

Основным и практически единственным конкурентом 64-разрядных микропроцессоров пост-RISC архитектуры Intel IA-64 с точки зрения производительности остается IBM Power 4. Этот RISC-микропроцессор имеет наивысшие показатели производительности среди всех современных 64-разрядных микросхем.
 Первоначальные утверждения разработчиков IA-64, что после появления микропроцессоров данной архитектуры RISC-архитектура будет побеждена и наступит эпоха «пост-RISC», пока не реализовались. Рынку представлено уже второе поколение микропроцессоров IA-64, а лидером по производительности с плавающей запятой на тестах SPECfp2000 и Linpack (n=100 и n=1000) является RISC-процессор IBM Power4 (таблица 1). По целочисленной производительности (SPECint2000) лидируют 32-разрядные процессоры AMD Opteron и Intel Pentium 4, чуть опережая Power4.
Первоначальные утверждения разработчиков IA-64, что после появления микропроцессоров данной архитектуры RISC-архитектура будет побеждена и наступит эпоха «пост-RISC», пока не реализовались. Рынку представлено уже второе поколение микропроцессоров IA-64, а лидером по производительности с плавающей запятой на тестах SPECfp2000 и Linpack (n=100 и n=1000) является RISC-процессор IBM Power4 (таблица 1). По целочисленной производительности (SPECint2000) лидируют 32-разрядные процессоры AMD Opteron и Intel Pentium 4, чуть опережая Power4.
C появлением Madison (третье поколение IA-64) производительность вырастет на 30-50%, но подрастет и производительность конкурентов (хотя, возможно, и не в такой степени). Думаю, основными соперниками IA-64 должны остаться 64-разрядные RISC-процессоры. Микропроцессоры Pentium 4 подошли к ситуации, когда они будут не в состоянии поддерживать характерные для современного развития информационных систем объемы оперативной памяти (имеется в виду емкость, доступная одному приложению) даже в ПК-серверах, а производительность этих микропроцессоров возрастет в этом году, скорее всего, не очень сильно. Появились 64-разрядные AMD Opteron, но они вряд ли будут существенно быстрее Pentium 4/Xeon, по крайней мере, в 2003 году.
В условиях, когда будущее семейства Sun UltraSPARC как возможного лидера производительности вызывает определенный скепсис, флагманом RISC-архитектуры могут оказаться микропроцессоры Power4, а в будущем — Power5. Если проанализировать характеристики быстродействия Power4 (таблица 1), то обнаружится, что он имеет наиболее сбалансированную производительность: у Alpha и Itanium 2 — «провалы» с целочисленной производительностью, у Pentium 4 — отставание по плавающей запятой.
Power 4 оказались первыми микропроцессорами, в которых была реализована идея размещения нескольких процессорных ядер на одной микросхеме. Также двухъядерными планировались Alpha 21464. Эта идея стала архитектурным «ответом» RISC на вызов со стороны IA-64; будущие микропроцессоры UltraSPARC V и PA-RISC также ожидаются в многоядерном исполнении. Другая хорошая идея для RISC-архитектуры — поддержка многопоточности [2]. Однако в будущих поколениях процессоров архитектуры IA-64 также ожидается применение многопоточности и размещение двух процессорных ядер на одном кристалле. Поэтому спор между RISC и IA-64 во многом определяется тем, что лучше — явное «статическое» распараллеливание компилятором в EPIC/VLIW или «динамическое» распараллеливание выполнения команд аппаратурой суперскалярных RISC-процессоров между различными функциональными исполнительными устройствами.
Общая структура Power4
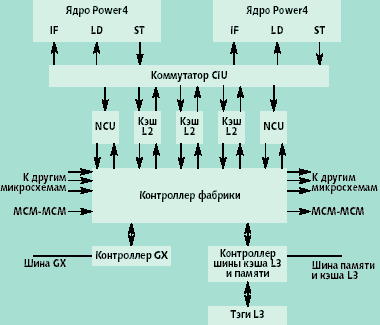
Публикации о Power4, относящиеся ко времени, предшествовавшему их реальному появлению [1-3], естественно, не содержали деталей микроархитектурной реализации. Детали эти — особенно по организации внеочередного суперскалярного выполнения команд — стали известны гораздо позднее [4-6]. На самом деле, Power4 (даже если забыть о наличии в кристалле двух формирующих SMP-конфигурацию процессорных ядер) — нечто большее, чем просто микропроцессор. Дело в том, что в микросхеме Power4 содержатся интегрированные аппаратные средства, определяющие важные архитектурные черты компьютерных систем на основе Power4 (рис. 1). В числе этих средств — порты каналов, напрямую связывающих Power4 с другими процессорами внутри так называемого «многомикросхемного» модуля (MCM — multi-chip module); порты каналов связи между различными модулями МСМ; канал ввода-вывода (шина GX); интегрированный контроллер шины оперативной памяти и кэша третьего уровня. Микросхема Power4 вместе с микросхемами кэша третьего уровня и контроллера оперативной памяти практически определяют структуру SMP-компьютеров на базе Power4.
|
| Рис. 1. Общая организация микросхемы Power4 |
Надо подчеркнуть, что тенденции к интеграции в микропроцессоры дополнительных аппаратных средств обнаруживаются и в ряде других микропроцессоров. Так, 64-разрядные AMD Opteron имеют интегрированный контроллер оперативной памяти. Это, как известно, способствует уменьшению задержек при обращении в память — одно из главных узких мест сегодняшних компьютерных систем. Подобно Power4, Opteron имеет порты к специальным каналам Hyper Transport, используемым для организации межпроцессорных связей и ввода-вывода. Alpha 21364, также имеет встроенный контроллер памяти и поддержку каналов межпроцессорных связей и ввода-вывода.
Однако Power4 имеет много уникальных особенностей микроархитектуры. Наиболее яркой является необычная по современным меркам организация кэш-памяти. Как видно из рис. 1., микросхема Power4 содержит два одинаковых процессорных ядра. Каждое из этих ядер имеет свой кэш первого уровня, свои исполнительные устройства (EU — executive unit), конвейеры и т.п. Однако кэш второго уровня у этих ядер общий. Для доступа к этому кэшу со стороны процессорных ядер применяется коммутатор CIU (core interface unit). Каждое ядро имеет по три порта к CIU (для выборки команд — IF, загрузки регистров — LD и сохранения данных — ST).
Кэш второго уровня организован в виде трех независимых блоков, каждый со своим контроллером и портами CIU. Контроллеры кэша второго уровня работают одновременно, обрабатывая по 32 байта за такт процессора. Эти данные передаются в I-кэш первого уровня или D-кэш первого уровня. При сохранении данных процессорами последние используют порты CIU шириной 8 байт. Логической частью кэша второго уровня являются также два так называемых некэширующих устройства (NCU — non-caching unit), каждое приписанное к своему процессору. NCU-устройства отвечают за сериализацию команд и выполнение некэшируемых операций в иерархии памяти [4, 5]. Распределение обработки запросов в кэш второго уровня между тремя блоками способствует увеличению производительности.
Через специальное устройство — «контроллер фабрики» (FC — fabric controller) — данные могут быть направлены в кэш третьего уровня и оперативную память. Через контроллер шины GX, имеющий порт к FC, осуществляется весь ввод-вывод. Кэш третьего уровня реализован как отдельная микросхема, являясь внешним по отношению к процессорам. Кэш третьего уровня является общим для модуля MCM, конструкция которого может содержать, кроме микросхемы кэша третьего уровня, четыре микросхемы Power4. Для передачи данных между микросхемами Power4, входящими в МСМ, и между самими модулями МСМ, в FC предусмотрены выделенные порты. Детали строения кэша третьего уровня и МСМ, как сказано выше, мы предполагаем рассмотреть в статье, посвященной компьютерам на базе Power4.
Организация кэш-памяти
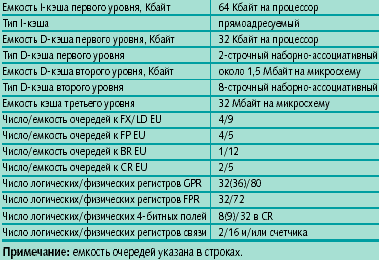
Характеристики кэш-памяти Power4 приведены в таблице 2. Интегрированная в микросхему Power4 кэш-память (I-кэш первого уровня, D-кэш первого уровня, кэш второго уровня) использует строки кэша длиной 128 байт. Емкость D-кэша первого уровня равна 32 Кбайт, что вдвое меньше, чем у I-кэша первого уровня, однако последний является прямоадресуемым, в то время как D-кэш первого уровня имеет двухстроковую наборно-ассоциативную организацию, что способствует увеличению его эффективной емкости по сравнению с прямоадресуемой организацией.
| Таблица 2. Некоторые характеристики микроархитектуры Power4 |
|
I-кэш первого уровня является однопортовым и может читать или писать 32 байта за такт, что эквивалентно 8 командам (всего же в строке кэша содержится, соответственно, 32 команды PowerPC). Оглавление I-кэша индексируется эффективным (исполнительным) адресом (EA — effective address), а каждая строка содержит поэтому 42 бита реального адреса. Кроме I-кэша первого уровня в Power4 имеется специальный буфер предварительной выборки команд емкостью четыре строки по 32 команды в каждой. Аппаратура Power4 осуществляет предварительную выборку одной или двух последовательных строк I-кэша (в зависимости от попадания или промаха) в этот буфер, если находит, после проверки, что их нет в I-кэше. При промахе в I-кэше перед обращением в кэш второго уровня просматривается сначала блок предварительной выборки команд.
D-кэш первого уровня, использующий FIFO-алгоритм замещения данных и сквозную запись, имеет три порта. Это позволяет ему в одном такте читать две 8-байтные величины и одновременно записывать 8 байт. При промахе в D-кэше первого уровня запрос на строку кэша направляется в кэш второго уровня, сохраняясь при этом в очереди LMQ (load miss queue), емкость которой составляет 8 строк. В случае, если LMQ заполнена, соответствующая команда загрузки регистра «отвергается» и будет выдана повторно спустя 7 тактов. Для команд сохранения для обеспечения возможности внеочередного выполнения применяются несколько специальных очередей сохранения, в том числе, очередь StQ (рис. 2). Кроме того, в Power 4 реализована аппаратная предварительная выборка данных в кэши разного уровня, позволяющая скрыть задержки при обращении в память (см. детали в [6]). Время выполнения загрузки/сохранения регистров с плавающей запятой равно 4 и 12 тактам при работе с кэшем соответственно первого и второго уровня.
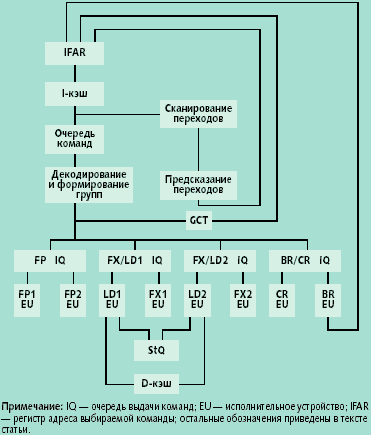
| Рис. 2. Микропроцессорное ядро Power4 |
|
Кэш второго уровня является уже 8-строчным наборно-ассоциативным, и имеет емкость 1,41 Мбайт [6]. Это меньше, чем у других RISC-процессоров с большим интегрированным кэшем: в Alpha 21364 кэш второго уровня имеет емкость 1,75 Мбайт, в PA-8700 D-кэш первого уровня имеет емкость 1,5 Мбайт (плюс 750 Кбайт в I-кэше первого уровня), но в этих случаях кэши не разделяются между процессорными ядрами. Это, однако компенсируется использованием с Power4 кэша третьего уровня большой емкости (32 Мбайт на двухъядерную микросхему Power4 или 128 Мбайт на модуль MCM), построенного по технологии eDRAM (embedded DRAM). Кроме того, для высокопроизводительных приложений, чувствительных к высокой пропускной способности оперативной памяти, IBM предлагает вариант Power4 с одним процессорным ядром [6]. В этом случае не только не возникает конкуренции за доступ в оперативную память между процессорными ядрами одной микросхемы, но и емкость кэша в расчете на процессор достигает рекордных значений.
Кэш второго уровня передает строку за 4 такта. В качестве алгоритма замещения строк в нем используется псевдо-LRU. Информация, записываемая в кэш второго уровня из кэша первого уровня, поступает порциями по 8 байт и сначала буферизуется в двух (по числу процессоров) очередях, имеющих по 4 строки длиной 64 байта каждая. Для поддержания согласованного представления данных в кэше второго уровня используется расширенный разработчиками протокол MESI, включающий 7 состояний. Время выполнения загрузки/сохранения регистров с плавающей запятой при работе с кэшем первого уровня равно 4 тактам, а с кэшем второго уровня — около 14 тактов. Кроме того, в Power4 реализована аппаратная предварительная выборка в кэши разного уровня, позволяющая скрыть задержки при обращении в память [6].
В определенном смысле еще одним типом кэш-памяти современных микропроцессоров можно считать буферы быстрой переадресации TLB, используемые для ускорения преобразования из виртуального адреса EA в адрес реальной памяти RA. В архитектуре PowerPC кроме обычного TLB предполагается еще наличие SLB (Segment Lookaside Buffer), ассоциативного буфера емкостью 64 строки, который используется для таблицы сегментов.
В Power4 имеются две таблицы ERAT, куда помещаются пары (EA, RA) — одна для I-кэша (IERAT), другая для D-кэша (DERAT). Обе являются двухстрочными наборно-ассоциативными, емкостью по 128 строк, и используют EA как индекс. Кроме того, имеется 4-строчный наборно-ассоциативный TLB емкостью 1024 строки, общий для команд и данных (естественно, каждое процессорное ядро имеет свои блоки TLB). В случае промаха в IERAT/DERAT делается попытка найти нужную информацию в TLB. Так, при промахе при обращении в DERAT соответствующая команда будет отвергнута и останется в своей очереди на выполнение; попытка ее выполнения будет повторена минимум семью тактами позже. Для перезагрузки ERAT из TLB требуется 10 тактов. Емкость TLB позволяет адресовать не менее 4 Мбайт памяти (больше емкости кэша второго уровня), что по сравнению с Power3 уменьшает вероятность промахов в TLB и соответственно потенциальные накладные расходы.
Преимуществом реализации TLB в Power4 является поддержка страниц памяти емкостью не только 4 Кбайт, но и 16 Мбайт. Применение страниц малой емкости в приложениях, реально использующих большое адресное пространство, может приводить к частым промахам при обращении к буферу TLB, имеющему ограниченную емкость.
Микроархитектура процессорных ядер
На рис. 2 представлена блок-схема процессорных ядер Power4. Процессоры Power4 являются суперскалярными, осуществляющими внеочередное спекулятивное исполнение команд с использованием техники переименования регистров. За один такт процессор может запустить на выполнение до 8 команд, но «поддерживаемый темп» (т.е. число команд, завершающих выполнение за один такт) равен 5.
UltraSPARC III в состоянии выполнять максимум 6 команд за такт (поддерживаемое значение — 4 команды за такт). Pentium 4 может запускать на выполнение до 6 микроопераций за такт. Itanium 2 может реально выполнять одновременно команды двух связок, т.е. 6 команд за такт. В Alpha 21464 планировалось запускать на выполнение до 10 команд за такт и завершать выполнение до 8 команд за такт. Одновременно в Power4 может находиться на разных стадиях выполнения до 200 команд, а в Pentium 4 — до 126 микроопераций.
В составе Power4 имеется 8 конвейеризованных исполнительных устройств, в том числе два одинаковых устройства с плавающей запятой (FP EU), каждое из которых может выполнять команды «умножить и сложить», что дает 4 результата с плавающей запятой за такт. Помимо FP EU, имеется два устройства загрузки регистров/сохранения (LD EU), которые выполняют арифметические действия по генерации адресов; два устройства для работы с числами с фиксированной запятой (FX EU), устройство выполнения переходов (BR EU) и устройство выполнения логических операций с регистром условий (CR EU). Только одно из устройств FX EU может делить, а операции извлечения квадратного корня и деления с плавающей запятой не конвейеризованы.
Предсказание переходов
Для современных суперскалярных микропроцессоров, имеющих длинные конвейеры (в Power4 основной конвейер имеет 15 стадий), высокая точность предсказания переходов крайне актуальна, а методы предсказания переходов быстро развиваются. Задержка при неправильном предсказании перехода в Power4 составляет не менее 12 тактов. В Power4 за один такт из I-кэша может быть выбрано до 8 команд. Логика предсказания переходов сканирует их, и за один такт может обработать до 2 команд перехода. Расчет адреса перехода для абсолютной и относительной адресации происходит на этапе сканирования переходов.
Подобно другим современным RISC-процессорам, в Power4 задействовано несколько механизмов предсказания переходов, включая статическое и динамическое предсказание. При этом направление безусловных переходов не предсказывается, а направление условных переходов предсказывается всегда. Для переходов, используемых при вызовах подпрограмм (bclr — «переход по регистру связи») применяется специальный стек адресов, а для команд переходов в цикле (bctr — «переход по регистру счетчика») используется особый «кэш счетчика» (count cache). Он является прямоадресуемым и имеет емкость 32 строки, каждая из которых содержит 62-разрядные адреса. Запись в этот кэш, как и в стек адресов перехода при вызовах подпрограмм, происходит, если на это указано в коде программы.
Для динамического предсказания в Power4 используются три таблицы истории переходов. Первая — традиционная таблица истории переходов емкостью 16К строк, индексом в которой является адрес команды перехода. Она вырабатывает одноразрядный предиктор, который в IBM именуют локальным предиктором.
Вторая таблица, дающая глобальный предиктор, — уникальная особенность Power4; она связана с диспетчированием команд в Power4 группами по 5 команд. Эта таблица также содержит 16К строк и позволяет сгенерировать одноразрядный глобальный предиктор. В таблице отслеживается «путь выполнения» программы, приводящий к переходу. Этот путь выполнения представлен 11-разрядным вектором глобальной истории, по 1 биту на группу команд для всех предыдущих выбранных 11 групп. Бит в этом векторе указывает, была ли следующая группа команд выбрана из последовательного сектора I-кэша или нет. Вектор глобальной истории хэшируется с адресом команды перехода, используя поразрядное «исключающее или», генерируя индекс в этой таблице.
Наконец, третья таблица — таблица селектора, имеет те же самые 16К строк, в которых отслеживается, какая из двух схем предсказания работает лучше; на ее основе генерируется окончательное предсказание переходов. Подобный вариант реализации лучшего выбора, но между динамическим и статическим предсказанием переходов, был реализован в HP PA-8500.
Динамическое предсказание переходов может быть «перекрыто» статическим, генерируемым программно, для чего используются два ранее зарезервированных бита в командах условного перехода архитектуры PowerPC. Если эти биты обнулены (как предполагалось в PowerPC), используется аппаратное динамическое предсказание. Статическое предсказание переходов, генерируемое, например, компилятором, применяется, в частности, в архитектуре HP PA-8x00.
Конечным результатом работы логики предсказания переходов является загрузка в регистр адреса выбираемой команды (IFAR). В то время как некоторые разработчики других микропроцессоров заявляли о превышении уровня точности предсказания переходов в 90%, оценки такого рода для Power4 автору неизвестны.
Работа конвейеров Power4
Первые стадии конвейера (IF, IC, BP), рис. 3, отвечают рассмотренным выборке команд и предсказанию переходов. Затем на стадиях с D0 по DG осуществляется декодирование и образование групп команд (по 5 команд на группу). Концепция группы команд введена в Power4 для упрощения логики внеочередной суперскалярной обработки «на лету» большого числа одновременно выполняемых команд. В отличие, скажем, от Pentium 4, в Power4 не реализована точная обработка прерываний, состояние процессора фиксируется «с точностью до группы команд». При этом команды из различных групп могут начинать выполняться во внеочередном порядке. Скажем, команда из последующей группы может запуститься на выполнение до какой-либо команды из предыдущей (если судить по исходным программным кодам) группы.
Декодирование в Power4 имеет особенности, характерные скорее для современных х86-совместимых процессоров, чем для процессоров архитектуры RISC: RISC-команды архитектуры PowerPC декодируются в так называемые внутренние команды, называемые IOP. Так что реально исполняются внутренние команды, и группы команд содержат по 5 внутренних команд. Таким образом, IOP есть аналог микроопераций в Pentium 4. Справедливости ради надо сказать, что, в отличие от Pentium 4, IOP-команды, как правило, совпадают с обычными командами PowerPC.
К использованию IOP разработчиков вынудила необходимость обеспечить высокую тактовую частоту. Поэтому IOP содержат только команды, которые читают не более двух регистров и пишут не более чем в один регистр. Исключение сделано для некоторых команд с плавающей запятой типа «умножить и сложить», в которых применяется три регистра-источника. Другие команды при необходимости разбиваются на последовательность IOP-команд. Так, команда загрузки нескольких слов в регистры преобразуется в несколько IOP-команд загрузки слова. Если при декодировании команды требуется две IOP, в IBM используют термин «крекинг« (cracking), а если требуется больше, то говорят о «миликодированных» (milicoding) командах.
При крекинге обе порождаемых IOP-команды должны оказаться в одной группе, и если места в текущей группе не хватает, группа завершается и начинается создание следующей группы команд. Миликодируемые команды всегда размещаются в новой группе команд, а команда, следующая за миликодируемой, в отличие от случая крекинга всегда начинает новую группу.
При декодировании команды располагаются в группе последовательно по мере поступления, со слота 0 и по слот 4. Последний слот, однако, зарезервирован для команд перехода, и если их в группе нет, сюда помещается команда «нет операции» (noop). При необходимости команды noop вставляются внутрь группы, чтобы «протолкнуть» команду перехода в слот 4. Конечно, применения команд noop хотелось бы избегать, но на практике она вставляется не только в коды для Power4, но и для других RISC-процессоров, в том числе для Alpha.
За один такт диспетчируется только одна группа (т.е. все ее 5 команд). Диспетчирование состоит в посылке IOP из группы команд в очереди выполнения. Группы диспетчируются последовательно в порядке их расположения в программном коде, однако выборка IOP-команд из очередей на выполнение в исполнительные устройства EU осуществляется во «внеочередном» порядке.
За один такт может завершиться только одна группа команд. Это подразумевает завершение выполнения с фиксацией результатов не только всех команд данной группы, но и всех предшествующих групп. Команды, которые нельзя выполнить спекулятивно, не выполняются до тех пор, пока они не должны завершаться следующими. Примерами таких команд являются команды синхронизации контекста; такие команды образуют отдельные группы.
Для реализации внеочередного выполнения многие архитектурные регистры Power4 подвергаются переименованию. Команды, устанавливающие регистр, не являющийся переименуемым, завершают группу. Команды, выполняющие операции с регистром условий, в программных кодах встречаются реже других, и их расположение разработчики ограничили слотами 0 и 1. Для управления группами используется таблица завершения групп GCT емкостью 20 строк, в каждой из которых содержится адрес первой команды группы и информация о завершении команд группы.
В таблице 2 представлены данные о количестве и емкости очередей выдачи команд на выполнение для исполнительных устройств разного типа. В случае, если очередь является общей для нескольких устройств, слоты очереди распределяются между ними фиксированным образом.
Для того чтобы группа команд могла быть диспетчеризована на выполнение, необходимо, чтобы были доступны все необходимые для нее ресурсы, в противном случае диспетчеризация задерживается. Среди этих ресурсов:
- строка таблицы GCT;
- слоты в очередях выдачи команд для всех команд группы;
- физические регистры для всех переименуемых регистров, устанавливаемых командами группы; при этом из-за возможного разбиения некоторых команд PowerPC на последовательность IOP в Power4 было добавлено 4 дополнительных логических регистра общего назначения (GPR) и дополнительное 4-битное поле в регистре CR (переименовываются именно эти 4-битные поля);
- строка в очереди переупорядочения загрузки LRQ (всего в этой очереди имеется 32 строки);
- строка в очереди переупорядочения сохранения SRQ (той же емкости, что и LRQ).
Последние два типа ресурсов используются при внеочередном выполнении команд загрузки/сохранения регистров в [4, 5].
Как мы видим, имеется ряд ограничений на формирование группы команд, что также способствует упрощению аппаратуры Power4 (сложность аппаратуры поддержки внеочередного спекулятивного выполнения — один из основных недостатков современных суперскалярных RISC-процессоров) и соответственно созданию возможностей роста тактовой частоты. Диспетчеризация групп происходит последовательно, как и завершение выполнения групп, однако возможные при этом потери производительности (уменьшение среднего числа выполняемых за такт команд) менее важны по сравнению с увеличением среднего числа выполняемых за такт команд из-за внеочередного выполнения команд. Крайне интересно было бы получить сравнительные оценки достигаемых в реальных программах уровней среднего числа выполняемых за такт команд для Power4 и Itanium 2.
Вернемся к обсуждению конвейеров Power4 (рис. 3). Диспетчеризация групп и переименование регистров отвечают стадии MP. На стадии ISS команды IOP выдаются в устройства EU, на стадии RF осуществляется чтение регистров, а на стадии EX вычисляется результат, записываемый в нужный регистр на стадии WB. Конвейер, в котором команды попадают в EU CR, аналогичен рассмотренному конвейеру для операций с фиксированной запятой и на рисунке не представлен. Конвейеры с плавающей запятой требуют для выполнения шесть тактов (6 ступеней вместо одной EX). Для завершения команд всех конвейеров требуется еще два такта (стадии XF и СР), если все предыдущие группы и команды данной группы уже завершены.
Интересно, что общая длина конвейера, 15 стадий, в Power4 меньше, чем в обладающем самой высокой частотой процессоре Pentium 4 (20 стадий), однако это больше, чем обычно используется или планируется к использованию в других процессорах: 14 стадий в UltraSPARC III, 12 — AMD Hammer, 9 — Alpha 21464, 8 — Itanium 2, 7 — Alpha 21264. Это коррелирует с наивысшей достигнутой на сегодня в Power4 тактовой частотой среди всех микропроцессоров, не имеющих архитектуру х86.
Заключение
Что касается технологических особенностей Power4, то в настоящее время они производятся по 0,13-микронной технологии и содержат свыше 180 млн. транзисторов при площади 265 кв. мм. Технологическое лидерство IBM в области полупроводникового производства общеизвестно, и в данном конкретном случае оно позволило достигнуть не только достаточно высоких тактовых частот (выпускаются процессоры с частотами 1,2, 1,45, 1,5 и 1,7 ГГц), но и достаточно низкого для высокопроизводительных процессоров уровня энергопотребления (70 Вт на частоте 1,7 ГГц).
С точки зрения производительности Power4 является наиболее сбалансированным по сравнению со своими предшественниками той же архитектуры (семейства Power, PowerPC, RS64) и, особенно если его себестоимость оказывается не слишком высокой, может быть использован во всем спектре компьютеров RISC-архитектуры от IBM. Подобная унификация, по сравнению с применением нескольких различных процессоров, является очевидным плюсом.
Анализ особенностей микроархитектуры Power4, связанных с внеочередным выполнением команд, говорит о потенциальных возможностях дальнейшего совершенствования соответствующих аппаратных средств. Это, в сочетании с высокими достигнутыми показателями производительности, говорит о том, что по этим показателям RISC-процессоры по-прежнему соперничают с IA-64. Процессоры IBM фактически становятся основным конкурентом представителей семейства Itanium. Вероятно, следующим этапом в этом противостоянии станет поединок Madison и Power5.
Работа поддержана РФФИ, проект 01-07-90072 n
Литература
- К. Diefendorff, Power4 focuces on Memory Bandwidth. Microprocessor Report, 1999, v. 13, No. 13.
- В. Корнеев, Эволюция микропроцессорных архитектур. // Открытые системы, 2000, № 4.
- М. Кузьминский, Будущее архитектуры Power4. // Открытые системы, 2000, № 4.
- J.M. Tendler, J.S. Dodson, J.S. Fields, H. Le, B. Sinharoy, «IBM e-server POWER4 System Microarchitecture». IBM White Paper, Oct. 2001.
- J.M. Tendler, J.S. Dodson, J.S. Fields, H. Le, B. Sinharoy, «POWER4 system microarchitecture», IBM J. Res. Develop., 2002, v. 46, No. 1.
- S. Behling, R. Bell, P. Farrell, H. Holthoff, F. O?Connell, W. Weir, «The POWER4 Processor Introduction and Tuning Guide». IBM, Nov. 2001.
- e-server pSeries and IBM RS/6000 Performance Report, May 6, 2003.
Мир микропроцессоров RISC понес существенные потери: прекращено развитие семейства Alpha; объявлено о свертывании работ над PA-RISC и MIPS R1x000. Между тем, успех Alpha 21364 (они по производительности вычислений с плавающей запятой обогнали Itanium 2 на тестах SPECfp2000), а также проектные показатели Alpha 21464 (по числу одновременно исполняемых команд) свидетельствуют, что потенциал RISC все еще велик.
***Состав исполнительных устройств в Power4 выглядит достаточно солидно. Четыре результата с плавающей запятой за такт способны выдавать также Alpha 21364, PA-8x00 и Itanium 2 (х86-совместимые процессоры дают только два 64-разрядных результата). В Power4 реализованы также имеющиеся в архитектуре PowerPC «необязательные» команды с плавающей запятой, в том числе вычисления обратной величины и обратного квадратного корня, и условное присвоение с плавающей запятой, позволяющее избегать команд перехода.
