

Статья описывает архитектуру и структуру системных компонентов Intel 870, спроектированных по принципу строительных блоков с целью создания недорогих масштабируемых многопроцессорных систем.
Серверные системы предприятий становятся все более разнородными. Сегментация серверных платформ приводит к появлению большого количества наборов микросхем. Одни производители разрабатывают специальные наборы микросхем с разными системными архитектурами для того, чтобы удовлетворить требования различных видов серверов, или используют стандартные для отрасли компоненты, необходимые при создании систем младшего класса, а также проектируют свои собственные компоненты для систем среднего и старшего класса [1-6]. Другие — разрабатывают компоненты, которые масштабируются от небольших до очень крупных систем [7]. Второй подход предполагает дополнительные затраты для серверов младшего класса, а первый — дополнительные затраты на разработку, производство и другие накладные расходы.
Архитектура и конфигурации
Набор микросхем 870 поддерживает два различных класса архитектуры многопроцессорных систем с разделяемой памятью.
- Архитектура с разделяемой памятью на единой шине для систем, имеющих от 2 до 4 процессоров (рис. 1).
- Архитектура с распределенной разделяемой памятью для систем, имеющих от 4 до 16 процессоров.
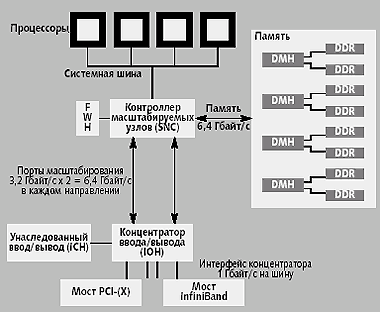
|
| Рис. 1. Конфигурация с четырьмя процессорами |
Первая архитектура обеспечивает высокую производительность, стоит недорого и прекрасно подходит для сервера младшего класса. Процессоры имеют свой собственный кэш, и для контроля доступа к памяти по шине используют интерфейсный модуль внутренней шины. По этой причине протоколы согласования кэшей, применяемые в этих системах, часто называют отслеживающими, или snoop-протоколами [11].
В системной конфигурации (рис. 1) двумя основными компонентами набора микросхем 870 являются контроллер масштабируемых узлов (Scalable Node Controller, SNC) и концентратор ввода/вывода (I/O Hub, IOH).
SNC поддерживает от одного до четырех процессоров и взаимодействует непосредственно с системной шиной (Front Side Bus) процессоров. Контроллер основной памяти в SNC поддерживает четыре канала доступа к памяти. Концентратор памяти DDR (DDR Memory Hub, DMH) на каждом из каналов управляет восемью DDR DIMM. SNC также взаимодействует с концентратором встроенных программ (Firmware Hub, FWH), который служит в качестве загрузочной памяти.
SNC подключен к IOH через два порта масштабирования (Scalability Port, SP). Каждый SP предоставляет полосу пропускания 3,2 Гбайт/с в каждом из направлений. IOH поддерживает четыре интерфейса концентратора для связи с мостами PCI/PCI-X или мостами InfiniBand. Для поддержки унаследованных устройство ввода/вывода используется сокращенная версия интерфейса концентратора.
Данная конфигурация набора микросхем 870 ограничена по полосе пропускания и лимитирована электрическими возможностями системной шины процессоров. Некоторые традиционные системы позволяют подключать к одной шине значительное число процессоров [12, 13]. Однако этот подход не приемлем для высокопроизводительных компьютеров. Для того чтобы число процессоров было больше четырех, архитектура 870 использует многоузловую схему, в рамках которой кластеры из четырех процессоров взаимосвязаны с компонентами коммутатора портов масштабирования (Scalability Port Switch, SPS), как показано на рис. 2 для 16-процессорной конфигурации.
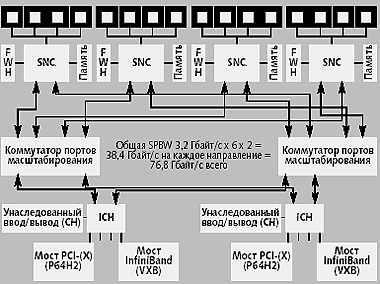
|
| Рис. 2. Конфигурация с 16 процессорами |
SPS обеспечивает взаимосвязь и поддержку согласованности для встроенных многоузловых многопроцессорных систем. Он имеет шесть интерфейсов SP для взаимосвязи SNC и компонентов IOH.
В многоузловых конфигурациях память физически распределена между узлами, но для всех процессоров она представляется как единое физическое пространство. Многоузловые системы 870 обеспечивают простоту парадигмы программирования для архитектур разделяемой памяти.
Архитектуры с распределенной памятью могут значительно отличаться по длительности задержки при доступе к локальной и удаленной памяти, причем иногда на порядок. Соотношение между задержкой при удаленном и локальном доступе в многоузловой конфигурации 870 равно примерно 2,2, что не требует такой оптимизации программного обеспечения для увеличения производительности. Механизм HotPage в 870, который будет описан ниже, стимулирует подобную оптимизацию программного обеспечения с тем, чтобы средняя задержка при доступе к памяти в крупных системах была ближе к уровню задержки при обращении к локальной памяти.
Протокол SP ориентирован на поддержку масштабирования, и он позволяет системным производителям проектировать специализированные компоненты коммутатора для создания крупномасштабных когерентных систем с несколькими шасси. На рис. 3 представлена гипотетическая 64-процессорная конфигурация, в которой четыре 16-процессорных шасси взаимодействуют через выделенные каналы.
Модульные компоненты
Набор микросхем 870 — это модульная архитектура, базирующаяся на основных строительных блоках, которые были представлены выше: контроллер масштабируемых узлов (SNC), коммутатор портов масштабирования (SPS) и концентратор ввода/вывода (IOH). Кроме того, для поддержки связи и создания гибких конфигураций используются концентратор памяти и мосты ввода/вывода.
Контроллер масштабируемых узлов
SNC — это центральный компонент в конфигурации «процессор/подсистема памяти». Он включает в себя интерфейсы к процессору и подсистеме памяти, интерфейс встроенного программного обеспечения и два порта масштабирования для доступа к вводу/выводу и удаленной памяти. SNC поддерживает до четырех процессоров; поддерживает память DDR SDRAM на частоте 200 МГц через интерфейс DMH; имеет два SP-порта; допускается подключение до 32 DIMM-модулей, т. е. до 128 Гбайт на SNC при использовании модулей DDR емкостью 1 Гбайт.
SNC имеет четыре высокоскоростных канала точка-точка для связи с четырьмя DMH, которые подключены к компонентам DDR DRAM. Четыре канала обеспечивают пиковую пропускную способность при доступе к памяти 6,4 Гбайт/с на узел. SNC может буферизовать до 8 Кбайт записываемых данных, обеспечивая приоритет операций чтения над операциями записи.
Чередование последовательных операций доступа многих модулей оптимизирует использование полосы пропускания и минимизирует влияние накладных расходов. Переупорядочивание позволяет обеспечить постоянный доступ, пропуская запросы к занятым модулям. Операции доступа распределяются по четырем очередям, чтобы минимизировать конфликты синхронизации между операциями доступа. Если операции доступа выполняются в конкретном адресном диапазоне, они сортируются по каналам, а затем по младшему разряду модуля. В противном случае они сортируются по модулям. Арбитр выбирает из бесконфликтных операций доступа, находящихся в начале четырех переупорядоченных очередей.
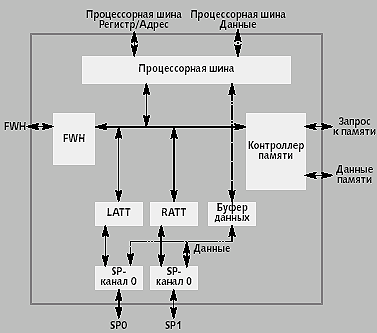
|
| Рис. 4. Микроархитектура SNC высокого уровня |
SNC состоит из трех основных компонентов (рис. 4).
- Модуль слежения за транзакциями при локальном доступе (Local Access Transaction Tracker, LATT), который контролирует запросы к процессору. Он преобразовывает запросы к процессору в запросы к контроллеру памяти или SP и возвращает ответы процессорам.
- Модуль слежения за транзакциями при удаленном доступе (Remote Access Transaction Tracker, RATT), который контролирует входящие транзакции с портов масштабирования до тех пор, пока не будут выполнены необходимые операции слежения и/или доступа к памяти.
- Буфер данных (Data Buffer) передает и хранит данные при взаимодействии между шиной процессоров, интерфейсом памяти и интерфейсами SP.
Коммутатор портов масштабирования
SPS — это коммутатор межсоединений, который связывает SNC и компоненты IOH через порты масштабирования. SPS поддерживает шесть идентичных SP с пиковой пропускной способностью 38,4 Гбайт/с. Встроенный snoop-фильтр контролирует состояние всех строк кэша в процессоре и кэшах IOH; он сокращает число snoop-запросов к удаленным узлам и поддерживает протокол согласованности кэша SP. Внутренние соединения представлены модулем перекрестных соединений и сетью шин для критически важного согласованного трафика.
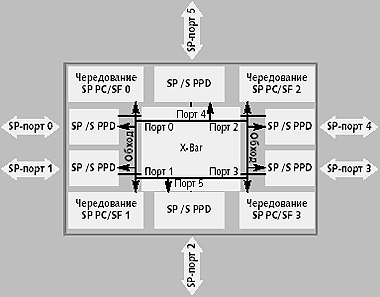
|
| Рис. 5. Микроархитектура SPS высокого уровня |
Как показано на рис. 5, каждый SP реализует физический канал и часть уровней протокола SPPD. Существует четыре централизованных модуля протокола SP (SPPC) и snoop-фильтра (SF), которые чередуются для того, чтобы увеличить пропускную способность и упростить физическую структуру, хотя они формируют один логический модуль. Все порты связываются с помощью модуля перекрестных соединений (X-Bar) и сети шин. Эти шины сокращают задержку при критически важных операциях.
SPPD выполняет декодирование адрес/запрос для того, чтобы определить, как пакеты должны передаваться в SPS. Он управляет передачей данных между портами, в том числе передачей измененных данных. SPPC (Centralized SP Protocol/Snoop Filter) содержит программируемое ядро протоколов, которое обрабатывает запросы и ответы и, в случае необходимости, порождает транзакции. Оно поддерживает глобальное упорядочивание и содержит логику, предотвращающую зависание системы, чтобы гарантировать равноправие между узлами. Объединенный массив тегов snoop-фильтра занимает 1 Мбайт и может поддерживать состояние около 200 тыс. строк кэша. Он способен обслуживать до 266 млн. операций поиска и обновления snoop-фильтров в секунду. Каждая запись содержит тег адреса, вектор присутствия (один разряд на узел), состояние протокола согласования кэшей (M/E, S, I) и разряды проверки ECC.
Концентратор ввода/вывода (IOH)
IOH — центральный компонент подсистемы ввода/вывода серверов на базе набора микросхем 870. IOH поддерживает механизм предварительной выборки и кэш чтения для использования полной полосы пропускания при возврате данных. В концентраторе предусмотрено два интерфейса SP для связи либо с SPS, либо с SNC. Четыре интерфейса концентратора обладают пиковой пропускной способностью 1 Гбайт/с каждый.
IOH поддерживает идеологию строительных блоков, реализованную в 870, что позволяет создать гибкую и конфигурируемую подсистему ввода/вывода. Кроме того, в состав подсистемы ввода/вывода входят такие компоненты, как унаследованный концентратор контроллера ввода/вывода ICH, мост PCI/PCI-X (P64H2) и адаптер контроллера хоста InfiniBand (VXB). Поскольку IOH взаимодействует с различными мостами ввода/вывода, микроархитектура, в основном, оптимизируется в соответствии с поведением трафика ввода/вывода. На рис. 6 представлена блочная диаграмма микроархитектуры IOH.
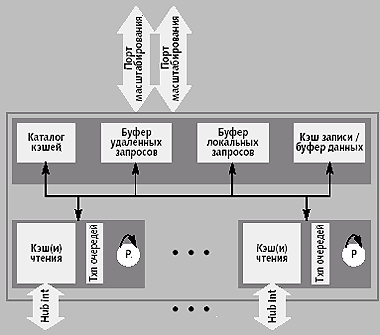
|
| Рис. 6. Микроархитектура концентратора ввода/вывода |
- Кэши чтения (Read Cache). Для каждого интерфейса концентратора выделена одна из кэшей чтения емкостью 4 Кбайт. Полностью согласованные кэши чтения позволяют использовать активный алгоритм предварительной выборки, не предлагая устаревшие данные. Этот размер удобен для хранения достаточного количества результатов операции предварительной выборки при чтении, чтобы компенсировать задержку при обращении к памяти. Независимые кэши чтения предотвращают взаимное создание помех между трафиками различных интерфейсов концентратора.
- Кэш записи и буфер данных (Write Cache и Data Buffer). В IOH реализован один кэш записи. Согласованное кэширование при записи позволяет связывать записываемые данные с определенными строками кэшей, увеличивая эффективность SP и сокращая накладные расходы при работе snoop-фильтров в системе.
- Каталог кэшей (Cache Directory). Каталог контролирует строки кэшей, размещенные в нескольких кэшах чтения и в кэше записи. Каталог также отвечает за контроль дублирования записей в разделяемых строках.
- Буферы локальных и удаленных запросов (Local and Remote Request Buffer). Эти буферы отслеживают согласованные транзакции, инициируемые IOH (буфер локальных запросов, Local Request Buffer), и согласованные транзакции, инициируемые другими компонентами (буфер удаленных запросов, Remote Request Buffer). Эти буферы совместно используются для выявления конфликтов доступа и поддержки согласованности кэшей.
- Механизмы предварительной выборки при чтении (Read Prefetch Engine). IOH динамически выполняет предварительную выборку от имени взаимодействующих устройств ввода/вывода. Эти устройства, как правило, оптимизированы с учетом традиционных задержек при доступе к памяти, поэтому для увеличения пропускной способности при чтении IOH должен выполнять предварительную выборку не только для запросов, инициированных устройствами ввода/вывода.
- Упорядоченные очереди (Ordering Queue). IOH использует по своей природе неупорядоченный протокол, поддерживаемый на SP. Как посредник для устройств ввода/вывода, которые следуют правилам упорядочивания "поставщик-потребитель" [10], IOH максимально увеличивает производительность за счет предварительной выборки, конвейерных операций и параллелизма там, где это возможно.
Порт масштабирования
Порт масштабирования — кэш-когерентный интерфейс «точка-точка», предназначенный для создания многопроцессорных систем с разделяемой памятью, которые преодолевают ограничения архитектур, базирующихся на разделяемой шине. Интерфейс SP состоит из трех уровней абстракции — физического уровня (Physical Layer), уровня канала (Link Layer) и уровня протоколов (Protocol Layer).
На физическом уровне применяется технология [8], при которой одни и те же контакты служат для передачи сигналов в обоих направлениях в полнодуплексном режиме. Это базовый интерфейс синхронизации, когда отправитель посылает сигналы синхронизации параллельно с данными, и получатель использует эти сигналы для выборки данных. Каждый интерфейс порта масштабирования имеет ширину 40 разрядов, из которых 32 разряда служат для передачи данных, 2 разряда — для контрольной информации уровня канала и 6 разрядов — для обеспечения целостности данных. Интерфейс работает на частоте 800 млн. передач в секунду, в силу чего пиковая пропускная способность составляет 3,2 Гбайт/с на порт в каждом направлении. Порт масштабирования — это пакетный интерфейс, где запросы и ответы мультиплексируются в одном и том же физическом канале, и каждый пакет содержит заголовок, используемый для маршрутизации пакета и для указания его атрибутов. Эффективная пропускная способность достигается на интерфейсе в зависимости от распределения пакетов различного размера. В пиковый период SP способен реализовать эффективную пропускную способность на уровне 80%.
Уровень канала SP поддерживает виртуальные каналы и обеспечивает управление потоками и надежную передачу. SP использует два виртуальных канала для создания независимого виртуального межсоединения для передачи запросов и ответов по одному физическому каналу. Уровень канала также отвечает за определение ошибок передачи и применяет схему повторной передачи, используя для восстановления модифицированную версию протокола перемещаемого окна «вернись на n».
Уровень протокола в SP реализует машину состояния и предоставляет ресурсы для поддержки таких возможностей, как когерентность кэшей, согласованность TLB, синхронизация, передача прерываний и так далее. Уровень протокола ориентирован на работу моделей семейства процессоров Itanium и Xeon. Этот протокол позволяет реализовать высокопроизводительную и гибкую структуру межсоединений, не полагаясь на упорядоченную структуру для операций, чувствительных к производительности.
Протокол совместимости SP позволяет агентам кэширования устанавливать строки кэша в состояние «измененный», «уникальный», «разделяемый» или «некорректный» (Modified, Exclusive, Shared, Invalid — MESI). Используемый протокол базируется на концепции распределенного каталога (snoop-фильтр), который отслеживает строки, размещенные в кэше, а не все строки в памяти. Это позволяет все snoop-фильтры хранить в одном и том же компоненте как машину состояния каталога для поддержки высокой производительности, что было бы невозможно в традиционном каталоге. Отделение snoop-фильтра от агента памяти было реализовано с целью воплощения в наборе 870 принципа «строительных блоков», что позволяет использовать контроллеры узлов и концентраторы ввода/вывода, предназначенные для недорогих систем. Это реализуется посредством транзакций, которые обращаются к памяти одновременно за счет согласования, устраняющего возможные конфликты доступа. Протокол также выполняет оптимизацию согласованных транзакций при работе устройств ввода/вывода. Разрешение конфликтов при одновременном доступе к одной и той же строке кэша выполняется упрощенным и распределенным образом.
Протокол совместимости SP поддерживает расширение до крупномасштабных систем за счет распределенного каталога второго уровня, согласованного с основным snoop-фильтром.
Надежность, обслуживаемость и готовность
Архитектура 870 предназначена для поддержки вычислительной среды для корпоративных приложений, работающих круглосуточно и ежедневно.
Выявление и обработка ошибок
Архитектура 870 выявляет более 50 уникальных ошибок. Например, все пути передачи данных защищены с помощью контроля четности или ECC, содержимое snoop-фильтра защищено с помощью ECC, а ошибки в протоколах на основных интерфейсах (в том числе на SP) помечаются тегами. Там, где это возможно, ошибки обнаруживаются, корректируются или локализуются, заносятся в регистры компонентов и о них рассылаются уведомления. Типизация и сигнализация об ошибках совместимы с архитектурами аппаратной проверки семейства Itanium и IA-32 [14].
В архитектуре реализована избыточность, позволяющая быстро перезагрузиться в упрощенном режиме в случае, если на компоненте или в межсоединении возник сбой. Например, если ошибка возникла на интерфейсе SP, система перезагружается и переконфигурируется таким образом, чтобы использовать только один коммутатор SPS. В упрощенном режиме производительность системы снижается.
Обслуживаемость
ECC реализуется в подсистеме памяти таким образом, чтобы система продолжала работать, несмотря на ошибки в SDRAM, например, сбой на устройстве является корректируемой ошибкой. Каждый компонент предоставляет интерфейс, совместимый с SM Bus 2.0, который имеет доступ ко всем внутренним регистрам, позволяя диагностировать ошибки и/или конфигурировать систему с помощью сервисного процессора. Наконец, 870 предоставляет возможность добавлять/удалять/заменять узел процессор/память или узел ввода/вывода в работающей системе. Некоторые функции, интегрированные в SP, поддерживают необходимый для этого порядок выполнения программного обеспечения, в том числе возможность подключать/отключать интерфейс во время работы, сигнализацию (через прерывания) в случае событий соединения/инициализации.
Разделение доменов
SPS поддерживает разделения системы на два домена. Домен — это «система в системе»: каждый домен имеет свой собственный экземпляр ОС. Каждый домен поддерживает независимую перезагрузку, независимый статус ошибки и сигнализацию, т. е., система, в которой реализованы все возможности архитектуры 870. Для домена можно зарезервировать два или больше портов (в домене должны быть представлены и SNC, и IOH). Разделение достигается за счет конфигурирования SPS (через установку прописываемого программного обеспечения или за счет использования консоли удаленного управления) во время инициализации системы. Как только система разделена, узлы процессор/памяти и узлы ввода/вывода могут переноситься из одного раздела в другой с помощью функций горячего добавления узлов.
Улучшенная оптимизация производительности
Оптимизация за счет чередования адресов и переупорядочивания памяти максимально увеличивает полосу пропускания при доступе к памяти. Когерентные кэши ввода/вывода и предварительная выборка компенсируют задержку ввода/вывода при операциях чтения, даже в крупных, многоузловых конфигурациях. Snoop-фильтр сокращает общую задержку и освобождает от необязательного контроля трафика. Такая оптимизация, как сеть шин в SPS, минимизирует задержку.
Переупорядочивание обращений к памяти
Протокол DDR / DRAM включает в себя множество «пустых» циклов (dead cycle) в шине передачи данных в память. Самое большое количество пустых циклов возникает при замене страницы, которая происходит тогда, когда два последовательных запроса обращаются к различным страницам одного и того же DIMM-модуля. В этом случае второй запрос откладывается на время, необходимое для закрытия ранее активированной страницы, выполняемого перед активацией страницы. Это время для DDR200, как правило, составляет 70 нс. Кроме того, существуют накладные расходы на переключение длительностью один цикл (10 нс для DDR200) для переключения с операций чтения на запись и обратно или когда считываемые данные получают с различных DIMM-модулей по одному и тому же каналу DDR.
Если все запросы к памяти размещаются в очереди FIFO и обрабатываются по порядку, протокол снижает эффективность, что приводит к значительному падению постоянной пропускной способности для случайного потока запросов, типичного для работы сервера. Однако если запросы можно переупорядочить, чтобы избежать конфликтов, это позволит увеличить постоянную пропускную способность и сократить среднее время задержки.
Настройка производительности для SNC и подсистемы памяти в общем была сделана с помощью детальной модели эмуляции микроархитектуры. При определении окончательной структуры очередей и методик было выявлено множество различных структур очередей, назначения очередей, переупорядочивания и других методов распределения рабочей нагрузки.
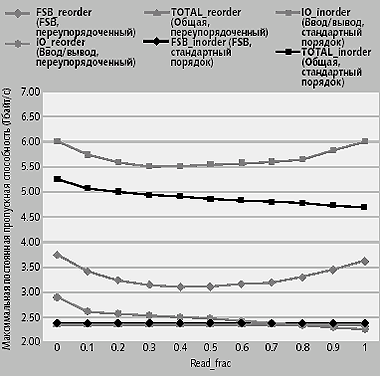
|
| Рис. 7. Максимальная постоянная пропускная способность — переупорядочивание или стандартный порядок |
На рис. 7 сравнивается схема переупорядочивания с обработкой запросов к памяти в стандартном порядке по уровню постоянной пропускной способности в системе из одного узла для различного сочетания операций чтения/записи. Переупорядочивание, избавляющее от замены страниц и накладных расходов на переключение, увеличивает максимальную постоянную пропускную способность на 12-30%, в зависимости от сочетания транзакций чтения/записи.
Кэширование ввода/вывода
IOH реализует интегрированный механизм кэширования и предварительной выборки, чтобы обеспечить высокую пропускную способность при вводе/выводе. Предварительная выборка строк компенсирует задержку при чтении из памяти и избавляет от необходимости при каждом запросе на чтение передавать сигналы через весь набор микросхем к памяти и обратно.
Настраиваемая предварительная выборка и синхронизация передачи
IOH применяет алгоритм настройки, используя два динамических профиля (консервативный и агрессивный) для спекулятивной предварительной выборки строк кэша. Предварительная выборка инициируется после того, как обслужен первый запрос для данного потока1. Последующие запросы на чтение из потока, которые попадают в кэш чтения (возможно, из предварительно выбранных данных) передаются обратно напрямую, не вызывая дополнительной задержки. Механизм предварительной выборки может воспринимать трафик реального времени и менять свою скорость генерации запросов для различных режимов, и он переключается с одного профиля на другой с учетом того, какие условия в данный момент преобладают. Степень предварительной выборки меняется в зависимости от числа имеющихся потоков для данного профиля предварительной выборки. Например, если существует только один поток, а профиль предварительной выборки установлен как «агрессивный», тогда количество строк кэш, извлекаемых посредством предварительной выборки, может достигать восьми. Если число потоков увеличить до двух, то каждый поток ограничен максимум четырьмя строками. Предварительная выборка продолжается до тех пор, пока поток остается зарезервированным и не достигнут верхний предел синхронизации. Эта настраивающаяся саморегуляция — компромисс между предварительной выборкой достаточного объема данных в потоке и не чрезмерными затратами полосы пропускания при доступе к памяти.
Анализ производительности
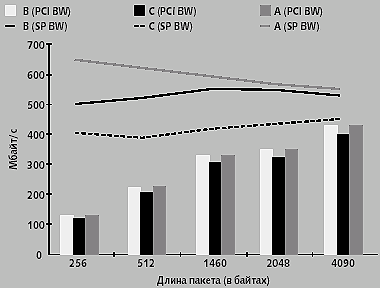
|
| Рис. 8. Производительность ввода/вывода при различных профилях предварительной выборки с двумя потоками Fiber Channel при средней нагрузке |
Для того чтобы определить оптимальную величину предоставляемой полосы пропускания и минимальное количество промахов при обращении к памяти для различных параметров предварительной выборки IOH, было проведено множество экспериментов по моделированию ситуаций. На рисунке 8 представлены результаты исследований, проведенных для конфигурации с двумя устройствами Fiber Channel PCI 66/64, к каждому из которых запросы передаются на частоте 250 Мбайт/с при средней нагрузке для трех различных профилей предварительной выборки. Профиль C очевидно неоптимален, поскольку предварительная выборка неэффективна. Профили A и B обеспечивают более высокую пропускную способность, чем профиль C на шине PCI, которая достигает почти 420 Мбайт/с (рост 7-16%), но профиль A использует большую пропускную способность SP, чем профиль B (больше примерно на 30-150 Мбайт/с) при практически той же самой производительности PCI. Это ясно показывает соотношение производительностей между оптимизацией предварительной выборки и определением уровня системной пропускной способности при выборе приемлемых параметров предварительной выборки.
Механизм горячих страниц
Многоузловые конфигурации архитектуры 870 отличаются меньшей задержкой при обращении к локальной памяти. Для программного обеспечения, которое поддерживает паритет процессоров и настраивается с учетом приоритетности обращений к локальной памяти, производительность будет оптимальной.
Чтобы помочь программному обеспечению в оптимизации при локальном доступе, компонент SNC содержит некоторую память, которая отслеживает и подсчитывает количество обращений к каждому конкретному адресу или диапазону адресов (размер диапазона задается программным образом). Данный механизм, получивший название «горячей страницы», служит для определения самых «популярных» мест в памяти, к которым обращаются удаленные узлы, и оптимизации программного обеспечения для преобразования этих обращений в операции с локальным узлом.
Заключение
Архитектура набора микросхем 870 может удовлетворить требования современных, весьма разнородных сегментов рынка серверов. Эта архитектура использует подход строительных блоков, позволяющих создавать масштабируемые серверы с процессорами семейств Itanium и Xeon.
Система, содержащая до 4 процессоров, может быть создана примерно при тех же затратах, которые требуют традиционные наборы микросхем, в то время как топологии многоузловых систем, поддерживающие до 16 процессоров и больше, повторно используют те же самые компоненты. Компонент SPS позволяет устанавливать до 16 процессоров, в то время как протокол SP позволяет системным производителям создавать многопроцессорные системы еще большего масштаба.
Архитектура 870 обладает широкими функциями RAS, которые традиционно оставались прерогативой специализированных наборов микросхем, используемых в серверах среднего класса и крупномасштабных базовых серверах. Архитектура 870 позволяет реализовывать поддержку RAS в стандартном для отрасли наборе микросхем. Она дает возможность создавать надежные и обслуживаемые серверы переднего плана, которые традиционно отставали в этой области и полагались на полную системную избыточность.
Архитектура 870 никогда не жертвует производительностью ради того, чтобы реализовать обширные возможности, упомянутые выше. Четырехпроцессорные системы на базе 870 имеют аналогичную или даже более высокую производительность, чем немасштабируемые традиционные наборы микросхем, в то время как многоузловые системы обеспечивают низкую задержку при доступе к памяти и высокую пропускную способность.
Статья содержит информацию о продуктах, находящихся на стадии разработки. В окончательный продукт могут быть внесены изменения.
Faye Briggs, Michel Cekleov, Ken Creta, Manoj Khare, Steve Kulick, Akhilesh Kumar, Lily Pao Looi, Chitra Natarjan, Sivakumar Radhakrishnan, Linda Rankin, Intel 870: A Building Block for Cost Effective Scalable Server. Copyright 2002, Intel Corp. All rights reserved. Translated with permission.
Литература
- IBM, IBM X-Architecture Technology, http://www.pc.ibm.com/ us/ eserver/ xseries/ xarchitecture/ index.html
- HP, HP rp5400 Series Technical White Paper, http://www.hp.com/ products1/ servers/ rackoptimized/ rp5400series/ infolibrary/ pdfs/ 5400-whitepaper.pdf
- HP, HP Server rp8400 Technical White Paper, http://www.hp.com/ products1/ servers/ rackoptimized/ rp8400/ rp8400infolib/ rp8400_whitepapers.pdf
- HP, HP Superdome Technical White Paper, http://www.hp.com/ products1/ servers/ scalableservers/ superdome/ infolibrary/ whitepapers/ technical_wp.pdf
- Sun, Sun Fire 6800/4810/4800/3800 Systems Overview, http://192.18.99.138/ 805-7362-11/ 805-7362-11.pdf
- Sun, Sun Fire 15K System Overview, http://192.18.99.138/ 806-3509-10/ 806-3509-10.pdf
- SGI, SGI 3000 Family Reference Guide, http://www.sgi.com/ origin/ 3000/ 3000_ref.pdf
- M. Haycock, R Mooney, "A 2.5GB/s Bidirectional Signaling Technology", Hotinterconnects V Symposium Record, pp. 149-156, August 1997
- JEDEC Standard - Double Data Rate (DDR Specification), Rev 1.0, JESD79, June 2000
- PCI Local Bus Specification 2.2, PCI SIG, 2000
- V. Milutinovic, M. Tomasevic, "Cache Coherence Problem in Shared-Memory Multiprocessors", IEEE Computer Society Press, 1993
- T. Lovett, S. Thakkar, "The Symmetry Multiprocessor System", Proc. 1988 Int'l Conf. Of Parallel Processing, University Park, Pennsylvania, pp. 303-310
- M. Cekleov et al, "SPARCcenter 2000: Multiprocessing for the 90's", Proceedings of COMPCON Spring '93, San Francisco, California, February 22-26, 1993
- Itanium Processor Family Error Handling Guide, http://www.intel.com/ design/ itanium/ downloads/ 249278.htm
