

Метакомпьютер* — сетевая среда распределенных вычислений с децентрализованной иерархической системой управления, объединяющая разнородные вычислительные ресурсы. Сегодня имеется множество решений для управления заданиями в такой среде, но пока ни одна из разработок не достигла стадии программного продукта, готового к промышленному использованию.

Метакомпьютер образован совокупностью вычислительных систем (ВС), управляющих компьютеров и, возможно, вычислительных модулей (ВМ), связанных одной или несколькими коммуникационными средами для предоставления пользователям прозрачного доступа к вычислительным ресурсам, которые превышают ресурсные возможности отдельных ВС. Прозрачность означает, что от пользователя скрыта конкретная топология метакомпьютера.
Ряд исследовательских проектов (например, grid.ncsa.uiuc.edu/GridShib) направлен на разработку систем управления метакомпьютером на основе инфраструктуры сервисов безопасности, пересылки файлов и запуска заданий пакета Globus Toolkit [1]. Следует также упомянуть работы, посвященные управлению заданиями в распределенной вычислительной среде, которые выполняются в ИПМ им. М.В. Келдыша РАН [2], ИСП РАН [3] и др. Однако пока ни одна из разработок не достигла стадии программного продукта, готового к промышленному использованию.
Для обеспечения прозрачного доступа пользователей к вычислительным ресурсам метакомпьютера в работе [4] предлагается новый подход к организации системы управления. При запуске и контроле над выполнением заданий пользователь взаимодействует с системой управления метакомпьютера, которая представляет собой распределенную самовосстанавливающуюся при отказах совокупность взаимодействующих менеджеров с древовидной топологией информационных связей.
Менеджеры могут выполняться на управляющих или выделенных компьютерах. В зависимости от объекта управления все менеджеры подразделяются на два типа — менеджеры вычислительных систем и менеджеры подсетей (доменов), объединяющих некоторое подмножество вычислительных систем и доменов нижнего уровня. Каждый менеджер следит за состоянием подконтрольных ему ресурсов, выделяет свободные ресурсы заданиям, управляет заданиями в процессе выполнения и реализует ряд других функций, включая поддержку работоспособности ресурсов.
Иерархическая древовидная структура системы управления обеспечивает отсутствие «дедлоков» при выполнении алгоритмов планирования заданий и выделении им ресурсов. Она позволяет сократить число объектов управления (вычислительных систем), приходящихся на один субъект управления (менеджер). Наконец, эта структура дает возможность учитывать специфику управления разнородными объектами за счет объединения под управлением одного менеджера компонентов, сходных по архитектуре, составу и типу ресурсов, политике администрирования и т.п.
В процессе функционирования менеджеры ведут базу данных ресурсов и обмениваются данными об их состоянии: каждому смежному менеджеру передается результат обобщения данных, полученных от остальных смежных менеджеров. Таким образом, в базе данных ресурсов каждого менеджера представлена обобщенная информация о состоянии всех вычислительных ресурсов метакомпьютера.
Планирование заданий системой управления состоит в установлении для каждого задания порядка выделения требуемого количества ресурсов каждого типа (процессоров, дисковой и оперативной памяти, внешних устройств, файлов и т.п.). Порядок выделения ресурсов зависит от алгоритмов планирования, реализуемых менеджерами системы управления. При рациональном выборе этих алгоритмов можно не только выделять заданию количество ресурсов, значительно превышающее ресурсные возможности отдельной ВС, но и получать пропускную способность метакомпьютера, превышающую суммарную пропускную способность всех ВС при обслуживании каждой из них своего потока заданий без перераспределения этих заданий между ВС. Последний эффект достигается за счет выравнивания загрузки ВС и отсутствия простоев одних ВС при наличии в очередях других заданий, ждущих освобождения ресурсов.
В качестве базового программного обеспечения, используемого для реализации функциональности системы управления метакомпьютера, применяется пакет Globus Toolkit [1]. В каждой ВС может использоваться какая-либо локальная система планирования заданий: поддерживаемая Globus Toolkit (LSF, PBS, PRUN, NQE, CODINE и др.) или другая, например СУПЗ в МВС-1000 [5,6], дополненная интерфейсом с Globus. Для удаленного запуска и управления заданиями используются возможности службы GRAM, входящей в состав Globus Toolkit.
Брокер задания
Задания пользователей специфицируются паспортом [6]. В нем указываются необходимые для решения прикладной задачи программы и данные, а также задаются требования к вычислительным ресурсам: какое количество ресурсов каждого типа необходимо выделить и на какой временной интервал. Ввод задания в метакомпьютер осуществляется через управляющий компьютер одной из ВС. При этом на компьютере запускается специальный сервис взаимодействия с пользователем — брокер задания (БЗ).
БЗ проверяет корректность спецификации задания, при необходимости дополняет параметры паспорта задания и передает его менеджеру системы управления, функционирующему на данной ВС. В дальнейшем БЗ получает информацию о ходе планирования заданий от менеджеров системы управления и предоставляет ее пользователю.
Менеджер ВС с учетом текущего состояния базы данных ресурсов и в соответствии с реализуемой стратегией планирования принимает решение о назначении задания на ресурсы своей ВС, передает его смежному менеджеру или ставит в свою очередь заданий (если в метакомпьютере нет требуемых ресурсов). После каждого изменения состояния базы данных ресурсов менеджер просматривает свою очередь заданий и выбирает для дальнейшего планирования те задания, для которых появились необходимые ресурсы в какой-либо ВС.
В случае принятия решения о назначении задания некоторой ВС, менеджер этой ВС сообщает ее адрес БЗ для удаленного запуска задания средствами пакета Globus Toolkit, а после запуска задания передает БЗ сведения о ходе его выполнения. Запуск задания может осуществляться непосредственно менеджером ВС или системой планирования заданий ВС (СУПЗ, PBS и т.п.). В последнем случае менеджер ограничивается постановкой задания в очередь системы планирования заданий, которая запускает его в соответствии с собственным алгоритмом обслуживания очередей.
Все взаимодействия между брокером и менеджерами осуществляются через безопасную среду передачи данных, формируемую средствами подсистемы безопасности пакета Globus Toolkit — GSI (Globus Security Infrastructure).
Алгоритм функционирования менеджеров системы управления
После запуска системы управления метакомпьютера между менеджерами устанавливается защищенное SSL-соединение и в результате опроса подконтрольных ресурсов инициализируется база данных ресурсов менеджеров. Менеджеры обмениваются сообщениями двух типов: изменение (содержит указание на корректировку базы данных ресурсов) и запрос ресурса (содержит паспорт введенного в метакомпьютер задания). Первый тип сообщений используется для распространения по системе менеджеров сведений об изменении состояния ресурсов метакомпьютера. Кроме того, он позволяет извещать брокера задания о постановке задания в очередь менеджера или системы планирования заданий ВС, о начале или завершении выполнения задания. Получив такое сообщение, менеджеры используют содержащуюся в нем информацию для корректировки своей базы данных ресурсов, формируют обобщенное описание состояния ресурсов, а в случае его отличия от предыдущего обобщенного описания транслируют изменения смежным менеджерам.
Для определения ВС метакомпьютера с требуемым количеством свободных ресурсов используется таблица свободных ресурсов базы данных ресурсов. Каждая строка таблицы соответствует одной из ВС, управляемой данным менеджером, или одному из доменов, который содержит указанные свободные ресурсы. Владелец свободного ресурса (ВС или домен) идентифицируется адресом URL или IP. Для идентификации домена используется адрес ВС, в которой функционирует смежный менеджер в направлении домена (по дереву менеджеров), содержащего этот свободный ресурс.
Обобщенная информация о свободных ресурсах, имеющихся в соответствующей ВС или домене метакомпьютера, содержится в строках таблицы в виде списка {R1,R2,...}, где Ri — количество единиц свободного ресурса в одной из ВС метакомпьютера. Обобщение описания состояния свободных ресурсов заключается в том, что в список свободных ресурсов каждое значение включается однократно и без детализации его расположения в метакомпьютере (в случае адресации домена). Точный адрес ресурса (адрес ВС) определяется в процессе планирования и назначения задания при передаче паспорта задания от одного менеджера к другому.
При получении менеджером сообщения второго типа от БЗ или смежного менеджера содержащийся в сообщении паспорт задания помещается в очередь заданий соответствующего менеджера. Просмотр очереди заданий осуществляется менеджером после получения каждого сообщения 1-го или 2-го типа. Задания выбираются из очереди для дальнейшего планирования с учетом их приоритетов и получаемых из базы данных ресурсов менеджера сведений о наличии необходимых ресурсов. Выбранное задание передается менеджеру, адресуемому полем «Адрес владельца ресурса» строки таблицы, которая соответствует выделяемому заданию свободному ресурсу.
После назначения задания ВС ее менеджер устанавливает защищенное соединение с брокером задания и сообщает ему адрес ВС для выдачи команды на запуск задания от имени пользователя. Блок-схема алгоритма функционирования менеджера системы управления приведена на рис. 1.
Организация ввода/вывода
Время выполнения программы в метакомпьютере серьезно зависит от распределения используемых ею данных по ВС. Одним из апробированных способов повышения эффективности ввода/вывода является отказ от использования разделяемого диска управляющего компьютера и запуск заданий на тех ВМ, на локальных дисках которых уже находятся все необходимые данные. В частности, этот подход используется для организации контрольных точек, если система планирования заданий позволяет при рестарте занять те же ВМ [6].
Такому варианту назначения задачи присущи значительные временные задержки, связанные с необходимостью ожидать освобождения всех ВМ, на которых размещены наборы данных контрольной точки.
Для уменьшения времени доступа к удаленно расположенным данным возможно их кэширование в ВС в сочетании с упреждающей выборкой. Она осуществляется в соответствии с прогнозируемой последовательностью обращений к блокам файла данных.
Упреждающее кэширование
Сервис упреждающего кэширования реализуется как надстройка над распределенной файловой системой PVFS [7]. Выбор этой файловой системы обусловлен ее популярностью и распространенностью, а также тем, что PVFS может быть загружена как приложение на ВМ, выделенные для выполнения параллельной программы.
Для обеспечения независимости от размера блока данных, принятого в файловой системе, кэширование осуществляется порциями блоков. Размер порции в блоках фиксирован и задается при развертывании системы кэширования. В каждую ячейку дисковой кэш-памяти помещается одна порция файла. Каждый блок данных присутствует в дисковой кэш-памяти однократно. Структура дисковой кэш-памяти представляет собой совокупность ячеек, каждая из которых состоит из трех полей: флаг состояния ячейки (занята/свободна), файловый дескриптор начального блока порции данных и непосредственно данные.
Информация о блоках, записанных в дисковую кэш-память, заносится в таблицу кэшируемых блоков, которая содержится в специально выделенной области оперативной памяти. Таблица кэшируемых блоков содержит дескриптор файла, дескриптор блока данных, адрес ячейки в дисковой кэш-памяти (смещение начала ячейки от начала файла кэш-памяти), в которой размещен данный блок, время записи блока в кэш и флаг модификации блока (модифицирован/не модифицирован).
Для каждой параллельной задачи на управляющем компьютере запускается менеджер файлового кэширования вычислительной системы (МКВС), а на каждом выделенном для исполнения этой программы ВМ — менеджер файлового кэширования вычислительного модуля (МКВМ). МКВС кэширует в глобальной дисковой кэш-памяти ВС блоки файлов, расположенных вне данной вычислительной системы (удаленно расположенных). МКВМ осуществляет кэширование в локальной дисковой кэш-памяти ВМ блоков файлов, расположенных на дисках ВС (локальных файлов), включая и блоки глобальной дисковой кэш-памяти ВС.
Информация об удаленно расположенных файлах скрыта от МКВМ. Алгоритмы функционирования МКВМ и МКВС почти аналогичны. Разница состоит лишь в том, что в МКВС запросы на ввод/вывод поступают не от прикладного процесса, а от процессов подкачки данных, и подкачка данных осуществляется в глобальную дисковую кэш-память из удаленно расположенных файлов. Блок-схема обобщенного алгоритма функционирования менеджеров приведена на рис. 2.
Описанные варианты организации системы управления ресурсами и заданиями, алгоритмы упреждающего кэширования данных в метакомпьютере были исследованы на имитационных моделях и показали свою эффективность. Сейчас осуществляется их реализация в метакомпьютере, объединяющем вычислительные ресурсы ряда научно-исследовательских организаций и учебных заведений.
ЛИТЕРАТУРА
- Foster Ian, Kesselman Carl. Globus: A Metacomputing Infrastrusture Toolkit.
- Коваленко В., Коваленко Е., Корягин Д., Любимский Э., Хухлаев Е.. Управление заданиями в распределенной вычислительной среде. Открытые системы, 2001, №5-6.
- Avetisyan A., Gaissaryan S., Grushin D., Kuzjurin N., Shokurov A. Managing Parallel Computational Tasks in a Grid Environment. The XIX International Symposium on Nuclear Electronics & Computing. Bulgaria, Varna, Sep. 2003.
- Korneev V.V., Vasenin V.A., Kiselev A.V., Baranov A.V., Roganov V.A. The Approach to Building the System Software for Parallel Supercomputers/ Proceedings of the 8th World Multi-Conference on SYSTEMICS, CYBERNETICS AND INFORMATICS. SCI 2004 July 18--21, 2004, Orlando, Florida (USA), vol. II, Computer Techniques.
- Фортов В.Е., Левин В.К., Савин Г.И., Забродин А.В., Каратанов В.В., Елизаров Г.С., Корнеев В.В., Шабанов Б.М. Суперкомпьютер МВС-1000М и перспективы его применения. — М:^ Наука и промышленность России. 11(55) 2001.
- Баранов А.В., Лацис А.О., Храмцов М.Ю., Шарф С.В. Руководство системного программиста (администратора) системы управления прохождением задач МВС-1000/М.
- Carns P. H., Ligon W. B. III, Ross R. B. and Thakur R. PVFS: A Parallel File System For Linux Clusters. Proceedings of the 4th Annual Linux Showcase and Conference Atlanta, GA, October. 2000, с. 317-327.
Андрей Киселев (a_v_k@rambler.ru), Виктор Корнеев (korv@rdi-kvant.ru), Дмитрий Семенов, Илья Сахаров — сотрудники ФГУП «НИИ «Квант» (Москва).
Оценка эффективности системы управления метакомпьютера
Исследовались три варианта системной организации вычислительных ресурсов: четыре независимые ВС и эти же ВС, объединенные в метакомпьютер по двум вариантам организации структуры информационных связей менеджеров (М) системы управления (см. рисунки).
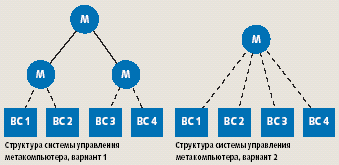
Во всех экспериментах использовались одинаковые реализации потоков заданий и длительностей их выполнения. Они были сформированы на основе статистических данных, полученных в процессе эксплуатации ВС МВС-1000/М в Межведомственном суперкомпьютерном центре РАН [5].
Эксперименты проводились для различного количества ВМ в ВС (от 5 до 500) и различной длительности моделирования (от 500 до 50 тыс. единиц модельного времени). Для каждой модели отношение числа выполненных заданий к общему количеству заданий, поступивших в систему, оставалось практически неизменным во всех экспериментах. При небольшом количестве ВС в метакомпьютере это отношение имеет практически одинаковые значения для моделей с 1 и 2 вариантами структуры системы управления. Так, за 5 тыс. единиц модельного времени в систему поступило 1658 заданий. Отношение количества обработанных заданий к общему количеству поступивших для моделей метакомпьютеров составило ~0,74, а при использовании модели независимых ВС равнялось ~0,49.
Эксперименты с увеличением числа моделируемых ВС в метакомпьютере показали снижение эффективности метакомпьютера с централизованным вариантом структурной организации системы управления (вариант 2) по сравнению с эффективностью метакомпьютера, имеющего иерархическую структуру информационных связей (вариант 1). Предложенный вариант построения системы управления сетевой средой распределенных вычислений обеспечивает большую эффективность использования вычислительных ресурсов по сравнению с системой независимых ВС и централизованным вариантом структурной организации управления.
Оценка эффективности упреждающего кэширования
Для экспериментов были разработаны модели двух вариантов вычислительной системы: с применением упреждающего кэширования и без него. Выигрыш от применения упреждающего кэширования оценивался с помощью сравнения модельного времени выполнения задачи для каждого варианта системы. В имитационных моделях использовались следующие допущения, упрощающие модель:
- прикладная программа содержит только операции чтения из файлов;
- обмен данными по коммуникационным каналам между ВМ одной ВС и между разными ВС моделировался в виде соответствующих временных задержек;
- за единицу модельного времени была принята длительность передачи одного блока данных по локальной вычислительной сети.
Для разведочного моделирования была использована следующая модель параллельной программы. Параллельная программа представляет собой совокупность одинаковых ветвей, каждая из которых выполняется на одном ВМ. Параметрами модели задаются количество используемых программой локальных и удаленно размещенных файлов, частота обращений к каждому файлу, вероятность обращения к следующему блоку файлов при выполнении очередной операции ввода, количество блоков данных, читаемых за одну операцию ввода. Каждая ветвь программы работает со своей частью каждого файла. Для каждой операции ввода случайно выбирается файл, к которому будет происходить обращение.
Исследовался наиболее простой алгоритм упреждающей загрузки данных One Block Lookahead (OBL) — подкачка на один блок вперед. Его сущность заключается в подкачке (i+1)-го блока данных в момент считывания i-го блока. При очистке кэша использовалась стратегия Last Recently Used (LRU) — выгружается самый неиспользуемый.
Имитационное моделирование показало, что упреждающее кэширование существенно повышает эффективность распределенной обработки данных. Например, на выполнение 300 операций ввода/вывода было потрачено ~17 тыс. единиц модельного времени, что оставляет ~52% от времени выполнения задания без применения механизма упреждающего кэширования (~33 тыс. единиц).
Очевидно, что время, требуемое для чтения порции данных из удаленно расположенных файлов, значительно больше времени чтения из локальных файлов ВС. Чем больше удаленно размещенных файлов использует программа, тем большую эффективность ВС обеспечивает применение упреждающего кэширования, поскольку каждое попадание к кэш дает значительный прирост производительности.
По результатам имитационных экспериментов можно сделать такой вывод: применение упреждающего кэширования дает увеличение производительности при преимущественном использовании программой удаленно размещенных файлов, для повышения эффективности работы с которыми и создавался этот механизм. Для локальных файлов эффективность упреждающего кэширования значительно ниже, что объясняется существенными накладными расходами, необходимыми для его поддержки.
*Авторы используют в своей статье термин «метакомпьютер», введенный на страницах журнала «Открытые системы» в 1999 году (http://www.osp.ru/os/1999/11-12/045.htm), однако в соответствии с изменениями терминологии в области распределенного компьютинга, в последующих публикациях по данной тематике применяется термин grid. — Прим. Ред.
