

Многие компании сталкиваются сегодня с необходимостью организации отказоустойчивых хранилищ информации. Постепенно такие системы на предприятиях обрастают различными аппаратными и программными платформами, имеющими собственные способы управления и организации доступа к ресурсам, а также обеспечения их безопасности; по мере этого возникает задача консолидации разобщенных компонентов хранения и создания общей системы управления им.
При выборе решения по хранению данных первым делом необходимо конкретизировать цели. Так, для предприятия, о котором пойдет речь, требовалось создать хранилище данных, чей объем за два десятилетия сбора информации превысил 5 Тбайт, обеспечить необходимый уровень надежности, предусмотреть возможность резервного копирования, построить дублирующую систему хранения на удаленной площадке и, наконец, построить единую систему управления. Четких параметров стоимости решения первоначально не ставилось; они выявились уже в ходе выполнения проекта.
Аппаратное обеспечение
Кластеры
Как известно, кластерные технологии позволяют объединять несколько серверов для обеспечения постоянной готовности и управляемости сетевых ресурсов. Кластеры состоят минимум из двух узлов и разделяемого (совместно используемого) дискового пространства. Кластеры могут поддерживать следующие функции: передача управления ресурсами при сбое (failover); возвращение управления ресурсами на исходный узел после его восстановления (failback); перераспределение нагрузки (ресурсов) между узлами (load balancing).
Минимально возможная конфигурация — двухузловые кластеры, в большинстве случаев способные обеспечить приемлемый уровень готовности, означающий, что несмотря на поломку техники услуги будут доступны пользователям, а у администраторов останется время на ремонт или замену. Конечно, в каждом конкретном случае этот уровень нужно рассчитывать. Так, добавление третьего узла доводит время безотказной работы до 99,99% — 55 минут потенциального простоя в год. Ряд операционных систем позволяет строить только двухузловые кластеры, чего часто бывает недостаточно. Далее идет класс решений, рассчитанных на 4-8 узлов; реализовать для них режимы failover и load balancing гораздо сложнее, и многие производители делают это только для двух узлов. Еще более совершенные кластерные решения (из стандартных, а не заказных компонентов) позволяют объединять в кластер до 32 узлов.
Кластерные технологии позволяют свести к минимуму вынужденные простои, вызванные, например, профилактическим обслуживанием, когда ресурсы одного из узлов могут быть переведены на другие узлы. Также без остановки всей системы в кластер могут вводиться дополнительные узлы.
Чтобы обеспечить повышенную надежность, необходимо устранить единые точки сбоя. Например, если узлы подключены к единственной системе хранения, то нужно организовать дублирующие пути передачи информации между узлами и дисковой подсистемой. Надежной должна быть и сама дисковая подсистема: диски с большим временем наработки на отказ, электронные компоненты проверенных поставщиков и т.д. Диски требуется объединять в RAID-массивы. Время хранения данных измеряется десятилетиями, соответственно, RAID здесь ключевое решение — без избыточности не будет отказоустойчивости. При этом уровень дискового массива определяется конкретной задачей. В нашем случае главным критерием был доступный объем, а не скорость, поэтому RAID 0 и 1 не подходили, уровень 2 мало кто видел в работе, а уровни 3, 4 и 5 по накладным расходам (один дополнительный диск) были одинаковы. (Оценки скорости обмена и доступа требуют тщательного изучения и представляют собой отдельную задачу; в данной статье она не рассматривается. — Прим. ред.)
Для получения действительно отказоустойчивого решения необходимо продублировать и само дисковое хранилище, предусмотрев, как минимум, «каждой твари по паре». Для катастрофоустойчивого решения, способного противостоять пожарам, землетрясениям, наводнениям, терактам и т.д., необходимо организовать резервный центр хранения (управления), географически разнесенный с основным на расстояние до 100 км, что вытекает из требований некогда весьма известного свода рекомендаций Гражданской Обороны, разработанного на случай применения оружия массового поражения или стихийных бедствий. На случай катастрофы такой центр должен быть оснащен сходным оборудованием и располагать актуальной информацией, что требует постоянного канала связи для синхронизации данных.
В качестве узлов кластера были предложены Intel-серверы от Compaq, хотя универсальность решения предполагает возможность включения в него компьютеров других архитектур. К примеру, дисковые стойки и ленточные библиотеки можно подключать как посредством SCSI, так и через сеть хранения (SAN — storage area network). Сама идеология SAN позволяет совместно использовать ресурсы хранения различными узлами, независимо от платформы. В результате, система хранения и резервного копирования с соответствующим программным обеспечением может быть подключена как к одному компьютеру, так и к кластеру произвольной архитектуры. На данный момент в кластер входят серверы Proliant ML370, ML530, ML570 и ML750 в башенном исполнении, а также Proliant DL380, DL580, DL590/64 (с процессором Itanium), DL760 и 8500 в стоечном исполнении. Эти серверы поддерживают от 2 до 8 процессоров и снабжены 64-разрядными шинами PCI/66 МГц, необходимыми для подключения высокоскоростных устройств ввода/вывода. Многопроцессорность обеспечивает дополнительную надежность, а также позволяет наращивать вычислительную мощность. Вариант PCI с частотой 33 МГц и шириной 32 разряда не предоставлял требуемой скорости обмена для дублирующих путей на Fibre Channel (132 Мбайт/с против 2x1 Гбит/с, т.е. примерно 250 Мбайт/с).
Дисковый массив
Еще не так давно для того, чтобы разместить несколько десятков гигабайт информации, требовалось строить иерархическую систему хранения, в которой относительно небольшая часть данных располагалась на жестких дисках, мало используемые данные перемещались специальными программными обеспечением на более емкие и дешевые магнитооптические диски, а совсем редко используемые — на магнитные ленты. Так выстраивалась трехуровневая система с приемлемой относительной стоимостью хранения информации, хотя и в ущерб производительности.
Современные жесткие диски стали значительно вместительнее. Магнитооптические же технологии не получили достойного развития. Ленточные накопители сделали за это же время большой шаг вперед как по емкости, так и по скорости обмена данными и доступа к ним. В качестве одного из возможных современных решений можно указать на семейство дисковых хранилищ Compaq Enterprise Modular Array 12000.
Модель EMA 12000 D14 имеет в своем составе дисковый RAID-контроллер (уровни 0, 1, 0+1, 3, 5) с поддержкой интерфейсов Wide Ultra 2/3, кэш емкостью 256 Мбайт с возможностью расширения до 512 Мбайт. Связь с управляющим компьютером осуществляется через сеть данных по соединению Fibre Channel (FC) на скорости 1 Гбит/с. Имеется возможность установки резервного FC-контроллера с прозрачным переключением на него в случае сбоя. Диски размещаются в 9 полках по 14 дисков; таким образом, при применении 72-гигабайтных дисков получится 9,1 Тбайт «сырой» емкости. Для повышения отказоустойчивости хранилища диски организуются в массив RAID уровня 3 или 5 в зависимости от типа преобладающих операций ввода/вывода (короткие, до 64 Кбайт, запросы лучше обрабатываются дисковыми массивами уровней 3 или 4; в рассматриваемом проекте преобладают длинные последовательные запросы, поэтому предпочтительнее оказался уровень 5). Для этого придется выделить по одному диску из полки; кроме того, для автоматического восстановления массива в случае выхода из строя какого-либо диска, целесообразно также оставить еще по одному диску на полку в «горячем резерве». Это даст возможность обслуживающему персоналу заменить вышедший из строя диск без риска нарушить целостность системы. Эффективная емкость системы составит 7,8 Тбайт (9 полок по 12 дисков на 72 Гбайт). Дисковый массив предназначен для работы для работы в гетерогенной среде и поддерживает широкий спектр операционных систем.
Волоконно-оптические соединения
Ясно, что большие объемы дисковой памяти в корпусе компьютера не уместить. Одной из первых возможностей внешнего размещения устройств хранения была шина SCSI, которая позволила подключать к одному контроллеру до 15 устройств, удаленных на расстояние до 25 м. Со временем потребности в увеличении скорости передачи данных и расстояния между устройствами выросли настолько, что все усовершенствования SCSI оказались не в состоянии их удовлетворить. На выручку пришли волоконно-оптические технологии, зарекомендовавшие себя в локальных и глобальных сетях.
Поначалу оптическим кабелем связывали непосредственно контроллер в компьютере с дисковой стойкой. Затем эта идея трансформировалась в сети хранения, к которым стали подключать не только диски, но и другие устройства хранения, например, ленточные и оптические накопители и библиотеки. Применение оптоволокна позволило обойти ограничения, налагаемые электрическим интерфейсом. Скорость передачи данных сначала увеличилась до 100 Мбит/с, потом до 1 Гбит/с, а сегодня уже есть оборудование, способное работать со скоростью 2 Гбит/с. Расстояние между устройствами при этом тоже значительно увеличилось; при использовании соответствующего оптоволокна и излучателей оно может доходить до 100 км без дополнительной ретрансляции сигнала. Еще одним важным моментом стала возможность, в отличие от SCSI, подключать к одной системе хранения более двух управляющих компьютеров, что позволяет строить многоузловые кластеры. (Справедливости ради стоит отметить, что Fibre Channel на небольших расстояниях можно реализовать и на медной проводке.)
Многоузловые кластеры, а также сети с несколькими хранилищами, требуют для соединения компонентов концентраторов или коммутаторов, количество которых зависит от количества компонентов в сети хранения или кластере, необходимой скорости обмена данными между узлами и других условий. Скажем, для одного компьютера и шести дисковых стоек вполне достаточно 8-портового концентратора, а четыре компьютера и две стойки лучше обслуживаются коммутатором. В нашем проекте было предложено разместить элементы кластера не просто в разных комнатах, но и на разных этажах.
Необходимыми составляющими будут оптические кабели, оптоэлектронные преобразователи (GBIC — GigaBit Interface Converter), FC-контроллеры для управляющих компьютеров и FC-концентраторы или FC-коммутаторы в зависимости от условий. Если помещения находятся на расстоянии до 200 м друг от друга, то можно использовать коротковолновые преобразователи GBIC-SW и многомодовый кабель диаметром 62,5 микрона. Если же расстояние между ними от 200 до 500 м, то можно использовать все те же коротковолновые преобразователи, но многомодовый кабель должен быть диаметром 50 микрон. При расстояниях до 10 км необходимо использовать длинноволновые преобразователи и одномодовый кабель диаметром 9 микрон. Для организации катастрофоустойчивого решения с выносом элементов на расстояние до 100 км потребуется конвертер для очень длинных дистанций GBIC-VLD и одномодовый оптический кабель диаметром 9 микрон.
Предположим, что расстояние не превысит 200 м, тогда понадобятся: FC-коммутатор на 8 портов для обеспечения пропускной способности до 8 Гбит/с; FC-контроллеры для компьютеров; коротковолновые преобразователи для коммутатора и для контроллеров в компьютерах и дисковых массивах; 62,5-микронный многомодовый кабель.
Схема соединений в двухузловом кластере представлена на рис. 1.
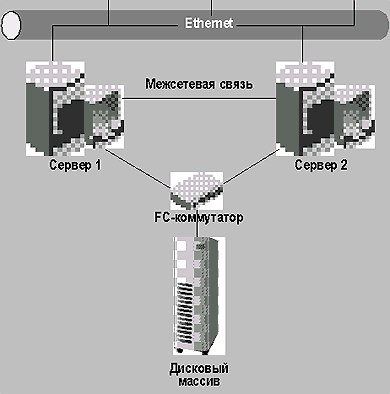
|
| Рис. 1. Двухузловой кластер |
Резервное копирование
В последнее время получило распространение мнение, что защита оперативных данных может быть надежной и без резервного копирования — достаточно создать дисковый массив RAID. Да, дисковые массивы позволяют безостановочно обрабатывать данные даже в случае сбоя одного из дисков, входящих в массив, однако они не защищают логическую целостность данных, которые могут быть нарушены или потеряны из-за алгоритмических ошибок или программных сбоев. Особая статья — человеческий фактор. Самая распространенная и обидная ошибка — случайное удаление нужных данных. Еще одна напасть — вирусы, преднамеренно портящие программы и данные или удаляющие их. В данном случае с точки зрения RAID-контроллера выполняемые действия абсолютно невинны: происходят обычные операции чтения/записи/стирания, а файлов на дисках не останется! Тут спасти в состоянии только заранее подготовленная, актуальная и надежно хранящаяся резервная копия. Иногда может пригодиться не последняя, а более ранняя копия (скажем, если какие-то файлы попали «в резерв» уже зараженными); можно попытаться восстановить их в первозданном виде из предыдущей копии. Другой пример: собранные данные некоторым образом обработаны, а сохранены именно полученные результаты.
Современные технологии магнитных лент позволяют помещать на одну кассету до 110 Гбайт данных без сжатия и хранить их до 30 лет, однако жесткие требования к условиям хранения лент (постоянная температура и влажность) сохраняются. Еще одним достаточно сложным условием является необходимость регулярного перематывания архивных лент (а иногда и чтения/перезаписи) для устранения эффекта размагничивания. В этом отношении оптические и магнитооптические носители вне всякой конкуренции; гарантированное время сохранности данных на них достигает 100 лет, нет размагничивания и осыпания носителя, нет боязни внешних магнитных полей и повышенных температур. К сожалению, емкость носителей этих типов для хранения информации действительно большого объема пока недостаточна.
Непременное условие для катастрофоустойчивых решений хранения — наличие дублирующей резервной копии за пределами основного здания (предприятия, города). Хранилище следует оснастить системой поддержания микроклимата, а ленты рекомендуется сохранять в пожаростойком шкафу. Необходимо предварительно согласовать регламент доступа в помещения с резервными лентами в случае чрезвычайных ситуаций на основной площадке. Например, для производств с непрерывным циклом неприемлемо хранить ленты в отделении банка, закрытом в выходные дни.
Такой объем данных не поместить на одну ленту — нужна роботизированная библиотека достаточной емкости. В качестве такой библиотеки можно взять Compaq ESL9198SL Enterprise Library на 198 слотов для ленточных кассет, комплектуемую стримерами числом от 1 до 8, с общей емкостью до 21,78 Тбайт. Одновременное использование нескольких стримеров позволит поднять скорость копирования до 316,8 Гбайт/час (без сжатия).
Высокая надежность механизмов библиотеки гарантирует более 1 млн. циклов загрузки/выгрузки кассет. Значительный уровень готовности обуславливается применением компонентов, заменяемых в горячем режиме (могут заменяться стримеры, контроллеры и блоки питания), а также избыточностью ключевых узлов. Благодаря применению сети хранения трафик резервного копирования не попадает в пользовательскую компьютерную сеть (см. рис. 2).
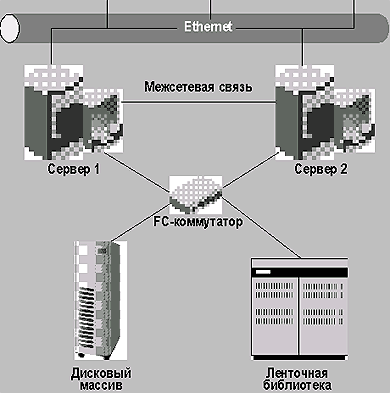
|
| Рис. 2. Схема подключения для резервного копирования |
Отказоустойчивость
Отказоустойчивость можно рассматривать в двух аспектах: с точки зрения сбоя или поломки одного из компонентов и с точки зрения техногенных катастроф. Отсюда и два подхода к достижению отказоустойчивости — локальное расположение и территориально разнесенное.
«Локальная» отказоустойчивость
Контроллеры дисковых массивов не только управляют обменом данными с дисками массива, но и выполняют ряд других функций, определяемых встроенными программами. Наиболее актуальными для нас являются клонирование (cloning) и моментальные снимки (snapshot). Клонирование позволяет иметь зеркальную копию всего 9,1-терабайтного хранилища, благодаря чему вторую дисковую стойку можно разместить удаленно, например, в помещении, где находится второй узел кластера. Помимо увеличения надежности, клонирование делает возможными интенсивные вычисления с использованием дисковой подсистемы на втором узле кластера без ущерба производительности основного массива.
Моментальные снимки «замораживают» состояние дискового массива и позволяют манипулировать целостными данными, например, для длительных вычислений, тестирования или резервного копирования, тогда как непрерывно могут продолжать поступать новые данные. Временное окно для резервного копирования можно сократить с часов до нескольких минут. Чтобы при этом избежать коммуникационных проблем, необходимо задействовать дублирующие пути прохождения данных в сети хранения.
Все рассмотренные компоненты (компьютеры, дисковые стойки и ленточная библиотека) могут комплектоваться дублирующими FC-контроллерами и другими ключевыми элементами, например, блоки питания, вентиляторы, диски, стримеры и др. Даже избыточные блоки питания могут запитываться от независимых линий электропитания (рис. 3).
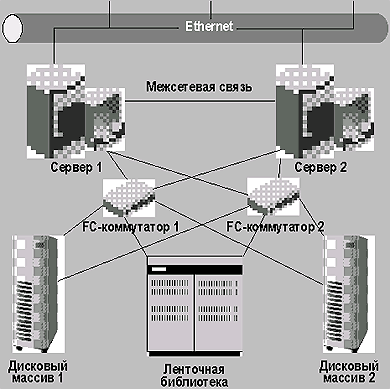
|
| Рис. 3. Отказоустойчивая система хранения с дублирующими связями |
Географическая разнесенность
В особо ответственных случаях недостаточно обеспечить только локальную отказоустойчивость; создаются запасные площадки для управления и обработки информации. Посредством волоконно-оптических соединений можно обеспечить высокоскоростную связь на весьма значительном расстоянии. Если по каким-либо причинам невозможно организовать собственный оптический канал, то можно использовать арендованные каналы, которые обычно предоставляют только часть от общей пропускной способности физического канала («порции» могут составлять, например, 64 Кбит/с или 2 Мбит/с). Для кластеров этого, как правило, недостаточно: для обеспечения когерентности данных в разных узлах им требуется очень высокая скорость обмена данными. Существует несколько возможных решений данной проблемы; рассмотрим одно из них.
На удаленную площадку управления выносится третий узел кластера, который находится в режиме постоянной готовности (standby), а не участвует в активной обработке данных; благодаря этому минимизируется передаваемый этому узлу поток информации. По большому счету, узел надо обеспечить межсерверной связью, по которой между узлами передается так называемое «сердцебиение» (heartbeat) — сигнал о состоянии узлов кластера. Если такой сигнал от одного из узлов пропадает, считается, что узел вышел из строя; в таком случае по заранее определенному алгоритму его задачи передаются другим узлам. Этот сигнал практически не занимает полосу пропускания, но чувствителен к задержкам.
В случае полной остановки работы основного центра управления (а не только выхода из строя узлов кластера), запасная площадка должна взять на себя всю нагрузку. Это означает, что на запасной площадке должны быть не только вычислительные ресурсы, но и собственно данные — в полном объеме и актуальном состоянии. Напрашивается вывод о необходимости организовать на запасной площадке дисковое хранилище такой же емкости, что и на основной и с точно такими же данными. При непосредственном волоконно-оптическом соединении это не проблема; другое дело, как обеспечить когерентность данных в удаленных хранилищах при низкоскоростных каналах связи. Для решения этой задачи Compaq предлагает инструментарий Data Replication Manager, позволяющий реплицировать данные из одной системы хранения на другую. Репликация данных может производиться как в синхронном, так и в асинхронном режимах.
Data Replication Manager обеспечивает катастрофоустойчивость хранилищ данных, а также перенос рабочей нагрузки — причем без участия управляющего компьютера. Спаренные контроллеры дискового массива при использовании этого инструментария позволяют с помощью FC-коммутаторов производить зеркалирование на больших расстояниях. Данные копируются с локального контроллера напрямую в другой контроллер на удаленной площадке.
В синхронном режиме данные одновременно записываются в кэш локального и удаленного контроллеров. Статус выполнения операции ввода/вывода посылается управляющему компьютеру только тогда, когда все дисковые массивы завершат обновление своих данных. В асинхронном режиме статус выполнения операции ввода/вывода посылается управляющему компьютеру сразу, как только данные будут записаны локальным контроллером (т.е. еще до того, как это успеют сделать удаленные системы). Асинхронный режим ускоряет время отклика системы, но удаленные копии могут не полностью совпадать с последними данными на локальной площадке.
С DRM удаленные площадки посредством шлюзов FC-ATM можно разнести на расстояние сотен и даже тысяч километров друг от друга. Технология ATM идеально подходит для случаев, когда расстояние между защищаемыми площадками очень велико или когда нет возможности организовать прямое волоконно-оптическое соединение. Шлюз FC-ATM поддерживает скорости доступа от 1,544 Мбит/с до 155 Мбит/с; с помощью шлюза можно связать несколько удаленных площадок для репликации данных по разделяемым или арендованным каналам E1 (2,048 Мбит/с). При передаче данных по общедоступным каналам связи данные для обеспечения необходимой защищенности могут быть зашифрованы. Завершенная схема катастрофоустойчивого решения по хранению данных большого объема представлена на рис. 4.
Аппаратный мониторинг
Важным аспектом функционирования сложной системы является слежение за ее основными параметрами и предупреждения в случае выхода параметров за определенные границы, так как это имеет значительное влияние на производительность, надежность и отказоустойчивость. Все компоненты системы имеют встроенные функции аппаратного мониторинга своего состояния. Эту информацию может собирать Compaq Inside Manager или другая SNMP-консоль управления.
Compaq Inside Manager может отображать собранную статистику, задавать множество параметров работы компонентов системы, а также управлять в реальном режиме времени многими из компонентов. Встроенные в компоненты средства постоянной самодиагностики позволяют предсказать ухудшение параметров до фактического отказа оборудования, что позволяет заменить деградирующее оборудование до его поломки или сбоя. Compaq Inside Manager обладает возможностями оповещения администраторов системы о наступлении критических для работоспособности системы или заранее предопределенных событиях: остановка вентилятора, переключение на запасной волоконно-оптический канал, превышение определенного порога или ухудшение работы конкретного жесткого диска. Уведомления могут высвечиваться на консоли, рассылаться по электронной почте, передаваться на пейджеры и телефоны.
Программное обеспечение
Централизованное управление доступом
Сегодня никого не нужно убеждать, что доступ должен быть защищенным и контролируемым. Другое дело, как обеспечить этот защищенный доступ в разнородных средах как для внутренних пользователей сети, так и для партнеров, заказчиков и, возможно, других пользователей через Internet? Даже просто вести списки быстро растущего числа пользователей отдельных программ или баз данных становится невероятно трудно. А с учетом того, что каждая система имеет свои правила и способы регистрации пользователей и предоставления им доступа, человеку справится с этим просто невозможно. Единственный выход — централизовано и унифицировано хранить информацию в службе каталогов. На сегодняшний день существует несколько таких служб, которые при сходной базовой функциональности сильно отличаются друг от друга масштабируемостью, возможностью работы на разных платформах и поддержкой открытых стандартов.
Единственная служба каталогов, поддерживающая все основные платформы, — это NDS eDirectory компании Novell. Служба способна работать более чем с миллиардом объектов. Являясь базой систем управления идентификационными параметрами, политикой и правами доступа, каталог лежит в основе любого комплексного решения безопасности. eDirectory позволяет собирать, хранить, систематизировать и использовать всю информацию о пользователях, необходимую для назначения индивидуальных прав доступа сотрудникам, клиентам и партнерам.
Во многих организациях для решения разных задач используются различные платформы; как показывает практика, экономически это часто более выгодно, чем приверженность продуктам одного производителя. Однако у такого решения есть и оборотная сторона: усложняется задача управления всем этим разнообразием. При небольшом числе пользователей она решается простым увеличением штата администраторов; но есть и более элегантное решение — NDS Authentication Services, обеспечивающее защищенный доступ и занимается созданием, удалением и модификацией учетных записей пользователей, синхронизацией паролей и их перераспределением между корпоративными платформами. Novell SecureLogin обеспечивает защищенный доступ к приложениям. SecureLogin предоставляет пользователям доступ практически ко всем корпоративным приложениям с помощью однократной регистрации в сети.
Novell Modular Authentication Service позволяет задействовать множество способов аутентификации, включая пароли, маркеры, смарт-карты, биометрию, цифровые сертификаты, причем как по отдельности, так и в произвольной комбинации. С помощью его можно построить градуированную систему разграничения полномочий; например, для запуска определенных программ и доступа к данным достаточно ввести имя пользователя и пароль, для доступа к другим нужно дополнительно вставить смарт-карту, а для изменения особо важных данных — еще и считать отпечаток пальца.
Организация кластера и хранилища данных
Кластеры на платформе Intel можно построить с помощью ряда сетевых операционных систем, в том числе, Novell NetWare, Windows NT, Windows 2000 и некоторых вариантов Linux. Windows 2000 Server поддерживает максимум 4 процессора, не поддерживает кластеры и не умеет работать с сетями хранения. Windows 2000 Advanced Server поддерживает до 8 процессоров и двухузловые кластеры; общая емкость дисковой подсистемы ограничена 2 Тбайт; поддерживаются сети хранения, но для управления ими требуются утилиты сторонних производителей. Windows 2000 Datacenter Server поддерживает до 32 процессоров и 4-узловой кластер, но поставляется по особому заказу, а емкость дисковой подсистемы ограничена 2 Тбайт.
NetWare 5.1 и 6.0 поддерживают до 32 процессоров и кластеры до 32 узлов. В состав NetWare 6.0 входит журналируемая 64-разрядная файловая система Novell Storage Services, которая поддерживает тома емкостью до 8 Тбайт и допускает монтирование до 255 томов. Поддерживаются сети хранения.
Одним из достоинств новой версии NSS является возможность бронирования (overbooking) места для логических томов, суммарная емкость которых может превышать реально имеющееся физическое дисковое пространство. Когда данные займут все свободное место, можно будет просто увеличить число дисков или добавить дополнительную дисковую стойку и присоединить их к имеющимся томам на ходу, не останавливая сервер и не прерывая работы приложений и пользователей. Журналирование обеспечивает надежное и быстрое восстановление работоспособности томов после сбоев. Поддерживается функция моментальных снимков (snapshot), позволяющая программам резервного копирования делать целостные резервные копии даже открытых файлов. Благодаря поддержке сжатия увеличивается доступное дисковое пространство. Предусмотрен механизм дисковых квот для пользователей и отдельных каталогов, что позволяет контролировать занимаемое дисковое пространство.
Программное обеспечение резервного копирования
Описанное решение по хранению данных накладывает довольно жесткие требования на программаму резервного копирования. Программа резервного копирования должна поддерживать: работу с различными платформами; работу в автономном режиме по расписанию; роботизированные ленточные библиотеки; сети хранения. Такими возможностями обладают программные пакеты Veritas Backup Exec, CA ARCserve и Legato Networker. Некоторые пакеты позволяют организовывать несколько стримеров в ленточной библиотеке в так называемый «избыточный массив независимых лент» (RAIT — redundant array of independed tape), что дополнительно повышает надежность резервной копии.
Павел Гарбар (p.garbar@spb.croc.ru) — специалист компании «КРОК Северо-Запад».
