

Помнится, в борьбе со стратегической оборонной инициативой Рональда Рейгана наши военные предлагали следующий «асимметричный ответ»: вывести на орбиту всякие «штучки», которые сделали бы невозможными полеты в околоземном пространстве из-за возникающих при столкновении повреждений космических кораблей. Когда в борьбе за рынок микропроцессоров в Sun Microsystems представили UltraSPARC T1 (прежнее кодовое название — Niagara), на ум сразу пришло словосочетание — «асимметричный ответ», настолько нетрадиционное решение предложила компания.

Отправной точкой этого решения было утверждение: «Для типичных компьютерных приложений высокая производительность процессора не важна». А точнее — лучше иметь много не слишком мощных процессоров.
Рынок решает не все
Прежде всего, рассмотрим некоторые характеристики и тенденции развития современных серверных микропроцессоров, имея в виду нагрузку на них, создаваемую типичными коммерческими приложениями (в противоположность приложениям научно-технического характера). Многие из изложенных ниже фактов хорошо известны, однако для детализации и конкретизации некоторых из них воспользуемся оценками Sun [1].
В Sun сделали упор на противопоставлении теоретически высоких показателей параллелизма на уровне команд (Instruction Level Parallelism, ILP), характерных для современных высокопроизводительных микропроцессоров, параллелизму на уровне нитей (TLP, Thread Level Parallelism, TLP). Показательно, что рабочие нагрузки сетевого типа, с интенсивной работой с нитями, типичны для 30% современных одно- и двухпроцессорных серверов [2].
В Sun приводит весьма полезную таблицу (Табл. 1), характеризующую рабочую нагрузку, формируемую различными классами типичных коммерческих приложений для серверов: Web-сервер, Java-приложения, ERP (двух- и трехуровневый тесты SAP), оперативная обработка транзакций (тест TPC-C), системы поддержки принятия решений (TPC-H) и др. Ни на одном из этих приложений, кроме TPC-H, не достигается высокий уровень ILP, в то время как во всех этих случаях уровень TLP высок. Так, в 2004 году около 90% всех двухпроцессорных серверов были выполнены на базе Intel Xeon. Для этих микропроцессоров «нормальное» количество выполненных за такт команд равняется примерно 0,5.
В рассматриваемых коммерческих приложениях доминируют задержки из-за работы с оперативной памятью. Команды работы с памятью и условных переходов в типичном программном коде для серверов составляют порядка 30-40% [2]. Между тем все эти команды способны вызвать длительные простои процессора в связи с непопаданием в разного уровня кэш-память.
В последние два десятилетия производители микропроцессоров с целью увеличения ILP наращивали их тактовую частоту и сложность логики; соответственно возрастала величина потребляемой электрической мощности [3]. Но если производительность процессоров росла по закону Мура, удваиваясь каждые полтора-два года, то производительность оперативной памяти удваивается лишь за шесть лет. Поэтому современные процессоры до 85% времени проводят в ожидании выполнения операций с памятью [1]. Это иллюстрирует рис. 1, показывающий, в частности, соотношение времен расчета и работы с памятью для каждой нити.
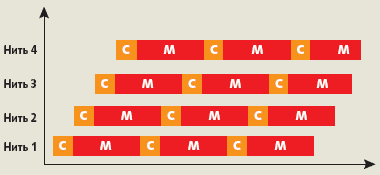
|
| Рис. 1. «Маскирование задержек при работе с ОП на 4 нитях в ядре Т1 (С — время вычислений, М — задержка оперативной памяти) |
При переходе к использованию нового процессора с удвоенной скоростью выполнения арифметических и логических операций, но с сохранением прежней оперативной памяти производительность приложения возрастает всего на 7,5%! И зачем только нам все время предлагают приобретать новые, все более сложные и высокопроизводительные процессоры?
Конечно, реальная ситуация не так однозначна. Для каждой новой компьютерной системы с новыми процессорами обычно имеется описание архитектуры, из которого в первом приближении можно понять, что можно ожидать от работы (возможно, новой) подсистемы памяти, а также доступны результаты тестов, откуда можно получить некоторые количественные оценки. И поставщики обычно показывают, как с переходом на новые процессоры возрастает производительность на реальных тестах, подобных приведенным в табл. 1.
С другой стороны, производители оперативной памяти многие годы успешно наращивают плотность упаковки и емкость, однако требования роста производительности, в первую очередь уменьшения ее задержек, увы, в должной мере адекватного ответа не находят.
Из сказанного становится понятным, почему в Sun предложили перестать гоняться за производительностью процессора на одной нити и переориентироваться на достигаемую пропускную способность в смысле общего числа решенных задач в единицу времени. Именно эта новая парадигма нашла отражение сначала в стратегической инициативе Sun Throughput Computing, а в конце прошлого года — и в новой продукции компании — микропроцессоре UltraSPARC T1 и серверах Sun Fire T1000/T2000.
Стремление к высокой пропускной способности компьютера — только один из важнейших компонентов новой стратегии Sun. В качестве критерия качества продукции компания предложила использовать показатель SWaP (Space, Watts and Performance — «пространство, ватты и производительность»):
где Space измеряется в стандартных единицах высоты стоечного оборудования (1, 2, 3 и т. д. соответственно для устройств в формфакторе 1U, 2U, 3U…), производительность — в показателях тестирования SPEC (Sun предпочла сравнивать T1000/T2000 с двухпроцессорным сервером IBM eServer x346 на тестах SPECweb2005), а потребляемая мощность — понятно, в ваттах.
Почему для формулы выбраны именно эти параметры, с учетом ориентации на центры обработки данных, достаточно очевидно. В Sun указывают на данные аналитиков [1]. Так, в IDC утверждают, что электропитание установленных в США серверов обходится в 5 млрд. долл. в год, а аналитики Gartner предостерегают, что 80% центров обработки данных будут ограничены по электропитанию, физическому пространству или возможностям охлаждения.
По собственным данным Sun, показатель SWaP для T2000 в четыре раза лучше, чем у сервера IBM. Несомненно, исходная посылка — «нам не нужна высокая производительность на одной нити» — способствует достижению высоких показателей [4]. Действительно, ядра в современных многоядерных микропроцессорах могут работать на более низких тактовых частотах (это уменьшает требуемое электропитание, пропорциональное кубу тактовой частоты) и быть более простыми (меньше транзисторов, меньше площадь ядра и больше плотность упаковки, а следовательно, и меньше электропитание).
Представляется, однако, что SWaP не самоцель; корректнее было бы отнести SWaP на 1 долл. стоимость сервера, а еще точнее — разделить производительность на полную стоимость владения. Величина SWaP, поделенная на стоимость сервера, для Sun T1000/2000 дает хорошие результаты.
UltraSPARC T1 стал первым в семействе микропроцессоров с большим числом поддерживаемых нитей от Sun Micorsystems. Необходимо сказать, что такое кристально чистое воплощение описанных принципов, как получилось в T1, возможно, первоначально и не планировалось. Исходный проект Afara был упрощен, и это привело к увеличению надежности конструкции и уменьшению стоимости, что в конечном итоге должно способствовать успеху Niagara на рынке недорогих серверов. В последующих версиях Niagara могут появиться некоторые задуманные изначально, но позднее удаленные специфические функции наподобие типа аппаратной поддержки криптографических функций (EAS, 3DES, эллиптические кривые); возможно также появление модели с плавающей точкой в каждом ядре, а не как сейчас — одного на всю микросхему и т.д. [5].
Водопад нитей
Итак, по сравнению с ранними сообщениями о том, что может появиться в Niagara, финальная версия UltraSPARC T1 была заметно упрощена [2]. В своем анализе мы основываемся главным образом на публикациях [1, 3, 5-6].
Как следует из рис. 2, общая структура UltraSPARC T1 включает восемь ядер (каждое из них имеет аппаратную поддержку до четырех нитей) и неблокирующийся координатный коммутатор, соединяющий эти ядра с кэшем второго уровня и оперативной памятью, а также с подсистемой ввода/вывода. Такая структура напоминает классическое построение SMP-систем с коммутатором, сложившееся еще в середине 90-х годов (например, в узлах Convex SPP1000). Отличие состоит в том, что доступ в кэш второго уровня, который в UltraSPARC T1 является общим для всех процессорных ядер, опосредован коммутатором, в то время как в аналогичных SMP-серверах кэш второго уровня — свой для каждого процессора.
Подобная структура T1 позволяет разработчикам говорить о том, что T1 — это настоящая «система на кристалле». Такая схема построения T1 имеет, несомненно, свои плюсы. Один из них — уменьшение числа компонентов, необходимых для построения сервера: ряд компонентов, размещавшихся на системной плате SMP-cервера, в том числе системная шина/коммутатор, теперь интегрируется в микросхему. В [1] указано, что T1000 содержит 2357 компонентов, T2000 — 3411, в то время как, скажем, HP DL385 с двумя двухъядерными процессорами AMD Opteron — 5176 компонентов, а Dell 6850 — уже 7086 компонентов.
Данная особенность T1 приводит к упрощению конструкции сервера, а значит, к увеличению надежности и уменьшению стоимости. Общий кэш второго уровня можно динамически распределять между различными ядрами (нитями). Конечно, при этом возникают и определенные проблемы. Во-первых, кэш второго уровня отделен от процессорных ядер коммутатором, что увеличивает задержки; однако коммутатор интегрирован в микросхему, и дополнительные задержки могут быть не слишком велики. Во-вторых, при вводе/выводе данные проходят в оперативную память (или из нее) через кэш второго уровня, дополнительно нагружая кэш-память.
Коммутатор имеет высокую общую пропускную способность — свыше 200 Гбайт/с. Для каждой пары «источник-приемник» в коммутаторе предусмотрена очередь длиной в две строки; всего в этих очередях может одновременно содержаться до 96 транзакций.
Поскольку Т1 сконструирован для работы с большим числом нитей приложений, активно работающих с памятью и имеющих большое рабочее множество страниц (т.е. нуждающихся в оперативной памяти большой емкости), необходимо было позаботиться о высокой поддерживаемой пропускной способности памяти. В T1 интегрировано четыре контроллера памяти, что позволяет работать с четырьмя каналами типа DDR2/533 шириной 144 разряда (включая биты ECC), по четыре модуля DIMM на канал. Общая поддерживаемая емкость память — до 128 Гбайт; суммарная пропускная способность памяти равна при этом 25,6 Гбайт/с. И DDR2, и интегрированные контроллеры памяти — это самые современные решения. Преимущества интеграции контроллеров памяти в микропроцессор уже продемонстрированы семействами процессоров IBM Power и AMD Opteron: именно они являются сегодня мировыми лидерами производительности.
Пиковая пропускная способность памяти в Т1 в четыре раза выше, чем в Intel Xeon/Pentium 4, Itanium 2 или AMD Opteron. Конечно, реальная пропускная способность оперативной памяти всегда ниже теоретической; в Sun приводят следующие оценки: 5,7 Гбайт/с для Opteron и 4,4 Гбайт/с для Pentium 4. Кроме того, в двухпроцессорных SMP-серверах на платформе Intel эта пропускная способность памяти разделяется между двумя процессорами, так что в расчете на один процессор получается та же пиковая пропускная способность памяти, что и у T1 в расчете на одно ядро.
Обратимся теперь собственно к процессорным ядрам. Каждое из них реализует архитектуру SPARC V9 и представляет собой подобие RISC-процессора, без возможностей внеочередного спекулятивного выполнения команд и развитой системы предсказания переходов — особенностей, характерных для современных суперскалярных микропроцессоров.
Каждое из этих ядер в свою очередь имеет аппаратную поддержку многонитевой обработки (multithreading) — до четырех нитей, или суммарно до 32 нитей на весь процессор. Напомним, что технология HyperThreading, многонитевая обработка в Intel Xeon/Pentium 4 ограничена всего двумя нитями [7]. Многонитевая обработка в T1 является мелкозернистой: переключение нитей осуществляется на каждом такте по простой циклической схеме. В случае если в нити возникает простой (скажем, промах при работе с кэш-памятью), нить помечается специальным флагом, и происходит переключение на работу с другой нитью.
Собственно, именно поэтому предсказание переходов в ядрах T1 и не требуется: осуществляется переход или нет, ядро все равно переключается на другую нить. Такое поведение T1 позволяет скрыть возникающие задержки при работе с памятью разных уровней. Очевидным условием этого является наличие достаточного количества нитей; поэтому Т1 эффективен только на соответствующей рабочей нагрузке.
Все восемь ядер (и соответственно 32 нити) разделяют общий кэш второго уровня емкостью 3 Мбайт, организованный в виде четырех банков (с чередованием адресов с шагом в 64 байт), являющийся 12-канальным частичноассоциативным. «Аномально» большое число каналов — 12 — предусмотрено, очевидно, с учетом ориентации T1 на работу с большим числом нитей.
Применение общего кэша второго уровня, по мнению разработчиков, помогло упростить протокол обеспечения когерентности кэш-памяти. В кэше второго уровня находятся тэги кэша первого уровня, расположенные в специальном каталоге. Строки кэша первого уровня могут при этом находиться всего в одном из двух состояний — «верная/неверная».
В целом в UltraSPARC T1 характеристики иерархии памяти выглядят с первого взгляда парадоксально. Задержки по обращению в кэш второго уровня и в оперативную память — т. е. то, что сильно влияет на производительность типовых коммерческих приложений, — довольно велики. В то же время на высоком уровне поддерживается пропускная способность оперативной памяти, которая для таких приложений, казалось бы, не важна из-за скорее случайных обращений в память. Однако все это верно для одной нити, о высокой производительности которой в Sun не заботятся: архитектура T1 нацелена на высокую пропускную способность на смеси из многих нитей, когда задержки маскируются, а требования к памяти изменяются почти на противоположные.
Кэш-память первого уровня устроена более традиционным способом. У каждого ядра имеется свой кэш команд емкостью 16 Кбайт (4-канальный частично ассоциативный, с длиной строки 32 байт) и кэш данных емкостью 8 Кбайт, также 4-канальный частично ассоциативный с длиной строки 16 байт. В кэше данных первого уровня используется алгоритм сквозной записи, в отличие от кэша второго уровня, применяющего обратную запись.
Все это было бы вполне привычно, если не вспоминать, что кэш первого уровня разделяется между четырьмя нитями! Складывается ощущение, что в среднем на одну нить приходится кэш первого уровня катастрофически малой емкости. Однако в Sun указывает, что вероятность промаха в кэше первого уровня составляет тем не менее всего 10%, в то время как для того чтобы существенно улучшить этот показатель на коммерческих приложениях с большим рабочим множеством страниц, емкость кэша первого уровня потребовалось бы увеличить слишком сильно; задержки же из-за промаха в кэш первого уровня скрываются благодаря одновременной работе четырех нитей [3].
Замещение строк в кэше команд первого уровня происходит просто случайным образом, но за один такт из кэша первого уровня выбираются сразу две команды. Все это также отвечает стремлению к работе с несколькими «низкопроизводительными» нитями. Кроме кэшей команд и данных первого уровня в каждом ядре имеются ассоциативные буферы быстрой переадресации (I-TLB и D-TLB) емкостью по 64 строки. Эти буферы также разделяются между четверкой нитей. Кроме того, в устройстве загрузки/записи в память каждого ядра имеются четыре буфера записи по 8 строк, по одному буферу на нить. Каждая четверка нитей разделяет общий кэш первого уровня, TLB и функциональные исполнительные устройства ядра, о которых мы скажем ниже. Каждая нить имеет и собственные ресурсы; кроме буфера записи это в первую очередь регистры.
Конвейер процессорных ядер T1 имеет исключительно низкую по современным меркам длину — всего шесть стадий. Это связано с отказом от стремления к высоким тактовым частотам (самый яркий пример с противоположного фланга — Pentium 4 с конвейером аж о 30 стадиях). Кроме того, в Т1 нет механизма высокоточного предсказания переходов, и при длинном конвейере переход вызывал бы слишком большие (в смысле числа тактов) простои.
На первых двух стадиях конвейера (выборка; отбор нити) происходит выборка команд из кэша команд и определение того, со счетчиком команд какой из четырех нитей будет осуществляться их работа. На третьей стадии команды декодируются и осуществляется доступ в файл регистров.
Про файл целочисленных регистров общего назначения следует сказать особо. Он имеет три порта чтения и два порта записи, а суммарно — 640 64-разрядных регистров с однотактным временем доступа. У каждой из четырех нитей регистры свои. Как и вообще в архитектуре SPARC V9, реализованной в ядрах T1, нити используют оконный механизм с перекрывающимися окнами регистров. В любой момент времени одно окно, которое видит нить, активно; оно включает 8 входных, 8 локальных и 8 выходных регистров (еще 8 регистров являются глобальными); всего каждая нить имеет 8 регистровых окон [3]. Поддержка столь большого числа быстродействующих регистров в многопортовом файле на относительно маленькой площади кристалла — бесспорный успех разработчиков.
Четвертая стадия конвейера — собственно выполнение. Для этого в каждом ядре T1 имеется АЛУ, сдвигатель, умножитель и делитель. Первые два устройства имеют однотактовую задержку выполнения; умножение и деление — длинные команды, выполнение которых вызывает переключение на другую нить. В состав каждого ядра входит Modular Arithmetic Unit — устройство для «помодульного» умножения и возведения в степень, применяющихся, в частности, в расчетах ключей для SSL. На пятой стадии работает устройство загрузки/записи в память, на шестой (обратная запись) изменяется содержимое файла регистров.
Поскольку ядер в T1 всего восемь, и каждое из них может завершать выполнение по одной команде за такт, весь Т1 завершает за такт выполнение до 8 команд.
Процессоры UltraSPARC T1 работают на частотах 1,0 или 1,2 ГГц и содержат порядка 300 млн. транзисторов. T1 изготавливаются Texas Instrumnets по 90-нанометровой технологии и имеют площадь 378 кв. мм. Типовое тепловыделение для частоты 1,2 ГГц составляет 72 Вт, пиковое — 79 Вт. Это меньше, чем в одноядерных процессорах AMD Opteron; в процессорах Intel тепловыделение еще выше.
Cерверы T1000 и T2000
Процессоры UltraSPARC T1 ориентированы на приложения, нити которых не требуют высокой производительности и не решают одну общую задачу. Поэтому архитектура не предполагает возможности объединения нескольких процессоров в составе SMP-системы, если не считать того, что уже один T1 делает сервер таковой в логическом плане, для программиста. Предполагается, что на рассматриваемых приложениях масштабирования можно легко добиться путем построения кластеров на базе T1000/Т2000.
В серверах T1000/T2000 вся «логика» размещена на системной плате. Это относится, в частности, к самим процессорам, DIMM-модулям, подсистеме ввода/вывода и сервисному процессору. На рис. 3 представлена блок-схема T1000 с формфактором 1U, на рис. 4 — блок-схема Т2000, имеющего формфактор 2U.
Сервер Т1000 использует не все возможности UltraSPARC Т1: два контроллера памяти из четырех, шесть ядер из восьми возможных. Соответственно задействовано два канала памяти, имеющие максимум восемь DIMM-модулей. Все модули должны иметь одинаковую емкость; к каждому каналу подсоединяется два или четыре модуля. Они имеют емкость 0,5/1/2 Гбайт, а потому общая емкость оперативной памяти в Т1000 не превышает 16 Гбайт.
Сервисный процессор, подсоединенный к Т1, выполняет типичные функции, во многом пересекающиеся с поддерживаемыми известными по системным платам х86-совместимых серверов «микросхемами здоровья»: контроль за температурными показателями, скоростями вращения вентиляторов, уровнями напряжения на плате и т.д. В Sun обозначают набор подобных функций термином Advanced Light-Out Management. Доступ к сервисному процессору обслуживающий персонал может получить через последовательный порт или через Ethernet.
Связь Т1 с подсистемой ввода/вывода осуществляется по шине JBus, работающей на частоте 200 МГц и имеющей ширину 128 разрядов; ее пиковая пропускная способность равняется 3,1 Гбайт/с (на шине мультиплексируются адреса и данные). Для перехода к стандартным шинам ввода/вывода используется мост JBus с PCI-Express (PCI-E).
Этот мост образует два канала PCI-E: PCI-E x8 (на плате имеется разъем для соответствующей низкопрофильной карты) и PCI-E x4, к которому подсоединяется мост к традиционной 64-разрядной шине PCI-X и двухпортовый адаптер Gigabit Ethernet. К PCI-X подсоединены еще один двухпортовый адаптер Gigabit Ethernet и контроллер жестких дисков SAS или SATA. Внутренний диск в Т1000, как это обычно бывает в 1U-серверах, всего один.
Т1000 комплектуется блоком питания всего в 300 Вт и в базовой конфигурации стоит в США чуть менее 3 тыс. долл. (По такой цене в России можно приобрести высокопроизводительный двухпроцессорный сервер с одноядерными х86-совместимыми процессорами, например AMD Opteron.)
Самую грубую прикидку производительности удобно сделать относительно Intel Xeon: их тактовая частота в три с лишним раза выше (T1 в Т1000 работает на частоте 1 ГГц), но число ядер втрое меньше, чем в Т1, а достигаемая величина IPC в ядрах Niagara оценивалось в 0,7-0,8 против 0,5 для Xeon [2]. На самом деле на рассматриваемых приложениях с частым переключением контекста нити эффективное значение IPC в Xeon может быть даже ниже. Эта оценка дает лишь самое грубое представление о «конкуренто?способности» микропроцессора; более полную картину можно составить, проанализировав результаты тестов производительности.
Серверы T2000 имеют структуру, схожую с Т1000, однако используют все возможности T1: четыре контроллера оперативной памяти и соответственно четыре канала, 16 DIMM-модулей общей емкостью до 32 Гбайт, более высокая тактовая частота (1,2 ГГц).
Мост JBus с PCI-E в Т2000 поддерживает два канала PCI-Eх8. Отметим, что в T2000 задействованы не только каналы PCI-E, но и коммутаторы PCI-E. Структура подсистемы ввода/вывода в Т2000 очень похожа на Т1000. В Т2000 возросло число слотов PCI-Ex8 (до трех), PCI-X/133 МГц (до двух); явно выделен южный мост, к которому подсоединяются традиционные порты USB-1.1 и DVD. Контроллер жестких дисков SAS/SATA непосредственно соединяется с коммутатором PCI-Ex8. Этот контроллер, LSI SAS1064, поддерживает четыре жестких диска. Применяются 2,5-дюймовые диски (10 тыс. оборотов в минуту, 73 Гбайт); уменьшение формфактора, как и высокая скорость вращения, способствуют уменьшению времени доступа.
В Sun полагают, что применение JBus вполне достаточно: оно позволяет работать даже с высокоскоростными адаптерами Infiniband 4x. Однако уже появилась более быстрая реализация таких адаптеров, и пропускная способность этого межсоединения будет расти и дальше. Возможно, поэтому JBus может потенциально оказаться узким местом. По мнению автора, наиболее эффективным решением было бы применение открытых стандартов, например, каналов HyperTransport, как в Opteron.
Cерверы Т1000/Т2000, как и сам процессор Т1, имеют целый ряд особенностей, способствующих высокой готовности. Кроме традиционных избыточных блоков электропитания и вентиляторов (в Т2000), это поддержка кодов ECC и технологии Сhipkill в оперативной памяти, аппаратная прочистка (scrubbing) памяти, защита адресов памяти по четности, реконфигурирование каналов памяти и избыточность (sparing) оперативной памяти.
В Т1 данные в кэше второго уровня защищены кодами ЕСС (поддерживается также прочистка кэша), тэги защищены по четности, применяются избыточные колонки и строки кэша. Кэши команд и данных первого уровня, как и их тэги, защищены по четности. Многие из этих механизмов доступны и в других серверах и микропроцессорах. Поэтому отдельно хочется отметить коррекцию четырехкратных и обнаружение восьмикратных ошибок в памяти [5].
На тестах SPECcpu2000 процессоры Т1 будут выглядеть не очень хорошо; их задачи иные. В качестве типичных тестов, «интересных» для Т1, следует указать на SPECweb2005, SPECjbb2005 и SPECjAppServer2004. На последнем тесте кластер из двух серверов с восьмиядерными процессорами Т1 достиг 616 единиц jOPS@standard против 543 единиц для сервера HP rx4640 с четырьмя процессорами Itanium 2/1,6 ГГц, который потребляет почти в четыре раза больше электроэнергии, чем Т2000. Естественно, и отношение стоимость/производительность у Sun при этом лучше. Серверы Т2000 могут эффективно масштабироваться при объединении в кластеры; 7-узловой кластер Т2000 на данном тесте сильно опережает по производительности 8-узловые кластеры IBM с узлами-серверами р550 на базе Power5+/1,9 ГГц, HP (узлы — rx4640) и 6-узловой кластер HP на базе серверов DL380 с процессорами Xeon/3,6 ГГц.
На тестах SPECweb2005 сервер Т2000 достиг производительности 14 001 единица против 4348 — для двухпроцессорного IBM x346 на базе Xeon/3,8 ГГц и 7881 — для четырехпроцессорного IBM p550.
На тестах SPECjbb2005 сервер Т1000 достиг 51540 bops против 39985 — для двухпроцессорного четырехъядерного сервера IBM x346 на базе Xeon и 32820 — для двухпроцессорного сервера IBM p520 с Power5+/1,9 ГГц. Dell PowerEdge SC1425 c двухпроцессорными одноядерными Xeon/3,6 ГГц достиг только 24 208 bops. Двухпроцессорный сервер Fujitsu Siemens на базе двухъядерных процессоров Opteron 280 достиг 61155 bops. Т2000 на этом тесте имеет уже 63378 bops, что выше, чем у четырехъядерного сервера IBM p550, но меньше, чем, например, у четырехпроцессорного восьмиядерного сервера с Opteron 880 от Fabric7 Systems (95587 bops).
Т1000 и Т2000 достигают прекрасных результатов при генерации личных ключей RSA/DSA. Приводимые Sun оценки используют разные тесты: pk11rsaperf/pk11dsaperf для T1000/Т2000, и OpenSSL — для 32-процессорного сервера IBM p690 на базе Power4/1,3 ГГц, двухпроцессорных серверов Dell PowerEdge на базе Xeon/3,6 ГГц и других многопроцессорных серверов. Очевидно, тест OpenSSL при этом не распараллеливался, и задействовать несколько процессоров в многопроцессорных серверах было нельзя.
На двухуровневых тестах SAP SD, требующих больше процессорных ресурсов, чем, например, TPC-C (оперативная обработка транзакций), показатели T2000 — 950 пользователей, HP BL25p (четыре ядра) — 974 пользователя, HP DL580n (четыре процессора Xeon/3,3 ГГц) — 939 пользователей, HP rx4640 (восемь ядер) — 1320 пользователей, IBM p570 (четыре ядра) — 1313 пользователей.
Приведенные результаты подтверждают высокую реальную производительность серверов Sun с микропроцессорами T1. Возможно, главными конкурентами серверов Т1000/Т2000 по производительности, критерию SWaP, в том числе с учетом стоимости, могли бы оказаться серверы самой компании Sun Microsystems — на платформе AMD Opteron (правда, серверы на этой платформе выпускают и IBM, и HP, и многие другие производители). Так или иначе, UltraSPARC T1, как и серверы T1000/T2000, — весьма оригинальные и перспективные разработки Sun, которые, безусловно, усиливают ее позиции на компьютерном рынке.
Литература
- Sun Fire T1000 and T2000 Server Architecture. White Paper, Sun Microsystems, Dec. 2005.
- C. Rijk, Niagara: A Torent of Threads. www.aceshardware.com/read.jsp?id=65000292
- P. Congetria, K. Ainguran, K. Oluxotun, Niagara: A 32-way Multithreaded SPARC Processor. IEEE Micro, March-April, 2005.
- L. Spracklen, S.G. Abraham, Chip Multithreading Opportunities and Challenges. IEEE Int. Symp. High-Performance Computer Architecture, 2005.
- K. Krevill, The Sun UltraSPARC T1 Processor Released. Microprocessor Report, Jan. 3, 2006.
- W. Brugg, J. Alabado, The UltraSPARC T1 Processor — High Bandwidth for Throughput Computing. Sun Microsystems, Dec. 2005.
- Михаил Кузьминский, Многонитевая архитектура микропроцессоров. // «Открытые системы», 2002, № 1.
