

 Мэйнфреймы IBM, или, как называют их сегодня, cерверы System z, занимают уникальное положение в компьютерном мире. Долгое время они служили источником архитектурных идей для разработчиков других вычислительных систем. В настоящее время серверы «z-серии» обеспечивают выполнение не только традиционных приложений мэйнфреймов, но и современных приложений, для которых конструировались большие Unix-серверы RISC-архитектуры.
Мэйнфреймы IBM, или, как называют их сегодня, cерверы System z, занимают уникальное положение в компьютерном мире. Долгое время они служили источником архитектурных идей для разработчиков других вычислительных систем. В настоящее время серверы «z-серии» обеспечивают выполнение не только традиционных приложений мэйнфреймов, но и современных приложений, для которых конструировались большие Unix-серверы RISC-архитектуры.
Теперь стало возможным говорить о взаимопроникновении идей. Происходит определенное сближение System z и открытых индустриальных стандартов, используемых в RISC-серверах и серверах x86-архитектуры. В z10 активно применяются средства обмена данными Infiniband, PCI-Express и другие технологии, а часть архитектурных решений близка к используемым в IBM Power6 и серверах на их базе.
У z10 немало уникальных аппаратных особенностей – и в микроархитектуре 64-разрядных CISC-процессоров, достигших наивысшей для CISC-архитектуры тактовой частоты 4,4 ГГц, и в архитектуре SMP (z10 – последняя разработка больших серверов этой архитектуры), и в средствах ввода-вывода – например, Infiniband 12x DDR сегодня делает только IBM. В сочетании с уникальным программным обеспечением операционных систем, в первую очередь z/OS, это обусловливает актуальность анализа аппаратных возможностей z10.
Процессоры z10
Целью разработки процессоров z10 (микросхемы Central Processor, CP) было существенное увеличение производительности по сравнению с z9. Это связано с расширением класса рабочих нагрузок, характерных для сегодняшних мэйнфреймов. К традиционной рабочей нагрузке мэйнфреймов, требующей кэша большой емкости, добавились приложения новых типов, дающие большую вычислительную нагрузку и меньшие требования к емкости кэша. Еще одна цель создателей z10 – повышение энергоэффективности.
CP в z10 являются четырехъядерными, построенными по КМОП-технологии IBM c применением технологии «кремний на изоляторе» и с типоразмером 65 нм. CP содержит 993 млн транзисторов и имеет соответственно большую площадь – 454 кв. мм. Его 64-разрядные процессорные ядра (Processor Unit, PU) уникальны уже потому, что достигли наивысшей в своем классе тактовой частоты (более высокие характеристики только у RISC-процессоров Power6).
Но и само строение СР имеет много оригинальных особенностей (рис. 1). Помимо четырех ядер PU, в CP предусмотрены контроллер оперативной памяти MC, контроллер высокоскоростной шины ввода-вывода GX, а также два сопроцессора COP, каждый из которых используется совместно парой PU [1].
Высокая плотность упаковки и надежность работы обеспечиваются благодаря знаменитому конструктиву IBM MCM (Multi-Chip Module), который агрегирует в себе пять микросхем СР, кэш второго уровня и другую электронику. (Младшие модели линейки z10 BC не используют MCM, а из четырех ядер активными, или видимыми пользователю, являются три.)
Любопытно, что разработчики провели оценку производительности альтернативной схемы организации СР с тремя PU, каждое из которых поддерживало бы одновременную работу двух нитей. При той же площади микросхемы это давало бы примерно такую же производительность, как четыре однонитевых PU.
Повышение производительности процессоров z10 достигнуто в первую очередь благодаря значительному росту тактовой частоты (в поколении z9 оно равнялось 1,7 ГГц) и переработке структуры кэш-памяти. Иерархия кэш-памяти в z10 включает кэш команд первого уровня (I-кэш L1) емкостью 64 Кбайт, кэш данных первого уровня (D-кэш L1) емкостью 128 Кбайт, а также новый уровень кэша для команд и данных (L1.5) для команд и данных емкостью 3 Мбайт; все они являются «собственными» для каждого PU. Кроме того, вне микросхемы СР имеется еще общий кэш второго уровня (L2) емкостью 48 Мбайт.
В z10, как и в Power6, не применяется внеочередное спекулятивное выполнение, характерное для большинства других современных микропроцессоров. Минусом последнего подхода является повышение задержек и возможность останова конвейера из-за взаимозависимостей между командами. В Power6 (и в меньшей степени в z10) старались взаимозависимости минимизировать. В результате достигнутая тактовая частота в z10 при данной технологии изготовления лишь немногим уступает Power6 (4,7 ГГц).
Общая длина «основного» конвейера (по аналогии с процессорами архитектур 86 и RISC будем считать таковым целочисленный конвейер) в z10 составляет 19 тактов, что всего на несколько стадий больше, чем в самых высокочастотных процессорах Intel Xeon c микроархитектурой Core, но в полтора раза ниже, чем в суперконвейерной архитектуре Intel NetBurst. В случае сбоя в PU к этим стадиям добавляется еще пять стадий контрольной точки/восстановления для автоматического аппаратного восстановления при сбое.
Всего можно выделить пять групп стадий конвейера z10: выборка команд; декодирование и выдача на выполнение; доступ в память (в D-кэш); выполнение (команды с фиксированной и плавающей запятой имеют разные участки конвейера); обработка сбоев.
Стадии выборки команд (их пять) реализуются устройством выборки команд IFU (рис. 1). Оно отвечает также за предсказание переходов. Кроме I-кэша L1 c двухтактным доступом здесь представлен также буфер быстрой переадресации TLB (128 строк, 4-канальный). В I-кэше команды хранятся в исходном недекодированном виде. Емкость I-кэша по сравнению с z9 уменьшена в четыре раза, поскольку появился собственный для PU высокопроизводительный кэш L1.5, где также хранятся команды.
В связи с большой длиной конвейера в z10 используется агрессивное предсказание переходов, в первую очередь с применением 5-канального наборно-ассоциативного буфера BTB (Branch Target Buffer) емкостью 10К строк с полем истории на восемь состояний. Кроме того, для переходов, у которых точность предсказания оказывается низкой, применяется специальная таблица PHT емкостью 512 строк. Еще одна структура, используемая в PU параллельно c BTB, – MTBTB (Multiple Target Branch Target Buffer) емкостью 2К строк, использующая хеш-функцию от истории произошедших переходов (детальнее логика предсказания переходов описана в [1]).
За стадии декодирования и выдачи команд на выполнение отвечает блок IDU (Instruction Decoding Unit), которому отвечает суперскалярный конвейер шириной в две инструкции и глубиной в шесть стадий.
В процессоре z9 конвейер короче, но за такт декодируется максимум одна команда.
Стадии доступа в память используют D-кэш L1, имеющий двухтактный конвейеризованный доступ, и двухканальный наборно-ассоциативный блок TLB емкостью 512 строк, обеспечивающий два параллельных доступа по чтению. Стадии доступа в память также обрабатываются суперскалярно с «шириной» в две команды.
В поколении z9 эти стадии могли выполняться во внеочередном порядке. В z10 этого нет, зато реализована аппаратная и программная предварительная выборка в кэш L1. Соответственно в z-Architecture появились новые команды prefetch. А «движок» аппаратной предварительной выборки использует так называемый «буфер истории шагов» емкостью 32 строки с 11-разрядным полем шага (stride). Предварительная выборка работает не так агрессивно, как это делают другие ориентированные на вычисления суперскалярные процессоры, поскольку z10 ориентирован на коммерческую нагрузку. Зато милликоды (так называют встроенные декодированные последовательности, реализующие команды) для длинных пересылок MVCL могут запускать предварительную выборку страниц емкостью 4 Кбайт.
На стадиях выполнения задействовано несколько функциональных устройств: два целочисленных конвейерных устройства FXU и два устройства с плавающей запятой – двоичное конвейерное устройство BFU и десятичное устройство DFU. Большинство целочисленных команд может выполняться в обоих FXU, но некоторые более редкие – только в первом FXU.
B процессорах z9 параллельное выполнение целочисленных команд и команд с плавающей запятой не допускалось; в z10 допускается частичный параллелизм выполнения. BFU выполняет арифметику с плавающей запятой в старом шестнадцатеричном формате мэйнфреймов, а также совместимые со стандартом IEEE P754 операции. Кроме того, в BFU выполняется целочисленное умножение и деление. Ряд компонентов BFU совместим с аналогичными компонентами Power6.
Устройство DFU обеспечивает арифметику, совместимую с IEEE P754. В z9 это было реализовано в милликодах, в z10 – аппаратно. Для выполнения записи данных в оперативную память имеется очередь записи в устройстве LSU (Load/Store Unit), что позволяет перенаправлять оттуда данные, например, в последующую команду загрузки регистров вместо длительного обращения в память [1].
Как это делалось в мэйнфреймах IBM еще несколько десятков лет назад, в случае сбоя процессоров происходит автоматическое восстановление и попытка повторения невыполненной команды. В z10 имеется устройство восстановления RU, которое создает защищенную кодами ЕСС контрольную точку для последующего восстановления. В z9 восстановление было организовано по-иному: в двухъядерной микросхеме центрального процессора там имелось общее «резервное устройство» (sparing unit).
Рассмотрим теперь другие устройства процессорного ядра (рис. 1), в том числе устройство преобразования адресов XU и иерархию кэш-памяти [1,2]. XU используется, в частности, для динамического преобразования виртуальных адресов в физические и содержит буфер TLB L2. Буфер TLB в z10 поддерживает не только стандартные 4-килобайтные страницы, но и большие страницы емкостью 1 Мбайт.
I-кэш L1 является 4-канальным наборно-ассоциативным, D-кэш L1 – 8-канальным, объединенный кэш L1.5 для команд и данных – 12-канальным. Вся эта кэш-память у каждого процессорного ядра – своя, в отличие от кэша L2, который вообще находится вне микросхемы СР. Кэши всех уровней имеют длину строки 256 байт, как и в z9. При этом в L1 и L1.5 применяется сквозная запись, а в L2 – так называемые операции store-in, когда сохраняемые в памяти данные записываются туда не сразу, а буферизуются. Поэтому они могут быть доступны другим процессорным ядром и подсистеме ввода-вывода без обращения в оперативную память.
Появление L1.5 в z10 позволило по сравнению с z9 уменьшить емкости кэшей L1 и увеличить их быстродействие. При попадании в кэш L1.5 строка (16 квадрослов) передается в L1 по одному квадрослову за такт при средней задержке 14,5 такт.
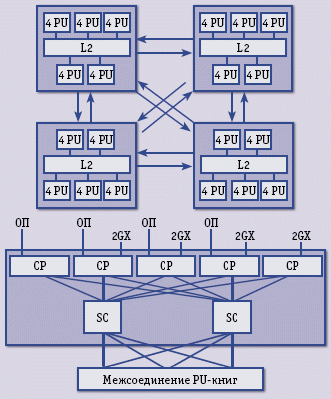
Кэш L2 использует инклюзивный подход и является общим для пяти микросхем СР, упакованных в МСМ (рис. 2). Он имеет емкость 48 Мбайт, является 24-канальным наборно-ассоциативным и, как и L1.5, защищен кодами ECC (в кэше L1 применяется контроль четности). Около 90% промахов в кэше L1 удовлетворяется за счет кэшей L1.5 и L2. О когерентности кэша мы скажем ниже.
В структуре СР представлен еще сопроцессор СОР; другие компоненты СР мы обсудим ниже при анализе структуры SMP-серверов z10. Сопроцессор СОР управляется в основном из милликодов и используется для сжатия данных и задач криптографии. Он включает в себя два устройства сжатия данных и два криптографиеских «движка» – цифровой и для хеширования.
В СОР поддерживается стандарт 3DES, а в z10 появилась и поддержка AES, а также Secure Hash Algorithm (SHA-2) для ключей с длиной до 512 бит. СОР обеспечивает декомпрессию со скоростью до 8,3 Гбайт/с, сжатие – до 240 Мбайт/с и шифрование на скоростях 290-960 Мбайт/с.
Таким образом, резюмируя усовершенствования процессора z10 по сравнению с z9, следует указать на новый высокопроизводительный конвейер; улучшенное предсказание переходов; аппаратную и программную предварительную выборку данных; появление нового кэша L1.5; аппаратную поддержку десятичной арифметики с плавающей запятой; развитие функциональности СОР и др. В CISC-архитектуре z10 появилось 50 новых команд. А всего в ней имеется теперь 894 команды, из которых 668 реализовано аппаратно.
В результате для обработки транзакций в больших базах данных, в том числе на стандартной для мэйнфреймов рабочей нагрузки LSPR, производительность по сравнению с z9 возросла в полтора раза, а на новых приложениях с большей процессорной нагрузкой – вдвое [1].
Общая структура SMP-серверов
Конструктив МСМ в z10, имеет размер 95x95 мм, включает пять микросхем СР и две микросхемы SC (System Controller). Кэш L2 содержится в микросхеме SC. Следующий в иерархии конструктива элемент, так называемая PU-книга, помимо МСМ содержит до 48 модулей DIMM, а также 8 слотов для плат ввода-вывода (концентратор IOH, I/O Hub) [3]. Напомним, что контроллер памяти и контроллер шины ввода-вывода (GX) встроены в СР.
Микросхемы SC выполняют функции концентраторов, связывающих СР внутри PU-книги и PU-книги между собой. Таким образом, топология межсоединения в z10 – полносвязная, на базе коммутаторов, в то время как в z9 применялась с точки зрения производительности менее эффективная топология двойного кольца.
В сравнении z10 с большими SMP-серверами Sun Fire E25k, HP Integrity Superdome, а также с серверами IBM на базе Power6 отличительной особенностью z10 является наличие огромного кэша L2 вне процессорных микросхем. Такая трехуровневая система кэш-памяти большой емкости приводит к тому, что системные шины в z10 в типичных ситуациях нагружены менее чем на 30% [2].
По сравнению с z9, в z10 число основных типов микросхем уменьшилось до двух (SC и СP). SC обеспечивает когерентное межсоединение 20 процессорных ядер из PU-книги и их общий кэш L2, а также когерентное соединение PU-книг между собой (всего в z10 может быть до четырех PU-книг, то есть архитектура допускает до 80 PU) в полносвязную систему с межсоединением типа «точка-точка». Эта когерентность охватывает также и подсистему ввода-вывода.
Когерентность кэш-памяти внутри PU-книги основывается на разработанном IBM расширении протокола MOESI c добавлением новых состояний. Его реализация, как и поддержка когерентности на уровне межсоединения PU-книг, рассмотрены в [2].
Суммарная пиковая пропускная способность интерфейсов СР с SC в z10 уменьшилась до 47 Гбайт/с против 54,4 Гбайт/с для z9. Это вызвано появлением в z10 кэша L1.5 и уменьшением числа промахов в кэше, не разрешаемых в пределах СР. Зато более чем в два раза возросла пропускная способность чтения из локальной оперативной памяти в PU-книге (до 68,3 Гбайт/с) и пропускная способность передачи данных между PU и межсоединением PU-книг (до 70,3 Гбайт/с).
Оперативная память в z10 размещается на буферизованных модулях DIMM DDR2-533 собственного производства IBM, так что при емкости модуля в 8 Гбайт в четырех PU-книгах на 192 слотах DIMM в z10 EC можно получить емкость оперативной памяти в 1,5 Тбайт. В системе z10 BC применяются модули DIMM емкостью 2/4 Гбайт при максимальной емкости оперативной памяти в 256 Гбайт. Контроллер памяти в СР имеет четыре канала, но общая схема построения памяти сложна (в частности, применяется каскадирование). Кроме того, один СР из каждого МСМ не имеет прямого соединения с памятью.
Повторим, в z10 задержки в кэше L1 меньше, чем в z9. Задержка обращения в кэш L1.5 составляет около 3 нс, в локальный кэш L2 данной PU-книги – 20 нс (88 тактов), а обращение в удаленный кэш L2 другой PU-книги требует 52 нс, что близко к z9 (хотя число тактов в z10 больше из-за более высокой тактовой частоты СР). Также близки к z9 задержки оперативной памяти: 134 нс (591 такт) – для чтения из локальной памяти, 162 нс (712 тактов) – для чтения из удаленной памяти вне данной PU-книги [2].
Это отличные результаты для полностью сконфигурированной системы. В собственных материалах IBM приводятся данные о задержке оперативной памяти Sun Fire E25k (440 нс) и HP Integrity Superdome (395 нс). Методика корректного сопоставления задержек памяти в системах SMP/ccNUMA – область научных дискуссий, и на сказанном выше мы остановимся.
Подсистема ввода-вывода
В z10 подсистема ввода-вывода претерпела существенные изменения по сравнению с z9. В поколении z10 возросла и надежность подсистемы ввода-вывода, и суммарная пропускная способность ввода-вывода (более чем вдвое). Однако из-за естественных ограничений объема публикации мы не можем рассмотреть здесь эту подсистему (она описана в Web-версии статьи) и огромный пласт особенностей z10, связанных с отказоустойчивостью. Применение кластеров Parallel Sysplex позволяет обеспечить непрерывную доступность и катастрофоустойчивость (последнее – благодаря использованию географически распределенных конфигураций кластеров) [5].
Конструктив
Старшие модели z10 EC (Enterprise Class) основаны на традиционном конструктиве IBM CEC (Central Electronic Complex). PU-книги входят в состав СЕС, они монтируются на пассивной плате (backplane), выступающей в качестве их межсоединения, но не имеющей активных цепей. На одну такую плату монтируется до четырех PU-книг. Одна из книг должна содержать не более 17 PU, а не 20, как остальные [2,5,6]. В отличие от z9, PU-книга z10, кроме МСМ, содержит средства управления FSP (Flexible Support Processor) и модули DIMM.
Модель z10 EC содержит две стойки (две рамы, A и Z). Рама А включает четыре PU-книги, два двухконтурных модульных устройства охлаждения MRU, два устройства IBF (Integrated Battery Function), средства воздушного охлаждения вентиляторами (АМА), т.н. корзину ввода-вывода и др. Рама Z содержит два устройства IBF, две корзины ввода-вывода, АМА, устройство обеспечения электропитания BPA (Bulk Power Assembly) и др.
Ясно, что для 77 PU, работающих на тактовой частоте 4,4 ГГц (процессорная микросхема выделяет 300 Вт), для 1,5 Тбайт оперативной памяти и высокоскоростных коммуникаций (платы IOH потребляют около 30 Вт) требуется серьезное охлаждение. Серверы z10 по габаритам сопоставимы с RISC-серверами старшего класса, но отличаются высокой плотностью упаковки. Поэтому в z10 EC применяется жидкостное охлаждение (а МСМ имеют для этого специальную конструкцию). Кроме того, на случай его сбоя предусмотрено запасное, воздушное охлаждение. При этом автоматически понижаются частоты и уровни вольтажа в процессоре.
Что касается младших моделей z10 BC, то они занимают всего одну стойку. Там применяется только воздушное охлаждение, а конструктив МСМ не используется. Эти модели имеют только раму А и весят около 900 кг. Они занимают площадь всего 1,4 кв. м и потребляют 4,3-7,3 кВт в зависимости от конфигурации.
Конфигурации z10
В реальных конфигурациях z10 BC и EC не все имеющиеся PU доступны пользователям в качестве обычных процессоров. В моделях ВС из 12 PU два задействованы как сервисные процессоры, а в моделях ЕС из 77 PU пользователям доступно до 64. Кроме того, часть PU может применяться для ограниченных целей, например только для работы с Linux (Integrated Facility for Linux, IFL), что уменьшает стоимость z10 для пользователя. Кроме IFL, упомянем zAAP (zApplication Assist Processors) для работы с Java и XML, zIIP (zIntegrated Information Processor) для обработки транзакций в бизнес-приложениях корпоративного уровня, а также сетевой нагрузки и IPSec [4]. Подробнее с конфигурациями z10 BC/EC можно ознакомиться в [4,6].
Сказанное позволяет делать вывод, что z10 представляет собой значительный шаг вперед как с точки зрения производительности, так и с точки зрения обеспечения непрерывной безотказной работы, однако экономическая рецессия сказалась и на объемах продаж z10 в 2009 году. Реагируя на ситуацию, в IBM планируют модифицировать свою ценовую политику, в том числе устанавливая специальные цены на конфигурации с процессорами IFL. В скором времени можно ожидать и появления нового поколения аппаратных средств.
Литература
- C.L. Shum, F. Busaba e.a., Design and microarchitecture of the IBM System z10 microprocessor. IBM J. Res. & Develop., Vol. 53, No. 1, 2009.
- P. Mak, C.P. Walters e.a., IBM System z10 processor cache subsystem microarchitecture. IBM J. Res. & Develop., Vol. 53, No. 1, 2009.
- E.W. Chencinsky, M.A. Check e.a., "IBM System z10 I/O system. IBM J. Res. & Develop., Vol. 53, No. 1, 2009.
- IBM System z10 Business Class (z10ВС) Reference Guide. IBM, ZSO03021-USEN-04, Oct. 2009.
- J.G. Torok, F.E. Bosco e.a., Packaging design of the IBM System z10 Enterprise platform central electronic complex. IBM J. Res. & Develop., Vol. 53, No. 1, 2009.
- IBM System z10 Enterprise Class (z10EС) Reference Guide, IBM, ZSO03018-USEN-04, Oct. 2009.
Михаил Кузьминский (kus@free.net) – старший научный сотрудник учреждения РАН «Институт органической химии им. Н.Д. Зелинского» (Москва).
Рис. 1. Структура микросхем СР в z10
