

Использование любой информационной технологии, новой или известной еще со времен первых ЭВМ, должно быть оправдано. Увы, на практике так получается не всегда. Поставленная нашим заказчиком задача была на первый взгляд достаточно проста: создать комплекс прикладных программ, принимающий выходные данные от нескольких уже существующих информационных систем и выполняющий их сопоставление, обработку и хранение результатов. Ну и конечно, доставку этих самых результатов пользователям в требуемом виде. Казалось бы, типичный проект, начинающийся с постановки задачи, выработки стратегии реализации, создания, тестирования, внедрения и всего того, что обычно делается в таком случае. Однако как выяснилось уже в самом начале, словосочетание «типичный проект» никак не подходило для описания проблем, с которыми мы столкнулись. Система предназначалась для эксплуатации на железных дорогах и, учитывая специфику отрасли, простых решений здесь быть не могло.

Министерство путей сообщения никак нельзя назвать типичной структурой, однако описанный в статье опыт мог бы быть интересен тем, кто сталкивался с проблемами, возникающими в работе с крупными предприятиями, отягощенными своей корпоративной культурой. Ситуации, подчас возникающие в таких организациях, требуют нестандартного подхода, когда хорошо известные и испытанные средства не всегда оказываются эффективны.
За последние годы в области телекоммуникаций и создания сетевой инфраструктуры МПС совершило гигантский рывок вперед. Разрозненные локальные сети подразделений в большинстве своем объединены в единую корпоративную информационную сеть на базе протокола IP. К сожалению, разработка прикладных систем пока отстает от развития сети.
Нам предстояло создавать систему в одном из наиболее интересных направлений информатизации на железнодорожном транспорте — автоматизированном построении графика исполненного движения (ГИД). Нашими пользователями должны стать поездные диспетчеры — люди, непосредственно влияющие на процесс управления движением поездов. Постановку задачи отличала необходимость строить график слежения за передвижением грузовых поездов по так называемым «кольцевым маршрутам» перевозки сырьевых ресурсов от производителей к переработчикам. Такой график сам по себе предполагал использование новых решений, поскольку требования к нему достаточно сильно расходились с требованиями к стандартному ГИД.
Входными данными служили информационные сообщения о различных операциях с поездами, вагонами, грузом и проч. Эти данные поступали сразу от нескольких первичных систем обработки, которые в свою очередь получали их в результате ручного ввода или после опроса состояния различных устройств (стрелки, рельсовые цепи и т.п.). Система должна была свести все эти данные — в идеале дополняющие, а на практике зачастую противоречащие друг другу — в единую структуру, отражающую движение поездов по отдельным участкам железной дороги. Помимо отображения самого факта движения поезда в близком к реальному масштабе времени график подразумевал наличие множества форм статистической отчетности и различных справок (перевозимый груз, типы вагонов и локомотивов, ведущие состав машинисты и др.).
Нюансы отраслевой информатизации
Первой серьезной проблемой стала значительная рассредоточенность в корпоративной сети как источников первичных данных, так и пользователей. По условиям эксплуатации система, выполняющая обработку и хранение данных, должна была располагаться в вычислительном центре дороги. Большинство же пользователей находились в отделениях дороги, на станциях и других дорогах, и все они должны иметь оперативный доступ к данным системы.
Как оказалось, несмотря на наличие мощной корпоративной сети, многие локальные сети подразделений по-прежнему связаны между собой медленными модемными каналами. И даже локальные сети крупных отделений, соединенные между собой высокоскоростными магистралями, время от времени выпадают из глобальной сети в результате нарушений связи из-за сбоев оборудования и человеческих ошибок. Не добавляло оптимизма и то обстоятельство, что несмотря на наличие общей корпоративной сети, дороги отгорожены друг от друга разнообразными межсетевыми экранами, средствами создания виртуальных частных сетей или, в крайнем случае, списками доступа (составлялись эти списки так: сначала закрывалось все, а потом по мере нарастания недовольства пользователей, понемногу открывались отдельные службы). Основными общедоступными сетевыми службами оставались, как правило, только электронная почта, ftp и Web. С другой стороны, в небольших подразделениях дорог (в них также находилась часть наших потенциальных пользователей) ввиду отсутствия подготовленного персонала поддержка прикладных систем оставалась на весьма невысоком уровне.
Не менее серьезной проблемой стали постоянно меняющиеся требования к выходным формам и к представлению графических данных. Руководители разных уровней (даже не являясь потенциальными пользователями) вносили множество предложений и поправок, естественно, желая увидеть их в действии... «вчера». (Это относится не только к внедряемым системам, но и к уже принятым в эксплуатацию и успешно работающим.) Вместе с этим действительно существовала реальная необходимость внесения серьезных изменений в уже действующие системы, что было вызвано и новыми отраслевыми требованиями, развитием технологий и множеством других факторов. Естественно, это касалось и систем, которые являлись источниками первичных данных: менялся как формат, так и смысл передаваемых показателей.
Стало ясно, что простым набором отдельных проблемно-ориентированных приложений не обойтись. Возникали вопросы, на которые обычные средства разработки ответов не давали. Как обеспечить надежный доступ к данным значительного объема по низкоскоростным каналам с частыми потерями соединения? Как в кратчайшие сроки донести до всех пользователей обновленные отчетные формы?
В результате было принято решение о разработке базовой, системной платформы, позволяющей создавать надежные и в то же время легко модифицируемые прикладные системы, и уже на ней построить прикладную систему.
Системная платформа
Все поступающие сообщения возникали в результате некоего события в реальном времени (изменение состояния устройств, заполнение формы, таймер и т.д.), а после полного цикла обработки система переходила в состояние ожидания следующего сообщения. Каждый цикл обработки разбивался на отдельные этапы, по завершению которых нужно было что-либо записать в базу данных и передать сообщение на следующий этап, исключая сообщения, которые могли быть обработаны за один шаг. А поскольку данные от разных систем поступали асинхронно, легко было организовать независимую обработку различных групп сообщений. Разбивка обработки каждого сообщения на этапы дала возможность выполнять эти этапы независимо. Система, реализующая такой механизм обработки, могла бы состоять из набора модулей, параллельно выполняющих обработку сообщений на каждом отдельном этапе и обменивающихся сообщениями между собой.
Уже начальный этап проектирования показал, что в данной ситуации необходим компонентный или модульный принцип организации приложения. Основным недостатком монолитных систем является невозможность изменения логики обработки данных без остановки и замены всего приложения. Такой подход не позволил бы распределить обработку по нескольким серверам, сделав проблематичным масштабирование всей системы. Возникли бы проблемы отладки; к примеру, поиск причины утечки памяти был бы невозможен без полного анализа всей логики работы.
Для построения распределенных систем можно использовать хорошо известные технологии, скажем, CORBA и DCOM. Стоит отметить, что по сравнению с компонентами, требующими регистрации и использующих достаточно громоздкий механизм вызова удаленных процедур, применение поддерживающих обмен сообщениями на основе протокола IP отдельных модулей проще и эффективнее. В нашем случае применение каких-либо протоколов для межкомпонентного обмена, отличных от общедоступных, привело бы к серьезным трудностям с внедрением и последующей эксплуатацией, учитывая специфику организации межсетевого взаимодействия отдельных подразделений (это не раз подтверждалось на практике). К тому же архитектура системы вовсе не предполагала взаимодействия между отдельными компонентами путем вызова заранее объявленных функций. Входными событиями для системы были сообщения, поступающие единым потоком, и мы решили сохранить тот же принцип обмена и внутри системы. Каждое сообщение представляло собой неструктурированную информационную единицу, формат которой был известен получателю, поэтому не возникало необходимости в описании внешних интерфейсов взаимодействия — достаточно было просто принимать входной поток сообщений, и уже сам модуль обработки должен был решить дальнейшую судьбу сообщения.
Гораздо лучше подходили Web-службы. Однако проблема заключалась в том, что нужна была не просто отдельная служба с заранее определенной функциональностью. Для реализации возможности быстрого изменения логики обработки данных необходима была система, в которой мы могли бы «по ходу дела» менять правил игры. Не устраивала необходимость активизации и управления Web-служб неким внешним средством: это только усложнило бы общую конструкцию системы. К тому же, если до конца следовать концепции Web-служб, запросы к ним должны были поступать в соответствии с протоколом SOAP, базирующимся на XML. Между тем, внешние источники сообщений никакого представления об XML не имели и поддерживать его в большинстве своем не собирались. Можно долго рассуждать о преимуществах и недостатках применения XML; идея универсального языка разметки данных, конечно, замечательна, но в данном конкретном случае такой подход был бы непрактичен.
В качестве обработчика события было решено использовать отдельный, независимый модуль, на вход которому передавалось пришедшее сообщение, а тот в свою очередь выполнял его обработку, опираясь на сценарии, созданные специально для каждого этапа обработки. Для сохранения результатов модуль имел необходимый набор функций работы с СУБД (рис. 1).
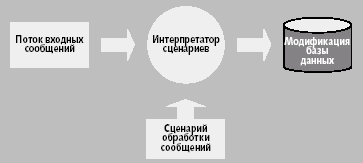
|
| Рис. 1. Модуль обработки сообщений |
Этот модуль был организован как простой интерпретатор сценариев, поддерживающий некий протокол обмена сообщениями и содержащий набор необходимых функций обработки и доступа к данным. Основой языка сценариев стал классический вариант языка Паскаль, дополненный специализированными функциями. Сценарий каждого этапа обработки хранился в отдельном файле. Модуль обеспечивал их «кэширование», когда при первом обращении к сценарию тот загружался в оперативную память и оставался там до тех пор, пока файл сценария не был обновлен. Файл параметров модуля мог быть изменен «на ходу», без перезапуска самого модуля. Для отладки сценариев и локального контроля работы модуля использовались несколько видов журналов регистрации событий.
В качестве СУБД решено было использовать Microsoft SQL Server 2000. На такой выбор повлияла ее распространенность в отрасли, кроме того, в вычислительных центрах и крупных отделениях появились специалисты с соответствующей подготовкой. На момент принятия этого решения в ряде подразделений активно использовались Oracle и IBM DB2, обладавшие примерно равными возможностями и удовлетворявшие предъявляемым требованиям по функциональности и производительности. Однако для Windows наибольшую надежность, простоту в установке и администрировании показал SQL Server 2000. Немаловажным фактором являлась сложность поддержки прикладных систем на местах, а в линейке Microsoft SQL Server имелись варианты «на все случаи», позволяющие строить различные конфигурации. Самый простой вариант установки — Personal Edition — стал для нас очень удачным выбором при построении небольших локальных узлов. А возможности масштабирования и создания распределенных баз наиболее мощного варианта — Enterprise Edition — дополняли концепцию распределенной обработки, предполагающую создание центрального обрабатывающего комплекса, выполняющегося параллельно на нескольких серверах.
Следующим шагом стал выбор механизма обмена сообщениями между модулями системы. На сегодняшний день наиболее полно реализуют механизм обмена сообщениями, пожалуй, Microsoft Message Queuing (MSMQ) и IBM MQSeries. Это продвинутые системы, обеспечивающие асинхронный обмен сообщениями между приложениями. Приложения взаимодействуют с клиентскими частями этих систем посредством вызовов интерфейсных функций, а серверные части берут на себя поддержку и управление очередями сообщений, маршрутизацию сообщений, обеспечение безопасности обмена, поддержку транзакций. Как механизм взаимодействия между разнородными системами эти средства незаменимы (к примеру, клиентские части MQSeries реализованы более чем на десятке различных платформ). Но для обмена между однотипными приложениями в рамках одной системной платформы такие средства слишком громоздки. В нашем случае не требовались ни механизмы маршрутизации, ни средства безопасности, которая обеспечивалась на общесетевом уровне; дублировать все это в приложениях не имело смысла. Отдельные клиентские и серверные части, почти никак не управляемые приложением и требующие специальной установки и администрирования, отнюдь не упрощали общей конструкции.
Взяв от этих систем идеи, необходимые для реализации механизма обмена сообщениями, мы создали свой собственный прикладной протокол обмена сообщениями — MTP (Message Transfer Protocol). Созданный на базе TCP/IP, он был ориентирован на асинхронную передачу сообщений между двумя участниками обмена (абонентами). Главной особенностью этого протокола было то, что абоненты равноправны в инициативе установления логического соединения. Каждый абонент содержал в себе клиентскую и серверную часть, а инициатором соединения всегда выступал абонент, в очереди у которого были сообщения для передачи (рис. 2). Такой подход делал ненужным поддержку открытого соединения абонентом, ожидающим поступления сообщений. Более того, соединения закрывались после очень непродолжительного времени простоя (несколько минут). Сделано это было с целью оптимизации использования вычислительных ресурсов и повышения надежности.

|
| Рис. 2. Обмен сообщениями между абонентами МТР |
Для реализации протокола MTP была написана библиотека, компилируемая вместе с приложением. Эта библиотека с минимальным количеством вызовов функций, обеспечивавших все необходимое для обмена сообщениями. Поддержка очередей сообщений, гарантированная доставка и строгое следование последовательности передачи сообщений были стандартно реализованы в данной библиотеке. Отдельных серверных или клиентских частей не предусматривалось.
Надежность обмена сообщениями между абонентами достигалась за счет накопления отправляемых сообщений в выходных очередях абонента. Сообщение считалось успешно переданным и удалялось из выходной очереди только после приема подтверждения от получателя. В случае сбоев сообщение передавалось повторно. Очереди сообщений сохранялись в файлах на диске с буферизацией в оперативной памяти. Это с одной стороны ограничивало объем очередей только свободным дисковым пространством, а с другой повышало скорость обмена небольшими сообщениями. Для минимизации потерь данных в случае фатальных сбоев в системе были разработаны механизмы периодического сброса очередей из оперативной памяти в файл и механизм аварийного сохранения данных, реализованный через взаимодействие с операционной системой.
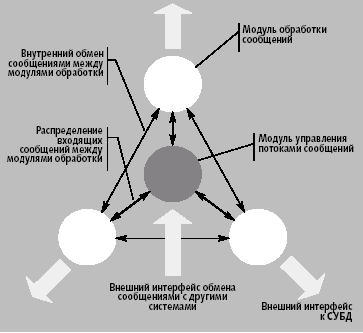
|
| Рис. 3. Взаимодействие модулей внутри одной системы |
Для распределения входящих сообщений и обмена с другими системами был создан специальный модуль управления потоками сообщений (рис. 3) — своеобразный центр, который помимо распределения потоков сообщений играл роль шлюза между модулями обработки и внешними системами. Через него же подключались дополнительные модули расширения. Модули обработки могли вести обмен сообщениями как напрямую между собой, так и через модуль управления. Это позволяло масштабировать систему, распределяя модули обработки между несколькими серверами заменой всего лишь нескольких строк в файле конфигурации, не затрагивающей самих сценариев обработки. К тому же, обмен сообщениями с остальными модулями обработки через центральный узел оказался очень эффективным на медленных каналах, когда выгоднее пропускать весь поток данных через одно логическое соединение.
Прикладная система
В прикладной системе можно выделить три основных узла: первичные системы (источники данных от систем других разработчиков), центральный обрабатывающий комплекс и локальные системы, обслуживающие пользователей (рис. 4). Центральный обрабатывающий комплекс по определению не работал с пользователями. Его главной задачей была обработка данных и поддержка основной базы данных, соответственно, он в основном состоял из модулей обработки сообщений. Локальные системы состояли преимущественно из модулей, обеспечивающих доступ к данным конечных пользователей. Модуль обработки сообщений в локальных системах обеспечивал обмен по протоколу MTP и синхронизацию данных между основной и локальной базой данных.
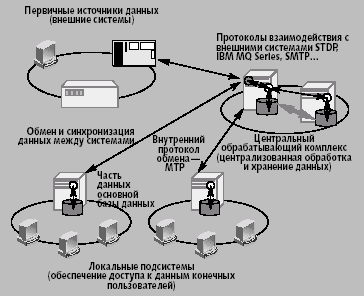
|
| Рис. 4. Построение прикладной системы |
Локальные системы были необходимы ввиду большой рассредоточенности пользователей в корпоративной сети. Такие системы, находясь в подразделениях дорог и обслуживая пользователей своей локальной сети (или ближайших сетей), в значительной степени решали проблему гарантированного доступа к данным. В случае сбоев в магистральных каналах передачи данных или нарушений в работе основного комплекса пользователи могли продолжать работу с локальными системами. Время, за которое отсутствие данных начинало сказываться на скорости вывода графической информации, в системе составляло не менее 20-30 минут. Очереди сообщений, накапливавшиеся при отсутствии связи с абонентом, предотвращали потерю данных. Требования к вычислительным ресурсам самих модулей обработки были невысоки, поэтому, в принципе, локальную систему можно было разместить непосредственно на рабочей станции отдельного пользователя, связанного с основной системой обычным аналоговым модемом. Поскольку основная нагрузка в локальной системе ложилась не на модули обработки данных, а на средства доступа к данным, то все требования к аппаратным ресурсам определялись объемом данных в локальной системе. В первую очередь это касалось объема оперативной памяти, скорости обмена с дисковой подсистемой и, в какой-то степени, производительности центрального процессора.
Еще одно нестандартное решение легло в основу обмена данными между центральным обрабатывающим комплексом и локальной системой. База данных локальных систем содержала в себе часть основных данных, требовавшихся пользователям. Вместо использования механизмов репликации Microsoft SQL Server центральный обрабатывающий комплекс, основываясь на внутренней логике обработки данных, более оптимально составлял блоки данных для передачи каждой локальной системе в отдельности. Такое решение в значительной степени оптимизировало обмен данными, а механизмы сжатия, учитывающие типы передаваемых данных позволили сократить трафик, что в дальнейшем очень оправдало себя при обмене данными по медленным каналам. В значительной степени была упрощена процедура настройки обмена. В описании параметров фигурировали понятия, более близкие к реальности, нежели при настройке репликации. При подключении новых локальных систем администраторам не нужно было вдаваться в хитросплетения взаимосвязей таблиц и наборов записей: достаточно было указать, какие именно данные (движение поездов, погрузка вагонов и т.д.) в каком объеме (скажем, диапазон станций или набор участков) необходимо передавать.
Для приема данных от пользователей была разработана так называемая командная система. Все данные пользователей локальных систем передавались в виде командных сообщений в центральный обрабатывающий комплекс, где проводился их входной контроль и модификация данных в основной базе данных. После этого все изменения передавались в локальные системы. Таким путем поддерживалась непротиворечивость данных.
Несмотря на условное деление на центральную и локальные системы, все они представляли единую распределенную систему с общей подсистемой контроля и управления. Модульность, связь на уровне транспортных сетевых протоколов, очереди сообщений — все это делало систему устойчивой к различным сбоям и отказам, как сетевого оборудования, так и вычислительных систем. Система могла продолжать работу даже после разрыва связи, распавшись на отдельные составляющие, которые снова объединялись в единое целое после устранения проблем безо всякой потери данных. Бывали ситуации, когда в результате сбоя ОС нарушалась работа стека сетевых протоколов и в системе попросту «исчезали» локальные адреса (все модули оказались изолированными друг от друга). Но, несмотря на это, за счет накопления очередей сообщений, реализованных в библиотеке поддержки протокола MTP, потери данных не происходило, и после перезагрузки система автоматически продолжала работу с момента сбоя.
Представление результатов
На практике, сталкиваясь с трудоемким процессом распространения и обновления приложений, всегда хотелось иметь централизованные средства, обеспечивающие представление пользователям требуемой информации. Для этого использовались самые разные способы: хранение единственной копии приложения на сервере и запуск его пользователями на своих рабочих станциях через файловую службу, применение систем управления рабочими станциями, помимо прочего обеспечивающими и управление установленными приложениями (к примеру, Microsoft System Management Service). Имелись и такие экзотические способы, как работа с приложением через терминальный доступ к серверу, что при мощных рабочих станциях, ненамного уступающих серверу, не могло не вызвать недоумения. Все эти способы оправдывали себя в локальных сетях с небольшим числом пользователей, однако в большой корпоративной сети были неэффективны, а зачастую и вовсе неприемлемы.
Оптимальным вариантом можно считать доставку отчетности и форм ввода данных через Web, а для отображения сложных графических данных, изменяющихся в близком к реальному времени режиме, использовать обычные приложения.
Проблему с доставкой и обновлением стандартных приложений решили следующим образом: был написан небольшой компонент ActiveX, который со стартовой страницы загружал эти приложения по протоколу HTTP, а затем их запускал. Копирование приложения происходило только в случае, если на сервере находилась новая версия. Оперативная отчетность, непосредственно связанная с отображаемой графической информацией, выводилась самими приложениями средствами встроенного Web-браузера (рис. 5).
Все HTML-страницы в системе были рассчитаны на работу с Internet Explorer 5.0 и выше: система строилась для определенного круга корпоративных пользователей и «случайно» заходящих пользователей не предполагалось. Оформление и получение отчетных форм в нужном виде строилось с использованием вложенных таблиц стилей таблиц и динамических страниц. Для первичного контроля вводимых данных и некоторой активизации содержимого страницы использовался JavaScript.
Еще одной проблемой было обновление отображаемой информации при изменении в базе данных. Стандартным решением являются периодические запросы к базе данных для поиска обновленных данных. Однако, учитывая случайный характер обновления данных, такой метод был крайне неэффективен и порождал больше «шума» (т.е. запросы, не возвращающие данные, но расходующие ресурсы), чем результатов. Для решения этой проблемы был применен стандартный прием оповещения в IP-сетях — широковещательная рассылка. Специальная внешняя серверная процедура, вызываемая триггером, рассылала пакеты-оповещения с идентификаторами модифицированных записей. Как показала эксплуатация, метод себя оправдал: потери даже в сильно загруженных сетях были минимальными.
С HTTP-сервером и активным формированием страниц дело обстояло несколько сложнее. Идея использования Microsoft Internet Information Server (IIS) одобрения не получила: разнообразные интересные возможности системы не компенсировали ее тяжеловесность и излишнюю сложность в управлении. Не радовали и многочисленные успешные вирусные атаки на IIS. Но нашей системе и не нужны были все возможности IIS. Все, что требовалось, — это доставка страниц и выполнение приложений WinCGI и CGI.
Работа по активному формированию содержимого страниц была возложена на SQL-сервер. SQL-запросы сами по себе и так являются достаточно мощным инструментом, а использование хранимых процедур на сервере давало дополнительные возможности. Все, что должен уметь в нашем случае Web-сервер, — найти внутри запрашиваемой страницы шаблон с SQL-запросом, передать его серверу, а результат вернуть как часть страницы. HTTP-сервер в нашей системе как раз таким сервером и был. От вирусов он был защищен идеально: в силу своей ограниченности он просто не понимал, что они от него хотят. Единственным дополнением был отдельно реализованный шлюз между HTTP-сервером и SQL-сервером. Такое решение несколько усложнило общую конструкцию, зато сделало возможным независимую работу Web-сервера и шлюза с базой данных. Эти модули можно разнести по разным серверам или собрать систему нужной конфигурации из нескольких модулей для повышения производительности.
Основной же функцией шлюза было получение запроса от Web-сервера и передача его SQL-серверу, а затем получение результата в виде набора записей, форматирование по указанному в запросе шаблону и передача результата Web-серверу. Для оптимизации запросов шлюз некоторое время поддерживал соединение открытым после отработанного запроса и использовал его повторно для аналогичных запросов; использование объектной модели доступа к данным на основе ActiveX (ActiveX Data Object) делало такой механизм весьма эффективным. Для быстрого обновления страниц с отчетными формами Web-сервер имел механизм синхронизации страниц с вышестоящими серверами по аналогии с прокси-серверами.
Централизованный контроль и управление
Последнее, что делало этот набор модулей единым целым, — подсистема централизованного контроля и управления. От каждого модуля системы требовалась возможность изменения основных рабочих параметров «на ходу», что и легло в основу принципа централизованного управления. В каждый модуль встраивалась небольшая библиотека, функции которой регистрировали рабочие параметры модуля и позволяли выполнять управление: остановка и запуск, изменение параметров конфигурации, обновление сценариев обработки и т.д. Библиотека предусматривала внешний IP-интерфейс для подключения приложений контроля и управления.
Поскольку наша система строилась по иерархическому принципу и вершиной дерева становился, как правило, модуль управления потоками, на него же возлагалась функция концентратора управления. Такое построение позволяло приложениям управления подключаться к центральному модулю системы и через него осуществлять управление всей системой. К тому же предполагалось создание набора отдельных приложений управления с различной функциональностью. Часть приложений занималось сбором текущих показателей, их анализом и отображением статистики; другие предназначались для обновления конфигурации, сценариев, хранимых процедур и модификации структуры таблиц баз данных. Чтобы не нагружать каждый модуль множеством соединений для подсистемы контроля, все это делалось через главный модуль в иерархии. Более того, этот модуль самостоятельно производил опрос параметров всех нижестоящих систем и хранил их у себя, что давало возможность с помощью одного запроса к нему получить состояние всей системы.
Изменения в системе могли выполняться как директивно, путем непосредственного указания, какой параметр и в каком модуле нужно изменить, так и в пакетном режиме. Для этого создавался общий пакет всех вносимых изменений (с возможностью синхронной остановки работы части модулей) и передавался на исполнение пакетному обработчику. Основным же направлением для приложений контроля стала их направленность не просто на выдачу текущих показателей, а именно на анализ работоспособности всей системы на основе различных показателей.
Когда от системы требуется круглосуточная работоспособность, очень важно заранее оповещать администраторов о проблемах. Именно для этих целей и было необходимо средство анализа состояния всей системы и оповещения о критических значениях показателей (постоянному росту очередей или снижению объемов потока менее среднестатистических показателей). В противном случае возникали ситуации, когда проблемы в работе системы уже начинали влиять на работу пользователей, а администраторы, не имея средств контроля, все еще не подозревали об этом. Пользователи, недовольные скоростью выдачи результата или устаревшими данными, сообщали о проблемах; администраторы спешили им на помощь, не догадываясь, что проблемы возникли в самой системе. На восстановление уходило значительное время, а зачастую, как следствие упущенного времени, происходила безвозвратная потеря данных. Это еще раз подчеркивает необходимость механизма централизованного контроля и управления для эффективной эксплуатации системы; его отсутствие способно свести на нет любые усилия по поиску оптимального решения.
Заключение
Автор статьи вовсе не призывает разработчиков отказаться от решений, предлагаемых производителями системного и прикладного программного обеспечения, и самим «с нуля» создавать прикладные системы. Есть множество хороших инструментов, которые с успехом можно использовать для создания прикладных систем самых разных уровней. Совсем необязательно использовать полный набор горячих «фирменных» решений, которые, как уверяют их поставщики, ведут к успеху.
Использовав возможности двух хорошо известных средств (SQL Server 2000 и Internet Explorer 5.0), мы добавили лишь одно собственное решение по созданию механизма обработки данных. Все остальное — это дополнения, связывающие компоненты в единую систему. В результате, сосредоточив решение всех специфических проблем в модулях собственной разработки, мы сумели воспользоваться преимуществами стандартных средств и построить оптимальную систему, успешно справляющуюся с поставленной задачей.
Игорь Васильев (wiw@svrw.ru) — ведущий специалист НПЦ «Инфотэкс» (Екатеринбург).
