

В статье проанализирована предложенная компанией AMD архитектура x86-64 и рассмотрены некоторые ее достоинства и недостатки по сравнению с другими 64-разрядными архитектурами, в первую очередь Intel/HP IA-64. Дан краткий обзор микроархитектуры процессоров AMD Hammer, в которых впервые будет реализована архитектура x86-64. Характеристики Hammer сопоставлены с другими современными и перспективными высокопроизводительными процессорами.
Если все высокопроизводительные микропроцессоры RISC-архитектуры, выпускающиеся с конца 90-х годов, являются 64-разрядными (Сompaq/DEC Alpha, SGI/MIPS R1x000, IBM Power, HP PA-8x00, Sun UltraSPARC), то основные CISC-архитектуры (Intel x86, IBM S/390) переходят от 32 к 64 разрядам только сейчас (IA-64 [1, 2], IBM z/Architecture [3]).
Переход от S/390 к z/Architecture выглядит достаточно естественным расширением, в то время как переход от x86 (ныне IA-32) к IA-64 означает, по сути, полную смену системы команд. Думаю, это обусловлено тем, что х86 начала свое историческое развитие с 8-ми, а затем 16-разрядных систем. Поэтому остававшаяся по соображениям совместимости относительно статичной в течение очень многих лет система команд со временем стала довольно «неестественной» с точки зрения других 32-разрядных процессоров.
Итак, если IBM перешла к 64-разрядной платформе эволюционным путем, переход от х86 к IA-64 — это революция; совместимость обеспечивается лишь путем аппаратной эмуляции. Пока непонятно, хочет ли Intel в будущем вообще отказаться от IA-32 в пользу IA-64, но то, что все программное обеспечение для IA-64 нужно как минимум перетранслировать — не говоря уже о дальнейшей оптимизации под IA-64 — это кажется ясным. Очевидно, переход на платформу IA-64 займет немало времени и будет стоить весьма дорого.
Совершенно другим путем пошла компания AMD. Она предложила собственную модернизацию архитектуры x86, которая (как и в случае с IBM) является естественным эволюционным развитием — подобно тому, как х86 в свое время была модернизирована с 16 до 32 разрядов.
Почему же 32-разрядные CISC-платформы становятся 64-разрядными только сейчас, хотя потребности в 64-разрядных приложениях стали достаточно большими уже несколько лет назад? Кроме уже отмеченной сложности перехода (очевидной в случае IA-64 и z/Architecture) следует указать и на резкое удешевление оперативной памяти при одновременном росте емкости модулей памяти. В результате 4-гигабайтный предел емкости для 32-разрядных систем оказывается вполне достижим уже в современных ПК. Так почему бы не поднять производительность ПК-сервера за счет установки дополнительной памяти, коль скоро это становится не так дорого?
Архитектура х86-64
Представляется, что отличия архитектуры х86-64 от IA-32 даже меньше, чем отличия IBM z/Architecture от S/390. В AMD всячески стараются подчеркнуть, что внесенные изменения минимальны [4], хотя анализ полного описания [5] позволяет выявить достаточное количество мелких нюансов, касающихся, правда, в первую очередь разработчиков системного программного обеспечения, а не приложений.
Ключевых же изменений х86-64 по сравнению с сегодняшним состоянием IA-32 действительно не так много и они в определенном смысле аналогичны тем, которые были внесены при переходе от 16-ти к 32-разрядной архитектуре х86. Эти нововведения включают:
- 64-разрядные виртуальные адреса (в конкретной реализации возможна меньшая разрядность);
- "плоское" (flat) адресное пространство с единым пространством кодов, данных и стека;
- 64-разрядный счетчик команд (RIP);
- режим адресации относительно счетчика команд;
- расширение регистров общего назначения (целочисленных) до 64 разрядов;
- добавление 8 новых регистров общего назначения (R8-R15);
- добавление еще 8 SSE-регистров XMM8-XMM15 разрядностью 128 (соответствует предложенному Intel расширению SSE2).

|
| Рис. 1. Пример расширения регистров общего назначения |
«Указания» на дополнительные регистры и размеры данных вводятся как префикс команд. Набор основных регистров x86-64 представлен на рис. 1. Регистры являются 64-разрядными, за исключением 32-разрядного регистра EFLAGS, 128-разрядных регистров ХММ и 80-разрядных регистров с плавающей запятой ST. Архитектура x86-64 включает, в частности, SSE2-расширения IA-32, представленные в Pentium 4.

На рис. 1 показано, каким образом расширены новые 64-разрядные регистры относительно 32-разрядных регистров в IA-32. Для выполнения 16-разрядных операций регистр А адресуется как АХ, для выполнения 32-разрядных операций — как EAX, а для выполнения 64-разрядных — как RAX. При выполнении 32-разрядных операций, в которых целочисленный регистр служит регистром результата, 32-разрядные значения дополняются нулями до 64-разрядных. 8-ми и 16-разрядные операции над целочисленными регистрами сохраняют старшие разряды неизменными [4].
Для работы с 64-разрядной адресацией в х86-64 введен режим Long Mode (назовем его «расширенным режимом»). Режим работы задается управляющим битом LMA (Long Mode Active), который взводится, если микропроцессор переходит в расширенный режим. В расширенном режиме регистры сегментов ES, DS, FS, GS, SS игнорируются. В регистре CS (дескриптор сегмента кода) находятся биты, уточняющие режимы работы микропроцессора.
В х86-64 расширенный режим имеет два «подрежима»: 64-разрядный режим и режим совместимости. В режиме совместимости обеспечивается двоичная совместимость с 16-ти и 32-разрядными режимами х86. Выбором подрежима управляет бит CS.L. Если он установлен в 0 (режим совместимости), 64-разрядная операционная система, работая в режиме LMA, может выполнять старые 16-ти и 32-разрядные х86-приложения. За выбор размера операнда отвечает бит CS.D.
По умолчанию, в 64-разрядном режиме (взведен бит LMA, CS.L = 1, CS.D = 0) применяются 64-разрядные адреса и 32-разрядные операнды. Используя префиксы команд, можно изменить размер операнда (установить его равным 64 или 16 разрядам), а также изменить размер адреса (установить равным 32 разрядам). В таблицах 1 и 2 указаны основные допустимые типы режимов процессора и режимов работы операционной системы и приложений.
Приведенные данные показывают, что процессоры с архитектурой х86-64 могут работать как с уже существующими 16-ти и 32-разрядными, так и с новыми 64-разрядными операционными системами. В последнем случае в режиме совместимости возможно одновременное выполнение 16-ти и 32-разрядных приложений благодаря установке соответствующих бит в индивидуальных сегментах кодов. При этом 32-разрядные приложения могут использовать первые 4 Гбайт виртуальной памяти.
Для выяснения особенностей микропроцессоров с архитектурой х86-64 необходимо анализировать регистры EAX/EBX/ECX/EDX, в которые помещаются результаты выполнения команды CPUID (при ее вызове, как и ранее, в EAX нужно положить 8000_0000h). Если 29-й бит в EAX равен 1, микропроцессор работает в расширенном режиме.
В х86-64 имеется еще ряд интересных усовершенствований, особенно для задач системного программирования. В качестве примера отметим введение нового регистра приоритета задач TPR, который используется для ускорения обработки прерываний. За подробностями отсылаем читателей к описанию x86-64 [5].
Микроархитектура Hammer
Процессор Athlon относится к седьмому поколению архитектуры x86, реализованному компанией AMD. Первые процессоры, в которых будет реализована архитектура х86-64, получили кодовое название Hammer и представляют собой восьмое поколение х86-процессоров от AMD. В них продолжилась тенденция определенного отхода системы команд процессоров AMD от полной тождественности с Intel x86. Однако если прежде отличия были связаны с введением AMD новых команд 3DNow!, то теперь Hammer, в отличие от х86, становится 64-разрядным. В Hammer применяются 64-разрядные внутренние «шины», используемые для обмена данными. Виртуальное адресное пространство является 48-разрядным, а пространство физических адресов — 40-разрядным.
Целями AMD при создании данного семейства микропроцессоров, помимо очевидной цели поддержи х86-64, были [6]:
- по возможности минимальное увеличение площади микросхемы;
- обеспечение возможностей дальнейшего беспрепятственного роста тактовой частоты процессора на современном уровне развития технологий;
- обеспечение при этом ускорения как 64-разрядных, так и 32-разрядных приложений. Общее представление о микроархитектуре Hammer дает рис. 2 [6, 7].
В современных наиболее мощных RISC-процессорах имеется тенденция интеграции в микропроцессор кэш-памяти второго уровня большой емкости. Как Intel, так и AMD в своих высокопроизводительных процессорах не так давно уменьшили емкость кэша второго уровня с 512 Кбайт до 256 Кбайт, одновременно интегрировав его в процессор. Но в Pentium 4 Northwood разработчики Intel вновь расширили кэш второго уровня до 512 Кбайт. Соответствующие официальные данные по Hammer отсутствуют; между тем емкость кэша второго уровня может сильно повлиять на его производительность. По мнению некоторых аналитиков, емкость кэша второго уровня в старших моделях Hammer будет вчетверо выше, чем у современных моделей Athlon.
Буферы быстрой переадресации в данном процессоре по сравнению с Athlon модернизированы. I-TLB первого уровня в Hammer имеет емкость 40 строк (на 16 строк больше, чем раньше) и является полностью ассоциативным. У D-TLB первого уровня те же характеристики. Оба буфера TLB обеспечивают работу со страницами памяти емкостью 4 Кбайт, 2 Мбайт и 4 Мбайт.
I-TLB второго уровня, как и D-TLB второго уровня, содержат по 512 строк (вдвое больше, чем в Athlon) и являются 4-канальными частично-ассоциативными. Как указано в [6], TLB обладают уменьшенными по сравнению с Athlon задержками. Кроме того, аппаратно реализована возможность разделения TLB между несколькими процессами (для этого предусмотрен специальный «фильтр поджога»).
Очевидно, что увеличение емкости TLB и поддержка страниц памяти больших размеров ориентированы на использование в системах с большой емкостью памяти; это естественно для 64-разрядных приложений. Возможность разделения TLB, в свою очередь, может повышать производительность многозадачных операционных систем на серверных приложениях.
Традиционным направлением совершенствования современных микропроцессоров является улучшение точности предсказания переходов. В Hammer имеется массив адресов переходов емкостью 2К строк, а также таблица глобальной истории переходов, содержащая 16К 2-разрядных счетчиков (в 4 раза больше, чем у Athlon). Наконец, емкость стека адресов возврата — 12 строк.
Важной особенностью, способствующей повышению производительности, является интеграция в Hammer контроллера оперативной памяти. Это позволяет и пропускную способность увеличить, и уменьшить задержки. Данные характеристики будут автоматически улучшаться с ростом частоты процессора. Для архитектуры х86 эта особенность уникальна; Compaq же в своих новейших процессорах Alpha EV7 идет по такому же пути.
Контроллер памяти будет иметь интерфейс шириной 8 или 16 байт к оперативной памяти типа DDR. В последнем случае речь идет о двухканальной DDR-памяти, по 4 регистровых DIMM-модулей на канал. AMD обещает поддержку как регистровых, так и небуферизованных DIMM-модулей для памяти типа DDR PC1600/PC2100/PC2700. При использовании PC2700 в двухканальном варианте пропускная способность оперативной памяти достигнет значения 5,3 Гбайт/с. Для сравнения, процессор Intel McKinley, который вследствие особенностей архитектуры IA-64 нуждается в повышенной пропускной способности оперативной памяти, будет снабжен системной шиной лишь немного быстрее — 6,4 Гбайт/с.
Применение при построении систем на базе Hammer технологии HyperTransport позволит уменьшить задержки оперативной памяти с ростом тактовой частоты микропроцессора, автоматически повышать пропускную способность так называемых snoop-проб при поддержании когерентности кэша в многопроцессорных системах с ростом частоты и, наконец, масштабировать пропускную способность и емкость оперативной памяти с ростом числа процессоров в системе.
Фронтальная часть конвейера включает выборку и декодирование команд (рис. 2). Логика работы этих стадий в Hammer усложнилась, возросла степень упаковки команд, направляемых декодерами к планировщикам. По сравнению с Athlon длина этой части конвейера возросла на 2 стадии, так что общая длина целочисленного конвейера Hammer равна 12, а конвейера с плавающей запятой — 17 стадий [6]. По мнению разработчиков, это должно способствовать беспроблемному росту тактовой частоты процессора по мере совершенствования технологии изготовления. Первоначально планируется использовать 0,13-микронную технологию «кремний-на-изоляторе»; во второй половине 2003 года планируется переход к 0,09 мкм.
Надо отметить, официальные данные о площади, занимаемой Hammer, отсутствуют. Между тем, появились сообщения о том, что процессор ClawHammer будет обладать площадью всего 105 мм2, в то время как Athlon/Palomino, выполненный по той же технологии на 0,13 мкм — 80 мм2. Для сравнения, площадь McKinley, судя по представленным Intel на международной конференции ISSCC ?2002 данным, — 464 мм2.
Недостатки и достоинства длинных конвейеров хорошо известны: легче увеличивать тактовую частоту, но больше потери на перезаполнения конвейера, в частности, при неправильном предсказании перехода. Интересно сопоставить длину конвейера Hammer с другими современными микропроцессорами Intel. В Pentium 4, добившемся рекордных частот в 2,2 ГГц, по сравнению с Pentium III длина конвейера благодаря использованию технологии HyperPipeline возросла вдвое — до 20 стадий. Это имело ту же цель — обеспечение беспрепятственного роста тактовой частоты; в Intel говорят о 10 ГГц к 2005-2006 годам. В McKinley длину конвейера, наоборот, сократили — до 8 стадий против 10 в Itanium, но его ожидаемая частота — 1 ГГц.
Производительность, как известно, зависит не только от тактовой частоты, но и от числа реально выполняемых за такт команд. По утверждению AMD [6, 7], в Hammer число это повысится. А вот на какой частоте будет работать Hammer, не сообщается; можно предположить, что этот показатель окажется около 2 ГГц.
Построение систем на базе Hammer
Мы рассмотрели основные особенности микроархитектуры Hammer, за исключением применения технологии HyperTransport. Она используется в Hammer как для подсоединения системы ввода-вывода, так и для организации межпроцессорных связей. Фактически благодаря встроенному в Hammer контроллеру оперативной памяти и применению технологии HyperTransport в Hammer интегрированы основные функции набора микросхем (точнее говоря, северного моста).
Собственно технология HyperTransport развивается одноименным консорциумом, основанном компаниями AMD, Sun Microsystems, Cisco Systems, Nvidia, Transmeta и Apple Computer. Думаю, потребности в разработке такой технологии диктовались в первую очередь возникновением узких мест в системах ввода/вывода в ПК и вообще использованием шин PCI, характеристики производительности которых не удовлетворяют требованиям современных высокопроизводительных сетевых плат и каналов ввода/вывода для жестких дисков.
Каналы HyperTransport при том же числе контактов, что и PCI, обеспечивают гораздо более высокую пропускную способность: пиковая величина ее составляет 3,2 Гбайт/с. Каналы HyperTransport имеют ширину 16 разрядов, обеспечивая 1,6 миллиардов передач в секунду в каждом направлении. HyperTransport позволяет осуществить соединения типа «точка-точка» с полнодуплексным режимом и расщепленной обработкой транзакций. Такие характеристики данной технологии позволяют использовать ее и для организации межпроцессорных связей; в последнем случае, в отличие от ввода/вывода, применяется вариант HyperTransport с поддержанием когерентности кэша.
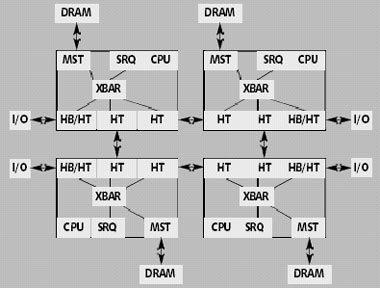
|
| Рис. 3. Схема построения 4-процессорных систем на базе Hammer |
Процессоры Hammer имеют по три порта для каналов HyperTransport (рис. 3), плюс порт к контроллеру оперативной памяти. Поэтому в состав процессора введен коммутатор ХВОХ [6], который маршрутизирует команды и данные между этими портами и интерфейсом системных запросов (очередь SRQ). Эта очередь имеет длину 24 строки, а очередь к DRAM-контроллеру (Memory Command Queue) — 20 строк [7]. Для связи с подсистемой ввода/вывода в Hammer используется мост Host Bridge, тогда два других канала HyperTransport задействуются в межпроцессорных обменах.
Единственное, что не встроено в Hammer — это интерфейс с AGP; поэтому микросхеме, занимающей место северного моста (рис. 4), необходимо поддерживать этот интерфейс. Предполагается, что это будет AGP 8X.
С этой микросхемой соединен южный мост. Хотя AMD традиционно предлагает набор микросхем для своих новых процессоров и сделает это, очевидно, и для Hammer, уже известно о разработках южного моста для этого процессора компаниями Nvidia и VIA Technologies. Кроме того, в многопроцессорных системах ожидается применение «шлюза» между HyperTransport и PCI-X [7]; возможно применение аналогичных средств для других стандартов ввода/вывода.

|
|
Рис. 4. Архитектура многопроцессорных систем на базе Hammer а) однопроцессорная система б) двухпроцессорная система в) четырехпроцессорная система |
Схемы, представленные на рис. 4, демонстрируют эффективность построения многопроцессорных систем на базе Hammer. В таких компьютерах с ростом числа процессоров масштабируются не только вычислительная мощность, емкость и пропускная способность оперативной памяти, но и ресурсы подсистемы ввода/вывода. Так, в 8-процессорной системе доступными будут 64 (8х8) DIMM-модуля (до 128 Гбайт) и 4 канала HyperTransport с суммарной пропускной способностью 25 Гбайт/с для дуплексной передачи.
AMD анонсировала набор микросхем серии 8000, который будет доступен в четвертом квартале 2002 года. Он включает микросхемы AMD-8151 (организует интерфейс с AGP 3.0), AMD-8131 (мост от HyperTransport к PCI-X) и AMD-8111 (концентратор ввода/вывода, обеспечивает поддержку PCI-32/33 МГц, USB, IDE и т.п.).
Интересно организовано обеспечение когерентности кэша с использованием каналов HyperTransport при числе процессоров от 4 и выше: в обработке соответствующих запросов участвуют несколько образуемых каналами HyperTransport путей между процессорами [7], что способствует ускорению работы. В принципе возможно построение систем с числом процессоров Hammer, большем 8, но для этого понадобится коммутатор HyperTransport.
Задержки при работе с локальной (ближней к микропроцессору) оперативной памятью незначительно возрастают при обращении к «удаленной» памяти. На ненагруженной 4-процессорной системе задержка равна 140 нс, на аналогичной 8-процессорной системе — 160 нс. Это позволяет говорить об архитектуре SMP, а не ссNUMA. Вместе с тем применение технологии коммутации вместо системных шин позволяет достигнуть высоких показателей и по пропускной способности оперативной памяти. Для операций типа копирования она составляет 8 Гбайт/с для 4-процессорной системы, что, по утверждению AMD, существенно выше, чем в шинных архитектурах [7].
В ожидании Hammer
Начало продаж Hammer начнется ориентировочно в третьем квартале 2002 года. Первым микропроцессором данного семейства станет ClawHammer, ориентированный на одно- и двухпроцессорные системы; затем появится SledgeHammer. Хотя по сути Hammer должен вступить в конкуренцию с микропроцессорами архитектуры IA-64 (к тому времени должен появиться и McKinley), можно предположить, что в будущем Hammer окажется в состоянии вытеснить Athlon на всем спектре применений (но на это может уйти не один год). Это означает также, что Hammer может стать конкурентом Pentium 4.
Кроме существующих 32-разрядных операционных систем, на 64-разрядную архитектуру Hammer переносятся NetBSD, FreeBSD и Linux, а также современные разновидности Windows.
Преимуществами х86-64 и Hammer являются:
- совместимость с 16-ти и 32-разрядными приложениями при высоком уровне производительности выполнения;
- относительная (по сравнению с IA-64) простота перехода от х86 и соответственно отсутствие необходимости чрезмерных финансовых затрат на этот переход;
- меньший риск неудачи новой архитектуры;
- простота разработки и реализации;
- небольшая площадь, что повышает выход годных и облегчает масштабирование по тактовой частоте.
Можно сказать, что благодаря выбранному «эволюционному» подходу можно более надежно предсказать успехи в росте производительности.
Перечисленные преимущества сопровождаются и некоторыми потенциально «опасными» для AMD моментами. Архитектура х86-64 не столь «революционна», как IA-64; более того, число регистров по сравнению с современными RISC-процессорами не выглядит достаточно большим, что, как известно, усложняет оптимизацию программ.
AMD придется продемонстрировать, что высоты производительности достижимы главным образом за счет технологии (и соответствующего роста тактовой частоты), но не за счет архитектуры. Пока это успешно доказывает, в частности, Pentium 4, а вот обратных доказательств со стороны IA-64 пока не получено.
Для создания 64-разрядных приложений понадобится разработать оптимизирующие компиляторы, информация о которых пока отсутствует. Наконец, современная компьютерная индустрия стоит на пороге выбора новых стандартов ввода/вывода — Infiniband, PCI-X, 3GIO, HyperTransport. Жесткая привязка к технологии HyperTransport способна вывести AMD в лидеры, но и несет в себе определенный риск.
Что касается областей применения, где нужна 64-разрядная архитектура, то AMD указывает в первую очередь на СУБД, САПР, средства создания цифрового «содержания». По мнению автора, процессоры Hammer могут оказаться активно востребованы на быстро растущем сегменте рынка — кластерах (в первую очередь, Linux-кластерах) с двухпроцессорными узлами.
В настоящее время очень популярной является такая платформа на базе Athlon MP; аналогичные системы на базе Pentium 4/Xeon стоят заметно дороже. При сохранении такого соотношения AMD сможет рассчитывать на успех и в этой части рынка.
Работа поддержана РФФИ, проект 01-07-90072.
Литература
- Михаил Кузьминский, "Краткий обзор IA-64". "Открытые системы", 1999, № 9-10
- Михаил Кузьминский, "Микроархитектура Itanium". Открытые системы, № 9, 2001
- Михаил Кузьминский, "Z-архитектура. Современные 64-разрядные мэйнфреймы IBM". "Открытые системы", 2001, № 10
- "x86-64 Technology White Paper", 2001, AMD
- "AMD 64-Bit Technology. The AMD x86-64 Architecture Programmers Overview", AMD, 2001, Jan.
- "AMD Eight-Generation Processor Architecture. White Paper", AMD, 2001, Oct.
- F. Weber, "AMD Next Generation Microprocessor Architecture", Microprocessor Forum, 2001
Михаил Кузьминский (kus@free.net) — старший научный сотрудник Центра компьютерного обеспечения ИОХ РАН (Москва).
