

Причиной возврата к подзабытым иерархическим структурам в варианте XML стало более естественное для человека отражение семантики предметного мира. XML-СУБД позволяют непосредственно отображать документооборот в базе данных, а не перепроектировать его, что и обусловило актуальность и перспективность такой базы. Мы попытались расширить реляционную модель данных и используемую ею организацию внешней памяти для реализации корректной и эффективной обработки XML-документов. Оказалось, это не очень сложно, в различных реляционных СУБД многое есть уже в готовом виде и достаточно лишь сменить точку зрения.
Иерархическую модель данных в варианте XML можно наложить «поверх» реляционной модели. Для этого, в первую очередь, необходимо сохранить в базе данных номера позиций узлов, выбрав их в качестве естественного составного первичного ключа. Работа с таким ключом как с кластерным индексом позволяет оптимизировать использование реляционной структуры физической памяти под иерархическую. Помимо поддержки порядка следования узлов XML-СУБД должна эффективно работать с нелаконичными именами, разреженными и слабо структурированными данными, с XML-данными заранее неизвестной структуры.
Наша XML-СУБД основана на открытом интерфейсе B-деревьев СУБД Cache компании InterSystems и является составной частью созданного нами инструмента qWORD-XML, используемого в ряде проектов создания хранилищ данных, связанных с большими базами информации о населении (В. Веселов, А. Долженков, XML и технологии баз данных. «Открытые системы», 2000, № 5-6).
Актуальность XML-СУБД
Существует стереотип, что XML — это прежде всего удобный формат обмена данными, язык описания документов, некий результат развития Internet-технологии и т.п. Все это так, однако технология XML — это еще и некоторая конкретная иерархическая модель данных.
С точки зрения специалиста по базам данных синтаксис XML выглядит вычурно и избыточно. XSLT не похож на реляционную алгебру, XQuery хоть и похож на SQL, но еще не принят Консорциумом W3C в качестве стандарта. Эта особенность технологии XML становится понятной, если простить ей то, что она выросла не из логико-математических моделей, а из языков описания документов. Как мы увидим, этот ее недостаток стал важным преимуществом.
За 30 лет господства реляционных СУБД их производители убедили многих пользователей в том, что иерархические и сетевые модели данных — пройденный этап, нечто примитивное, плохо отражающее семантику предметного мира и явно уступающее по возможностям реляционной модели. На самом деле реляционная модель была принята именно потому, что она проста, что позволяет использовать строгий логико-математический аппарат. И именно простота позволила наладить производство различных реляционных СУБД. Тогда, 30 лет назад, Кодд продемонстрировал, что при равных семантических возможностях реляционная модель данных проще, чем сетевая или иерархическая. По-видимому, реляционная модель так и останется непревзойденной по соотношению возможности/сложность. Однако пользователи хотели и хотят большей семантики. Кодд, прекрасно это понимая, пытался, насколько возможно, расширять реляционную модель данных. Производители реляционных СУБД делали это за счет вторичных структур, находящихся как бы над моделью данных, например, за счет объектных оболочек или кластерных ключей. Заметим, что развитие вторичных «надсистемных» структур неизбежно приводит к тому, что во внешнем (логическом) представлении они спустя некоторое время становятся первичными.
За прошедшее время аппаратные мощности возросли необычайно. Сегодня удобство проектирования и эксплуатации баз данных экономически важнее, чем скорость обработки данных на компьютере. Математическая строгость и логичность еще не означает удобства. Так, человечество пользуется избыточной десятичной системой счисления, а не двоичной или восьмеричной (кстати, согласно Кодду, избыточна и сущность «связь» в реляционной модели). Можно, конечно, сказать, что так «исторически сложилось». Но нет, просто двоичной системой счисления неудобно пользоваться: числа длинные и трудно запоминаются.
Чем же неудобна реляционная модель данных и чем удобна модель XML? Как это связано с расширением семантики? Рассмотрим такую типичную для проектировщика баз данных задачу, как документооборот. (Большинство предметных областей может быть формально сведено к документообороту.) Легко ли отобразить документооборот в реляционной базе данных? Обычно каждый документ распадается на одну, чаще несколько таблиц, некоторые таблицы, полученные из разных документов, объединяются. Генерация документов — обратный процесс. Тяжело приходится со слабоструктурированными документами и разреженными данными. Еще тяжелее — с документами неизвестной заранее структуры. Можно ли алгоритм обработки реального документа непосредственно положить в основу программного кода хранимой процедуры? Нет, ваши документы в реляционной базе данных — уже совсем другие. Плохо с временными рядами. С событиями еще хуже. Замечательная, но редкая ситуация, когда документооборот проектируется «с чистого листа». Гораздо чаще документооборот либо уже существует в бумажном виде, или имеется набор требований, предписывающих, каким ему быть. В этом случае, по сути дела, происходит не отображение реального документооборота, а его перепроектирование, причем обычно с переобучением противящегося этому персонала.
Предполагается, что XML-СУБД в перспективе позволят решить задачу прямого отражения реальных документов и алгоритмов их обработки в базах данных без перепроектирования, тем самым подняв процесс разработки приложений до уровня декларативного языка. Это предположение базируется на том, что структура данных реального документа естественным образом описывается языком XML, которому соответствует вариант иерархической модели данных.
Иерархические структуры в рамках реляционных СУБД
Поскольку иерархические модели данных обычно лучше соответствуют семантике предметной области, то они пытаются «проникнуть» в традиционные СУБД поверх реляционной модели, опираясь на то, что реальное физическое хранение данных всегда упорядочено. Речь идет о наложении иерархической структуры как вторичной, позволяющей сохранить строгость реляционной модели, привнося в нее дополнительные преимущества иерархической модели при условии эффективной работы с внешней памятью.
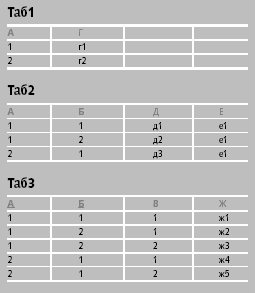 |
| Пример 1. Атрибуты ссылочных ключей с именами А в Таб2 и А+Б в Таб3 входят в состав составных первичных ключей А+Б и А+Б+В этих же таблиц |
Начнем с логического представления. Простейшие способы наложения иерархии показаны в примерах 1 и 2. В первом варианте атрибуты ссылочных ключей с именами А в Таб2 и А+Б в Таб3 (подчеркнуты) входят в состав составных первичных ключей А+Б и А+Б+В этих же таблиц (жирным шрифтом). С иерархической точки зрения, таблица Таб2 является дочерней по отношению к Таб1, а Таб3 — соответственно к Таб2.
 |
| Пример 2. Ссылочные ключи Б*, В* в состав первичных А*, Б*, В* не входят |
Во втором варианте (пример 2, примеры записей не показаны) ссылочные ключи Б*, В* в состав первичных А*, Б*, В* не входят.
Наложение иерархии предполагает, что наличие возможности эффективной выборки записей этих таблиц в последовательности иерархического обхода. В примере 3 показана последовательность записей, возникающая при иерархическом обходе данных, представленных в примере 1. Заметим, что последовательность записей в рис. 1 не является результатом денормализации трех таблиц: это просто записи тех же таблиц, отсортированные между собой по значениям атрибутов А, Б, В.
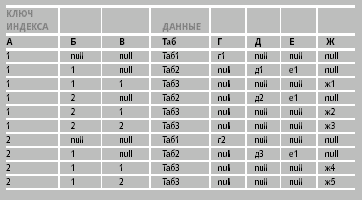 |
| Рис. 1. Последовательность записей из Таб1, Таб2, Таб3 |
Теперь рассмотрим аспекты физического хранения. При выборке иерархической последовательности записей существенен быстрый выход по ссылке на нужные записи и задача быстрого их чтения (минимизация числа операций ввода-вывода). В современных реляционных СУБД (Microsoft SQL Server, Oracle) первая задача решается с помощью индексов, а вторая — с помощью кластерных индексов.
В физической памяти индексы значений атрибутов реализуются наиболее эффективным образом, обычно с помощью хеш-таблиц, а кластерные индексы с помощью B-деревьев. Хеш-таблицы обеспечивают наиболее быстрое обращение к участку физической памяти, содержащему данные, относящиеся к значению индексируемого атрибута. B-деревья работают немного медленнее, чем хеш-таблицы, но зато, кроме быстрого обращения, в операциях обновления данных поддерживают порядок следования участков памяти, содержащих данные, в соответствии с сортировкой значений кластерного ключа.
 |
| Рис. 2. Усложненный вариант примера 1 |
Обычно в реляционных СУБД с индексами ситуация следующая. Сами записи хранятся один раз в индексе первичного ключа, а все остальные индексы в данных содержат ссылку на этот первичный ключ. Если хранить сами записи целиком, то индекс N атрибутов таблицы, грубо говоря, приведет к N-кратному увеличению физически хранимого объема данных. Применительно к рассмотренному примеру 2, индексация выглядит так, как показано на рис. 2: проиндексированы первичные ключи А*, Б*, В*, ссылочные ключи Б*, В*, а также один из неключевых атрибутов — Е* таблицы Таб2*.
Чуть более усложненный вариант примера 1 показан на рис. 2. Поскольку первичные ключи — составные, то в ключе индекса записываются не атомарные значения составляющих его атрибутов, а их «кластер». Если бы, например, значения относились к строковому типу данных, то таким кластером будет строка, полученная путем присоединения строки второго значения к строке первого. Первый пример отличается от второго также тем, что в нем нет необходимости индексации ссылочных ключей, так как они входят в состав «головы» индекса первичных ключей. Напротив, дополнительно проиндексирован атрибут В, поскольку индексация А+Б+В нам ничего не дает для поиска по значениям В: они находятся не в «голове» ключа индекса, а в его «хвосте».
 |
| Рис. 3. Пример использования «кластерного» ключа |
Под кластерными индексами в Micrsoft SQL Server и Oracle понимаются несколько разные вещи. В SQLServer речь идет об индексации группы атрибутов, принадлежащих одной таблице. Если эта группа не отвечает требованиям, предъявляемым к первичному ключу, то к ней добавляется суррогатная (генерируемая системой) «добавка». В любом случае получается индексированный составной первичный ключ или, иначе, кластерный ключ (рис. 3). При этом данные физически хранятся в последовательности из примера 1. В Oracle речь идет об индексации группы атрибутов, одновременно принадлежащих разным таблицам, что позволяет физически хранить таблицы в более сложносвязанном виде, например, в виде иерархической структуры.
Модель данных включает в себя три главных аспекта: структурный, манипуляционный и целостный. Реализацию структурного аспекта вместе с аспектами эффективного использования физической памяти мы рассмотрели на примере работы с индексами. Поскольку мы не выходили за рамки реляционной модель, то манипуляции и целостность в реляционном смысле остаются в силе. В данном контексте остановимся на вопросе манипуляций и целостности в смысле иерархическом.
Поддержка целостности данных в иерархических моделях данных, в первую очередь, сводится к целостности связей «отец-сын». В данном случае эти связи реализованы на первичных и ссылочных ключах реляционных таблиц. Если в реляционных СУБД поддерживается целостность по ссылочным ключам (например, в смысле каскадных операций), то автоматически она будет поддерживаться и в иерархическом смысле. Выделение конкретного поддерева на физическом уровне при использовании кластерных ключей сводится к быстрому чтению нескольких последовательных блоков памяти. В примере 1 чтение займет несколько больше времени. Присоединение одного поддерева под узел другого сводится к соединению таблиц по совпадающим значениям атрибутов и выделению второго поддерева и т.п. Проблема может возникнуть на уровне SQL. Если расписать выделение поддерева набором команд SQL, то, несмотря на оптимизацию физической памяти, это еще не значит, что они действительно будут быстро обработаны СУБД : можно по несколько раз читать одно и то же, можно и сортировать уже рассортированное.
Можно ли язык иерархических запросов (например, XQuery или, хотя бы, его составную часть XPath) эффективно транслировать в SQL? Теоретически да. Практически же эта возможность определяется работой оптимизатора SQL-запросов конкретной реляционной СУБД и той версией SQL, которую она поддерживает.
Особенности иерархической XML-СУБД
 |
| Рис. 4. Два типа узлов в реляционной модели данных |
Прежде всего, необходимо разобраться, какие типы узлов бывают в иерархии XML. В реляционной модели можно выделить два типа узлов: записи и атрибуты (рис. 4).
Имя записи определяется именем таблицы, которой она принадлежит. Собственного значения запись не имеет, но зато имеет дочерние узлы: атрибуты и дочерние записи. Одна или несколько дочерних записей ссылаются на родительскую при помощи ссылочного ключа. Порядок следования записей и порядок следования атрибутов не важны — перестановка строк и столбцов реляционной таблицы ничего не меняет.
Иерархическая модель данных, построенная на основе синтаксиса XML, существенно отличается от реляционной. В объектной модели XML-документа (XMLDOM) описывается 12 типов узлов, что выглядит несколько странно и избыточно (это, как уже отмечалось, обусловлено «наследием» языков описания документов). Рассматривая узлы в том же контексте, в котором рассматривали узлы реляционной модели данных, можно свести их многообразие к трем типам и получить таблицу 1.
Атрибут в модели данных XML — полный аналог атрибута в реляционной модели, но элемент полным аналогом записи не является. Порядок следования элементов, относящихся к одному родительскому узлу принципиально важен - это синтаксически разные конструкции. Помимо атрибута и элемента в XML существуют узлы, достаточно принципиально, со структурной точки зрения, от них отличные — узлы, не имеющие дочерних, но имеющие собственные значения и позицию в списке всех своих «братьев». К таковым относятся, например, узлы «текст», «комментарий». Вопреки XMLDOM, элементы с содержимым «только текст» по характеру своего реального использования как «упорядоченных атрибутов», по-видимому, следует относить не к элементам, а именно к этому типу узлов.
Таким образом, только атрибуты могут быть эквивалентно отображены из одной структуры в другую. Отображение элемента в запись дополнительно требует сохранения его позиции в списке всех своих «братьев». Это может быть сделано при помощи специального атрибута, которому дадим имя «позиция». Третий тип узлов («другие узлы») кроме этого, требует сохранения своих значений.
 |
| Рис. 5. Три типа узлов в объектной модели XML-документа |
Разговоры о поддерживающих XML реляционных СУБД пользователь обычно понимает так, что данные могут быть без потерь перенесены в СУБД. Для этого используются схемы отображения, содержащие информацию о том, каким именно образом реляционные узлы (записи и атрибуты или, если угодно, объекты и свойства) и узлы XML-документа должны отображаться друг в друга. Но информация о позициях XML-узлов в реляционные базы данных обычно не записывается. Схемы отображения ее содержат, но лишь с точностью до порядка следования групп одноименных узлов — можно задать порядок следования.
Убедится в том, что реляционные базы данных в состоянии поддерживать лишь те XML-данные, которые были из них же и сгенерированы, несложно. Возьмите любой файл XML, где важен порядок следования узлов (например, XSL, XSD-схему или даже просто XHTML), отобразите их в реляционную СУБД и попытайтесь восстановить в исходном виде. Ничего не получится. Пользователю следует помнить, что за утверждениями о том, что Microsoft SQL Server или Oracle «поддерживают XML», на самом деле стоит лишь ограниченная поддержка XML в части обмена данными. В обеих этих СУБД поддержка XML в структурной части реализуется на базе уже имеющихся конструкций.
Позиция узла уникальна в пределах всех других узлов-потомков его родителя. Упорядоченное множество позиций всех предков узла и его самого всегда уникально в пределах базы данных. Это множество всегда существует и однозначно, имеет четкий и понятный смысл, не зависящий от смысла конкретной базы данных или XML-документа, и поэтому является наилучшим претендентом на выбор в качестве первичного ключа. Назовем его «позиционным первичным ключом». Для иллюстрации сказанного вернемся к примеру 1. Рассмотрим значения атрибутов А, Б, В как позиции соответствующих узлов, а первичные ключи как позиционные. Запись этих данных синтаксисом XML выглядит так.
<Таб1 Г=«г1»>
<Таб2 Д=«д1» Е=«е1»>
<Таб3 Ж=«ж1»/>
<Таб2 Д=«д2» Е=«е1»>
<Таб3 Ж=«ж2»/>
<Таб3 Ж=«ж3»/>
<Таб1 Г=«г2»>
<Таб2 Д=«д3» Е=«е1»>
<Таб3 Ж=«ж4»/>
<Таб3 Ж=«ж5»/>
Если с точки зрения XML позиционный ключ — это ключ естественный, то с реляционной точки зрения он видится как ключ суррогатный. Мы опробовали оба варианта записи данных — как в примере 1 и на рис. 3, оба они также представлены на схемах из рис. 6. Несмотря на более медленную скорость сборки XML-дерева, окончательный выбор был сделан на первом варианте, поскольку он практически более удобен с точки зрения работы поисковой машины: запросы XPath чаще всего строятся на основе имен узлов, а не их позиций.
 |
| Рис. 6. Два варианта записи данных |
Поддержка хранения узлов как упорядоченных множеств — важнейшая особенность XML-СУБД. Наряду с ней есть еще ряд особенностей, реализовать которые в рамках реляционной СУБД может оказаться сложным, и которые должны эффективно поддерживаться XML-СУБД.
1. Нелаконичность имен узлов. Консорциум W3C придает минимальное значение лаконичности языка XML, в частности размеру имен узлов. Размер имен становится еще большим, если к ним приписать URI пространства имен, что совершенно необходимо для обеспечения поддержки их мировой уникальности. Длинные имена приводят к очень длинным указателям XPath, что затрудняет работу поисковой машины. На наш взгляд, целесообразна (автоматически исполняемая на уровне СУБД) замена имен на уникальные в пределах базы данных короткие коды. Собственно, кодирование имен начинается уже в XML-документе: вместо URI пространства имен используется короткий и уникальный в пределах документа префикс.
2. Одинаковость имен узлов, расположенных в структурно разных частях XML-документа. С реляционной точки зрения это выглядит как наличие в БД нескольких таблиц с одинаковыми именами и общим описанием. Ситуация может быть решена, если одноименным таблицам назначить различные коды как реляционные имена, а описания продублировать. Однако все не так просто, если учесть достаточно типичную для XML рекурсивность в описаниях, приводящую к неконтролируемому разрастанию подобных реляционных описаний. Например, Таб2 и Таб3 могут быть описаны как дочерние по отношению к Таб1, Таб1 и Таб3 как дочерние к Таб2, а Таб1 и Таб2 как дочерние к Таб3. У нас эта ситуация решена путем задания реляционных имен как полного набора всех родительских имен (точнее уже упомянутых кодов) от корня, например, Таб1/Таб2/Таб3.
3. Разреженность данных. Пример разреженных данных можно увидеть на рис. 1, в виде обилия значений null. На уровне физической памяти ситуация может быть решена, если хранить записи не как два последовательных списка (один для имен атрибутов в описаниях, другой для значений в данных), а как один упорядоченный по кодам список пар код атрибута — значение, не храня в списке пары, в которых значение null. Код атрибута, в нашем решении, вошел в состав ключа индекса в рис. 6.
4. Работа с XML-данными заранее неизвестной структуры. Это — принципиальная особенность XML-СУБД, выгодно отличающая ее от реляционных СУБД. Данные могут быть записаны в XML-СУБД без предварительного ввода каких-либо их описаний и компиляций соответствующих классов, причем после ввода они сразу (по завершению транзакции, без вмешательства администратора) должны вместе с автоматически созданным минимумом описаний быть доступны пользователю для запросов. В нашем случае этот вопрос решен путем унификации обработки XML-узлов и правильного использования объектного подхода.
