


Сама идея Information Lifecycle Management (ILM), как это нередко бывает в ИТ, не нова. И ранее предпринимались попытки систематизировать знания и технологии, имеющие отношение к управлению информацией от момента ее создания до утилизации. Однако сегодня лавинообразный рост объемов данных, удешевление стоимости носителей и прогресс технологий, заставили по-новому осмыслить проблему управления информацией. Действительно, по данным Gartner, к 2005 году число ежедневно отправляемых почтовых сообщений составит 36 млрд., что втрое больше, чем было в 2001 году. Согласно оценкам журнала Storage Magazine, 3 тыс. работников уже сегодня в среднем ежедневно отправляют по электронной почте терабайт данных. В ряде отраслей наблюдается экспоненциальный рост объемов генерируемых документов. Скажем, системы класса Picture Archive and Communications System большого госпиталя способны ежегодно формировать более 5 Тбайт мультимедийных данных. Аналогичный всплеск имеется и в науке, финансах, страховании и других отраслях. Средний прирост объемов ежегодно накапливаемой информации составляет 45-60% — и это при том, что согласно отчету Enterprise Storage Group (ESG), широко используется ссылочная информация, позволяющая уменьшить дублирование. По данным той же ESG, объемы неструктурированных данных растут даже быстрее структурированных, и к концу 2004 года неструктурированные данные будут составлять 51% всей вновь созданной за год информации, объем которой согласно отдельным модельным оценкам составляет до 5 экзабайт.
А надо ли хранить всю производимую информацию? Если нет, то какую, где и как долго? Как обеспечить наиболее удобный и оптимальный доступ к ней? Следует учесть, что кроме общекорпоративных правил, определяющих сроки хранения той или иной информации, имеются международные и национальные законы, а также и нормативные акты. Все они, не считая еще множества отраслевых актов, например, требований к документации по объектам ядерной энергетики или результатам испытаний медицинских препаратов, достаточно четко регламентируют сроки хранения информации. При этом сами данные также со временем изменяются. Это хорошо видно на примере банковской транзакции, когда для создания наиболее важного для финансового учреждения документа, баланса, сначала собираются все специфические транзакции, живущие только до момента их анализа или распечатки, потом формируются консолидированные отчетности и итоговый баланс, а данные по локальным операциям через месяц прекращают свое существование. Таких примеров множество, но ясно, что для учета нормативов хранения и процесса устаревания информации требуются специальные технологии, позволяющие отслеживать периоды жизни данных и обеспечивающие адекватные способы доступа к ним.
Но и это еще не все. Бизнес ищет пути уменьшения стоимости операций: глобализация, трудности экономик ряда стран и регионов, неизбежный рост стоимости трудовых ресурсов вынуждают больше думать о реорганизации существующих методов работы, чем о закупках новейших решений. Однако сегодня управление жизненным циклом информации реализуется преимущественно вручную буквально на каждом из его этапов: выделение соответствующей системы хранения, репликация, резервирование, архивирование и удаление данных, используются отдельные приложения, практически никак не интегрированные друг с другом (рис. 1). Также в основном вручную инициируются процессы резервирования и восстановления данных, например, администратор корпоративной инфраструктуры хранения должен создать скрипты для запуска приложений резервирования по определенному расписанию, а затем в некоторый момент отправить магнитные ленты с резервированными данными в удаленный архив или запустить процесс репликации на удаленную систему хранения. В таких условиях сложно говорить о гарантированном уровне качества обслуживания. Кроме того, подобный подход практически не учитывает особенности использования информации различными приложениями.
 |
| Рис. 1. Жизненный цикл информации |
Ожидается, что интегральный подход к обработке информации позволит уменьшить стоимость владения и увеличить производительность выполнения процессов обработки документов, причем при гарантированном соблюдении соглашений об уровне обслуживания (service level agreement, SLA). Понимание ILM до сих пор не устоялось, однако ясно, что за этим термином скрывается не столько расширенная система документооборота, не продукт, а комбинация процессов и решений, имеющая целью предоставить информацию в нужном месте в нужное время и по оптимальной цене. Это достигается за счет непрерывной оптимизации всех процессов обработки информации на протяжении всего ее жизненного цикла с учетом политик, определяемых пожеланиями бизнеса, соглашений об уровне обслуживания и требований к снижению стоимости владения. Так, только за счет учета фактора цена/производительность для разных уровней иерархии размещения информации можно существенно сократить издержки. Действительно, по данным EMC, стоимость хранения на верхнем уровне конфигураций SAN/NAS составляет 5 центов за мегабайт, на среднем, допускающем доступ к информации в реальном времени, диске — 1 цент, а стоимость архивных данных на ленточных библиотеках составляет менее 0,1 цента.
Концепция ILM
Итак, ILM охватывает все процессы управления размещением, хранением, распределением, миграцией, архивированием и удалением данных в инфраструктуре предприятия. ILM реализует сервисы по обработке данных в рамках общего сервис-ориентированного подхода к предоставлению ресурсов. С каждым элементом корпоративных данных на каждом этапе их жизненного цикла соотносятся определенные параметры качества обслуживания: производительность носителя, доступность, уровень защиты, скорость восстановления, стоимость хранения и т.д. ILM-решения позволяют формировать корпоративные политики по заданию уровня обслуживания для данных различных приложений и управлять этими данными в соответствии с заданными политиками на протяжении всего их жизненного цикла. Ключевая задача ILM — на каждом этапе жизни информации гарантировать размещение данных на тех носителях, характеристики которых удовлетворяют заданным параметрам QoS (quality of service — «качество обслуживания»). Тем самым ILM способствует оптимальному распределению ресурсов хранения между приложениями. Для решения этой задачи ILM-среда должна включать средства классификации корпоративной информации по степени ее значимости для бизнес-процессов компании и инструменты управления размещением данных на устройствах хранения в соответствии с этой классификацией. Например, ILM разместит данные от критичных бизнес-приложений ILM на высокопроизводительном дисковом массиве с возможностью зеркалирования томов.
Функции ILM не ограничиваются только управлением хранением данных на определенных носителях. Требуется еще решать задачи интеллектуального управления потоками работ и бизнес-процессами, которые задействуют на эти данные. ILM управляет информацией на основе изменяющихся с течением времени критериев ее значимости для бизнес-процессов и потребностей приложений. Жизненный цикл данных начинается с момента их создания в различных системах, таких как электронная почта, ERP, СУБД, финансовые приложения, системы обработки изображений и др. Затем под управлением ILM реализуются процессы доступа, распределения, сохранения и ликвидации данных. ILM позволяет задавать политики для такого управления, в которых специфицируются параметры качества сервиса данных: доступность, защищенность, скорость восстановления, производительность, местонахождение носителя и стоимость хранения.
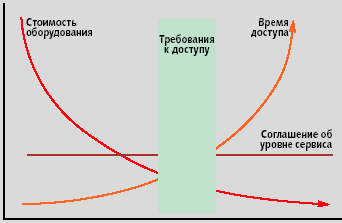 |
| Рис. 2. Пример параметрической оптимизации размещения объектов хранения |
Для того чтобы реализовать перечисленные задачи, ILM следует базировать на инфраструктуре хранения, включающей устройства разных классов, использовать программный инструментарий управления хранением и увязывать между собой задачи управления инфраструктурой хранения и потребности бизнес-приложений по размещению, использованию, хранению и миграции данных. Требуется отслеживать время нахождения конкретного информационного объекта на определенном уровне, частоту его использования, объем, возраст, легальность доступа и т.п., одновременно соизмеряя полученные данные с требуемыми параметрами стоимости, целесообразности хранения на том или ином уровне и адекватности SLA. Процессы миграции (рис. 2) инициируются после анализа текущего состояния информационного объекта, либо по событию извне, например, в соответствии с политиками, задающими пороговые значения параметров.
Политики
Содержание политик определяют внешние критерии, формируемые бизнесом: необходимый объем информации, требуемый для принятия бизнес-решения; состав SLA; разграничение прав доступа и т.п. Первый критерий определяется бизнес-логикой и часто не поддается формализации, а получается, например, на основе рекомендаций консультантов. Как только определен объем информации, определяются требования по ее защите. Показатель RPO (Recovery Point Objectives) специфицирует критическую массу информации, которая может быть утеряна при фатальных событиях без нарушения бизнеса (как много транзакций может быть потеряно). В некоторых случаях (для банков) это значение равно нулю, но для промышленности потери нескольких транзакций могут быть не столь критичны. Показатель RTO (Recovery Time Objectives) определяет время простоя системы от момента возникновения нарушения до восстановления работоспособности. Обычно это время, необходимое для перезагрузки и отката на предыдущее состояние. Ясно, что когда речь идет о нескольких терабайтах данных, то на их восстановление могут уйти часы и даже дни. Применительно к ILM соглашения об уровне обслуживания могут означать, например, гарантированное время доступа к информационному объекту. Допустим, время доступа к данным, созданным сегодня и вчера должно составлять n секунд, а позавчера, вплоть до недельной давности — m секунд, что, в конечном итоге, влияет на выбор конкретной технологии хранения.
Права доступа зависят от требований к управлению и целостности данных. Например, требуется обеспечить доступ только внутри компании, или необходимо обеспечить возможность обращения к документации со стороны внешних партнеров. При каждой миграции данных с одного уровня на другой средства ILM должны согласовывать свои действия с этими требованиями, например, сохранив возможность доступа к редко используемому в последнее время документу из офиса, после его перемещения в архив.
Структуризация информационных объектов
Согласно практике работы с информацией, в ILM выделяют три уровня организации информационных объектов.
Том. Это базовый уровень, своего рода контейнер с данными, над которым система хранения осуществляет те или иные операции. Том имеет свой идентификатор — LUN (Logical Unit Number), позволяющий параллельно обрабатывать данные независимо от их физического размещения, создавать копии, хранить информацию о виртуальных носителях, осуществлять мониторинг текущего состояния информационного объекта и т.п. С точки зрения приложения любые перемещения LUN с одного носителя на другой должны быть прозрачны — логический адрес объекта остается неизменным.
Файловая система. Информационными объектами файловой системы или базы данных являются файлы, каталоги, узлы, таблицы, метаданные. Как и для базового уровня, объекты файловой системы с точки зрения приложений должны быть нейтральны к конкретной физической реализации. Для этого служит пул метаинформации, позволяющей виртуализировать файловую систему, однако сегодня еще невозможно прямое обращение к классам хранения (логическая структуризация) и осуществляется непрямая табличная адресация. Поэтому, в частности, атрибуты процессов в ILM вычисляются через таблицу указателей.
Приложения. Реальные проблемы в ILM кроются не в процессах создания или размещения данных на хранение, а при обеспечении приложениям доступа к информационным объектам с соблюдением нормативов по срокам хранения, SLA, целостности и безопасности. К примеру, сообщения электронной почты могут содержать конфиденциальную информацию о начислении налогов, которые согласно определенным нормам должны иметь как свой конкретный срок хранения, так и степень защищенности. Приложения, отвечающие за архивирование и удаление данных должны учитывать эти моменты.
Все три уровня информационной структуры могут жить только вместе, что требует специального сервиса по интеграции. Скажем, физическая файловая система связана с виртуальными томами, задействованными в LUN — любое расширение файловой системы влечет за собой череду логических шагов по изменению метаданных. Другой пример — электронная почта. Конкретное послание может быть удалено с почтового сервера, однако если согласно политикам срок действия соответствующей информации еще не закончился, система архивирования сохранит это сообщение в своей базе — данный процесс выполняется на уровне приложений, но сама база перемещается на более медленный физический носитель — уровень файловой системы.
Технологии и архитектуры
С точки зрения концепции, неважно, на какой конкретно ИТ-конфигурации построено ILM-решение — главное, чтобы обеспечивалось консолидированное взаимодействие всех территориально-распределенных компонентов. Сетевые системы хранения существенно упрощают выбор архитектуры ILM, каждому серверу предоставляется доступ к нужному ему хранилищу.
После определения технологии доступа к данным, технические параметры для ILM начинают играть вспомогательную роль, что достигается за счет технологии виртуализации. С точки зрения ILM не имеет значения, на оборудовании какого производителя будут храниться данные: важны лишь параметры стоимости и быстродействия. То же можно сказать про сети и серверы — выбор в каждом случае осуществляется автоматически путем поиска решения удовлетворения требований политик на основе описаний характеристик оборудования и программного обеспечения. Например, система хранения от производителя A имеет более высокие показатели производительности, однако продукт от производителя B дешевле, но, решение от производителя С имеет более расширенную функциональность, позволяющую полнее решать задачи архивирования.
Обращение к территориально-распределенному хранению является одним из необходимых атрибутов ILM, особенно в свете обеспечения надежности. Как правило, различают три уровня «распределенности»: кампус (характерная удаленность — до 10 км); город (100 км); регион. В первом случае применяются технологии Fibre Channel, ESCON и FICON. В других речь идет об IP, ATM или DWDM.
Центральное хранилище, снабженное кроссплатформными средствами администрирования категории SRM (storage resource management), содержит характеристики системы хранения, параметры физических дисков, логических томов, файловых систем, контейнеры баз данных и т.п. Для размещения конкретных типов данных могут потребоваться разные типы систем хранения; задача SRM состоит в анализе и принятии решения о способе и месте хранения данных. Задача не сводится только к определению по типу файла места и способа их размещения — требуется еще анализ, например, по их принадлежности определенному департаменту. Например, отделу маркетинга требуются большие мультимедиа файлы, надежность хранения которых в общем случае может быть невысокой, а финансовый департамент оперирует относительно компактными текстовыми таблицами, от сохранности которых может зависеть судьба бизнеса.
ILM глазами HP
В контексте продвигаемой компанией Hewlett-Packard концепции адаптивного предприятия, реализация ILM осуществляется средствами интегрированного управления ресурсами хранения, которые сосредоточены в модулях НР OpenView, и прежде всего в OV Storage Area Manager. Эти средства выступают в качестве «панели управления» сетевой инфраструктурой хранения и выполняют такие задачи, как обнаружение устройств и определение топологии сети хранения, мониторинг и управление событиями, генерацию отчетов по уровню загрузки ресурсов хранения. Информационные хранилища ILM строятся на базе сетевых устройств хранения, а также программных компонентов для управления этими устройствами. Эти компоненты архитектуры НР ILM (сеть хранения и интегрированное управление ресурсами хранения), а также функции перемещения и защиты данных являются ключевыми элементами стратегической архитектуры HP ENSAextended. ILM дополняет возможности инфраструктуры хранения ENSAextended средствами управления информацией на разных этапах жизненного цикла.
Хранилища
НР ILM базируется на хранилищах информации двух типов: оперативной и справочной, причем понятие хранилище включает в себя как аппаратные, так и программные компоненты. Хранилище оперативной информации предназначено для данных, создаваемых и постоянно используемых приложениями. Как видно на рис. 3, между приложениями и оперативными данными в архитектуре НР ILM нет промежуточных звеньев.
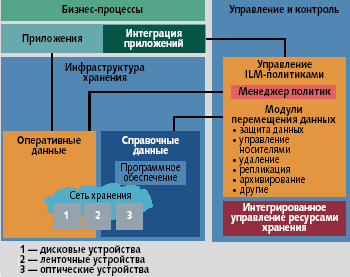 |
| Рис. 3.Архитектура НР ILM |
Со временем оперативная информация стабилизируется, обращения к ней и внесение изменений происходят все реже и в определенный момент вообще прекращаются. Такая информация, согласно концепции НР, классифицируется как справочная, используемая в задачах добычи данных, для соблюдения государственных нормативов по хранению определенных типов документов и т.д. В соответствии с заданными политиками, ILM перемещает данные, классифицированные как справочные, на более подходящие носители. На этом этапе могут решаться проблемы архивирования и присвоения данным атрибутов для последующего поиска и выборки. В задачу ILM входит не только перемещение данных из одного хранилища в другое, но и перераспределение информации между различными системами хранения в рамках одного хранилища, так чтобы хранение информации удовлетворяло требованиям бизнес-приложений, сформулированных в терминах SLA: уровень защиты, скорость восстановления, производительность устройства, тип сетевого соединения и т.д.
Для описания хранилищ информации в архитектуре ILM на физическом уровне вводится понятие SmartCell — модульная «ячейка» хранения в архитектуре НР ILM, объединяющая сетевые системы хранения и, в совокупности с другими такими ячейками, обеспечивающая необходимые параметры доступности, производительности, стоимости и т.д. SmartCell может включать дисковое, магнитное или оптическое устройство хранения и процессорную мощность для реализации функций индексирования, поиска и выборки данных. Поддержка этих функций позволит различным бизнес-приложениям осуществлять доступ к данным путем запросов к приложению индексирования/выборки. Иными словами, для получения информации не потребуется обращаться к приложению, с помощью которого данные создавались и помещались на хранение. В результате, доступ к данным сможет получить любое, соответствующим образом авторизованное приложение. К примеру, даже спустя годы финансовые записи, созданные уже несуществующим в данный момент приложением, сможет использовать новая система финансового анализа.
Хранилище динамической (оперативной) информации содержит активно используемые данные, причем, как правило, критичными для бизнеса приложениями, поэтому для их хранения в ILM-политиках определяются классы устройств с наиболее высоким уровнем производительности и доступности. В арсенале НР этим характеристикам удовлетворяют дисковые массивы семейств StorageWorks XP, StorageWorks Enterprise Virtual Array и StorageWorks Modular SAN Array. Кроме того, для обеспечения необходимого уровня качества обслуживания хранилище оперативной информации использует адекватные технологии восстановления данных.
Система хранения справочной информации может иметь достаточно сложную структуру, включая различные типы подсистем хранения и программный инструментарий управления. Поскольку это хранилище предназначено для очень больших и постоянно растущих объемов информации и рассчитано на многолетнее использование, оно должно быть хорошо масштабируемым и высоконадежным. Система хранения справочной информации включает в себя два основных компонента: единицы физического хранения SmаrtCell и программное обеспечение. SmartCell может строиться на базе различных типов устройств, в том числе дисковых массивов, ленточных устройств, систем хранения с условно-однократной записью (WORM) и оптических устройств. НР предлагает для обеспечения защиты и архивирования данных серии ленточных устройств, а также оптические системы и планирует расширять свои модельные ряды в этой области. В перспективе к списку устройств для реализации хранилищ справочной информации будут добавлены дисковые системы на базе Serial ATA и массивы, поддерживающие соединения iSCSI. Поскольку предполагается, что каждая ячейка SmartCell имеет собственные возможности индексированного поиска, на множестве таких ячеек поиск информации можно будет выполнять параллельно. В HP утверждают, что такой подход к построению единого репозитория справочной информации предприятия более эффективен и обеспечивает большую масштабируемость, чем централизация всех этих функций во внешней базе данных. Объединение отдельных модулей в единую систему хранения справочной информации реализуется на уровне программного обеспечения.
Интеграция приложений
В архитектуре НР ILM компоненты интеграции приложений отвечают за связь между функциями управления размещением, хранением и миграцией данных и прикладными решениями. В частности, в их задачу входит приостановка работы приложений при репликации информации или извлечения объектов данных, которые нужно архивировать. Именно интеграционные компоненты обеспечат прозрачность ILM-решений для приложений и их пользователей. Благодаря им достигается основная цель ILM — данные ассоциируются с нужным приложением, в нужное время и с параметрами хранения, определенными в политиках.
Интеграцию приложений с функциями уровня управления политиками в архитектуре НР ILM можно реализовать на базе API, специфических для определенного типа оборудования, или с помощью отраслевого стандарта SNIA SMI-S. В архитектуре HP ENSAExtended поддерживаются оба варианта, однако в НР целенаправленно ведется работа по продвижению стандарта интеграции разнородных сетевых устройств хранения и систем управления хранением SMI-S. Кроме того, ставка делается на взаимодействие приложений друг с другом на уровне Web-служб, которые, в частности, станут основой концепции архитектуры информационной среды адаптивного предприятия HP Darwin Reference Architecture. Предполагается, что со временем возможности Web-служб найдут свое применение и в интеграции компонентов ILM и бизнес-приложений.
Управление политиками
Управление политиками в архитектуре НР ILM возлагается на программный компонент Policy Manager и модули перемещения данных (Data Movement plug-in). Реализация отдельного программного модуля для автоматизации управления политиками стоит в планах НР на ближайшие год-два, а пока функциональность менеджера политик поддерживается в системе OV Storage Builder, входящей в интегрированный пакет приложений для управления сетями хранения OV Storage Area Manager. Управление политиками базируется на централизованном представлении информации о пользователях ресурсов хранения и степени загрузки дискового пространства для различных хост-систем, устройств хранения, логических устройств, томов, каталогов и отдельных пользователей. Кроме того, в системе есть средства анализа истории работы с информацией, оценки тенденций использования ресурсов и прогнозирования будущих потребностей на их основе, позволяющих своевременно принимать решение о модернизациях. Ведется также реестр файлов и каталогов, к которым в течение длительного времени не было обращений и которые потенциально могут составлять резерв оптимизации емкости хранения.
В перспективе, по замыслу НР, программный инструментарий Policy Manager станет центром общей архитектуры управления данными с возможностями единого контроля за хранилищами как оперативной, так и справочной информации. Кроме того, будет реализована центральная консоль для определения параметров качества сервиса данных и соответствующих политик. Задача Policy Manager — анализировать данные в контексте приложений: идентифицировать приложение, с которым ассоциированы данные; определять, где они хранятся; на каком этапе жизненного цикла в данный момент находятся и где, соответственно, должны размещаться. На основе этой информации менеджер политик установит правила, в соответствии с которыми модули перемещения данных автоматически будут размещать данные на устройствах хранения нужного класса в нужном информационном хранилище.
Модули перемещения данных отвечают за выполнение директив менеджера политик и выполняют копирование или перемещение данных на носитель определенный с помощью политик. Основные операции перемещения данных в архитектуре ILМ: репликация (создание избыточных копий объектов данных, в том числе, на удаленных носителях); резервирование; архивирование; удаление; миграция (перенос данных с одного устройства хранения на другое в соответствии с правилами управления иерархическим хранением). Модули перемещения реализуют запросы бизнес-приложений на выполнение операций копирования и переноса данных с носителя на носитель и позволяют определять объекты данных в терминах приложений или конечных пользователей, а не в терминах устройств хранения (например, объект данных может быть задан как почтовый ящик или сообщение электронной почты).
Система ILM должна поддерживать различные варианты перемещения данных в зависимости от правил, определенных менеджером политик (рис. 4). Один из вариантов перемещения данных — архивирование, при котором данные размещаются на долгосрочное хранение в репозитории с возможностями индексирования и выборки информации. Однако такому архивированию могут предшествовать промежуточные перемещения данных, например, репликация с целью последующего восстановления. Данные перемещаются с помощью приложения репликации из оперативного хранилища в хранилище справочной информации, откуда они в дальнейшем могут быть восстановлены. Еще один пример копирования оперативных данных в хранилище справочной информации — репликация.
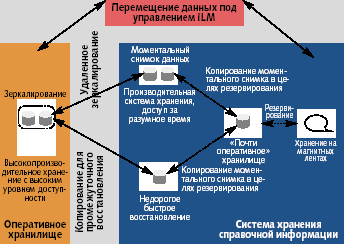 |
| Рис. 4. Перемещения данных в соответствии с политиками ILM |
Следующий вариант — репликация тома. Например, для некоторой системы обработки транзакций каждую ночь выполняется моментальный снимок базы данных, а затем эта копия остается в оперативном хранилище и продолжает использоваться. С другой стороны, такая же копия может быть сделана в рамках поддержки непрерывности работы приложений в случае сбоев, и тогда, оставаясь в оперативном хранилище, эти данные уже не будут активно использоваться.
Надо отметить, что менеджер политик может задавать перемещение данных не только между физическими устройствами хранения, но и между классами систем хранения, соответствующими разным уровням качества обслуживания, причем такие классы могут быть реализованы на одной системе хранения. Скажем, различные конфигурации RAID могут иметь разные параметры QoS, но на одном дисковом массиве могут одновременно существовать несколько таких конфигураций.
Все операции по перемещению данных в ILМ-системе реализованы в системе управления резервным копированием НР OpenView Data Protector, а также в программных модулях управления дисковыми системами хранения семейства StorageWorks. На ближайшую перспективу НР планирует совершенствование функций архивирования и управления дисковыми копиями в модулях перемещения данных, что должно заложить основу для реализации развитых возможностей резервирования на дисковые устройства хранения. Этому будет способствовать и недавнее приобретение компании Persist Technologies, разработчика программных решений по управлению архивированием.
Стратегия HP ILM
В ближайшие годы НР планирует реализовать все необходимые компоненты полномасштабного ILM-решения, в которое войдут программные системы управления политиками и перемещением данных, средства управления различными типами хранилищ информации и аппаратные системы для реализации этих хранилищ, а также консалтинговые услуги по созданию ILM-систем. Основу для реализации стратегии HP ILM в настоящее время составляют программные модули, входящие в семейство OpenView, Storage Builder и Data Protector. Модуль Storage Builder обеспечивает централизованное управление ресурсами в сетевой инфраструктуре хранения в контексте определенных бизнес-приложений (таких, скажем, как Oracle или Microsoft Exchange); он устанавливает соответствие между логическим представлением данных на хост-системе в виде файлов и томов и их реальным размещением на устройствах хранения, а затем на основе этих представлений отслеживает, анализирует и настраивает распределение дискового пространства между приложениями и пользователями. Data Protector управляет резервированием, архивированием и восстановлением информации, дополняя эти функции возможностями моментального копирования и другими средствами перемещения данных, которые поддерживаются в модулях управления устройствами хранения.
В НР предполагают реализовывать свою стратегию в области ILM по трем основным направлениям:
- разработка семейства ILM-решений для определенных приложений;
- совершенствование инфраструктуры сетевого хранения, разработка новых устройств и новых классов хранения;
- разработка новых технологий хранения, включая программное управление хранилищами для оперативной и справочной информации, средства перемещения данных и другие специальные управляющие модули.
Системы ILM будут строиться исходя из потребностей конкретных прикладных бизнес-решений. Первая полномасштабная реализация ILM-конфигурации предлагается для архивирования и управления документами систем электронной почты и Microsoft Office. В дальнейшем аналогичные решения будут построены для приложений Oracle, SAP и для определенных классов задач (в частности, таких, как управление медицинскими данными, юридической информацией и CRM).
ILM глазами FSC
Предлагая свою версию ILM-решения, компания Fujitsu Siemens Computers выступает в роли системного интегратора и вместе со своими продуктами, реализующими операции того или иного этапа жизненного цикла информации, предлагает решения других компаний, главным образом EMC/Legato и Network Appliance.
CentricStor
Данное решение призвано обеспечить виртуализацию всех процессов работы с магнитными лентами и роботизированными комплексами, используемыми на таких этапах ILM как исходное размещение, репликация и миграция. CentricStor построено на базе стандартных промышленных решений: Intel-серверы, RAID-системы и продукты на базе протокола Fibre Channel, ленты LTO в составе библиотек IBM Magstar, StorageTek и ADIC. Управление всеми накопителями на магнитных лентах осуществляется централизовано и нет необходимости в загрузке разнообразных драйверов. Обеспечивается параллелизм (до 512 виртуальных устройств). Благодаря использованию встроенной системы CentricStor RAID и интеллектуального кэша для выполнения операций резервного копирования и восстановления обеспечивается высокая надежность. Сервисные программы осуществляются в соответствии с принятыми политиками (репликация томов, обновление несущей поверхности, сжатие данных и т.п.) и автономно.
VFM
VFM (Virtual File Manager) — решение по виртуализации файловых серверов, путем использования структуры глобальных имен, созданной из комбинации имен файлов в NAS и Windows-серверов. VFM позволяет прозрачно для различных платформ осуществлять конфигурирование на различных уровнях, с учетом таких требований как возраст данных, уровень доступа к ним, размер, частота обращения и т.п.
Резервное копирование и репликация
Для безопасного резервирования в среде Windows используются программные продукты NetWorker, BrightStor и ARCServe. Кроме этого, для блочного инкрементального копирования может применяться система FAS/Nearstore SnapVault от Network Appliance. Специальные модули обеспечивают интерфейсы между системой NetWorker, СУБД и приложениями для выполнения процедур резервного копирования, репликации и восстановления. Эти модули изолируют приложения и СУБД от особенностей работы конкретных аппаратно-программных решений, отвечающих за хранение. Вместе с EMC компания FSC предлагает сценарий автоматического восстановления данных после сбоя или умышленного повреждения приложений SAP. В среднем, на ряде модельных примеров удавалось за пять минут восстановить процесс доставки данных для приложения. Для реализации этого сценария предлагается аппаратно-программная конфигурация, состоящая из программных средств группы Symmetrix Remote Data Facility/Asynchronous (SRDF/A), Symmetrix DMX GigE MultiProtocol Channel Director и Primecluster.
Почтовые серверы играют большую роль в поддержке бизнес-процессов; их простои или даже неоптимальное использование в состоянии парализовать деятельность предприятия. Решение easyXchange (рис. 5) призвано обеспечить бесперебойную работу почтовых систем за счет интеграции с FibreCAT, системами хранения и продуктами EmailXtender, DiskXtender и NetWorker от компании Legato. Служба Volume Shadow Copy Service позволяет несколько раз в день осуществлять резервное сохранение всей конфигурации и накопленных на текущий момент почтовых сообщений. Программный инструментарий NetWorker Business Suite обеспечивает параллельное копирование без нарушения основного рабочего процесса при гарантии доступности почтовых данных для Exchange Server 2003. Посредством EmailXtender почтовые сообщения перемещаются из хранилища в архив, и при случайном удалении или сбое можно будет выполнить восстановление для последней контрольной точки. Программный модуль Single Mailbox Recovery for Exchange — мощное средство восстановления индивидуальных почтовых ящиков, каталогов или отдельных сообщений. Для реализации дисциплины иерархического хранения, EmailXtender можно дополнить DiskXtender.
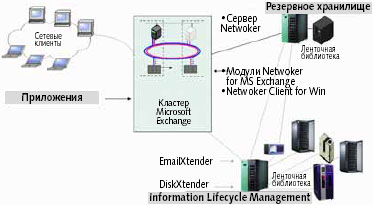 |
| Рис. 5. Архитектура easyXchange |
Полное копирование информационного объекта выполняется при помощи средств Symmetrix SRDF, позволяющих асинхронно зеркалировать LUN от одной системы хранения Symmetrix к другой. При этом модифицированные данные физически передаются только один раз, независимо от числа модификаций, сделанных приложением. FibreCAT MirrorView позволяет через сеть хранения синхронизировать данные между двумя устройствами FibreCAT (модели CX400 и CX600), а блок-ориентированное программное обеспечение SAN Copy дает возможность копировать LUN между различными системами хранения, например, между разными моделями Symmetrix, FibreCAT или оборудованием других производителей.
А арсенале интеграционных решений FSC есть и средства реплицирования по IP-сетям — продукт EMC Celerra Replicator, позволяющий создавать удаленные или локальные копии файловых систем. Для обеспечения безопасности копирования между системами хранения используется инструментарий Celerra OnCourse, позволяющий, в частности, консолидировать данные на одном узле и, наоборот, распределять информацию с одного узла на несколько серверов.
Для целей резервного копирования и восстановления в ILM-решениях от FSC применяются также продукты от Network Appliance, например, FAS/NearStore SnapMirror для зеркалирования сетевых томов путем актуального копирования только измененных блоков данных. FAS/SyncMirror целиком асинхронно зеркалирует тома и почти немедленно автоматически переключает управление на резервный том в случае сбоя основного тома. Primergy Duplex Data Manager осуществляет дублирование запросов на ввод/вывод на разные системы хранения, что позволяет на разных логических устройствах создавать несколько копий исходных данных, синхронизированных с источником.
Не забыты и продукты от Veritas. В частности, для зеркалирования данных критически важных приложений с использованием разных дисков и подсистем используется Veritas Volume Manager, а Veritas Volume Replicator может в режиме «один ко многим» и «многие к одному» выполнять групповые репликации в асинхронном и синхронном режиме, в том числе и через IP-сети.
Миграция, архивация и удаление
Процессы миграции в решениях FSC для ILM могут поддерживаться системой управления иерархическим хранением DiskXtender UNIX/Windows, которая прозрачно осуществляет для приложения перенос данных с основного хранилища на вспомогательное, а для отдельных приложений, например, для почтовых систем используются специальные модули. SnapView Integration Module for Exchange (SIME), входящий в состав решения SnapView, позволяет для Microsoft Exchange Application Server и Exchange Backup Server вызывать процедуры сохранения и восстановления пользовательских и служебных данных.
NetWorker Archiving обеспечивает функции архивирования для клиентов NetWorker. В процессе архивирования происходит запись данных, имеющих большой срок хранения на специальные архивные тома, не допускающие повторной перезаписи в автоматическом режиме. Для почтовых систем предлагается использовать EmailXtender, убирающий сообщения с сервера и сохраняющий их в архивном хранилище Enterprise Message Center с одновременным индексированием.
Centera Compliance Edition — программное решение, служащий для мониторинга периода использования информации, защиты и обеспечения безопасного доступа к информационным объектам. Одна из его функций — удаление объектов по мере завершения периода их активного использования. Вкупе с этим решением используется система FAS/NearStore SnapLock Compliance, работающая с томами NearStore или FAS и управляющая обработкой WORM-данных. NearStore и FAS поддерживают расширенные функции идентификации наподобие Kerberos, Active Directory, NTLM, NIS и LDAP, средства контроля (CIFS ACL, NFS Permissions и др.) и работу с кодированными данными (IPSec, SecureAdmin).
Время интегрировать
Отдельные элементы ILM уже можно было встретить и в мэйнфреймах, и в отдельных корпоративных решениях, построенных на базе архитектур клиент-сервер, но сегодня пришло время интеграции разрозненных знаний, технологий и методов из этой области. Индустрия готова к этому, а появление авторитетных системных интеграторов стимулирует это процесс. Однако не следует, сломя голову бросаться внедрять ILM. Ключевым фактором должны быть требования бизнеса. Иногда еще сложно понять все взаимосвязи и потоки документов внутри компании, прояснить все требования с целью их формализации в виде политик или требований SLA. Кроме этого, имеются еще и чисто организационные проблемы, например, антагонизм интересов различных департаментов; в этом случае без помощи внешних консультантов консолидировать процесс управления информацией на протяжении всего ее жизненного цикла будет весьма сложно.
