

Алгоритмы сортировок — одна из самых популярных тем в программировании. Однако ее обсуждение обычно сводится к тому, что быстрее сортировки Хоара (или, как ее называют, быстрой сортировки) еще не придумано. Но имеются уже другие подходы к разработке алгоритмов, например, параллельное программирование.

Сортировки обычно сравнивают по количеству операций сравнения и/или пересылки. Чем их больше, тем предположительно медленнее алгоритм [1]. Но такой подход явно не подходит к параллельным алгоритмам. Более универсальный критерий — абстрактное время работы алгоритма.
Если взглянуть на типичную блок-схему программы, то легко увидеть, что, как путь пешехода — не прямая линия, так и программа содержит ветвящиеся и циклические участки, а ее условные операторы подобно перекресткам и переходам разбивают программу на линейные участки. Эти участки и можно считать отдельным шагом — тактом абстрактного дискретного времени или линейной последовательностью таких шагов. Здесь каждый такт — это несколько операторов на языке высокого уровня или, если говорить о низком уровне реализации алгоритма, какое-то число команд ассемблера.
Но «программный путь» можно представить и как последовательную смену внутренних состояний алгоритма, когда переход из одного состояния в другое осуществляется, исходя из анализа значений внутренних и внешних данных, данных и текущих состояний других параллельных алгоритмов. И если условия для перехода наступили, то переход этот сопровождается выполнением действий. Иногда такие действия ассоциируются напрямую с состояниями и исполняются при любом переходе в них. Так обобщенно — в форме автоматов Мили и Мура — можно описать модель программ на базе модели конечного автомата.
Формально модели блок-схем и конечных автоматов эквивалентны; для любой блок-схемы можно создать эквивалентный автомат [3]. Для этого необходимо разметить операторы-действия блок-схемы (прямоугольники) символами внутренних состояний конечного автомата. При этом множество путей из одного состояния в другое определяет множество переходов, условия, встречающиеся на пути, — условие срабатывания перехода, операции — действия на этом переходе.
Переход от блок-схем к конечным автоматам делает явными дискретные шаги, присущие в той или иной форме любой модели вычислений. Они на формальном уровне соответствуют дискретным тактам абстрактного или модельного времени [4]. В модель автомата, в отличие от блок-схемы, модель реального времени включена явно: он по определению функционирует в дискретном времени. Зная реальную длительность дискретного такта и само количество тактов, можно довольно точно — точнее, чем по формуле — рассчитать реальное время работы модели.
Переход к эквивалентному автомату и последующий расчет дискретного времени его работы вводит критерий, который позволяет точнее оценить эффективность алгоритма, представленного блок-схемой. Мы исследуем его на известных алгоритмах сортировок. Кроме того, мы разработаем параллельные сортировки, сравним их между собой и с их последовательными «конкурентами».
Быстрая сортировка
Прежде чем рассмотреть быструю сортировку, рассмотрим самую простую — «пузырьковую». В работе [2] приведен листинг ее программы на Си, а блок-схема представлена на рис. 1. На ней показаны отметки, которые соответствуют внутренним состояниям эквивалентного автомата, а также имена предикатов и действий автомата, которыми помечены элементы блок-схемы. По аналогии созданы и автоматные модели сортировок Шелла и быстрой сортировки [2, 5].
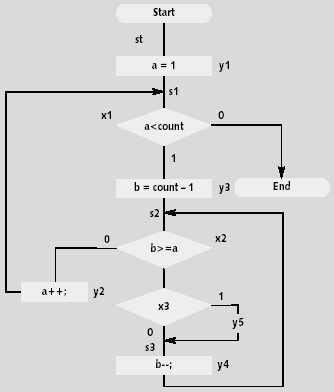
|
| Рис. 1. Алгоритм пузырьковой сортировки |
Автоматные модели позволяют точнее судить о сложности алгоритмов. Из сравнения по количеству состояний, числу входов/выходов (или предикатов/действий) и общему числу переходов следует, что сортировка Хоара самая сложная (таблица 1). Это общеизвестный факт, но только теперь он выражен еще и в конкретных цифрах.
В колонках таблицы 1 размещены результаты работы на массивах разной длины, где массив — кратное повторение тестового набора из 15 чисел — 1, 11, 15, 4, 9, 2, 7, 3, 5, 12, 10, 6, 8, 13, 14.
Полученные на автоматных моделях данные тестирования соответствуют известным оценкам скорости работы рассматриваемых алгоритмов. Видно, что и автоматная модель пузырьковой сортировки — самая медленная, а быстрая сортировка Хоара имеет преимущества в сравнении с сортировкой Шелла на больших наборах данных. Таким образом, абстрактное время работы эквивалентной модели столь же отражает характеристики исходного алгоритма, как и реальное время его работы.
Умная сортировка
Для демонстрации таких проблем параллельных систем, как блокировки или тупики (deadlock), ситуации отталкивания (starvation) и т.п., Дейкстра давно предложил задачу об обедающих философах [6, 7]. И приходится только удивляться, что ее еще не применили для решения проблемы сортировки.
В задаче несколько философов садятся обедать за общий стол, где каждому выделено место и вилка, лежащая слева. Для еды нужны две вилки, одну из которых философ должен взять (попросить) ее у соседа справа. Проблема не только в том, что сосед может ее не дать, или вилки соседа может не оказаться на месте, но и в том, что вилку самого философа могут взять, а потом и не вернуть. Решение задачи заключается в создании такого протокола взаимодействия между философами, который исключал бы конфликты, приводящие к «голодной смерти» одного из объектов.
Впрочем, сейчас нас в задаче о философах интересуют не тупики, а то, что им можно поручить задачу сортировки. Для этого нужно поручить каждому философу сортировку вилок, которыми он ест. Сами вилки при этом нужно предварительно перенумеровать (в соответствии с данными массива) и определить, кому из философов соответствует первый элемент массива. Через какое-то время философы упорядочат вилки в соответствии с критерием сортировки. Такой алгоритм сортировки на базе философов мы будем далее называть «умной сортировкой» или Ф-сортировкой.
В используемом нами решении отдельный философ представлен двумя параллельными моделями — «вилкой» и «слугой» [6, 7]. Модели представлены на рис. 2 автоматами P и F. Эти автоматы, взаимодействуя между собой, реализуют поведение отдельного философа, а философы, общаясь между собой, - общее поведение системы, решая, как в нашем случае, задачу сортировки данных. Связи автоматов на графе изображены пунктирными стрелками. Аналогичными стрелками показаны связи философа с его соседями. Автоматы и связи в сумме составляют модель философа в форме СМКА (сетевая машина конечного автомата) [8].
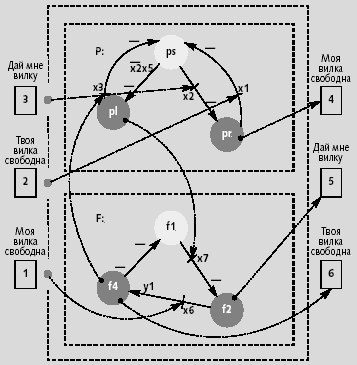
|
| Рис. 2. СМКА модель философа |
В СМКА компонентные автоматы функционируют параллельно и в едином дискретном времени. Поэтому мы вправе по числу тактов любого из автоматов сети судить о дискретном времени, которое затрачено системой на решение задачи. Абстрактнее время сортировки массивов данных философами приведено в таблице 2 (строка Philosopher). Сравнения таблиц 1 и 2 показывает, что философы сортируют массивы втрое быстрее, чем быстрая сортировка.
О реальном времени исполнения тестов
Обсудим теперь соответствие абстрактного и реального времен. Поскольку автоматные модели реализованы на виртуальной, а не на реальной машине, то от них нельзя ждать реальных скоростей, которые показывают эквивалентные им сортировки, реализованные на «родной» архитектуре.
Но, рассматривая реализацию параллельных алгоритмов и обращая внимание на реальную скорость работы, нужно учитывать и проблему реализации самого параллелизма. В современных популярных процессорах и операционных системах он, в основном, моделируется. При этом моделью параллельных вычислений следует считать модель потоков, нитей и т.п. Но это означает, что параллельные алгоритмы, исполняемые на виртуальной автоматной машине и на «родной», параллельной, но тоже виртуальной машине, находятся примерно в равных условиях. Таким образом, реализуя тот или иной параллельный алгоритм (те же сортировки), мы по их работе можем оценивать эффективность соответствующих параллельных моделей и/или виртуальных машин.
«Умная сортировка» представляет одновременно и параллельную модель вычислений. При этом она позволяет достаточно точно оценить эффективность реализации виртуальной машины, а не только алгоритма сортировки как такового. Данные таблицы 2 позволяют оценить скоростные качества параллельной автоматной модели. И если реализовать этот же алгоритм, используя типовые параллельные механизмы (нити и т.п.), то скорость сортировки будет в несколько раз меньше.
Реальное время выполнения теста можно определить лишь с определенной точностью. Дискретные же шаги или абстрактное время определяются точно. Безусловно, при сравнении разных алгоритмов, нужно учитывать отличие в кодах действий, а также его влияние на реальное время работы модели, но, как правило, у близких алгоритмов, а тем более эквивалентных, одинаковые по смыслу действия и отличаются незначительно.
Конвейерная сортировка
Практическая значимость задачи сортировки и результаты тестирования Ф-сортировки стимулируют на поиски еще более эффективных алгоритмов. Можно ли сортировку еще ускорить? Один из путей — создать большее число связей между объектами, другой — использование более простых протоколов. Последний путь, который мы рассмотрим на примере «конвейерной сортировки», наиболее реален.
Представим философов, которые, подчиняясь определенному ритму, как на конвейере, берут вилки, затем едят и, меняя, если необходимо, их местами, кладут вилки опять на стол. А чтобы при этом не было конфликтов с соседями, пусть философы делают это через одного и через такт. Пусть, к примеру, на одном такте пищу поглощают («сортируют») философы с нечетными номерами, на другом — с четными. Результаты работы такой «конвейерной сортировки» представлены в таблице 2 строкой Pipeline. Скорость сортировки «на конвейере» выросла более чем в пять раз!
Об эффективности автоматной виртуальной машины
Попробуем оценить использованную при тестировании виртуальную машину с точки зрения эффективности реализации параллельных процессов. Для чего сведем результаты тестирования последовательной автоматной сортировки Хоара и параллельных алгоритмов в отдельную таблицу 3.
В сравнении с алгоритмом Хоара процесс сортировки может быть ускорен в пятнадцать раз. Но, правда, в абстрактном времени. В реальном же времени, алгоритм Хоара в разных режимах работы имеет или самую высокую скорость работы или самую низкую. При этом режим работы без вывода текущей информации о состоянии массива соответствует приложению вычислительного типа. Так работают, например, стандартные библиотечные функции.
Сортировка «на базе философов» — это аналог приложения реального времени, у которого количество, например, контролируемых датчиков равно количеству параллельных процессов. Реальное время реакции такого приложения определяется длительностью одного такта модели. Оно вычисляется делением времени исполнения теста в миллисекундах на общее число шагов.
Данные в столбце V позволяют оценить влияние задержек, вносимых виртуальной машиной. При интенсивном выводе данных, автоматное моделирование последовательных вычислительных процессов замедляет процесс вычислений примерно на 3-4% для одного процесса и менее чем втрое при наличии почти двух тысяч параллельных процессов. Действительно, время работы гораздо сильнее зависит от режима работы приложения (в одном из тестов размер сформированного текстового доходит до 36 Мбайт), чем от количества параллельных процессов.
Из сравнения столбцов V и VI следует довольно любопытный вывод: запись в файл на диск и отображение этой же информации в окне приложения занимает примерно одинаковое время. Влияние вывода во всех его проявлениях на эффективность работы приложения существенно. Тот же программный цикл, но без вывода данных, займет ничтожно малое время (строка Qsort, столбец III).
Выводы
Существующие аппаратные параллельные архитектуры (кластеры, матричные, векторные процессоры и т.п.) специализированы, а потому имеют достаточно узкую область применения и в общем случае низкую эффективность. На примере сортировок мы рассмотрели универсальную параллельную модель — СМКА, в которой отдельный процесс — это автомат, а все автоматы — система взаимосвязанных автоматов, работающих в абстрактном едином времени. Эффективность данной модели по отношению к другим лучше всего оценить, решая конкретные примеры. Сортировки — почти идеальное средство для выяснения преимуществ той или иной модели, языка или технологии и для их сравнения между собой.
Результаты тестирования убеждают, что синхронные системы (например, конвейерная сортировка) эффективнее систем асинхронного типа (Ф-сортировка). Можно пойти даже дальше, предположив, что нет синхронного и асинхронного программирования, а есть просто параллельное программирование, базирующееся на той или иной модели вычислений, но использующее разные типы протоколов — синхронные и асинхронные.
Параллельная сортировка может быть быстрее быстрой, но пока лишь в определенных ситуациях. Оговорку «может быть» и по поводу «ситуаций» мы можем исключить полностью, реализовав виртуальную машину аппаратно. На первом этапе можно даже ограничиться реализацией не в полном объеме: выигрыш можно получить, используя даже более простой последовательный автоматный вариант.
Сделанные выводы относятся к решению более глобальных проблем, чем тема сортировки. Они связанны с созданием и реализацией универсальной параллельной модели и программной технологии на ее базе. Сортировки — лишь пример ее приложения. Пример, как можно судить по результатам тестирования, положительный.
Литература
- Вирт Н. Алгоритмы и структуры данных: Пер с англ. — М.: Мир, 1989.
- Шилдт Г. Теория и практика С++: пер. с англ. - СПб.: BHV — Санкт-Петербург, 1999.
- Баранов С.И. Синтез микропрограммных автоматов. — Л.: Энергия, 1979.
- Глушков В.М. Введение в кибернетику. — К.: Изд-во АН Украинской ССР. 1964.
- Сравнение алгоритмов сортировки. http://mastergl.narod.ru/sort.html
- Любченко В.С. Обедающие философы Дейкстры (о модели параллельных процессов) http://www.softcraft.ru/auto/ka/fil/fil.shtml
- Хоар Ч. Взаимодействующие последовательные процессы: Пер. с англ. — М.: Мир, 1989.
- Любченко В.С. От машины Тьюринга к машине Мили. «Мир ПК», 2002, № 8.
Вячеслав Любченко (sllubch@mail.ru), программист АКБ «Алекскомбанк» (г. Александров).
