
Организации накапливают все более внушительные объемы данных из растущего числа функционирующих на различных платформах источников, как структурированной, так и неструктурированной информации. Они хранят данные на почтовых серверах, на Web-серверах, в электронных таблицах, в файлах приложений и в файлах мэйнфреймов. Так банковское учреждение может хранить касающиеся одного и того же клиента сведения сразу во многих источниках. Часто бывает, что данные представлены в разных форматах потому, что компании пользуются несколькими системами хранения, или потому, что они приобрели или слились с другими компаниями
Поиск необходимых сведений в нескольких источниках может быть сопряжен с большими сложностями и значительными затратами времени — в первую очередь из-за того, что в ходе каждой операции поиска запросы пользователей традиционно адресуются лишь одному источнику данных.
Столкнувшись с этой проблемой, некоторые поставщики разработали решения, основанные на технологии так называемого «федеративного» (federative) доступа к нескольким базам данных. Назовем такие продукты, как Liquid Data компании BEA Systems, программный инструментарий IBM DB2 Information Integrator (DB2 II), следующая версия Microsoft SQL Server, известная под рабочим названием Yukon, и СУБД Oracle 9i. С помощью этих средств пользователи могут одновременно обращаться с запросами сразу к нескольким разнородным источникам данных.
Потребность в технологии федеративного доступа к базам данных будет проявляться в первую очередь при эксплуатации систем, предназначенных для управления Web-контентом. Кроме того, как утверждает Тед Фридман, аналитик компании Gartner, компании будут реализовывать эту технологию в системах управления отношениями с клиентами (customer relationship management, CRM), которые, как правило, работают с данными из многих источников.
Вероятно, поставщики возьмут федеративные технологии на вооружение в качестве средства для получения преимуществ на рынке СУБД, отличающемся жесткой конкуренцией.
Технология изнутри
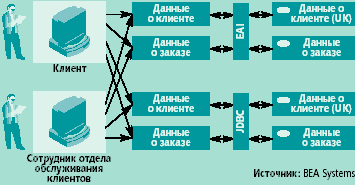
|
| Рис. 1. Традиционно пользователь (например, сотрудник отдела обслуживания клиентов), желающий получить информацию из нескольких источников, может опрашивать источники лишь в порядке очереди, а это связано с более значительными затратами времени и средств, чем в случае одновременного доступа к множеству источников. В данном случае доступ пользователей к отдельным базам данных осуществляется с помощью программных средств интеграции приложений предприятия (enterprise application integration, EAI) и JDBC. |
Информационные системы традиционной архитектуры (рис. 1) в каждый момент обеспечивают доступ лишь к одному источнику данных. Объясняется это тем, что до недавнего времени не существовало ни универсального языка для данных, ни качественных метаданных. Если пользователи желают получить необходимые данные из нескольких источников, они должны располагать точными метаданными, описывающими хранимые данные в форматах, доступных для чтения на различных платформах. Между тем, программные и аппаратные средства не отличались ни достаточной мощностью, ни функциональностью, необходимой для осуществления доступа к распределенным данным.
Раньше разработчики вручную создавали адаптеры для работы с полученными из нескольких источников данными, используя при этом API соответствующих источников. Однако вручную созданные адаптеры не способны автоматически подстраиваться под обновляемые версии API.
Централизованный подход
Централизованный подход к извлечению данных из различных источников, как правило, предполагает дублирование и последующий сбор скопированных данных в одну базу (или очень небольшое их число). Затем пользователи обращаются к этим агрегированным базам данных, которые иногда называют хранилищами.
Когда данные собраны в одном источнике, пользователи могут быстрее получить требуемую информацию, а система может с большей легкостью, чем в случае, если бы весь материал был разбросан по различным системам, нормализовать данные и выполнить другие операции по их обработке. Однако для сбора информации в централизованный источник требуется, чтобы данные, которые часто хранятся в различных форматах, были приведены к одному, а в ходе этого процесса, возможно появление ошибок.
Кроме того, хранилищам данных может оказаться сложно взаимодействовать с новыми источниками данных в незнакомых форматах. Наконец, то обстоятельство, что данные нужно дублировать и работать с несколькими их копиями, приводит к повышению издержек.
Федеративный подход
Федеративный подход (его реализацию средствами Liquid Data иллюстрирует рис. 2) предполагает доступ к данным, находящимся непосредственно в разнородных источниках, и создание единого виртуального хранилища. Разработчики могут писать все свои запросы к федеративной системе данных, играющей роль посредника, роль которого, в сущности, состоит в том, чтобы абстрагироваться от соединений с различными серверными источниками данных.
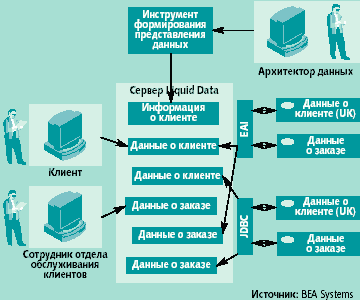
|
| Рис. 2. Технология федеративного доступа к базам данных позволяет пользователям (например, сотруднику отдела обслуживания клиентов) одновременно обращаться к данным из нескольких разнородных источников. В соответствии с разработанной компании BEA Systems технологией Liquid Data архитектор данных формирует стандартизованные представления данных так, чтобы пользователи могли «под одним углом зрения» изучать несхожие материалы. Затем система объединяет данные с тем, чтобы придать материалу логическую стройность; например, все данные о клиенте объединяются в одну категорию, а данные о заказе — в другую. Так пользователи могут с помощью однократных запросов сервера Liquid Data автоматически получать доступ к нескольким разнородным источникам данных. |
Однако, как поясняет Фридман из Gartner, процесс сбора данных из различных источников создает дополнительную нагрузку на систему. К тому же обработка «на лету» распределенных запросов, обращенных к различным источникам данных, по его словам, предполагает перемещение по сети значительных объемов данных, что может существенно снизить ее пропускную способность. Наконец, в случае использования федеративного подхода при выполнении нормализации и других операций по обработке данных возникает больше сложностей.
В период с 1998-го по 2001 год разработкой и продвижением федеративных технологий баз данных пытались заниматься несколько компаний. Но часто их системы оказывались слишком сложными, а разработанные средства обработки распределенных запросов плохо справлялись со своими задачами. Сегодня в рамках федеративной технологии доступа к базам данных сложилось два основных подхода.
Серверный подход предполагает физическое создание федеративного пути для одновременного доступа к данных из нескольких разнородных источников. Поставщики модернизируют серверы баз данных так, чтобы они с большей эффективностью взаимодействовали с другими серверами. Подход на базе программного обеспечения промежуточного слоя предполагает установление каналов связи между пользователями и источниками данных программным путем. Доступ одних серверов к другим осуществляется не через аппаратные компоненты, а с помощью программных средств.
Новые технологии
Возможность одновременно направлять запросы нескольким источникам, содержащим разнородные данные, возникла благодаря нескольким технологическим решениям. Так, повышение эффективности оптимизаторов запросов, программ, которые с помощью системы правил осуществляют тонкую подстройку выполнения запросов, стало следствием применения более совершенных алгоритмов. С другой стороны, повысилось быстродействие центральных процессоров и жестких дисков, что привело к росту производительности систем поиска.
Технология федеративного доступа к базам данных позволяет взаимодействовать (в той или иной степени) с данными, написанными практически на любом языке, однако своим существованием она во многом обязана языку XML.
Используемые в языке XML теги представляют семантику данных, которая может быть распознана разнородными системами. Таким образом, XML облегчает выполнение запросов на получение информации, хранящейся на различных платформах в различных структурах данных. XML помогает системе расшифровывать данные из разнородных источников, а сети и оснащенные средствами многопотоковой обработки операционные системы одновременно обрабатывают запросы пользователя на получение данных из нескольких хранилищ.
Важной технологией, обеспечивающей реализацию объединенного доступа к базам данных, обещает стать язык XQuery. Этот язык позволяет пользователям формулировать «интеллектуальные» запросы на информацию, хранимую в различных источниках, обмениваемую между этими источниками и представляемую из них с помощью XML.
Без особого языка, предназначенного для составления запросов к файлам XML трудно обойтись, поскольку содержащиеся в таких файлах данные образуют иерархические структуры и, значит, не вписываются в реляционную модель данных, в рамках которой обычно и используется язык SQL.
Новый язык для современных технологий управления базами данных нужен еще и потому, что язык SQL был разработан в конце 70-х годов, в период, когда не было ни Internet, ни XML.
Продукты, реализующие технологию федеративного доступа
BEA Liquid Data
Компания BEA Systems разработала систему Liquid Data для своего сервера приложений WebLogic Enterprise Platform. По словам Эджея Патела, вице-президента компании и генерального менеджера по Liquid Data, этот продукт, в основу которого положено связующее ПО, выступает в качестве интерфейса между пользователем и распределенными серверами. Для распознавания мощных метаданных и последующего их использования с целью извлечения данных из нескольких источников, данная технология предусматривает применение языка XML в сочетании с Web-службами. Данные из различных баз данных автоматически приводятся к стандарту XML.
IBM DB2 Information Integrator
Разработанный корпорацией IBM продукт DB2 II представляет собой федеративный сервер для интеграции данных. Система опрашивает источники данных из их мест расположения и затем с помощью управляющих базами данных серверов консолидирует полученные результаты.
Функционирование системы отчасти обеспечивается тем, что разработанная компанией платформа DB2, которая уже совместима с языком SQL, оснащается интерфейсом XQuery. Для взаимодействия с источниками данных, созданных другими производителями, в системе DB2 II используются специальные «оберточные» программы.
Microsoft Yukon
До конца 2003 года Microsoft планирует выпустить в свет бета-версию Yukon. Это один из вариантов разработанной в компании СУБД SQL Server, в котором, помимо прочего, будет облегчена обработка данных, представленных в разных форматах и полученных из разных источников.
В пакете Yukon заимствованные из SQL Server средства для работы с XML будут дополнены интерфейсом XQuery, что даст возможность использовать как SQL-, так и XQuery-запросы. Кроме того, в изделии Yukon будут реализованы и объединенная, и централизованная модели доступа к данным. Microsoft планирует начать выпуск Yukon одновременно с выпуском версии ОС Windows, имеющей рабочее название Longhorn.
Oracle 9i
Сандипан Банерджи, курирующий вопросы управления продуктами в отделе серверных технологий Oracle, утверждает, что в Oracle 9i реализованы оба подхода к организации федеративного доступа к данным из нескольких разнородных источников.
Платформа Oracle 9i предназначена прежде всего для взаимодействия с хранилищами данных в соответствии с централизованной моделью. Однако, как поясняет Роберт Тоум , менеджер по продуктам группы разработки распределенных баз данных Oracle, «если вас больше устраивает объединенный подход, можете воспользоваться средством, которое мы именуем Distributed SQL». Эта функция интегрирует несколько хранилищ данных.
Кроме того, Oracle 9i предполагает использование словаря данных для опроса удаленных баз данных о таких, к примеру, сведениях, как имена их таблиц и столбцов. Посредством этого формируется представление о получаемых данных.
В продукте реализована технология Oracle Streams, обеспечивающая регистрацию изменений в содержимом удаленных баз данных и хранение их в очередях. Позднее пользователи могут отражать эти изменения в своих системах; эта процедура гарантирует, что в распоряжение пользователей попадают самые последние версии данных из различных источников.
При использовании технологий федеративного доступа к базам данных имеют место достаточно интенсивные обмены между пользователями и источниками данных, поэтому в сетях отмечаются задержки и непроизводительные затраты ресурсов. Кроме того, на серверы возлагается бремя получения и обработки запросов; серверы должны преобразовывать, очищать и оптимизировать данные. Все эти факторы снижают производительность системы.
Если на протяжении ближайших пяти лет спрос на технологии федеративного доступа к базам данных возрастет, это будет иметь положительное воздействие на рынок «плоских» баз данных. А тот факт, что в W3C занимаются разработкой стандарта XQuery, может способствовать появлению на рынке новых поставщиков средств федеративного доступа к базам данных.
Есть основания полагать, что по мере того, как повышается эффективность процессоров и алгоритмов кэширования, будет расти и эффективность технологий федеративного доступа к базам данных, отметил Филипп Рассом, аналитик компании Giga Information Group.
Стивен О?Грейди, аналитик занимающейся исследованиями рынка компании RedMonk, полагает, что будущее за технологиями федеративного доступа к базам данных. «Пусть разные поставщики предлагают различные решения проблемы, — отметил он, — но все дело в том, что технические средства в данной сфере наконец-то вышли на уровень потребностей, а значит, что пришло время средств управления федеративнми данными. По мере того как предприятия будут проявлять все больший интерес к информации, находящейся на периферии главного поля деятельности предприятия, спрос на эти изделия будет расти».
Попытки реализовать федеративный подход предпринимались и раньше, но без особого успеха. В некоторых случаях разработчикам удавалось получать доступ к более чем одному хранилищу данных, однако задача надлежащей интеграции с многими источниками до недавних пор оставалась неразрешенной.
***
Федеративная технология, как правило, обходится дешевле, позволяет выполнять задачу быстрее и порождает меньше ошибок, поскольку данные остаются на местах своего постоянного хранения. Кроме того, с помощью этой методики можно с легкостью обращаться к новым источникам данных.Дэвид Гир (d@geercom.com) — независимый автор, специализирующийся на проблемах технологии.
David Geer, Federated Approach Expands Database-Access Technology. IEEE Computer, May 2003. IEEE Computer Society, 2003, All rights reserved. Reprinted with permission.
