

DVM-подход к разработке параллельных программ отличается использованием модели параллелизма по данным и управлению. Базирующаяся на этом подходе DVM-система предоставляет программисту языки программирования C-DVM и Fortran-DVM, позволяющие написать один вариант программы для последовательного и параллельного выполнения. Такая программа, помимо описания алгоритма содержит правила его параллельного выполнения, «невидимые» для стандартных компиляторов с последовательных языков и не препятствующие выполнению и отладке DVM-программы как обычной последовательной программы.
В начале 90-х годов получили широкое распространение многопроцессорные системы с распределенной памятью, однако трудоемкость разработки для них параллельных программ препятствовала эффективному использованию их. Было предложено много различных подходов к разработке параллельных программ, созданы десятки различных языков параллельного программирования и множество различных инструментальных средств. В основе того или иного подхода лежит модель программирования, которую нельзя путать с моделью выполнения параллельной программы — эта модель может быть очень близка к модели выполнения, а может значительно от нее отличаться.
Имеются две основные модели параллельного выполнения программы на многопроцессорных компьютерах — модель передачи сообщений и модель общей памяти. В первой параллельная программа представляет собой систему процессов, взаимодействующих посредством передачи сообщений, что может быть использовано на любых многопроцессорных конфигурациях. Во второй параллельная программа представляет собой систему нитей (threads), взаимодействующих посредством общих переменных и примитивов синхронизации. Нить — легковесный процесс, имеющий с другими нитями общие ресурсы, включая общую оперативную память. Эта модель может использоваться только на многопроцессорных системах с общей памятью или с DSM (Distributed Shared Memory — распределенная общая память).
В качестве модели программирования можно выбрать одну из этих моделей, например Фортран+MPI, Си+Pthreads, Occam, однако такая низкоуровневая модель непривычна и неудобна, заставляя иметь дело с параллельными процессами и низкоуровневыми примитивами передачи сообщений или синхронизации. И, главное, программист должен распределять вычисления (а в модели передачи сообщений еще и данные) между процессами. Поэтому вполне естественно, что прикладной программист хотел бы иметь дело с высокоуровневой моделью программирования, которая позволяла бы описывать алгоритм в терминах массива целиком (как это делается на последовательных компьютерах), а не манипулировать локальными частями массива, размер которых зависит от числа используемых процессоров.
Примером такой высокоуровневой модели является модель последовательного программирования. Мечта всех прикладных программистов — получить инструмент, автоматически преобразующий его последовательную программу в параллельную. К сожалению, для систем с распределенной памятью такое автоматическое распараллеливание обеспечить не удается.
Во-первых, поскольку взаимодействие процессоров через коммуникационную систему требует значительного времени (время самого простого взаимодействия велико по сравнению со временем выполнения одной машинной команды), то вычислительная работа должна распределяться между процессорами крупными порциями. Совсем другая ситуация была на векторных машинах и на многопроцессорных системах с общей памятью, где для автоматического распараллеливания программ на языке Фортран достаточно было проанализировать только самые внутренние циклы программы на предмет возможности параллельного выполнения (замены на векторные операции). В случае мультипроцессоров приходилось уже анализировать объемлющие циклы для нахождения более крупных порций работы, распределяемых между процессорами. Такое укрупнение требует анализа крупных фрагментов программы, обычно включающих в себя вызовы различных процедур, что, в свою очередь, требует сложного межпроцедурного анализа. Поскольку в реальных программах могут использоваться конструкции, статический анализ которых принципиально невозможен (например, косвенная индексация элементов массивов), то с увеличением порций распределяемой работы увеличивается вероятность того, что распараллеливатель откажется обрабатывать конструкции, которые на самом деле допускают параллельное выполнение.
Во-вторых, в отличие от многопроцессорных машин с общей памятью, на системах с распределенной памятью необходимо произвести не только распределение вычислений, но и распределение данных, а также обеспечить на каждом процессоре доступ к удаленным данным, расположенным на других процессорах. Для этого недостаточно просто обнаруживать факт наличия зависимости по данным в цикле или между разными циклами, а требуется точно определить тот сегмент данных, который должен быть переслан с одного процессора на другой.
В третьих, распределение вычислений и данных должно быть произведено согласованно. Несогласованность приведет, вероятнее всего, к тому, что параллельная программа будет выполняться гораздо медленнее последовательной. Если на системе с общей памятью распараллелить один цикл, занимающий 90% времени решения задачи, то можно рассчитывать на почти десятикратное ускорение программы, даже если оставшиеся 10% будут выполняться последовательно. На системе с распределенной памятью распараллеливание этого цикла без учета последовательной части может вызвать не ускорение, а замедление программы, поскольку для выполнения последовательной части потребуется интенсивный обмен данными между процессорами. Согласованное распределение вычислений и данных требует тщательного анализа всей программы, и любая неточность может привести к катастрофическому замедлению.
Следует отметить, что если программисту все же предоставили бы желанный инструмент, то он столкнулся бы с проблемой анализа и повышения эффективности выполнения полученной параллельной программы. Поскольку модель программирования очень далека от модели выполнения, то было бы очень трудно объяснить программисту, какие преобразования программы он должен осуществить для ее эффективного выполнения.
В модели параллелизма по данным отсутствует понятие процесса и, как следствие, явная передача сообщений или явная синхронизация. В этой модели (рис. 1) данные последовательной программы распределяются программистом по процессорам параллельной машины. Последовательная программа преобразуется компилятором в параллельную, выполняющуюся либо в модели передачи сообщений, либо в модели с общей памятью. При этом вычисления распределяются по правилу собственных вычислений: каждый процессор работает только с собственными данными.
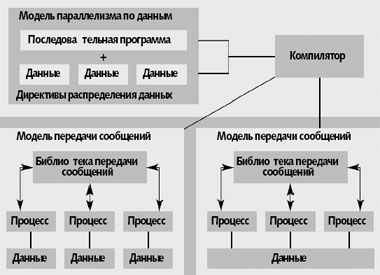
|
| Рис. 1. Схема отображения программы в модели параллелизма по данным |
Обобщение и стандартизация моделей параллелизма по данным привели к созданию в 1993 году стандарта HPF (High Performance Fortran [1]) — расширения языка Фортран 90. Безусловно, по сравнению с MPI язык HPF намного упрощает написание параллельных программ, однако его реализация требует от компилятора очень высокого интеллекта, а самая сложная часть работы, которая вызывала проблемы при автоматическом распараллеливании (распределение данных) возлагается на программиста. Но, и с оставшейся частью работы компилятор не всегда способен справиться без дополнительных подсказок.
Модель параллелизма по управлению возникла как естественная альтернатива явному использованию модели общей памяти при разработке программ — вместо программирования в терминах нитей предлагалось расширить языки специальными управляющими конструкциями: параллельными циклами и секциями, позволяющими, например, описать параллельное выполнение нескольких процедур. Создание и уничтожение нитей, распределение между ними витков параллельных циклов или параллельных секций — все это брал на себя компилятор. Первая попытка стандартизовать такую модель привела к появлению в 1990 году проекта языка PCF Fortran (проект стандарта X3H5). Однако этот проект [2] тогда не привлек широкого внимания, возможно, по причине снижения интереса к многопроцессорным системам и всеобщим увлечением кластерных, метакомпьютерных систем и HPF. Однако, спустя несколько лет, ситуация изменилась. Успехи в развитии элементной базы сделали перспективным и экономически выгодным создание мультипроцессорных систем, а надежды на то, что HPF станет фактическим стандартом для разработки вычислительных программ, не оправдались — разработчикам компиляторов не удалось добиться приемлемой эффективности выполнения HPF-программ. В октябре 1997 крупнейшие вендоры объединили свои усилия и года выпустили описание языка OpenMP Fortran [3] —расширение языка Фортран 77, а позже вышли аналогичные расширения языков Си и Фортран 90/95.
Модель параллелизма по данным и управлению
Эта модель, положенная в основу языков параллельного программирования Fortran-DVM [4] и C-DVM [5], объединяет достоинства модели параллелизма по данным и модели параллелизма по управлению. Базирующаяся на этих языках система разработки параллельных программ (DVM-система [6]) была создана в ИПМ им. М.В. Келдыша РАН. В отличие от модели параллелизма по данным, программист в DVM-системе распределяет по процессорам параллельной машины не только данные, но и соответствующие вычисления. При построении DVM-системы был использован новый подход, который характеризуется следующими принципами.
1. Система должна базироваться на высокоуровневой модели выполнения, удобной и понятной для программиста. Такая DVM-модель была разработана в 1994 году [4].
2. Языки параллельного программирования должны представлять собой стандартные языки последовательного программирования, расширенные спецификациями параллелизма. Эти языки должны предлагать программисту модель программирования, достаточно близкую к модели выполнения. Знание программистом модели выполнения его программы и ее близость к модели программирования существенно упрощает анализ производительности программы и проведение ее модификаций.
3. Спецификации параллелизма должны быть прозрачными для обычных компиляторов (например, оформляться в виде специальных комментариев). Во-первых, это упрощает внедрение новых параллельных языков, поскольку программист знает, что его программа без каких-либо изменений может выполняться в последовательном режиме на любых архитектурах. Во-вторых, это позволяет использовать метод поэтапной отладки DVM-программ: на первом этапе программа отлаживается как последовательная; на втором выполняется в специальном режиме проверки DVM-указаний; на третьем этапе программа может быть выполнена в специальном режиме, когда промежуточные результаты параллельного выполнения сравниваются с эталонными результатами (например, результатами последовательного выполнения).
4. Основная работа по реализации модели выполнения параллельной программы (например, распределение данных и вычислений) должна осуществляться динамически. Это позволяет обеспечить динамическую настройку DVM-программ при запуске (без перекомпиляции) на параметры приложения (количество и размер массивов данных) и конфигурацию параллельного компьютера (количество процессоров и их производительность). Тем самым программист получает возможность иметь один вариант программы для выполнения на последовательных и параллельных системах различной конфигурации. Кроме того, на основании информации о выполнении DVM-программы на однопроцессорном компьютере можно посредством моделирования работы системы поддержки предсказать характеристики выполнения этой программы на параллельной системе с заданными параметрами (производительность процессоров и характеристики коммуникационных каналов).
DVM-система состоит из компиляторов с языков FORTRAN-DVM и C-DVM, системы поддержки выполнения параллельных программ; отладчика параллельных программ; анализатора и предсказателя производительности.
Языки Fortran-DVM и C-DVM
Спецификации параллелизма
Программы на языках Fortran-DVM и C-DVM, помимо описания алгоритма обычными средствами языков Фортран 77 или Си, содержат спецификации (директивы) параллелизма, описываемые на языке Fortran-DVM в виде спецкомментариев:
<начало-директивы> <директива> <начало-директивы> :: CDVM$ | *DVM$ | !DVM$
На языке C-DVM директивы описывается в виде спецмакросов DVM. Директивы на двух языках отличаются только синтаксисом и «невидимы» для стандартных компиляторов, поэтому DVM-программа без изменений может выполняться как в параллельном, так и в последовательном режимах. При распараллеливании программы пользователь должен:
- выявить параллелизм на уровне задач и описать одномерные массивы задач;
- определить распределенные массивы и параллельные циклы;
- описать согласованное распределение массивов и вычислений (задач, витков параллельных циклов). Данные и вычисления, не специфицированные пользователем, автоматически размножаются по всем процессорам;
- описать общие данные — определить межпроцессорные зависимости по данным по распределенным измерениям массивов;
- отметить точки (операторы) программы, в которых используются новые значения общих данных.
Теоретически распараллеливание программы в модели DVM можно рассматривать как отображения индексных (дискретных) пространств (рис.2). В модели DVM определены следующие базовые индексные пространства: массивы задач, массивы данных, циклы и массив (решетка) виртуальных процессоров. В результате отображений для каждого виртуального процессора определяется подмножество данных и подмножество вычислений (операторов). Согласование этих подмножеств управляется правилом собственных вычислений: данные всегда вычисляются на том процессоре, куда они отображены. С помощью перераспределения данных пользователь может варьировать загрузку процессоров.
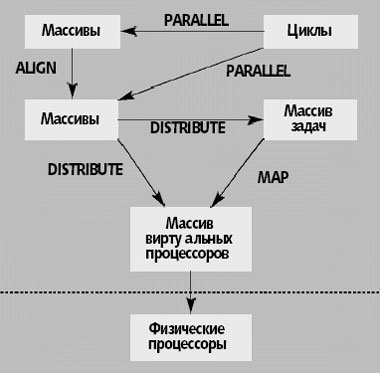
|
| Рис. 2. Отображение последовательной программы |
Параллелизм задач
Параллелизм задач в модели DVM — это независимое по данным выполнение процедур и крупных блоков операторов. Если в программе существует такой уровень параллелизма, то пользователь должен описать одномерный массив задач с помощью директивы CDVM$ TASK TT(nt), где nt — максимальное количество задач. Каждую задачу необходимо отобразить на секцию массива виртуальных процессоров с помощью директивы CDVM$ MAP TT(i) ONTO P(ni1 : ni2, mi1 : mi2 ), где TT(i) — i-ая задача массива задач TT, P — двухмерный массив виртуальных процессоров. Вычисления (блок операторов) отображаются на задачу с помощью директивы CDVM$ ON TT(i).
Отображение данных
Отображение данных осуществляется директивами DISTRIBUTE и ALIGN, например отображение одномерного массива:
CDVM$ DISTRIBUTE AR (<формат>) [ONTO T(n)]
<формат> = BLOCK — отображение равными блоками,
WGT_BLOCK(WB,NWB) — отображение взвешенными (неравными) блоками
* — отображение целым измерением
Пусть при запуске программы задана линейка виртуальных процессоров P(NP). При отображении равными блоками индексное пространство измерения разделяется на NP блоков (отрезков) и i-ый блок отображается на виртуальный процессор P(i). При отображении взвешенными блоками задается вектор весов WB размера NWB для каждой точки (или группы соседних точек) индексного пространства измерения. Измерение массива разделяется на NP блоков так, чтобы минимизировать отклонение веса каждого блока (суммы весов точек блока) от среднего значения. Такое отображение позволяет сбалансировать загрузку процессоров. Отображение целым измерением означает, что измерение не будет разделяться между процессорами и целиком распределено на каждый процессор (локальное, нераспределенное измерение). Если присутствует опция ONTO T(n), то массив отображается на n-ую задачу массива задач T, а точнее на ту часть линейки процессоров P(NP), на которую отображена n-ая задача.
Отображение многомерного массива осуществляется посредством задания отображения каждого его измерения. При этом количество распределенных измерений массива не может превышать количество измерений решетки процессоров.
Очень часто требуется отобразить несколько массивов согласованно, что требуется и для того чтобы уменьшить количество данных, вычисляемых на одних процессорах и используемых на других, доступ к которым требует существенных накладных расходов. Для организации согласованного отображения нескольких массивов используется механизм выравнивания одного массива на другой с помощью директивы ALIGN. Рассмотрим следующий фрагмент программы:
real A(N), B(N) CDVM$ DISTRIBUTE A (BLOCK) CDVM$ DISTRIBUTE B (BLOCK) … CDVM$ PARALLEL ( i ) ON B( i ) do i = n1,n2 B( i ) = A( f( i )) enddo
Пусть OWN(B(i)) обозначает виртуальный процессор, на который распределен элемент B(i). Виток цикла с индексом i будет выполняться на процессоре OWN(B(i)). Если элемент A(f(i)) будет распределен на процессор OWN(B(i)), то для каждого витка цикла все данные будут распределены на одном процессоре. Чтобы обеспечить такую локализацию данных, необходимо вместо директивы CDVM$ DISTRIBUTE B (BLOCK) применить директиву выравнивания индексных пространств массивов CDVM$ ALIGN B(i) WITH A( f( i )), которая устанавливает соответствие между элементами B(i) и A(f(i)). Это означает, что элемент B(i) будет распределен на процессор OWN(A(f(i))). При выполнении программы можно динамически изменять распределение данных с помощью директив REDISTRIBUTE и REALIGN. Однако надо понимать, что такое перераспределение может потребовать значительных затрат времени.
Параллелизм циклов
Директива PARALLEL встроена в язык Фортран в виде спецкомментария
CDVM$ PARALLEL (i1,...,im) ON A(L1,...,Ln)
где Lk = ak х ij + bk — линейная функция от индекса j-ого цикла (из m-мерного тесно-гнездового цикла), 0 < k < (n+1), 0 < j < (m+1), A — идентификатор массива данных или массива задач. Директива устанавливает соответствие между витком многомерного цикла с индексами (i1,...,im) и элементом A(L1,...,Ln). Это означает, что виток цикла будет выполняться на том процессоре, куда будет отображен элемент массива A(L1,...,Ln).
Спецификация общих данных
Данные, вычисляемые на одних процессорах и используемые на других, можно разбить на две основные категории. Во-первых, общие данные, возникающие при выполнении на разных процессорах разных параллельных конструкций программы. Такие данные отражают зависимость между этими параллельными конструкциями, для учета которой необходимо организовать пересылку общих данных после выполнения первой конструкции и до начала выполнения второй. Примерами служат «Соседние» общие данные и REMOTE-данные. Во-вторых, общие данные, возникающие при выполнении на разных процессорах одной параллельной конструкции. Они отражают имеющуюся в этой конструкции зависимость по данным. В общем случае такая конструкция не может выполняться на распределенных системах параллельно с приемлемой эффективностью. Но часто можно организовать эффективное параллельное выполнение этой конструкции.
«Соседние» общие данные. Рассмотрим следующий фрагмент программы:
CDVM$ PARALLEL (i) ON B(i), SHADOW_RENEW (A(d1:d2)) do i = d1+1, N-d2 B( i ) = A( i-d1 ) + A( i+d2 ) enddo
Требуемые каждому процессору общие данные размещены на соседних виртуальных процессорах. Спецификация SHADOW_RENEW указывает, что в цикле используются новые значения общих данных из массива A, d1 указывает размер требуемых данных с левого соседа, а d2 — с правого. Для доступа к удаленным данным используются «теневые» грани, представляющие буфер, который является непрерывным продолжением локальной секции массива в памяти процессора. Перед выполнением цикла требуемые удаленные данные пересылаются с соседних процессоров в теневые грани массива А на каждом процессоре. Доступ к этим данным при выполнении цикла производится обычным образом (через ссылки на массив A).
Существует асинхронная форма спецификации, которая позволяет совместить пересылку данных в теневые грани с вычислениями.
REMOTE-данные. Иногда доступ к удаленным данным требует заведения специальных буферов и соответствующей замены «удаленных» ссылок на массив, через которые происходят обращения к удаленным элементам массива. Рассмотрим следующий фрагмент:
DIMENSION A(100,100), B(100,100) CDVM$ DISTRIBUTE A (*,BLOCK) CDVM$ ALIGN B( I, J ) WITH A( I, J ) … CDVM$ REMOTE_ACCESS ( A(50,50) ) С замена ссылки A(50,50) ссылкой на буфер и С рассылка значения A(50,50) по всем процессорам 1 X = A(50,50) … CDVM$ REMOTE_ACCESS ( B(100,100) ) С пересылка значения В(100,100) в буфер процессора own(A(1,1) 2 A(1,1) = B(100,100) … CDVM$ PARALLEL (I,J) ON A(I,J) , REMOTE_ACCESS ( B(I,N) ) С рассылка значений B(I,N) по процессорам own(A(I,J)) 3 DO 10 I = 1, 100 DO 10 J = 1, 100 10 A(I,J) = B(I,J) + B(I,N)
Первые две директивы REMOTE_ACCESS специфицируют удаленные ссылки для отдельных операторов, а третья специфицирует удаленные данные (элементы N-го столбца матрицы B) для всех процессоров, на которых выполняется цикл (при этом на каждый процессор будет переслана только необходимая ему часть столбца матрицы B).
Редукционные данные. Рассмотрим следующий фрагмент программы:
CDVM$ PARALLEL (i) ON B(i), REDUCTION ( SUM(s)) do i = 1, N s= s+B( i ) enddo
Вообще говоря, имеющаяся зависимость по данным (переменная s) требует последовательного выполнения витков цикла с передачей значения переменной s от каждого отработавшего процессора к следующему. Однако если пренебречь влиянием отсутствия ассоциативности машинных операций сложения, то можно эффективно распараллелить такой цикл. Для этого на каждом процессоре заводятся копии переменной s, в которых при параллельном выполнении цикла будут посчитаны частичные суммы. После выполнения цикла необходимо посчитать глобальную сумму посредством суммирования всех частичных сумм. Аналогично можно поступить для распараллеливания циклов, в которых вычисляется максимальное или минимальное значение элементов массива. Такие общие данные называются редукционными. При их спецификации необходимо указать ту редукционную операцию, которую требуется выполнить после цикла для объединения частичных результатов, посчитанных на каждом процессоре.
ACROSS-данные. Рассмотрим фрагмент программы:
CDVM$ PARALLEL (i) ON B(i), ACROSS (B(d1:d2)) do i = d1+1, N-d2 B( i ) = B( i-d1 ) + B( i+d2 ) enddo
ACROSS-данные (элементы массива B) также являются соседними общими данными, но используются и обновляются в одном и том же цикле (в цикле имеется зависимость по этим данным). Параметры d1 и d2 указывают размеры общих данных на соседних процессорах слева и справа, соответственно. Такая зависимость по данным в общем случае требует последовательного выполнения витков цикла с передачей значений обновленных общих данных от каждого отработавшего процессора к следующему. Однако во многих случаях, например, когда двухмерный цикл распределен по одному измерению на линейку процессоров, можно эффективно распараллелить такой цикл, если организовать его конвейерное выполнение. Идея конвейерного выполнения заключается в том, что первый процессор выполняет часть «своих» витков цикла и передает следующему процессору соответствующую порцию обновленных общих данных. После получения этих данных второй процессор начинает выполнять «свои» витки цикла параллельно с выполнением первым процессором второй порции витков и т.д. Оптимальный размер порции зависит от количества витков цикла, времени выполнения каждого витка, числа процессоров, а также латентности и пропускной способности коммуникационной среды. Система поддержки DVM-программ обеспечивает вычисление оптимальной порции витков и соответствующее дробление одного или нескольких измерений цикла, а также передачу обновленных общих данных между процессорами.
Директива DISTRIBUTE описывает распределение массива А на двумерную решетку процессоров. Количество форматов BLOCK определяет количество измерений решетки виртуальных процессоров. Первое измерение массива распределяется равными блоками по первому измерению решетки процессоров, второе по второму измерению решетки. При запуске программы может быть задана любая двумерная решетка процессоров.
Компиляция и модель выполнения DVM-программ
Параллельная программа на исходном языке Fortran-DVM (или C-DVM) превращается в программу на языке Фортран 77 (или Си), содержащую вызовы функций системы поддержки и выполняющуюся в соответствии с моделью SPMD (одна программа - много данных) на каждом выделенном задаче процессоре. В момент запуска программы существует единственная её ветвь (поток управления), которая начинает выполнение с первого оператора программы сразу на всех процессорах виртуальной многопроцессорной системы. Для распределённой конфигурации примером такой машины может служить MPI-машина. В этом случае, виртуальная многопроцессорная система — это группа MPI-процессов, которые создаются при запуске параллельной программы. Число процессоров виртуальной многопроцессорной системы и её представление в виде многомерной решетки задаётся в командной строке при запуске.
Все объявленные в программе переменные (за исключением специально указанных «распределённых» массивов) размножаются по всем процессорам. При входе в параллельную конструкцию (параллельный цикл или область параллельных задач) ветвь разбивается на некоторое количество параллельных ветвей, каждая из которых выполняется на выделенных ей процессорах. При выходе из параллельной конструкции все ветви сливаются в ту же самую ветвь, которая выполнялась до входа в параллельную конструкцию.
Эффективность
Для DVM-программ вопрос эффективности выполнения принципиален, поскольку эти программы должны при запуске динамически (без перекомпиляции) настраиваться на количество и производительность выделенных для их выполнения процессоров. Для оценки эффективности выполнения DVM-программ используются тесты NPB 2.3 [7], отражающие характер вычислительных задач различных классов, за исключением задач с нерегулярными сетками.
Однако, сравнение на тестах NPB 2.3 не вполне правомерно — они написаны на очень высоком профессиональном уровне и являются объектом пристального внимания многих специалистов. При разработке реальных параллельных программ, как правило, достижение высокой эффективности требует многократных изменений программы для поиска наилучшей схемы распараллеливания. Успешность такого поиска определяется простотой модификации программы. Кроме того, прикладному программисту трудно реализовать многие часто используемые приемы распараллеливания так же эффективно, как они реализуются системами программирования, поэтому на реальных программах MPI-подход очень часто проигрывает по эффективности DVM-подходу.
Переносимость
Огромная заслуга разработчиков MPI заключается в обеспечении переносимости параллельных программ на различные архитектуры с распределенной и общей памятью. Однако перенос MPI-программ на неоднородные кластеры и сети приводит к заметной потере эффективности, поскольку прикладной программист фактически не имеет возможностей для написания программ, способных настраиваться на производительность разных процессоров.
При использовании MPI очень сложно разрабатывать программы, способные выполняться на различном числе процессоров с разными по объему данными, поэтому многие программисты предпочитают иметь разные варианты программ для разных конфигураций данных и процессоров, а также отдельный вариант программы для работы на однопроцессорной машине.
Главные трудности связаны с отсутствием в языке программирования такого понятия, как распределенный массив и вместо такого единого массива на каждом процессоре используется свой локальный массив. Их соответствие исходному массиву, с которым программа имела бы дело при ее выполнении на одном процессоре, зафиксировано только в голове программиста и, возможно, в комментариях к программе.
DVM-программы могут без каких-либо изменений компилироваться и выполняться на последовательных архитектурах в среде компиляторов Фортран 77/90 или Си. Переносимость DVM-программы на произвольные кластеры или сети обеспечивается тем, что она преобразуется в программу, содержащую вызовы функций системы поддержки, которая для организации межпроцессорного взаимодействия использует библиотеку MPI. Такая программа может выполняться всюду, где есть MPI и компиляторы с языков Си и Фортран 77. Кроме того, программы на языке Fortran-DVM могут автоматически конвертироваться в программы на языке HPF или HPF2, а в дальнейшем и в OpenMP-программы.
Отладка
Отладка параллельной программы является процессом более трудоемким, чем отладка последовательной и причина не только в сложности параллельной программы, но и в ее недетерминированном поведении, затрудняющем достижение правильности результатов, и отладку эффективности. Раньше с подобными трудностями сталкивались, в основном, разработчики операционных систем и систем реального времени, которые сами и создавали для себя специальные средства отладки. Функциональная отладка DVM-программ [8] осуществляется поэтапно. Сначала программа отлаживается на рабочей станции как обычная последовательная программа с использованием штатных средств. Затем на той же рабочей станции программа пропускается в специальном режиме проверки DVM-указаний, что позволяет выявить их правильность и полноту. На следующем этапе программа может быть пропущена на параллельной машине (или рабочей станции, имитирующей параллельную машину) в режиме сравнения промежуточных результатов ее параллельного выполнения с эталонными результатами, полученными при ее последовательном выполнении.
Для отладки программы на реальной параллельной машине используются также средства накопления трассировки, позволяющие зафиксировать последовательность обращений к переменным и их значения, а также последовательность вызовов функций системы поддержки выполнения DVM-программ.
Для отладки эффективности DVM-программ используется анализатор производительности, позволяющий получить информацию об основных характеристиках эффективности выполнения программы (или ее частей) на параллельной системе. Для облегчения такой отладки можно использовать специальный инструмент — предсказатель производительности, позволяющий смоделировать выполнение DVM-программы на параллельной конфигурации с заданными параметрами (топология коммуникационной сети, ее латентность и пропускная способность, а также производительность процессоров) и получить прогнозируемые характеристики эффективности ее выполнения.
Выводы
Итак, основные достоинства DVM-системы:
- высокоуровневая модель программирования, позволяющая описывать алгоритм в терминах массива целиком, а не требовать от программиста манипулирования локальными частями массива, размер которых зависит от числа используемых процессоров;
- один вариант программы для эффективного выполнения на последовательных и параллельных системах различной конфигурации;
- высокоуровневые средства функциональной отладки, анализа и предсказания эффективности.
Система DVM может использоваться на рабочих станциях SGI, HP, IBM, SUN и ПК с ОС UNIX и Windows 95/98/2000/NT. На данный момент система установлена на следующих параллельных системах: МВС-1000M (МСЦ), МВС-1000/16 (ИПМ РАН и ИММ УрО РАН); МВС-1000/200, Convex SPP 1600 (ИПМ РАН); вычислительные кластеры SCI и SKY (НИВЦ МГУ); вычислительный кластер NCI (Пекин); Parsytec CC (ИММ РАН); вычислительный кластер ННГУ (Н.Новгород).
Система в виде исходных текстов, библиотек, набора демонстрационных программ и документации доступна по адресу http://www.keldysh.ru/dvm/.
Литература
[1] High Performance Fortran Forum. High Performance Fortran Language Specification. Version 1.0, May 1993
[2] PCF Fortran. Version 3.1. Aug.1, 1990
[3] OpenMP Consortium: OpenMP Fortran Application Program Interface, Version 1.0, October 1997
[4] Konovalov N.A., Krukov V.A., Mihailov S.N. and Pogrebtsov A.A. Fortran DVM - a Language for Portable Parallel Program Development. Proceedings of Software For Multiprocessors & Supercomputers: Theory, Practice, Experience. Institute for System Programming, RAS, Moscow, 1994
[5] Коновалов Н.А., Крюков В.А., Погребцов А.А., Сазанов Ю.Л. С-DVM - язык разработки мобильных параллельных программ // Программирование. 1999, № 1
[6] DVM-система. http://www.keldysh.ru/dvm/
[7] Bailey D., Harris T., Saphir W., Van der Wijngaart, Woo A., Yarrow M.The NAS Parallel Benchmarks 2.0. NAS Technical Report NAS-95-020, NASA Ames Research Center, Moffett Field, CA, 1995
[8] В.А.Крюков, Р.В.Удовиченко, «Отладка DVM-программ» // Программирование, 2001, № 3
Николай Коновалов (konov@keldysh.ru), Виктор Крюков (krukov@keldysh.ru) — сотрудники Института прикладной математики им. Келдыша РАН (Москва)
Пример параллельной программы на языке Fortran-DVM (алгоритм Якоби)
PROGRAM JAC_DVM PARAMETER (L=8, ITMAX=20) REAL A(L,L), B(L,L) CDVM$ DISTRIBUT A (BLOCK,BLOCK) CDVM$ ALIGN B(I,J) WITH A(I,J) C массивы A и B распределяются блоками DO IT=1, ITMAX CDVM$ PARALLEL (J,I) ON A(I,J) DO J=2, L-1 DO I=2, L-1 A(I,J)=B(I, J) ENDDO ENDDO CDVM$ PARALLEL (J,I) ON B(I,J), SHADOW_RENEW (A) C Двухмерный параллельный цикл, итерация С (i,j) выполняется, C на том процессоре, где размещен элемент С B(j,i) C копирование теневых элементов массива A C с соседних процессоров перед выполнением цикла DO J=2, L-1 DO I=2, L-1 B(I,J)=(A(I-1,J)+A(I,J-1)+*A(I+1,J)+A(I,J+1))/4 ENDDO ENDDO ENDDO END
Директива ALIGN определяет распределение массива В, согласованное с распределением массива А: элемент B(I,J) будет распределен на тот же процессор, где размещен элемент A(I,J).
Оба цикла удовлетворяют требованиям параллельного цикла модели DVM. Обе директивы PARALLEL описывают распределение витков цикла, согласованное с распределением массивов: А и В: виток цикла с индексами (I,J) будет выполняться на том же процессоре, где размещены элементы A(I,J) и B(I,J). Анализ оператора присваивания первого цикла показывает, что левая и правая часть оператора для каждого витка цикла распределены на том же процессоре, где выполняется виток цикла (следствие выполнения директив ALIGN и PARALLEL). Анализ второго цикла показывает, что не для каждого витка цикла выполняется локализация данных (отсутствие общих данных). Это определяется сравнением индексных выражений по каждому распределенному измерению левой и правой частей оператора. Если индексные выражения не равны и отличаются на постоянную небольшую величину, то в данном цикле возникают общие данные типа SHADOW. Спецификацией SHADOW_RENEW(А) пользователь указывает, что в данном цикле используются новые значения общих данных.
Реализация спецификации в системе поддержки показана на рисунке 3. Во-первых, при распределении массива на каждый процессор распределяется не только секция массива, но и так называемые области перекрытия или теневые грани (на рис. они темнее). Ширина теневых граней определяется разницей индексных выражений в левой и правой части операторов присваивания. Для данного примера ширина всех граней равна 1. Во-вторых, перед параллельным циклом со спецификацией SHADOW_RENEW(А) система поддержки произведет массовый обмен данными между «соседними» процессорами решетки.
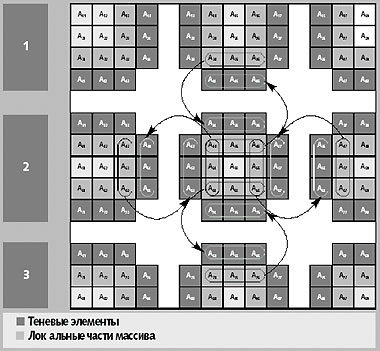
|
| Рис. 3. Отображение массива A(8,8) на процессорную решетку 3х3 |
