
 Созвучие терминов Web Search и Enterprise Search может создать впечатление технологической близости двух направлений, объединенных общим словом «поиск». Бытующее заблуждение относительно их близости распространено настолько, что во многих статьях, посвященных Enterprise Search, можно встретить практически один и тот же пассаж — хотя и в разных интерпретациях. Авторы, говоря о необходимости развития технологий Enterprise Search, обычно утверждают, что пользователи корпоративных сетей сталкиваются с проблемами поиска нужной информации, поэтому они выражают неудовлетворенность, сравнивая возможности популярных поисковых систем в World Wide Web с предоставляемыми им возможностями поиска во внутренних сетях. Эта неудовлетворенность и рассматривается как стимул к развитию и совершенствованию технологий и инструментов корпоративного поиска. Если бы все было так просто, то проблема информационного обеспечения сотрудников предприятий была бы давно решена. Да, в случае, если под областью действия средств Enterprise Search понимать только поиск информации на сайтах, расположенных в корпоративных сетях, то две задачи поиска практически ничем не отличаются друг от друга. Однако есть существенное различие, которое обусловлено тем, что в качестве источников в корпоративных сетях выступают не только сайты и наполняющие эти сайты страницы, созданные по единым стандартам, но и множество иных баз данных и самых разных репозиториев структурированных и неструктурированных данных.
Созвучие терминов Web Search и Enterprise Search может создать впечатление технологической близости двух направлений, объединенных общим словом «поиск». Бытующее заблуждение относительно их близости распространено настолько, что во многих статьях, посвященных Enterprise Search, можно встретить практически один и тот же пассаж — хотя и в разных интерпретациях. Авторы, говоря о необходимости развития технологий Enterprise Search, обычно утверждают, что пользователи корпоративных сетей сталкиваются с проблемами поиска нужной информации, поэтому они выражают неудовлетворенность, сравнивая возможности популярных поисковых систем в World Wide Web с предоставляемыми им возможностями поиска во внутренних сетях. Эта неудовлетворенность и рассматривается как стимул к развитию и совершенствованию технологий и инструментов корпоративного поиска. Если бы все было так просто, то проблема информационного обеспечения сотрудников предприятий была бы давно решена. Да, в случае, если под областью действия средств Enterprise Search понимать только поиск информации на сайтах, расположенных в корпоративных сетях, то две задачи поиска практически ничем не отличаются друг от друга. Однако есть существенное различие, которое обусловлено тем, что в качестве источников в корпоративных сетях выступают не только сайты и наполняющие эти сайты страницы, созданные по единым стандартам, но и множество иных баз данных и самых разных репозиториев структурированных и неструктурированных данных.
Отмеченная разнородность источников делает бесполезным простой перенос в корпоративную среду обычных поисковых машин. Enterprise Search — совершенно отдельный сегмент ИТ и требует особых знаний. В этой области лидерами являются три относительно небольшие специализированные компании Autonomy, FAST Search&Transfer и Endeca Technologies, а не гиганты, подобные Google, Microsoft или IBM. Показательно, что состав участников рынка ведущие аналитики из Gartner и Forrester Research представляют себе примерно одинаково. Бизнес, связанный с Enterprise Search, относительно невелик (его суммарный объем в 2007 году оценивается примерно в 400 млн. долл.), но весьма динамичен. Средний ежегодный прирост данного рыночного сегмента превышает 10%, а лидеры демонстрируют темпы в диапазоне от 50 до 100%. Особенность рынка Enterprise Search заключается в доминировании европейских компаний: Autonomy — британская компания, FAST — норвежская, а Endeca — из Бостона, но с немецкими корнями.
Enterprise Search и информационное обеспечение
Необходимость в информационном обеспечении сотрудников предприятий существовала всегда. Это область действия науки, которая давно называется информатикой (information science), то есть науки об информации, ее не следует путать с сохранившимся с советских времен названием «информатика» для науки о компьютерах (computer science). Предметом информатики является изучение методов структурирования, создания, манипулирования, выделения, распределения и распространения информации между людьми, в организациях и в информационных системах. Задолго до внедрения компьютеров в бизнес существовало направление деятельности, называвшееся Information Retrieval; этот термин переводили на русский язык как «информационный поиск», а системы этого класса называли, соответственно, «информационно-поисковыми системами» (Information Retrieval System, IRS). Тогда использовались ручные процедуры для индексирования документов, создания тезаурусов и дескрипторов. Чрезвычайно важно, что эти «античные» системы предназначались для выделения информации (именно информации и именно выделения) из разных бумажных документов или, в лучшем случае, их копий на микропленке. «Выделение» — это более точное значение слова retrieval.
При переходе от ручных методов работы с данными к компьютерным открылась возможность для автоматизации основных рутинных действий, в том числе:
-
консолидация данных — сбор данных из разнородных источников и помещение их в надежное хранилище;
-
распространение данных — перенос данных из одних мест в другие, включая операции в СУБД;
-
федерация данных — виртуализированное представление разрозненных данных в форме единого источника;
-
доступ к данным — использование различных методов индексации для обеспечения доступа к данным.
Однако, как бы ни были развиты автоматизированные процедуры работы с данными, они не могут исключить участия человека в «производстве» информации. Действительно, если отбросить игру в слова, то информация рождается в сознании человека в процессе его работы с данными. На рис. 1 представлена общая картина возможных видов работ, связанных с поиском информации. На эти операции сотрудники современных офисов затрачивают 20-40% своего рабочего времени. По любым меркам это много, но экстраполяция на обозримое будущее грозит дальнейшим ухудшением ситуации: количество данных, как хорошо известно, растет по экспоненте, а методы доступа к ним совершенствуются значительно медленнее. Осознание этой диспропорции становится стимулом для развития технологий, попадающих в категорию Enterprise Search, ведь пока иного продуктивного инструмента для работы с данными, кроме поиска, не придумано: многообещающие заявления со стороны приверженцев искусственного интеллекта, среди которых «Поиск релевантных знаний» или «Понимание текстов», остались на бумаге.
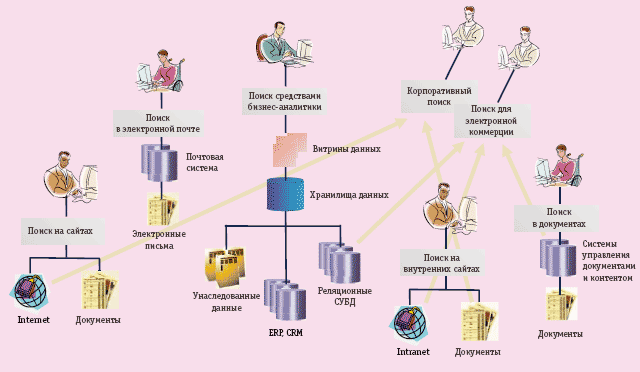
Рис. 1. Общая картина возможных видов работ, связанных с поиском информации
Поиск и только поиск, но в то же время термин Enterprise Search в качестве обобщающего названия технологического комплекса, служащего для обнаружения данных в корпоративном информационном пространстве, нельзя признать лучшим выбором. Не случайно аналитики Gartner отказались от этого термина в пользу Enterprise Information Access. При переводе на русский язык использование слова «поиск» неудачно. В приложении к обнаружению данных в Internet глагол search точнее отражает саму процедуру поиска, выделение интересующего подмножества данных, границы которого в достаточной мере размыты; при работе с корпоративными данными требуется обнаружить вполне конкретные данные, а потому здесь лучше подходит глагол find. Возможно, разумнее всего было бы использовать аббревиатуру EIA, но термин Enterprise Search уже приобрел широкие права гражданства, сохраним и мы название, задействованное прежде — корпоративный поиск, подразумевая, что термины эти тождественны. В перспективе система EIA должна обеспечить доступ ко всем корпоративным источникам данных.
Общая схема работы системы EIA (рис. 2) очевидна; она включает коннекторы к различным источникам данных, на специализированном конвейере данные обрабатываются и формируются общие индексные файлы, доступ к ним может осуществляться с использованием самых разнообразных рабочих мест.
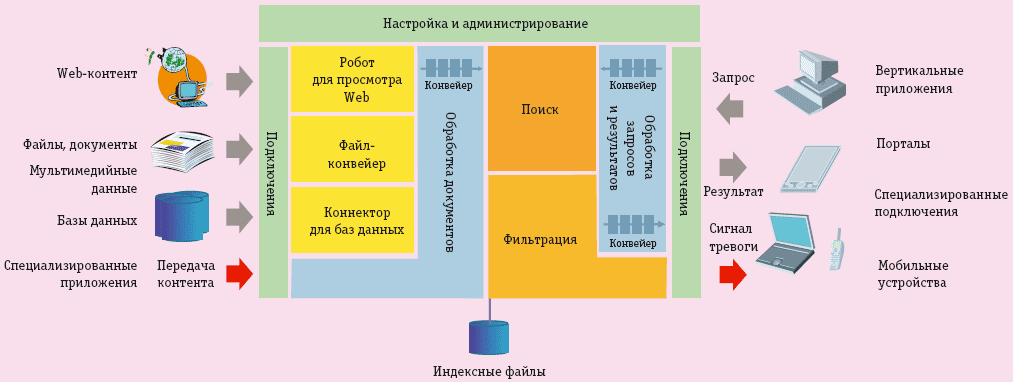
Рис. 2. Общая схема работы системы EIA
Enterprise Search 2.0
Всеобщее увлечение последних лет, выражающееся в добавлении ко всему, к чему можно, модного индекса «2.0», не миновало и доступ к корпоративной информации. Теперь все, что делалось до сих пор, обрело индекс «1.0», а новое — «2.0». Проповедники Enterprise Search 2.0 считают, что для первого поколения была характерна ориентация на данные, а основное внимание было сосредоточено на той стороне процесса поиска, которая выражается словом searching. В отличие от первого поколения второе поколение EIA ориентировано на информацию, теперь важнее поиск точных результатов (finding). Самое удивительное заключается в том, что ничего принципиально нового по сравнению с традиционными информационно-поисковыми системами не произошло. Если же присмотреться внимательнее, то несложно обнаружить, что «новое» заключается в возвращении человека в контур работы с данными; только при участии человека может быть обеспечена необходимая точность поиска.
Общее понятие о точности и релевантности поиска можно получить из рис. 3. Здесь подмножество A представляет весь релевантный запросу контент, имеющийся в информационном пространстве, где осуществляется поиск, подмножество С — результаты поиска, и подмножество В — найденные релевантные результаты. Тогда достоверность поиска выражается отношением B/A, а его точность равна отношению B/C.

Особенность парадигмы Enterprise Search 1.0 выражалась словами Single Shot Relevancy, то есть «релевантность с первого попадания». Так построены все поисковые системы World Wide Web: мы делаем один запрос и получаем нужные результаты. Мы можем как-то изменить запрос, но специальных механизмов, обеспечивающих обратную связь, не предусматривается. Однако подход Single Shot Relevancy соответствует идее поиска, выраженной термином search, предполагающим приблизительность, он обеспечивает достоверность, а в корпоративных условиях не менее важна точность, здесь критичнее find, обнаружение именно того, что требуется (рис. 4), того документа, о существовании которого пользователь знает заранее.

Для того чтобы повысить точность поиска по запросам (drill down analysis — «анализ с повышенным уровнем детализации»), не остается ничего другого, как сделать поиск «интерактивным». Для этого пользователь получает возможность, используя обратную связь, корректировать запросы и постепенно добиваться требуемой ему точности. Процедура напоминает артиллерийскую стрельбу: перелет — изменение прицела, недолет — следующее изменение и так до точного попадания в цель.
Чтобы такая процедура была эффективной, потребуются новые методы представления результатов поиска, простого списка страниц с краткой аннотацией, как это делают обычные поисковые машины, недостаточно. Результаты могут быть выданы в текстовой форме, с указанием связей между отдельными компонентами. Большие перспективы у графических форм представления результатов поиска. В особую задачу выливается необходимость работы с мультимедийными данными. Значимость этой задачи можно проиллюстрировать хотя бы тем, что повсеместно распространились камеры видеонаблюдения, но собранные ими данные до экстренных случаев лежат мертвым грузом. Можно представить себе эффект в обеспечении безопасности, если бы имелись средства для анализа. Но решение этой задачи потребует качественно новых подходов. Любые нынешние поисковые машины построены на нескольких основных принципах: данные хранятся в виде отдельных документов, поэтому для повышения производительности можно использовать распределенную архитектуру, используя метаданные, можно каким-то образом определять смысл документа и, опираясь на модели, добиваться требуемой релевантности. Ни один из имеющихся инструментов не работает в приложении к мультимедийным данным; пока это непаханое поле для будущих научных исследований.
