

Речь идет об обучающихся программных агентах, выполняющих в Сети рутинные действия по поручению своих хозяев.
Активно взаимодействуя друг с другом, такие агенты способны обеспечить качественно иной уровень сетевых служб.
Развитие агентских сетей в Internet можно рассматривать как появление новой, самоорганизующейся программной среды, в которой все большую роль будут играть самоадаптация и самообучение, постепенно вытесняя жесткий детерминизм современного программного обеспечения. Иными словами, Internet рано или поздно начнет обучаться.
Сеть «для людей»
Сеть в сознании большинства его пользователей ассоциируется с World Wide Web, которая инициировала положительную обратную связь: «больше контента — больше пользователей — еще больше контента». В результате разросшаяся за считанные годы Всемирная паутина объединила практически весь бесплатный «публичный» контент и большую часть компьютерных пользователей. Вслед за профессиональной аудиторией в Internet пришел и бизнес. Экспоненциальный рост взбудоражил умы, и вокруг возникающих как грибы после дождя «доткомов», воцарилась атмосфера нового Клондайка. Сейчас, после нескольких лет Internet-лихорадки, мы наблюдаем отрезвление инвесторов и «похмельный» откат первой волны коммерциализации Сети. Многие громкие начинания не оправдали надежд и вместо прибылей продолжают, в основной своей массе, приносить убытки.
В чем причина неудачного опыта коммерциализации Internet? Среди прочих причин есть и чисто технологическая: недостаточная пока степень интеграции Internet-служб, не позволяющая в полной мере воспользоваться глобальными ресурсами Сети. Принципиальную доступность любой информации через Internet не следует путать с реальными возможностями работы с ней. В итоге и отдача от доступа к глобальному океану информации во многом иллюзорна. Сейчас в принципе доступны почти все информационные массивы, собранные в бесчисленных базах данных, однако, по-настоящему освоен лишь тонкий «поверхностный» слой этой информации. Web содержит сейчас порядка 2,5 млрд. документов, а общий объем подключенных к Сети баз данных составляет примерно 550 млрд. документов. Эти документы выдаются по соответствующим запросам в виде динамических, формируемых на лету, HTML-страниц. Причем 95% этих баз данных находятся в общественном пользовании. Если в Web лежит от 10 до 20 Тбайт текстовой информации, то в базах данных — порядка 7,5 петабайт. (http://www.sims.berkeley.edu/how-much-info/internet.html).
Освоение Сети означает в первую очередь реальную возможность найти нужную информацию. Внешний дизайн страниц в Web и принципы навигации в нем рассчитаны на человеческое восприятие, однако, одновременно эта информация оказывается доступной и роботам, без устали путешествующим по тем же гиперссылкам. «Глубины» же Internet по-прежнему доступны лишь людскому глазу. Люди обращаются с запросами к многочисленным базам данных, получая в качестве ответа динамические HTML-страницы, которые роботам недоступны. Большая часть актуальной коммерческой информации, хранящаяся в корпоративных базах данных, по-прежнему малодоступна для пользователей Сети: доступ-то имеется, но глобальный поиск — отсутствует. В итоге, пользователь (даже оплативший доступ к платным базам данных) вынужден самостоятельно копаться в многочисленных «черных ящиках» локальных баз данных, не имея возможности систематического глобального поиска.
Итак, сегодня Internet предоставляет прекрасные возможности для «тусовки», тогда как адекватные средства работы с наиболее ценной коммерческой информацией в нем отсутствуют. Неудивительно, что коммерциализация Сети идет совсем не такими темпами, какие можно было бы ожидать, глядя на развитие Web.
Сеть «для агентов»
В том или ином виде, но поиск в «глубинной» Сети должен быть автоматизирован. Вместо людей это должны делать роботы-агенты, но совсем не так, как это происходит сейчас. Существующие поисковые серверы стремятся создать у себя единый глобальный индекс, сравнимый по объему со всем гипертекстовым массивом Web. Этот путь тупиковый. Очевидно, собрать воедино и проиндексировать содержание всех баз данных в мире не представляется возможным. Вместо этого можно превратить существующую сеть баз данных в единую распределенную поисковую систему, если хотите, в нейрокомпьютер, объединяющий разрозненные базы, каждую со своей структурой, в единое целое. Естественно, это не простая задача, однако, отнюдь не утопичная.
Первое, важнейшее, условие для создания единой поисковой системы — стандартизация. Надо договориться о стандартах хранения и обмена структурированной информацией. Это отлично понимают идеологи современной компьютерной индустрии. Сюда, например, можно отнести использование XML для описания структуры информации в самых разных областях, в этом же русле лежит и инициатива UDDI (Universal Description, Discovery and Integration), объединяющая усилия Microsoft, IBM, и других компаний по созданию единой XML-спецификации товаров и услуг, а также глобальной системы поиска в Internet поставщиков по заданному профилю.
 |
|
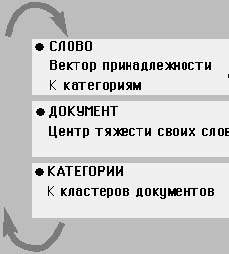
Рис. 1. Алгоритм обучения семантике Bootstrap-алгоритм формирования самосогласованного набора семантических категорий при обучении на коллекции документов |
Однако сама по себе стандартизация еще не решает всех проблем. Возьмем, например, важнейшую задачу поиска в массивах текстовой информации, где стандартизация не проблема. Ведь для полнотекстовых поисковых систем запросом может быть произвольный набор терминов или отрывок текста. И тем не менее, глобальной распределенной полнотекстовой поисковой системы пока не существует.
В действительности, создание распределенной базы данных масштаба Сети, состоящей из многих миллионов узлов, требует решения весьма не простой проблемы маршрутизации поисковых запросов.
Лабиринты «малого мира»
Распределенный поиск информации, рассредоточенной по многим базам данных, предполагает отсутствие единого поискового индекса. Каждая локальная база, обслуживаемая своим поисковым агентом, индексирует свой контент и способна обрабатывать поисковые запросы по нему. Однако для глобального поиска в сети этого явно недостаточно. Что же тогда будет связывать эти локальные базы в единую поисковую сеть? Где должна храниться метаинформация о размещении информации в этой сети, как ни в тех же самых базах данных?
Минимум, необходимый для распределенного поиска, — это адреса поисковых агентов в сети, по которым к ним можно обращаться с запросами. Соответственно, агенты, кроме знания своего контента, должны знать также набор адресов некоторого подмножества других агентов. Тогда любой агент в сети сможет перенаправить запрос другим агентам, если сам не в состоянии полностью его обработать. Чем шире этот набор адресов, тем короче пути до нужной информации.
Если все агенты равноправны и независимы, то кратчайший путь между любыми двумя агентами равен примерно , где N — полное число агентов в сети, а K — характерное число межагентских связей. Эта величина, радиус сети, как видим, слабо зависит от параметров сети. Весьма слабо чувствительна она и к предположению относительно равноправия агентов. В противоположном, крайнем случае полностью централизованной архитектуры с одним агентом-диспетчером, знающим адреса всех остальных агентов, каждый из которых знает, в свою очередь, только о нем, мы получим правильную оценку радиуса (R=2), приняв за характерное число связей среднее геометрическое от числа связей у простого агента и агента-диспетчера, т.е. возможность достичь любой точки даже очень большой сети со случайными связями за относительно небольшое число шагов, известна как эффект малого мира. Например, радиус человеческого общества равен примерно 6 (каждый человек знаком с каждым через цепочку из примерно шести знакомых). Аналогично, исследования показали, что и в научном сообществе ученые связаны друг с другом через цепочку из примерно 6 соавторов (см. www.ncrg.aston.ac.uk/~vicenter/smallworld.html). Иными словами, для того чтобы суметь переправить запрос от любого агента любому другому требуется не так уж и много. Достаточно лишь, чтобы каждый агент знал адреса хотя бы нескольких других агентов и тогда в принципе любой запрос к произвольному агенту сможет достичь того места поисковой сети, где лежит нужная информация.
Дьявол, говорят, кроется в деталях. Если каждый агент знает содержание лишь своей информации, то как он тогда сможет осмысленно переадресовать свой запрос? Просто транслировать его всем известным агентам? Это приведет к лавинообразному размножению запросов. Если же, как это сделано в сети Gnutella, ограничить распространение запроса небольшим числом переадресаций, мы существенно ограничим область поиска. Единственный разумный выход: сделать маршрутизацию запросов в сети направленной. Агенты должны иметь некоторое представление о характере информации у своих соседей, и направлять запросы в соответствии с их содержанием. Таким образом, речь идет об адресации по содержанию, т. е. об ассоциативной памяти.
Для локального поиска агенты могут иметь сколь угодно подробный индекс своего контента, для маршрутизации же запросов им достаточно иметь лишь приближенное, сжатое представление о характере информации у их соседей — понимать ее семантику. Образно говоря, они не должны знать, что конкретно хранится у их соседей, но должны приблизительно «догадываться», о чем это.
Понимание семантики информации — сжатого представления ее содержания — является, таким образом, важнейшим условием создания глобальных распределенных поисковых систем следующего поколения. Это есть та нить Ариадны, которая только и позволит отыскивать нужную информацию в лабиринтах глобальной сети. Поиск в агентской сети должен направляться ассоциативными ссылками агентов друг на друга, подобно тому, как навигацию в «человеческой» World Wide Web делают возможными ассоциативные гиперссылки между HTML-страницами. Только, в отличие от WWW, агенты должны уметь устанавливать такие гиперссылки самостоятельно, без участия человека.
Как научить агентов распознавать содержание текстов, обучить их семантике естественного человеческого языка?
Семантический анализ контента
Нейрокомпьютинг у многих людей ассоциируется с проблемой распознавания образов. В данном же случае мы имеем дело с семантическими образами — чрезвычайно сжатом представлении, по которому невозможно восстановить не только конкретное содержание документа, но даже его лексику. Соответственно, семантический поиск основан не на ключевых словах, а, скорее, на ключевых понятиях. Если лексическое представление документа — это спектр его терминов, то семантическое представление — вектор присутствия в нем семантических категорий. Число этих категорий может быть на несколько порядков меньше числа терминов.
Сжатие информации при переходе от лексического к семантическому описанию документов приводит к ее обобщению, что эквивалентно получению некоторого знания. Ведь возможность более сжатого описания данных опирается на выявлении скрытых в них закономерностей. Семантическое представление информации, соответственно, подразумевает обучение языку, точнее, лишь некоторым его аспектам — закономерностям совместного употребления слов в документах. Но именно эти закономерности и определяют во многом значения слов. Действительно, смысл слова зависит от его употребления и определяется совокупностью всех тех его комбинаций с другими словами, в которых оно встречается в языке.
Основная проблема здесь состоит в том, что при этом мы должны, подобно Мюнхаузену, «приподнять себя за волосы» (английский вариант — «за шнурки ботинок», откуда и происходит название методики bootstrap). Действительно, значение каждого слова определяется его контекстом, состоящим из других слов, значения которых, в свою очередь, определяются их собственным контекстом, включающим и значение данного слова.
Поэтому алгоритм обучения построен на циклической схеме постепенного приближения к оптимальному разложению всех слов по семантическим категориям, отражающему статистику их совместного употребления в обучающей выборке. Оптимальная семантика сохраняет в сжатом виде максимально возможное количество информации о характере употребления слов в языке. Например, поскольку различные словоформы одного и того же слова обычно употребляются в одном и том же контексте, их семантические вектора будут практически совпадать. Поэтому при семантическом поиске мы можем не заботиться о том, в какой именно форме употребляется то или иное слово в искомом документе. То же относится и к синонимам: не важно, какими именно словами выражена та или иная мысль — ее семантическое представление практически не зависит от конкретного выбора терминов.
В итоге, семантическое описание гораздо компактнее лексического. Для тонкой настройки лексического запроса необходимо подобрать обширный набор терминов по данной тематике, используя для его расширения тезаурус языка (сведения о словоформах и синонимах), а также экспертные знания об этих терминах. Семантическое обучение автоматизирует получение всех этих знаний. Обучение семантике любого языка в любой предметной области занимает даже на коллекциях из миллионов документов всего лишь несколько часов времени обычного ПК, т.е. обходится практически даром. В то же время, распознавание смысла текстов позволяет легко настраивать персональные информационные фильтры, т.е. обучать персональных агентов-секретарей. Не удивительно поэтому, что семантические технологии легли в основу многих решений в области автоматической обработки и персонализации информационных потоков. Например, английская компания Autonomy использует подобную технологию для автоматической расстановки гиперссылок между документами в своем продукте Portal-in-a-Box. Другой продукт — Mindwave компании HNCS использует распознавание смысла для обслуживания входящих информационных потоков и запросов от клиентов, например, в центрах телефонного обслуживания. Мы же проиллюстрируем возможности семантического анализа данных на примере продукта российской компании «НейрОК».
Semantic Explorer
Semantic Explorer 2.2 предназначен для автоматической кластеризации документов, рубрикации новых поступлений, навигации и поиска информации в больших текстовых массивах, включая Web. На стадии обучения сервер системы Semantic Explorer 2.2 производит настройку своего семантического блока на «диалект» данного хранилища, выявляя базовые семантические категории. Автоматически формируется аннотированное дерево тематических категорий, по которым раскладываются все имеющиеся в хранилище документы. На стадии эксплуатации вновь поступающие документы автоматически раскладываются по этим тематическим директориям. Клиентская часть комплекса (рис. 2) отображает тематическое дерево слева, а справа — в панели результатов — содержимое документов.
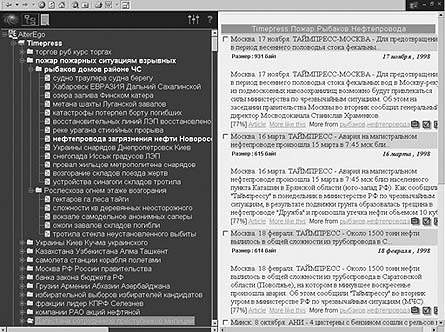 |
| Рис. 2. Иерархическая кластеризация сообщений российских информационных агентств в системе Semantic Explorer 2.2. Слева — полученная в результате самообучения система тематических категорий. Справа — документы из выбранной категории |
Поскольку все документы кодируются точками в семантическом пространстве, для каждого документа можно найти документы, сходные по содержанию. Эти документы могут находиться и в других тематических категориях, поскольку ни одна классификация не в состоянии отразить истинного расположения документов в многомерном семантическом пространстве. Например, ближайшими к документу про аварию на магистральном трубопроводе оказались документы из смежных кластеров, посвященных восстановительным работам и стихийным бедствиям.
Кроме семантического, Semantic Explorer предоставляет и лексический поиск. При этом семантическое дерево позволяет легко различать контекст употребления терминов в различных частях базы данных. Например, поиск по ключевому слову «Чубайс» приносит документы и из категории «Москва РФ России», и из категории «Компании РАО акции», отражающие соответственно деятельность Анатолия Борисовича как политического деятеля и бизнесмена.
Кроме привычного «одномерного» отображения дерева тематических каталогов, в Semantic Explorer 2.2 реализованы и двумерные самоорганизующиеся карты, дающие наглядное представление об объеме и относительном расположении различных тематических кластеров. Навигация по коллекции в этом случае напоминает полеты в виртуальных галактиках документов (рис. 3).
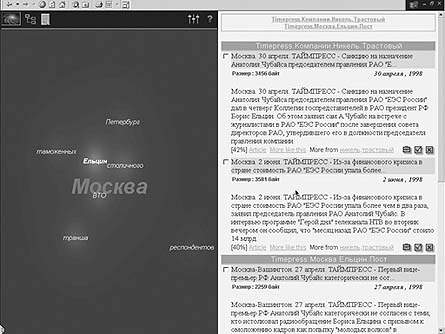 |
| Рис. 3. Галактики документов из смежных кластеров |
Встроенный в Semantic Explorer робот, выкачивающий и разбирающий содержимое HTTP-страниц по заданному сценарию, позволяет реализовать автоматический мониторинг выделенных подмножеств Сети.
Сеть семантических агентов
Итак, мы убедились, что можно автоматически формировать очень емкое, семантическое описание содержания текстовых баз данных (семантический индекс обычно не превосходит 5% от объема базы данных). Это позволяет как людям, так и поисковым агентам понять, о чем говорится в данной коллекции документов. Пользователи получают средство наглядной навигации по базам данных, а также возможность задавать нечеткие поисковые запросы «по подобию». Поисковые агенты — возможность целенаправленного поиска информации в базах данных при наличии у них соответствующего семантического индекса.
Семантическая индексация позволяет, таким образом, создавать распределенные хранилища информации, масштабируемые до размеров глобальной Сети. Их можно реализовать в виде сети адаптивных поисковых агентов, каждый из которых обслуживает поисковые запросы по своей локальной информации, и знает каким агентам в случае надобности лучше переадресовывать такие запросы. При этом он ведет подробный индекс своей собственной информации и имеет сжатое представление о характере информации у своих соседей по поисковой сети. Подобного рода поисковая сеть из миллионов тематических поисковых серверов сможет обеспечить качественно иной уровень информационного обеспечения в Internet.
Навстречу машинному обучению Internet
Internet сегодня по-прежнему находится в стадии становления. Поисковые серверы индексируют лишь поверхностный слой доступной информации, нет справочно-поисковых служб, объединяющих многочисленные базы данных Сети. Доступ к коммерческой информации Internet не автоматизирован.
Ключом к освоению информационного океана Internet могут стать технологии машинного обучения. Направленный поиск в Сети подразумевает наличие сжатого, приближенного представления о характере информации в ее узлах. Это представление возникает в результате обучения семантике языка, позволяющей идентифицировать тематику документов.
Электронный бизнес современных порталов, заимствуя у телевидения модель вещания, не использует в полной мере потенциал Internet как программируемой сетевой среды распространения информации. Агентское ПО может кардинально улучшить ситуацию с коммерциализацией Сети. Кстати, косвенным свидетельством нарастающей роли машинного обучения в Internet служит рост котировок лидеров этого направления на фоне падающего индекса NASDAQ.
Сергей Шумский (shumsky@neurok.ru) — сотрудник компании «НейрОК» (Москва)
