
Сегодня графические процессоры из устройств с традиционным фиксированным набором функций конвейера трехмерной графики постепенно превращаются в гибкий вычислительный механизм общего назначения.
В начале 90-х годов повсеместная доступность интерактивной трехмерной графики казалось чем-то из области фантастики. Однако уже к концу десятилетия почти все новые компьютеры оснащались графическим процессором (Graphics Processing Unit, GPU), предназначенным для выполнения визуально ярких интерактивных операций, требующих высокой вычислительной производительности.
Эта существенная перемена стала неизбежным следствием роста потребительского спроса на видеоигры, совершенствования технологий производства полупроводниковых компонентов и эффективного использования параллелизма при опережающем наполнении графического конвейера. Сегодня по критерию совокупной вычислительной мощности графические процессоры опережают наиболее производительные процессоры общего назначения, и разрыв этот продолжает увеличиваться.
Графический конвейер
Задача любой системы обработки трехмерной графики состоит в том, чтобы синтезировать изображение из описания сцены для графических приложений, выполняющихся в режиме реального времени; скажем, в видеоиграх на экран должно выводиться 60 кадров в секунду. Сцена включает в себя отображаемые графические примитивы, а также описание характера освещения, то есть способа отражения света каждым из объектов с учетом положения и пространственной ориентации зрителя.
Создатели графических процессоров традиционно реализовывали синтез изображения с помощью аппаратного конвейера, состоящего из ряда специализированных ступеней. Приведем общий обзор классического графического конвейера; постараемся показать, что по аналогии с рендерингом в режиме реального времени разработчики любых графических приложений могут использовать современные графические процессоры в качестве параллельных вычислительных механизмов общего назначения.
На входе конвейера
В большинстве графических систем, работающих в режиме реального времени, предполагается, что изображения состоят из треугольников. Поэтому в первую очередь необходимо разбить все возможные формы — многоугольники, сложные поверхности и прочие фигуры — на элементарные треугольники. С помощью базовой библиотеки компьютерной графики (чаще всего OpenGL или Direct3D) разработчик последовательно передает на вход конвейера по одной вершине треугольника. А графический процессор по мере необходимости собирает из этих вершин треугольники.
Преобразования модели
Графический процессор может задавать любой логический объект сцены в своей собственной локальной системе координат. Такой подход удобен для объектов, которые, как правило, задаются иерархически. Но за удобство приходится платить: перед рендерингом графический процессор должен преобразовать все объекты в общую систему координат. Чтобы предотвратить деформацию или скручивание треугольников, все преобразования должны ограничиваться простыми аффинными операциями вращения, сдвига, масштабирования и т.д.
Потребность в эффективном оборудовании, способном каждую секунду выполнять миллионы векторных арифметических операций с вещественными числами, стала одной из главных движущих сил революции графических процессоров с параллельной обработкой.
На выходе данной ступени конвейера мы получаем поток треугольников, представленных в общей трехмерной системе координат. Зритель располагается в начале координат, а взгляд его ориентирован вдоль оси z.
Освещение
При размещении каждого треугольника в глобальной системе координат графический процессор может рассчитать его цвет на основе информации об освещении сцены. В качестве примера приведем расчеты для точечного источника света (представьте себе очень маленькую электрическую лампочку). Графический процессор управляет освещением, суммируя воздействие каждого отдельно взятого источника света. При этом графический конвейер использует формулу расчета освещенности Фонга (B-T. Phong, Illumination for Computer-Generated Images. Communications of the ACM, June 1975), в основу которой положена наглядная феноменологическая модель, аппроксимирующая представление на экране материала из пластика. У таких материалов тусклое рассеянное освещение основы сочетается с ярким зеркальным блеском. В формуле освещенности Фонга цвет на выходе рассчитывается следующим образом: C=KdLi(N·L)+KsLi(R·V)s.

Моделирование камеры
На следующем этапе все цветные треугольники проецируются на плоскость виртуальной камеры. Как и при преобразовании, графический процессор решает эту задачу путем умножения матрицы на вектор. Это также подчеркивает важность эффективного выполнения векторных операций на аппаратном уровне. На выходе этой ступени конвейера мы получаем поток треугольников в экранных координатах. Все готово к преобразованию в пикселы.
Растеризация
Все попадающие в экранное пространство треугольники отображаются на дисплее в виде некоторого набора пикселов. Процедуру определения этих пикселов называют растеризацией. На сегодняшний день создатели графических процессоров реализовали множество алгоритмов растеризации, но все они подчиняются одному принципу: воздействие на каждый конкретный пиксел осуществляется независимо от остальных. Благодаря этому система может обрабатывать все пикселы в параллель; существуют даже экзотические архитектуры, где управление каждым пикселом осуществляется с помощью отдельного процессора. Соблюдение этого непременного условия независимости привело к тому, что разработчики графических процессоров создают конвейеры со все более высокой степенью параллелизма.
Обработка текстур
Для повышения реализма на поверхности часто накладываются так называемые «текстуры». Таким образом, создается ощущение дополнительной проработки изображения. Графические процессоры хранят текстуры в высокоскоростной памяти. При проведении расчетов процессор обращается к этой области памяти для уточнения окончательного цвета пикселов.
На практике графическому процессору может потребоваться попиксельный доступ к различным текстурам для получения более точного визуального представления; в частности, такая потребность возникает, если текстуры оказываются больше или меньше фактического разрешения экрана. Поскольку характер обращений к памяти текстур обычно носит регулярный характер (соседним пикселам, как правило, требуется информация о фрагментах текстур, расположенных в непосредственной близости друг от друга), задержки, возникающие при операциях чтения из памяти, удается компенсировать за счет оптимизации устройства буфера.
Скрытые поверхности
В большинстве сцен одни объекты оказываются загорожены другими. Если бы каждый пиксел просто записывался в память дисплея, на переднем плане появлялись бы треугольники, рассчитанные последними. В результате при выводе на экран каждого очередного представления необходимо сортировать все треугольники, от заднего до переднего плана, для правильной обработки скрытых поверхностей. Это дорогостоящая операция, выполнить которую удается не для любых сцен.
Все современные графические процессоры имеют буфер глубины — область памяти, в которой хранится информация о расстоянии от каждого пиксела до зрителя. Перед выводом на дисплей графический процессор сравнивает расстояние от зрителя до текущего пиксела с расстоянием до того пиксела, который уже отображен на экране. Текущий пиксел выводится на экран только в том случае, если он расположен ближе к зрителю.
Совершенствование графических конвейеров
 В процессе своей эволюции графические процессоры прошли путь от графических конвейеров с жесткой логикой до программируемых вычислительных сред, способных осуществлять поддержку таких конвейеров. Устройства с фиксированным набором функций, предназначенные для преобразования вершин и текстурных пикселов, вошли в состав более обширного семейства процессоров-шейдеров, способных решать не только эти, но и многие другие задачи. В ходе эволюции на протяжении нескольких поколений отдельные ступени конвейеров постепенно вытеснялись программируемыми устройствами. К примеру, в процессоре Nvidia GeForce 3, выпущенном в феврале 2001 года, появились программируемые шейдеры вершин. В этих шейдерах устройства, предназначенные для выполнения умножения матрицы на вектор, дополнились механизмами вычисления экспоненциальных функций, извлечения квадратных корней, а также короткой предопределенной программой, обеспечивавшей трансформацию вершин и расчет освещения.
В процессе своей эволюции графические процессоры прошли путь от графических конвейеров с жесткой логикой до программируемых вычислительных сред, способных осуществлять поддержку таких конвейеров. Устройства с фиксированным набором функций, предназначенные для преобразования вершин и текстурных пикселов, вошли в состав более обширного семейства процессоров-шейдеров, способных решать не только эти, но и многие другие задачи. В ходе эволюции на протяжении нескольких поколений отдельные ступени конвейеров постепенно вытеснялись программируемыми устройствами. К примеру, в процессоре Nvidia GeForce 3, выпущенном в феврале 2001 года, появились программируемые шейдеры вершин. В этих шейдерах устройства, предназначенные для выполнения умножения матрицы на вектор, дополнились механизмами вычисления экспоненциальных функций, извлечения квадратных корней, а также короткой предопределенной программой, обеспечивавшей трансформацию вершин и расчет освещения.
В процессоре GeForce 3 появились и средства ограниченного конфигурирования системы обработки пикселов. Аппаратные возможности обработки текстур была дополнена механизмом комбинирования регистров (register combiner), благодаря которым удалось создать новые визуальные эффекты, например эффект «мыльного пузыря», продемонстрированный на рис. 1. Затем гибкость графических процессоров еще увеличилась, добавились средства поддержки длинных программ, появились дополнительные регистры, а также новые примитивы управляющей логики (в том числе операции ветвления, циклы и подпрограммы).
В процессорах ATI Radeon 9700 (июль 2002 года) и Nvidia GeForce FX (январь 2003 года) на смену не всегда удобному комбинированию регистров пришли полностью программируемые шейдеры пикселов. В выпущенном в ноябре 2006 года процессоре Nvidia GeForce 8800 функции программирования появились на этапе сборки примитивов. Благодаря этому разработчики получили возможность управлять построением треугольников из трансформированных вершин. Рис. 2 показывает, что современные графические процессоры позволяют добиться потрясающей реалистичности изображений.
 Повышение точности сопровождалось увеличением «программируемости». Первоначально графический конвейер обеспечивал представление каждого цветового канала только 8-разрядным целым числом. Таким образом, количество значений может варьироваться от 0 до 255. В процессоре ATI Radeon 9700 цвет кодировался уже 24-разрядным вещественным числом, а в Nvidia GeForce FX — 16-разрядными и 32-разрядными числами. Обе компании заявляют, что в будущих процессорах для представления цвета будут использоваться 64-разрядные вещественные числа двойной точности.
Повышение точности сопровождалось увеличением «программируемости». Первоначально графический конвейер обеспечивал представление каждого цветового канала только 8-разрядным целым числом. Таким образом, количество значений может варьироваться от 0 до 255. В процессоре ATI Radeon 9700 цвет кодировался уже 24-разрядным вещественным числом, а в Nvidia GeForce FX — 16-разрядными и 32-разрядными числами. Обе компании заявляют, что в будущих процессорах для представления цвета будут использоваться 64-разрядные вещественные числа двойной точности.
Чтобы удовлетворить неослабевающий спрос на эффективные средства работы с графикой, производители графических процессоров активно совершенствуют возможности параллельной обработки. В графических процессорах уже достаточно длительное время используются регистры векторной обработки учетверенной длины, напоминающие те, которые включены в современные процессоры Intel для выполнения инструкций Streaming SIMD Extensions (SSE). Количество таких процессоров, работающих параллельно, также увеличилось с четырех в GeForce FX до 16 в модели GeForce 6800 (апрель 2004 года) и до 24 в процессоре GeForce 7800 (май 2005-го). Графический процессор GeForce 8800 содержит 128 скалярных шейдеров, работающих на особой тактовой частоте, которая в два с половиной раза опережает (по отношению к скорости вывода пикселов) более ранние процессоры. Таким образом, их вычислительную мощность можно считать эквивалентной 128 ·2,5/4 = 80 шейдерам пикселов учетверенной длины.
Объединенные шейдеры
Последним этапом эволюционного перехода от жесткого конвейера к гибкой вычислительной структуре стало появление объединенных шейдеров. Они впервые были реализованы в процессоре ATI Xenos, предназначенном для игровой приставки Xbox 360, а компания Nvidia предложила свой вариант такого рода решения в процессоре GeForce 8800, предназначенном для ПК.
Вместо встраивания отдельных процессоров для ретушеров вершин, геометрических ретушеров и шейдеров пикселов в архитектуре унифицированных шейдеров реализована одна большая сеть распределенных вычислений; мощности процессоров параллельной обработки вещественных данных достаточно для решения всех трех задач. На рис. 3 показано, что вершины, треугольники и пикселы обрабатываются распределенной сетью, вместо того чтобы проходить через конвейер со ступенями фиксированной длины.
Данная конфигурация повышает эффективность работы графического процессора в целом, потому что спрос на различные шейдеры может варьироваться в широких пределах в зависимости от особенностей, присущих разным приложениям и даже различным частям одного приложения. К примеру, видеоигра может начинаться с формирования изображения неба и удаленной местности на основе крупных треугольников. В этом случае очень быстро исчерпываются ресурсы шейдеров пикселов традиционного конвейера, в то время как ресурсы шейдеров вершин остаются практически нетронутыми. Но по прошествии всего лишь одной миллисекунды играющий может задействовать средства работы с детализированными геометрическими объектами для отображения сложных персонажей. В данной ситуации загружены уже шейдеры вершин, а на шейдеры пикселов нагрузки почти никакой.

В данном примере GeForce 8800 при отображении неба мог бы использовать 90% имеющихся в его распоряжении 128 процессоров в качестве шейдеров пикселов, а 10% — в качестве шейдеров вершин. При формировании фигуры удаленного персонажа соотношение меняется на противоположное. В результате мы получаем гибкую параллельную архитектуру, которая повышает эффективность использования ресурсов графического процессора и предоставляет более широкие возможности разработчикам игр.
GPGPU
Высокий уровень параллельной нагрузки, характерный для трехмерной компьютерной графики, воспроизводимой в режиме реального времени, предъявляет крайне высокие требования к пропускной способности арифметического блока и потоковой памяти, но вместе с тем допускает весьма существенные задержки при выполнении отдельных вычислительных операций, поскольку окончательное изображение выводится с интервалом в целых 16 миллисекунд. Подобные характеристики рабочей нагрузки определяют базовую архитектуру графического процессора. Если процессор общего назначения оптимизируется с учетом требования минимизации задержек, то для графического процессора главное — оптимизация пропускной способности.
Суммарная вычислительная мощность графических процессоров потрясает. На простых тестах (graphics.stanford.edu/projects/gpubench) производительность GeForce 8800 достигает 330 GFLOPS (миллиардов операций над вещественными числами в секунду). Растущая вычислительная мощность, программируемость и точность графических процессоров заставляет заняться исследованием возможностей их применения в качестве графического вычислительного устройства общего назначения (general-purpose graphics processing unit, GPGPU). Исследователи, взявшие на вооружение подход GPGPU, используют графический процессор в качестве вычислительного сопроцессора, а не устройства синтеза изображений.
Специализированная архитектура графических процессоров хорошо подходит для реализации не любого алгоритма. Многие приложения ориентированы на последовательную обработку, для них характерны непредсказуемые всплески обращений к памяти. Вместе с тем многие важные задачи требуют значительных вычислительных ресурсов и хорошо укладываются в характерную для графического процессора схему интенсивной многоядерной арифметической обработки. Другим нужна высокая пропускная способность при обработке больших объемов данных, и тут уже в полном блеске может продемонстрировать себя подсистема потоковой памяти графического процессора.
Перенос правильно подобранного алгоритма на платформу графического процессора зачастую помогает в 5-20 раз увеличить производительность по сравнению с выполнением на современном процессоре общего назначения хорошо написанного, оптимизированного кода. А некоторые алгоритмы, особенно удачно ложащиеся на архитектуру графического процессора, позволяют добиться стократного роста производительности.
Среди заметных успехов идеи GPGPU следует отметить проект Стэнфордского университета Folding@home, в ходе которого пользователи со всего мира предоставляли свободное время своих процессоров для решения задач, связанных с изучением структуры белка (folding.stanford.edu). Новый клиент Folding@home, учитывающий особенности графических процессоров, буквально за месяц подарил участникам проекта дополнительные 28000 GFLOPS. Это на 18% превышает общее число операций с плавающей запятой, которое выполнили в рамках проекта процессоры общего назначения Windows-компьютеров начиная с октября 2000 года.
Еще один успех GPGPU связан с работами исследователей из университета штата Северная Каролина и корпорации Microsoft. С помощью кода, разработанного для графического процессора, они одержали победу на конкурсе TeraSort в категории 2006 Indy PennySort, быстрее других выполнив тестовый пример сортировки соотношения между ценой и производительностью для операций базы данных (gamma.cs.unc.edu/GPUTERASORT). Разработчикам библиотеки HavokFX (www.havok.com), предназначенной для расчета различных физических эффектов, с помощью технологии GPGPU удалось добиться десятикратного ускорения вычислений, позволяющих обеспечить реалистичное поведение объекта в компьютерных играх.
Давид Любке (dluebke@Nvidia.com) — научный сотрудник компании NVIDIA Research; Грег Хамфрис (humper@cs.virginia.edu) — преподаватель Университета штата Вирджиния.
David Luebke, Greg Humphreys. How GPUs Work. IEEE Computer, February, 2007. IEEE Computer Society, 2007. All rights reserved. Reprinted with permission.
Однородные координаты
Точка трехмерного пространства обычно задается триадой координат (x, y, z). Однако в компьютерной графике часто бывает полезным ввести четвертую координату w. Для перевода точки в новое представление принимаем w = 1. При восстановлении оригинального представления производим следующее преобразование: (x, y, z, w) -> (x/w, y/w, z/w).
На первый взгляд такое преобразование может показаться ненужным усложнением, но тем не менее, оно сулит ряд существенных преимуществ. К примеру, неопределенную точку (x, y, z, 0) можно использовать для представления направляющего вектора (x, y, z). При таком унифицированном представлении точек и векторов ряд полезных преобразований, сводится к простому умножению матрицы на вектор; в противном случае это оказалось бы невозможным. К примеру, операции умножения
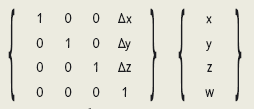
Кроме того, подобные матрицы можно использовать для выполнения полезных нелинейных преобразований, в частности при создании эффекта перспективы.
