
Незаметно, но неотвратимо параллельные вычисления и распределенная обработка данных входят в нашу жизнь — то, что еще десять лет назад было привилегией избранных, теперь становится массовым. Уникальные возможности дает Internet, потенциально позволяя создать самый большой параллельный компьютер. Главное — научиться эффективно использовать уже имеющийся потенциал Сети.

Еще совсем недавно мы восхищались архитектурой и потрясающими возможностями параллельных компьютеров ILLIAC IV, Cray-1 и Connection Machine, как им на смену пришли сначала IBM SP-1, Cray T3D и HP V-Class, а затем IBM pSeries 690, Cray X1 и HP Superdome. Если раньше подобные компьютеры ассоциировались лишь с рейтингом Top500, включающим самые мощные компьютеры мира, то сейчас установка многопроцессорного сервера в информационном центре крупной компании не вызывает удивления.
Все первые параллельные вычислительные системы были уникальны: оригинальная архитектура, последние достижения микроэлектроники, специальное программное обеспечение, специализированные сервис и поддержка. Но уникальность означает высокую цену и недоступность. Сегодня ситуация совсем иная. Вычислительный кластер может собрать любая лаборатория, отталкиваясь от своих реальных потребностей в вычислительной мощности и доступного бюджета. Для большого класса задач, где не предполагается тесного взаимодействия между параллельными процессами, решение на основе обычных ПК и сети Fast Ethernet будет вполне эффективным. А чем такое решение принципиально отличается от локальной сети современного предприятия? С точки зрения прикладного программиста — почти ничем. Если у него появится возможность использования подобной конфигурации для решения своих задач, то она и станет параллельным компьютером.
Уникальные возможности дает Internet. Глобальную сеть можно рассматривать как самый большой параллельный компьютер, состоящий из множества компьютеров, своего рода метакомпьютер [1]. В принципе, роль коммуникационной среды метакомпьютера может играть любая сетевая технология. Вместе с тем, к Internet всегда был и будет особый интерес, поскольку никакая отдельная вычислительная система не сравнится по своей мощности с потенциальными возможностями Глобальной сети. Главное — научиться этот потенциал эффективно использовать.
Конструктивные идеи использования распределенных вычислительных ресурсов для решения сложных задач появились относительно недавно. Первые прототипы систем метакомпьютинга стали доступными с середины 90-х годов. Некоторые претендовали на универсальность, часть же была сразу ориентирована на решение конкретных задач; где-то ставка делалась на использование выделенных высокопроизводительных сетей и специальных сетевых протоколов, а где-то за основу брались обычные каналы и протокол HTTP. Например, расширение PACX-MPI поддерживает объединение в метакомпьютер нескольких MPP-систем, возможно, с различными реализациями MPI. Система Condor (www.cs.wisc.edu/condor/) распределяет задачи по существующей корпоративной сети рабочих станций, используя время, когда компьютеры простаивают без нагрузки, например, ночью или в выходные. Проект SETI@home для решения задачи поиска внеземных цивилизаций объединил миллионы компьютеров по всему миру для распределенной обработки поступающих с радиотелескопа данных. Проект GIMPS (Great Internet Mersenne Prime Search, mersenne.org) направлен на поиск простых чисел Мерсена (числа вида 2P-1, где P — простое число). В ноябре 2001 года в рамках данного проекта было найдено максимальное на данное время число Мерсена, содержащее в своей десятичной записи более 4 млн. цифр. Десятки тысяч компьютеров по всему миру, отдавая часть своих вычислительных ресурсов, работали над этой задачей два с половиной года.
Связав различные вычислительные системы, сегодня можно сформировать специальную единую вычислительную среду. Какие-то компьютеры могут подключаться или отключаться, однако с точки зрения пользователя эта виртуальная среда неизменно остается единой. Работая в такой среде, пользователь лишь выдает задание на решение задачи, а остальное метакомпьютер делает сам: компилирует и собирает задание, ищет доступные вычислительные ресурсы, отслеживает их работоспособность, осуществляет передачу данных, если требуется, выполняет преобразование данных в формат компьютера, на котором будет выполняться задача, и т.п. Пользователь может и не узнать, ресурсы какого именно компьютера были ему предоставлены. Если потребовались вычислительные мощности для решения задачи, то подключаемся к метакомпьютеру, формулируем задание и — получаем результат.
Проводя ставшую популярной аналогию между энергетической сетью и метакомпьютером, хотелось бы перенести столь же простой способ использования электричества для решения пользователем своих бытовых задач и на вычислительные среды. Но вот тут-то и возникают основные проблемы, определяемые сложностью организации самого метакомпьютера. В отличие от традиционного компьютера метакомпьютер имеет целый набор присущих только ему особенностей.
- Огромные ресурсы, не сравнимые с ресурсами обычных компьютеров: десятки и сотни тысяч доступных процессоров, колоссальный объем оперативной и внешней памяти, большое число активных приложений, пользователей и т.п. Задумайтесь, как должна быть устроена ваша программа, чтобы эффективно использовать хотя бы часть этих ресурсов? Как должна быть организована сама вычислительная среда, чтобы эффективно управлять столь сложной системой?
- Распределенный характер. Компоненты метакомпьютера могут быть удалены друг от друга на тысячи километров, что неизбежно вызовет большую латентность и, следовательно, скажется на оперативности их взаимодействия.
- Динамичность конфигурации. Состав физических компонентов метакомпьютера постоянно меняется. На системе поддержки работы лежит поиск подходящих ресурсов, проверка их работоспособности, распределение поступающих задач, отслеживание корректного хода их выполнения вне зависимости от текущей конфигурации метакомпьютера в целом.
- Неоднородность. Разные операционные системы, различные системы команд и форматы представления данных, различная загрузка и каналы, принципиально различные архитектуры, начиная с домашних персональных компьютеров и учебных классов и заканчивая мощнейшими векторными, массивно-параллельными и SMP-суперкомпьютерами.
- Объединение ресурсов различных организаций. Политика доступа и использования конкретных ресурсов может сильно меняться в зависимости от их принадлежности к той или иной организации. Метакомпьютер не принадлежит кому-либо одному. Политика его администрирования может быть определена лишь в самых общих чертах; согласованность работы огромного числа составных частей метакомпьютера предполагает обязательную стандартизацию работы всех его служб.
Речь идет не просто об аппаратуре или о программах, а о целой инфраструктуре. В комплексе должны рассматриваться такие вопросы, как средства и модели программирования, распределение и диспетчеризация заданий, технологии организации доступа, интерфейс с пользователями, безопасность, надежность, политика администрирования, средства доступа и технологии распределенного хранения данных, мониторинг состояния различных подсистем и др.
Системы метакомпьютинга — куда идем?
Работы по созданию и апробации систем метакомпьютинга активно идут по трем направлениям. Мы не будем здесь рассматривать проекты наподобие SETI@home или GIMPS, четко направленные на решение конкретных задач и не предоставляющие сколько-нибудь универсальных средств решения других задач.
Первое направление — создание универсальных метакомпьютерных сред. Практически все основные производители (в том числе, IBM, HP и Sun Microsystems) работают в данном направлении. Многие берут в качестве стандарта Globus (www.globus.org), создавая программную инфраструктуру для своих платформ, формируются глобальные полигоны, объединяющие в рамках супервысокоскоростных сетей значительные распределенные ресурсы. Проводятся серии экспериментов, направленные на отработку новых сетевых технологий, методов диспетчеризации и мониторинга в распределенной вычислительной среде, интерфейса с пользователем, моделей и методов программирования.
Потенциал этого направления, безусловно, огромен, но число нерешенных проблем пока перевешивает реальный эффект; впрочем, отдельные элементы универсальных распределенных сред уже удается успешно применять в рамках масштабных проектов, подобных TeraGrid (www.teragrid.org) и European DataGrid (www.eu-datagrid.org).
Второе направление — развитие первого. Здесь универсальность среды заменяет четкая ориентация на конкретные задачи. Речь идет о создании специализированных метакомпьютерных сред для решения предопределенного набора многократно используемых «тяжелых» вычислительных задач (своего рода специализированных вычислительных порталов). Это направление намного проще реализовать на практике, чем первое. Структура задачи, для которой создается среда, заранее понятна, особенности и целесообразность работы задачи на всех видах вычислительных ресурсов среды можно оценить заранее, проблема переноса с платформы на платформу также решается в момент создания среды. С помощью специально спроектированных средств оформляется, скажем, Web-интерфейс к программе, которая предварительно уже подготовлена к выполнению в рамках метакомпьютерной среды. Пользователь не занимается явным программированием; ему нужно лишь задать набор входных данных, формируя, тем самым, запрос на решение задачи, не вникая в детали того, где и как реально программа будет выполнена. Данное направление находит применение в коммерческом секторе: класс задач определен, компьютеры есть на столе практически каждого сотрудника, а проблемы безопасности естественным образом решаются в рамках корпоративной сети. Одним из возможных средств создания подобных сред является система UNICORE.
Третье направление состоит в разработке инструментария для организации распределенных вычислительных экспериментов. Безусловно, универсальная среда — это здорово, но когда она появится? Да и всем ли дадут ей пользоваться? Globus Toolkit — стандарт де-факто, но он слишком тяжел в установке и сложен в использовании. А что делать, если 2 тыс. компьютеров организации могут отдать лишь на ночь или на два выходных дня? А если системные администраторы не хотят устанавливать на свои компьютеры ничего лишнего? Нужен простой инструментарий, который помог бы быстро создать распределенное приложение и использовать доступные вычислительные ресурсы. По этому пути несколько лет назад мы пошли, отрабатывая различные технологии организации и проведения распределенных вычислительных экспериментов.
Основные требования к системе были сформулированы так:
- ориентация на вычислительные задачи;
- работа через Internet, возможность использования всех доступных в Сети вычислительных ресурсов различной мощности;
- минимум дополнительных действий и системного вмешательства на используемых ресурсах;
- масштабируемость системы, устойчивость к неоднородности и изменению конфигурации вычислительной среды;
- простота адаптации прикладных программ.
Созданная система получила название X-Com (meta.parallel.ru). К настоящему времени она прошла апробацию в ряде экспериментов с использованием широкого спектра ресурсов: от простых домашних компьютеров до мощных параллельных вычислительных систем, от использования Internet до работы на выделенном гигабитном полигоне Московского университета.
Доступный метакомпьютинг
|
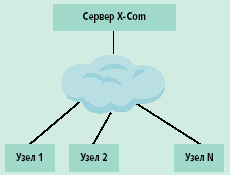
| Рис. 1. Модель функционирования системы X-Com |
X-Com имеет простую структуру, соответствующую модели «ведущий/ведомые». В основе системы лежит клиент-серверная архитектура, в которой можно выделить два базовых компонента (рис.1).
Сервер X-Com — центральная часть системы, отвечающая за разделение исходного набора данных на блоки, распределение заданий между узлами, координацию работы подчиненных узлов, контроль целостности результата расчета, сбор результата в единое целое. Узел X-Com — любая вычислительная единица (рабочая станция, узел кластера, виртуальная машина), на которой происходит расчет прикладной программы. Отдельные блоки входных данных передаются от сервера на узлы, где и происходит расчет, а полученные на узлах результаты передаются обратно на сервер. Узлы отвечают за обработку блоков входных данных, запрос новых заданий для расчета от сервера, передачу результатов расчета на сервер.
Взаимодействие между узлами и сервером в X-Com происходят по протоколу HTTP, что позволяет подключать к системе практически любые вычислительные мощности, имеющие доступ к Сети.
Система не требует специальной настройки для работы через прокси-серверы, межсетевые экраны и другие системы защиты. Данные, передаваемые системой, аналогичны стандартному трафику Сети. Для использования системы в штатном режиме не требуется прав привилегированных пользователей.
|
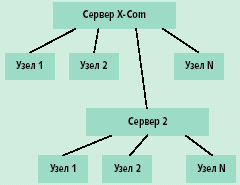
| Рис. 2. Пример реальной организации процесса вычислений средствами X-Com |
Для организации эффективного взаимодействия между сервером и узлами, а также для обеспечения масштабируемости системы при подключении большого числа узлов можно воспользоваться промежуточными серверами. В этом случае система приобретает иерархическую древовидную структуру произвольной вложенности. В листьях дерева всегда расположены вычислительные узлы, в корне находится центральный сервер X-Com. Промежуточные серверы (например, Сервер 2 на рис. 2), с точки зрения центрального сервера выглядят обычными вычислительными узлами, а с точки зрения нижележащих вычислительных узлов — центральным сервером.
Серверы последующих уровней целесообразно вводить, когда коммуникационный канал между ними и центральным сервером нестабилен или обладает малой пропускной способностью, а связь между промежуточным сервером и его узлами устойчива и поддерживается на достаточно высокой скорости. В такой ситуации промежуточный сервер буферизует некоторую порцию заданий для подчиненных ему узлов и результаты их вычислений. Взаимодействие с центральным сервером уже идет не отдельными порциями, а целыми блоками. Более того, без промежуточного сервера разрыв связи на время, сопоставимое со временем расчета порции данных на конечных узлах, привел бы к потере результатов вычислений и необходимости повторной обработки. За счет буферизации подобные эффекты можно обойти.
Заметим, полная архитектура системы X-Com не содержится ни в одном узле дерева и не управляется каким-либо единственным компонентом системы. Это, в частности, позволяет в процессе работы подключать новые узлы или отключать уже работающие без опасения нарушить ход расчета. Никаких помех подобная динамика изменения конфигурации вычислительной среды системе X-Com не создает. Центральный сервер знает, какие порции данных уже обработаны, какие находятся в процессе обработки, а какие пока не трогали вовсе. Если подключился новый узел, ему выдается очередное задание. Если узел отключился, не доведя свою работу до конца, то выданное ему задание перераспределяется между другими узлами. Если от какого-либо узла слишком долго не поступает никакой информации, то узел считается отключившимся, а его работа перераспределяется между другими узлами.
|
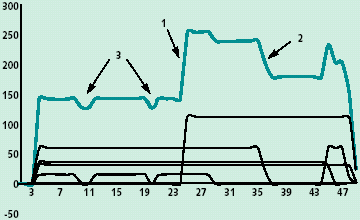
| Рис. 3. Изменение числа процессоров, участвующих в эксперименте. Верхний график отображает общее число процессоров в системе, нижние — по каждой отдельной системе |
На рис. 3 показан график изменения во времени числа работающих процессоров, привлеченных для одного из расчетов. Видно, что общее число процессоров сильно меняется. Резкий подъем, отмеченный на графике (1), связан с подключением к расчету через сутки после его начала вычислительных систем НИВЦ МГУ. Уменьшение (2) вызвано падением канала связи с Уфой. Через несколько часов связь восстановилась, и кластер УГАТУ вновь подключился к работе. Небольшие изменения числа процессоров (3) связаны с особенностью настройки кластера в ИММ УрО РАН: время работы пользовательского процесса ограничивалось 500 минутами. По достижении этой точки процессы X-Com автоматически снимались, после чего их приходилось запускать заново.
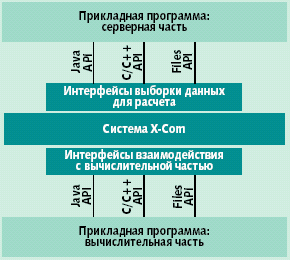
Любая прикладная программа, работающая в рамках системы X-Com, разбивается на две части: серверную и вычислительную (рис. 4). Серверная часть прикладной программы управляет формированием наборов данных для расчета на узлах и может быть реализована на любом языке программирования при условии соответствия одному из трех API системы X-Com. Вычислительная часть представляет собой основной расчетный модуль, который может быть реализован с помощью любой технологии программирования, возможно, не соответствующей технологии серверной части прикладной программы, но с соблюдением правил соответствующих API.
|
| Рис. 4. Взаимодействие прикладной программы с X-Com |
Большие расчеты
Совместно с группой специалистов Центра «Биоинженерия» РАН в распределенном режиме решалась задача определения скрытой периодичности в генетических последовательностях. Основную сложность в данном случае представляли высокая вычислительная сложность алгоритмов и огромный объем входных данных. По самым скромным подсчетам для обработки материала, имеющего реальное научное значение, на одном процессоре потребовалось бы обработать несколько гигабайт входной информации и долгие месяцы непрерывных вычислений. На вход программы подавались описания структуры генетических последовательностей, закодированные стандартным набором символов a-t-g-c, а на выходе появлялась информация о найденных во входных последовательностях повторах тех или иных фрагментов (рис. 5).
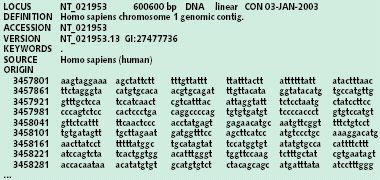
|
| Рис. 5. Пример фрагмента записи генетической последовательности |
Входные данные были взяты из специализированного банка данных — центрального хранилища актуальной информации о генетической структуре различных организмов (ncbi.nih.gov). Во всех расчетах были задействованы географически удаленные вычислительные ресурсы, объединенные с помощью X-Com.
Для решения исходной задачи в среде X-Com все входные последовательности разбивались на порции, содержащие от нескольких десятков до нескольких сотен тысяч символов. Часть порций нарезалась с «перехлестом». В этом случае конец предыдущей порции совпадал с началом последующей, что было необходимо для нахождения повторов в самой зоне разрезания. Количеством символов в порции можно было регулировать объем вычислений, необходимый для ее обработки в разумное время. В проведенных экспериментах время обработки одной порции менялось в пределах нескольких десятков минут. Серверная часть прикладной программы выполняла «нарезку» исходных последовательностей и «сборку» полученных результатов. Для интеграции с системой X-Com использовался Files-API, предполагающий размещение как входных порций, так и результатов расчета в файловой системе центрального сервера X-Com. Для сокращения сетевого трафика выполнялась оперативная компрессия всех передаваемых данных. Вычислительная (клиентская) часть прикладной программы осталась практически без изменений. Общий объем написанного для интеграции с системой X-Com дополнительного кода составил менее 200 строк.
В серии экспериментов одновременно с решением основной прикладной задачи преследовались две дополнительные цели: проверить потенциальные возможности X-Com и определить особенности ее работы при пиковых нагрузках. Остановимся подробнее на двух наиболее интересных экспериментах.
Особенность первого эксперимента — географический размах: 14 удаленных вычислительных систем, принадлежащих 10 организациям, расположенным в 8 городах и 6 различных часовых поясах. В разные моменты данного промежутка времени к эксперименту подключалось 407 процессоров; максимальное число одновременно работающих процессоров составило 385; в среднем по эксперименту эта величина оказалась равной 296. Общее время эксперимента составило около 64 часов. Один средний компьютер справился бы с подобной задачей лишь за два года непрерывной работы. Взаимодействие между компьютерами шло по обычным каналам связи; суммарно было передано 9 Гбайт данных. Максимальная загрузка исходящего канала данных от центрального сервера составила около 7 Мбит/с.
В таблице 1 перечислены вычислительные системы, работавшие в этом эксперименте. Число выполненных каждой системой заданий определялось как их мощностью, так и длительностью участия в эксперименте. Так, кластеры Дубны и Переславля-Залесского работали все время, а системы из Твери и Уфы подключались лишь на несколько часов.
Несмотря на значительную географическую удаленность использованных вычислительных систем, эффективность работы системы в целом (отношение суммарного времени полезных вычислений на узлах к общему времени использования данных узлов в эксперименте) превысила 95%.
Задача второго эксперимента, организованного НИВЦ МГУ и Межведомственным суперкомпьютерным центром, — работа в условиях максимальной неоднородности. В расчете участвовали четыре типа вычислительных ресурсов: отдельные компьютеры, учебный класс, традиционные вычислительные кластеры и суперкомпьютер МВС-1000М (www.jscc.ru). Часть компьютеров работала под управлением Windows, а часть — под Linux (как правило, Red Hat). На части компьютеров использовались процессоры Intel, на остальных — Alpha. Одновременно в эксперименте применялись три различных режима использования ресурсов.
- МОНО - монопольное использование, при котором вычислительная система полностью отдавалась под проведение данного эксперимента.
- ОЧЕР -работа через стандартные системы управления очередями заданий (данный режим не требует менять политику администрирования и использования вычислительной системы при ее подключении и после ее выхода из эксперимента).
- ЗАН - режим "по занятости" позволяет использовать свободные ресурсы вычислительной системы. С помощью специальных алгоритмов система X-Com определяет, что узел в данный момент не используется, и запускает на нем прикладную задачу. Как только любая другая программа на узле проявляет активность, X-Com прерывает работу прикладной задачи.
Эксперимент продолжался 14,5 часов. Среднее число одновременно работающих процессоров составило 125; максимум — 150. Всего к эксперименту подключалось 437 различных процессоров. Казалось бы, слишком много, учитывая среднее число. Но объясняется это очень просто: суперкомпьютер МВС-1000М объединяет 768 процессоров, и система управления заданиями при распределении программы на реальные процессоры не обязана учитывать, куда были распределены предыдущие варианты этой же программы.
Всего за время эксперимента было передано 26,8 Гбайт данных. Время обработки одной порции данных — от 1 секунды до 10 минут. Несмотря на значительную коммуникационную нагрузку и специально созданную неоднородность, эффективность работы всей системы составила 92,9%.
В таблице 2 приводятся характеристики вычислительных систем, режимов их использования и агрегированные данные хода вычислений.
Наиболее эффективно системы используются в монопольном режиме. Небольшие накладные расходы, возникшие при использовании режима «по занятости», во многом объясняются малым изменением вычислительной нагрузки на соответствующих кластерах во время данного эксперимента. Самый большой процент оборванных сеансов оказался при использовании стандартных систем управления очередями. Объясняется это тем, что при постановке в очередь система заказывает для программы некоторое время. После того, как программу распределяют на реальные узлы, она начинает штатную обработку порций данных, продолжая ее до момента, пока не исчерпает свой лимит по времени, после чего всегда происходит разрыв сеанса между узлом и сервером.
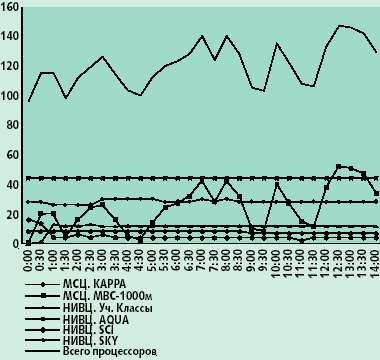
|
| Рис. 6. Изменение числа процессоров в «неоднородном» эксперименте |
На рис. 6 показано, как менялось число задействованных процессоров в целом и в каждой отдельной вычислительной системе по ходу эксперимента. Наибольший вклад в частоту изменения этой величины внес суперкомпьютер МВС-1000М, что вполне объяснимо, учитывая непредсказуемый характер времени постановки наших заданий, сосуществующих вместе с заданиями большого количества других пользователей.
Метакомпьютинг жить будет
Несмотря на кажущуюся вычурность и нереальность создаваемой глобальной вычислительной системы, область применения метакомпьютеров исключительно обширна. Удачных примеров использования идей метакомпьютинга для решения реальных задач уже немало, хотя большинство работ пока уникальны, трудоемки и до массового использования универсальных метакомпьютерных сред еще далеко.
Легко было сказать, опираясь на аналогию с электрической сетью: «Подключайся и используй». На практике же возникает огромное количество действительно серьезных проблем. Часть из них касается вопросов политического и экономического характера. Без решения таких вопросов не обойтись; их обязательно надо учитывать, поскольку масштаб работ по метакомпьютингу выходит на межгосударственный уровень.
Тем не менее, у метакомпьютинга большое будущее. Во многих областях объединение вычислительных ресурсов даст превосходный результат, предоставляя простое, экономичное и доступное средство для решения многих задач. Дело за малым — нужны активные исследования в данной области, эксперименты, опыт. Необходимо объединение усилий и исследователей, и организаций. Тем более что объединение и метакомпьютинг — очень близкие понятия.
Работа выполняется при поддержке РФФИ, гранты N 02-07-92000, 02-07-90442.
Литература
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. // СПб.: БХВ-Петербург, 2002.
Владимир Воеводин (voevodin@parallel.ru) — заместитель директора НИВЦ МГУ, Максим Филамофитский (maxim@rbc.ru) — технический директор компании «Росбизнесконсалтинг».
