудования и блоков питания.
Каковы же общие требования к специализированной приставке хранилищ данных? Прежде всего, ее модульная конструкция должна быть масштабируемой: интегрированные аппаратные средства, программное обеспечение и внешняя память должны быть оформлены в виде единых блоков, которые при необходимости можно будет просто включить в имеющуюся конфигурацию. Архитектура решения должна обеспечивать эффективное распараллеливание обработки и охватывать процессоры, память, диски, контроллеры и специализированное программное обеспечение. Сетевое соединение, объединяющее процессорные узлы и дисковую память, должно обладать высокой пропускной способностью. Операции дискового ввода/вывода должны быть оптимизированы с применением алгоритмов кэширования, кластеризации и распределения данных на носителях, различных механизмов индексации, балансировки произвольного и последовательного доступа и потоковой обработки данных. Благодаря этому по сравнению с традиционными технологиями должна обеспечиваться более высокая производительность и низкая стоимость решения.
Архитектурные подходы
По типу конструктивного решения и используемых компонентов можно выделить несколько классов решений [2].
Прежде всего, это классические устройства, воспринимаемые как черные ящики. Их высокие характеристики обеспечиваются применением заказного нестандартного оборудования, например специализированных интегральных схем (ASIC) или программируемых логических матриц (FPGA). Подбные устройства ориентированы на решение таких специфических ресурсоемких задач, как обработка запросов, требующая полного просмотра таблиц, и быстрое развертывание специализированных хранилищ и витрин данных, поэтому пользователь не может изменять их конструкцию.
Архитектура «черных ящиков» была характерна для устройств первого поколения, но сегодня разработчики делают выбор в пользу стандартных компонентов. Несмотря на то что решения Netezza — это все еще в определенной мере «черные ящики», компания Calpont уже кардинально пересматривает архитектуру своей бездисковой системы, а компания DATAllegro от изделий перешла к модели, используемой подавляющим большинством крупных поставщиков, — разработке тщательно конфигурированных аппаратно-программных комплексов стандартных технических средств и программного обеспечения.
Сборки из готовых стандартных компонентов предлагаются в виде законченного изделия или эталонной конфигурации (которая может быть установлена и использована и по которой комплектуется и развертывается решение у заказчика). В качестве компонентов применяются серийно производимые серверы, запоминающие устройства, сетевые контроллеры и соединения, модули шифрования, компрессии данных и версии программного обеспечения одного или нескольких поставщиков, при этом балансировка производительности и надежности сборки предварительно выполняется поставщиком решения.
Квазиустройства представляют собой совокупность готовых отконфигурированных и протестированных программных компонентов, которые могут эффективно работать на рекомендованных платформах. Основными особенностями таких решений является простота развертывания и функциональные возможности программного обеспечения.
От родоначальников платформ хранилищ данных
Усилия компании Teradata сконцентрированы на поддержке больших баз и хранилищ данных. Архитектура системы изначально ориентирована на потребности различных категорий пользователей, которым нужны средства подготовки отчетов и аналитической обработки.
Большинство реляционных СУБД создавались для систем оперативной обработки транзакций, где необходим быстрый доступ и обновление одиночных записей. Однако универсальные СУБД не всегда справляются с задачами, присущими технологиям хранилищ данных, — полным просмотром таблицы, объединением таблицы, сортировкой и агрегированием данных. В Teradata Database подобные ограничения сняты: благодаря автоматической сегментации данных, балансировке рабочих нагрузок и распараллеливанию процессов обработки эффективно обрабатываются сложные структуры данных и упрощается управление средой хранилища данных.

Параллельная архитектура Teradata (рис. 1) обеспечивает дробление сложных запросов на более мелкие задачи, возлагаемые на множество виртуальных процессоров, так называемых «процессоров модулей доступа» (Access Module Processor, AMP), каждый из которых ответственн за определенный сегмент базы данных. Вторая группа виртуальных процессоров (Parser Engine, PE) обеспечивает синтаксический анализ, декомпозицию запросов и управление их обработкой.
Аппаратные компоненты взаимодействуют через высокоскоростное сетевое соединение BYNET и образуют гибкую MPP-систему с централизованным управлением. Такая схема обеспечивает линейную масштабируемость решения от двух до тысяч физических и десятков тысяч виртуальных процессоров и его эффективность для систем как начального, так и общекорпоративного уровня.
Сетевое соединение BYNET обладает свойствами избыточности, отказоустойчивости и интеллектуальными средствами коммутации, что в SMP-системах позволяет СУБД координировать и синхронизировать работу до 1024 узлов без увеличения сетевого трафика и деградации производительности по мере роста хранилища. Тесная же интеграция решения с серверами NCR и корпоративными устройствами хранения NCR Enterprise Storage обеспечивает при необходимости плавное наращивание мощностей системы.
Активные средства управления системой TASM (Teradata Active System Management) призваны упростить управление большими рабочими нагрузками. Цель разработчика состоит в том, чтобы предоставить пользователям возможность задавать приоритеты, правила и критерии оценки предоставляемых сервисов — все остальное должна обеспечивать система: балансировку точечных и требующих полного просмотра таблиц запросов, бесконфликтное хранение оперативных данных и аналитическую обработку для тактического и стратегического планирования.
Классические устройства и «коммодитизация»
Компания Netezza первой предложила рынку специализированную приставку хранилищ данных. В ее решении, как и в устройствах DATAllegro, первоначально предусматривалось нетрадиционное использование аппаратных средств и собственная программная реализация распараллеливания управления данными «поверх» стандартной СУБД с открытым кодом [1]. Между тем в последней версии продукты DATAllegro V3 уже представляют собой сборки из готовых стандартных компонентов в специально подобранных конфигурациях (рис. 2).
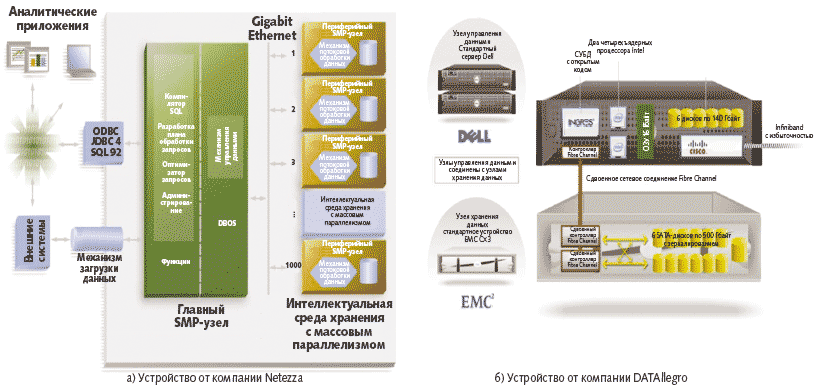
Эволюция архитектуры специализированных приставок DATAllegro подтверждает общую тенденцию «коммодитизации» ИТ-решений, проявляющуюся в стремлении производителей использовать массовые и взаимозаменяемые компоненты с сохранением отличительных свойств конечных изделий.
В данном случае основными элементами конструкции являются серверы Dell, сетевые устройства хранения данных среднего уровня EMC Clariion и оборудование для организации межсоединений Infiniband от компании Cisco (рис. 2). Используется особая схема подключения дисков: в каждом модуле EMC они разбиты на два массива RAID 1 по шесть дисков, каждый из которых назначается собственному серверу. Система работает под управлением 64-разрядной операционной системы CentOS Linux.
Ядро механизма управления данными образует СУБД Ingres — современная система управления базами данных, функциональные возможности которой и в особенности средства сегментирования данных, устраняющие необходимость полного просмотра таблиц соответствуют требованиям среды хранения оперативных данных. Для поддержки MPP-схемы обработки и сериализации доступа к данным, позволяющим полностью задействовать мощности стандартных компонентов, были введены соответствующие расширения функциональности СУБД. На сегодняшний день это, пожалуй, главный «привнесенный» разработчиками DATAllegro компонент решения, высокая производительность которого достигается благодаря выполняемой изготовителем точной настройке конфигурации.
Интерфейсы решения DATAllegro согласованы с недавно выпущенным инструментарием интеграции данных IBM Information Server, что позволяет создавать масштабируемые, высокоэффективные системы очистки, преобразования и предоставления данных приложениям и пользователям по первому требованию.
Решения от лидеров
Успех предложенных независимыми поставщиками специализированных приставок повлиял на политику крупных компаний. Так, IBM предлагает сбалансированные решения различного масштаба и производительности для создания хранилищ и витрин данных предприятиями малого и среднего бизнеса, филиалами компаний и крупными корпорациями на базе новой версии СУБД DB2?9, серверов и систем хранения данных IBM (см. статью Натальи Дубовой «Динамическое хранилище данных» в этом выпуске журнала «Открытые системы»).
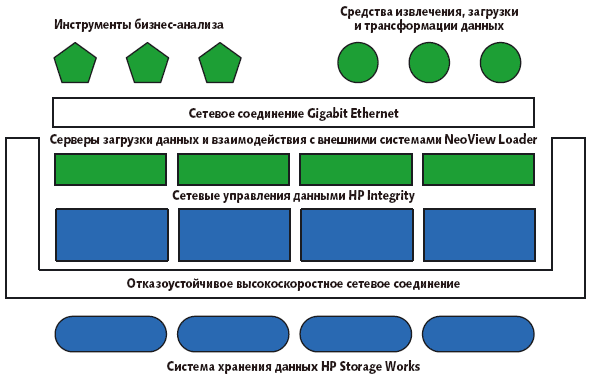
В области технологий управления данными главным продуктом корпорации Microsoft стал SQL Server 2005, который поддерживает базы данных большого объема, сегментирование данных таблиц и индексов, 64-разрядные средства кэширования данных и оптимизации ввода/вывода, а также новые инструменты извлечения, преобразования, интеграции и загрузки данных. В качестве системного партнера для специализированных решений для хранилищ данных была выбрана компания HP. Предлагаются эталонные конфигурации на базе устройств хранения HP StorageWorks и серверов HP Proliant (объем хранения — 0,5-1,5 Тбайт) или HP Integrity (0,5-10 Тбайт). Для управления ими используются HP Insight Manager или HP Integrity Essentials. Задачи оперативного анализа на основе реляционных баз данных, ETL (извлечение, преобразование и загрузка данных) и бизнес-аналитики решаются посредством программного обеспечения Windows Server 2003, SQL Server 2005, SQL Server Integration, Reporting, Analysis Services, а также инструментов для оценки производительности SQL Server 2005 (рис. 3).
Компании Oracle, Dell, EMC, HP, IBM, PANTA и Sun Microsystems развивают инициативу Information Appliance Initiative, направленную на разработку оптимизированных решений для хранилищ данных, в которых используется СУБД Oracle Database 10g и оборудование ведущих изготовителей. Предлагаются два вида решений: Oracle Foundations (сбалансированные эталонные конфигурации программного обеспечения, аппаратных средств, дисковой памяти, устройств ввода/вывода и сетевого оборудования), а также Oracle Information Appliances (готовые комплексы, построенные на основе подобных конфигураций). Такие наборы решений имеются для разных операционных систем и СУБД, устанавливаемых на различных линейках серверов и систем хранения от компаний–участников инициативы.
Sun и Greenplum наряду с совместными решениями с Oracle предлагает специализированное устройство MPP-архитектуры на базе ОС Solaris 10, СУБД PostgreSQL от компании Greenplum, высокоскоростного сетевого соединения и сервера данных Sun Fire X4500.
Новый облик корпоративной платформы хранения
В основу кластерной платформы хранилищ данных HP NeoView положена MPP-архитектура. Механизм управления данными и обработки запросов реализован на серверах HP Itanium Integrity, на которых установлено ядро операционной системы Guardian и реляционная СУБД, обеспечивающие формирование отказоустойчивой среды долговременного хранения данных на базе модулей HP StorageWorks Fibre Channel и поддержку единого общекорпоративного представления данных. При обмене данными в качестве буферных накопителей служат дисковые устройства HP StorageWorks. Загрузкой данных и взаимодействием с внешними системами по сети Gigabit Ethernet управляют выделенные узлы NeoView Loader на серверах HP Proliant под управлением ОС Linux. Узлы соединяются с помощью отказоустойчивого высокоскоростного сетевого соединения (рис. 4).
Платформа будет поставляться в виде специализированных устройств в нескольких конфигурациях, насчитывающих 16-128 узлов с двухпроцессорными серверами-лезвиями. Каждому процессору может соответствовать один или два логических диска, имеющие основную и резервную области, и в каждой стойке могут быть организованы дисковые массивы. В полной комплектации эта «максималистская» платформа занимает до 24 серверных стоек.
Основу программного обеспечения NeoView составляет переработанная версия СУБД Tandem NonStop SQL, имеющая длинную историю, восходящую к ранним версиям Ingres; эта система получила широкое признание как отказоустойчивая параллельная СУБД для крупномасштабных проектов, и будет небезынтересно узнать, как она проявит себя в аналитических системах. В свое время велись разработки варианта NonStop SQL для хранилищ данных на платформе Windows NT. Любопытно, что беглый взгляд на спецификации SQL для NeoView обнаруживает наличие специфических для аналитических задач конструкций (например, RANK и RUNNINGSUM).
Как система MPP-архитектуры, NeoView обеспечивает автоматическое распределение таблиц и данных по узлам. Управление индексами и материализованными представлениями, как утверждают в HP, возложено на систему, хотя обе конструкции поддерживаются средствами SQL. Собственно аналитическая обработка в платформе не предусмотрена и должна выполняться при помощи продуктов третьих фирм (например, Business Objects, Informatica, SAS и др.) через стандартные интерфейсы взаимодействия.
Платформа NeoView играет центральную роль в программе реорганизации собственных хранилищ и витрин данных HP; уже к 2008 году более 762 специализированных баз данных должны быть интегрированы в единое распределенное корпоративное хранилище данных. Потенциальных потребителей новой платформы HP видит среди крупных заказчиков, которым благодаря применению стандартных компонентов, а также собственного программного обеспечения и ОС Linux могут быть предложены привлекательные цены в интервале между стоимостью решений Teradata и специализированных приставок Netezza, DATAllegro, Sun/GreenPlum и Vertica.
Экзотика
Помимо решений компаний-первопроходцев и последовавших за ними лидеров, в сегменте специализированных приставок хранилищ данных можно обнаружить и ряд «экзотических» предложений нескольких небольших компаний. Так, основанная в 2005 году известным исследователем и пионером технологий баз данных Майклом Стоунбрейкером, компания Vertica разработала СУБД для grid-архитектур, в которой данные на физическом уровне организованы не построчно, а по столбцам реляционных таблиц. Предполагается, что система будет реализована как специализированная приставка на стандартных аппаратных платформах под управлением ОС Linux. Даже для сверхбольших хранилищ и витрин данных решение Vertica обеспечивает исключительно высокую производительность, в особенности при обработке нерегламентированных SQL-запросов при решении задач анализа маршрутов доступа к Internet, выявления случаев мошенничества и исследования детальных данных о клиентах и транзакциях в телекоммуникационных, финансовых и торговых системах и других задач бизнес-анализа.
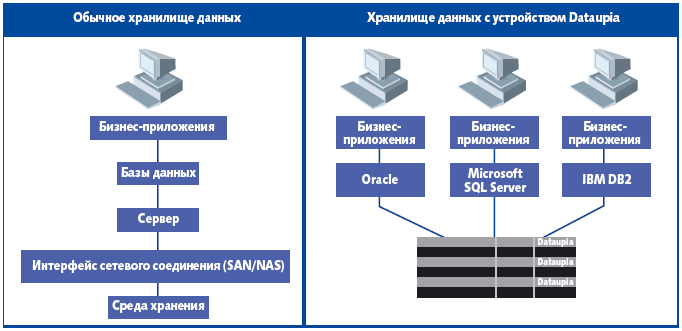
В аппаратно-программном ускорителе доступа к данным Satori Server 12000 от компании Dataupia применяются лезвия на двухъядерных процессорах AMD Opteron, каждый из которых хранит до 2 Тбайт данных; при увеличении нагрузки можно установить дополнительные модули. В качестве операционной системы используется Linux. Взаимодействие устройства с целевой системой осуществляется через интерфейсы механизма исполнения реляционной СУБД (Oracle, DB2 или Microsoft SQL Server), при этом устройство берет на себя выполнение низкоуровневых операций управления данными (синтаксический анализ, объединение отношений и др.) и памятью (рис. 4). Имеется утилита извлечения и копирования данных с существующих носителей, работающее в фоновом режиме средство построения индексов, а также средства обеспечения отказоустойчивости, резервного копирования и восстановления данных.
Аналитическая платформа Kognitio WX2, являющаяся, по сути, специализированным квази-устройством, получила признание в телекоммуникационных системах для анализа данных об отношениях с клиентами, подготовки маркетинговых кампаний, сегментации клиентской базы и решения других задач.
Отличительная особенность реализации устройства Dataupia, ориентированного на ускорение доступа к большим объемам исторических данных, — отсутствие необходимости какой-либо модификации приложений, они продолжают пользоваться соответствующими интерфейсами реляционной СУБД.
Разнообразные применения
Новые специализированные приставки обеспечивают ускоренное по сравнению с традиционными решениями развертывание и внедрение хранилищ и витрин данных, а приобретение и эксплуатация предварительно сконфигурированных и оттестированных комплексов обходится дешевле. При этом в ряде случаев возрастает скорость обработки запросов и гарантируется отказоустойчивость системы. Применение подобных аппаратно-программных комплексов может облегчить решение многих задач, в том числе консолидации разрозненных витрин данных, разгрузки основного хранилища для решения важных аналитических задач, создания изолированной среды для проведения аналитических исследований и обработки нерегламентированных запросов, поэтапной реализации корпоративных хранилищ, хранения исторических данных и быстрого развертывания локальных хранилищ и витрин данных для подразделений и филиалов организации.
Эволюция специализированных приставок хранилищ данных подтверждает, что, когда потребности бизнеса превышают возможности информационных технологий, обязательно находятся компании-энтузиасты, одни из которых разрабатывают, а другие смело внедряют нестандартные аппаратно-программные комплексы. По мнению Курта Монаша, руководителя консалтинговой компании Monash Information Services, это может быть предвестником серьезного пересмотра архитектурных представлений [3]. Однако с приходом нового поколения более дешевых и мощных компьютеров общего назначения «первопроходцы» оказываются не в состоянии продолжать развитие уникальных систем — и такие решения либо полностью вытесняются универсальными, либо получают вторую жизнь, но уже на новых массово выпускаемых средствах. Достаточно вспомнить судьбу машин обработки списков на базе языка Lisp, компьютеров для обработки документов Wang, высокопроизводительных графических станций Silicon Graphics, машин баз данных Britton-Lee и даже популярнейших мини-компьютеров DEC. Все они не выдержали конкуренции с персональными компьютерами. Но, конечно, развитие массово применяемых технологий неизбежно аккумулирует лучшие из вытесненных технологий, хотя часто и без особой выгоды для их создателей.
Поэтому наметившийся перевод специализированных приставок хранилищ данных на стандартные платформы и компоненты — верный признак их успеха в конкуренции с традиционными решениями, подтверждаемый опытом как начинающих, так и зрелых компаний. Можно предположить, что по мере совершенствования функциональных возможностей эти устройства сначала найдут широкое применение в технологиях хранилищ данных, а через какое-то время новшества, реализованные в них, органично впишутся в архитектуру будущих инфраструктурных компонентов интеллектуальной среды хранения данных.
-
Александр Александров, Машины хранилищ данных. «Открытые системы», 2006, № 2.
-
Appliances: more bang for your terabyte. Computerwire, 2006, Issue 56.
-
C. Monash, Design Choices in MPP Data Warehousing. Monash Information Services, 2007.
* Аналитики Gartner считают малыми хранилища данных объемом меньше 5 Тбайт, средними — размером от 5-20 Тбайт, а большими — хранилища, объем которых превышает 20 Тбайт полезных сведений без учета индексов и других служебных данных. — Прим. автора.
