

В компьютерных технологиях сегодня отчетливо просматривается стремление с минимальными потерями перенести в виртуальный мир объекты мира реального. Объектно-ориентированная СУБД — именно то средство, которое обеспечивает запись объектов в базу данных «как есть». Данное обстоятельство стало решающим аргументом в пользу выбора ООСУБД для переноса семантики объектов и процессов реального мира в сферу информационных систем. Цель данной статьи — рассмотреть внутреннюю организацию современных ООСУБД.
Рис. 1. Основные элементы ООСУБД
Рис. 2. Применение базовых понятий объектной модели в ООСУБД
Рис. 4. Управление версиями в ООСУБД Versant
Таблица 1. Особенности ООСУБД Jasmine, Versant и ODB-Jupiter
Использование объектного подхода к проектированию систем [11] поднимает роль ООСУБД как средства для наиболее естественного хранения и манипулирования создаваемыми объектами [1]. ООСУБД находят широкое применение в Internet — огромном собрании разнородных данных, поступающих из разных источников. Текст, картинки, видео и звук, из которых составляется Web-страница, хранятся в ООСУБД как набор объектов, подготовленный к передаче программе-клиенту, что позволяет добиться быстрой реакции сервера на запрос. Все большую популярность получают активные Web-серверы, на лету генерирующие страницы, используя язык Java. Практически все ведущие разработчики ООСУБД выбрали Java одним из основных для себя языков программирования. Несмотря на наличие многих теоретических проблем, ключевой из которых, безусловно, является сложность строгой формализации объектной модели данных, многие эксперты полагают, что за этими системами будущее [10].
Единого мнения по поводу того, как конкретно следует организовывать ООСУБД, нет. Тем не менее, можно указать ряд непременных свойств, которым они должны удовлетворять. Эти свойства продекларированы в «Манифесте систем объектно-ориентированных баз данных» [6], а впоследствии закреплены в документах ODMG, организации, объединяющей ведущих производителей ООСУБД, ставящей своей целью выработать стандарты, соблюдение которых обеспечивало бы переносимость приложений. Используемая в статье терминология отражает требования стандарта ODMG 2.0 [13], однако при описании примеров, взятых из различных коммерческих ООСУБД, авторы в первую очередь опирались на документацию соответствующих производителей. Поскольку большинство рассматриваемых вопросов касается внутренних особенностей систем, которые в полном объеме не документированы, то ряд выводов основывается на результатах экспериментов с соответствующими программными продуктами, а также на опыте разработки аналогичных систем. Отсутствие исчерпывающей технической информации об ООСУБД типа Versant [15] или Jasmine [12] заставило авторов более подробно остановиться на изложении особенностей ODB-Jupiter [5], доступной им в полном объеме.
Модель данных
В соответствии со стандартом ODMG 2.0 [13] объектная модель данных характеризуется следующими свойствами.
- Базовыми примитивами являются объекты и литералы. Каждый объект имеет уникальный идентификатор, литерал не имеет идентификатора.
- Объекты и литералы различаются по типу. Все элементы одного типа имеют одинаковый диапазон изменения состояния (множество свойств) и одинаковое поведение (множество определенных операций). Объект, на который можно установить ссылку, называется экземпляром; он хранит определенный набор данных.
- Состояние объекта определяется набором значений, реализуемых множеством свойств. Этими свойствами могут быть атрибуты объекта или связи между объектом и одним или несколькими другими объектами.
- Поведение объекта определяется набором операций, которые могут быть выполнены над объектом или самим объектом. Операции могут иметь список входных и выходных параметров строго определенного типа. Каждая операция может также возвращать типизированный результат.
- База данных хранит объекты, позволяя совместно использовать их различным пользователям и приложениям. База данных основана на схеме данных, определяемой языком определения данных, и содержит экземпляры типов, определенных схемой.
Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация определяет внешние характеристики типа: пользователю для работы с объектом предоставляется набор операций и набор атрибутов объекта, при помощи которых можно работать с реальными экземплярами. Реализация определяет внутреннее содержание объектов, например операции.
Тип также является объектом. Поддерживается иерархия супертипов и подтипов, реализуя стандартный механизм объектно-ориентированного программирования — наследование.
ООСУБД обслуживает множество баз данных, каждая из которых содержит определенное множество типов. В базах данных могут содержаться объекты соответствующего типа из этого множества. Тип имеет набор свойств, а объект характеризуется состоянием в зависимости от значения каждого свойства. Операции, определяющие поведение типа, едины для всех объектов одного типа. Свойство едино для всего типа, а все объекты типа также имеют одинаковый набор свойств. Значение свойства относится к конкретному объекту.
Идентификатор объекта
Как это следует из модели данных, каждый объект в базе данных уникален. Существует несколько подходов для идентификации объекта. Самый простой — присвоить ему уникальный номер (OID — object identificator) в базе и никогда больше не повторять этот номер, даже если предыдущий объект с таким номером уже удален. Недостаток такого подхода состоит в невозможности перенести объекты в другую базу без потери связности между ними. Решение этой проблемы заключается в использовании составного идентификатора. Например, в Versant идентификатор OID имеет формат xxxxxxxx:yyyyyyyy, где xxxxxxxx — идентификатор базы данных, yyyyyyyy — идентификатор объекта в базе. Составленный таким образом OID позволяет переносить объекты из базы в базу без потери связи между объектами или без удаления объектов с перекрывающими номерами.
В Jasmine применяется другой способ — формирование OID из имени класса объекта и собственно номера объекта. Идентификатор имеет вид classnamexxxxxxxx, где classname — имя класса, а xxxxxxxx — номер объекта этого класса. Недостаток такого подхода заключается в том, что проблема переноса объектов не решена полностью. В разных базах могут оказаться объекты одного класса, а уникальность номеров соблюдается только в пределах одной базы. Преимущество подхода — в простоте извлечения объектов нужного класса: объекты одного класса будут иметь идентификатор, имеющий общую часть. Идеальный же вариант — использование OID, состоящего из трех частей: номер базы, номер класса, номер объекта. Однако и при этом остается вопрос о том, как обеспечить уникальность номеров баз и классов на глобальном уровне — при использовании ООСУБД на различных платформах, в разных городах и странах.
Новые типы данных
Одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и использования новых типов данных. Концептуально объект характеризуется поведением и состоянием. Определение типа заключается в определении поведения, т.е. операций, которые могут быть выполнены объектом или над состоянием объекта — набором атрибутов определенных типов (атрибут может иметь любой объявленный в базе тип). Важная особенность ООСУБД состоит в том, что создание нового типа не требует модификации ядра базы и основано на принципах объектно-ориентированного программирования: инкапсуляции, наследовании, перегрузке операций и позднем связывании.
Как правило, в ООСУБД для объектов, которые предполагается хранить в базе (постоянные объекты), требуется чтобы их предком был конкретный базовый тип, определяющий все основные операции взаимодействия с сервером баз данных. Поэтому для создания своего типа необходимо унаследовать свойства любого имеющегося типа, наиболее подходящего по своему поведению и состоянию к типу, который требуется получить, расширить недостающие операции и атрибуты и переопределить, по необходимости, уже имеющиеся.
Пример на рис. 3 иллюстрирует возможность наращивания типа «человек» (Person), который может быть «мужчиной» (MalePerson), «женщиной» (FemalePerson), «взрослым» (Adult) или «ребенком» (Child). Соответственно возможны попарные пересечения этих типов. Каждый из этих типов может иметь свой набор свойств и операций. Любой объект типа MalePerson, FemalePerson, Adult или Child является объектом типа
Person. Аналогично объект подтипа MaleAdult, полученного наследованием типов MalePerson и Adult является человеком, мужского пола, взрослым и, соответственно, может пользоваться свойствами и операциями всех своих супертипов.
Функционирование базы основано на схеме данных. Как уже отмечалось в определении объектной модели, любой тип является объектом, следовательно, схемы данных являются уровнем интерпретации специфических служебных объектов, использующих свойства этих объектов как схему для создания новых типов. Схема данных может быть как первичной для создания классов, которые собирается использовать программист, так и вторичной, выделяемой из созданных на языке программирования (скажем, на C++) классов и загружаемой в базу. Язык ODL разработан ODMG как универсальный язык описания объектов и не претендует на то, чтобы называться полноценным языком программирования. Для целей разработки этой же организацией предусмотрены элементы расширения классических объектных языков C++, Smalltalk, Java, позволяющих описать структуру объектов, их связи и типы связей.
В объектных базах данных также различают два вида операций и атрибутов, распространяющих свое действие только на конкретный экземпляр или на весь тип.
В примере из таблицы 1 определен тип «Подразделение учета входящей корреспонденции», атрибут «Название подразделения». Все объекты входящей корреспонденции данного подразделения могут относиться только к этому подразделению и, для того, чтобы не засорять базу данных лишней информацией, название подразделения хранится в коде пользовательских программ, а не в объектах, хранимых в базе. Это справедливо в том случае, если название подразделения не меняется. Для атрибутов объектов, значение которых может меняться, такой механизм не подходит: атрибут «Название входящего документа» в различных экземплярах может иметь различные значения. Аналогичный механизм применим и для операций: пользователь может определять операции для конкретного экземпляра. Базы данных, которые могут хранить код операции в экземпляре типа и способны его выполнить, называются активными объектными базами.
Оптимизация ядра СУБД
Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями для него являются кэширование объектов, ведение версий объектов, разделение прав доступа к конкретным объектам. Ядро объектно-реляционной СУБД остается реляционным, а «объектность» реализуется в виде специальной надстройки. Как следствие, ООСУБД свойственно более высокое быстродействие на операциях, требующих доступа и получения данных, упакованных в объекты, по сравнению с реляционными СУБД, для которых необходимость выборки связных данных ведет к выполнению дополнительных внутренних операций [4].
Язык СУБД и запросы
Общепризнанны две группы вариантов языков запросов. Первая объединяет языки, унаследованные от SQL и представляют собой разновидность OQL (Object Query Language), языка, стандартизованного ODMG. Хотя он существенно отличается от SQL, некоторое подобие явно прослеживается. Например, в Versant поддерживается большинство функций стандарта SQL-92, включая и большой набор арифметических действий и констант. Однако некоторые функции принципиально не могут быть реализованы для объектных баз данных только средствами SQL (например, функции модификации структуры данных). Это обусловлено прежде всего возможной потерей связи с объектами в прикладных программах. Объектно-реляционные СУБД используют различные варианты ограниченных объектных расширений SQL.
Вторая, сравнительно новая (применяется с 1998 года) группа языков запросов базируется на XML. Собирательное название языков этой группы — XML QL (или XQL). Они могут применяться в качестве языков запросов в объектных и объектно-реляционных базах данных. Использование в чисто реляционных базах не целесообразно, поскольку языком предусматривается объектная структура запроса [8].
Транзакции
В соответствии со стандартом ODMG 2.0 транзакции представляют логический блок, гарантирующий атомарность (atomicity), целостность (consistency), изолированность (isolation) и долговечность (durability). Атомарность предполагает, что операции в рамках транзакции либо полностью выполняются, либо полностью не выполняются. В соответствии с требованием целостности, транзакция, инициируемая в находящейся во внутренне логически связанном состоянии базе данных, приводит ее в другое логически связанное состояние. Изолированность гарантирует, что ни один другой пользователь не сможет увидеть изменений, проводимых в рамках этой транзакции, пока не будет выполнена операция commit («принять»). Долговечность означает, что изменения, проведенные в рамках транзакции и сохраненные в базе данных операцией commit, сохранятся даже в том случае, если произойдет сбой системы. Это свойство гарантирует, что для завершенных операцией commit транзакций данные не будут потеряны. На примере ООСУБД Versant рассмотрим наиболее типичные виды транзакций: короткие, длинные, вложенные.
Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках сеанса работы с ООСУБД. Это наиболее простой вид транзакций, реализованный во всех современных СУБД. Все объекты подлежащие изменениям блокируются, а после принятия транзакции разблокируются, изменения же записываются в базу данных.
Длинные транзакции предназначены для увеличения производительности при групповой работе. Реализовано это следующим образом. Например, в Versant можно создавать персональные и групповые базы. Для снижения вычислительной нагрузки на центральный сервер при одновременной работе большого числа пользователей в Versant предлагает пользователям, постоянно работающим с определенными объектами, возможность организации персональной базы данных. Пользователи работают со своей базой, а объекты из нее синхронизируются с групповой базой данных. Пользователь, начав длинную транзакцию, тем самым отмечает объекты, с которыми предстоит работать в групповой базе данных (операция «поставить на контроль» — check out). Эти объекты копируются в его персональную базу, а в групповой базе блокируются, причем блокировать их можно как на запись, так и на чтение. В групповой базе создается объект, содержащий все данные о длинных транзакциях. В случае повреждения групповой базы или физического отключения сервера групповой базы пользователь сможет продолжать работу с объектами в своей персональной базе, а после восстановления групповой базы — синхронизировать объекты. Перед завершением длинной транзакции пользователь должен поместить все измененные объекты обратно в основную базу (операция «зарегистрировать» — check in). После этого объекты копируются в основную базу, а блокировка снимается. В случае аварийного завершения длинной транзакции все изменения будут потеряны.
Вложенные транзакции по принципу функционирования аналогичны коротким. В процессе выполнения одной транзакции формируются другие. Если в текущем сеансе работает один процесс, то создается стек, а если несколько процессов — дерево транзакций.
Блокировки
Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения одновременного изменения данных. В соответствии с терминологией, принятой в системе Versant [14], существуют короткие, продолжительные и оптимистические блокировки.
Короткие блокировки (short lock) предназначены для обеспечения последовательного доступа к данных при многопользовательском режиме работы. Они автоматически выполняются во время выполнения коротких транзакций.
Продолжительные блокировки (persistent lock) обеспечивают блокирование объектов на продолжительное время — часы, дни, недели. Применяются совместно с длинными транзакциями. При этом объект может быть заблокирован несколькими способами: с исключением снятия другим процессом (hard lock); с возможностью снятия другим процессом (soft lock); по конкретным операциям.
Перемещение объектов
Немалое значение для ООСУБД имеет возможность перемещения объектов из одной базы в другую [3]. Подобный механизм применяется в ООСУБД Versant [15], в которой поддерживаются следующие способы перемещения объектов.
- Миграция объектов: постоянное их перемещение, например в другую базу данных. В качестве примера можно привести перемещение объектов из базы оперативных данных в базу данных архивного назначения.
- Постановка на контроль (check out): копирование объектов в персональную базу данных при выполнении длинной транзакции. Как уже говорилось, для оптимизации загрузки вычислительных ресурсов пользователь может работать со своей персональной базой, перемещая и копируя из групповой базы только те объекты, с которыми ведется достаточно длительная работа. Данная операция приводит к копированию объектов из групповой базы в персональную.
- Регистрация объектов (check in): копирование объектов в групповую базу данных из персональной при выполнении длинной транзакции.
Ведение версий
В «Манифесте объектно-ориентированных баз данных», поддержка множественных версий объектов отнесена к необязательным характеристикам ООСУБД. Однако большинство современных коммерческих ООСУБД поддерживает версионность; более того, именно она рассматривается многими авторами как отличительная черта ООСУБД (это не совсем так, поскольку и в других СУБД, используя специфические приемы, можно поддержать версионность: но, безусловно, в ООСУБД реализация такого механизма будет гораздо проще).
Важность версионности для ООСУБД обусловлена их историческими корнями: считается, что версионность появилась для решения задач автоматизированного проектирования, выделившись постепенно в самостоятельный класс систем. Для САПР характерна задача сохранения многих версий одного и того же проекта. Впрочем, поддержка версионности может оказаться полезной и для других приложений. Достаточно указать на делопроизводство, где также необходима поддержка многих версий (редакций) документа, при этом высока вероятность появления запросов типа: «Найти редакцию проекта контракта по состоянию на 1.12.2000». Кроме того, версионность способствует повышению надежности информационной системы в целом: пользователи модифицируют не сами объекты, а их версии, а окончательные изменения происходят на сервере лишь после выполнения специальных процедур. Это уменьшает вероятность порчи информации из-за ошибок оператора или вследствие каких-то умышленных действий.
В качестве примера вновь рассмотрим ООСУБД Versant [16]. Для всех объектов возможно сохранение всех версий их изменения. Создается граф происхождения версий, поддерживающий ряд свойств.
- Доступ к любой ранее сохраненной версии. Благодаря этому свойству возможно извлечение из базы данных, например, случайно удаленных данных.
- Установка версии по умолчанию. Это свойство объясняет причину возникновения ветвей в графе происхождения версий, так как любая порожденная версия создаст ветвь от установленной текущей, не последней версии.
- Удаление версии. Вполне логичным является необходимость удаления некоторых версий (например, промежуточных или случайно порожденных) из графа происхождения версий.
Физические хранилища
Один из ключевых моментов функционирования любой СУБД — хранилище данных. Обычно база данных объединяет несколько хранилищ, каждое из которых ассоциируется с одним или несколькими файлами. Хранятся как метаданные (класс, атрибут, определения операций), так и пользовательские данные. Выделяют три типа хранилищ:
- системное хранилище, использующееся для хранения системы классов, создается на этапе формирования базы данных и содержит информацию о классах, о наличии и месторасположении пользовательских хранилищ;
- пользовательское хранилище для хранения пользовательских объектов;
- служебное хранилище, содержащее временную информацию, например сведения о заблокированных объектах, об активных транзакциях, различного вида списки запросов пользователей и т.д.
В СУБД Jasmine, выделяют четыре вида хранилищ.
- Системное хранилище (system store) используется для хранения системы классов, создается на этапе установки Jasmine и содержит информацию о семействах классов и пользовательских хранилищ. Возможно определение пользовательских хранилищ для помещения в них описаний пользовательских семейств классов.
- Пользовательское хранилище (user store) служит для хранения пользовательских объектов, например Persons, Projects или Locations. Пользовательские хранилища могут располагаться внутри системного.
- Рабочее хранилище (work store) предназначено для поддержки временной информации в ходе сеанса работы, например результатов поисковых запросов.
- Хранилище транзакций (transaction store) используется для хранения временной информации, связанной с организацией транзакций.
Другой пример — организация хранилищ в ООСУБД Versant, все базы данных в которой делятся на групповые и персональные. База данных состоит из нескольких физических разделов:
- системный раздел (system volume), который создается автоматически при создании базы данных;
- раздел данных (data volume), который может быть добавлен для увеличения доступного размера базы;
- раздел логического протокола (logical log volume) и раздел физического протокола (physical log volume) предназначены для хранения служебной информации о транзакциях, блокировках для обеспечения возможности отката транзакций и восстановления базы.
Иерархия типов ООСУБД
На рис. 5а представлена иерархия типов ООСУБД Jasmine. Корневым типом является тип Object, подтип Literal является типом, образующим все простые типы. На основе подтипа Entity формируются все служебные типы: коллекции, сессии, транзакции и т.д. Такая организация позволяет хранить в базе любой объект, хотя с точки зрения затрат на размещение объектов в базе это требует больших ресурсов, чем в случае изолированной организации типов.
Для создания приложения необходимо создать последовательность сцен, которые служат своеобразным холстом для написания полноценного графического интерфейса. На нее визуально помещаются объекты из базы. Такими объектами могут быть графические, видео- или аудиофрагменты. Для всех экранных элементов могут быть назначены функции, вызываемые по событиям.
Теперь рассмотрим организацию типов ООСУБД Versant (рис. 5б).
В отличие от ООСУБД Jasmine в данном случае далеко не все типы являются потомками базового типа PObject. Тип PClass предназначен для работы с типами и их индексами, определенными в базе. Тип PDOM предоставляет методы для работы с базой данных, администрирования сеансов, контроля транзакций и блокировок. Все остальные объекты, в том числе пользовательские, являются потомками PObject и могут быть хранимыми.
Особенности реализации ООСУБД ODB-Jupiter
Идентификатор объекта, 3-байтовое целого числа, представляет собой номер первой страницы цепочки записи в страничном файле базы данных. Поскольку идентификатор не привязан к базе данных, перенос объектов невозможен. В принципе это не является серьезным ограничением, и в прикладной программе от этого можно избавиться.
Реализовано два механизма расширения базового набора типов. Во-первых, возможно наследование, расширение и переопределение классов базовых типов, написанных на С++. Кроме этого, используя особенности базового класса TOdbObject, можно динамически добавлять к ним необходимые свойства.
В иерархии базовых классов основное положение занимает класс TOdbObject, который содержит все необходимые свойства и методы для управления процессом доступа к базе и выполнения индексации. Все остальные классы переопределяют его методы, добавляя проверку корректности реализуемого ими типа и специфический индексатор. Класс TObjectChild, определенный внутри TOdbObject, содержит указатель на элемент типа TOdbObject и ряд дополнительных структур. Из элементов этого класса определен динамический массив vector, позволяющий сформировать массив внедренных объектов-потомков TOdbObject. Каждый внедренный объект может иметь свой тип и, соответственно, отдельно индексироваться. Доступ к внедренным объектам, естественно, возможен только через основной объект. Все приведенные на диаграмме типы далее в статье называются стандартными.
Определение класса TodbObject выглядит следующим образом:
class TOdbObject {
protected:
struct TObjectChild {
TOdbObject* a_Child;
void* a_Info;
};
class TChildren: public vector
{
dword m_dwIndexor;
public:
TChildren();
TIndexKey* FirstIndex();
TIndexKey* NextIndex();
dword GetIndexor() ;
};Атрибуты
Рассмотрим атрибуты объекта TodbObject.
Динамический массив объектов, внедряемых в данный объект:
TChildren *m_pChildren;
Идентификатор объекта и указатель на объект-владелец, предназначенные для определения объекта, в массив m_pChildren которого он включен:
TObjID m_nObjectID; TOdbObject *m_pParent;
Служебный идентификатор объекта предназначен для обеспечения доступа к объектам, включенных в массив m_pChildren. Каждый объект в массиве m_pChildren имеет уникальный для данного массива номер в диапазоне от 1 до 0xFFFF:
dword m_dwUniqum;
Права доступа к объектам подразумевают разрешение определенных операций данному пользователю с объектами этого типа:
dword m_dwAccess;
Индексатор объекта обеспечивает индексацию данных этого объекта:
TIndexator *m_pIndexator; TIndexKey *m_pIndex;
Специальные флаги объекта:
dword m_dwFlags.
Флаг захвата объекта, обозначающий, что данный экземпляр уже редактируется:
bool m_Attach.
Операции
Классы-потомки должны иметь все перечисленные функции для того, чтобы сервер мог получить к ним доступ. Как и предусмотрено объектным подходом, все атрибуты класса должны быть закрыты от непосредственной модификации и чтения. Для этого должны быть определены соответствующие операции.
// получить идентификатор объекта virtual TObjID GetID(); // установить идентификатор объекта virtual void SetID(TObjID id); // получить указатель на владельца virtual TOdbObject* GetOwner(); // получить указатель на предка virtual TOdbObject* GetParent(); // получить служебную информацию virtual void* GetInfo(); // «прописать» предка virtual void SetParent(TOdbObject* pParent); // определить служебный идентификатор virtual dword GetUniqum(); // установить служебный ID virtual void SetUniqum(dword dwUnique); virtual dword PrivilegeLevel(); virtual void SetPrivilegeLevel(dword dwPriority); // определить ID virtual TObjID GetObjectID (TOdbObject* pObject); // функции работы с флагами virtual bool SetFlags(dword dwFlags); virtual bool ClearFlags(dword dwFlags); virtual dword GetFlags();
Каждый тип имеет свое строковое имя, которое возвращает функция virtual const char* RunTimeClassName();
В зависимости от того, что требуется от класса потомка, могут быть добавлены любые внутренние функции работы с данными, однако внешний интерфейс должен оставаться неизменным. Данные могут иметь любой внешний формат, однако их формат в базе может меняться, например данные могут быть сжаты, поэтому есть сразу несколько функций, возвращающих длину:
virtual dword GetSize(), GetLength(), GetLength(dword), GetSize(dword), AsciiLength().
Объекты имеют сложную структуру, что не позволяет сравнивать их непосредственно. Для этих целей существует функция:
virtual int IsEqual(TOdbObject * pObj);
Для объектов необходимо обеспечить стандартный набор операторов языка пользовательской программы; для этого переопределяются стандартные операторы и устанавливаются преобразователи типов. Таким образом, все потомки этого класса имеют одинаковый интерфейс. Оператор [] позволяет не задумываться над размещением внедренных объектов, предоставляя возможность обращаться к ним по номеру m_dwUniqum.
virtual TOdbObject& operator =(char* pData); virtual TOdbObject& operator =(void* pData); virtual operator void*(); virtual operator char*(); int operator ==( const TOdbObject& outer ) ; virtual TOdbObject& operator =( char* pData); virtual TOdbObject& operator =( void* pData); virtual TOdbObject& operator[](dword dwIndex); virtual dword SetData(void *pvBuffer), GetData(void *pvBuffer);
Каждый объект имеет стандартный набор функций управления данными. Объект имеет уникальный номер, поэтому программа-клиент, выполняющая, скажем, операцию obj-Read(237), получит данные объекта с номером 237, в том случае, конечно же, если пользователь обладает соответствующими правами. При поиске из индексного дерева извлекаются записи идентификаторов объектов, представленные в виде цепочки, а доступ к конкретным данным осуществляется соответствующими функциями позиционирования.
// Определить/установить
// идентификатор базы
virtual TObjectNum
GetDatabaseID();
virtual bool SetDatabaseID
(TObjectNum Number);
// Определить имя сервера:
virtual const char*
GetServerName();
// Определить строковое имя базы:
virtual const char*
GetDatabaseName();
// Прочитать объект из базы:
// virtual bool Read
(TObjectNum Number);
// Выделить место под новый объект:
virtual TObjectNum New();
// Обновить объект в базе:
virtual bool Update();
// Удалить объект из базы:
virtual bool Delete();
// Искать объект:
virtual TCdbFind* Search(dword
dwUniqum = 0);
// Добавить новый объект:
virtual void Add();
// Редактировать объект:
virtual bool Edit(); Функции работы с индексом обеспечивают универсальный интерфейс для всех потомков базового класса, позволяющий индексировать их, предварительно преобразовав к стандартному типу. Объект может иметь несколько индексов. Для позиционирования по ним предназначен комплект функций. Каждому индексу соответствует уникальное строковое имя: virtual const char* IndexName();
У объекта может быть несколько ключей. Например, при разборе любого текста каждое слово представляется отдельным значением.
virtual dword TotalLenKeyVal(); virtual TKeyValue& GetKeyValPair(dword dwIndex); virtual bool ExistKey(TKeyValue& kvPair); virtual dword AmountIndex(); virtual dword AmountKey(); virtual bool CreateIndexData(); virtual bool ReleaseIndexData(); virtual bool NewIndex( char* pszName, char* pszType, void* pvInfo = null);
Функция построения поискового запроса, позволяющая преобразовать запрос произвольного типа в стандартный в виде записи машинной записи логических операций:
virtual bool GetQuery(char* pszBuffer, uint& uErr);
Для контроля вводимых данных потомки базового класса должны переопределять функцию IsValid, разрешающую или не разрешающую помещение данных в объект.
Детали функционирования
Рассмотрим наиболее существенные элементы базового класса TodbObject, начав с процедуры создания объекта. Каждый объект принадлежит конкретной базе конкретного сервера. В базе объект идентифицируется по уникальному номеру, физически представляющему собой номер головной страницы страничного файла базы данных, что позволяет получить быстрый доступ к нему, однако не позволяет осуществить перенос объектов из одной базы в другую. Каждый объект базы, имеющий определенный внутренний тип, должен иметь и внешний тип (или вид), позволяющий сформировать индекс. Клиент, желающий добавить некоторые данные в базу, создает ссылку на локальный объект соответствующего типа, способного хранить эти данные. Объекту назначается сервер и база данных, в которую его необходимо поместить. Функция TOdbObject::New возвращает идентификатор объекта в указанной базе, зарезервированный под созданный объект. Помещение данных в базу и их индексация происходит по вызову функции TOdbObject::Add. Для чтения документа необходимо знать его идентификатор, передаваемый в функцию TOdbObject::Read. Перед изменением данных в прочитанном из базы объекте необходимо заблокировать объект в базе. Автоматически это действие не выполняется, поэтому для блокирования объекта повторно вызывается OdbObject::Read. Сервер интерпретирует это как блокирование объекта и, в случае, если другие пользователи также попытаются начать редактирование, им будет выдано соответствующее исключение. Обновление данных в базе клиентом допускается только в том случае, если объект заблокирован именно этим клиентом; это реализуется функцией TOdbObject::Update. Аналогичным образом устроено и удаление объекта из базы.
Поиск объекта в базе происходит в соответствии со следующей схемой. Создается пустой объект; свойства пользователя в нем не заполняются. Ему присваивается флаг поиска, после чего данные, которые будут присвоены объекту, интерпретируются как значение для поиска. Функция TOdbObject::Search инициирует процедуру поиска, результатом которой является массив найденных объектов и значений внедренных объектов. Сервер обрабатывает полученные от клиента объекты для поиска: изымается строковое имя индекса, соответствующее данному типу и поисковый запрос. Совокупность поисковых запросов, полученная от внедренных объектов, последовательно обрабатывается, а результат объединяется по идентификаторам объектов (выполняется логическая операция пересечения множеств найденных объектов).
Существует специальный язык запросов, определенный для стандартных типов.
Для новых типов данных возможно добавление дополнительных поисковых запросов, однако, по своей природе модули преобразования поискового запроса и модули индексации являются внутренними механизмами сервера, и могут модифицироваться только программистами.
Транзакции и блокировки
В ODB-Jupiter реализован механизм коротких транзакций. Поддерживается блокировка объектов на запись. Технически это осуществляется так: при чтении любого объекта сервер заводит список пользователей, открывших объект на чтение. При закрытии объекта пользователь из этого списка удаляется. Если любой из пользователей начнет выполнять операцию чтения объекта повторно, то сервер интерпретирует данную операцию как захват на редактирование, и, соответственно, пока объект не освободится, доступ других пользователей на редактирование к нему будет запрещен. По завершению редактирования, сервер рассылает уведомления об изменении объекта всем, кто был занесен в список прочитавших. Тем самым обеспечивается поддержка последней версии объекта на всех клиентах и сохранение целостности.
Индекс
Индекс реализуется в виде B+-дерева. Ключом к нему могут служить произвольные данные. При обращении к дереву данные рассматриваются как байтовая последовательность длиной до 255 байт. Индекс может содержать любые численные и символьные ключи. Листья дерева содержат значения, для большинства типов являющихся списками идентификаторов объектов, соответствующих данному ключу. Индексация данных проводится только для тех объектов, у которых указан соответствующий флаг. В зависимости от описываемого классом типа базы, функции индексации могут по-разному интерпретировать данные и помещать различные значения ключа. Простейшие примеры: индексатор для типа TOdbLong помещает в качестве ключа число типа long в двоичном виде, а в качестве значения идентификатор объекта; TOdbString — символьную строку в качестве ключа и идентификатор объекта в качестве значения; TOdbText — отдельные слова текста в качестве ключей (для одного объекта допускаются несколько ключей) и совокупность номеров объектов и номеров слов в тексте объекта в качестве набора значений. Доступ объектов к определенному индексному дереву осуществляется по символьному имени внешнего типа данной разновидности объектов.
Заключение
В статье рассмотрены вопросы внутренней организации ООСУБД Versant, Jasmine и ODB-Jupiter. Объектно-ориентированные СУБД имеют хорошие перспективы для развития [7], обусловленные появлением совершенствованием технологий связи, быстрым развитием Internet, постоянным ростом используемых объемов данных. Возможность гибкой настройки схемы данных, а также способность хранить большое количество объектов делают оправданным применение ООСУБД на крупных предприятиях. Следует также отметить все более и более широкое использование объектного формата XML-документов.
Литература
[1] Андреев А.М., Березкин Д.В., Кантонистов Ю.А. Выбор СУБД для построения информационных систем корпоративного уровня на основе объектной парадигмы //СУБД 1998, № 4-5, сс. 26-50, — М: «Открытые системы», 1998
[2] Андреев А.М., Березкин Д.В., Кантонистов Ю.А. Среда и хранилище: ООБД, «Мир ПК» 1998, №4, сс. 74-81 М: «Открытые системы», 1998
[3] Андреев А.М., Березкин Д.В., Кантонистов Ю.А., Мальцев С.А. Подход к интеграции разнородных СУБД, Компьютерная хроника 1999, №4, — М: Интерсоциоинформ
[4] Андреев А.М., Березкин Д.В., Кантонистов Ю.А., Самарев Р.С. Разработка многопоточного сервера СУБД для Windows NT, Компьютерная хроника 1999, №4 — М: «Интерсоциоинформ»
[5] Андреев А.М., Березкин Д.В., Кантонистов Ю.А., Смирнов Ю.М., Объектно-ориентированная база данных ODB-Jupiter., Приборостроение 1998, №1 — М: Приборостроение
[6] Аткинсон М., Бансилон Ф., ДеВитт Д., Манифест систем объектно-ориентированных баз данных. СУБД 1995, № 4, сс. 142-155, — М: «Открытые системы», 1995
[7] Зильбершац А., Здоник С. Стратегические направления в системах баз данных, СУБД 1997, № 4, сс. 4-23 — М: «Открытые системы», 1997
[8] Питц-Моултис Н., Кирк. Ч. XML: пер. с англ.- СПБ: БХВ-Петербург, 2000
[9] Пржиялковский В., Новые одежды знакомых СУБД. Объектная реальность, данная нам, СУБД 1997, № 4, сс. 88 — М: «Открытые системы», 1997
[10] Саймон А.Р. Стратегические технологи баз данных. — М.: Финансы и статистика, 1999
[11] Фаулер М., Скотт К. UML в кратком изложении. — М.: Мир, 1999
[12] Jasmine. Concepts, Version 1.21.: Documentation. Computer Associates International, 1998
[13] The Object Database Standard: ODMG 2.0. Morgan Kaufmann Publishers Inc., 1997
[14] Versant ODBMS 5.0. C++ reference manual. Versant Object Technology Corp., 1997
[15] Versant ODBMS 5.0. Concepts and usage. Versant Object Technology Corp., 1997
[16] Windows NT ODBMS. Release Notes 5.0.8. Versant Object Technology Corp., 1997
Арк. Андреев (arka@inteltec.ru) — доцент МГТУ им. Баумана, Дмитрий Березкин (dmitryb@inteltec.ru) и Роман Самарев (roman@inteltec.ru) — сотрудники НПЦ «Интелтек Плюс»
| Атрибуты типа | Значение атрибутов типа | Значение атрибутов объекта |
| Название подразделения | Подразделение учета входящей корреспонденции | Нет |
| Название входящего документа | Нет | Постановление правительства № 357 |
| Запрос на уточнение данных о продукте | ||
| Поздравление с праздником |
Разработка приложений с использованием ODB-Jupiter
На основе ODB-Jupiter создана информационно-поисковая система ODB-Text, обладающая универсальной структурой хранимых данных и мощным механизмом поиска. ODB-Text является документо-ориентированной и единицей информации в ней является документ.
 |
Концептуально ODB-Text построена таким образом, чтобы пользователь имел возможность расширения стандартного типа документа без внесения изменений в текст программы. Это стало возможным благодаря механизму внедренных объектов.
Класс TodbTextDocument — потомок TodbObject, соответственно и остальные классы также являются его потомками. Назначение класса TRegisterDocument — хранить описание типа документа, формируемое пользователем. Назначение класса TRubricDocument — хранить документ типа «рубрика» для того, чтобы создать древовидную структуру рубрикатора, хранящего ссылки на все документы. Назначение класса TMDocument — хранить документы, имеющие тип, определенный пользователем. Информационно-поисковая система реализует возможность использования одним клиентом нескольких баз сервера.
Основное назначение такого разделения — разгрузить дисковую подсистему сервера, оптимальным образом разместив базы, нагрузка на которые по числу обращений и объемам данных сильно различается. Документы типа TMDocument располагаются в базе main, документы типа TRubricDocument в базе rubr, документы типа TRegisterDocument в базе config.
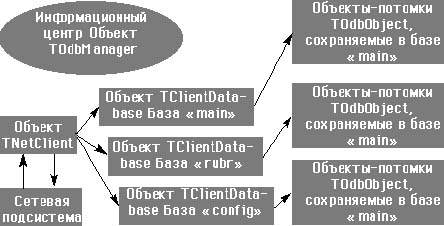 |
Для формирования пользовательского типа данных используется класс TMDocument, унаследовавший от TOdbObject поле TChildren *m_pChildren. Поскольку каждый внедренный объект может иметь свой собственный тип, это используется для создания списка реквизитов документа. Сам список реквизитов формируется в соответствии с записью документа типа TRubricDocument. Каждый реквизит имеет свой собственный номер, хранимый в поле m_dwUniqum. По этому номеру формируется неизменяемое дерево индексов, соответствующее данному реквизиту. Таким образом, обеспечивается возможность свободного добавления и удаления реквизитов любого типа документа.
Реквизиты могут быть как одиночными, так и множественными. Механизм этот основан на внедренных объектах. Из класса TMDocument доступ к своим реквизитам возможен либо посредством обращения по номеру m_dwUniqum реквизита, используя operator[](long), либо по имени реквизита, используя operator [](char*).
Индексация внедренных объектов производится таким образом, что в качестве значения ключа используется идентификатор документа в целом. При этом становится возможным поиск документа по всей совокупности реквизитов.
Для того чтобы обеспечить возможность переноса документов, хранящихся в базе, необходим независимый от хранилища идентификатор. Каждый документ снабжен реквизитом «идентификатор документа», представляющим собой строку, содержащую имя типа документа и его номер.
