

XML - это самостоятельная технология, хотя и возникшая исторически как Internet-технология. Представляется важным рассмотреть технологию XML в отрыве от Internet и в связи с технологиями баз данных: реляционной, объектной и концепцией корпоративных хранилищ. Как связан язык XML с реляционным, почему на его основе может и должна быть построена модель данных, что собой представляет XML-ориентированная база данных, существуют ли таковые на сегодняшний день?
О возникновении XML как языка
На исторические причины возникновения XML можно посмотреть с двух различных, но связанных между собой точек зрения (рис. 1):
 |
| Рис.1. Две точки зрения на XML |
Первая состоит в том, что семантическая ограниченность языка разметки гипертекста HTML не позволяла разработчику Web-приложений описывать специфичную информацию, например, химические или математические формулы. Возникла практическая потребность в других языках разметки, структурно аналогичных HTML, но с другой семантикой. В результате стараний Консорциума W3C был создан метаязык XML, на основе которого заинтересованные разработчики создали и создают специфичные дочерние языки разметки - CML, MathML и уже десятки других. С учетом небольшой синтаксической доработки, HTML также является дочерним языком XML.
Вторая точка зрения состоит в следующем. Информация, заключенная в любом документе, в том числе и в Web-странице, является в большей или меньшей степени регулярной. Ранние варианты HTML слабо учитывали эту регулярность, что приводило к громоздкости сообщений на этом языке и не вполне удовлетворяло разработчиков Web-приложений. Первым делом, стараниями W3C-консорциума, разработчикам была предоставлена возможность вычленить из HTML-документа описание внешнего вида отдельных, регулярно повторяющихся его фрагментов в самостоятельный объект - таблицу стилей CSS. Далее была вычленена в самостоятельный объект собственно разметка - таблица стилей XSL, которую, возможно, следовало бы более точно назвать таблицей шаблонов разметки. В итоге остался XML-документ, описывающий в чистом виде структуру данных документа. Таким образом, структурированные данные документа были отделены от способа их логико-графического представления (разметки) в виде списков, параграфов, таблиц, диаграмм и т.п., а логико-графическое представление от конкретного внешнего вида (стиля) - размеров, цветов, начертаний и т.п.
В общем виде XML-документ имеет структуру произвольного дерева, которая описывается набором вложенных друг в друга тегов, каждый из которых имеет следующий синтаксический вид:
<ИмяУзла ИмяАтр1=»значение»
ИмяАтр2=»значение» ... >
вложенные теги и тексты
Разница этих двух точек зрения на XML состоит в том, что ставить во главу угла - разметку или данные. В первом случае имена тегов и их атрибутов являются указателями на конкретный шаблон разметки и стандартизуются в словарях-спецификациях XML для каждого конкретного языка разметки. Во втором случае имена тегов XML - это указатели регулярных данных самого XML- документа. Нас интересует второй вариант, и под XML-документом мы будем понимать структуру данных документа, выраженную языком XML.
Перевод с реляционного языка в XML и наоборот
Реляционный язык - это язык кортежей (неупорядоченных множеств пар «ИмяРеквизита-ЗначениеРеквизита») и отношений (неупорядоченных множеств кортежей, имеющих одинаковый набор имен реквизитов). Внешним представлением сообщений на реляционном языке является набор двухмерных таблиц. Конкретное приложение, работающее с реляционными базами данных, делает разметку отношений, кортежей и значений в таблицы, строки (записи) и клетки (поля) и придает им некоторый внешний вид, обычно по опциональному выбору пользователя.
Внешним представлением сообщений на языке XML является набор реальных документов (и электронных, и бумажных), визуализация которых происходит при помощи универсального браузера (например, Internet Explorer 5) на основании XSL и CSS.
Перевод сообщений с реляционного языка на XML синтаксически не однозначен. Для иллюстрации рассмотрим простой пример, состоящий из 3 отношений, 5 реквизитов и 5 кортежей (рис. 2).
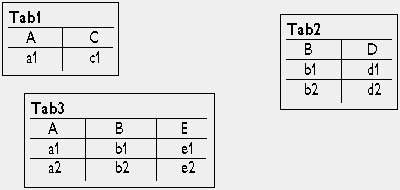 |
| Рис. 2. Пример реляционных данных |
В простейшем и наиболее компактном варианте получается следующая конструкция (вариант 1):
Ее недостатком является неоднородность представления кортежей и значений, что, например, осложняет отображение расширенных реляционных моделей. Если значения оформлять также в виде тегов, то получим следующее (вариант 2):
a1c1 b1d1 b2d2 a1b1e1 a1b2e2
Оба варианта используют двухуровневую вложенность XML-узлов, с помощью которой устанавливаются направленные связи кортеж-значение.
Направленные связи от записей Tab1 к записям Tab3 и от записей Tab2 к записям Tab3 (Tab3 обычно называют таблицей-связкой для реализации связей типа «многие-ко-многим») указываются одинаковыми значениями ключевых реквизитов A и B. В языке XML связи обычно указываются явно путем вложения тегов друг в друга и путем применения ссылок. Это позволяет в нашем примере убрать ссылочные ключи в Tab3 и установить ссылки на одного родителя путем вложения тега Tab3 в Tab2 и на второго родителя (Tab1) с помощью атрибутов Id и Ref (вариант 3):
a1
c1
b1
d1
e1
b2
d2
e2
Для того чтобы выполнить обратную операцию - привести произвольные XML-данные к реляционным - в первую очередь их необходимо преобразовать к одному из описанных выше вариантов. Для примера возьмем вариант 3.
1. Для каждого тега (в общем виде) вынесем все атрибуты, кроме Id и Ref, и все фрагменты текста в отдельные вложенные теги. Получится следующая структура:
<ИмяУзла Id=»Указатель» Ref1=»Указатель» Ref2=»Указатель»...> <ИмяАтр1> Значение <ИмяАтр2> Значение ... <ИмяТекста1> Только текст <ИмяТекста2> Только текст ... Только вложенные теги
2. Реляционные данные хранятся в неупорядоченном виде, а данные XML в упорядоченном. Если в порядке следования атрибутов, фрагментов текста и вложенных тегов заложен смысл, то его, возможно, следует сохранить путем добавления к этой структуре специального вложенного тега, содержащего эту информацию.
3. Узлы предпоследнего уровня иерархии, которым соответствуют кортежи, не могут содержать одноименные вложенные теги - эта ситуация должна быть преобразована. Грубо говоря, в реляционной таблице клетка не может быть разделена на части. Кроме того, если она и может быть пустой, то уж никак не может отсутствовать. Поэтому, необходимо учесть разницу между отсутствующим и пустым тегом последнего уровня.
4. Узлы последнего уровня иерархии, которым соответствуют значения реквизитов, не могут содержать ссылочных атрибутов Id и Ref, так как в реляционных данных связи по ключам существуют только на уровне кортежей.
Преобразование варианта 3 в вариант 2 происходит путем включения ключевых тегов, в качестве которых, в общем случае, удобно использовать суррогатные ключи.
Как видно из рассмотренного примера, если данные размещать как текст и «размечать» их именами тегов, а атрибуты использовать только для ссылок, то получается весьма однородная структура, синтаксически несколько более широкая, чем реляционная.
XML как модель данных
На основе языка XML может быть построена модель данных. В настоящий момент строгой модели данных нет, но она, вероятно, может быть построена на основе реляционной. Зачем она нужна? По очень простой и веской причине - естественности. Причем естественности во всех аспектах - логическом представлении данных, манипулирования ими и поддержки их целостности.
Представление данных как XML-документов является естественным, поскольку они получаются из реальных документов. Представлять данные как документы привычнее и понятнее, чем представлять их как реляционные таблицы. Реляционная таблица, в лучшем случае, отдельный фрагмент документа. Неестественность табличного представления легко прочувствовать вначале при проектировании реляционных баз данных, когда из набора имеющихся документов происходит вычленение сущностей, и затем при подготовке отчета, когда из этих же сущностей вновь создаются документы. Манипулировать данными с использованием такой естественной для человека (но логически избыточной!) сущности как «связь» также привычнее и понятнее, чем со ссылочными ключами, которые в реальных документах встречаются редко.
В настоящий момент существует набор стандартных операций низкого уровня для работы с XML-документами - удалить или перенести узел с поддеревом, создать документ или узел, выделить коллекцию узлов по такому-то признаку и т. п. Строгая модель данных предполагает создания на основе низкоуровневых логических операций ограниченного набора логически корректных операций верхнего уровня, позволяющих пользователю манипулировать данными без использования программирования, то есть «от кнопки», на уровне пользовательского интерфейса.
В любом случае, создавая набор операций манипулирования верхнего уровня в рамках XML?ной модели данных, следует отталкиваться от необходимости отразить в этом наборе именно те операции, которые совершаются в реальной жизни, причем, прежде всего, не с электронными, а с бумажными документами. Естественность - первична, а математическая логика хоть и обязательна, но вторична. С исторической точки зрения, реляционная модель данных - это очередная провалившаяся попытка навязать людям нечто очень «правильное», но искусственное, типа эсперанто. Этот набор операций будет совсем другим, чем в реляционной модели. Проиллюстрируем это на нижеследующих примерах.
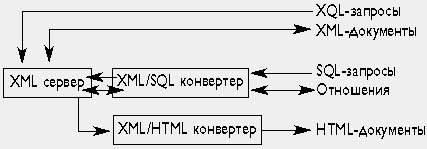 |
| Рис. 3. XML-ориентированные базы данных |
Манипулирование документами в реальной жизни называется документооборотом. Если мы хотим сделать базу данных полноправным участником документооборота (иначе говоря, общаться с ней на естественном языке), то она должна манипулировать документами как участник документооборота. А действует он, образно говоря, так: «Когда поступит документ № 1, возьми документ № 2, просуммируй значения в таких-то полях и запиши результат в такое-то поле документа № 3 и т.д.». Манипулирование документами - это всегда порождение нового документа, виртуального (аналог временных отношений в реляционной модели) или записываемого в базу данных. Отдельный документ или его фрагмент может возникать как результат отработки события документооборота и сам являться событием, порождающим новые документы или их фрагменты.
Модель данных XML любит «вредную избыточность» данных, не приемлемую для реляционных баз данных. «Иванов» в документе № 1 и «Иванов» в документе № 2, хотя речь и идет об одном и том же человеке, не одно и тоже - документы №1 и №2 возникли в разные моменты времени и, соответственно, в разных контекстах. В процессе документооборота часто данные многократно переносятся по цепочке от одного документа к другому, что вполне естественно и должно адекватно отражаться в модели данных. Вопрос о минимизации количества хранимой информации и оптимизации скорости доступа к ней - это вопрос физического хранения, а не логической модели.
Поддержка целостности данных при удалении узла XML-дерева сводится к удалению поддерева этого узла и всех поддеревьев в других документах, на узлы которых этот узел ссылается. Естественно, совокупность иерархических и горизонтальных направленных связей не должна образовывать циклических графов. Операция довольно дорогая, но редко применяемая - только в случае внесения заведомо ошибочных данных.
Если документ был составлен правильно, то он прекращает свое действие вовсе не с помощью операции «удаление», а на основании некоторого другого документа, его отменяющего. «Удаленный» документ не исчезает бесследно - историческая целостность документов поддерживается в архивах в течение определенного срока.
XML-ориентированные базы данных
XML-ориентированные базы данных в качестве модели данных использует модель данных, принятую в самом XML. Следует отличать XML-ориентированные базы данных (напрмер, Tamino или Cache) от реляционных, поддерживающих обмен данными на языке XML (Oracle, Microsoft SQL Server и др); в основе последних лежит реляционная модель.
Авторам статьи на текущий момент времени известно две XML-ориентированные базы данных - Tamino (компания Software AG) и Cache (InterSystems), причем со второй из них авторы непосредственно работают.
Столь быстрое появление этих баз как XML-ориентированных обусловлено тем, что еще задолго до появления XML они использовали в качестве физического представления данных верхнего уровня структуры, аналогичные структурам XML-документов - ненормализованные деревья (с горизонтальными связями). Несколько упрощая, можно сказать, что для этих баз XML-доступ к данным - это прямой доступ к данным. Естественно, что и методы манипулирования ненормализованными деревьями в основном совпадают с низкоуровневыми логическими операциями над XML-документами. Что касается высокоуровневых методов, то их скорее следует считать не строгими, а прагматическими.
Разумеется, и Tamino, и Cache поддерживают реляционный и объектный доступ к данным, работу на различных платформах и т. п. и т. д. Из маркетинговых заявлений разработчиков хочется обратить внимание на два момента, имеющих отношение к нашей теме.
1. XML-БД обеспечивают существенно более высокую скорость выполнения транзакций, в том числе через интернет, что обусловлено, с одной стороны, меньшими затратами на преобразования данных и, с другой стороны, известным своей эффективностью способом управления памятью как B-деревом.
2. XML-БД характеризуются высокой скоростью разработки приложений, что обусловлено унификацией данных, методов их обработки и, конечно же, естественностью их представления.
Данные и метаданные в XML-ориентированных базах данных
XML-документы, имеющие одинаковые уникальные имена тегов и порядок их вложенности друг в друга, и не зависимо от количества вложенных одноименных тегов, относятся к одному классу документов и являются его экземплярами. Внутри класса экземпляры документов и их узлы различаются по уникальному идентификатору ID. Говоря языком документооборота, класс - это описание бланка документа (где и какие поля, как называются, какими чернилами заполнять, на основании чего именно, кому и когда передать документ после заполнения и т.п.), а экземпляр - один заполненный бланк.
Класс описывается одним или несколькими XML-метадокументами, которые являются экземплярами соответствующих метаклассов. Сам метакласс имеет описание в виде таких же XML-метадокументов, являющихся тоже экземплярами этих же метаклассов. Таким образом, XML-база является описанной «на самой себе», что удобно по ряду причин, в частности, позволяет использовать одно и то же программное обеспечение как для работы с данными, так и для работы с метаданными.
Классы разделяются на две большие группы:
- Исходные XML-документы, элементы которых «прошиты» взаимными связями (Id и Ref). Связи могут указывать как на узлы этого же документа, так и на узлы другого документа, находящегося как в этой же базы данных, так и какой-либо другой, расположенной на удаленном сервере. Если ставится задача полной поддержки исторической целостности, то кроме указателей связей в атрибуты тегов элементов записывается системная дата последнего изменения этого элемента.
- Аналитические XML-документы, полученные из исходных XML-документов путем заполнения содержимого тегов (текста) значениями, получаемыми либо путем прямого перенесения, либо путем аналитической обработки значений из других XML-документов. Возникает ли подобный документ в момент его запроса (виртуальный документ) или рассчитывается заранее (хранимый документ), определяется практической целесообразностью.
Для описания классов используются экземпляры следующих метаклассов (не обязательно по одному):
- Schema - описывает структурные свойства XML-элементов для исходных XML-документов - перечень имен дочерних элементов, обязательность и возможность множественности данного элемента и т. п., а также тип данных содержимого элемента и принадлежность домену. Осуществляет проверку поступившего на сервер или, чаще, заполняемого на клиенте документа.
- XSLT-документы - описывают преобразования исходных XML-документов в аналитические XML-документы.
- XSL-документы с таблицами CSS и набором скриптов Behaviors - определяют, соответственно, разметку и стиль оформления документов, а также поведение элементов для электронных документов.
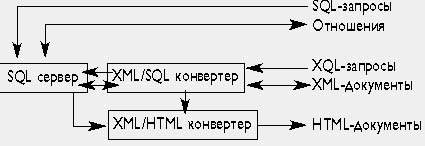 |
| Рис. 4. Реляционные базы данных, поддерживающие обмен данными на XML |
Помимо описанных выше классов и метаклассов XML-ориентированные базы данных включают в себя:
- Набор сценариев для работы различных групп пользователей. У сервера, как у полноправного участника документооборота, также есть свой сценарий. Сценарий связывает события, порождаемые пользователем или порождаемые «внутри» XML-базы (триггеры), с соответствующими метадокументами (Schema, XSLT, XSL) и операциями манипулирования, совершаемыми на клиенте или на сервере. По сути, сценарий - это данные, описывающие логику работы приложения, препарированного на составные части с целью унификации.
- Библиотеку готовых XSL-шаблонов, CSS-стилей, скриптов Behaviors для упрощения проектирования документов, возможности изменения на пользователе логико-геометрического представления и внешнего вида документа, а также для подготовки XSL-документов по умолчанию. Например, вид и поведение полей для ввода во входной форме могут быть определены по умолчанию на основании типа данных, записанного в Schema.
XML-ориентированные и объектно-ориентированные базы
XML-документ является информационным объектом и экземпляром одного из классов, содержащихся в XML-ориентированной БД. XML-документы являются информационными объектами, и их классы собственных методов не имеют. Работа с XML-документом происходит с помощью методов объекта анализатора (например, ActiveX Microsoft.XMLDOM), в который его загружают вместе с информационными объектами-описателями (Schema, XSL, CSS, набор скриптов).
Структура XML-документов унифицирована, и персональные методы для отдельного класса создавать смысла не имеет, поскольку сразу возникает естественное желание иметь возможность применить этот метод и к другим классам. Вместо инкапсуляции метод размещают либо в библиотеке, либо в анализаторе и параметризуют его данными, находящимися в информационных объектах-описателях. Заметим, что система управления XML-ориентированная база данных - такой же анализатор, только более мощный.
Если основным признаком объектно-ориентированной базы данных считать инкапсуляцию методов обработки информационных объектов в сами же эти объекты, то XML-ориентированные базы развиваются в прямо противоположном направлении: объекты разъединяются на свои логические составляющие части, эти части представляются в открытом формате, классифицируются, унифицируются и размещаются по библиотекам с возможностью доступа к ним через Internet.
Судя по темпам развития, XML-технологии объектно-ориентированные базы данных так и не успеют достигнуть того расцвета, который в свое время прошли их реляционные «предшественники».
XML-ориентированные базы в роли корпоративных хранилищ данных
XML-технология как нельзя лучше отвечает концепции корпоративных хранилищ данных (КХД), которую мы и рассмотрим с точки зрения XML-ориентированных баз данных.
1. Прежде всего, КХД - это совокупность нескольких, связанных между собой баз данных.
XML - это Internet-технология, имеющая в этом аспекте следующие позитивные моменты. Во-первых, XML - открытый формат описания данных, непосредственно понятный пользователю без броузера или анализатора. Во-вторых, XML - мировой стандарт для структуризации сложной информации, ее передачи как между сервером и клиентом, так и между сервером и сервером, как в локальной, так и глобальной сетях. В-третьих, XML предоставляет возможность создания глобальных децентрализованных баз данных с индивидуальным набором исходных и аналитических документов, хранимых на соединенных в общую сеть серверах. В-четвертых, конвертируемость XML-документов в реляционное представление и обратно позволяет подсоединить к XML-ориентированным корпоративным хранилищам реляционные базы данных.
2. КХД поддерживает историческую целостность данных. В КХД попадает исчерпывающий набор исходных данных из различных источников, который хранится в своем первоначальном состоянии и не удаляется. Для исходных данных допускается некоторое нарушение целостности и непротиворечивости.
В XML-ориентированных базах данных разборка класса XML-документов и установление связей с другими классами может быть отложена на неопределенное время. Документы записываются в своем первоначальном состоянии, фиксируются системные даты - поступления документа, установление связей между элементами различных документов, прекращения действия документа.
3. Помимо исходных данных, КХД содержит интегрированную аналитическую информацию, необходимую для принятия решений. Интеграция предусматривает объединение данных с приведением их к единому синтаксическому и семантическому виду и устранению нарушений целостности и противоречивости.
В XML-ориентированных базах данных разобранный документ - это такой же аналитический XML-документ, как и ответ на запрос, собственно аналитический расчет, выходная или входная формы.
4. Логическая структура аналитических данных в КХД отражает точку зрения корпоративного пользователя, которая различна для разных групп пользователей, и изменяется во времени.
Аналитические документы в XML-ориентированной базы данных как раз и отражают конкретную точку зрения как на конкретный документ, так и на их динамическое взаимодействие друг с другом на определенном временном интервале.
5. КХД должно обладать высокой скоростью обработки запросов пользователей, вследствие чего допускается высокая избыточность аналитических данных, отражающая промежуточные результаты статистически часто встречающихся запросов пользователей.
Скорость обработки запросов - это, в первую очередь, вопрос физического хранения и физического манипулирования данными, не имеющий отношения к XML как способу логического представления. На уровне логического XML-представления данных скорость обработки запроса зависит от того, являются ли результирующий или промежуточные XML-документы виртуальными или реально хранимыми. В XML-ориентированных КХД предполагается высокая доля реально хранимых аналитических документов.
Анатолий Долженков (dol@sparm.com) - директор по науке СП.АРМ, Валерий Веселов (valera@sparm.com) - системный аналтик СП.АРМ, (Санкт-Петербург).
