


Компьютерный мир проходит мучительный процесс эволюционного перехода от вычислительных систем в их, если так можно сказать, «чистом виде» через системы обработки данных и далее к системам управления информацией. Мучительность этого процесса состоит в том, что на каждом из его этапов усложняются не только средства, но и предмет обработки — причем и предмет, и средства управления информацией далеки от полноценного определения.
Когда появились первые компьютеры, они использовались непосредственно, отвечая своему названию — как средство автоматизации расчетов. Вплоть до 70-х годов применение компьютеров ограничивалось решением математических задач, поэтому достаточно было представлять данные в виде массивов чисел, что не представляло особого труда. Затем необходимость оперирования данными с более сложной структурой привела к появлению систем управления базами данных; этот этап начался в 70-е годы и протянулся до современности. На первых двух этапах участие человека ограничивалось подготовкой данных и анализом конечных результатов.
Особенности третьего этапа связаны, прежде всего, с проявлением фундаментальных отличий двух «соседствующих» понятий — данных, являющихся продуктом, потребляемым машиной, и информации, продуктом, который потребляет человек (об отличии данных от информации см. также статью «Неожиданная информатика»). Эти различия пока еще не вполне осознаны, поэтому и появляются на свет отдельные, чаще паллиативные решения, которые в каком-то смысле выходят за рамки традиционных систем обработки данных, но пока не стали в полном смысле этого слова информационными системами. К этой категории решений относятся и те, что стали обозначать выражением «управление жизненным циклом информации».
Управление жизненным циклом информации (Information Lifecycle Management, ILM) вошло в число наиболее «раскручиваемых» направлений в области систем хранения данных 2003 года. По сложившейся традиции (вспомним историю становления Web-сервисов) раскрутка начинается с того, что усилиями отраслевых аналитиков и соответствующих производителей формируется культовое отношение к продвигаемым технологиям. Как обычно, те, кто выступают в роли наиболее активных промоутеров технологий, не слишком компетентны в озвучиваемом ими предмете. Сущность ILM так же плохо понята ими сегодня, как сущность Web-сервисов пару лет назад. Появление концепции ILM в ее нынешнем виде, как мне представляется, есть ни что иное, как ответ индустрии на запросы пользователей. И если этот ответ назвали ILM, то придется принять это имя.
Временем рождения ILM стали первые годы нового тысячелетия, годы, когда возникла необходимость создавать крупные и распределенные хранилища данных, а вместе с ними пришло осознание того, насколько несовершенны существующие методы. К тому же, данные в электронной форме стали обязательным компонентом экономической и общественной жизни. Cоциум оказался в зависимости от надежности хранения электронных данных. И, естественно, в ряде развитых стран начали появляться законодательные нормы, регулирующие работу с данными; они стали еще одним стимулом к появлению ILM. Наибольшую известность приобрел акт Sarbanes-Oxley Act, устанавливающий требования к прозрачности деловой информации (его появление было стимулировано полосой разоблачений мошенничества в крупных корпорациях). Из медицины пришел Health Insurance Portability and Accountability Act — документ, определяющий нормативы работы с персональными данными. Известны также такие документы, как Gramm-Leach-Bliley Act и Patriot Act.
ILM — еще одна оболочка
Если попытаться перевести происходящее на простой язык технологий, то за разнообразными, зачастую противоречащими друг другу конкурентными представлениями ILM просматриваются признаки процесса, присущего компьютерной отрасли на протяжении всей ее истории, — выстраивание оболочек, называемое «капустным принципом». Когда-то был голый компьютер, потом появились языки программирования, потом операционные системы и т.д. В программировании давно прошел процесс перехода от непосредственного использования машинных кодов к языкам программирования высокого уровня, а вот в системах хранения данных аналогичная, неизбежная, процедура затянулась на десятилетия. Если уподобить блоки данных на дисках словам в оперативной памяти, то использование файловых систем есть ни что иное, как аналог Ассемблера. Физические адреса данных заменяются логическими, и появляется возможность использования символических имен; между физическими и логическими адресами устанавливается соответствие посредством тех или иных таблиц. До тех пор, пока монопольное положение занимали решения категории DAS (direct attached storage), т. е. системы хранения, непосредственно подключаемые к компьютеру, а для управления файлами хватало ресурсов операционной системы, ситуация казалась удовлетворительной.
Одной из первых поворот в изменении видения проблемы хранения данных продемонстрировала корпорация EMC, приобретшая за последнее время компании Data General, Legato Systems, Documentum и VMware. Поначалу политика приобретения софтверных компаний производителем систем хранения данных выглядела довольно странной. Но когда EMC превратила Information Lifecycle Management в основной девиз своего дальнейшего развития, ее замысел стал более или менее ясным. Вслед за EMC в близких направлениях активно двинулись Hewlett-Packard, IBM, Veritas Software, Sun Microsystems и, возможно, кто-то еще. Каждая из этих компаний по-своему интерпретирует ILM, некоторые даже используют собственную версию названия. IBM стремится реализовать свой опыт в области управления иерархическим хранением данных (hierarchical storage management, HSM), HP опирается на собственный ресурс в виде инструментария управления OpenView, Sun Microsystems хочет реализовать потенциал «супероперационной» системы N1, и т.д.
HSM — это техническая организационная схема хранения данных, а ILM — система оперирования данными в рамках всего предприятия. Соответственно и лица, ответственные за HSM и ILM, находятся на разных уровнях административной иерархии. В первом случае это технические специалисты, а во втором — директора информационных служб, которые отвечают за данные как за один из ключевых ресурсов предприятия.
В обязанности ИТ-службы, организующей ILM, входит:
- ранжирование данных по мере их устаревания с течением времени, с условием обеспечения доступа к ним и сохранности до тех пор, пока данные остаются актуальными;
- выработка стратегии при создании систем хранения и обеспечение ее реализации;
- отслеживание процессов преобразования и перемещения данных от момента создания и до удаления;
- сохранение наиболее актуальных данных на наиболее быстрых, из имеющихся устройств хранения, и перемещение их по мере старения на более экономичные устройства;
- обеспечение оптимального времени доступа к данным в соответствии с этапом их жизненного цикла;
- архивирование вышедших из употребления данных на автономных устройствах или их уничтожение.
Количественные предпосылки ILM
Для того чтобы оценить значение концепции ILM, желательно хотя бы умозрительно представить себе, что представляют собой объемы данных, которыми приходится оперировать сегодня, и как они соотносятся с объемами данных, с которыми приходилось работать прежде. Обратимся к одному из наиболее интересных исследований, связанных с измерением количественных показателей накапливаемых данных и распределением этих данных по различным средствам хранения, которое регулярно проводится сотрудниками университета Беркли.
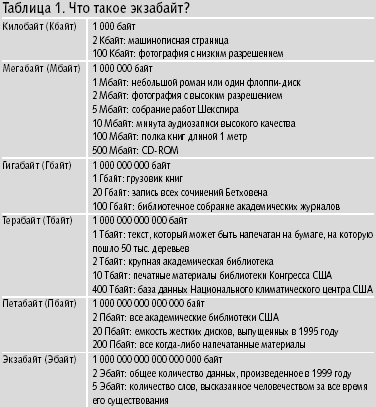
О темпах прироста объема хранимых данных лучше всего свидетельствуют две цифры: в 1999 году в мире всего было произведено от 2 до 3 экзабайт данных, а в 2002 — от 3 до 5 экзабайт. Из таблицы 1 следует, что количество накапливаемых всего за один год данных примерно равно объему всей устной речи, когда-либо произнесенной за всю историю человечества. При этом более 90% (таблица 2 ) этих данных хранится на магнитных носителях и почти 50% — на компьютерных лентах или дисках (таблица 3). Иными словами, совокупные объемы данных, которыми приходится управлять, уже измеряются петабайтами и экзабайтами. Лучшего доказательства для актуальности ILM придумать сложно.
Качественные предпосылки ILM
Среди источников, которые чаще всего цитируют, доказывая необходимость организации ILM, лидирует статья Фреда Мура, президента аналитической компании Horison Information Strategies (Fred Moore, Information Lifecycle Management, www.horison.com/horison/industry_topics/ Lifetime_Data_Management.doc). В качестве несомненного достоинства этой работы следует отметить, что несмотря на ее название в ней с первых же слов речь идет о жизненном цикле не ИНФОРМАЦИИ, а ДАННЫХ. В своей статье Мур попытался разобраться с тем, что происходит с данными в рамках их жизненного цикла, как происходит процесс их старения, а главное, если, как утверждают все аналитики и производители, данные приобретают такое огромное значение для бизнеса, то почему мы так мало о них знаем.
Хронологически первыми были работы в области HSM. Они начались примерно пятнадцать лет назад в связи с приложениями, работающими на мэйнфреймах, а сейчас становятся популярными в системах, работающих под управлением Unix и Windows NT. Анализ использования данных и стремление их каким-то образом ранжировать позволил выявить закономерность старения данных (рис. 1).
То обстоятельство, что данные стремительно стареют (например, как следует из графика на рис. 1, по истечению месяца вероятность повторного использования данных снижается до единиц процентов), способствовало формированию в середине 90-х годов так называемой концепции Nearline, авторы которой рассматривали технологию работы с данными чрезвычайно примитивно. Они полагали, что по окончании видимого жизненного цикла данные следует архивировать, а затем еще несколько лет подержать в архивированной форме, после чего — просто уничтожать. Эта концепция попросту наивна, поскольку определенные данные могут быть востребованы через многие десятки лет, о чем свидетельствует действующая система бумажных архивов, вопрос в том, о каких данных идет речь.
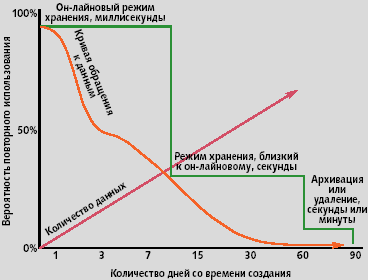 |
| Рис. 1. Вероятность повторного использования данных в зависимости от времени жизни |
Данные критически важные для контроля за деятельностью в бизнесе и здравоохранении необходимо хранить в течение ста лет. При всем том, что вероятность их повторного использования чрезвычайно низка, в определенных критических ситуациях они могут быть востребованы. (Как тут не вспомнить старика-архивариуса Коробейникова из «Двенадцати стульев», который составлял реестр реквизированной мебели, ведь пригодился же он Остапу Бендеру.)
По мере замены бумажных документов электронными этот процесс будет развиваться. В изменившихся условиях новая политика в отношении данных должна основываться не на том, как и когда они могут быть повторно использованы, а на юридической и экономической значимости данных. Теперь девиз отношения к данным оказался переформулирован следующим образом: «Не важно, будут ли данные когда-либо использованы, важно, чтобы они были сохранены». Изменение — на порядки — сроков хранения данных соответствующим образом меняет управление жизненным циклом данных, очевидно, они должны по мере старения мигрировать с устройств, обеспечивающих быстрый доступ, на устройства, обеспечивающие низкую удельную стоимость хранения (рис. 2), но не могут быть потеряны или уничтожены. Подобная задача уже возникала много лет назад, когда потребовалось создать архивы данных, полученных в результате геофизических исследований. По перечисленным причинам возникает необходимость в программных средствах и системах управления ресурсами хранения данных (storage resource management, SRM). Они в совокупности с технологиями HSM образуют техническую основу управления жизненным циклом данных.
Будущее — в конвергенции
То, что открылось техническим специалистам в области систем хранения как откровение, таковым вовсе не является. Управление информацией, а точнее, управление неструктурированными данными как область человеческой деятельности существует многие десятки лет. Эта область не занимает особенно заметного места в бизнесе, в основном ею заняты небольшие компании и университетские исследователи, но все же сегодня она представлена несколькими общественными ассоциациями.
Одна из старейших была организована в 1943 году как Американская национальная ассоциация микрофильмирования. Позже она была преобразована в Ассоциацию по управлению информацией и изображениями (Association for Information and Image Management, AIIM). В настоящее время AIIM полностью сосредоточила свои усилия на управлении контентом предприятия (Enterprise Content Management, ECM). Логику перехода от технологии микрофильмирования к управлению контентом вполне можно представить как перспективу развития ILM в будущем. Точно так же, как микрофильмирование, новое направление начинается как сугубо технологическое, но оно с неизбежностью должно прийти к управлению контентом. По всей видимости, произойдет некий процесс конвергенции, специалисты по управлению информацией обогатят данную область своими гуманитарными наработками, а компьютерные специалисты — техническими. С позиций ECM управление информацией интегрирует ряд технологий, которые существуют независимо друг от друга, в том числе, управление документооборотом и управление бизнес-процессами, портальные технологии, управление знаниями, обработка изображений, создание хранилищ данных, добыча данных и др.
Другая известная организация ARMA International до последнего времени в основном связывала свою деятельность с управлением записанной информацией (recorded information management, RIM), а в более широком контексте — со стратегическим управлением информацией (strategic information management, SIM). Обширный список американских организаций, деятельность которых так или иначе относится в ILM, можно найти на сайте http://callitt.leavenworth.army.mil/links/ilmrellinx.htm. Небезынтересно отметить военную принадлежность этого источника; вообще же к управлению неструктурированными данными особое внимание проявляют различные государственные организации, а также специальные и силовые службы. В отечественных условиях им пока достаточно «изъять сервер», но что делать с развитыми распределенными системами хранения данных? Сегодня на всех перечисленных в этом разделе Web-сайтах отмечается необычайная активность, она связана с тем, что буквально на глазах стала очевидной взаимосвязанность всех этих ILM, RIM, SIM, ECM и т.п., равно как и критическая важность конвергенции. Весьма приблизительно различное отношение к данным, свойственное разным направлениям, представлено в таблице 4.
EMC и Documentum — конкретный пример конвергенции
Водораздел между компьютерными методами работы с данными и более традиционными методами информационной работы до последнего времени проходил, главным образом, по линии между структурированными и неструктурированными данными. Для человека столь же естественно работать с неструктурированными данными, как для компьютера — со структурированными. Однако положение меняется, и уже сейчас более 80% хранимых данных являются неструктурированными; в дальнейшем их доля постоянно будет только возрастать.
Пока в этом рыночном сегменте действует не так много участников, да и вообще управление неструктурированными данными информацией, находится в зародышевом состоянии. Работой с неструктурированными данными занимаются такие относительно небольшие компании, как Interwoven, Open Text, Ventana Research, FileNet. В близкую область — управление контентом предприятия — вовлечен целый ряд компаний, в том числе Autonomy, Convera, Inxight, Stratity и Verity. Особое место среди них занимала компания Documentum, которая до приобретения ее корпорацией EMC, в течение ряда лет была известна как поставщик решений для управления документами. Но несколько лет назад специалисты компании осознали степень проникновения неструктурированных данных в корпоративную среду, и Documentum стала стремительно изменять свой профиль, превращаясь в поставщика инфраструктуры для неструктурированных данных. Компания стала создавать платформу, ориентированную на данные; платформа должна была бы стать концентратором для неструктурированных корпоративных данных. Именно в этот переходной момент Documentum была куплена EMC. Совершив это приобретение, EMC, занимавшаяся прежде исключительно системами хранения, со всей очевидностью заявила, что хочет занять нишу поставщика платформ для неструктурированных данных. Технически на первых порах решение, которое с полным правом можно отнести к категории ILM, будет основываться на комбинации продуктов семейства Centera, относящихся к числу систем хранения данных, адресуемых контентом (content-addressed storage, CAS), и репозитория Documentum 5 ECM.
