

Скорость стала определяющим фактором конкурени. По словам Джека Уэлча, бывшего главы General Electric, она продлевает молодость компаниям и людям. Это как нельзя лучше обюясняет тенденю роста ежегодных инвестий в ИТ-ресурсы, но по мере информатизаи предприятия возрастает его зависимость от их состояния. И не случайно среди основных факторов риска руководители предприятий нередко упоминают информаонные технологии.
Рост числа компонентов ИТ-инфраструктуры приводит к увеличению времени внеплановых простоев. Поиск причин таких простоев все больше усложняется из-за взаимного влияния компонентов. Сбои могут полностью парализовать работу предприятия, привести к конфликтам и экономическим потерям, поэтому в методике расчета совокупной стоимости владения ИТ-ресурсами (TCO, Total Cost of Ownership) учитываются и затраты на внеплановые простои.
|
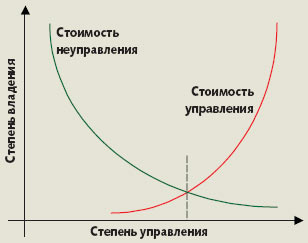
| Рис. 1. Минимизая совокупных затрат |
Внедрение мер, наленных на уменьшение числа и продолжительности внеплановых простоев, обуславливает дополнительные затраты на управление при одновременном снижении стоимости неуправления (обюема прямых и косвенных потерь от простоев). На практике выбирается решение, которое характеризуется наименьшей суммой стоимости управления и стоимости неуправления (рис. 1).
Методы управления проектными рисками
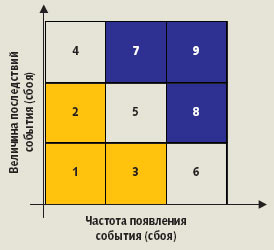
Число и продолжительность внеплановых простоев имеют вероятностную природу, сходную с природой рисков, поэтому в области ИТ управление рисками является одним из требований со стороны пользователей, руководства и владельв бизнеса. В терминах управления риском последний определяется как произведение вероятности (частоты) проявления события (сбоя) и величины его последствий. Возможные комбинаи частоты проявления и величины последствий рисковых случаев удобно представлять в виде матри уровней риска (risk-level matrix). Пример матри 3х3 (по три градаи вероятности и величины последствий) приведен на рис. 2.
|
| Рис. 2. Матри уровней рисков |
В документах [1б-4] рассматриваются разные варианты матри уровней риска (от 3х3 до 5х5) с различными диапазонами вероятности и величины последствий рисковых событий. Однако, в конечном счете, все рисковые события можно сгруппировать по трем основным категориям: высокий уровень риска, средний и малый. При этом все источники единодушны в том, что события с высоким уровнем риска необходимо предотвращать, событиями со средним уровнем риска нужно управлять, а события с низким уровнем риска приходится игнорировать. На матри, показанной на рис. 2, области 1б-3 соответствуют низкому уровню риска, области 4б-6 – среднему, а области 7б-9 – высокому. В табл. 1 приведены основные методы управления проектными рисками [4, 5]. Наиболее «интересными» являются риски среднего уровня (области 4б-6 на рис. 2), поэтому в дальнейшем будут рассматриваться преимущественно они.
Особенности управления рисками в ИТ
Для анализа стоимости простоев полезно рассмотреть модель готовности ИТ-ресурсов (рис. 3).Степень «неготовности» пропорональна произведению времени восстановления работоспособности и степени влияния сбоя. Она может быть рассчитана как отношение площадей соответствующих прямоугольников на рис. 3.
Внеплановые простои, относящиеся к области 6 на рис. 2, характеризуются малыми значениями MTBF и произведения MTTR* i1. Примерами таких сбоев являются проблемы, связанные с производительностью, например небольшие (едини минут) задержки электронной почты на корпоративном сервере. Само по себе подобное событие несущественно и может быть проигнорировано, поскольку оно затрагивает лишь отправителя и получателя и не приводит к потере информаи. Но при интенсивном документообороте задержки приводят к заметному снижению эффективности работы персонала и к соответствующим экономическим потерям.
Простои, относящиеся к области 5 на рис. 2, характеризуются умеренными значениями MTBF и произведения MTTR* i1. Примером таких событий является сбой, требующий замены 48-портового коммутатора рабочих групп. Он затрагивает множество пользователей, но при наличии на складе запасного коммутатора замена будет выполнена достаточно быстро. Современные сетевые устройства выходят из строя не так уж часто, поэтому связанный с данным сбоем риск может расниваться как средний по уровню.
К области 4 на рис. 2 относятся внеплановые простои, характеризующиеся большими значениями MTBF и произведения MTTR* i1. Они возникают очень редко, поэтому их можно было бы считать невероятными и игнорировать – если бы не серьезные последствия таких сбоев. Серьезность последствий определяется как степенью влияния сбоя i1 (например, вышел из строя весь комплект аппаратуры на борту спутника), так и значительным временем восстановления работоспособности MTTR (событие даже может иметь необратимый характер, например в случае человеческих жертв или невозможности ремонта оборудования на борту спутника).
Целью управления является снижение показателя неготовности. Как показано на рис. 3, сделать это можно за счет уменьшения влияния сбоя i1, увеличения среднего времени между сбоями (MTBF) и уменьшения времени восстановления (MTTR).
При оптимизаи стоимости управления необходимо учитывать два фактора: человеческий (наличие эксплуатирующего персонала) и временной (назначенный срок службы).
Необходимость в обслуживающем персонале связана с тем, что современные системы управления являются преимущественно автоматизированными, но не автоматическими. Их производители делают ставку на человеческий интеллект, усиленный ИТ-средствами и упорядоченностью проссов эксплуатаи. Дело в том, что, во-первых, причины сбоев нередко невозможно обюяснить на основе информаи, накопленной системой управления. Во-вторых, необходимо адекватное реагирование на любые, в том числе нестандартные и быстро меняющиеся, ситуаи. На современном уровне развития технологии пока не могут составить конкуреню человеческому интеллекту.
Наличие службы эксплуатаи оправданно только при достаточно большом количестве сбоев. В противном случае стоимость устранения каждого сбоя окажется неоправданно высокой (персонал будет недозагружен). Однако именно сокращение числа сбоев позволяет уменьшить штат эксплуатирующего персонала, а за счет этого – повременную составляющую стоимости управления.
Время – не менее важный фактор. Показатели функонирования ИТ-ресурсов необходимо определять с учетом всего срока их службы, работоб?способности устройств и требуемого показателя готовности в течение всего срока службы. Обычно производители указывают лишь среднее время наработки на отказ их устройств, что не дает полного представления о том, как будет вести себя оборудование в течение всего срока службы. Однако, согласно нтральной предельной теореме теории вероятностей [6], плотность вероятности выхода устройств из строя близка к нормальному распределению, характеризующемуся математическим ожиданием б? и стандартным отклонением о?. Типичная зависимость вероятности выхода устройства из строя от времени приведена на Рис. 4. В начале срока службы вероятность отказа пренебрежимо мала, затем монотонно возрастает, после чего асимптотически приближается к едини.
По известному назначенному сроку службы может быть определена вероятность выхода компонента из строя. Например, при б?=5 лет и о?=1 год вероятность выхода устройства из строя к кон шестого года эксплуатаи приблизительно равна 80%. Если же расчетная вероятность выходит за допустимые грани (что весьма вероятно), необходимо рассматривать варианты управления, такие как резервирование, замена устройства после сбоя или превентивная замена.
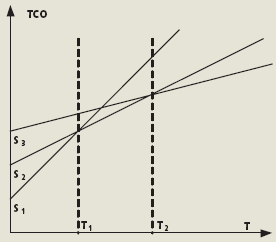
Также необходимо помнить, что TCO – функя от времени. Причем стоимость неуправления является повременной величиной (начальные затраты на ИТ-ресурсы могут не учитываться при анализе вариантов), стоимость управления имеет как дополнительные начальные затраты, так и повременные (преимущественно на персонал), а снижение совокупной стоимости владения ИТ-ресурсами обеспечивается оптимальным соотношением начальных и повременных затрат. TCO минимизируется с учетом предполагаемого срока службы ИТ-ресурсов. Как правило, более высокие начальные затраты на средства управления оправданны при снижении повременных затрат. Чем дольше предполагаемый срок службы ИТ-ресурсов, тем больше в TCO доля повременных затрат и тем большая стоимость управления может быть обоснована. Соотношения TCO для трех гипотетических вариантов реализаи приведены на рис. 5.
|
| Рис. 5. Зависимость TCO от времени |
Для коротких сроков службы ИТ-ресурсов предпочтительным представляется решение с наименьшими начальными затратами (вариант S1). Для среднего временного интервала [Т1-Т2] наиболее выгодным является промежуточный вариант с умеренными начальными затратами S2. Однако для временного интервала [Т2-Т2+] вариант с наибольшими начальными затратами S3 оказывается наиболее выгодным ввиду снижения повременных затрат (по сравнению с затратами, характерными для первых двух вариантов).
Методы управления ИТ-ресурсами
Резервирование
Резервирование обеспечивается за счет аппаратной избыточности: чем ниже надежность устройства, тем выше требуемая степень избыточности. Для известных коэффиентов готовности отдельного устройства и требуемого коэффиента готовности необходимое количество устройств может быть рассчитано по следующей формуле:
<необходимое количество устройств> = (ln(1 - <требуемый коэффиент готовности>))/(ln(1 - <коэффиент готовности отдельного устройства>))Соответственно, общая стоимость решения будет равна произведению рассчитанного таким образом количества устройств и стоимости одного устройства. Добавление одного дополнительного устройства приводит к повышению результирующей надежности на 40%, двух – на 73%, трех – на 100%. Другими словами, добавление второго устройства дает прирост готовности 33%, а третьего – 27%. Зависимость между результирующей готовностью и необходимым количеством избыточных устройств имеет затухающий характер, вследствие чего существует некое пороговое значение n, при достижении которого дальнейшее повышение уровня готовности окажется экономически невыгодным.
Метод резервирования позволяет снизить степень влияния сбоя (i1*MTTR на рис. 3). Например, можно воспользоваться кластерами для повышения надежности критически важного сервиса.
Достоинства: можно отказаться от расходов на управление (обслуживание) системой в течение назначенного срока службы.
Недостатки: результаты расчета применимы только к аппаратному обеспечению, поскольку характер проявления ошибок ПО изучен недостаточно. Чтобы воспользоваться результатами расчета применительно к сбоям ПО, необходимо обеспечить возможность восстановления работоспособности устройства (например, путем его перезапуска) при возникновении программных (не фатальных) сбоев, однако большая часть ресурсов оборудования расходуется при этом «вхолостую».
Применимость: назначенный срок службы системы должен быть меньше среднего времени наработки на отказ ее отдельных компонентов.
Проактивное управление
Как понятно из Рис. 4, уменьшая время использования отдельного устройства, можно добиться достаточно малой вероятности его выхода из строя. В «классическом» виде проактивный подход предусматривает регулярную замену компонентов на новые (аналогично тому, как при техобслуживании автомобилей после определенного пробега меняют ремни газораспределительного механизма). Например, жесткие диски заменяют по истечении гарантийного срока, т.е. через три года, а не после их выхода из строя.
График и периодичность замены определяются требованиями к готовности системы, вероятностью отказа единичных устройств как функи от времени и назначенным сроком службы системы. Оптимальный срок службы устройства определяется балансом между стоимостью превентивной замены устройства и снижением уровня риска благодаря этой замене.
Достоинства: расходы на управление (обслуживание) системой в течение назначенного срока службы могут быть рассчитаны; достижим практически любой уровень готовности системы для практически любого назначенного срока ее службы.
Недостатки: доля используемого ресурса оборудования относительно мала.
Применимость: в общем случае данный подход применим только к аппаратному обеспечению. Он особенно выгоден, если срок службы системы превосходит среднее время наработки на отказ устройств. В этом случае выход из строя каждого устройства превращается из возможного события в неизбежное. А если время простоя также является важным фактором (область 5 на рис. 2), то превентивная замена в запланированный период обеспечит наименьшую сумму стоимости управления и неуправления. Побочным результатом применения проактивного подхода является высвобождение большого количества компонентов с практически неиспользованным ресурсом по наработке. Обычно они перепродаются со скидкой (что позволяет дополнительно снизить стоимость решения) либо используются для модернизаи менее важных узлов.
Разновидностью проактивного управления является внедрение проссов управления проблемами, релизами, мощностями и т.п. [7]. На основании сведений о проявлениях и причинах сбоев устанавливается их корневая причина (например, эксплуатируется устаревшая версия программного драйвера), после чего выполняются действия по ее устранению (например, программный драйвер обновляется на всех устройствах, даже не подвергшихся сбою). Данный подход наилучшим образом применим в областях 6 и 5, но малопригоден для области 4 (небольшая частота сбоев). В отличие от резервирования и «классического» проактивного управления, этот подход одинаково применим к сбоям оборудования и ПО, а также к событиям, связанным с производительностью, безопасностью и т.п. Явных недостатков у него нет. Однако его использование возможно лишь при наличии персонала, занимающегося изучением и устранением проблем, применении средств автоматизаи сбора и анализа сведений о сбоях, а также при определенном уровне зрелости проссов эксплуатаи.
Управление индентами
Речь идет о классическом проссе возобновления работы после сбоя [7]. Например, в случае аварийного завершения программного просса выполняется его перезапуск.
Достоинства: в отличие от резервирования и «классического» проактивного управления, данный метод позволяет максимально раонально использовать ресурс оборудования (он полностью вырабатывается – вплоть до выхода устройства из строя). Этот метод одинаково применим к сбоям оборудования, ПО и виртуальных обюектов (например, сервисов). Его результаты не зависят от времени наработки на отказ компонентов и назначенного срока службы системы. Метод управления индентами применим также к событиям, связанным с производительностью, безопасностью и т.п. Он может задействоваться в условиях эволюи (развития и модернизаи) обюектов управления.
Недостатки: иногда подразумевает простой оборудования в период восстановления его работоспособности после сбоя. Эта проблема решается за счет резервирования наиболее важных компонентов ИТ-ресурсов.
Применимость: необходима автоматизированная система мониторинга и управления, требуются эксплуатирующий персонал для обнаружения и устранения индентов и внедрение просса управления индентами. Данный подход применим для сбоев средней частоты и воздействия (область 5), но управление относительно безобидными индентами из области 6 (которые можно было бы игнорировать, если бы не их количество) приведет к росту общей стоимости каждого из них (добавится стоимость управления). В области 4 (отсутствие регулярных сбоев) затраты на службу эксплуатаи могут оказаться необоснованными.
Заблаговременное прогнозирование
Данный подход предполагает прогнозирование изменения состояния ИТ-ресурсов, в том числе с учетом предполагаемых изменений внешних (по отношению к обюекту управления) факторов. Его применение особенно выгодно, если неизбежна задержка между обнаружением сбоя и реагированием на него (например, при выходе из строя ретранслятора на вершине сопки). Если отслеживать изменения параметров оборудования, можно заблаговременно прогнозировать выход их значений за грани допустимого диапазона и планировать ремонтно-восстановительные работы.
С математической точки зрения задача состоит в анализе связей между несколькими независимыми переменными (называемыми также предикторами) и зависимой переменной. Для решения этой задачи обычно используются продуры множественной регрессии [8]. В общем случае зависимость может иметь нелинейный характер, но для «разумных» периодов линейная интерполяя прогнозирования применима.
Этот подход может успешно использоваться в тех случаях, когда трудно обосновать непосредственную взаимосвязь между какими-либо показателями, например между повышением производительности труда бизнес-подразделений и увеличением расходов на ИТ.
Достоинства: позволяет прогнозировать поведение контролируемых параметров, а также ожидаемый эффект от тех или иных изменений.
Недостатки: высокие требования к квалификаи персонала, необходимость предварительной разработки (для лей прогнозирования) моделей поведения обюектов управления.
Применимость: необходим персонал, занимающийся изучением предполагаемых «внешних» изменений и расчетом необходимой модернизаи обюектов управления, требуется определенный уровень зрелости проссов эксплуатаи. Должны быть внедрены автоматизированные средства контроля над состоянием и загрузкой обюектов управления (в противном случае сбор данных для прогнозирования будет занимать слишком много времени), проссы управления индентами и проблемами, а также уровнями сервиса (обеспечивают исходные данные для прогнозирования).
Методы управления рисками для ИТ
Применительно к ИТ указанные в табл. 1 методы управления проектными рисками можно интерпретировать следующим образом (табл. 2).
Сравнивая рис. 2 и рис. 3, можно обратить внимание на то, что область 4 характеризуется достаточно высоким значением MTBF, и управлять требуется произведением MTTR*i1. Типичный пример – сбои в аппаратуре бортового радиотехнического комплекса спутника-ретранслятора, находящегося на геостаонарной орбите (ремонт обюективно невозможен).
Область 6 характеризуется аномально большим количеством сбоев. Низкая стоимость каждого сбоя позволяет предположить отсутствие заметного взаимовлияния ИТ-ресурсов. Типичные примеры – неоптимальная настройка исправных компонентов на начальном этапе работы системы и система с большим количеством неконтролируемо вносимых изменений.
Область 5 характеризуется умеренным числом сбоев (среднее значение MTBF) и стоимостью каждого сбоя (произведение MTTR*i1).
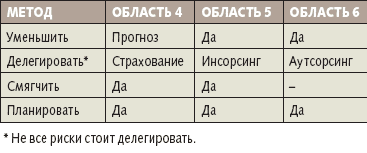
Рассмотрим применимость методов управления к рискам среднего уровня, относящимся к разным областям матри, с лью снижения стоимости неуправления (табл. 3).
|
| Табли 3. Применимость методов управления к рискам среднего уровня |
Метод «Уменьшить». К области 6 применимо проактивное управление (релизами, проблемами, мощностями конфигурай, изменениями и т.п.), внедрение систем управления. Управление индентами не всегда может быть использовано, если сбои носят краткосрочный характер (например, при сбое одного из маршрутизаторов Internet время реаки персонала превысит время поиска альтернативного маршрута протоколом маршрутизаи). Область 5 – реактивное управление (управление индентами, внедрение автоматизированных систем управления) и/или проактивное (например, превентивная замена оборудования). Прямое применение метода «Уменьшить» в области 4 затруднено из-за чрезвычайно высокой степени влияния сбоя (угроза жизни людей) либо обюективной невозможности устранить сбой (отказ оборудования космического аппарата). Однако при наличии системы диагностики можно контролировать изменение параметров обюекта управления, прогнозировать возможность выхода значений параметров за грани заданного диапазона и выполнять упреждающие действия.
Метод «Делегировать». В области 4 аутсорсинг не всегда уместен, поскольку при высокой степени влияния каждого сбоя появляется дополнительный фактор риска («непрозрачность» организаи-подрядчика). В области 6 надо учитывать, что размер страховых взносов должен превышать среднестатистические показатели убытков, и при очень большой частоте сбоев страхование окажется экономически неоправданным. Зато экономически оправданным будет использование профессионализма подрядчика. С учетом достаточно больших частоты и степени влияния сбоев можно сделать вывод, что в области 5 делегирование осуществимо только путем инсорсинга (т.е. с помощью «домашней» эксплуатирующей организаи).
Метод «Смягчать». В области 4, с учетом небольшой частоты сбоев, применение резервных компонентов (в том числе создание резервных нтров) позволит снизить степень влияния сбоев. В области 5 полезно выборочное резервирование компонентов, оказывающих наибольшее влияние на остальные ИТ-ресурсы. В области 6 применение данного метода не рекомендуется, поскольку это приведет к росту числа сбоев вследствие увеличения количества устройств.
Метод «Планировать». В области 4 обычно разрабатываются планы восстановления после катастроф (disaster recovery plan). В области 5 создаются инструки по устранению индентов и графики превентивной замены оборудования. В области 6 применяются инструки по разработке релизов, их тестированию и внедрению.
Из табл. 3 видно, что не все методы управления пригодны для конкретных областей. Однако для каждой области могут быть применены несколько методов управления.
Далеко не шутка
Если бы строители возводили здания так же, как программисты пишут программы, то первый же дятел разрушил бы вилизаю. Это – далеко не шутка, поскольку причиной примерно 40% сбоев ИТ-систем является программное обеспечение, а еще 40% индентов связаны с человеческим фактором. Мы рассмотрели проблему управления ИТ-ресурсами с точки зрения управления рисками – одной из областей свода знаний по управлению проектами. В свою очередь, само проектное управление развивается уже более 100 лет (в первую очередь, в строительстве), и за эти годы используемые в нем подходы доказали свою универсальность и значимость. Анализ проектных методов управления рисками показал возможность их использования в мире информаонных технологий, а также позволил дать рекомендаи по оптимальному применению этих методов.
Литература
- Risk Management Guide for Information Technology Systems. Recommendations of the National Institute of Standards and Technology // NIST Special Publication 800-30. – 2004.
- Risk Management Guide for DoD acquisition. Fourth Edition // The defense acquisition university press Fort Belvoir. – 2001.
- A Guide to the Project Management Body of Knowledge, PMBOK guide. – 3rd ed., 2004.
- PRINCE2. Third edition. Crown. – 2002.
- Управление проектами: Основы профессиональных знаний. Наональные требования к компетени спеалистов. – М.: «Консалтинговое Агентство «КУБС Групп-Кооперая, Бизнес-Сервис». – 2001.
- Вентль Е.С., Овчаров Л.А. Теория вероятностей и ее инженерные приложения. – М.: Высшая школа. – 2000.
- ITIL Service Support. Office of Government Commerce (OGC). – Crown Copyright. – 2003.
- Нареш Малхотра. Маркетинговые исследования и эффективный анализ статистических данных. – К.: ТИД «ДС». – 2002.
Игорь Щетинин (shchetinin@i-teco.ru) – руководитель отдела технического проектирования компании «Ай-Теко» (Москва).
