
Одним из примечательных, но не слишком публичных событий 2006 года стала дискуссия по поводу закона Роберта Меткалфа. Напомним, что в свое время Меткалф, изобретатель Ethernet, высказал предположение, что значение той или иной сети можно оценить количеством связей между участниками, способными вступить во взаимодействие. Если допустить, что в пределе каждый участник может быть связан с каждым, то тогда суммарное число связей пропорционально квадрату числа узлов сети. Отмеченная закономерность впоследствии была названа законом Меткалфа, причем не им самим, а известным проповедником телекоммуникаций Джорджем Гилдером. Спустя несколько лет Дэвид Рид, рассмотрев различные способы распространения данных в сети, постулировал собственный закон с формулировкой, наделяющей сети еще большим значением. Но в июле 2006 года группа авторов из Университета штата Миннесота во главе с Эндрю Одлыжко, которых можно отнести к категории Internet-скептиков, опубликовала в журнале IEEE Spectrum статью, озаглавленную «Закон Меткалфа неверен». В частности, они вменили в вину этому закону то, что он сыграл роль катализатора, спровоцировавшего кризис «доткомов», который возник, как они уверены, из-за завышенной оценки значимости Internet. Одлыжко и его коллеги считают, что ценность Internet существенно ниже и подчиняется еще одному эмпирическому закону — закону Ципфа*.
Но какому бы закону ни подчинялась сеть, опыт показывает, что количество сообщений, получаемых узлами сети, возрастает с колоссальной скоростью. В полной мере это утверждение относится к информационным системам разного рода биржевых и финансовых площадок. Давление со стороны потоков входных данных становится одним из важных факторов, влияющих на эволюцию информационных систем.
Возрастающая скорость потоков и огромные объемы входных данных стимулируют создание корпоративных информационных систем, базирующихся на архитектурных принципах EDA и SOA. Однако системная архитектура решает только часть проблемы: нужен еще агрегат для перехвата и предварительной обработки событий, выделения сложных событий из потоков простых событий. Инструмент такого рода получил название «машины для обработки потоков» (Stream Processing Engine, SPE). В дополнение к нему для последующего распространения потоковых данных нужна также «нервная система предприятия» (Enterprise Nervous System, ENS). Созданием соответствующих технологий, которые принято обобщенно называть термином обработка потоков событий (Event Stream Processing, ESP), занято пока не более десяти компаний, в том числе такие «стартапы», как Aleri, Apama, AptSoft, Coral8, Streambase, Syndera, а также подразделения крупных компаний IBM, Progress Software и Tibco. Отдать безусловный приоритет, признать лидером нельзя ни один из проектов, но все же стоит учесть, что компания Streambase основана не кем иным, как легендарным Майклом Стоунбрейкером. В отличие от других исследователей Стоунбрейкер не просто предложил новый программный продукт, но и предпослал ему общие требования для продуктов этого класса.
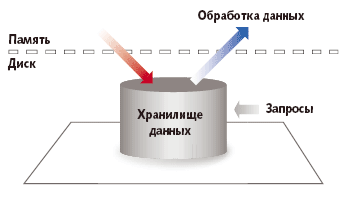 |
| Рис. 1. Чтобы обработать данные по традиционной схеме, их прежде необходимо сохранить в реляционной СУБД |
Мы привыкли к тому, что входные данные поступают в базу, откуда они выбираются по запросу (рис. 1). Для ускорения этой процедуры может быть разработано какое-то специализированное программное обеспечение, могут использоваться реляционные СУБД, резидентные в основной памяти, в некоторых случаях находят себе применение алгоритмы, заимствованные из области искусственного интеллекта (так называемые «машины правил»), известные с 70-х годов. Предлагаемые правила не являются догмой, скорее их можно представить как принципы, по которым могут строиться машины для работы с потоковыми данными. Альтернативная схема (рис. 2) предполагает, что данные в основном обрабатываются в потоке и только необходимая их часть поступает в системы хранения.
Соответствующая этой схеме универсальная машина обработки потоков данных может быть построена, если будут соблюдены следующие восемь правил.
Правило 1. Работать с мобильными данными
Для того чтобы уменьшить задержки, связанные с записью данных на диск, каким бы быстрым ни был диск, он как механическое устройство работает в совершенно ином временном диапазоне, нежели электронные устройства. Поэтому потоковые операции необходимо выполнять «на лету», как это показано на рис. 2. Еще одна причина задержек — пассивность существующих СУБД. Данные из них можно получить только по запросам, «вытягиванием», а каждый запрос — это потеря времени. В середине 90-х годов появлялись разработки, связанные с созданием активных баз данных (Active DBMS, ADBMS), что тогда они остались невостребованными.
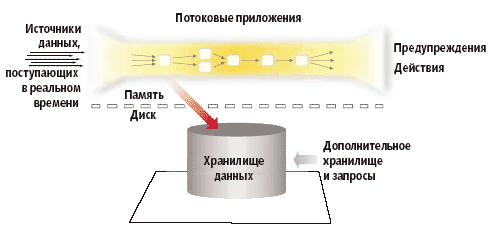 |
| Рис. 2. В машине для обработки потоковых данных происходит их обработка «на лету» с использованием части данных из операционных хранилищ |
Правило 2. Использовать язык SQL, адаптированный к потокам данных
Необходим специализированный язык запросов. Стоунбрейкер предлагает свою версию языка, которую он назвал по аналогии с SQL, StreamSQL. Успех SQL основывается на том, что он дает возможность выражать сложные преобразования данных благодаря использованию мощного набора примитивов, позволяющих фильтровать, сливать, устанавливать корреляцию, агрегировать данные. Это язык, по сути, стал стандартом для практически всех известных СУБД и знаком большому числу специалистов, а потому логично было бы разработать его продолжение, с ориентацией на потоки. StreamSQL сохраняет все возможности SQL, добавляя к нему развитые оконные средства, возможность смешивать хранимые данные с потоковыми, специализированный набор примитивов, ориентированных на потоки. Как и SQL, язык StreamSQL обеспечивает высокий уровень абстракции, избавляя от необходимости знать особенности физических ресурсов и информационной инфраструктуры.
Правило 3. Приспосабливаться к неоднородности потоков — к задержкам, отсутствию данных, нарушению заданной последовательности
Обычные системы на базе традиционных СУБД строятся в предположении, что запросу обязательно предшествует перенос данных в базу. В системах реального времени такую упорядоченность обеспечить невозможно, необходимо обрабатывать имеющиеся данные и сохранять работоспособность приложений в условиях неполноты данных.
Правило 4. Генерировать предсказуемые результаты
Данные могут поступать с нарушением последовательности и быть неполными, однако система не имеет права генерировать ошибочные результаты; она должна быть устойчивой к случайным факторам, только в таком случае может быть обеспечена достаточная надежность и достоверность результатов.
Правило 5. Интегрировать хранимые и потоковые данные
Использование SQL для исторических данных, а Stream — для потоковых позволяет собрать лучшее из двух миров.
Правило 6. Гарантировать безопасность и готовность данных
Несмотря на присущие им нестационарность и непредсказуемость, потоковые данные могут иметь большое значение для бизнеса, поэтому их безопасности и готовности должно уделяться особое внимание. Большинство известных способов, предназначенных для обеспечения этих качеств, рассчитаны на статические данные, которые можно сохранить и восстановить; для потоковых же данных эта пара процедур не годится. Пока единственным решением остаются кластерные конфигурации высокой готовности. Такие схемы, которые еще называют «тандемными» (Tandem-style), предполагают горячее резервирование и восстановление в реальном времени.
Правило 7. Автоматически масштабировать и создавать автономные разделы
Необходимо предусмотреть возможность распределения приложений по множеству процессоров или компьютеров; это особенно важно в связи с появлением дешевых кластерных конфигураций, а также многопотоковых и многоядерных процессоров.
Правило 8. Обрабатывать и отвечать одновременно
Система должна обеспечивать устойчивую работу под нагрузкой, измеряемой сотнями или даже тысячами событий в секунду, с задержкой не более нескольких миллисекунд.
Руководствуясь приведенными правилами, в компании Streambase построили одноименную платформу; в ней реализованы следующие основные функции.
- Захват данных. Для этой цели в Streambase предусмотрены встроенные адаптеры, позволяющие установить взаимодействие с большинством поставщиков данных. Кроме того, имеются средства для программирования специализированных адаптеров.
- Обработка и анализ данных о событиях. В Streambase используется адаптированная к событиям реляционная модель и язык обработки событий StreamSQL.
- Вывод. По результатам обработки потоков Streambase может запускать другие приложения и снабжать обобщенными данными потребителей, в том числе системы бизнес-мониторинга, которые могут визуализировать результаты, используя метафору пульта управления.
- Среда разработки. В Streambase имеется собственная графическая среда разработки, созданная на основе платформы Eclipse, предлагаются утилиты для тестирования и отладки.
От Ingres до Streambase

Майкл Стоунбрейкер, закончивший Принстонский университет в 1965 году, является обладателем нескольких академических наград, в том числе медали Джона фон Неймана, учрежденной IEEE, и первым лауреатом премии Эдгара Кодда, которой награждает SIGMOD. В настоящее время работает профессором в Массачусетском технологическом институте. В середине 70-х годов вместе с Юджином Вонгом в Университете Беркли создал СУБД Ingres, предназначенную для мини-ЭВМ, работавших под управлением ОС Unix, позже основал компанию Ingres Corporation, проданную в 1994 году корпорации Computer Associates и относительно недавно возродившуюся под собственным именем. Вернувшись в Беркли, работал над СУБД Postgres, основал сначала компанию Illustra, а затем Cohera. В конце 90-х, перебравшись в МТИ, работал по проекту Aurora, целью которого было создание систем обработки потоковых данных с использованием версии языка запросов SQL, названной StreamSQL. На фундаменте этих наработок была образована компания Streambase Systems.
* Закон, названный в честь Джорджа Ципфа (1902-1950), был выведен на основании исследования частоты использования слов в тексте. Если наиболее часто используемое слово встречается n раз, то второе по частоте — в k раз реже, то есть n/k, третье — n/k2 и т.д. Применительно к ценности Сети имеется в виду, что значение отдельных связей с ростом их числа уменьшается. — Прим. автора.
