
 Понятие Business Intelligence (BI) появилось достаточно давно, однако в правильном контексте употребляется относительно редко. Скорее всего, это связано с отсутствием подходящего русскоязычного эквивалента — наиболее распространенные варианты: «бизнес-разведка», «бизнес-аналитика», «бизнес-интеллект» лишь частично отражают суть. Понятие Business Intelligence было введено аналитиками Gartner Group в конце 80-х годов для обозначения «пользователецентрического процесса, включающего в себя доступ и исследование информации, ее анализ, выработку интуиции и понимания, ведущие к улучшенному и неформальному принятию решений». Позже появилось уточнение, BI — «инструменты для анализа данных, построения отчетов и запросов, помогающие бизнес-пользователям «переплыть» море данных для того, чтобы синтезировать из них значимую информацию…».
Понятие Business Intelligence (BI) появилось достаточно давно, однако в правильном контексте употребляется относительно редко. Скорее всего, это связано с отсутствием подходящего русскоязычного эквивалента — наиболее распространенные варианты: «бизнес-разведка», «бизнес-аналитика», «бизнес-интеллект» лишь частично отражают суть. Понятие Business Intelligence было введено аналитиками Gartner Group в конце 80-х годов для обозначения «пользователецентрического процесса, включающего в себя доступ и исследование информации, ее анализ, выработку интуиции и понимания, ведущие к улучшенному и неформальному принятию решений». Позже появилось уточнение, BI — «инструменты для анализа данных, построения отчетов и запросов, помогающие бизнес-пользователям «переплыть» море данных для того, чтобы синтезировать из них значимую информацию…».
Иными словами, под Business Intelligence принято понимать комплекс методов, технологий и реализующих их программных продуктов, позволяющих собирать, обрабатывать и анализировать исходные данные о факторах и событиях, оказывающих влияние на какую-либо деятельность (в частности, бизнес), с целью получения на их основе качественно новой информации и знаний о системном влиянии таких факторов. Этим BI отличается, например, от конкурентной разведки, которая концентрируется на сравнительном анализе возможностей собственного бизнеса и бизнеса реальных или потенциальных соперников, и от информационно-аналитической деятельности, подразумевающей тотальный анализ сведений в некоторой искусственно ограниченной предметной области. На практике под технологиями BI обычно подразумевают различные OLAP-решения, что значительно сужает понимание термина и возможностей, которые этот подход предоставляет.
Классы BI-систем
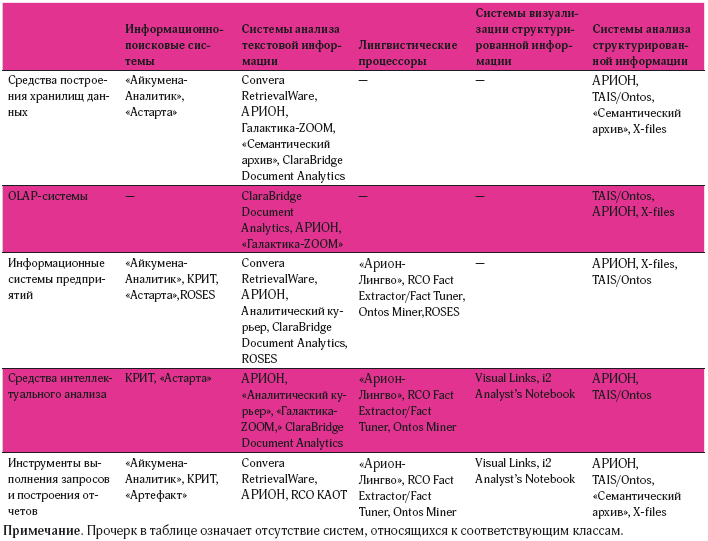
Аналитики Gartner разделяют BI-продуктов на классы: средства построения хранилищ данных (Data Warehousing); системы оперативной аналитической обработки (OLAP); информационные системы предприятий (Enterprise Information Systems, EIS); средства интеллектуального анализа данных (Data Mining); инструменты для выполнения запросов и построения отчетов (Query and Reporting Tools). В случаях, когда компонентный состав системы не определен, но выявлен круг актуальных информационно-аналитических задач, представляет интерес альтернативное деление, в основу которой положены характерные классы информационно-аналитических задач: информационно-поисковые системы; системы анализа текстовой информации; лингвистические процессоры; системы визуализации структурированной информации; системы анализа структурированной информации.
Информационно-поисковые системы — продукты, основной функцией которых является накопление и оперативный полнотекстовый поиск документальной информации. В этих системах часто присутствуют такие приятные дополнительные возможности, как поиск с учетом морфологии языков, словарей синонимов и даже фонетический поиск.
Системы анализа текстовой информации рассматривают тексты документов как структурированные последовательности связанных терминов, что повышает избирательность поиска. Вместо отдельных терминов пользователи таких систем оперируют понятием «тема», что позволяет не только более качественно проводить отбор документов, но и выполнять аналитическую обработку.
Лингвистические процессоры. Системы этой группы ориентированы на преобразование входящего потока документов (неструктурированных или частично структурированных) в структурированный массив, отражающий характеристики объектов и их взаимосвязи при помощи алгоритмов морфологического, синтаксического и семантического анализа. Лингвистические процессоры, как правило, не предоставляют пользователям готовых прикладных возможностей, но применяются для автоматической обработки больших массивов входящих документов.
Системы визуализации структурированной информации предназначены для агрегирования и отображения информации, полученной из различных источников (реляционных баз данных, структурированных файлов), и кроме функций визуализации предлагают набор функций поиска информации, ее редактирования, формирования специализированных отчетов и синхронизации с источниками информации (в том числе и в режиме реального времени).
Системы анализа структурированной информации обладают возможностями аналитической обработки (логический вывод, поиск фактов и ситуаций, выявление похожих объектов и ситуаций, контекстный анализ, поиск неявных связей и др.) с использованием данных, полученных из разнородных источников. При этом в автоматическом или автоматизированном режиме проводится анализ не только отдельных терминов или объектов, как в случае систем анализа текстовой информации, но также их логически взаимосвязанных комбинаций.
Следует отметить, что большинство существующих программных продуктов относятся к нескольким классам как при разбиении по Gartner Group, так и при делении по решаемым информационно-аналитическим задачам. В таблице 1 приведен перечень доступных на российском рынке систем, представленных согласно обеим классификациям.
Таблица 1. Перечень систем бизнес-аналитики
Что есть что
«Астарта»
Компания «Когнитивные технологии» разработала систему «Астарта», включающую в себя серверное программное обеспечение, предназначенное для предварительной обработки (сбора, рубрикации, индексирования информации); клиентское приложение, выполняющее поиск и обработку информации, накопленной в системе; Web-клиент с ограниченным функционалом. Система предлагает функции настройки на источники данных (папки файловой системы, каналы электронной почты, Web-ресурсы, ftp-ресурсы и т.д.) и имеет встроенный Web-краулер для сканирования сайтов по заданным URL в соответствии с предусмотренным расписанием (crawler — паук-путешественник — программа, автоматически проходящая по всем ссылкам, найденным на Web-странице, и определяющая, куда идти дальше в зависимости от заданного контекста). Применительно к системам бизнес-анализа, краулер — составная часть автоматизированных поисковых систем, которая выполняет поиск в Сети новых документов и извлекает текстовую информацию для последующей обработки). Найдя необходимый источник, система преобразует информацию к единому текстовому формату, фильтрует ее по ключевым словам на соответствие конкретной тематике, контролирует и удаляет дубликаты, выделяет реквизиты в соответствии с предопределенными шаблонами. Система проводит морфологический анализ текстов документов, выделяет термины и выполняет неисключающую рубрикацию по ним. Поиск и анализ документов осуществляется при помощи АРМ пользователей на основе клиентского Windows-приложения, а также возможностей пакетов Microsoft Excel и Statistica.
«Астарта» — документальная информационно-поисковая система, обладающая средствами поиска и рубрикации, основанными на статистическом исследовании встречаемости терминов в текстах документов. Система обладает развитыми средствами сбора информации из Сети, однако при статистической обработке данных придется смириться с необходимостью использования дополнительных пакетов: Microsoft Excel и Statistica.
АРИОН
Компания «САЙТЭК» разработала систему АРИОН (автоматизации работы с информацией оперативного назначения), в состав которой входят: компонент сбора информации из разнородных источников (базы данных, Internet, документальные массивы, внешние информационные системы и т.п.); лингвистический процессор; компонент управления задачами; сервер приложений, реализующий все функции обработки и представления информации; рабочие места пользователей (аналитика, оператора, корректора, администратора, эксперта) на базе тонкого клиента. Лингвистический процессор «АРИОН-Лингво» — самостоятельный продукт, который может поставляться независимо.
Документальная и фактографическая информация, поступающая из разных источников, обрабатывается при помощи адаптеров, обеспечивающих контроль дубликатов, преобразование форматов и кодировок входных документов к единому внутрисистемному виду; также выполняется полнотекстовое индексирование и неисключающая рубрикация документов по ключевым словам. Слабоструктурированные данные (адресная строка, паспортные данные и т.п.) и тексты документов проходят формато-логический контроль, из них извлекаются объекты, их атрибуты и взаимосвязи, полученные семантические сети объединяются в фактографической базе данных путем объединения совпадающих объектов. Пользователи получают доступ к информации через тонкого клиента.
Система относится к нескольким классам по обеим классификациям, обладая возможностями фактографической обработки информации, средствами преобразования текстовой информации в структурированную форму, функциями идентификации информационных объектов, а также расширенным составом поисковых и аналитических режимов обработки данных, а также специализированными аналитическими режимами, такими как контекстный анализ, поиск неявных взаимосвязей, поиск похожих по шаблону ситуации или документа, многофакторный статистический анализ, средства извлечения и анализа фактов. Обратной стороной медали является достаточно сложный интерфейс и большое количество настроек, что не позволяет приступить к эксплуатации системы сразу после установки — требуется конфигурирование под предметную область заказчика и обучение пользователей.
«Артефакт»
Компания «Интегрум-Техно», специализирующаяся на поддержке онлайн-архива центральных и региональных СМИ, правовых баз данных, а также архивов таких организаций, как Роспатент, Госкомстат и т.д., разработала систему «Артефакт», включающую в себя систему предварительной обработки и сервер приложений. Доступ к информации реализован через Web-интерфейс.
Информация в виде текстовых документов различных форматов размещается в файловой системе, затем импортируется в систему. Тексты документов индексируются, в них выделяются реквизиты и их значения, определяется взаимное расположение терминов в тексте. Обработанные документы распределяются по нескольким разделам базы данных в зависимости от значений реквизитов, языка, источника и т.д.
Решение представляет собой документальную информационно-поисковую систему, обладающую, помимо основных функций индексирования и поиска, функциями статистического анализа встречаемости терминов. От других представителей этого класса система «Артефакт» выгодно отличается наличием полностью функционирующей бесплатной версии с ограничением на просмотр всего текста найденных документов, гибким языком запросов и несколькими видами статистического анализа.
«Айкумена-Аналитик»
Компания «Айкумена» предлагает систему «Айкумена-Аналитик», которая состоит из Web-краулера, собирающего документальную информацию на заданных ресурсах Cети; системной базы данных под управлением реляционной СУБД; сервера приложений; АРМа пользователей на основе тонкого клиента.
Исходные документы приводятся краулером к единому текстовому формату и загружаются в системную базу, где эти документы классифицируются в соответствии с общим рубрикатором, в котором есть общие и персональные папки. Неисключающая рубрикация проводится по ключевым словам с учетом морфологии. При изменении параметров рубрики производится фоновая классификация всего массива документов относительно этой рубрики. На основании результатов рубрикации выполняется аннотирование документов по ключевым словам. В текстах документов выделяются описания персон и организаций: строятся факты, объединяющие эти объекты. Результат работы — рубрика или выборка — экспортируются в формате Word.
«Айкумена-Аналитик» — документальная информационно-поисковая система, обладающая отдельными статистическими функциями.
«Аналитический курьер»
Системный интегратор, компания «Ай-Теко» предлагает на рынке бизнес-аналитики систему «Аналитический курьер», включающую в себя подсистему полнотекстового индексирования и поиска; набор автоматов для структуризации полнотекстовой информации; набор Web-приложений, реализующих прикладные функции.
Для хранения документов и информации о них в системе применяется реляционная СУБД. «Аналитический курьер» позволяет в автоматизированном режиме накапливать отдельные документы, подборки документов, ресурсы Сети. Для каждого документа устраняется омонимия, местоимения заменяются соответствующими им существительными, определяются ключевые темы, выполняются статистическая рубрикация и кластеризация, а также аннотирование. На основе связей между документами строится семантическая карта массива документов.
«Аналитический курьер» — развитая система анализа текстовой информации, поддерживающая работу с многоязычными источниками информации, имеющая удобный интерфейс поиска документов и личные папки пользователей с индивидуальными настройками.
КРИТ
Компания «Смартвейр» предлагает систему КРИТ (коллектор рассеянной информации в текстах), представляющую собой клиентское Windows-приложение без собственной БД.
Пользователи системы указывают параметры подключения к источникам данных — полнотекстовым документам, и в соответствии с запросом пользователя выполняется поиск с подсветкой ключевых слов из запроса. В выборке документов выделяются объекты и связи, результаты отображаются и редактируются в графическом и табличном виде, полученные результаты не сохраняются, но экспортируются в формате RTF.
КРИТ — информационно-поисковая система с возможностью структуризации текстовой информации, позволяющая выполнять поисковые запросы к документальным источникам, структуризацию результатов запросов и их интерактивное редактирование в визуальной форме. К недостаткам можно отнести отсутствие разграничения доступа и зависимость скорости работы системы от объема памяти на клиентской машине.
«Семантический архив»
Компания «Аналитические бизнес-решения» предлагает системы для анализа и оценки открытых материалов в интересах государственных и частных структур.
В состав системы «Семантический архив» входит Web-краулер, адаптер-загрузчик для импорта структурированной информации из реляционных БД, системная БД и АРМ пользователей. Источниками документальной информации, поступающей в систему, могут быть URL, отдельные файлы и папки, реляционные базы данных. Информация из реляционных баз приводится к единому текстовому формату, рубрицируется по ключевым словам и загружается в системную базу. Пользователи при помощи Windows-приложения последовательно выбирают необработанные документы из общей очереди, проверяют результаты автоматического выделения объектов и связей, их классификации. Аналитики работают с другим Windows-приложением, результатами работы которых могут быть файлы Microsoft Office (подборки документов, статистические графики и гистограммы) или семантические сети в Microsoft Visio.
Семантический архив — фактографическая информационно-аналитическая система, обеспечивающая накопление документальной информации, ее преобразование в структурированную форму, статистическую обработку полученных данных и их визуальный анализ.
X-Files
Данная система содержит полнотекстовую подсистему индексирования и поиска; набор автоматов для структуризации полнотекстовой информации; набор приложений, реализующих прикладные функции системы и доступных посредством Web-интерфейса.
Исходные документы накапливаются в хранилище, а затем в фоновом режиме обрабатываются процессами-автоматами, которые выделяют из их текстов описания объектов и фактов. Функции ввода и хранения документов аналогичны функциям системы «Аналитический курьер».
X-Files относится к классу систем накопления и анализа информации по различным информационным объектам (сбора и ведения досье). Отличительными особенностями продукта являются средства работы с многоязычными источниками информации и механизмы генерации отчетов-досье по интересующим объектам. Однако возможности адаптации системы к русскоязычным текстам несколько ограничены.
Семейство OAS/Ontos Miner/Light Ontos
Системный интегратор компания «Авикомп Сервисез» предлагает семейство следующих BI-продуктов: Ontos Miner — семантическое аннотирование текстов; Ontos Annotation Server (OAS) — технологическая платформа распределенной обработки неструктурированной информации и размещения результатов семантического анализа в хранилище; Light Ontos — облегченная версия OAS,
сочетающая средства Ontos Miner и интерфейс конечного пользователя.
Исходная информация вводится непосредственно (отдельные документы) из папки (мониторинг) и из Сети. Документы преобразуются к единому формату (плоский текст) и загружаются в хранилище или файловую систему, тексты анализируются, в результате местоимения частично заменяются на существительные, к которым они относятся, и выделяются объекты и связи. Объекты и связи обрабатываются агентами предварительной идентификации и слияния, полученная информация размещается в хранилище RDF (Resource Description Framework — разработанный консорциумом W3C стандарт для описания ресурсов) на основе реляционной СУБД и доступна пользователям OAS посредством сервера навигации и аналитического сервера. Далее определяются семантические фокусы документов — выбираются часто упоминаемые объекты, содержащие наибольшее количество связей в рамках этих документов. В процессе работы пользователей с фактографической информацией в фоновом режиме выполняются идентификация и слияние объектов, а также применение правил логического вывода.
Семейство OAS/Ontos Miner/Light Ontos относится к классу фактографических информационно-аналитических систем, и основное место в нем занимают средства преобразования текстовой информации в структурированную форму. Однако имеются некоторые ограничения по адаптации лингвистических механизмов для обработки русскоязычных текстов.
Visual Links
Институт проблем безопасности и анализа информации предлагает систему Visual Links от компании Visual Analytics, продукты которой соответствуют общепринятому в силовых структурах США стандарту информационно-аналитической деятельности IALEIA (International Association of Law Enforcement Intelligence Analysts).
В состав системы Visual Links входит интеграционный сервер, обеспечивающий выборку информации из источников данных и ее предоставление пользователям, а также АРМ пользователей на основе Java-клиента.
Администратор системы формирует общую модель данных и описывает для нее отображение моделей данных источников (задает сущности, атрибуты, связи), а также настраивает ключевые поля в пользовательском интерфейсе. Выборка информации из источников данных производится по запросам пользователей, идентификация сущностей выполняется по совпадению строк, составленных из значений ключевых полей. Результаты выборки транслируются в общую модель данных и отображаются в пользовательском интерфейсе. Пользователь задает поисковый запрос к конкретному источнику, получая выборку, которая присоединяется к построенной им ранее сети, результаты экспортируются в виде HTML-файлов либо в формате Microsoft Office. В качестве источников данных могут использоваться произвольные СУБД, а также форматированные файлы.
Visual Links — фактографическая система визуального анализа, обеспечивающая выполнение поисковых запросов к источникам структурированных данных, агрегирование результатов и интерактивный визуальный анализ полученной информации. Система содержит удобные визуальные средства работы с данными больших объемов. Однако при этом можно сделать запрос только к одному источнику информации, а обращение к другим возможно только при уточнении запроса.
Семейство RCO KAOT/RCO Fact Extractor/RCO Fact Tuner
Компания «Гарант Парк Интернет» предлагает решения для синтаксического и семантического анализа текстов, используемые в продуктах других производителей, например, технологию анализа и поиска текстовой информации (RCO, Russian Context Optimizer).
В состав семейства продуктов компании входят: RCO Fact Extractor — мультиплатформный модуль анализа текстов на естественном языке; RCO Fact Tuner — графическое средство настройки правил анализа текстов, используемых Fact Extractor. Правила формулируются и сохраняются в виде текстовых файлов на специализированном языке; RCO KAOT — оболочка для работы с информацией, обработанной при помощи RCO Fact Extractor; набор сопутствующих программных модулей для решения отдельных аналитических задач. Система RCO KAOT включает в себя логико-лингвистический процессор на основе RCO Fact Extractor, сервер приложений, обеспечивающий предоставление информации пользователям, АРМ пользователей на основе тонкого клиента и утилиту Fact Tuner для формирования правил разбора текста.
Ввод документов осуществляется из папок файловой системы. Документы в виде плоского текста поступают в хранилище на базе реляционной СУБД, преобразуются к единой кодировке и разбираются в соответствии с заданными правилами синтаксического анализа средствами RCO Fact Extractor (выделяются семантические сети). На основе построенных сетей строятся ключевые темы массива документов, проводятся автоматическая кластеризация и рубрикация. Затем обработанная информация через Web-интерфейс становится доступной пользователям.
RCO KAOT — документальная информационно-аналитическая система, ориентированная на поиск и рубрикацию документов на основе средств синтаксического анализа и выделения ключевых тем, а также аналитическую обработку на основе статистического анализа ключевых тем. В своем классе продукт отличается высокой точностью поиска.
«Галактика ZOOM»
Корпорация «Галактика» предлагает систему «Галактика ZOOM», которая содержит: программу предварительной обработки поступающих в систему данных, их рубрикации, индексирования и построения информационных портретов объектов; сервер приложений, обеспечивающий предоставление информации по запросам пользователей; АРМ пользователей системы с Web-интерфейсом.
Данные в систему импортируются из различных источников и обрабатываются специализированными модулями-конвертерами, после чего происходит преобразование к единому формату хранения и размещение в системной базе данных. Затем проводится морфологический анализ, полнотекстовое индексирование документов, строятся информационные портреты документов, выделяются основные темы, документы классифицируются и кластеризуются. Выполнение поисковых и аналитических запросов осуществляется с использованием функций формирования и итеративного уточнения информационных портретов запросов и искомых документов.
ClaraBridge Document Analytics
Компания «EPAM Systems», стратегический партнер компании ClaraBridge, предлагает для крупных коммерческих предприятий BI-систему ClaraBridge, состоящую из логико-лингвистического процессора, OLAP-сервера для хранения и обработки данных и генераторов отчетов.
Документы могут вводиться в пакетном режиме из папок файловой системы или из Сети. Поступающие в систему полнотекстовые документы в форматах TXT, PDF, Microsoft Office, HTML и т.д. преобразуются адаптерами (коннекторами) к единому текстовому формату и размещаются в хранилище. Тексты документов разбираются RCO-подобными модулями, выделяемые синтаксические структуры (темы) сохраняются в БД системы и индексируются. Процесс-диспетчер по мере появления новых документов вызывает процедуры рубрикации, выделения объектов и описаний фактов, статистической обработки. Доступ пользователей к информации реализован через генератор OLAP-отчетов.
ClaraBridge — документальная информационно-аналитическая система, ориентированная на выделение и статистическую обработку ключевых тем документов, обладающая также возможностью экспорта результатов обработки ключевых тем в структурированном виде. При этом ограниченные аналитические функции системы компенсируются богатыми интеграционными возможностями.
Семейство i2
Компания «РДТЕХ» предлагает продукты семейства i2 от компании i2 Limited, соответствующие стандарту IALEAI.
Базовая комбинация семейства i2 состоит из продуктов Analyst’s Notebook, iBase и iBridge. Analyst’s Notebook — средство визуального конструирования и анализа схем и диаграмм; iBase — система управления объектными базами данных в графическом режиме; iBridge — интеграционное решение, позволяющее Analyst’s Notebook работать с различными источниками и потребителями информации.
Для начала работы в iBridge заносятся описания источников данных, но для ручного ввода данных настройка не требуется. Структурированная информация, выбранная по запросу пользователя из источников данных или непосредственно введенная им в систему, отображается в виде схемы (диаграммы) и может редактироваться и дополняться. Построенные схемы и диаграммы, а также результаты запросов могут быть сохранены для дальнейшего использования средствами iBase. Результаты со структурированной информацией могут быть экспортированы в форматах Analyst’s Notebook, Word, HTML, PDF, а также размещены в реляционных базах данных, XML-файлах.
Приложение Case Notebook предназначено для анализа развития ситуации во времени. При помощи ручного ввода данных о событиях или импорта таких данных из источников создается информационный массив, к которому в дальнейшем применяются аналитические операции.
Семейство i2 представляет собой систему визуализации структурированной информации, полученной из различных источников, агрегируемой с использованием логических процедур и анализируемой пользователями в интерактивном режиме. Система содержит широкий набор функций визуального редактирования и анализа схем данных.
Convera RetrievalWare
Компания Convera Technologies предлагает систему RetrievalWare, в которую входят сервисы-синхронизаторы, обнаруживающие изменения в источниках информации и обновляющие системную БД; модули доступа и фильтрации (AFM), обеспечивающие контентную фильтрацию, приведение поступающей информации к единому виду и ее нормализацию; конвейер индексирования, выполняющий предварительную обработку документальной информации (индексирование, рубрицирование и т.д.); сервер приложений, обеспечивающий предоставление информации по запросам пользователей.
Документальная информация выбирается из источников посредством сервисов-синхронизаторов, отслеживающих изменения в их информационных массивах. Поступающие документы обрабатываются модулями доступа и фильтрации (AFM), выполняющими их преобразование к единому формату, определение кодировки, нормализацию терминов, полнотекстовое индексирование. Локализация лексических процедур и задание предметной области осуществляется за счет использования языковых картриджей. Доступ пользователей к размещенным в системе документам, а также результатам их рубрикации и индексирования, осуществляется интерактивно (посредством Web-клиента) или программно (специализированные Web-сервисы). Результаты работы могут быть экспортированы в виде отчетов и дайджестов в форматах Word и HTML.
RetrievalWare — документальная информационно-аналитическая система, ориентированная на логическую обработку текстовой информации. Система поддерживает до 200 форматов текстовых редакторов и возможность работы с бумажным архивом, позволяет распараллелить трудоемкие операции по отдельным вычислительным машинам, имеет хорошо документированные программные интерфейсы, что позволяет создавать дополнительные программные модули и применять их совместно с существующими. Правда возможности лингвистических и семантических механизмов анализа русскоязычных текстов несколько ограничены, что может вызвать определенные трудности при практическом применении в отдельных предметных областях.
ROSES
Компания «ФОРС — Центр разработки» предлагает продукт ROSES для контекстного поиска в корпоративных сетях и Internet, основанный на технологии Oracle Secure Enterprise Search 10g, обеспечивающей безопасность системы и RCO, благодаря которой поиск можно вести на русском языке с учетом особенностей русского словообразования и тезауруса.
В отличие от существующих на данный момент поисковых машин, ROSES обеспечивает защищенный быстрый поиск нужной информации по смысловым связям во всех внутренних (корпоративных) и внешних источниках. Результаты поиска фильтруются таким образом, что пользователю становятся видимыми только ссылки на разрешенные для просмотра ресурсы. Система также имеет встроенные средства ранжирования результатов, что облегчает поиск и повышает качество полученной информации. Обеспечивается поддержка всех общепринятых форматов, в частности, txt, HTML, XML, pdf, doc, rtf.
Итого
Несмотря на достаточно большой выбор BI-систем, типовых систем для решения широкого спектра задач, обеспечивающих одинаково эффективную работу как с документальной, так и со структурированной информацией, на рынке пока нет. Возможности всех систем индивидуальны, а применяемые алгоритмы и методы обработки информации различны для схожих задач пользователей, поэтому выбор программного продукта для решения конкретных задач должен осуществляться в соответствии с поставленными перед аналитическими подразделениями целями.
Выбор программного продукта для решения задач в сфере бизнес-аналитики должен основываться на системе критериев, соответствующих потребностям пользователей конкретной организации. Такая система может фиксировать технологические характеристики BI-системы (программную платформу, интеграционные возможности, соответствие стандартам), функциональные возможности (особенности сбора, накопления, поиска и анализа информации), возможности по защите информации (разграничение доступа, резервное копирование и восстановление, защита от атак), эргономические характеристики (персонификация информации, обеспечение совместной работы и удобство пользовательского интерфейса).
Что такое Business Intelligence?
Технологии извлечения знаний из текста
Динамическая классификация для аналитиков
Информация как источник энергии
