


История языков параллельного программирования насчитывает не один десяток лет. Придуманы и апробированы разнообразные способы написания программ, которые условно можно разделить на три группы.
- Последовательное программирование с дальнейшим автоматическим распараллеливанием.
- Непосредственное формирование потоков параллельного управления, с учетом особенностей архитектур параллельных вычислительных систем или операционных систем. Зачастую используется расширение традиционных последовательных языков операторами распараллеливания и синхронизации. Уровень параллелизма полностью контролируется разработчиком и может меняться в зависимости от конкретных условий.
- Описание параллелизма без использования явного управления обеспечивается заданием только информационных связей. Предполагается, что программа будет выполняться на вычислительных системах с бесконечными ресурсами, операторы будут запускаться немедленно по готовности их исходных данных.
Последовательное программирование выглядит весьма привлекательным, поскольку, на первый взгляд, позволяет: применять опыт, накопленный в течение многолетней эксплуатации вычислительных машин с традиционной архитектурой; использовать продукты, разрабатываемые десятилетиями; разрабатывать программы, не зависящие от особенностей параллельной вычислительной системы или ОС; не заботиться о параллельной организации программ, полагаясь на системы автоматического распараллеливания, решающие все вопросы по эффективному переносу программ на любую параллельную вычислительную систему. В свое время этот подход достаточно широко и разносторонне исследовался, однако многие из возлагавшихся на него надежд не оправдались. Сейчас он практически не используется в промышленном программировании, так как обладает следующими недостатками:
- распараллеливание последовательных программ очень редко обеспечивает достижение приемлемого уровня параллелизма из-за ограничений вычислительного метода, выбранного для построения соответствующей программы, что часто обуславливается стереотипами последовательного мышления;
- в реальной ситуации учесть особенности различных параллельных систем гораздо труднее, чем это изначально предполагалось.
Помимо этого, современные программы уже трудно считать последовательными. Повсеместно используются процессы, нити и прочие атрибуты параллельного программирования, предоставляемые операционными системами. Сами программы выполняются в многозадачном режиме, распределяются по клиентским и серверным компьютерам и т. д.
Практически во все времена в параллельном программировании наиболее популярными были подходы, учитывающие особенности параллельных вычислительных систем. При этом наряду с языками, применяются библиотечные средства поддержки параллельных процессов, реализованные на уровне операционных систем или специализированных пакетов. Несомненным достоинством здесь является максимальное использование возможностей конкретной архитектуры — программист, опираясь на знание специфической системы, потенциально может весьма эффективно распределять задачу. Параллельное программирование для конкретных архитектур широко использовалось в конце 70-х — начале 80-х годов. Были разработаны десятки вычислительных систем, значительно отличающихся друг от друга.
В дальнейшем развитие технологии создания однокристальных микропроцессоров привело к резкому снижению эффективности подобных разработок и к нецелесообразности построения нетрадиционных архитектур. Произошел переход к высокопроизводительным системам на основе стандартных аппаратных средств: симметричная многопроцессорность (SMP), кластеры, массовый параллелизм (MPP) и т.д. Это позволило унифицировать методы параллельного программирования, увязав их с семействами архитектур. Появились переносимые инструментальные средства и пакеты, позволяющие выполнять одни и те же программы на вычислительных системах, имеющих разные системы команд, управляемые различными операционными системами. К подобным программным системам следует отнести MPI (ориентация на передачу сообщений в системах с распределенной памятью [1]) и PVM (ориентация на параллельное программирование для систем с общей памятью [2]). Наряду с пакетами, обобщающими семейства архитектур, появились средства, обеспечивающие прозрачную поддержку кластерных вычислений для наиболее популярных операционных систем. К ним следует отнести систему Mosix [3], которая после компиляции с ядром Unix-подобных ОС обеспечивает миграцию по узлам кластера процессов, построенных с использованием стандартных методов их порождения (системный вызов fork).
Вместе с тем, использование явного управления вычислениями обладает рядом недостатков:
- программист сам должен формировать все параллельные фрагменты и следить за корректной синхронизацией процессов;
- использование в языках такого типа "ручного" управления памятью может привести к конфликтам между процессами в борьбе за общий ресурс (программисту самому приходится тщательно следить за распределением памяти);
- программы жестко привязаны к конкретной архитектуре или к семейству архитектур (смена поколений вычислительных систем или появление новых ведут к необходимости переработки накопленного программного обеспечения).
В этой связи неудивительно, что для достижения мобильности параллельных программ, написанных с использованием явного управления, постоянно разрабатывались соответствующие средства, направленные на преодоление трудностей, не существовавших при последовательном программировании.
В последовательных программах управление вычислениями реализовано достаточно просто и легко может быть преобразовано к другим формам. Методы построения параллельных программ ведут к дополнительным проблемам, возникающим при анализе потоков управления.
Наряду с более сложным управлением параллельные программы различного вида имеют и специфические механизмы, обеспечивающие разрешение конфликтов при доступе к общим ресурсам. Выявление этих механизмов и замена их соответствующими эквивалентами также затрудняет трансформацию одних параллельных программ в другие.
Существует еще более жесткая связь между используемыми вычислительными методами и структурой программы, что, в свою очередь, еще сильнее осложняет процесс переноса параллельной программы с одной архитектуры на другую.
Для достижения высокой эффективности необходим разумный баланс между параллелизмом и последовательными фрагментами: система должна учитывать особенности реализации и производительность отдельных подсистем конкретной архитектуры и, в соответствии с этим, ориентироваться на распараллеливание вычислений или наоборот, последовательную реализацию этих же фрагментов программы.
Мобильность и неявное управление
Разработка переносимых параллельных программ возможна только в том случае, если язык программирования позволяет скрыть механизмы управления вычислениями, специфичные для конкретных архитектур. Особенности обычно проявляются в явном управлении различными ресурсами. Дополнительные «шумы» вносятся управлением последовательностью вычислений по собственному усмотрению. Для того чтобы «избавить» программиста от подобных возможностей, были предложены языки с неявным описанием параллелизма, предусматривающие указание только информационной взаимосвязи между функциями, осуществляющими преобразование данных. Использование таких языков позволяет создавать программы, поддерживающие параллелизм на уровне операций, ограниченный лишь методом решения задачи; обеспечивать перенос на конкретную архитектуру, не распараллеливая программу, а сжимая ее максимальный параллелизм; проводить оптимизацию программы по множеству параметров с учетом архитектуры параллельной вычислительной системы, для которой осуществляется трансляция. Работы в этой области условно можно разделить на два направления: языки и методы функционального программирования; методы управления вычислениями по готовности данных.
Функциональное программирование
Функциональное программирование, имеющее давнюю историю, определяется как «способ построения программ, в которых единственным действием является вызов функции, единственным способом расчленения программы на части является введение имени для функции и задание для этого имени выражения, вычисляющего значение функции, а единственным правилом композиции — оператор суперпозиции функции» [4]. Среди первых языков, обеспечивших поддержку ограниченного параллелизма, был FP [5], возможность писать параллеллельные программы реализована в одной из версий Haskell (www.haskell.org). Параллелизм существующих функциональных языков ограничен рядом общих факторов.
- Набор базовых операций и структур данных изначально ориентирован на поддержку последовательных вычислений. Так, списки состоят из "головы" и "хвоста", что требует рекурсивной развертки и затрудняет одновременную обработку всех элементов. Поэтому последующие расширения таких языков могут служить только надстройкой, не поддерживающей параллелизм на уровне отдельных операций.
- Включение механизмов поддержки параллелизма во время создания ряда функциональных языков осуществлялось без полного анализа всех возможных вариантов. Как результат этим языкам присущи только ограниченные формы организации параллельных вычислений.
- Ограничения накладываются и синтаксисом языков. В некоторых из них просто отсутствует возможность описать параллелизм, присущий задаче.
Управление по готовности данных
Для того чтобы язык программирования мог обеспечить формирование параллелизма любого типа, он должен на уровне элементарных операций содержать механизмы размножения информационных потоков, их группирования в списки данных различного уровня вложенности, одновременного выделения из списков нескольких независимых и разнородных по составу групп. Обычно такие возможности заложены в потоковых моделях вычислений и языках, построенных на их основе.
Известны различные модели вычислений, поддерживающие управление по готовности данных [6]. В каждый из этих подходов заложен определенный метод порождения и синхронизации параллельных процессов. Однако в некоторых случаях реализованная модель вычислений не позволяет обеспечить максимальный параллелизм из-за ограничений, присущих отдельным механизмам организации параллельных вычислений. Эти проблемы решаются введением модели «идеального» вычислителя, обладающего бесконечными ресурсами, мгновенно выделяемыми по первому требованию для выполнения любой операции и хранения любых промежуточных данных.
Пути решения проблемы
Отсутствие практического интереса к созданию «идеальных» систем, обеспечивающих разработку переносимых параллельных программ, во многом обуславливается семантическим разрывом между методами написания программ, которые должны использовать параллелизм на уровне операций, и современными техническими средствами, обеспечивающими реальную поддержку только крупноблочного распараллеливания. Эффективнее и проще осуществлять кодирование, непосредственно поддерживающее архитектурно зависимые методы.
Вместе с тем, исследования в области создания переносимых параллельных программ представляют интерес, так как, в перспективе позволяют избежать переписывания кода при изменении архитектур вычислительных систем. Усилия должны быть направлены на создание языка, который не является основой машинной архитектуры, а предназначен для решения следующих задач:
- исследования и разработки систем программирования, обеспечивающих написание программ, не зависящих от архитектур конкретных параллельных вычислительных систем;
- создания методов преобразования архитектурно независимых параллельных программ в архитектурно зависимые;
- разработки промежуточных интерпретирующих средств, позволяющих выполнять архитектурно независимые программы на реальных системах.
Отсутствие средств, обеспечивающих решение этих задач, привело авторов к разработке функционального языка «Пифагор» (http://www.softcraft.ru/parallel.shtml), позволяющего распараллеливать программы на уровне операций, имеющего архитектурную независимость, достигаемую за счет описания только информационных связей, обладающего асинхронным параллелизмом, полученным путем выполнения операций по готовности данных. В языке отсутствуют переменные, что позволяет избежать конфликтов, связанных с совместным использованием памяти параллельными процессами.
Модель вычислений языка «Пифагор»
Особенности языка во многом определяются используемой моделью управления вычислениями. Именно она определяет подход к построению переносимых программ. Программа задается информационным графом, определяющим потоки передачи данных между вершинами - операторами. Операторы обеспечивают преобразования данных, их структуризацию и размножение. Предусмотрены следующие типы вершин: оператор интерпретации; константный оператор; оператор копирования данных; оператор группировки в список; оператор группировки в параллельный список; оператор группировки в список задержанных вычислений.
Динамика выполнения операторов задается механизмом продвижения начальной разметки графа по дугам модели. Она определяет обработку исходных данных, получение результатов и их использование в дальнейших вычислениях. Моделирование вычислительного процесса осуществляется в соответствии с рядом правил.
- Если все входные дуги вершины имеют разметку (исходные данные), то на выходных дугах происходит формирование разметки (результата) в соответствии с правилами срабатывания, определяемые оператором.
- Если входные разметки имеют кратность, превышающую единицу (одновременно сформировано несколько независимых наборов данных), то для заданной вершины формирование выходной разметки может начинаться при неполной входной разметке независимо для каждого из сформированных наборов входных данных, и осуществляется в соответствии с аксиомами срабатывания операторов.
- В процессе распространения разметка не убирается и не замещается. Каждая дуга графа может получить разметку только один раз. Из требования о недопустимости повторной разметки вытекает требование ацикличности информационного графа.
- Процесс распространения разметки заканчивается, когда все дуги графа имеют полную разметку в соответствии с предписанной кратностью или при невозможности распространения разметки.
Поддержка разметкой дуги нескольких независимых наборов данных позволяет описывать на уровне модели вычислений массовый параллелизм. При этом инициализация вычислений в вершине может начинаться до формирования полной разметки, так как обработка каждого из входных наборов осуществляется независимо.
Каждый из операторов модели обладает своими свойствами.
Оператор интерпретации описывает функциональное преобразование аргумента и имеет два входа, на которые через информационные дуги поступают функция F и аргумент X (рис. 1).
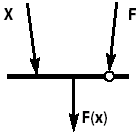 |
| Рис. 1. Оператор интерпретации с входами аргумента X и функции F |
Аргумент и функция могут быть результатами предшествующих вычислений. Оператор запускается по готовности данных. Получение результата задается разметкой выходной дуги. При текстовом описании оператор интерпретации имеет две формы: постфиксную, обозначаемую знаком «:», и префиксную, при которой функция отделяется от аргумента знаком «^». Наличие двух способов записи позволяет в дальнейшем комбинировать их для получения более наглядного текста программы. Выражение F(X) оператор интерпретации задает как X:F или F^X.
 |
| Рис. 2. Константный оператор |
Константный оператор не имеет входов (рис. 2). У него есть только выход, на котором постоянно находится разметка, определяющая значение константы. В языковом представлении константный оператор задается величиной предопределенного типа или константным выражением.
 |
| Рис. 3. Оператор копирования данных |
Оператор копирования осуществляет передачу данных с единственного входа на множество выходов. В текстовой форме копирование определяется через именование передаваемой величины и дальнейшее использование введенного обозначения. Используется постфиксное именование размножаемого объекта в форме: величина >> имя, и его префиксный эквивалент, имеющий вид: имя << величина. Например: y << F^x; (x, y):+ >> c. В графическом представлении (рис. 3) передача фиксируется установкой разметки на дугах, связанных с выходами вершины при размеченной входной дуге.
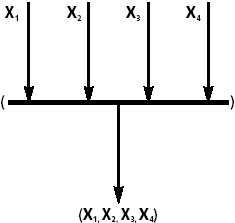 |
| Рис. 4. Оператор группировки в список |
Оператор группировки в список (рис. 4) имеет несколько входов и один выход. Он обеспечивает структуризацию и упорядочение данных, поступающих по дугам из различных источников. Порядок элементов определяется номерами входов, каждому из которых соответствует натуральное число в диапазоне от 1 до N.
В текстовом виде оператор задается ограничением элементов списка круглыми скобками. Нумерация элементов списка в данном случае задается неявно в соответствии с порядком их следования слева направо; это соглашение действует и в графическом представлении при отсутствии явной нумерации входов.
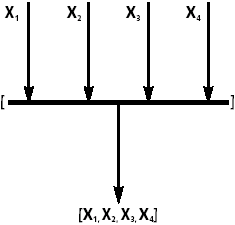 |
| Рис. 5. Оператор создания параллельного списка |
Оператор создания параллельного списка (рис. 5) обеспечивает группирование элементов, аналогичное списку данных. В текстовом виде группировка в параллельный список задается ограничением его элементов квадратными скобками. Кратность разметки, определяющая выходной набор данных равна сумме кратностей разметок всех входных дуг. Считается, что функция использует каждый элемент данного списка как независимый аргумент:
[x1,x2,...,xn]:f = [x1:f,x2:f,...,xn:f]
Если же параллельный список определяет набор функций, то все они выполняются одновременно над одним и тем же аргументом:
X:[f1,f2,...,fn] = [X:f1,X:f2,...,X:fn]
Оператор группировки в задержанный список задается вершиной, содержащей допустимый вычисляемый подграф, в котором возможно несколько входов и выходов. Входы связаны с дугами, определяющими поступление аргументов, а выходы определяют выдаваемый из подграфа результат (рис. 6). Спецификой такой группировки является то, что ограниченные оператором вершины (на графе ограничение задается контуром), представляющие другие операторы, не могут выполняться, даже при наличии всех аргументов. Их активизация возможна только при снятии задержки (раскрытие контура), когда ограниченный подграф становится частью всего вычисляемого графа.
 |
| Рис. 6. Список задержанных вычислений |
Первоначально задержанный подграф создает на своем единственном выходе константную разметку, которая является его образом. Эта разметка распространяется по дугам графа от одного оператора к другому, размножаясь, входя в различные списки и выделяясь из них до тех пор, пока не поступит на один из входов оператора интерпретации. При наличии на его обоих входах готовых данных происходит подстановка, вместо образа, самого задержанного графа с сохранением его входных связей. Опоясывающий контур при этом «убирается», и происходит выполнение активированных операторов. В результате на выходной дуге раскрытого подграфа вновь формируется результирующая разметка, которая и является одним из окончательных операндов оператора интерпретации. Данная процедура называется раскрытием задержанного подграфа. В текстовом виде группирование в список задержанных вычислений (для краткости будем называть его также «задержанным списком») задается охватом соответствующих операторов фигурными скобками. Его раскрытие ведет к образованию параллельного списка. Наличие этой конструкции позволяет откладывать момент начала некоторых вычислений или вообще не начинать их, что используется при организации выборочной обработки данных.
Наряду с особенностями, присущими различным операторам, следует остановиться на использовании оператора интерпретации. Он обеспечивает преобразование аргумента X, в результат Y, в соответствии с функцией F. В постфиксной нотации, выбранной для дальнейших иллюстраций, данное преобразование записывается так: X:F => Y.
Множество унарных функций F полезно разделить на два подмножества: F = {f1, f2}, где f1 — множество предопределенных функций языка, для каждой из которых аксиоматически задаются области определения и изменения, а f2 — множество функций, порождаемых при программировании. Следует отметить: выбор базового набора предопределенных функций осуществлен до некоторой степени субъективно, из соображений удобства. Введены арифметические функции, функции сравнения и прочие, аналогично тому, как это сделано и в других языках программирования. Например, функция сложения двух чисел x1, x2 задается так: (x1, x2):+, где первый аргумент оператора интерпретации является двухэлементным списком данных. Каждый элемент этого списка должен быть числом. Второй аргумент оператора интерпретации является функцией сложения, обозначенной значком «+». Результат функции является атомарным элементом.
Основные приемы функционально-параллельного программирования
Использование параллельных списков
Отсутствие операторов цикла в функциональных языках ведет к использованию рекурсии. В ряде случаев ее можно избежать, если алгоритм задачи предусматривает выполнение одной функции или списка функций над списком независимых аргументов. Тогда можно воспользоваться механизмом параллельных списков.
Параллельный список обеспечивает одновременное выполнение одной операции над всеми его элементами. Рассмотрим пример скалярного произведения двух векторов одинаковой длины. Аргументом функции ScalMultVec является двухэлементный список данных: W=((x1, x2, ... xn), (y1, y2, ... yn)). Функциональная программа будет организована следующим образом:
ScalMultVec << funcdef W { (W:#:[]:*) >> return }
Двухэлементный список W, состоящий из двух векторов, транспонируется (операция «#»), образуя множество пар (xi, yi). Следующая затем операция «[]» создает параллельный список пар, над которыми одновременно выполняется операция умножения «*». Результат, оказывается размещенным внутри круглых скобок, определяющих сформированный вектор. Его обозначение ключевым словом return ассоциируется с выдачей из функции. Пример:
((3, 5), (-4, 2)): ScalMultVec => (-12, 10)
Функции тоже могут задаваться параллельным списком, определяя тем самым множество потоков функций над одним потоком данных. Следующий пример иллюстрирует одновременное нахождение суммы, разности, произведения и частного двух чисел:
ParAddSumMultDiv << funcdef Param {(Param:[+,-,*,/]) >>return }
Результатом вычислений является четырехэлементный вектор, полученный применением разных операций к одному и тому же двухэлементному числовому списку, например:
(3, 5): ParAddSumMultDiv => (8, -2, 15, 6.000000e-001).
Использование задержанных списков
Для программирования вычислительных алгоритмов, предусматривающих ветвление, применяются задержанные списки с последующим выбором и раскрытием элемента, соответствующего дальнейшим вычислениям. Рассмотрим пример функции, находящей абсолютное значение скалярного аргумента:
Abs << funcdef Param {
({Param:-}, Param):
[(Param,0):(<,=>):?]:. >>return
};
Осуществляется одновременное сравнение аргумента с нулем на «меньше» и «больше или равно». Размещение этих операций внутри круглых скобок позволяет получить список данных из двух булевских величин. Операция «?» обеспечивает формирование параллельного списка, состоящего из порядковых номеров элементов, имеющих истинное значение. В данной ситуации возможен только один вариант. Полученное значение используется для выбора одного из элементов списка. Использование задержанного списка позволяет предотваратить немедленное вычисление унарного минуса. Оно произойдет только в том случае, если проверяемый параметр окажется отрицательным числом. Задержка второй альтернативы не нужна, так как параметр представлен уже сформированным значением. Функция «.» используется в качестве пустой операции. Она «раскрывает» задержанные списки и пропускает без изменения прочие аргументы. Рассмотрим выполнение программы при обработке отрицательного аргумента, равного -5.
({-5:-}, -5):[(-5,0)(<,>=):?]:.
=> ({-5:-}, -5):[(true,false):?]:.
=> ({-5:-}, -5):[1]:.
=> {-5:-}:. => -5:- => 5
При положительном аргументе, например, равном 3, результат будет получаться иначе.
({3:-}, 3):[(3,0)(<,>=):?]:.
=> ({3:-}, 3):[(false,true):?]:.
=> ({3:-}, 3):[2]:.
=> 3:. => 3
Использование параллельной рекурсии
Если вычислительный алгоритм предусматривает древовидное или рекуррентное использование функции для множества однотипных аргументов, число которых может быть произвольным (например, суммирование всех элементов вектора), то применяется параллельная рекурсивная декомпозиция списка аргументов, на самом нижнем уровне которой выполняется операция над одноэлементными или двухэлементными списками, полученными в результате разложения. После этого следует обратный ход со сверткой возвращаемых результатов. Рассмотрим вычисление суммы элементов числового вектора произвольной длины.
VecSum << funcdef Param { // 1
// Формат аргумента: (x1,... ,xn), где x1,... ,xn - числа 2
Len<]):?]^ // 4
( // 5
{Param:[]}, // 6
{Param:+}, // 7
{ // 8
block { // 9
OddVec << Param:[(1,Len,2):..]; // 10
EvenVec << Param:[(2,Len,2):..]; // 11
([OddVec,EvenVec]: VecSum):+ // 12
>>break // 13
} // конец блока 14
} // конец задержанного списка 15
) // 16
} // 17
В строке 3 определяется длина вектора (функция «|»), что позволяет в дальнейшем выбрать один из трех вариантов вычислений. При одноэлементном векторе возвращается значение атома, размещенного в списке (строка 6). Для двух элементов в списке (строка 7) осуществляется их суммирование. При большей длине (строки 9-12) происходит разбиение вектора на два (состоящих из четных и нечетных элементов), для каждого из которых одновременно осуществляется рекурсивный вызов функции VecSum, и суммирование возвращаемых результатов (строка 12). Строка 4, записанная в префиксной форме, обеспечивает проверку длины, селекцию одного из вариантов, раскрытие задержанного списка и возврат результата. Конструкция block используется для группировки операторов. Пример выполнения:
(-3, 6, 10, 25, 0): VecSum => 38
Наряду с представленными возможностями допустимо использование функций в качестве аргументов, динамический контроль типов данных, перегрузка функций с одинаковой сигнатурой. Последнее обеспечивает эволюционное расширение программы без изменения уже написанного кода. Поддерживаются типы, динамически порождаемые пользователем.
Преобразования функциональных программ
Использование функционального языка изменяет не только стиль программирования, но и облегчает различные эквивалентные преобразования, что позволяет настраивать программу под конкретную архитекуру. В качестве примера рассмотрим векторное произведение, которое в последовательном программировании можно описать следующим псевдокодом:
c := 0;
для i от 1 до N выполнить c := c + A[i]*B[i];
Предполагается, что A и B - векторы длины N, c - скаляр.
Даже такой простой код реализуется совершенно по-иному в различных параллельных системах. Например, векторная ЭВМ осуществляет попарное перемножение элементов в конвейерном умножителе и их непосредственную передачу на сложение в конвейерный сумматор. Кластерная система на основе MPI обычно использует распределение векторов по всем узлам с последующим раздельным перемножением и суммированием подвекторов. Окончательное суммирование осуществляется на одном из узлов кластера. В связи с тем, что автоматическое распараллеливание возможно только в простейших случаях и для узкого круга архитектур, программистам каждый раз приходится перерабатывать программу. Ситуация еще больше усугубляется при увеличении сложности задачи. В [1] показано, что при использовании только MPI, достаточно простая задача перемножения двух прямоугольных матриц может быть запрограммированна несколькими способами, эффективность применения каждого из которых зависит от размерности задачи и параметров подсистем кластера.
Ипользование функционального языка позволяет в большей степени сосредоточиться на проблемах конструирования каркаса программы, который может быть адаптирован к требованиям архитектуры путем дальнейших преобразований. Сама программа является предметом дальнейших исследований и преобразований. Например, векторное произведение первоначально может быть записано в виде следующей программы (с использованием уже представленных функций):
VecMult<< funcdef x {x:ScalMultVec:VecSum >>return}
В последующем возможны изменения этой программы с учетом эквивалентной реализации некоторых операций. В частности, параллельное суммирование VecSum можно заменить на последовательный аналог SeqVecSum, написанный следующим образом:
SeqVecSum << funcdef Param {
// Формат аргумента: (x1,... ,xn), где x1,... ,
xn - числа
Len<< Param:|;
return<< .^[((Len,2):[<,>=]):?]^
(
{Param:[]},
{(Param:1, Param:-1:SeqVecSum):+} //
голова+Сумма(хвост)
)
}
Эквивалентные реализации одних и тех же функций можно связать с методами их выполнения на различных архитектурах. Это позволит осуществить автоматические подмены в процессе адаптации исходной программы перед генерацией окончательного кода. Использование функций высших порядков позволяет создавать не конкретные вычислительные процедуры, а обобщенные операции, определяющие принципы формирования вычислений для различных функций. Например, параллельное суммирование элементов вектора VecSum может рассматриваться как конкретная реализация бинарной древовидной свертки. Последовательное суммирование SeqVecSum - это пример правой свертки.
Инструментальные средства
Использование языка для построения параллельных программ требует адекватного инструментария: транслятора, последовательного интерпретатора с возможностью пошагового выполнения, интегрированной среды. При создании такого инструментария всегда надо помнить о необходимости поддержки реального, а не виртуального параллелизма. Среди существующих средств, обеспечивающих поддержку кластерных и распределенных вычислений, можно отметить систему динамического распараллеливания Mosix [3] и библиотеку MPI [1]. Обе поддерживают распараллеливание на уровне процессов, но при этом имеют свои характеристики, влияющие на реализацию параллельного интерпретатора. Например, в языке «Пифагор» требуется, чтобы исполнительная система эффективно и, по возможности, автоматически поддерживала видимость бесконечных ресурсов, обеспечивая при этом реальное сжатие параллелизма с учетом существующих ограничений.
При решении подобных задач вряд ли имеет смысл ориентироваться на системы статического распараллеливания. Несмотря на эффективность «жесткого планирования», они мало подходят для решения задач, в которых параллелизм описывается динамически. Поэтому для реализации интерпретатора была выбрана система Mosix, обеспечивающая автоматическое распределение процессов по узлам кластера. Порождение процессов осуществляется стандартными средствами ОС Linux, что позволяет запускать интерпретатор как на кластере, так и на однопроцессорных системах, не использующих данный пакет.
Следует учесть, что поддержка параллелизма на уровне отдельных операций не обеспечивает эффективного выполнения функциональных программ, поскольку время создания параллельного процесса для элементарных операций будет много больше времени ее обычного последовательного выполнения. Для повышения производительности требуется реализовать автоматическое ограничение числа порождаемых процессов с учетом особенностей кластерной системы.
- Распараллеливание может быть установлено на уровне независимых наборов данных, которые должны быть параллельными списками. Функция, осуществляющая обработку этих данных, не должна быть предопределенной.
- Распараллеливание проводится на уровне функций. Они должны быть представлены в виде параллельных списков, и не являться предопределенными.
Еще одним фактором, влияющим на выполнение функциональных программ, является глубина распараллеливания рекурсивных функций. Параллельная рекурсия будет эффективна в том случае, если число процессов, порожденных в ходе интерпретации, не будут превышать количества узлов кластера, а время выполнения каждого из этих процессов будет больше времени миграции порожденного процесса на свободный узел кластера. Параметр, ограничивающий глубину распараллеливания, может накладывать дополнительные ограничения на уровень распараллеливания.
Опциональный ввод параметров, ограничивающих распараллеливание и глубину параллельного выполнения рекурсивных функций до определенного уровня, позволяет дополнительно настраивать интерпретатор на основе информации, полученной в ходе анализа алгоритма решаемой задачи и текущей архитектуры кластера. Использование специального языка, опирающегося на функциональную модель параллельных вычислений, на наш взгляд, является основным фактором, необходимым для переноса параллельных программ на различные архитектуры.
- Корнеев В.Д. Параллельное программирование в MPI. - Новосибирск: Изд-во СО РАН, 2000.
- Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. - СПб.: БХВ-Петербург, 2002.
- Barak A., La'adan O. The MOSIX Multicomputer Operating System for High Performance Cluster Computing. Journal of Future Generation Computer System, 1998, 13.
- Хендерсон П. Функциональное программирование. Пер. с англ. - М.: Мир, 1983.
- Backus J. Can Programming Be Liberated from von Neuman Style? A Functional Stile and Its Algebra of Programs. Communications of ACM. 1978, v. 21, No. 8.
- Алгоритмы, математическое обеспечение и проектирование архитектур, многопроцессорных вычислительных систем. Под ред. А.П. Ершова. - М: Наука, 1982.
Александр Легалов (lai@fivt.krasn.ru) — доцент кафедры нейроЭВМ Красноярского государственного технического университета, Дмитрий Кузьмин - старший преподаватель кафедры вычислительной техники Красноярского государственного технического университета, Федор Казаков — старший преподаватель кафедры нейроЭВМ Красноярского государственного технического университета, Денис Привалихин — аспирант Красноярского государственного технического университета.
Mosix
Система Mosix обеспечивает автоматическое перемещение процессов между рабочими станциями кластера. Она расширяет ядро Linux механизмами миграции и предоставляет комплект управляющих утилит, предназначенных для настройки системы распределения процессов, а также для отладки и контроля.
Особенностью Mosix является отсутствие централизованного управления — каждый узел кластера может работать как автономная система и самостоятельно управлять вычислительными процессами. Это позволяет динамически конфигурировать кластер, наращивая или сокращая количество узлов без остановки системы. При необходимости Mosix допускает использование статического управления, что позволяет накладывать явные ограничения для достижения максимальной эффективности конкретной кластерной архитектуры.
В отличие от таких пакетов, как MPI или PVM, фиксирующих процессы в конкретных узлах кластера, Mosix обеспечивает их прозрачную динамическую миграцию. При этом MPI и PVM могут использоваться совместно с Mosix.
