
Доминирующая архитектура современных суперкомпьютерных систем — это кластеры с большим числом узлов. Популярные еще совсем недавно массово-параллельные системы с физически и логически распределенной оперативной памятью на базе универсальных микропроцессоров в рейтинге TOP500 представлены лишь продукцией IBM и Cray, да еще рядом уникальных экземпляров, не имеющих доступных на рынке аналогов. Особое место в последнем, июньском списке крупнейших суперкомпьютеров мира занимает IBM Blue Gene/L.

Прежде всего, абсолютным лидером рейтинга TOP500 с производительностью 281 TFLOPS на тестах Linpack является инсталляция BG/L в Ливерморской национальной лаборатории США. Кроме того, в первой десятке представлено сразу три BG/L, в то время как всех остальных типов вычислительных систем — по одному. Наконец, в TOP500 вошли целых 25 инсталляций BG/L, а массово-параллельных систем Cray XT3/XD1 на базе AMD Opteron — только 16. Вместе с тем, подавляющее большинство (а именно 364) суперкомпьютерных систем в TOP500 являются кластерами. Поэтому закономерен вопрос, сохраняют ли системы с массовым параллелизмом (МРР-системы) серьезные перспективы?
Проанализируем архитектуру и технические характеристики BG/L и, в частности, постараемся определить, в чем состоят преимущества и возможные недостатки подобных систем по сравнению с более распространенными кластерами.
Цели и подходы
Задачей, стоявшей перед инженерами IBM при разработке BG/L, было создание универсальной масштабируемой, высоконадежной и одновременно компактной суперкомпьютерной системы, которая потребляла бы не слишком много электроэнергии. Большинство характеристик в этом перечислении носит относительный характер. Так, «компактность» — характеристика, безусловно, относительная: речь идет о более плотной упаковке — максимум GFLOPS в единице объема.
«Не слишком много электроэнергии» говорит о стремлении максимизировать производительность в расчете на 1 Вт. Учитывая, что максимальная конфигурация BG/L с пиковой производительностью 367 TFLOPS «тянет» на 10-20 МВт, об относительности напоминать уже не стоит.
В IBM всерьез задумались об электропитании уже давно. Сегодня, когда уже не первый год все производители вплоть до разработчиков самой массовой х86-платформы, компаний Intel и AMD, говорят о снижении затрат на энергопотребление, это стало общим местом. IBM приводит простенькую оценку, показывающую, что производительность (Пт) в расчете на одну стойку определяется производительностью в расчете на 1 Вт. Действительно, имеем
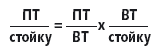
Между тем усовершенствования в электрической инфраструктуре идут очень медленно по сравнению с экспоненциальным прогрессом в производительности процессоров, и второй сомножитель, электрическая мощность стойки, для воздушного охлаждения остается, грубо говоря, константой порядка 20 Квт [2]. Стремление увеличить производительность стойки, а значит производительность в расчете на 1 Вт, и привело IBM к разработке столь оригинальной системы, как BG/L.
Наконец, что касается относительности характеристики «универсальность», ясно, что архитектура BG/L спроектирована в расчете на отличающиеся высокой масштабируемостью приложения, то есть такие, которые эффективно могут использовать большое количество процессоров. Поэтому BG/L универсальна по крайней мере, в смысле противостояния специализированным МРР-системам, таким, как QCDOC и QCSDP [3], спроектированным для решения задач ядерной физики.
Интересно проследить, используя какие подходы, в IBM решили достичь указанные цели. Во-первых, разработчики воспользовались не современными высокочастотными микропроцессорами, а процессорами с относительно низкой частотой и довольно «средней» производительностью. Как утверждается, это позволяет увеличить производительность в расчете на один ватт. Во-вторых, использована так называемая «система на кристалле» (system on chip, SoC), интегрированное решение, основная микросхема которого содержит все основные компоненты «нормального» компьютера.
В случае BG/L это вылилось в разработку специализированной микросхемы (ASIC), которая помимо двух микропроцессоров содержит также средства поддержки сетевой обработки. Это позволяет добиться не только высокой интеграции, но и низкого энергопотребления и низкой стоимости конструирования BG/L. Наконец, высокая степень интеграции, несомненно, способствует повышению надежности и доступности BG/L.
Среди ключевых архитектурных особенностей BG/L следует указать на межсоединение вычислительных узлов с топологией трехмерного (3D) тора, благодаря аппаратной поддержке передачи коротких сообщений имеющее низкие задержки.
Применяются и дополнительные сети для коллективных операций (учитывая естественную ориентацию BG/L на работу со средствами распараллеливания MPI, можно говорить об аппаратной поддержке соответствующих вызовов), для ввода/вывода и др. Дополнительные сети имеют, вообще говоря, иную топологию.
Отметим, что в архитектуре других популярных MPP-систем от Cray также используется межсоединение с топологией 3D-тора, однако их разработчики придерживаются другого подхода: они строят суперкомпьютеры на базе «традиционных» высокопроизводительных микропроцессоров (в данном случае AMD Opteron [1]).
В IBM, хоть и широко использовали собственные наработки при создании микросхем ASIC для BG/L, были вынуждены отказаться от высокопроизводительных процессоров Power4/5 или PowerPC 970, применение которых в иной ситуации казалось бы очевидным. Задача уменьшения частоты потребовала и других процессорных ядер, в качестве которых в BG/L использованы менее известные широкому кругу специалистов PowerPC 440/700 МГц. А блок операций с плавающей запятой и вовсе был разработан специально и располагается вне ядер PowerPC 440.
Общая архитектура BG/L
Назовем основные компоненты архитектуры BG/L. Это двухпроцессорные вычислительные узлы общим числом до 65536, связанные сетью с топологией 3D-тора (рис. 1), узлы ввода/вывода, а также четыре типа дополнительных сетей: коллективная (для коллективных MPI-операций), барьерная (для операций MPI_barrier), Gigabit Ethernet (для узлов ввода/вывода) и управляющая сеть [2, 4].
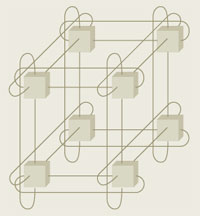 |
| Рис. 1. 3D-тор 2х2х2 |
Кроме того, в составе BG/L обязательно имеется сервисный узел (это вообще характерно для суперкомпьютеров, начиная еще с Cray-1), фронтальные узлы (с ними пользователи работают через традиционный вход наподобие login) и файловые серверы. Все это «фронтальное хозяйство» объединяется коммутаторами Gigabit Ethernet (рис. 2). Наконец, из-за конструктивных требований построения больших конфигураций со многими стойками в архитектуре BG/L представлены так называемые «канальные микросхемы» (Link Chip, LC).
Канальные микросхемы служат в первую очередь для того, чтобы организовать межстоечные связи, в том числе для сети 3D-тора. Если внутри стоек разводка основана на применении «срединных плат» (midplane), то между стойками организуются кабельные соединения. Канальные микросхемы как раз и обеспечивают порты, к которым подсоединяются кабельные разъемы.
Чтобы завершить краткое обсуждение конструктива BG/L, добавим, что эти вычислительные системы имеют целый ряд плат разных уровней. Прежде всего, это вычислительные платы, содержащие по два вычислительных узла (т.е. четыре процессора) и оперативную память. Емкость оперативной памяти вычислительной платы равна 1 Гбайт, или 512 Мбайт на узел. Сегодня это уже недостаточно и является узким местом BG/L; однако надо иметь в виду, что разработка BG/L была завершена несколько лет назад.
Еще одна пара узлов образует плату ввода/вывода. По сравнению с вычислительной платой здесь дополнительно поддерживаются соединения Gigabit Ethernet, а емкость памяти увеличена вдвое. Узлы ввода/вывода не содержат жестких дисков: эти узлы являются лишь посредниками в доступе к файловым серверам (рис. 2). Вычислительные узлы работают с Unix-подобными ядрами CNK (Compute Node Kernel), которые переадресовывают системные вызовы ввода/вывода на соответствующие узлы.
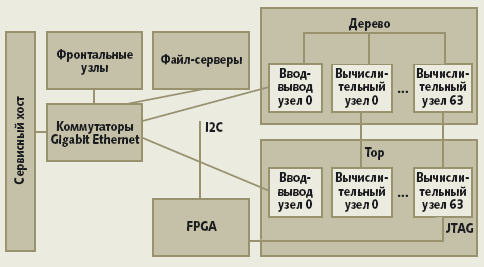 |
| Рис. 2. Архитектура BG/L |
Вычислительные платы вставляются в слоты так называемых «плат вычислительного узла» (два ряда по восемь вычислительных плат). Наконец, в срединную плату стойки монтируется до 32 плат узлов; таким образом в одной стойке размещается 2048 процессоров [4]. Напомним, что срединные платы отличаются от более распространенных «задних плат» (backplane) тем, что у первых слоты расположены с двух сторон. Нетрудно подсчитать, что в максимально допустимой на сегодня конфигурации BG/L, включающей 64 стойки, число процессоров достигает впечатляющего значения — 131072. Такое сверхбольшое число процессоров и есть причина сверхвысокой производительности.
В дополнение к перечисленным платам в BG/L представлены еще так называемые «платы каналов». Каждая из плат каналов содержит по шесть канальных микросхем и вставляется в слоты срединной платы. Всего на срединной плате монтируется четыре платы каналов.
Основное межсоединение узлов
Основным межсоединением вычислительных узлов в BG/L является сеть с топологией 3D-тора 64х32х32 [2, 5]. Это высокомасштабируемая сеть, в которой аппаратно поддерживается передача в том числе коротких сообщений (до 32 байт) с низкими задержками. Сообщения передаются непосредственно между парами узлов.
Пропускная способность при передаче от данного узла к соседним узлам в торе совпадает с пропускной способностью передачи в удаленные узлы (строго говоря, это справедливо при отсутствии загрузки сети). Симметрия узлов вызвана отсутствием «границ» 3D-тора, отличающегося этим от обычной трехмерной решетки, у которой узлы «на поверхности» имеют другое число ближайших соседей.
Понятно, что передача данных в 3D-торе в общем случае сопровождается транзитом через промежуточные узлы, а потому пропускная способность может варьироваться. Больший эффект дает применение BG/L при распараллеливании приложений, которые отличаются «локальными» (с точки зрения 3D-пространства) коммуникациями. Ясно, что очень естественно отображаются в эту технологию различные методы сеток.
Вероятно, это также способствует популярности топологии 3D-тора, которая широко применялась, например, в Cray T3E [6] и, как уже отмечалось, используется и в современных MPP-компьютерах Cray.
Сигнальная скорость каналов 3D-тора в каждом направлении в BG/L равна 1,4 Гбит/с. Каждый узел имеет шесть двунаправленных каналов, итого общая пропускная способность узла составляет 2,1 Гбайт/с [2]. Для сравнения, пиковая пропускная способность Infiniband 4xDDR равна 2,5 Гбайт/с. Аппаратная задержка 3D-тора при прохождении узла равна примерно 100 нс, так что максимальная задержка при полной конфигурации 64х32х32 составляет примерно 6,4 мкс (32 + 16 + 16 = 64).
Маршрутизация в торе происходит «на лету» (cut-through), и программное обеспечение узлов в ней не задействовано. Пакеты передаются по кратчайшему пути к узлу-получателю, с возможностью динамического выбора менее нагруженного пути. Такая адаптивность маршрутизации позволяет достичь высокой производительности даже при большой нагрузке.
В аппаратуре поддерживается режим широковещательной рассылки (multicast), что повышает ее эффективность. Наконец, имеется поддержка четырех виртуальных каналов, разделяющих аппаратные каналы связи, но имеющих собственные буферы. Виртуальные каналы могут задействоваться библиотекой MPI.
Каждая стойка (а точнее ее срединная плата) содержит решетку узлов 8х8х8, а «на поверхности» решетки используются кабели, соединяющие данную стойку с другими. Тор образуется с применением техники чередования стоек, что позволяет избежать прокладывания очень длинных кабелей, связывающих в тор «концевые» стойки. Эта техника хорошо известна в кольцевой топологии и применяется, например, для связи узлов с кластерным межсоединением SCI. Так, если нужно связать между собой шесть стоек в кольцо (или шесть узлов в SCI), то они соединяются между собой в порядке 1-3-5-6-4-2-1.
В 3D-торе применяются пакеты переменной длины, кратной 32 байтам (максимум 256 байт). Первые 8 байт пакета образуют заголовок канального уровня, который содержит номер пакета в последовательности, наименование узла-получателя, номер виртуального канала и размер пакета. (В заголовке содержатся и так называемые hint-биты; скажем, 100100 означает передачу пакета в положительном х-направлении и в отрицательном у-направлении.) Таблиц маршрутизации как таковых нет; вся информация о маршрутизации формируется программно, что и обеспечивает адаптивность маршрутизации.
Отдельных маршрутизаторов и плат адаптеров в этой сети не существует; вся аппаратура интегрирована в «вычислительную» ASIC-микросхему.
Чтобы обеспечить надежность коммуникаций, для данных заголовка применяется 1 байт с циклической контрольной суммой (СRC). Кроме того, к каждому пакету добавляется еще 24 бита CRC уже для всего пакета. Для обнаружения ошибок и восстановления после сбоя используются процедуры, аналогичные применяемым в коммутаторе IBM High Performance Switch или в HiPPI-6400 [5].
Важнейшая особенность BG/L — возможность разбиения всего компьютера на разделы. Парционирование в BG/L служит немного для иных целей, чем обычное парционирование, позволяющее кроме балансировки нагрузки применять разные операционные системы в разных разделах [7]. В архитектуре BG/L, ориентированной на применение MPI, каждому заданию нужно выделить некий поднабор процессоров, которые при распараллеливании будут монопольно использоваться этим заданием. Каждое задание запускается с определенным числом выделенных процессоров, которые образуют собственный раздел («маленький» тор). Разделы формируются динамически, при запуске задания на выполнение, используя программное обеспечение системы распределения ресурсов.
Канальные микросхемы, кроме того что они вовлечены в коммуникации между стойками, обеспечивают также аппаратную поддержку парционирования. Эти микросхемы направляют сигналы по кабелям для организации межстоечных коммуникаций и осуществляют перенаправление сигналов между своими различными портами. Канальная микросхема имеет в общей сложности шесть портов. Порты «А» и «B» напрямую связаны с узлами на срединной плате, а другие четыре порта соединены с кабелями.
Внутри канальной микросхемы может поддерживаться статическая маршрутизация любого порта с любым другим. Такая маршрутизация устанавливается хостом при создании раздела и изменяется только после его реконфигурации.
Канальные микросхемы применяются и для повышения надежности и готовности; при отказе аппаратуры узла он выводится из конфигурации путем перенаправления соединений с использованием канальных микросхем. Кроме того, канальные микросхемы имеют порты шин JTAG для работы с сетью управления BG/L.
Дополнительные сети
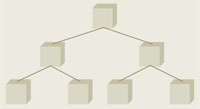 |
| Рис. 3. Коллективная сеть |
Глобальная коллективная сеть. Вызовы MPI_bcast могут реализовываться с использованием колец 3D-тора. Однако для широковещательной рассылки небольших сообщений, когда важна низкая задержка, в BG/L применяется специальная коллективная сеть. Эта операция может выполняться по всей сети или по поднабору узлов с задержкой не более 5 мкс.
Каждый канал коллективной сети имеет пропускную способность 2,8 Гбит/с, передавая и принимая 4 бита за такт процессора. Топология коллективной сети — дерево (рис. 3), что естественно для операций подобного рода. Соответственно, узел может иметь порты к трем каналам. Для широковещательных рассылок коротких сообщений применение коллективной сети целесообразно, но, начиная с некоторого размера сообщения, лучше применять тор, имеющий более высокую пропускную способность.
Аппаратные средства коллективной сети умеют выполнять целочисленные операции нахождения минимума в рамках глобальной сети, максимума, суммы, побитовые логические операции AND, OR, XOR. Глобальная сумма над числами с плавающей запятой требует порядка 10 мкс и два прохода по сети: на первом проходе вычисляется максимальная величина степени, а на втором складываются сдвинутые мантиссы.
В каждом разделе образуется своя собственная коллективная сеть. Маршрутизация в коллективной сети является статической.
Барьерная сеть. Это еще одна независимая сеть BG/L, которая служит для поддержания функций MPI_barrier и обеспечивает исключительно низкую задержку, всего 1,5 мкс на 64 тыс. узлов. Она также служит для целей диагностики и обработки глобальных прерываний.
Управляющая сеть. BG/L, особенно в больших конфигурациях, имеет огромное число потенциальных объектов диагностики — микросхем, термических сенсоров, блоков питания, вентиляторов и т.д. Мониторинг всего этого хозяйства осуществляет хост, использующий каналы Fast Ethernet. Специальные FPGA-микросхемы конвертируют пакеты Ethernet в традиционные управляющие сети I2C и JTAG (рис. 4). JTAG используется для процедуры начальной загрузки и отладочного доступа ко всем узлам.
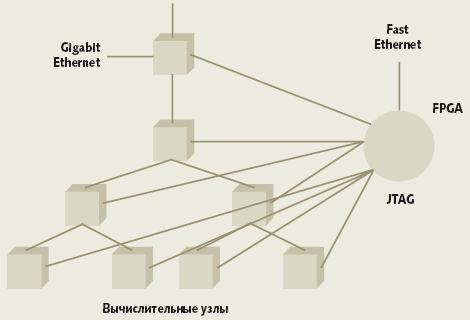 |
| Рис. 4. Управляющая сеть |
Сеть Gigabit Ethernet. Узлы ввода/вывода используют Gigabit Ethernet для доступа (через внешние коммутаторы) к параллельным файловым системам и внешним хостам. Число самих узлов ввода/вывода является конфигурируемым; максимальное отношение числа узлов этого типа к числу вычислительных узлов равно 1:8. Если это отношение равно 1:64, то в 64 стойках окажется 1024 узла ввода/вывода с агрегатной пропускной способностью ввода/вывода свыше 1 Тбит/с [2].
Узлы BG/L
Вычислительная микросхема BLC узлов BG/L построена по технологии IBM Cu-11 (КМОП, 130 нм). Она включает в себя два ядра PowerPC 440, устройство с плавающей запятой (FPU), память eDRAM (embedded DRAM), интегрированный контроллер DDR SDRAM, адаптер Gigabit Ethernet, буферы для маршрутизации на лету и средства управления сетями, в том числе 3D-тором и коллективной. Микросхемы BLC в вычислительных узлах и узлах ввода/вывода одинаковы, но Gigabit Ethernet используют только узлы ввода/вывода.
Основные блоки BLC представлены на рис. 5. Если ядра PowerPC 440 были, естественно, разработаны ранее, то некоторые другие блоки BLC, в том числе FPU, специально созданы для BG/L.
Ядра PowerPC 440 работают на тактовой частоте 700 МГц и могут выполнять до двух команд за такт. PowerPC 440 — это 32-разрядный суперскалярный процессор с расширенной архитектурой PowerPC и тепловыделением на уровне 1 Вт.
Конечно, 32-разрядность могла бы считаться минусом, поскольку серьезно ограничивает максимальную емкость оперативной памяти узла. Однако реальная емкость памяти в вычислительных узлах и того меньше — всего 512 Мбайт, и в этих условиях 32 разряда не могут считаться недостатком.
Основной конвейер PowerPC 440 имеет всего семь стадий (даже в «старинном» MIPS R4400 их было восемь) и может выполнять за такт две выборки команды или два декодирования, а также — внеочередным образом — выдачу, диспетчеризацию, выполнение и завершение двух команд. А всего конвейеров в PowerPC 440 три: для команд загрузки регистров и записи в оперативную память; простой целочисленный; комбинированный. Последний, кроме сложных целочисленных команд, выполняет системные команды и переходы. В процессоре применяется динамическое предсказание переходов с использованием таблицы предыстории BHT и кэша адресов переходов BTAC.
Файл 32-разрядных регистров общего назначения (всего их 32) имеет девять портов — шесть для чтения и три для записи. Этот файл имеется в двух экземплярах. Команды умножения, «умножить и сложить» полностью конвейеризированы и завершаются на каждом такте.
Кэши команд и данных первого уровня имеют емкости по 32 Кбайт при длине строки кэша 32 байт, являются 64-канальными наборно-ассоциативными и используют циклический алгоритм замещения round robin. Кэш данных первого уровня может работать в режимах обратной и сквозной записи. Полностью ассоциативный буфер быстрой переадресации TLB содержит 64 строки и является общим для команд и данных.
В структуре PowerPC 440 предусмотрена шина PLB (Procesor Local Bus) шириной 128 бит; она работает на половинной частоте процессора и объединяет три интерфейса: чтения/записи данных и чтения команд.
Блок FPU, подсоединяясь к имеющимся у PowerPC 440 портам APU (Auxuliary Processor Unit), выступает в качестве некого сопроцессора. Фактически FPU состоит из двух одинаковых частей. Каждая из них может завершать две команды «умножить и сложить» за такт, что дает темп четыре операции с плавающей запятой за такт и соответственно пиковую производительность 2,8 GFLOPS.
По мнению разработчиков, из-за ограничений пропускной способности памяти сильно увеличить эту величину в BG/L нельзя [2]. Таким образом, с точки зрения производительности с плавающей запятой, вычислительные узлы BG/L в разы уступают современным высокопроизводительным процессорам (например, 12 GFLOPS у каждого ядра Intel Xeon Woodcrest/3 ГГц).
FPU являются суперскалярными процессорами, выдающими на выполнение до двух команд, с внеочередным выполнением и завершением. В FPU поддерживаются SIMD-расширения архитектуры PowerPC.
Кроме кэша первого уровня, ядра PowerPC 440 используют очень небольшой кэш второго уровня (см. таблицу ), раздельный — для чтения и для записи, который служит в основном для предварительной (опережающей) выборки и буферов обратной записи кэша первого уровня. Длина строки в кэшах второго и третьего уровня — 128 байт.
Кэш третьего уровня (eDRAM, емкостью 4 Мбайт) может быть разбит на две секции, размеры которых можно изменять. Одна из них используется для отображения памяти, другая — как собственно кэш третьего уровня. Кэш может работать в режиме обратной записи и является общим для процессорных ядер. Кроме кэша третьего уровня, в BLC имеется общий для обоих ядер SRAM-кэш (рабочая память) емкостью 16 Кбайт с низкой задержкой и высокой пропускной способностью, которая используется для межпроцессорных коммуникаций и в том числе обеспечения работы механизма замков [8].
Контроллер памяти DDR-типа в BLC может обеспечивать пропускную способность 5,5 Гбайт/с. По утверждению разработчиков, пропускная способность в используемой иерархии кэшей трех уровней и оперативной памяти близка к максимуму, достижимому PowerPC 440 [2]. Следует отметить, что инженеры IBM всегда отличались умением создавать хорошо сбалансированные в смысле производительности микропроцессоры.
Заключение
Архитектура BG/L обладает большим числом абсолютно оригинальных черт. Кроме наличия целого семейства различных сетей, нельзя не упомянуть и возможность выделения одного из процессорных ядер в BLC исключительно для целей коммуникаций, и развитые средства обеспечения надежности и доступности, и многое другое.
Очевидными преимуществами (в том числе по сравнению с кластерами Beowulf) являются наличие специализированных сетей, обеспечивающих низкие задержки и повышающих эффективную пропускную способность; компактность и низкое энергопотребление (одна стойка имеет размеры 0,9х0,9х1,9 м и потребляет 27,5 КВт); высочайшая масштабируемость и удобная для декомпозиции задач топология 3D-тора и др.
Некоторые минусы BG/L являются прямым следствием ее достоинств. При малом и среднем числе узлов применение BG/L скорее невыгодно: эти процессоры не отличаются высокой производительностью, выигрыш осуществляется за счет большого числа процессоров. Соответственно приложения, которые плохо масштабируются на большое число процессоров, для BG/L не подходят. Другим серьезным ограничением является относительно небольшая емкость оперативной памяти в узлах. Можно с большой вероятностью предположить, что в следующем поколении, BG/P, появление которого ожидается в недалеком будущем, этот изъян будет ликвидирован. BG/P будет построен уже на базе PowerPC 450, а для сети ввода/вывода будет использован 10G Ethernet. B BG/P планируется достигнуть производительности петафлопного уровня. Вслед за ним, к 2010 году, ожидается разработка следующего поколения — BG/Q [9].
Наконец, общей бедой современных фирменных суперкомпьютеров, в отличие от кластеров, можно считать длительный цикл разработки аппаратуры. За это время на рынке появляются новые технологические решения, которые проще реализовать (и потому они там быстрее находят себе применение) в рамках «массовых» серверов, используемых в узлах кластеров Beowulf.
Есть и еще один момент — переносимость MPI-приложений. Конечно, в MPI можно создать и применять вирутальную топологию, но больший эффект достигается, если в MPI непосредственно учитывается физическая топология. Для кластеров это обычно звезда или (в случае большого числа узлов) толстое дерево, а 3D-тор применятся достаточно редко.
Как бы то ни было, количество инсталляций BG/L в мире продолжает расти, так что высокий коммерческий успех здесь очевиден. Возможно, в близкой перспективе системы BG/L будут работать и на российской земле.
Литература
- Михаил Кузьминский, Cray, да не тот. «Открытые системы», № 12, 2004.
- A. Gara, M. Blumrich et al, Overview of Blue Gene/L system architecture. IBM J. Res. & Dev., vol. 49, no. 2/3, 2005.
- P. Boyle, D. Chen et al, Overview of QCSDP and QCDOC Computers. IBM J. Res. & Dev., vol. 49, no. 2/3, 2005.
- N. Allsopp, J. Follows et al., Unfolding the e-server Blue Gene Solution. SG24-6686-00, IBM, Sept. 2005.
- N. Adiga, M. Blumrich et al, Blue Gene/L Torus Interconnection Network. IBM J. Res. & Dev., vol. 49, no. 2/3, 2005.
- Михаил Кузьминский, Пересадка «голов» на конвейере Сray. Computerworld Россия, № 9, 1998.
- Михаил Кузьминский, Доменная архитектура многопроцессорных компьютеров. «Открытые системы», № 10, 2000.
- M. Ohmacht, R. Bergamaschi et al, Blue Gene/L Compute Chip: Memory and Ethernet Subsystem. IBM J. Res. & Dev., vol. 49, no. 2/3, 2005.
- R. Stevens, The LLNL/ANL/IBM Collaboration to develop BG/P and BG/Q. www.er.doe.gov/ascr/Stevens-ASCAC-March20061.pdf
Таблица. Рис.5
