
В последние годы компьютерные устройства все чаще используются в качестве платформы для встроенных систем, предоставляющих новые и перспективные услуги, и разнообразие применений вычислительной техники поражает воображение даже по сравнению с тем, что было всего десять лет назад. Разработчикам предоставлен широчайший выбор аппаратного обеспечения, операционных систем и инструментария для создаваемых ими встроенных систем.
Подобное разнообразие платформ и инструментов - одновременно и благо, и бич разработчиков. С одной стороны, можно выбрать именно те инструменты и услуги, какие требуются тому или иному приложению. С другой стороны, найти самые подходящие продукты среди окружающего изобилия становится весьма затруднительно.
Несмотря на все различия, встроенные системы обладают рядом важных свойств, которые объединяют их с настольными и серверными системами, на место которых они зачастую приходят. Так как встроенные системы взаимодействуют с пользователями или пользовательскими средами, им нужны средства ввода/вывода. Многие встроенные системы выполняют сразу несколько задач, поэтому для диспетчирования и управления этими задачами они должны быть оснащены операционной системой определенного рода. Нередко встроенные системы должны иметь сложные службы управления базами данных.
Стратегия выбора инструментария баз данных для встроенных систем должна разворачиваться вокруг требований приложения. Различия между встроенными базами данных различных производителей очень велики. Одни не соответствуют всем требованиям определенного приложения, другие предоставляют значительно более широкие возможности. Тщательно проанализировав многочисленные варианты выбора, можно выбрать инструмент, подходящий по всем параметрам.
Выбирая операционную систему, аппаратную платформу и программное обеспечение баз данных для новой встроенной системы, имеют в виду необходимость создания системы, способной надежно работать при минимальном вмешательстве человека или вообще без него. В отличие от настольных и серверных систем, встроенные системы не могут «потребовать» вмешательства оператора, если при выполнении приложения возникает проблема.
И, наконец, существенное значение имеет скорость. Учет соображений производительности на этапе разработки, равно как и ее оценка для уже разработанного приложения имеет критическое значение. К счастью, существует немало методов оценки и повышения производительности для баз данных.
Итак, для разработки наилучшего решения, основанного на встроенной базе данных, необходимо выбрать продукт, оптимально соответствующий специфическим требованиям приложений и интегрировать его в это приложение. Начинать этот процесс необходимо с оценки служб, реализуемых встроенными устройствами.
Службы баз данных
Поскольку встроенные устройства включают очень широкий спектр служб, различные встроенные системы предъявляют различные требования к используемым базам данных.
Для некоторых встроенных систем старшего класса нужны масштабируемые службы обработки транзакций с высокой степенью распараллеливания. Подобные системы признанные поставщики баз данных для настольных и серверных платформ предлагают уже не один год. Тем не менее, известные реляционные базы данных редко подходят для встроенных систем в силу целого ряда причин.
Реляционные базы данных масштаба предприятия опираются на хорошо изученные методы обработки транзакций. В качестве примера можно привести протоколирование с упреждением, при котором запись до и после изменения фиксируется, таким образом можно совершить откат по отношению к этому изменению или при необходимости применить его корректно. Другим примером служит двухфазная блокировка, при которой значение остается заблокированным до тех пор, пока не будут завершены все изменения, чтобы в этот момент какой-либо другой пользователь не мог также внести в них изменения. В некоторых встроенных базах данных эти механизмы используются для реализации масштабируемых и надежных служб обработки транзакций, но в значительно более компактном виде по сравнению с реляционными базами данных уровня предприятия. В ряде встроенных систем полноценные средства восстановления после сбоев не требуются; нужны только сравнительно скромные средства распараллеливания и поддержка не слишком больших объемов данных. Другие не рассчитаны на поддержку нескольких одновременно работающих пользователей и не нуждаются в специальных средствах обработки транзакций, их главный приоритет - высокопроизводительная подсистема хранения данных.
Разумеется, производители баз данных стремятся продать свои продукты как можно большему числу пользователей. Многие встроенные базы данных предоставляют возможности конфигурирования, благодаря которым разработчики могут включать или удалять отдельные службы, такие как протоколирование с упреждением или двухфазная блокировка, в зависимости от требований того или иного приложения.
Базы данных для встроенных систем
Многочисленные встроенные операционные системы работают на поражающем своим разнообразием спектре аппаратных платформ. Поэтому выбрать хорошее ядро баз данных для встроенного приложения значительно труднее, чем проделать тот же выбор для настольной или серверной системы.
На сегодняшний день создатели встроенных операционных систем не далеко продвинулись в области стандартизации интерфейса. Усилия по стандартизации, предпринимаемые группой EL/IX при спонсорской поддержке Red Hat, нацелены прежде всего на то, чтобы поставить Linux-подобный интерфейс POSIX 1003.1 в привилегированное положение по отношению к другим встроенным систем. Однако стандарту не хватает подкрепленных им приложений и заинтересованности производителей операционных систем. Разработчикам баз данных приходится прилагать неимоверные усилия для переноса своего программного обеспечения на платформы, которые используют их потенциальные заказчики. В итоге, многие встроенные операционные системы попросту не поддерживают никаких средств управления базами данных коммерческого уровня.
Скорее всего, «повесть» о платформах со временем станет более оптимистичной. Сейчас на рынке встроенных операционных систем доминируют несколько коммерческих продуктов, в том числе Microsoft Windows CE, VxWorks компании Wind River Systems и Neutrino, разработанная компанией QNX. Хотя пока встроенные системы на платформе Linux завоевали небольшую долю рынка, есть все основания полагать, что у этой технологии хорошие перспективы на рынке встроенных систем. Консолидация производителей операционных систем и давление отрасли, направленное на стандартизацию интерфейсов, приведут к созданию большего числа качественных инструментов для разработчиков встроенных систем.
Рынок встроенных баз данных будет расти по мере роста рынка встроенных систем. Положение на нем резко контрастирует с положением на рынке настольных систем и серверов: здесь нет ярко выраженного лидера. Появление новых возможностей, будет стимулировать новые и известные компании, занимающиеся разработкой ПО управления базами данных, вкладывать солидные средства в выпуск новых продуктов и завоевание прочного положения на этом рынке. В долгосрочной перспективе, создатели встроенных систем получат разнообразный инструментарий разработки баз данных.
К несчастью, разработчики, в большинстве случаев лишены такой роскоши, как возможность думать лишь о долгосрочной перспективе. Тем (а их большинство) кому нужно предложить продукт уже сейчас, надо тщательно выбирать продукт, в точности отвечающий их требованиям. К тому же нужно весьма осторожно относиться к маркетинговым заявлениям разных фирм, поскольку, например, различные производители подразумевают под терминами «встроенные системы» и «встроенные базы данных» иногда совершенно неожиданные вещи.
Классификация баз данных
В таблицах 1, 2 и 3 приводятся сравнительные характеристики встроенных баз данных различных производителей. Они несколько произвольным образом подразделены на реляционные клиент-серверные продукты (они сведены в таблицу 1), объектно-ориентированные клиент-серверные продукты (таблица 2) и встроенные библиотеки, которые не требуют обязательной серверной обработки (таблица 3). Каждая категория имеет свои преимущества и свои недостатки и пользуется большей или меньшей популярностью в силу различных причин. Все перечисленные продукты, за исключением одного, библиотеки gdbm, описанной в таблице 3, поддерживают обработку транзакций и — в некоторой степени — параллельный доступ.
Производители клиент-серверных реляционных систем. Некоторые производители, например те, что перечислены в таблице 1, предлагают клиент-серверные реляционные системы. Такие компании, как Microsoft, Oracle, Sybase и Informix продают достаточно дорогие СУБД уровня предприятия и ядра баз данных этих продуктов разработчикам встроенных систем. Клиент-серверные реляционные продукты пользуются весьма большой популярностью, так как многие программисты уже хорошо знакомы с языком запросов SQL (Structured Query Language) и структурой реляционных баз данных. Основным недостатком клиент-серверных систем следует считать увеличение времени обработки, связанное с необходимостью связанных с определенными издержками коммуникациями между клиентом и сервером, а также дополнительную сложность установки, запуска и сопровождения независимого серверного процесса для встроенной системы.
Производители клиент-серверных объектно-ориентированных систем. Другая категория производителей, например те, что перечислены в таблице 2, обогащают рынок встроенных систем своим опытом в области разработки объектно-ориентированных баз данных. Продукты этих компаний, как представляется, хорошо подходят для применения во встроенных системах, однако именно их рассматривают в этом качестве крайне редко. С чем это связано? Дело в том, что наиболее популярные объектно-ориентированные базы данных разработаны для Unix-систем, поэтому в них глубоко «въелись» соответствующие особенности системы управления памятью и поведения процессов при установлении связи друг с другом. Перенос этих продуктов с одной архитектуры на другую связан с большими сложностями. Возможно, они еще проявят себя в среде ОС Linux или каких-либо иных разновидностей Unix, таких как FreeBSD, которыми оснащают ряд классов встроенных устройств.
Объектно-ориентированные базы данных популярны благодаря глубокой интеграции в них языков программирования C++ и Java, а также и потому, что сложность схемы такой базы данных порой глубоко скрыта от прикладного программиста. Их основным недостатком для рынка встроенных систем является чрезмерная загрузка, которую создают коммуникации между клиентом и сервером, и недостаточное количество поддерживающих их встроенных систем.
Производители встроенных библиотек. Производители, список которых приведен в таблице 3, разрабатывают свои продукты исключительно для встроенных систем. Все эти системы работают непосредственно в адресном пространстве приложений, которые их используют. Они предоставляют простой прикладной интерфейс на уровне языков программирования, который не требует применения механизма SQL-запросов для манипулирования данными. Основные преимущества встроенных библиотек состоят в том, что они обеспечивают:
- более быстрое выполнение так как операции с базой не предполагают установления связи с независимым сервером;
- повышенную надежность, обусловленную сокращением числа работающих во встроенной системе компонентов.
Однако библиотеки имеют очень серьезный недостаток: для поддержки нестандартных программных интерфейсов требуется вмешательство разработчика.
Выбор встроенной базы данных
Выбирая ядро базы данных для встроенной системы, необходимо иметь в виду несколько критериев.
Поддерживаемые платформы
Прежде всего, и это надо особо отметить, выбор платформы определяет многие последующие варианты выбора. Так, например, если предполагается, что встроенная система будет работать под управлением ОС Linux или VxWorks на компьютере с процессором Pentium и обычным магнитным диском, появляется возможность выбирать из числа нескольких баз данных.
Выбор же тех решений, которые используют менее популярные встроенные операционные системы, которым требуется работа более чем одной операционной системы, или тех, кто использует экзотические процессоры и память, в значительной степени ограничен. Производители встроенных операционных систем, как правило, ведут списки компаний-партнеров, продукты которых работают на их операционных системах. Некоторые распространяют свои программные продукты в исходных текстах, так что разработчики могут самостоятельно переносить их на новые платформы и новые процессоры. Для менее распространенных платформ, которые в меньшей степени поддерживаются производителями, это обстоятельство может оказаться весьма немаловажным.
Требования к ресурсам
Необходимо также учитывать нагрузку на ресурсы, которую создают встроенные системы. Имеет ли существенное значение объем памяти, занимаемый приложением? Будет ли система поддерживать клиент-серверную базу данных, или база данных должна быть действительно «встроенной» в адресное пространство приложения? Как правило, базы данных, распространяемые в виде библиотек, компактнее, чем поставляемые в виде независимых двоичных файлов.
Оценка производительности
Поддержка распараллеливания и масштабируемость являются в данном случае первостепенными критериями. Будут ли многочисленные управляемые параллельные потоки, поддерживаемые приложением, одновременно обращаться к базе данных? Насколько велика может быть база данных?
Некоторые системы были изначально рассчитаны на поддержку одновременно работающих пользователей и большие базы данных; другие нет. Масштабируемые продукты часто вступают в конкуренцию с продуктами младшего класса, которые поддерживают небольшое число пользователей и небольшие объемы данных. Обратное, однако же, неверно.
Рассматривая продукты с точки зрения масштабируемости, необходимо с большой осторожностью подходить к заверениям производителей, и всегда убеждаться, что продукт реально работает так же, как про него говорят. Разработчики настольных и серверных систем могут полагаться на результаты тестирования той или иной отраслевой организации, как правило, достаточно полно характеризующие базы данных. Разработчики встроенных систем такой возможности лишены. Оценка реальной производительности, тем не менее, имеет решающее значение, поскольку для встроенных систем — это самая значимая оценка. Большинство производителей встроенных систем предоставляют свои продукты для оценки бесплатно, таким образом, разработчики могут воспользоваться этим.
Требуемые службы
После того как выбрана работающая на целевой платформе база данных, которая соответствует требованиям к памяти и которая способна поддерживать требуемую нагрузку, необходимо определить, какие службы действительно необходимы для создаваемой встроенной системы.
Будет ли база данных использоваться только одним потоком управления или их будет больше одного? Если система не требует распараллеливания задач, приложение будет работать заметно быстрее, если отказаться от блокировок. Некоторые базы данных работают без блокировок или позволяют отключать их.
Необходимы ли специальные средства автоматизированного восстановления после сбоев? Некоторые встроенные базы данных просто воссоздают базу данных по вспомогательной версии всякий раз при запуске. Другие должны обладать устойчивостью к неожиданным остановам и рестартам. Если восстановление имеет принципиальное значение, следует выбрать систему, которая предоставляет такую службу. Если возможности восстановления не столь важны, можно остановить свой выбор на системе, которая не предоставляет этой службы или допускает возможность ее отключения, добившись, таким образом, ускорения работы.
Цена
Продуктов, соответствующих всем техническим требованиям, может быть не один и не два. В этом случае решающим аргументом для выбора становится, конечно, цена.
Несколько популярных встроенных баз данных распространяются бесплатно на определенных условиях. Даже некоторые коммерческие продукты можно получить бесплатно, поскольку их производители исходят из того, что, предоставив вам свою программу бесплатно, им впоследствии удастся предложить вам за деньги свои услуги и другое программное обеспечение.
Те же производители, которые взимают плату за свои продукты, могут придерживаться самой гибкой политики ценообразования. Как правило, в цену входит фиксированная оплата труда разработчиков, принимавших участие в создании программного обеспечения базы данных, для каждого приложения, встроенного в нее или для каждой платформы, на которой она используется. Многие производители отказываются от лицензирования по фиксированным расценкам, предлагая вместо этого выплаты в пересчете на копию или на пользователя. Впрочем, такие методы ценообразования менее характерны для рынка встроенных систем, нежели для других рынков.
Необходимо отдавать себе отчет в том, когда в действительности происходит оплата программного обеспечения. Некоторые производители предпочитают назначать цену за использование при разработке, в то время как другие устанавливают платежи на этапе использования готовой встроенной системы.
Самым надежным способом определить действительную стоимость той или иной базы данных являются переговоры с производителем. Политика ценообразования настолько многообразна, что сравнить продукты по стоимости можно, только реализовав их в рамках конкретного решения и сопоставив расходы.
Проектирование приложения
Когда поставлена точка в выборе встроенной базы данных, начинается не менее захватывающий процесс — процесс разработки такой встроенной системы, которая обеспечивала бы максимальную эффективность работы базы данных. Для того чтобы осуществить эту задачу, необходимо учесть такие соображения, как надежность, скорость и предсказуемость. Пользователи должны быстро получать правильные ответы на свои запросы и не должны страдать от сбоев или непредсказуемых результатов.
Скорости
Для того чтобы гарантировать быструю реакцию базы данных на запросы и обновления, ее необходимо с самого начала правильно сконфигурировать. Главными вопросами здесь являются структура данных и выделение необходимых ресурсов. При проектировании базы данных необходимо принять как минимум три принципиальных решения.
Представление данных. Если приложение и база данных используют различные представления для хранимых и обрабатываемых величин, каждая выборка и каждая операция записи в память будут требовать трансляции. Большинство встроенных баз данных оперируют с фиксированным числом типов данных в записях, формат которых диктуется особенностями ядра баз данных. Так, например, для типичной базы данных структуры языка Си или значения атрибутов Java-объектов необходимо будет преобразовать в записи, содержащие целые числа, даты, цепочки символов и другие известные типы данных. Только несколько баз данных (как правило, это библиотеки) поддерживают хранение данных в их естественном формате, без преобразования в формат базы данных. В этом случае трансляции не требуется.
Шаблоны доступа. Данные должны всегда оставаться вне «поля зрения» приложения, которое получает доступ к ним посредством запросов. Должны ли записи быть отсортированы по некоторому ключу? Могут ли приложения выбирать ключи, с тем чтобы требуемые ему записи (те, которые с большей вероятностью понадобятся приложению) размещались физически ближе друг к другу в базе данных?
Большинство ядер баз данных поддерживают хранение в виде В-дерева, в некоторых реализованы такие структуры, как хеш-таблицы. Считается неоспоримым, что В-деревья обладают более высокой производительностью, чем хеш-таблицы, поскольку в этом случае формируется кластер данных на физическом уровне, благодаря чему можно использовать местные ссылки со смежными ключами.
Кроме того, необходимо иметь в виду, что приложение будет выполнять поиск и обновление данных, и понимать физическую структуру хранения, которую обеспечивает база данных. Физически данные можно сгруппировать только по ключу. Если предполагается, что в приложении понадобится осуществлять поиск более чем по одному ключу, надо рассмотреть возможность определения вторичных индексов для дополнительных ключей поиска. Решая эту задачу, разработчик сталкивается с классической дилеммой информатики: стоит ли добиваться более быстрой работы программы за счет дублирования некоторой части данных, т. е. ценой расходования большего объема памяти.
Конфигурирование. Встроенные базы данных допускают конфигурирование с большей или меньшей степенью детализации. В числе традиционных параметров конфигурации - объем памяти, используемый вторичным кэшем, порядок хранения (запись данных на диск или просто хранение в памяти), уточнение способов, которыми разрешено накладывать блокировки на объекты. Реже встроенные системы позволяют включать или выключать целые подсистемы — такие как блокировки или ведение протокола — в зависимости от требований приложения. Однопользовательские базы данных не требуют блокировки. Приложения, предполагающие полное воссоздание базы данных при запуске, не требуют ведения протокола для обеспечения сохранности данных на случай сбоя.
Различные производители предлагают весьма многообразные возможности управления конфигурацией. Необходимо уяснить для себя, каково должно быть поведение базы данных и тщательно проработать конфигурацию. Как правило, следует отключить все ненужные подсистемы для экономии времени и повышения скорости работы.
Далее необходимо определить, какое пространство занимают записи базы данных и каков, соответственно, размер кэшей. Встроенные приложения отличаются большим разнообразием требований, а производители баз данных нередко предлагают совсем не те подразумеваемые установки, которые актуальны в большинстве случаев.
Простота прогнозирования
Встроенные системы должны работать без вмешательства человека. Например, если предполагается использовать их, скажем, там, «куда не ступала нога человека», или если их предполагаемые пользователи вообще на должны знать, что имеют дело с компьютером. Поэтому прогнозирование поведения встроенной системы гораздо более важно, чем прогнозирование поведения настольного решения, адресованного конечному пользователю.
Следует собрать все свое внимание, проверяя такие характеристики приложения, как контрольные признаки и другие индикаторы ошибок, тем чтобы можно было обеспечить их распознавание и восстановление при сбое без вмешательства извне. Например, если процедура записи обрывается из-за недостатка памяти, приложение должно иметь возможность «почистить» память, с тем чтобы завершить операцию записи. Если что-то происходит с сетевым соединением, система должна прозрачно перенаправить клиента на другое соединение.
Разрабатывать системы, ориентируясь прежде всего на предсказуемость их поведения, очень непросто, поскольку сбои при обработке запросов к базам данных могут происходить по целому ряду на первый взгляд необъяснимых причин. Тип сбоя зависит от того, какая используется база данных, и от того, как приложение ее использует. Среди примеров — транзакции, вызывающие неразрешимый конфликт ресурсов, создающие тупиковые ситуации и некорректные копии данных, а также другие ошибки элементов данных.
Сбой в работе базы данных может произойти, когда исчерпаны ресурсы. Неправильное управление системными ресурсами — распространенная ошибка, особенно часто разработчики не справляются с динамическим выделением и высвобождением памяти. Встроенные приложения могут работать очень продолжительное время, поэтому даже незначительные утечки памяти способны привести к исчерпанию доступной памяти. С точки зрения конечного пользователя, приложение начинает работать все медленнее и медленнее, а потом и вовсе останавливается. Отслеживание выделяемых ресурсов и их немедленное высвобождение в традиционных базах данных позволяет предотвратить исчерпание ресурсов.
Однако использование встроенных баз данных усложняет управление ресурсами. Если библиотека баз данных выполняет сложное выделение ресурсов и управление ими, программист должен быть уверен, что код приложения «понимает» поведение библиотеки. В состав многих библиотек входят альтернативные средства управления ресурсами, такие как пул описателей файлов или системы управления памятью, отличающиеся от аналогичных систем, предоставляемых операционной системой. Поэтому вызов функции операционной системы для высвобождения блока памяти может вызвать серьезную ошибку, если специализированная подсистема выделения памяти уже использовала этот блок.
Для того чтобы система быстро реагировала на запросы и обновления, ее необходимо корректно сконфигурировать с самого начала. С точки зрения конечного пользователя предсказуемость означает способность системы продолжать работу в течение долгого времени без «ручного» администрирования. Из этого следует, что система не выполняет резервного копирования, процедур восстановления и периодической реорганизации. Если для отслеживания изменения используется системный журнал, необходимо иметь гарантию того, что база данных периодически возвращает ненужные точки входа в журнал. Если база данных должна восстанавливаться после сбоя системы, приложению следует посылать предупреждение о том, что требуется восстановление, и необходимо предпринять необходимые действия, прозрачные для пользователя.
Выбор подходящей базы данных — ключ к решению задачи отчуждения администрирования. Для конкретного приложения необходимо решить, какие потребуются службы. Допустимо ли, чтобы изменения терялись в случае сбоя? Если это не так, то база данных, скорее всего, потребует выполнения процедуры восстановления при запуске после аварийного завершения. На этот случай должна быть предусмотрена возможность вызова системы восстановления из приложения без вмешательства конечного пользователя.
Настройка производительности
Почти все базы данных имеют одни и те же узкие места с точки зрения производительности. Известны три наиболее распространенных причины низкой производительности приложений со стороны баз данных: это два или более потоков управления, одновременно обращающихся к часто используемым данным, передача данных из памяти на диск и тупиковые ситуации.
Обращение к часто используемым данным
Большинство баз данных на время обработки блокируют используемые данные. Блокировки на чтение, как правило, носят разделяемый характер, в то время как блокировки на запись — исключительный. Если несколько потоков управления пытаются обратиться к одному объекту базы данных одновременно, и один из этих потоков имеет исключительные права на доступ, ему, тем не менее, придется ждать, когда завершится предыдущая обработка.
Потребность в недостающих ресурсах служит причиной проблем с производительностью. Независимо от того, чего ждет приложение — диска, заблокированного объекта или права на добавление записи в журнал, сокращение числа одновременных обращений — наилучший путь для повышения производительности.
Системные метаданные, описывающие содержимое и структуру таблиц и записей имеют, как правило, оперативный характер, поэтому большинство производителей баз данных обрабатывают их особым образом. На них накладывается значительно меньше исключительных блокировок, чем на другие, а немногие исключительные блокировки снимаются так рано, насколько возможно: все это должно служить повышению производительности системы.
Совместно используемые структуры, которые координируют многочисленные потоки и процессы, также могут служить причиной конфликта. Блокировки, как правило, защищают пулы буферов, например, однако, коммерческие системы разработаны так, чтобы эти блокировки действовали только очень короткое время. В результате, потребность в относительно небольшом числе записей, хранящихся в определенной приложением таблице, порождает конфликты.
Если приложение часто простаивает в ожидании снятия блокировок, наложенных другими транзакциями, вероятно, база данных содержит «горячие» данные. Если база данных поддерживает блокировки на уровне записи, можно использовать их для уменьшения числа конфликтных ситуаций. Другим решением может стать использование страниц меньшего размера. Это, конечно, паллиативное решение, но и оно дает удовлетворительные результаты. Меньшие страницы содержат меньше записей, поэтому блокировки на уровне страниц, которые накладывает база данных, действуют почти так же, как и блокировки на уровне записи.
Можно попытаться изменить приложение так, чтобы оно обращалось к оперативным данным в последнюю очередь и удерживало блокировки меньшее время, что также будет сокращать возможные конфликты.
Передача данных с диска в память
Перемещение данных с диска в память также служит узким местом систем с точки зрения производительности. Задержки зависят от электромеханических свойств дисковода, и снижение задержек часто требует больших усилий и немалых средств. Разработчики баз данных, как правило, пытаются обойтись наименьшим возможным количеством операций чтения-записи, там же, где эти процедуры обязательны, они выполняются последовательно. При разработке встроенных систем, можно выбирать из очень большого числа аппаратных платформ. В большинстве систем для хранения используются традиционные магнитные диски. Впрочем есть и такие, где долговременное хранение данных реализуется более экзотическими технологиями, например, флэш-памятью. Устройства флэш-памяти, благодаря которым данные в быстрой памяти не разрушаются даже при остановах системы и перезапусках, позволяют встроенной системе обойтись вообще без доступа к диску. Такие системы обладают оптимальной страничной структурой и при доступе к данным используются более крупные блоки памяти с одинаковым временем доступа. Это значительно эффективнее, нежели страничный доступ, необходимость в котором диктуется архитектурой хранения на базе вращающегося диска.
Удивительно, но ни один из известных поставщиков встроенных баз данных не предлагает подобного подхода. TimesTen, упомянутая в таблице 1, работает непосредственно в оперативной памяти, однако эта система предоставляет только ограниченную поддержку встроенным операционным системам. Но даже в TimesTen предусмотрены принудительные операции записи на диск для обеспечения постоянного хранения.
В большинстве встроенных систем магнитный диск играет роль резервного хранилища данных для записи информации в память. Можно реализовать манипуляции с данными полностью в памяти, без резервного хранилища, при этом доступная память должна быть достаточно большой для хранения базы данных целиком. В нескольких встроенных базах данных вместо магнитного диска в случаях необходимости используется оперативная память на устройствах флэш-памяти. В этой статье речь шла, в основном, о настройке производительности для передачи данных из диска на память, но все высказанные рекомендации в равной мере относятся и к передаче данных из памяти в оперативную память на устройствах флэш-памяти.
Как правило, система требует выполнения операций чтения/записи на диск при возникновении проблем с конфигурацией аппаратного обеспечения или в шаблоне доступа к данным, используемом приложением. Как правило, базы данных используют оперативную память как буфер для данных, которые обычно размещаются на диске.
При наличии достаточных ресурсов, программисты стремятся реализовать кэш такого объема, чтобы он поддерживал доступ к большинству страниц, не требуя подкачки данных с диска. Если памяти недостаточно, буфер будет «освобождаться» от некоторых страниц в процессе нормальной работы, поэтому, когда они понадобятся в следующий раз, их придется считывать заново.
Таким образом, система должна иметь достаточно большой буфер, чтобы хранить в нем все наиболее часто используемые страницы. Отказ от записи в кэш и частые подкачки - это сигнал о том, что он слишком мал для хранения всего «подручного» набора данных приложения. Разумеется, определенный объем операций ввода/вывода неизбежен, однако, в целях лучшей настройки производительности необходимо свести к минимуму число операций чтения и записи на диск.
Если процент попаданий в кэш низок, стоит рассмотреть возможность увеличить объем кэша. Какую величину считать низкой зависит от приложения, однако разумная цель, к которой следует стремиться — чтобы как минимум половина запросов приходилась на кэш-память.
Для увеличения процента попаданий в кэш можно также убедиться, что запросы и данные имеют одинаковые «шаблоны» размещения. Если приложение производит поиск данных по дате, и если обращение к одной дате с высокой вероятностью сопровождается обращением к нескольким близким датам, следует упорядочить записи в виде таблицы В-дерева. Тогда близкие даты в памяти будут размещаться также недалеко друг от друга, поэтому запросы будут обращаться к меньшему числу страниц. Впрочем, и этот принцип не лишен изъянов. Если из-за необходимости найти ссылку многочисленные потоки управления будут конкурировать за близкорасположенные записи, конфликт ресурсов может вызвать еще большее снижение производительности.
Если производится периодическое сканировние всей таблицы в поисках нужной записи, лучше создать индекс таблицы, благодаря которому приложение сможет быстрее получить искомые записи. Так, если таблица, предоставляемая клиентской системой, отсортирована по значению идентификатора, но поиск часто осуществляется по фамилии, нужно создать вторичный индекс, который упорядочивает таблицу по фамилии. Индексы систематизируют данные для ускорения просмотра по конкретному ключу, что может существенно сократить число обращений к подсистеме ввода/вывода.
Тупиковые ситуации
В большинстве баз данных используется механизм двухфазных блокировок, который гарантирует, что изменения, вносимые одним пользователем, не приведут к искажению результатов работы для другого пользователя. Каждый поток управления накладывает блокировку во время выполнения транзакции. Блокировка удерживается до тех пор, пока транзакция не завершена, после чего она немедленно снимается. На рисунке 1 представлена схема образования тупиков (deadlock) при двухфазной схеме работы, когда многочисленные потоки управления конкурируют за блокировку одного и того же объекта.
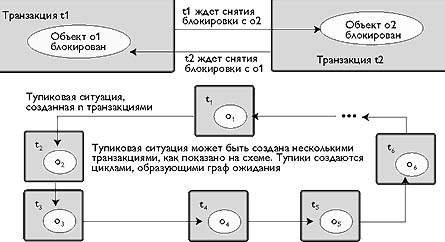 |
| Рис. 1. Тупиковая ситуация, возникшая при двухфазной блокировке Хотя этот метод предоставляет то преимущество, что изменения, вносимые параллельно работающими пользователями не искажают результатов друг друга, двухфазная блокировка может приводить к тупиковым ситуациям, когда несколько потоков конфликтуют за доступ к одному и тому же объекту |
Два источника. Если два потока управления блокируют один и тот же объект в разном порядке, каждый может оказаться вынужден ждать, пока другой не снимет блокировку. В этом случае ни один не может продолжать работу, в результате чего возникает тупиковая ситуация. Аналогично, если два потока управления разделяют блокировку одного и того же объекта, и оба пытаются преобразовать ее в исключительную блокировку, ни один не может завершиться, пока другой не освободит разделяемый ресурс. Результат тот же - тупик.
Все базы данных, в которых есть опасность возникновения тупиковых ситуаций, имеют механизмы для их обнаружения. Как правило, это прерывание одного потока управления, который вызывает подобную ситуацию и предоставление другому права на завершение работы. По всем изменениям, которые внес прерванный поток управления, осуществляется откат. Если приложение создает много тупиковых ситуаций, возникает много потоков, которые начинают работать, фактически, только для того, чтобы внести изменения, которые будут отменены при очередном откате. Проделанная ими работа пропадет впустую, отчего пострадает производительность системы.
Несколько возможных решений. Во встроенной системе полного устранения тупиковых ситуаций можно добиться простым отключением подсистемы блокировки. Если такая возможность поддерживается базой данных, и если это позволяет приложение, такое решение ускорит обработку. Если в системе работают однопользовательские приложения, а также многопользовательские приложения, в которых предполагается выполнение только операций чтения, можно смело отключать блокировки.
Если отключить блокировки невозможно, необходимо, насколько это возможно, уменьшить размер транзакций. Если приложение предполагает выполнение одной весьма продолжительной транзакции, следует попытаться разбить ее на несколько транзакций меньшего размера. Тогда каждая из них будет быстрее снимать блокировки, снижая вероятность их конфликта с блокировками от других транзакций.
Менее очевиден, однако, более эффективен другой выход — добиться того, чтобы все транзакции осуществляли блокировки в одном порядке. Тупиковые ситуации возникают в том случае, когда одна транзакция блокирует объект А и требует доступа к объекту В, в то время, как другая транзакция блокирует объект В и обращается к объекту А. Если написать программу так, чтобы транзакции обращались к объектам и осуществляли блокировки в одном и том же порядке, подобные тупики станут невозможны.
Другой продуктивный метод состоит в осуществлении предварительных корректных блокировок. Многие встроенные базы данных позволяют приложению определять блокировки, которые предполагается наложить на то или иное значение до того, как приложение реально получит к нему доступ. Если приложение считывает некую величину, которую впоследствии предполагает записывать, оно не сможет модернизировать блокировку на чтение до блокировки на запись, если за это время другой пользователь также наложил блокировку на чтение. Чтобы выйти из положения, приложение должно наложить блокировку на запись еще до того, как оно начнет реально осуществлять ее. При этом другой пользователь не сможет получить доступа к этому объекту в течение более продолжительного времени, что чревато конфликтом ресурсов, однако, таким образом устраняются тупиковые ситуации. Конфликт ресурсов не столь губителен для производительности, как тупиковая ситуация. Для того чтобы получить право на модернизацию блокировки, на чтение на блокировку на запись, необходимо определить тип доступа как RMW (read-modify-write — «чтение-обновление-запись»).
И, наконец, если все другие методы не дают результата, необходимо сократить допустимый интервал обнаружения тупиковых ситуаций. Чем дольше продолжается тупиковая ситуация, тем больше вероятность, что в нее будут вовлечены и другие транзакции. При этом для устранения тупика придется выполнять откат по большему числу транзакций, что все же хуже, чем заставлять эти транзакции ждать.
Оптимистическое управление параллельным выполнением
В некоторых базах данных вместо двухфазной блокировки используется стратегия, называемая оптимистическим управлением параллельным выполнением. Она позволяет устранить тупиковые ситуации. Эта стратегия не предусматривает блокировок, поэтому системы, где она реализована, полностью лишены тупиковых ситуаций, однако, и она определенным образом отражается на производительности.
Оптимистическое управление параллельным выполнением предполагает создание копий обновляемых данных, при этом измененные данные сохраняются до завершения транзакции. После завершения, система проверяет, не было ли внесено в данные противоречивых изменений. Если это обнаруживается, изменения аннулируются. Такая стратегия действительно является оптимистической, так как в процессе выполнения транзакции предполагается, что обновления будут произведены, правда, после завершения работы это предположение необходимо проверить.
Если две транзакции обновляют одну запись одновременно, возникнет конфликт, и результаты одной из транзакций будут аннулированы. Системы, действующие по принципу оптимистического управления, выявляют это только по завершении транзакции, и вся работа, проделанная транзакцией, аннулируется только на этом этапе. Если приложение предусматривает выполнение сложных транзакций, выполняющих большую работу, такая стратегия может привести к серьезным потерям производительности. При двухфазных блокировках одна из транзакций просто ждет, пока завершится другая и не выполняет бесполезной работы.
В системах, не подверженных конфликтам ресурсов, можно использовать либо двухфазную блокировку, либо оптимистическое управление: оба метода дадут хорошие результаты. Двухфазная блокировка редко приводит к тупиковым ситуациям, а при оптимистическом управлении меньше вероятность отказа от результатов работы транзакции из-за конфликтов.
Если же приходится иметь дело с приложениями, допускающими возникновение конфликтов на запись, приходится выбирать между двухфазной блокировкой и оптимистическим управлением. Стопроцентно верно, что если при записи возникают конфликты, лучше использовать двухфазную блокировку. Если две транзакции должны изменить одну и ту же величину в базе данных, лучше заставить их работать последовательно. При частом некорректном совместном использовании ресурсов оптимально использовать оптимистическое управление. В этом случае две транзакции смогут обновлять различные экземпляры одной записи, не конфликтуя друг с другом. Оптимистическое управление параллельным выполнением позволит обеим транзакциям работать без простоев, в то время, как при двухфазных блокировках такие простои будут возникать один за другим.
Разработка, реализация и использование высококачественных встроенных систем, ставит перед теми, кто берется за это дело, немало весьма сложных вопросов, —значительно больше, чем возникает при создании настольных и серверных систем. Разрешение этих вопросов требует обращать особое внимание на требования встроенных приложений и крайне разумно подходить к выбору инструментария.
Об авторе
Майкл Олсон - вице-президент по продажам и маркетингу компании Sleepycat Software, разрабатывающей программное обеспечение встроенных баз данных с открытым кодом и предоставляющей услуги в этой области. В сферу его интересов входит управление данными и инфраструктура мобильных вычислений. С ним можно связаться по электронной почте по адресу mao@sleepycat.com.
Selecting and Implementing an Embedded Database System, Michael A. Olson, IEEE Computer, September 2000, pp. 27-34. Copyright IEEE CS, Reprinted with permission. All rights reserved.
| Производитель | Продукт | Характеристика |
| Centura Software www.centurasoft.com | Velocis | Работает под управлением настольных, серверных и встроенных операционных систем. Поддерживает как SQL, так и интерфейсы программирования для управления данными. |
| Empress www.empress.com | RDBMS | Работает под управлением всех основных встроенных ОС. Поддерживает как SQL, так и интерфейсы программирования для управления данными. |
| Microsoft www.microsoft.com | MSDE | Совместимость снизу вверх с серверным ядром базы данных Microsoft SQL. Поддерживает только ограниченные возможности распараллеливания и сравнительно небольшие объемы данных. Работает только под управлением ОС Microsoft, на настоящий момент не добилась заметного проникновения на рынок встроенных устройств. |
| Oracle www.oracle.com | Oracle 8i | Работает под управлением широкого спектра ОС, в том числе в Linux, но не на встроенных операционных системах. Клиент-серверная версия поддерживает стандартные интерфейсы. |
| Pervasive www.pervasive.com | Pervasive.SQL 2000 | Поставляется для встроенных операционных систем; работает также под управлением настольных и серверных ОС. Поддерживает простой интерфейс программирования для операций с данными; может быть сконфигурирована с добавлением или исключением компонентов, в зависимости от требований встроенного приложения. |
| Polyhedra www.polyhedra.com | Polyhedra | Клиент-серверное ядро СУБД поддерживает SQL; работает на традиционных настольных и серверных ОС. |
| Solid www.solidtech.com | Solid Embedded | Предоставляет службы управления базами данных для многочисленных серверных и встроенных операционных систем. Ядро предоставляет доступ к данным посредством SQL, с предоставлением интерфейсов ODBC и JDBC. |
| Sybase www.sybase.com | SQL Anywhere | SQL-ядро допускает конфигурацию, предполагающую выполнение запросов только определенного приложения. Серьезный акцент на синхронизацию с предлагаемой Sybase базой данных уровня предприятия, работающей на сервере. |
| TimesTen www.timesten.com | TimesTen | Предоставляет доступ к стандартным реляционным данным, посредством SQL, ODBC и JDBC, однако, рассчитана на системы с большим объемом памяти. Выделение пространства оперативной памяти и на диске осуществляется по разным принципам, для оптимизации операций в оперативной памяти. Работает на настольных и серверных системах. |
| Производитель | Продукт | Характеристика |
| Objectivity www.objectivity.com | Objectivity/DB | Хранилище постоянных объектов C++ и Java. Поддерживает настольные и серверные операционные системы, не поддерживает встроенные ОС. Модель процессов сложнее, чем в продуктах других производителей. Разработчики могут дополнительно выполнять конфигурацию тиражирования других служб. |
| Persistence www.persistence.com | PowerTier | Библиотека для клиентских систем имеет интерфейсы к популярным базам данных. Поддерживает Enterprise Java Beans и C++. ПО работает на настольных и серверных операционных системах. Выбор серверной платформы определяется производителем ядра базы данных. |
| POET Software www.poet.com | POETObject | Библиотека для клиентских систем позволяет приложениям на C++ и Java взаимодействовать с разнообразными серверами баз данных, в том числе с объектно-ориентированной СУБД POET или реляционными продуктами Oracle или других производителей. Предоставляет постоянное хранилище объектов. Не поддерживает встроенные операционные системы. |
| Производитель | Продукт | Характеристика |
| Centura Software | RDM, db.linux | Библиотека RDM распространяется в исходных текстах. Работает на встроенных операционных системах. Версию RDM, перенесенную на Linux, компания предлагает как самостоятельный продукт db.linux. |
| FairCom www.faircom.com | c-tree Plus | Распространяется в исходных текстах. Компилируется в библиотеку, которая обращается напрямую в адресное пространство приложения. Официально поддерживается встроенными операционными системами QNX и LynxOS, однако, пользователи могут перенести исходный текст на другие операционные системы. |
| Free Software Foundation www.gnu.org | gdbm | Предоставляет простой API-интерфейс для записей данных; не поддерживает распараллеливания операций чтения-записи или обработки транзакций. Распространяется как продукт с открытым кодом по условиям лицензии Library General Public License. Не имеет предусматриваемой Free Software Foundation полной поддержки переносимости для встроенных систем. Тем не менее, имеются версии, перенесенные на многие операционные системы, кроме того, пользователи могут самостоятельно перенести продукт на новые операционные системы. |
| Informix www.informix.com | C-ISAM | Встроенная библиотека для управления данными предоставляет многие службы, требуемые встроенными системами. Тем не менее, библиотека работает только на настольных и серверных ОС. |
| Sleepycat Software www.sleepycat.com | Berkeley DB | Предлагает простой API-интерфейс для управления базами данных; допускает конфигурирование для добавления или исключения компонентов в зависимости от потребностей приложения. Распространяется в исходных текстах, работает на настольных и серверных операционных системах, а также некоторых встроенных системах. |
