

Измерение производительности х86-совместимых компьютеров в ОС Linux
Рассмотрены некоторые вопросы организации тестирования производительности х86-совместимых компьютеров. Для одно- и двухпроцессорных систем широкого диапазона производительности проведены измерения на тестах Linpack (n=100 и n=1000) и STREAM c использованием таймеров с разными разрешениями.
Показано, что для получения достаточно точных результатов необходимо применять таймеры, обладающие более высоким разрешением, чем стандартные 0,01 сек. Это справедливо для любых высокопроизводительных компьютеров, особенно при распараллеливании в многопроцессорных системах, а также в кластерах. В описываемых тестах таймер использовал счетчик тактов процессора, что для современных компьютеров обеспечивает разрешение меньше 1 мксек. Этот прием допустим в ряде операционных систем, работающих с архитектурой x86.
Несомненно, для пользователя лучший тест — выполнение его приложения или смеси его приложений. Когда такие данные недоступны или спектр используемых приложений очень широк, можно ориентироваться на интегральные тесты, являющиеся отраслевым стандартом (например, SPECcpu2000). Наконец, можно тестировать отдельные компоненты архитектуры — процессор, память и т. д. Подобные тесты позволяют получить более детальное представление об отдельных составляющих общей производительности компьютера. Два примера таких тестов рассмотрены в данной статье.
Измерение временных интервалов в тестах производительности
Измерение временных интервалов в тестах не представляет сложности, если типичные измеряемые времена прогона достаточно велики (от нескольких секунд). Во многих тестах оно гораздо выше; так, SPECcpu2000 может потребовать несколько часов. Однако ряд стандартных для отрасли тестов, в частности, Linpack и STREAM, на современных процессорах выполняются за доли секунды.
Дискуссия автора с Джеком Донгаррой, создателем тестов Linpack, поддерживающим официальную таблицу результатов тестов Linpack (http://performance.netlib.org/performance/ html/linpack.data.col0.html) показала, что тот считает необходимым оставить неизменными исходный текст теста и, соответственно, измеряемые промежутки времени выполнения. Это означает, что измерять промежутки времени выполнения большего числа прогонов соответствующей части теста, как предлагал автор, нельзя. Подобная позиция обусловлена стремлением сохранить максимальную «чистоту эксперимента»: огромное количество результатов было получено на старых компьютерах (в том числе представленные в таблице Linpack измерения автора для отечественного компьютера ЕС-1066), где время выполнения тестов было достаточно велико.
Рассмотрим подробнее ситуацию с измерением времени в х86-совместимых компьютерах. Нас будет интересовать, в частности, соответствующая служба времени в Linux. Эта операционная система становится все популярнее в корпоративных приложениях, в области высокопроизводительных вычислений и, особенно, в решениях, использующих кластерную архитектуру. Поскольку оригинальные тесты Linpack и STREAM написаны на Фортране, остановимся на подпрограммах времени выполнения, доступных в современных компиляторах этого языка, который по сей день остается ведущим в области сложных приложений научно-технического характера.
В ОС Linux для х86-совместимых процессоров 1 «тик» (т.е. разрешение) часов составляет 0,01 сек, что определяется соответствующей константой в ядре операционной системы. Все громадное количество таймеров, доступных в компиляторах с Фортрана для платформы х86 — нами проверялись, в частности, таймеры библиотек времени выполнения компиляторов Compaq Visual Fortran 6.6, Portland Group pgf77 v.3.1, Lahey Fujitsu lf95 v.6.0, Intel ifc 5.0 и g77 — обладают разрешением не лучше 0,01 сек (даже если в описании подпрограмм было указание на возможность получения более хорошего разрешения).
Проблема здесь не в Фортране и не в плохих подпрограммах, а в том, что используемые системные вызовы (gettimeofday, getrusage и т.п.) не дадут лучше 0,01 сек, так что и в Си ситуация будет ничем не лучше.
Что касается аппаратных средств, которые могут быть использованы для измерения времени, то в будущих наборах микросхем есть планы встроить часы реального времени с высоким разрешением. Пока же можно использовать счетчик тактов RDTSC (Read Time Stamp Counter), доступный на х86-совместимых процессорах, начиная с Pentium [1]. Однако в этом случае мы измеряем не процессорное, а так называемое «старт-стопное» (walltime) время. Это допустимо, когда измеряется время выполнения в тактах какого-либо небольшого участка ассемблерной программы. Если же измеряемое время становится большим, то в замеряемый интервал попадут и те такты процессора, когда «измеряемый» процесс был не активен, а работала операционная система (еще хуже, если ОС заменила этот процесс другим).
С какой частотой Unix вмешивается в работу процессора в обычной ситуации (при отсутствии «лишних» прерываний)? Диспетчер BSD каждые 4 тика (т.е. каждые 0,04 сек) понижает приоритет выполняющегося процесса и, кроме того, каждую секунду изменяет приоритеты процессов в зависимости от используемых ресурсов. Устанавливаемый по умолчанию квант времени в Unix SVR4 равен 0,2 сек, а для высокопроизводительных процессов — 0,04 сек [2]. В Linux, по крайней мере в ядре 2.2, кванты времени лежат в диапазоне 0,2-0,4 сек (точнее, 210-410 мсек) [3].
Таким образом, если измеряется интервал времени короче кванта (т.е. для Linux меньше 0,2 сек), и во время выполнения не возникло «сторонних» прерываний, отвлекающих процессор от обработки нашего процесса, то при попадании этого интервала «внутрь» кванта будет получено точное значение времени выполнения процесса между двумя точками замера. Если же замеряемый интервал не лежит целиком в пределах одного кванта, произойдет некий «выброс» во времени выполнения с соответствующим уменьшением рассчитываемой производительности, поскольку часть измеренных тактов будет затрачена ядром Linux. Чем меньше замеряемый интервал времени, тем больше вероятность, что он целиком разместится в пределах одного кванта. Однако, если это оказывается не так, доля «чужих тактов» и соответственно погрешность измерения возрастает, «выброс» будет заметнее.
При измерении интервалов длиннее кванта ядро «вмешивается» всегда; соответственно результат всегда будет несколько неточным. В общем случае таймер RDTSC дает некоторое систематическое завышение времени выполнения (добавляются «чужие такты»), соответственно занижая получаемую оценку производительности. Эта погрешность может быть пренебрежимо малой, но, вообще говоря, это обстоятельство надо иметь в виду при анализе результатов, полученных с использованием RDTSC.
При использовании таймера на базе RDTSC, как и любых подпрограмм, измеряющих старт-стопное время, необходимо позаботиться о том, чтобы при тестировании по возможности не возникало «лишних» прерываний и процессов, которые в принципе могут конкурировать за процессорное время. В Linux этого можно добиться путем перехода в однопользовательский (single) режим, отмены откачки на диск и «убития» всех ненужных процессов. Именно в таких условиях, если явно не указано противное, проводились измерения производительности в настоящей работе.
C целью уменьшения количества тактов, которое «съедает» ядро Linux, можно еще попробовать увеличить интервал времени, через который ядро производит «поджог» (сброс на диск) буферов данных файловой системы, изменив параметры в /proc/sys/vm/bdflush во время прогона теста. Однако умалчиваемая величина интервала даже для более часто сбрасываемых на диск структур (таких, как каталоги) составляет 5 сек. С нашей точки зрения, для рассматриваемых в статье тестов такие меры являются уже излишними, поскольку это должно вносить пренебрежимо малую ошибку времени выполнения.
В качестве иллюстрации важности применения при тестировании в Linux однопользовательского режима приведем примеры измерения производительности Athlon/700 МГц на тестах Linpack с использованием RDTSC. При параметрах n=100 и lda=201 (cм. ниже) производительность при измерениях изменялась в диапазоне 293,0-295,1 MFLOPS, а в однопользовательском режиме — от 295,1 до 295,8 MFLOPS.
Для n=1000 в обычном режиме производительность при использовании Lapack-процедур библиотеки Atlas-3.4.1 изменялась от 770,2 до 772,9, а в однопользовательском режиме — от 772,0 до 772,7. Таким образом, приемлемые результаты с точностью до 1 MFLOPS (с такой точностью результаты приводятся в официальной таблице Linpack) получаются только в однопользовательском режиме.
Еще один пример — Athlon XP1800+. При n=1000 с использованием Lapack/Atlas-3.4.1 и RDTSC замеренная производительность изменялась в диапазоне от 1596 до 1621 в обычном, и от 1622 до 1624 (т.е. 1623 ? 1 MFLOPS) — в однопользовательском режиме.
Наши измерения показали, что при использовании таймеров со стандартным разрешением ошибки измерений возрастают, и применение однопользовательского режима для получения удовлетворительных по точности результатов оказывается еще важнее, чем для таймеров RDTSC.
В двухпроцессорных системах есть еще один подводный камень. Он связан с тем, что после истечения кванта времени процесса следующий квант времени планировщик может предоставить этому процессу уже на другом процессоре, что потребует перезаполнения его кэш-памяти. Желательной стратегией было бы распределение процессу квантов времени одного и того же процессора (для обозначения этой стратегии используется термин affinity — «сродство»). Гарантировать такую стратегию в Linux, увы, нельзя даже в последних версиях ядер 2.4, однако практика показывает, что это требование все же обычно выполняется.
Кроме того, для Linux имеются «заплатки» ядра, позволяющие создать «набор процессоров» и приписать к нему задачу. Тогда, создав процессорный набор из одного процессора, можно добиться выполнения процесса только на нем. Впрочем, поскольку в настоящей работе измерялись короткие интервалы (в SMP-системах для n=1000 это несколько квантов), такие меры не представляются необходимыми.
Влияние таймера на измерения производительности
Полезно посмотреть на конкретных примерах, как влияет использование таймера на основе RDTSC по сравнению с таймерами со стандартным разрешением 0,01 сек.
В тестах Linpack на использованных нами компьютерах типичные времена составили от порядка 10-1 сек до 10-5 сек. В некоторых из таких измерений использование обычных таймеров оказалось возможным, однако для точных результатов RDTSC все же лучше. Так, ошибка стандартных таймеров в 0,01 сек на тестах Linpack (n=1000) для Athlon/700 МГц при использовании библиотеки Atlas приводит к ошибке производительности в 9 MFLOPS, а для Athlon XP/1533 МГц — уже в 39 MFLOPS.
Очевидно, что по мере роста производительности х86-совместимых процессоров стандартные таймеры будут все менее приемлемыми, а RDTSC-таймеры, чье разрешение будет улучшаться пропорционально тактовой частоте, останутся по-прежнему пригодными.
Для тестов STREAM при стандартной размерности массивов в 2 млн. элементов (см. ниже краткое описание STREAM) в зависимости от пропускной способности оперативной памяти мы измеряли времена от 0,04 сек до 0,15 сек. Замеряемые времена можно увеличить во много раз, увеличив размерность массивов. Однако этот резерв упирается в ограничение емкости физической памяти, в которой должны разместиться все массивы (при стандартной размерности они занимают всего 45 Мбайт). Поэтому применение RDTSC для тестов STREAM по мере роста производительности процессоров и увеличения пропускной способности оперативной памяти также будет все более оправданным; это целесообразно и сейчас, особенно для быстрых процессоров и памяти небольшой емкости. Если же не увеличивать размерность массивов, то пользоваться RDTSC-таймером необходимо.
Обратимся теперь к реальной точности измерений. «Инструментальное» (теоретическое) разрешение RDTSC-таймера равно 10-8 сек даже для 100-мегагерцевого процессора, и, как уже отмечалось, улучшается пропорционально тактовой частоте. Однако в реальных измерениях следует учитывать поправку на время вызова подпрограммы таймера, принимая в расчет перечисленные выше факторы, влияющие на точность измерения.
Даже для самого медленного из рассматриваемых в данной работе процессоров, Intel Celeron/433 МГц, измеренное предельное разрешение таймера равно 2x10 -7 сек. В тестах Linpack при n=100 отклонения от среднего значения при 30 измерениях по порядку величины не превышают 10-5 сек.
В тестах STREAM (по крайней мере, в версии 5.0) производится 10 измерений производительности и считается средняя величина времени выполнения. При этом во всех наших измерениях реальное подсчитанное тестом разрешение таймера было лучше 1 мксек, а точность (если угодно, среднеквадратичное отклонение) — не хуже нескольких микросекунд.
Эти данные вместе с приведенными ниже результатами тестов показывают, что применение RDTSC-таймера в рассматриваемых случаях является не только необходимым, но и как правило достаточным для получения приемлемой точности.
Краткое описание тестов
Дадим краткое описание тестов Linpack и STREAM, необходимое для понимания результатов и их обсуждения.
В тестах Linpack решается система линейных уравнений методом LU-разложения (или методом исключения Гаусса) [4]. В этой численной схеме точно определено, какое зависящее от размерности системы n количество операций с плавающей запятой (сложений и умножений; долей других операций можно пренебречь) нужно выполнить, и производительность в MFLOPS можно получить, поделив это число операций на время в секундах.
Метод включает две стадии. На первой, на которую у современных процессоров уходит основная часть времени, матрица коэффициентов приводится к треугольному виду. Количество требуемых на эту стадию операций с плавающей запятой пропорционально n3 (точнее, (2/3)*n3). На второй стадии полученная система уравнений решается; число требуемых для этого операций с плавающей запятой пропорционально n2.
Тесты Linpack предусматривают стандартные значения n=100 и n=1000. Кроме того, имеется тест High Parallel Linpack, который применяется в основном как тест на распараллеливание. Он допускает сколь угодно большое увеличение n, что позволяет достичь близкой к пиковой производительности и добиться лучшего распараллеливания даже в кластерах. В данной статье Linpack parallel не рассматривается.
Тест Linpack при n=100 практически не ускоряется при распараллеливании, хотя соответствующие результаты представлены в официальной таблице для некоторых векторных суперкомпьютеров с автоматическими распараллеливающими компиляторами с Фортрана. При n=1000 Linpack можно распараллелить достаточно хорошо, и с точки зрения автора, эти результаты интересны как пример распараллеливания задачи линейной алгебры с не слишком «заоблачными» размерностями.
Стандартный тест Linpack, результаты которого могут быть приняты для опубликования в официальной таблице, написан на языке Фортран-77, хотя есть аналогичные тексты и на Cи, и на Java. При n=100 в исходном тексте нельзя менять ни одной строчки, в то время как при n=1000 подпрограммы приведения к треугольному виду и собственно решения можно заменить на любые собственные, в том числе написанные на ассемблере. Предполагается, что расчет производится с величинами с плавающей запятой, имеющими не хуже чем 64-разрядное представление (double precision).
Основное время (на современных процессорах — порядка 90% [4]) при прогоне теста уходит на выполнение циклов типа циклов с телом Y(I) = Y(I) + Alpha*X(I). Формально такой цикл имеет большую долю операций обращения в память. Однако при n=100 используемая квадратная матрица целиком помещается в кэш современных микропроцессоров (в 1979 году, когда тест Linpack только появился, это было не так). Поэтому данный тест характеризует производительность процессора, «не затрагивая» оперативную память. Для векторных процессоров в случае, если они не имеют кэша, ситуация может быть иной, хотя там неким аналогом кэш-памяти будут векторные регистры.
При n=1000, напротив, матрица требует 8 Мбайт и не может полностью разместиться в кэш-памяти современных процессоров. Даже если емкость кэша второго (или третьего) уровня равна 8 Мбайт, он является смешанным, и (правда, очень маленькая) часть его будет, вероятно, содержать также команды. Единственное исключение — это IBM Power4, имеющий кэш третьего уровня емкостью 32 Мбайт на процессор.
Однако эффективные численные алгоритмы учитывают наличие кэш-памяти и позволяют организовать вычисления над отдельными блоками матриц так, чтобы при обработке блока он размещался в кэш-памяти. При этом нет падения производительности из-за непопадания в кэш, и обращения в память опять-таки не являются узким местом.
Обычно в тестах Linpack (n=1000) используются вызовы подпрограмм из пакетов Lapack и BLAS как библиотек времени выполнения, которые поставляются производителем компьютеров (для ПК-серверов это обычно не так). Альтернативой является многоплатформенная библиотека Atlas [5]. Для процессоров с архитектурой х86 конкурентом Atlas является библиотека Intel MKL [6], хотя доступны и другие альтернативы. Для Linux имеется версия MKL 5.0.1, которая использована в данной работе.
Такии образом, тесты Linpack при n=100 и 1000 являются «чисто процессорными», характерными для работы с векторами соответственно средней и большой длины. При n=100 тест Linpack характеризует также качество оптимизации компилятора, а при n=1000 — мастерство программиста (например, разработчика соответствующих подпрограмм библиотеки времени выполнения). В качестве иллюстрации полезности тестов Linpack для оценки производительности на конкретных приложениях укажу, что несколько лет назад нами была обнаружена корреляция между данными Linpack (n=100) и производительностью, достигаемой в самом мощном комплексе квантово-химических программ Gaussian-98 при расчетах так называемым методом ССП. Для этого метода характерна хорошая локализация в кэше и короткие векторы.
Между тем многие сложные приложения научно-технического характера (например, тот же Gaussian-98 — для ряда других методов квантовой химии) часто лимитируются пропускной способностью памяти. Индустриальным стандартом для пропускной способности оперативной памяти в 90-е годы стал тест STREAM (http://www.streambench.org). В этих тестах выполняются операции над длинными векторами четырех типов: copy (тело цикла A(I) = B(I)); scale (с телом A(I) = scalar*B(I)); add (C(I) = A(I) + B(I)) и triad (A(I)= B(I) + scalar*C(I)). Элементами векторов являются 64-разрядные числа с плавающей запятой. Очевидно, выполнение таких циклов лимитируется обращениями к оперативной памяти. Производительность теста меряется в количестве мегабайт в секунду, обработанных в этих циклах.
Исходные версии этих тестов, как и Linpack, были написаны на Фортране, хотя имеется и версия на Си; кроме того, имеется отдельная специальная таблица результатов, где могут приводиться данные, полученные при «ручной» оптимизации на ассемблере. Однако такие данные носят вспомогательный характер по отношению к основной таблице, результаты в которой характеризуют производительность процессора при работе с оперативной памятью и качество компилятора.
Для многопроцессорных систем при измерениях возможно выполнение параллельно нескольких копий теста. Для компьютеров с общим полем памяти текст на Фортране включает директивы OpenMP, что позволяет распараллелить выполнение соответствующих циклов.
Тесты STREAM идеально дополняют не зависящие от пропускной способности памяти тесты Linpack, и именно поэтому мы рассматриваем их совместно.
Результаты чизмерений производительности
В наших тестах использовалось пять различных типов серверов.
- Сервер на базе Intel Celeron/433 МГЦ (кэш второго уровня емкостью 128 Кбайт работает на частоте процессора) с набором микросхем 440 BX (плата ASUS P2B-F) и оперативной памятью типа РС100.
- Двухпроцессорный сервер на базе Intel Pentium III/600 МГц (кэш второго уровня емкостью 512 Кбайт, работающий с частотой 300 МГц) с набором микросхем 440BX (плата ASUS P2B-D) и оперативной памятью типа PC100.
- Сервер на базе AMD Athlon/700 МГц (кэш второго уровня емкостью 512 Кбайт с частотой 350 МГц) с набором микросхем VIA KX-133 (плата Gigabyte GA-7VX) и оперативной памятью типа PC133.
- Двухпроцессорный сервер на базе Intel Pentium III Tualatin/1266 МГц (кэш второго уровня емкостью 512 Кбайт с той же частотой) с набором микроcхем ServerSet III LE3 компании ServerWorks (плата Tyan S2518) с оперативной памятью типа PC133.
- Двухпроцессорный сервер на базе AMD Athlon XP 1800+ (кэш второго уровня емкостью 256 Кбайт, работающий на частоте процессора) с набором микросхем AMD 760MP (плата Tyan S2460), с оперативной памятью DDR266.
Эти серверы покрывают широкий диапазон производительности и включают процессоры с различной микроархитектурой ядра и разной кэш-памятью. Данные тестов Linpack для них отсутствовали, и мы отправили полученные результаты «на сертификацию» Джеку Донгарре.
Для трансляции применялся компилятор ifc 5.0, обладающий на сегодняшний день наилучшим уровнем оптимизации для х86-совместимых процессоров. Применение ifc 6.0 не должно привести к заметному улучшению производительности, поскольку в этой версии основные улучшения в оптимизации касаются, вероятно, поддержки Pentium 4, которые нами не тестировались. ifc 6.0 применялся только при построении и настройке библиотек Atlas 3.4.1 для Athlon XP. Для тонкой настройки оптимальной емкости кэша второго уровня (она была найдена равной 112 Кбайт) мы применяли RDTSC-таймер. Без этого оптимизация не давала воспроизводимых результатов. Существенной разницы с ifc 5.0 в производительности не обнаружилось.
Рассмотрим сначала результаты тестов Linpack, которые представлены в таблице 1. Что касается результатов при n=100, то обращает на себя внимание высокий результат, полученный для самого в общем-то медленного в тестах процессора Сeleron, который в данном случае опередил Pentium III/600 МГц. Это связано с тем, что матрица целиком помещается в кэше второго уровня Сeleron. Но в этом процессоре, в отличие от Pentium III/600 МГц, кэш интегрирован и эффективно работает на частоте процессора. Хорошие результаты процессоров Athlon связаны, в частности, с их способностью выполнять за такт сразу две операции с плавающей запятой — сложение и умножение.
Выравнивание положения матрицы в памяти повышает производительность: при ведущей размерности матрицы (lda), равной 200, производительность выше, чем при lda=201. Этот эффект сильнее сказывается на процессорах Athlon. Полученные нами результаты — наивысшие достигнутые сегодня для этих процессоров; данные для более высокочастотных моделей Athlon в официальной таблице результатов Linpack отсутствуют.
При n=1000 матрица не помещается в кэше. Поэтому Pentium III, как и полагается, опередил Celeron. Для иллюстрации того, как влияет на производительность выбор алгоритма, мы приводим результат для Celeron, отвечающий прямой трансляции исходного текста всех подпрограмм теста, чему отвечает работа с длинными циклами. Очевидно, это приводит к большому проценту непопаданий в кэш и деградации производительности по сравнению с n=100.
Поблочные алгоритмы, реализованные в MKL и Atlas, обеспечивают, грубо говоря, на порядок более высокую производительность, чем прямая трансляция. При этом выяснилось, что достигаемая производительность при использовании MKL и Atlas оказалась (в случае Сeleron) близка. В других тестах для процессоров Intel мы использовали MKL. Однако для процессоров Athlon применение Atlas-3.4.1 позволило достигнуть существенно более высокой производительности (таблица 1). При этом для Athlon XP/1533 в двухпроцессорном случае измеренная производительность оказалась несколько нестабильной (отклонения от среднего значения составили до 15 MFLOPS).
В таблице 2 сопоставлены некоторые полученные в [4] результаты для разных процессоров (при n=1000) и наши данные для Celeron.
Из этой таблицы видно, что и для других процессоров применение прямой трансляции исходного текста вместо использования библиотек понижает производительность, грубо говоря, на порядок (для Itanium/800 МГц — в 20 и более раз). Хорошие результаты, достигаемые при прямой трансляции на Pentium 4, связаны, вероятно, с высокой пропускной способностью оперативной памяти и аппаратной поддержкой предварительной выборки в кэш. Процессоры IBM Power всегда отличались высокой пропускной способностью оперативной памяти, а Power4 — вообще один из лидеров производительности, уступающий только Itanium 2. Однако в данном случае его прекрасный результат, очевидно, связан с тем, что при n=1000 квадратная матрица емкостью 8 Мбайт помещается в его кэш третьего уровня.
К сопоставлению результатов, полученных при прямой трансляции, следует подходить с некоторой осторожностью, поскольку в [4] не указано, какие версии компиляторов применялись. Отметим, что как наши результаты для Celeron, так и данные [4] показывают, что замена исходного текста вызовами подпрограмм BLAS нижних уровней (операции с векторами BLAS1 и векторно-матиричные операции BLAS2) не способна существенно поднять производительность. Лишь применение BLAS3/Lapack, что отвечает операциям над матрицами, позволяет эффективно реализовать «поблочный» подход и обеспечивает большое ускорение. Именно такой подход обычно применяется при n=1000 (и, в частности, в [4] и в настоящей работе).
|
| Примечание. (*) — значению 1,34 отвечает применение Atlas, значению 1,82 — MKL. |
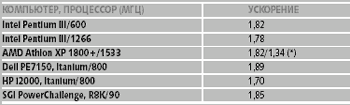
В таблице 3 приведены полученные нами ускорения расчета, достигаемые в двухпроцессорных х86-серверах SMP-архитектуры (при n=1000) по сравнению с однопроцессорными. До сих пор такие SMP-результаты в официальной таблице Linpack отсутствовали. Для сравнения приведены также значения ускорения, достигаемые в системах на Itanium и в используемом в Центре компьютерного обеспечения химических исследований РАН (где выполнялась описываемая работа) шестипроцессорном SMP-сервере SGI Power Challenge с RISC-процессором R8000/90 МГц.
Полученные нами результаты достаточно высоки. Следует отметить, что несмотря на рост производительности процессоров, опережающий рост пропускной способности оперативной памяти, что вместе может уменьшить достигаемое ускорение, измеренное ускорение оказалось близко, например, к Power Challenge с существенно более медленными процессорами. Хорошее ускорение в данном случае во многом связано с высокой локализуемостью в кэш-памяти. Для Athlon XP при использовании более «быстрой» библиотеки Atlas-3.4.1 (см. таблицу 1) ускорение оказалось значительно ниже.
В таблице 4 полученные нами данные сопоставлены с другими официальными результатами тестов Linpack. Для сравнения мы приводим не только результаты для х86-совместимых процессоров, но и для некоторых других процессоров, в том числе наиболее высокопроизводительных векторных процессоров, и лидеров производительности среди процессоров с архитектурой IA-64 и RISC.
Эти результаты показывают, что «массовые» микропроцессоры при n=100 практически догнали векторные процессоры (шансы обогнать их имеют как Itanium 2/1,2 ГГц, так и последние высокочастотные модели Pentium 4/2,8 ГГц). Лишь при n=1000 суперкомпьютеры Hitachi, Fujitsu и NEC существенно впереди.
Лидером среди микропроцессоров стал Itanium 2, который опережает IBM Power4, по крайней мере, при n=1000. Даже если предположить, что производительность Pentium 4 с ростом частоты масштабируется линейно, то 3-гигагерцевая версия, выход которой ожидается к концу 2002 года, все равно будет отставать (при n=1000) от Itanium 2. Однако мы не имеем данных, какой компилятор (в частности, поддерживающий ли команды SSE2) и какие библиотечные вызовы использовались в тестах для Xeon/2 ГГц, являющегося в таблице лидером среди х86-совместимых процессоров, а это может существенно влиять на результат.
Athlon XP 1800+ лишь немного отстает от Xeon/2 ГГц. Кстати, при n=1000 наш результат — наивысший из опубликованных для семейства Athlon; данные для процессоров Athlon XP с более высокой частотой отсутствуют. К концу 2002 года можно ожидать, что в борьбу включатся перспективные 64-разрядные процессоры AMD Hammer.
Мы привели в таблице также данные для SGI Power Challenge, чьи процессоры R8000 работают на частоте всего 90 МГц. Тем не менее, на векторах средней длины (n=100) они опережают используемые нами в узлах кластеров процессоры Pentium III/600 МГц. Это одна из ярких демонстраций мифа о необходимости борьбы собственно за тактовую частоту. Кроме Itanium 2 и Power4, это заблуждение опровергают и результаты векторных процессоров: их тактовые частоты (см. таблицу 4) не превышают 500 МГц.
Последний из приведенных в таблице 4 результатов — для Pentium II Xeon/450 — является иллюстрацией важности выбора компилятора при n=100: плохой результат в данном случае связан, очевидно, с применением транслятора g77, не отличающегося высоким уровнем оптимизации.
В графе «%» в таблице 4 приводится отношение достигаемой при n=1000 производительности к пиковой. Этот показатель в определенной степени характеризует «эффективность» архитектуры на длинных векторах (в среднем n/2=500), показывая степень приближения к пиковым возможностям, так сказать, ее «КПД». Векторные процессоры остаются лидерами не только по пиковой производительности (среди микропроцессоров лидерами по этому показателю являются Pentium 4/2,8 ГГц — 5,6 GFLOPS, а также Power4/1,3 ГГц — 5,2 GFLOPS) и по тестам Linpack (n=1000), но и по КПД их архитектуры при работе с длинными векторами. В общем, это естественно: они и разрабатывались для работы с векторами. Высокий уровень КПД имеет и архитектура IA-64.
Cреди RISC-процессоров высокий КПД, например, у SGI R8000. Наши результаты показали высокий КПД у Pentium III, который выше, чем у Power4; немного хуже КПД тестированного нами Athlon XP (в однопроцессорном случае). Некоторое отставание Pentium 4 по этому параметру может быть вызвано как архитектурными особенностями — например, возможным уменьшением в нем, по сравнению с Pentium III, числа одновременно исполняемых команд и существенным увеличением длины конвейера, или малой емкостью D-кэша L1, так и недостаточно эффективным применением команд SSE2.
Аналогично, исходя из данных таблицы 4, можно рассчитать КПД на тестах Linpack (n=100), т.е. с векторами средней длины (n/2=50). Некоторые из этих значений приведены в таблице 5, в которой для х86-совместимых процессоров приведены только полученные результаты, и данные для Pentium 4/2 ГГц. Данные для других х86-совместимых процессоров представляют меньший интерес, поскольку, во-первых, в измерениях использовались различные компиляторы, и, во-вторых, наши результаты с компилятором ifc, вероятно, являются на сегодня наиболее высокими из-за наивысшего уровня оптимизации в ifc.

|
Из таблицы 5 видно, что векторные суперкомпьютеры японского производства на векторах средней длины уступают по КПД не только процессорам Cray (опережая их при этом по абсолютному уровню производительности), но и процессорам архитектур RISC/CISC/IA-64. С учетом данных таблицы 4 это говорит о том, что применение векторных суперкомпьютеров при работе с векторами средней длины не является эффективным в приложениях, где пропускная способность оперативной памяти не является лимитирующим фактором (имеется в виду отношение стоимость/производительность векторных систем по сравнению с более дешевыми компьютерами на базе «массовых» микропроцессоров).
Высокий КПД в этой таблице имеют также RISC-процессоры SGI R8000 и Pentium III Tualatin. КПД Pentium 4 несколько меньше (возможные причины этого фактически обсуждены выше), а у Athlon XP лишь чуть уступает Pentium 4. Последнее может быть связано с несколько большей эффективностью применения команд SSE2 в Pentium 4 по сравнению с раздельным выполнением сложения и умножения разными функциональными устройствами в Athlon.
В качестве общего резюме к обсуждению результатов тестов Linapck можно сказать, что векторные процессоры существенно опережают обычные микропроцессоры лишь на длинных векторах. В свою очередь, Pentium 4 и Athlon лишь немного уступают по производительности 64-разрядным Intel/HP Itanium 2 и IBM Power4. К этому можно прийти из представленных выше данных тестов Linpack путем экстраполяции результатов х86-совместимых процессоров к более высоким тактовым частотам, уже доступным в настоящее время, однако этот вывод подтверждается и результатами тестов SPECcpu2000.
Рассмотренные нами тесты Linpack, которые характеризуют производительность процессора на задачах с плавающей запятой, практически не зависят от пропускной способности оперативной памяти, что, как правило, не типично для современных высокопроизводительных приложений. Рассмотрим теперь результаты тестов STREAM, которые в этом отношении хорошо дополняют Linpack. Соответствующие данные представлены в таблице 6, где кроме исследованных нами компьютеров приведены результаты для векторных процессоров и некоторых других микропроцессоров.
Эти данные показывают, что по пропускной способности оперативной памяти векторные системы по-прежнему далеко впереди микропроцессоров (для векторных процессоров применение векторных регистров вместо большого кэша в микропроцессорах требует и большей пропускной способности памяти для поддержания высокого темпа вычислений).
Представленные в таблице 6 полученные нами данные не являются рекордными; возможно, путем подбора опций компилятора ifc или применения других трансляторов можно было бы достигнуть наивысшей пропускной способности оперативной памяти. Однако нашей целью было получить сопоставимые между собой результаты для х86-совместимых процессоров, работающих с различными типами памяти, что и было достигнуто благодаря применению единого компилятора для серверов широкого диапазона производительности. Применение RDTSC-таймера позволяет гарантировать приемлемую точность.
В соответствии с таблицей 6, переход от 66-мегагерцевой шины Celeron/433 МГц к 100-мегагерцевой шине Pentium III/600 МГц приводит к реальному росту пропускной способности оперативной памяти примерно в те же полтора раза. Рост пропускной способности при переходе от Pentium III/PC100 к Athlon/PC133 составил около 1,6 раза, что больше, чем 33% из-за разницы PC133 и PC100, и коррелирует с более высокой пропускной способностью шины Athlon (200 МГц). Правда, в тесте triad пропускная способность памяти возросла как раз на треть. Pentium III/1266 МГц также использует память PC133, но с шиной 133 МГц, и его результаты ниже, чем у Athlon/700.
В среднем пропускная способность оперативной памяти при работе с Pentium III/1266 МГц оказалась на 20-40% выше, чем в Pentium III/600 МГц, т.е. в целом пропорционально росту «технологической» пропускной способности (PC133 против PC100).
Athlon XP/1533 МГц на тестах copy и scale показал вдвое более высокую пропускную способность в полном соответствии с «технологией» (DDR266 против PC133 с Pentium III). На add и triad ускорение оказалось ниже — в 1,7 и 1,4 раза соответственно. То, что Pentium 4 является лидером х86-совместимых процессоров по пропускной способности оперативной памяти (в таблице 6 для Pentium 4 приведены данные из официальной таблицы тестов STREAM), естественно, учитывая пропускную способность его шины (частота 400 МГц, а теперь и 533 МГц).
Более того, известно, что его архитектурные особенности и высокая тактовая частота для достижения высокой производительности требуют повышенной пропускной способности памяти, что нужно учитывать при анализе результатов. Мы укажем лишь на то, что результат существенно зависит от применяемого компилятора. Представленные в Таблице 6 результаты для Pentium 4/1,5 ГГц в среднем в полтора раза выше, чем для Pentium 4/1,4 ГГц из-за того, что в первом случае оптимизация была произведена под архитектуру Pentium 4, в частности, генерировались SSE-команды.
Данные официальной таблицы результатов STREAM для RISC-процессоров (в таблице 6 представлены только лучшие результаты для процессоров Alpha) говорят о том, что процессоры архитектуры х86 им не только не уступают, но, как правило, превосходят по пропускной способности оперативной памяти. Но нами было найдено, что при распараллеливании STREAM в использовавшихся в тесте двухпроцессорных серверах пропускную способность увеличить практически не удается, в отличие от многих SMP-серверов RISC-архитектуры. Это говорит о низкой эффективности архитектуры с однопортовой памятью, использованной в применявшихся нами ПК-серверах.
С нашей точки зрения, полученные в работе результаты измерений на тестах STREAM (соответствующие данные направлены «на сертификацию» с целью последующего помещения в официальную базу данных результатов) полезны для сопоставления оценок пропускной способности оперативной памяти для типовых х86-совместимых процессоров.
Можно также проанализировать, насколько поддерживаемая пропускная способность (результаты тестов STREAM) меньше теоретического предела для соответствующего типа памяти. С точки зрения аппаратуры, этот результат зависит не только от процессоров, но и от эффективности реализации северного моста в наборе микросхем. Отметим, что для ПК-серверов в первом приближении реальная пропускная способность оперативной памяти составляет примерно половину пикового значения (см. таблицу 6).
Выводы
Результаты проведенных измерений на тестах Linpack вместе с известными ранее данными позволяют предположить, что для приложений с плавающей запятой и векторами средней длины (менее 100) процессоры архитектуры x86 почти не уступают лидерам — Itanium 2 и Power4, а те, в свою очередь, практически не уступают векторным процессорам. Аналогично, на длинных векторах Itanium 2 и Power4 в несколько раз отстают от векторных процессоров японских производителей и заметно опережают процессоры архитектуры x86 от Intel и AMD.
По пропускной способности оперативной памяти большинство современных векторных процессоров по-прежнему далеко впереди микропроцессоров.
Пропускная способность оперативной памяти в ПК-серверах (как правило, с однопортовой памятью) может плохо масштабироваться при переходе от одного к двум процессорам.
Автор выражает благодарность РФФИ (проект 01-07-90072) и МКНТ (проект 1.2.63 за 2002 год).
Литература
[1] Using the RDTSC Instruction for Performance Monitoring. Intel Corp., 1997
[2] А. Маджидимер, Оптимизация производительности Unix, М.: Альфа-букс, 2002
[3] С. Максвелл, Ядро Linux в комментариях. Киев, ДиаСофт, 2000
[4] J.J. Dongarra, P. Luszczek, A. Petitet, The Linapck Benchmark: Past, Present and Future. Dec. 2001, www.netlib.org/utk/people/JackDongarra/PAPERS/hpl.pdf
[5] R.C. Whaley, A. Petitet, J.J. Dongarra, Authomated Empirical Optimizations of Software and the Atlas project. March 2000, www.netlib.org/atlas
[6] Intel Math Kernel Library Reference Manual. Intel Corp., 2001
[7] Intel Fortran Compiler User?s Guide. Intel Corp., 2001
Михаил Кузьминский — старший научный сотрудник ИОХ РАН (Москва)
