

Переход к многоядерным процессорам становится основным направлением повышения производительности. В статье рассмотрены современные многоядерные процессоры разных фирм, но основное внимание уделено микроархитектуре новейших двухъядерных процессоров AMD Opteron. Эти процессоры по большинству показателей производительности опережают своих х86-конкурентов от Intel, являясь лидерами целочисленной производительности среди серверных процессоров, лишь немного уступая IBM Power5 и Intel Itanium 2 на плавающей точкой. В статье приведены результаты выполненных автором измерений производительности двухпроцессорного четырехъядерного сервера Supermicro на базе Opteron 275.

Конец гонке тактовых частот микропроцессоров, тон в которой задавали Intel и AMD, был положен «благодаря» нерешенной проблеме токов утечки и неприемлемому росту тепловыделения микросхем. Некоторые специалисты Intel даже говорят, что тактовые частоты больше расти не будут (вероятно, все же имея в виду — в ближайшее время).
Разработка более совершенных микроархитектур, содержащих большее число функциональных исполнительных устройств, с целью повышения количества команд, одновременно исполняемых за один такт, — традиционный альтернативный росту тактовой частоты путь повышения производительности. Но такие разработки очень сложны и дороги; сложность разработки возрастает со сложностью логики экспоненциально.
Еще один подход к решению данной проблемы был реализован в VLIW/EPIC-архитектуре IA-64, где часть проблем переложена с аппаратуры на компилятор; однако сегодня разработчики признают, что для высокой производительности микроархитектура важнее.
Кроме того, при большом числе функциональных блоков микросхемы и большом ее размере возникает фундаментальная проблема ограниченности скорости распространения сигнала: за один такт сигнал не успевает добраться во все необходимые блоки. В качестве возможного выхода в микропроцессорах Alpha были введены так называемые «кластеры», где устройства частично дублировались, но зато внутри кластеров расстояния были меньше.
Можно сказать, что идея построения многоядерных микропроцессоров является развитием идеи кластеров, но в данном случае дублируется целиком процессорное ядро. Другим предшественником многоядерного подхода можно считать технологии наподобие Intel HyperThreading, где также есть небольшое дублирование аппаратуры.
Все ведущие разработчики микропроцессоров уже создали двухъядерные процессоры, и в дальнейшем число ядер на микросхеме может еще возрасти. Первыми появились двухъядерные RISC-процессоры — у Sun Microsystems (UltraSPARC IV; в будущих процессорах Niagara число ядер увеличится), IBM (Power4, Power5) и HP (PA-8800 и PA-8900). Intel вот-вот объявит о выпуске двухъядерных процессоров Montecito с архитектурой IA-64.
Наконец, о выпуске двухъядерных процессоров с архитектурой х86 в AMD и Intel объявили почти одновременно.
AMD предлагает 64-разрядные двухъядерные процессоры Opteron для серверных систем и рабочих станций и 64-разрядные двухъядерные Athlon64 — для настольных систем. Intel использует аналогичную 64-разрядную архитектуру EM64T в своих серверных процессорах Xeon и «настольных» Pentium 4.
Не вдаваясь в обсуждение маркетинговых особенностей, отметим, что имеются возможные технические причины того, что в Intel задержали появление своих двухъядерных процессоров Xeon; на момент подготовки статьи корпорация только объявила о будущем выпуске двухъядерных Xeon Paxville.
Серверные применения многоядерных процессоров сегодня более естественны и многообразны, чем для настольных систем. Многопроцессорные серверы — явление обычное, а вот как применять многопроцессорные настольные системы — это еще вопрос. Распараллеленных приложений для настольных систем практически нет; фактически речь может идти просто о многозадачной среде.
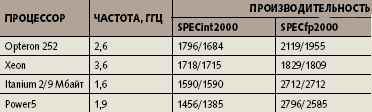
Процессоры Opteron и до появления двухъядерных версий опережали своих х86-конкурентов от Intel по производительности на большинстве приложений. Opteron вообще является лидером среди всех серверных процессоров по целочисленной производительности, хотя на тестах SPECint2000 и уступает «настольному» Pentium 4/3,8 ГГц. На тестах SPECfp2000 он уступает IBM Power5 и Intel Itanium 2. Однако последние процессоры достигают столь высоких показателей в том числе и за счет очень большой емкости кэша. Можно сравнить данные SPECfp2000 для Itanium 2/1,4 ГГц с 1,5-мегабайтным кэшем третьего уровня (сравнимо с 1 Мбайт у Opteron) и для Itanium 2 с той же частотой и кэшем в 3 Мбайт. При таком увеличении емкости кэша производительность Itanium 2 возрастает на 15% (данные для SGI Altix 350), а Opteron отстает от Itanium 2 с кэшем на 9 Мбайт всего на 30% (табл. 1).
|
| Таблица 1. Производительность серверных процессоров на тестах SPECcpu2000 (пиковое/базовое значение) |
На сложных приложениях, плохо локализуемых в кэше, относительные показатели Opteron должны улучшаться, особенно по сравнению с Itanium 2, не имеющими, как Opteron и Power5, встроенных контроллеров оперативной памяти, и разделяющими при доступе к ней общую шину. Да и стоимость процессоров со столь большим кэшем, как у Itanium 2 и Power5, также велика.
Микроархитектура Opteron/Athlon64
Общую архитектуру серверов на базе Opteron [1] в AMD называют «архитектурой с прямым соединением», поскольку процессоры «напрямую» соединены с оперативной памятью посредством встроенного контроллера памяти. В настоящее время Opteron поддерживает память DDR400, что обеспечивает пропускную способность 6,4 Гбайт/с на процессор. С ростом числа процессоров пропускная способность памяти растет линейно.
Архитектура, используемая в серверах на базе Xeon, предполагает наличие посредника между процессором и памятью в лице северного моста, что увеличивает задержки. При этом пропускная способность памяти не растет с числом процессоров: наоборот, они разделяют пропускную способность (до 6,4 Гбайт/с) между собой. В двухпроцессорном сервере пропускная способность памяти в расчете на процессор вдвое ниже, а в 4-процессорном SMP-cервере с Xeon MP — еще хуже (там системная шина имеет пропускную способность только 5,3 Гбайт/с, и ситуацию пытаются исправить увеличением емкости кэша).
В двухъядерном процессоре Athlon64 пропускная способность памяти в расчете на ядро также становится вдвое меньше; то же самое характерно и для двухъядерных процессоров Intel. Однако в будущих двухпроцессорных серверах с двухъядерными процессорами Xeon DP Paxville, имеющими четыре ядра на сервер, будет применяться набор микросхем Intel E7520, и пропускная способность памяти в расчете на ядро составит только 1,6 Гбайт/с: дело в том, что пропускная способность разделяется между всеми ядрами, подключенными к FSB. В двухъядерных Opteron пропускная способность памяти делится только между двумя ядрами каждого процессора.
Лишь в будущих двухъядерных Xeon MP Paxville с будущим набором микросхем E8500 для 4-процессорных серверов (8 ядер) предприняты некоторые меры для исправления ситуации: каждая пара процессоров (4 ядра) имеет собственную шину FSB с пропускной способностью памяти 10,6 Гбайт/с (по данным сайта www.xbitlabs.com). Для компенсации проблемы пропускной способности оперативной памяти в Intel снова предлагают увеличить емкость кэша. Возможно, выпуск двухъядерныx процессоров Xeon был задержан именно с тем, чтобы подготовить новый набор микросхем или новые процессоры с большей кэш-памятью.
Кроме того, Opteron/Athlon64 использует для поддержания когерентности кэша более совершенный протокол MOESI (в Pentium D/Smithfield применяется MESI, см. www.anandtech.com), что дает преимущества в масштабировании при работе с памятью. Связанный с работой протокола MOESI трафик в двухъядерных процессорах Athlon64 не затрагивает неблокирующийся коммутатор, а использует SRQ, очередь системных запросов, отвечающую за управление ядрами и определение их приоритета, и контроллер памяти. При этом также несколько уменьшаются задержки, поскольку не добавляются задержки на коммутаторе.
На сайте www.anandtech.com приводятся данные для задержек при передаче из кэша в кэш, возникающих, когда на одном процессорном ядре выполняется запись в память, а на втором — загрузка из этого адреса. На двух одноядерных Opteron/2,4 ГГц с интерфейсом к памяти, работающем на частоте 1 ГГц, задержка равна 159 нс, для двух ядер разных двухъядерных Opteron/2,2 ГГц — 164 нс, а для двух ядер одного процессора — всего 107 нс. Для Pentium D такого улучшения не наблюдается — задержка равна 240 нс, что близко к двум процессорам Xeon Nocona/3,2 ГГц (242 нс).
Для многопроцессорных серверов превосходство двухъядерных процессоров Opteron представляется более важным: часть трафика, вызываемого поддержкой когерентности кэша, приходится на SRQ и контроллер памяти, и не дает нагрузки на коммутатор. Кроме того, использование высокоскоростного интерфейса HyperTransport в Opteron/Athlon64 предполагает как соединение процессоров через HyperTransport с поддержанием когерентности кэша в многопроцессорных серверах, так и прямое — без северного и южного мостов — подсоединение через HyperTransport мостов шин PCI-X/PCI-Express, что также повышает производительность. Суммарная пропускная способность ввода/вывода для 8-процессорных систем на базе Opteron 8xx достигает 30,4 Гбайт/с, для двухпроцессорных систем на базе Opteron 2xx — 22,4 Гбайт/с. С точки зрения архитектуры памяти построение серверов с Opteron отвечает архитектуре ccNUMA, хоть пока и с небольшим, до 8, числом процессоров.
Можно упомянуть и другие преимущества Opteron, например, низкие величины задержек при работе с иерархией памяти. Так, задержка Opteron при выборке из кэша данных первого уровня равна трем тактам, и имеется два порта чтения, дающие возможность двух одновременных операций. В Xeon DP эта задержка равна 4 тактам, а порт чтения только один. (Данные для Xeon получены автором от Винсента Дипэвена, разработчика одной из сильнейших в мире шахматных программ Diep 3d [2]).К моменту начала нашего тестирования уже был известен ряд результатов, полученных главным образом для различных настольных приложений. Можно упомянуть, например, сопоставление Athlon64 X2 4800+ с Pentium D 840, Pentium 4 840/EE и другими процессорами на сайте www.anandtech.com, показывающее превосходство двухъядерных процессоров AMD по производительности на разных тестах (в том числе, Winstone2004 и SysMark2004). На сайте www.tomshardware.com проведено аналогичное сопоставление на многих тестах (в их числе PCMark 2004 и ScienceMark 2.0), выявившее превосходство двухъядерных Athlon64 X2. Однако там есть и противоположный пример, когда при работе смеси из четырех процессов Pentium 4 оказался быстрее благодаря поддержке HyperThreading.
На тестах SysMark2004 Opteron 275 опередил Pentium 4 840/EE и Pentium 4 EE/3,73 ГГц более чем на 30% (www.sudhian.com). Там же были приведены и результаты для шахматной программы Diep: Opteron 275 оказался более чем в полтора раза быстрее на одной нити, и вдвое быстрее при распараллеливании на двух нитях по сравнению с процессорами Intel. Однако не нужно забывать, что двухъядерные процессоры Pentium D дешевле, чем у AMD.
Тестировавшиеся аппаратные средства
В тестах использован 1U-сервер Supermicro AS-102A-8. Он содержал два двухъядерных процессора Opteron 275 stepping 2 с тактовой частотой 2,2 ГГц, имеющих стандартную емкость кэша в 1 Мбайт на ядро. Таким образом, тестировались самые старшие на данный момент модели двухъядерных процессоров AMD.
Сервер был укомплектован материнской платой Supermicro H8DAR-8 с набором микросхем AMD8131/AMD8111. На плате была установлена память DDR333 CL2.5 (четыре модуля DIMM емкостью по 1 Гбайт, по два на каждый процессорный разъем).
Сервер был снабжен BMC-платой от Supermicro, поддерживающей IPMI 2.0, для контроля скоростей вращения двух вентиляторов, температур обоих процессорных микросхем и общей температуры системы.
При нагрузке, создаваемой серьезными задачами вычислительной химии, температура Opteron не поднималась выше 50? C. При этом в машинном зале Центра компьютерного обеспечения химических исследований (ЦКОХИ) Института органической химии РАН, где проводилось тестирование, температура составляла 22?. (В применяющихся нами двухпроцессорных 4U-серверах на базе Opteron 242/1,6 ГГц в тех же условиях процессоры разогревались до более высоких температур.)
Для сравнения результаты некоторых тестов сопоставлены с данными для двухпроцессорных серверов с Opteron 242/1,6 ГГц, в которых также применяется память DDR333 (четыре модуля DIMM емкостью 512 Мбайт, по два модуля к каждому процессору).
Использованные программные средства
Операционная система
Сервер работал с ОС Linux 2.4.21 (SMP-ядро) в составе дистрибутива SuSE Linux 9.0, используемого также в кластере на базе Opteron 242 в ЦКОХИ. Последняя версия SuSE 9.3 имеет определенные сложности при инсталляции на серверах с двухъядерными процессорами Opteron, поэтому в условиях ограниченного времени доступности сервера для тестирования от нее было решено отказаться. Кроме того, в SuSE 9.3 используется ядро 2.6.11, а эффективная поддержка NUMA-режима, по имеющейся информации, стала доступна лишь с 2.6.12.
Однако надо учитывать, что при использовании NUMA-режима, когда процессу распределяется физическая оперативная память, подсоединенная к тому процессору, на котором работает процесс, производительность памяти может существенно увеличиться, и соответственно возрастет производительность приложений, интенсивно работающих с памятью.
Компиляторы, математические библиотеки и приложения
В наших тестах были использованы лучшие оптимизирующие компиляторы, умеющие генерировать 64-разрядные коды для Opteron/Athlon64 и Intel EM64T: EKO Path Compiler Suite 2.1 от Pathscale (включая Фортран-90 и Си), компилятор Фортран-90 ifort-8.1.023 от Intel, и компиляторы pgf77/pgf90 6.0-4 от Portland Group/STM. В использованных тестах можно было применять и g77, однако он обычно дает более низкие результаты (хотя, по доступной информации, качество его оптимизации в последнее время заметно улучшилось).
В тестах Linpack (n=1000) были сопоставлены все основные библиотеки оптимизированных 64-разрядных математических программ — AMD acml 2.6.0, Intel MKL 7.2, Atlas 3.7.8 и Kazushiga Goto 0.94.
В тестах, использующих MPI, применялись средства LAM MPI 7.0. Для измерения времени выполнения тестов Linpack применялся таймер, подобный стандартному для тестов STREAM, использующий системный вызов gettimeofday, а также более точный таймер с использованием счетчика тактов RDTSC [3], доработанный в ЦКОХИ для поддержания 64-разрядной архитектуры х86-64. Мы обнаружили, что вызов gettimeofday дает нестабильные результаты на тестах Linpack (n=1000), и применяли RDTSC-таймер.
В качестве приложений были использованы последние версии двух, пожалуй, наиболее популярных комплексов программ для решения задач вычислительной химии — Gamess-US и Gaussian-03 Rev. C02. Выбор этих приложений был обусловлен также и разнообразием типов рабочей нагрузки, которую можно получить в различных режимах расчета, и различными использованными инструментами распараллеливания: Linda для Gaussian (www.lindaspaces.com), DDI для Gamess.
В случае Gaussian-03 применялась стандартная двоичная версия от Gaussian, транслированная с pgf77-5.1. Gamess-US был транслирован в 32-разрядном варианте с использованием ifort-9.0, с ключами -O3 -xW. Кроме того, испытывалась создаваемая в ЦКОХИ в рамках проекта РФФИ 04-07-90220 программа замены диагонализации фокиана (в полуэмпирических расчетах сверхбольших молекул) прямым построением матрицы плотности в рамках схемы AM/1 [6]. В этой программе используется MPI; для трансляции применялся pathf90. Учитывая, что задачи вычислительной химии являются «классикой» для высокопроизводительных вычислений, проведенные тесты актуальны для оценок производительности двухъядерных Opteron в целом при различных рабочих нагрузках.
Тесты оперативной памяти
Первое, с чего мы начали, были тесты STREAM (www.streambench.org). В отличие от одноядерных Opteron, имеющих каждый собственные каналы в оперативную память, пары ядер двухъядерных процессоров разделяют общий канал. Таким образом, пропускная способность памяти в расчете на ядро падает вдвое. А в тестах STREAM именно пропускную способность и измеряют — на примере циклов copy (тело a(i)=b(i)), scale (a(i)=s*b(i)), add (a(i)=b(i)+c(i)) и triad (a(i)=b(i)+s*c(i)). Тесты STREAM должны показать, насколько ухудшаются показатели пропускной способности в расчете на ядро.
Пропускная способность памяти лимитирует производительность многих приложений. Например, это важно для задач гидро- и аэродинамики, где используются сеточные методы решения уравнений в частных производных. Классический пример — краткосрочный прогноз погоды.
По данным, полученным автором от Алана Шейнина из исследовательского центра в Сардинии, на одной из задач четыре ядра Opteron 275 оказались близки по производительности к двум (!) одноядерным процессорам Opteron с той же тактовой частотой. На других задачах четырехъядерный двухпроцессорный сервер оказался на 20-40% медленнее, чем два двухпроцессорных узла кластера с одноядерными Opteron.
Шейнин использовал ядра 2.6.9 и 2.6.12; по всей видимости, переход к ядру 2.6.12 способен существенно улучшить производительность. Он пришел к выводу, что на приложениях, где лимитирующим фактором оказывается пропускная способность памяти, лучше использовать одноядерные Opteron.
Другой иллюстрацией важности проблемы пропускной способности памяти могут служить коды программ моделирования океана (Стив Кузинс, Университет Майне, США) или наши коды вычислительной химии с заменой диагонализации. В обоих случаях оказалось предпочтительным использовать N однопроцессорных узлов кластера вместо N/2 двухпроцессорных. Так, на четырех ядрах Opteron 275 Кузинс не смог получить ускорения выше 2,5 раза.
Не менее важно для тестов STREAM и то, что имеются корреляции между показателями SPECcpu2000 и результатами в тесте triad. А показатель SPECfp_rate2000 можно приблизительно оценить по данным triad и пиковой производительности процессора.
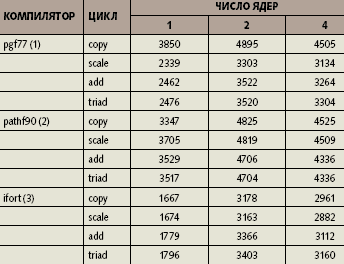
В зависимости от используемого способа распараллеливания соответствующих циклов имеется несколько разновидностей тестов STREAM. Стандартные тесты STREAM предполагают применение средств OpenMP (распараллеливание в модели общего поля оперативной памяти). Нами была использована последняя версия STREAM 5.4 (см. табл. 2).
|
| Таблица 2. Результаты тестов STREAM (Мбайт/с) на двухъядерных Opteron 275 |
Кроме того, имеется MPI-версия STREAM. Мы проверяли пропускную способность, достигаемую в ней, на сервере с Opteron 242 (табл. 3) и нашли, что пропускная способность в MPI-версии обычно несколько ниже (до 10% по сравнению с OpenMP), а масштабирование пропускной способности от одного к двум процессорам хуже (1,82-1,96 против 1,95-1,99 для OpenMP).
Из табл. 3 видно, что при фиксированном типе памяти (DDR333) рост частоты процессора (на 37,5%, с 1,6 до 2,2 ГГц) может приводить к небольшому росту пропускной способности на одной нити STREAM. Распараллеливание OpenMP-версии близко к идеальному (чуть меньше двух).
Практически идеальное масштабирование пропускной способности на данных тестах в серверах с одноядерными Opteron — следствие их эффективной микроархитектуры, включающей, подобно IBM Power5, встроенный контроллер памяти. В серверах с двухъядерными Opteron проявляется проблема разделения пропускной способности памяти (см. табл. 1).
Наши тесты показали, что масштабирование пропускной способности при переходе к применению двух ядер составило около 30% для pathf90. Для ifort масштабирование близко к 1,9 — возможно, потому, что пропускная способность на одной нити резко меньше; мы не подбирали ключи оптимизации для ifort, и эти результаты могут быть улучшены. pgf77 занимает промежуточное место между pathf90 и ifort.
Теоретически на двух ядрах Opteron 275 можно получить почти двукратное масштабирование пропускной способности, если использовать по одному ядру от каждого Opteron. Для этого требуется достичь двух целей.
Распределение оперативной памяти по «NUMA-схеме». Иными словами, надо обеспечить выделение памяти для нити в ее части, физически напрямую подключенной к процессору, на котором нить выполняется. В использованном нами ядре эффективная поддержка NUMA отсутствовала; с ядрами 2.6, как уже было сказано, ситуация может существенно улучшиться.
Применение в планировщике ядра «процессорного сродства». Средства из разряда processor affinity давно существуют в разных диалектах ОС Unix для многопроцессорных серверов. Их цель — приписать процесс к определенному процессору с тем, чтобы предотвратить миграцию выполняющегося процесса на другой процессор: это невыгодно для нитей высокопроизводительных приложений, поскольку требует дополнительного времени на заполнения кэша в «новом» процессоре. Для поддержания процессорного сродства в Linux имеется пакет schedutils, однако в данном случае он нами не применялся.
Если масштабирование при переходе от одного к двум ядрам оказалось различным для разных компиляторов, то при переходе к четырем ядрам все три компилятора «сошлись во мнении»: пропускная способность на четырех нитях оказалась меньше, чем на двух.
Результаты измерений на тестах STREAM практически подтверждают наличие проблемы пропускной способности оперативной памяти в многоядерных процессоров Opteron и позволяют объяснить плохое масштабирование с числом ядер некоторых приложений. Далее мы рассмотрим, насколько этот недостаток может сказаться на других задачах вычислительного характера.
Результаты тестов Linpack
Напомним, что тесты Linpack состоят в решении системы линейных уравнений размерности n x n методом Гаусса [3]. Остановимся сначала на результатах тестов Linpack для n=100, которые, среди прочего, позволяют сопоставить качество оптимизации компиляторов на типичных несложных циклах типа DAXPY (матрицу умножить на вектор плюс вектор).
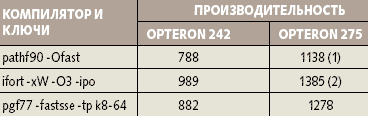
Оказалось, что компилятор pathf90, который считается лучшим, сгенерировал коды, которые существенно уступают ifort даже без максимального уровня оптимизации -xP, требующего коррекции выполняемого кода для обеспечения работоспособности на Opteron (см. табл. 4). Компилятор pgf77 также дает более высокий результат, чем pathf90.
|
| Таблица 4. Производительность на тестах Linpack (n=100), MFLOPS |
Таким образом, на Linpack (n=100) лучшие показатели обеспечивает Фортран-компилятор от Intel, а pathf90 проигрывает конкурентам. Кроме того, из табл. 4 видно, что увеличение частоты Opteron на 37,5% (от Opteron 242 к Opteron 275) сопровождается почти линейным ростом производительности.
Из табл. 5 видно, что наилучших результатов как по абсолютной производительности, так и по масштабируемости с числом процессоров позволяет добиться библиотека acml от AMD. Kazushiga Goto на одном процессоре чуть хуже; Atlas уступает им обоим, обгоняя лишь MKL. Однако с ростом числа процессоров/ядер масштабирование MKL лучше, чем у Atlas.
Достигаемое масштабирование производительности для MKL и acml на двух процессорах Opteron 242 близко к 1,9. Однако при использовании Opteron 275 на двух ядрах ускорение меньше — всего в 1,3 раза; при переходе от двух к четырем ядрам производительность возрастает всего лишь на 20% для Atlas и на треть — для MKL. Можно предположить, что это обусловлено проблемой пропускной способности памяти, поскольку на одноядерных микропроцессорах переход от двух к четырем процессорам способен давать ускорение в 1,8-1,9 раза.
Интересно сопоставить полученные результаты с данными для процессоров Pentium 4/Xeon, поскольку на тестах Linpack процессоры Intel показывают более высокие результаты.
Для новых 64-разрядных процессоров Xeon Nocona/3,2 ГГц с использованием ifort была зафиксирована производительность 1584 MFLOPS. Это наивысший результат в таблице, даже выше, чем у процессоров векторных суперкомпьютеров.
Однако Opteron 275 медленнее всего на 14%, в то время как пиковая производительность Nocona, как и тактовая частота, в полтора раза выше. Таким образом, на Opteron достигается существенно более высокий процент от пиковой производительности.
Тесты задач вычислительной химии
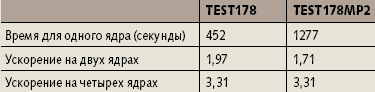
В табл. 6 приведены результаты для Opteron 275, полученные для комплекса программ Gaussian, а в табл.7 — для Gamess-US. В качестве «базовой» использовалась молекула тринитротриаминобензола из стандартного теста test178 к Gaussian-03 (размерность базиса равна 300), за исключением стандартного test397 (808 базисных функций).
|
| Таблица 7. Тесты Opteron 275 c Gamess-US |
Самый простой метод RHF (test178) практически не ускоряется при переходе к двум ядрам Opteron 275 даже в наиболее эффективном в данном случае распараллеливании в модели общего поля памяти (OpenMP). Это вызвано малым средним временем расчетов между взаимодействиями нитей, для увеличения которого во всех тестах, кроме test397, был отключен учет симметрии. В этом случае test178 распараллеливается удовлетворительно.
Однако при работе с Linda, где обмены данными между параллельными процессами больше, уже на двух ядрах наблюдается не ускорение, а замедление расчета. Очевидно, при этом возникла проблема пропускной способности памяти. На четырех ядрах была использована гибридная схема распараллеливания — две нити в OpenMP при двух Linda-процессах.
Идеальным должен был бы стать вариант, когда два Linda-процесса считаются на разных процессорах и каждый Linda-процесс, в свою очередь, распараллелен в OpenMP (две нити, по одной на каждое ядро процессора). Тогда проблема пропускной способности при обменах между ядрами одного процессора устраняется за счет использования общей памяти, а обмены данными между Linda-процессами относились бы к передачам между разными процессорными микросхемами, имеющими собственные каналы в памяти.
При работе Linda-процессов на парах ядер каждой процессорной микросхемы в тестах наблюдалось замедление относительно одного процессора — более сильное, чем при Linda-распараллеливании на два ядра.
Когда времена расчета более чем на порядок выше, чем в test178 (другие методы из табл. 6), частота обменов данными в Linda, очевидно, уменьшается, и ускорение становится приемлемым. Однако результаты в модели OpenMP по понятным соображениям оказываются обычно более хорошими, чем в Linda.
Можно сказать, что ускорение, достигаемое при распараллеливании задач квантовой химии в модели общего поля памяти на двухъядерных процессорах Opteron, выглядит вполне удовлетворительным, хотя оно зависит и от размера молекулы/базиса, и от метода расчета (так, ускорение для MP2 получилось несколько ниже, чем в Linda).
При использовании Linda на двух ядрах ускорение может быть удовлетворительным, но на четырех ядрах оно оказалось близко к 3. Данные test397 ясно указывают при этом на проблему пропускной способности памяти: в кластерах удвоение числа процессоров обычно приводит к ускорению в 1,8-1,9 раза, а на четырех ядрах Opteron 275 ускорение значительно хуже.
Остановимся на сравнении с двухузловым кластером на Giagbit Ethernet на базе двухпроцессорных узлов с Opteron 242. На одном ядре Opteron 275 задача считается на 30% быстрее, чем на Opteron 242. На двух процессорах Opteron 242 в узле ускорение равно 1,89, на четырех процессорах кластера — 3,53, что существенно выше, чем в Opteron 275 при работе с Linda (табл. 6).
Первые данные по оценкам эффективности Opteron 275 на Gaussian-03 были получены в Стэнфордском университете (www.sg-chem.net/cluster). Однако они ограничены только test397 и только распараллеливанием в OpenMP, в котором проблемы пропускной способности могут не проявляться. Нами же были рассмотрены все режимы распараллеливания Gaussian на более широком классе методов квантовой химии.
В наших тестах для Gamess-US (табл. 7) использовались те же молекулы, базисы и методы расчета (включая прямые расчеты с пересчетом интегралов), что и в Gaussian-03. Однако из-за различных критериев сходимости и других параметров прямое сопоставление времен расчетов по различным программам является некорректным, и можно пробовать сопоставлять лишь ускорение. Можно сказать, что применение DDI (с настройкой на работу через сокеты) в Gamess-US для RHF и MP2 дает вполне удовлетворительные результаты, близкие к полученным в OpenMP для Gaussian.
При этом необходимо учитывать возможную по?правку на резкое отличие времен выполнения по Gaussian и Gamess-US, что приводит, вероятно, к разной доле времени обмена данными в общем времени выполнения. Для метода MP2 время расчета в Gamess-US оказалось ниже, а ускорение — выше, чем в Gaussian, поэтому можно говорить о лучшей масштабируемости Gamess-US в этом методе.
Метод CIS (test178cis) в Gamess не поддерживается. Что касается test397, то время расчета по Gamess оказалось неприемлемо большим (задача была снята более чем через сутки после начала выполнения).
Для исследования возможностей распараллеливания задач квантовой химии, в которых ограничивающим фактором является пропускная способность межсоединения, в модели обмена сообщениями MPI, «не знающей» о наличии общего поля оперативной памяти, в ЦКОХИ был проведен тестовый расчет молекулы с размерностью базиса, равной 6500 (2600 атомов). Применялась разрабатываемая [6] полуэмпирическая программа прямого построения матрицы плотности путем ее «очистки». При использовании Opteron 275 на 3 ядрах было получено достаточно неплохое ускорение — 2,75.
В то же время, как уже отмечалось, при использовании двухпроцессорных узлов в кластере на базе Xeon проявили себя проблемы с пропускной способностью памяти. Вероятно, хорошее ускорение в данном случае определяется соотношением производительности процессора (в задаче лимитируют вызовы dgemm, производительность на которых близка к пиковой), пропускной способностью оперативной памяти и размерностью задачи. Пиковая производительность Opteron ниже, чем Xeon, поэтому обмены данными между MPI-процессами реже, а ускорение выше.
Выводы
- Анализ микроархитектуры двухъядерных процессоров AMD Opteron/Athlon64 показывает их преимущества в организации иерархии памяти по сравнению с двухъядерными х86-процессорами Intel.
- Проведенные измерения производительности на тестах STREAM экспериментально подтверждают наличие проблемы разделения пропускной способности оперативной памяти в двухъядерных процессорах Opteron 275. Однако это характерно для всех современных двухъядерных микропроцессоров, а достигаемая пропускная способность может улучшиться при переходе от использованного ядра Linux 2.4 к 2.6.
- Впервые получены оценки производительности на тестах Linpack (n=100, 1000) для ряда процессоров (в том числе для двухъядерных процессоров Opteron), которые войдут в очередную версию официальной таблицы тестов. Получен, в частности, наивысший среди всех процессоров (в текущей версии таблицы) результат при n=100 для процессоров Xeon Nocona/3,2 ГГц.
- Измерения ускорения, достигаемого при распараллеливании приложений вычислительной химии на двухпроцессорном сервере с двухъядерными процессорами Opteron 275, и проведенный анализ литературных данных показывают, что применение таких процессоров на многих задачах оказывается эффективным.
Литература
- М. Кузьминский, «64-разрядные микропроцессоры AMD». Открытые системы, № 4, 2002.
- М. Кузьминский, «О программе Diep3d и ее авторе». Computerworld Россия, № 10, 2005.
- М. Кузьминский и др., «Пути модернизации программных и аппаратных кластерных ресурсов для задач вычислительной химии». Сб. материалов II международного научно-практического семинара «Высокопроизводительные параллельные вычисления на кластерных системах», ННГУ, 2002.
- M. Schmidt, K. Baldridge, J. Boatz e.a., J. Comp. Chem., v. 14, 1993.
- Gaussian 03 Revision C.02, M.J. Frish, G.W. Trucks, H.B. Shlegel e.a., Gaussian, Inc., Wallingford CT, 2004.
- В.В. Бобриков, А.М. Чернецов, О.Ю. Шамаева, «Распараллеливание квантово-химических расчетов матрицы плотности с использованием полиномов Чебышева»: П. В сб. «Международный форум информатизации МФИ-2004. Труды международной конференции «Информационные средства и технологии», т. 1, 2004.
- Yu. J.-S. Kenny, Yu. Chim-Hui, J. Chem. Inf. Comput. Sci., v. 42, 2003.
Михаил Кузьминский (kus@free.net) — старший научный сотрудник ИОХ РАН (Москва). Автор выражает благодарность РФФИ за поддержку данной работы (проект 04-07-90220), компании «Т-платформы» — за возможность доступа к серверам на базе Xeon Nocona и компании Niagara Computers — за предоставление на тестирование сервера Supermicro на базе Opteron 275.
