
Процесс переноса приложений с одной СУБД на другую в общем случае является трудоемкой задачей, для решения которой полезно прежде познакомиться с практическим опытом выполнения таких работ. В статье рассказывается об особенностях переноса системы класса ERP с платформы Informix On-Line Dynamic Server на Microsoft SQL Server 2000.
|
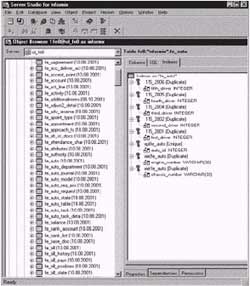
| База данных системы FinExpert в СУБД Informix |
В силу проблем, возникших у одного из наших заказчиков при попытках эксплуатации механизма репликации СУБД Informix [1, 2], а также ряда недочетов, было принято решение о смене СУБД. Среди возможных вариантов рассматривались Oracle 8i и Microsoft SQL Server 2000. В силу недостаточной активности на Украине других поставщиков, СУБД DB/2 и Sybase Adaptive Server практически изначально были исключены из рассмотрения. Основными факторами, сыгравшими роль в выборе заказчиком SQL Server 2000, стали: лучшее отношение цена/производительность; поддержка пяти видов репликации; организация и проведение Microsoft нескольких семинаров для сотрудников отдела АСУ заказчика.
Важную роль при переводе системы на SQL Server сыграл ряд проектных решений: автоматическая генерация сервером приложений SQL-запросов (StatementHelper); использование средств автоматической генерации схемы базы данных CA ERWin; минимальное число и объем хранимых процедур на сервере баз данных; минимальное использование несовместимого и нестандартного синтаксиса SQL-запросов, а также платформно-зависимых особенностей СУБД Informix.
Кроме того, изначально в системе предполагалось использование средств репликации Informix, причем:
- в каждой таблице системы должен был присутствовать целочисленный суррогатный автоинкрементный первичный ключ;
- для каждого экземпляра базы данных должен был быть задан уникальный диапазон изменения первичных ключей; это помешало воспользоваться стандартной для Informix схемы организации автоинкрементных полей (поля типа serial), заставив реализовать свою собственную схему;
- допускались весьма сложные WHERE-условия для репликации строк отдельных таблиц;
- репликация строк отдельных таблиц могла быть двунаправленной, в том числе с различными условиями отбора строк для различных направлений передачи.
Заказчиком была поставлена задача: в течение трех месяцев обеспечить работоспособность в среде SQL Server 2000 ядра системы и профильных для заказчика приложений; одновременно продолжить эксплуатацию части приложений системы под Informix; через девять месяцев обеспечить полную работоспособность всех приложений на SQL Server 2000.
Конвертация ER-схемы
Для начала была проведена так называемая конвертация «в лоб». Из ModelMart выгрузили ER-схему, изменив в ней значение параметра Target Server на SQL Server. Однако первая генерация такой схемы базы данных «породила» 5 тыс. ошибок, что несколько обескуражило, потребовалось изменить еще массу вещей.
В схеме базы данных присутствовали реляционные правила RULES и значения по умолчанию DEFAULTS, синтаксис которых для Informix отличался от синтаксиса для SQL Server, например:
Informix: create table FE_GLOBALVAR_VALUE(... timestamp_field datetime NOT NULL DEFAULT curent year to fraction(4)) SQL Server: CREATE DEFAULT CURRENT_Y2F AS current_timestamp go create table FE_GLOBALVAR_VALUE(... exec sp_bindefault CURRENT_Y2F4, 'FE_GLOBALVAR_VALUE.timestamp_field')
С помощью встроенного макроязыка CA ERWin можно создавать стандартные механизмы обработки объектов базы данных с конструкциями типа:
%if(%==(%DBMS,INFORMIX)) {}
%if(%==(%DBMS,SQL Server)) {}Поэтому в ряде случаев пришлось использовать вариантные определения RULES и DEFAULTS:
%if(%==(%DBMS,INFORMIX)) {
CURRENT YEAR TO FRACTION(4) }
%if(%==(%DBMS,SQL Server)) {
current_timestamp }Однако, как оказалось, вариантные определения в ERWin 3.5.2 поддерживаются только в скриптах пре- и постобработки. Поэтому пришлось писать обработчик скрипта генерации баз данных от ERWin, выполняющий дополнительное преобразование SQL-предложений вида:
%if(%==(%DBMS,SQL Server)){
[SQL Server script]}
%if(%==(%DBMS,INFORMIX)){
[INFORMIX script]}оставляя только скрипт для выбранной СУБД, а также:
CURRENT YEAR TO FRACTION CURRENT YEAR TO SECOND TODAY
с заменой их на фразу current_timestamp в случае генерации схемы для SQL Server.
Потребовалось также реализовать схему эмуляции глобальных переменных. В Informix присутствует поддержка глобальных переменных, которые устанавливались в каждом пользовательском сеансе и были доступны внутри сеанса между различными запросами и процедурами. Для SQL Server подобная функциональность отсутствовала, однако отказаться от глобальных переменных было сложно.
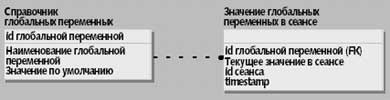
|
| Рис.1. ER-схема для эмуляции глобальных переменных |
Эта схема (рис. 1) включает в себя таблицу-справочник глобальных переменных (FE_GLOBALVARIABLES); таблицу с текущими значениями глобальных переменных в разрезе сеансов (FE_GLOBALVAR_VALUE); процедуры Fe_GetGlobalValue для получения значений глобальных переменных и Fe_LetGlobalValue для их установки.
Допустим, в ходе работы возникла необходимость получить значение глобальной переменной fe_can_insert_pk (по умолчанию оно устанавливается равным 0). Процедура:
exec Fe_GetGlobalValue ?fe_can_insert_pk?, @val Output
прежде всего пытается получить последнее по времени (поле Timestamp таблицы FE_GLOBALVAR_VALUE) значение для fe_can_insert_pk в текущем сеансе (@@SPID). Если же для данного сеанса в таблице FE_GLOBALVAR_VALUE нет значений глобальных переменных, добавляет записи в таблицу, исходя из значений по умолчанию. При этом формируются сразу все записи для всех возможных глобальных переменных в системе. Это сделано для ускорения работы — весь список глобальных переменных сеанса формируется один раз, при первом обращении. Сформировав список, процедура возвращает значение для запрошенной переменной.
Теперь предположим, что нам нужно изменить значение глобальной переменной с 0 на 1. Процедура:
exec Fe_LetGlobalValue ?fe_can_insert_pk?, 1
добавляет значение глобальной переменной в таблицу FE_GLOBALVAR_VALUE для сеанса @@SPID. Следует подчеркнуть, что при изменении значения глобальной переменной новое значение именно добавляется в таблицу, а не обновляется старое. Это должно уменьшить вероятность взаимных блокировок между сеансами. Побочным эффектом такого построения системы является наполнение таблицы FE_GLOBALVAR_VALUE «старыми» значениями глобальной переменной. Для устранения этого предусмотрен один из шагов задач (Tasks/Jobs) во время проведения регламентных работ над базой данных.
В силу перечисленных причин, для реализации схемы автоинкрементных полей не подходил стандартный путь IDENTITY, поэтому пришлось разработать собственную схему автоинкрементных полей. Схема автоинкрементных полей в проекте FinExpert основывается на 4 основных элементах.

|
| Рис. 2. ER-схема структуры таблиц схемы автоинкрементных полей |
- Таблица FE_SERIAL_RANGE, определяющая диапазон значений, которые может принимать автоинкрементное поле в каждой таблице системы.
- Таблица FE_SERIAL_HEAP, содержащая текущие значения автоинкрементных полей каждой таблицы системы (рис. 2).
- Триггеры INSTEAD OF INSERT триггеры на таблицах системы.
- Процедура FE_SERIALIZE для получения текущего значения автоинкрементного поля для таблицы, проверки выхода за допустимый для этой таблицы диапазон и выполнения ряда других действий.
Как это работает? Допустим, в таблицу FE_BODY_TYPE (типы кузовов марок автомобилей) добавляется новая запись:
insert into FE_BODY_TYPE (body_type_id, body_type_name) values(0, ?Кабриолет?)
При этом срабатывает триггер INSTEAD OF INSERT на таблице FE_BODY_TYPE. Тело триггера формируется по шаблону (см. подробнее раздел «Разработка шаблонов триггеров»).
Триггер обращается к процедуре FE_SERIALIZE, передает имя таблицы и значение автоинкрементного поля, переданное клиентом (в данном случае 0). Процедура FE_SERIALIZE выбирает максимальное значение автоинкрементного поля для таблицы FE_BODY_TYPE из таблицы FE_SERIAL_HEAP. Допустим, оно на текущий момент равно 5, тогда процедура увеличивает его на единицу и проверяет, не превышен ли диапазон допустимых значений автоинкрементного поля для таблицы FE_BODY_TYPE по таблице FE_SERIAL_RANGE. Если диапазон не превышен, новое значение поля возвращается в OUTPUT параметр процедуры FE_SERIAL_RANGE. После этого, процедура добавляет новое значение в таблицу FE_SERIAL_HEAP и изменяет глобальную переменную fe_last_serial. Теперь ее новое значение равно 6. Как видно из примера, в триггере используются временная таблица и курсор. Подробнее о таком решении можно узнать из работ [4, 5], основная идея которых была развита и дополнена.
Различия в реализации SQL
Не будем останавливаться на очевидных и мелких различиях в синтаксисе, а разберем более существенные.
В СУБД Informix 7.x имеется ограничение на длину наименований компонентов базы данных — до 18 символов. В силу системного требования, чтобы имена всех объектов в FinExpert начинались с префикса FE_, допустимая длина «значащей» части имени объектов сокращалась до 15 символов. Это ограничение было снято только в версии Informix 9.2x. Для SQL Server такое ограничение отсутствует, однако, в целях обеспечения совместимости с Informix было решено оставить ограничение на имена таблиц и полей базы данных в 18 символов.
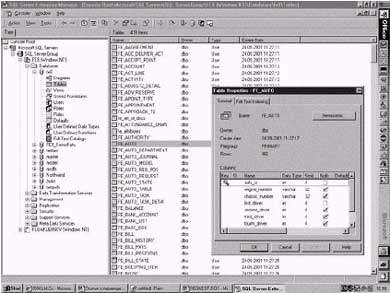
|
| Рис. 3. База данных системы FinExpert в СУБД Microsoft SQL Server |
Для имен индексов и триггеров, «автогенерируемых» из CA ERWin, совместимости не требуется, поскольку обращения к ним по имени в SQL-запросах отсутствуют. Для Informix имена таблиц сокращаются до 6 символов, что как раз и дает длину имени ссылки в 18 символов (имена ссылок в базе данных FinExpert 8.0 составляются из имен «родительской» и «дочерней» таблиц, префикса FE_ и постфикса, роль которого играет уникальный трехзначный номер ссылки). Для Microsoft SQL Server имена таблиц в этом случае не сокращаются.
И Informix, и SQL Server поддерживают по два варианта синтаксиса OUTER JOIN — в соответствии со стандартом ANSI SQL-92, и собственную реализацию (INFORMIX outer(tabname) / SQL Server *=).
Поскольку в системе, как правило, использовался «родной» для Informix вариант c ключевым словом outer, потребовалось переписать системный генератор SQL-запросов StatementHelper. Кроме того, если на таблицу, присоединенную посредством OUTER JOIN, накладывается дополнительное WHERE-условие, то SQL Server преобразует OUTER JOIN в INNER JOIN. Поскольку при работе с Informix этого не происходит, ряд «линейных» запросов пришлось переписать в запросы с подзапросами. Иначе в SQL Server выборка оказывалась неполной.
В Informix поддерживается работа с временными таблицами только одного вида — «локальными», которые видимы только создавшему их сеансу. Предусмотрено два метода создания таких временных таблиц: create temp table (... и select ... into temp tablename [with no log].
Аналогичные две возможности есть и в SQL Server 2000, но их синтаксис несколько отличается. Для create table вместо ключевого слова temp следует указывать имя таблицы, начинающееся с символа «#» (локальная временная таблица), или «##» (глобальная временная таблица, которая видна и из других сеансов):
Create table #table_name ( field1 integer, field2 varchar(50), ... )
или
select t1.field1, t1.field2 into #table_name from table1 t1 where t1.field3=?test?;
Из-за этого пришлось переписать в хранимых процедурах и коде сервера приложений системы все фрагменты, в которых велась работа с временными таблицами.
В процессе такой переделки выяснилась еще одна особенность работы с временными таблицами через ODBC driver for Microsoft SQL Server. При выполнении операторов Prepared неявно запускается хранимая процедура, что при создании локальных временных таблиц приводит к их исчезновению после окончания выполнения этой процедуры (т.е. фактически после окончания выполнения SQL-запроса на создание такой таблицы). Пришлось все вызовы для создания таких таблиц выполнять с помощью SQL Direct Execute [6].
Для конкатенации строк все оказалось «просто». В Informix конкатенация задается с помощью двойного вертикального слэша «||», а в SQL Server — с помощью знака сложения «+». По этой причине пришлось переписать множество представлений. Кроме того, при конкатенации Informix производит неявное преобразование аргументов нестрокового типа к типу varchar, а в SQL Server необходимо явно вызывать функцию convert.
Кроме типа данных datetime, Informix поддерживает еще и тип date (дата без времени), а в SQL Server есть только datetime. У этой проблемы оказались далеко идущие последствия; запрос вида:
Select field1, field2 from table1 Where field3 = ?2001-10-01?
нормально функционирующий в Informix, в SQL Server «неявно» преобразуется к виду:
Select field1, field2 from table1 Where field3 = ?2001-10-01 00:00:00?
и не возвращает данных. Чтобы решить эту проблему, пришлось в StatementHelper обрабатывать условия на поля типа дат и преобразовывать их с использованием специальной таблицы, согласно которой, в частности, приведенный выше запрос принимает вид:
Select field1, field2 from table1 Where field3 >= ?2001-10-01 00:00:00? and field3 <= ?2001-10-01 23:59:59?
В Informix разницу в днях между двумя датами можно подсчитать простым вычитанием, например:
select (close_date-issue_date) AS date_difference from table1
В SQL Server аналогичное действие придется описать как:
select DATEDIFF(«day», issue_date, close_date) from table1
Еще до начала работ по переносу было ясно, что структура системных таблиц в Informix и SQL Server совершенно различна, и все обращения к ним придется переписывать. Однако, в силу того, что системные таблицы в FinExpert использовались минимально, а для доступа к ним создавались специальные представления (views), потребовалось переделать только их.
В процессе тестирования обнаружилась неприятная проблема: SQL-операторы, в которых использовался отбор по условию LIKE, значений не возвращали. Проведенное исследование показало, что проблема проявляется, если выполняется «привязка» параметра (Bind). Мониторинг запросов с помощью SQL Server Profiler показал, что в таком случае фактическое значение параметра, поступающее на сервер, получается путем преобразования исходного, «правильного» значения к типу char(300) дополнением его пробелами до этого размера. Поэтому такой запрос ничего и не возвращал. Сначала проблему постарались решить автоматическим использованием функции RTRIM() в случае привязки параметра к условию LIKE. Однако выяснилось, что если выделять под параметр не char(300), а в точности столько байт, сколько требует параметр, проблемы можно избежать. В Informix делать это было необязательно, поскольку ODBC-драйвер выполнял такую операцию самостоятельно. Эта функциональность была реализована в низкоуровневом системном компоненте ODBCAPI.DLL, написанном на языке С++, с применением ATL 3.0, через который работают с базой данных все компоненты FinExpert.
Определенные проблемы возникли и при использовании параметров не в условии WHERE. Например, следующий запрос на SQL Server не возвращал ни одной строки:
select round(dbo.fe_is_null_d(sum (op.oil_pipe_length)),1), round(dbo.fe_is_null_d(sum (op.oil_pipe_length))*? /1000000, 1) from fe_oil_route r, fe_route_line l, fe_oil_pipe op where r.oil_route_id=l.oil_route_id and l.section_id=op.oil_pipe_id and r.oil_route_id=? [1] Unknown Double 7 [2] Unknown Long 90024653
Проблема исчезла, после того как первый параметр был «вмонтирован» в строку (вместо «привязки» он «укладывается» прямо в SQL-выражение). В Informix запрос нормально работает в неизменном виде, и возвращает корректный результат. После углубленного анализа оказалось, что ошибка происходит, если функция SQLNumResultCols(), позволяющая определить количество возвращаемых запросом столбцов, вызывается до того, как была выполнена операция BIND для всех параметров запроса. В этом случае результат оказывается неправильным, причем, если выполнить привязку для всех параметров, то количество полей сообщается верное, и запрос работает нормально. Поскольку количество возвращаемых запросом полей необходимо знать на этапе инициализации запроса, для решения этой проблемы создается фиктивный оператор, для него указываются все параметры без определения типов, потом вызывается SQLNumResultCols, которая теперь должна вернуть правильный результат, и фиктивный оператор освобождается.
В ходе разработки FinExpert на платформе Informix была написана функция fe_is_null_date, возвращавшая значение текущей даты в случае, если входной параметр равен Null, и сам этот параметр в противном случае. В случае использования SPL реализовать такую функцию несложно, однако для T-SQL, как выяснилось, функции SQL Server 2000 GetDate() и Current_timestamp, являющиеся аналогами функции Today, относятся к разряду недетерминированных, использование которых в определенных пользователями функциях не поддерживается. Одним из возможных решений была передача GetDate() в пользовательские функции в качестве одного из входных параметров: fe_is_null_date (@val,GetDate()), однако для этого пришлось бы переписывать все запросы с использованием fe_is_null_date. Поэтому, было принято решение написать так называемую «расширенную хранимую процедуру» (Extended Stored Procedure), которая возвращает текущее время. Для реализации такой процедуры на Visual C++ была написана специальная библиотека FE_XP.dll, которая экспортирует функции FeYear, FeMonth, FeDay, FeHour, FeMinute, FeSecond, FeFraction. После этого функцию fe_is_null_date стало легко реализовать с помощью использования экспортированных функций.
Переписывание процедур
В процессе перевода объектов баз данных, написанных на языке Informix SPL (процедуры, триггеры) обнаружились весьма значительные отличия между SPL и T-SQL.
Функции и процедуры. В SPL вплоть до девятой версии (Informix 2000), фактически отсутствовало различие между понятиями «функция» и «процедура». Схема получения возвращаемого такими объектами значения, скорее, подпадает под определение «функция». В SPL-коде обращение к такому объекту выглядит следующим образом:
let id=fe_create_book(in_open)
Однако такая процедура в Informix может вызываться и как функция, и как процедура:
execute procedure proc1(0, 1) select field1, proc1(field2, field3) from table1 where...
В SQL Server понятия процедур и пользовательских функций (UDF — user defined function) различаются. При этом пользовательские функции, впервые появившиеся в SQL Server 2000, имеют целый ряд серьезных ограничений: запрещение вызова недетерминированных функций (например, getdate()), из-за чего, в частности, пришлось реализовать внешнюю процедуру для получения текущей даты/времени из пользовательских функций; запрещение вызова хранимых процедур; запрещение операторов, изменяющих данные (кроме данных переменных типа Table, локальных для данной пользовательской функции), что потребовало ряд функций Informix переписать в процедуры SQL Server, а значения возвращать в виде выходных параметров.
В T-SQL результат возвращается в специальный параметр, помеченный как OUTPUT:
exec fe_create_book @id OUTPUT, @in_open.
Аналогичным образом трансформируются вызовы объектов в коде на Visual Basic, что приводит к «вариантным» вызовам:
Dim theStatement As ODBCDB.Statement
If mDestServer = SQL_MS Then
Set theStatement = inContext.CreateStatement
(«exec fe_create_book ?,?,?»)
Else
Set theStatement = inContext.CreateStatement
(«{?=call fe_create_book(?,?)}»)
End If
With theStatement.Params
If mDestServer = SQL_MS Then
.Item(1).Direction = odbcParameterInputOutput
Else
.Item(1).Direction = odbcParameterOutput
End If
.Item(1) = CLng(0)
.Item(2) = inContext.Today
.Item(3) = ParentBookId
End With
theStatement.ExecuteСерьезно различается также формат вызова функций. В T-SQL в формате вызова обязательно присутствие имени пользователя, которому принадлежит функция, вследствие чего запросы принимают следующий вид: select dbo.fe_is_null_d(param1). Поэтому возникла необходимость вносить соответствующие изменения в тексты представлений, а на уровне программного обеспечения промежуточного слоя организовать проверку выполняемых SQL-выражений, которая изменяет подстроку с обращением к функции и «дописывает» к ней имя пользователя. В случае настройки на СУБД Informix эта операция не выполняется.
Перехват ошибок. Одной из самых серьезных и до конца не решенных проблем, возникших при переводе SPL-кода в T-SQL, являются различия в реализации обработки ошибок внутри процедур. В Informix SPL допускается создание обработчика ошибок внутри блока BEGIN — END. Ошибки со специфицированными номерами, возникшие в пределах блока, обрабатываются непосредственно в нем, а не показываются клиенту. В SQL Server 2000 T-SQL создание такого рода обработчиков невозможно: возникшая ошибка будет показана клиенту в любом случае. Для того чтобы этого не произошло, приходится осуществлять дополнительную проверку перед выполнением операции, если это возможно, проверять переменную сеанса @@ERROR после выполнения операции, и вызывать оператор Return для прекращения выполнения процедуры в случае возникновения ошибки.
Блок действий для каждой записи выборки. Еще одной серьезной проблемой является отсутствие в T-SQL конструкции FOREACH, вместо которой в SQL Server необходимо использовать курсор по выборке, а иногда (в случае автоинкрементных триггеров) — комбинацию курсора и временной таблицы.
Модификация представлений
При переписывании представлений (views) основные проблемы были следующими:
- синтаксис OUTER JOIN;
- конкатенация строк;
- применение определенных пользователями функций;
- применение несовместимых функций сервера (скажем, в Informix есть функция TRUNC, а в Microsoft SQL Server функции с таким названием нет);
- вычисление разности между полями типа «дата»;
- использование GROUP BY;
- использование таких функций, как TODAY или CURRENT, которые в SQL Server имеют названия current_timestamp и getdate() соответственно;
- использование системных таблиц (например, аналог корректной для Informix конструкции select table_name from systables where tabid=1 выглядит в SQL Server как select name from sysobjects where id=1).
При попытке «лобового» переписывания двух представлений для SQL Server мы столкнулись с превышением максимального числа таблиц в запросе (не более 255). Это были представления «фактов», созданные для наполнения OLAP-куба [3], которые аккумулировали в себе множество разнородных данных, содержащихся в различных таблицах. В Informix эти представления создавались и работали нормально. Пришлось, действуя более творчески, переписать эти представления с максимальным уменьшением количества используемых таблиц. В основном таблицы удалось «сэкономить» за счет того факта, что псевдозапросы для получения «фантомных строк» вида select CONST AS field в Informix требуют обязательного указания таблицы в поле clause from, а в SQL Server это не обязательно.
Разработка шаблонов триггеров
Как уже говорилось, CA ERWin позволяет создавать стандартные механизмы обработки объектов базы данных, что послужило основой для разработки шаблонов создания ссылочных ограничений (referential constraint — RC) и триггеров. Изначально, необходимость в разработке шаблона создания RC возникла из-за того, что ERWin не позволяет автоматически создавать их с предопределенным именем. Поэтому при генерации базы создание RC отключается, а вместо них специальный скрипт постобработки изменяет имя создаваемой ссылки на требуемое и формирует оператор создания ссылки. Аналогичным образом создаются автоинкрементные триггеры на таблицы. Такая методика позволила легко создать вариантные шаблоны, которые изменяют синтаксис создаваемых операторов в зависимости от целевого сервера баз данных. Все автоинкрементные триггеры и RC имеют стандартные имена, а триггеры — стандартные тела. Приведем скрипт создания автоинкрементные триггеров:
%if(%==(%DBMS,INFORMIX)) {
create trigger %Substr(ti_%Upper(%TableName)
,1,14)%EntityId()
insert
on %UPPER(%TableName)
referencing new as inserted
for each row
(execute procedure fe_serialize("%UPPER
(%TableName)",inserted.%PK()) into %PK())
;}
%if(%==(%DBMS,SQL Server))
{
create trigger ti_%Upper(%TableName) on
%Upper(%TableName)
INSTEAD OF INSERT
AS
DECLARE @NewId int
DECLARE @RowNumber int
DECLARE @CurrRow int
SET @NewId=0
SET @CurrRow=1
select @RowNumber=count(*) from inserted
select * into #MyTmp from inserted
declare MyCurs cursor LOCAL
for select %Upper(%Pk()) from #MyTmp
FOR UPDATE
open MyCurs
WHILE @CurrRow<=@RowNumber
BEGIN
FETCH NEXT FROM MyCurs into @NewId
exec fe_serialize '%Upper(%TableName)',
@NewId OUTPUT
if @@Error<>0
begin
return
end
UPDATE #MyTmp SET %Upper(%Pk())
=@NewId WHERE
CURRENT OF MyCurs
SET @CurrRow=@CurrRow+1
END
insert into %Upper(%TableName) select
* from #MyTmp
deallocate MyCurs
GO }
«Заливка» данных
На этом этапе сначала создавались только таблицы базы данных без всех остальных объектов, дабы избежать проблем нарушения ссылочной целостности по ходу выполнения передачи данных из Informix. Затем выполнялась «заливка» данных путем прямой загрузки из одноименных таблиц Informix. После этого создавались индексы, ограничения целостности, триггеры, представления, процедуры и т.д.
Здесь, при одинаковой структуре баз данных, казалось бы, все должно бы было быть просто. Однако поля типа BLOB (INFORMIX Byte/SQL Server Image) импортировать не удалось. Кроме того, при импорте полей типа Date в случае, если в них находились значения меньшие, чем 1 января 1753 года (как правило, такие значения -х результат некорректный ввод данных) возникали ошибки. Informix такие даты принимает и хранит нормально.
Доработка и модификация COM-объектов
Реализация настройки на сервер баз данных. Для этого был использован ключ в реестре Windows на сервере приложений; варианты значений ключа — Informix, MS SQL. Чтобы все подряд не обращались к реестру сервера приложений, в одном из системных бизнес-объектов была реализована специальная public-функция, которая позволяла получить значение этого ключа и предоставить его остальным бизнес-объектам.
Использование «вариантных» запросов. В коде бизнес-объектов это выглядит примерно так:
Dim mDestServer As ServerTypes ? Проверим сервер. Если MS SQL — «позовем» функцию по-другому Dim isi As FeCtx.IServerInfo Set isi = mContext mDestServer = isi.GetDestServer Set isi = Nothing If mDestServer = SQL_MS Then ? Code for MS SQL Else: ? Code for INFORMIX End If
По собранной статистике, подобный «вариантный» код пришлось применить примерно в 5% запросов системы. Это достаточно неплохой показатель: объем доработок оказался сравнительно невелик.
Поддержка SQLExecDirect. Для выполнения некоторых запросов потребовалась поддержка SQL Direct Execute. Эта возможность была реализована в низкоуровневом системном компоненте ODBCAPI.DLL, написанном на С++, с применением ATL 3.0, через который работают с базой данных все компоненты FinExpert.
Поддержка OUTER JOIN. Изначально StatementHelper был переписан для реализации OUTER JOIN через условия вида where a.f2*=b.f2. Однако оказалось, что данный синтаксис нельзя использовать, если в списке таблиц фигурируют представления, внутри которых применяется ANSI-синтаксис OUTER JOIN. Кроме того, по информации Microsoft, поддержка «старого» варианта OUTER JOIN выполняется только в целях совместимости со старым кодом, и в дальнейшем будет прекращена. Поэтому пришлось реализовать поддержку OUTER JOIN в стандарте ANSI.
Обработка GROUP BY. В ряде случаев, когда в запросе применяются агрегатные функции и выражения, в Informix может потребоваться группировка по полям выражений. При этом поддерживается группировка по номеру поля вида: GROUP BY 2, 5, 7. В SQL Server при таких запросах список полей для GROUP BY, как ни странно, требуется меньший, а если группировка по полям выражений и нужна, то необходимо указывать поля, входящие в такие выражения. К сожалению, «системно» решить этот вопрос не удалось: «проблемные» запросы были найдены путем тестирования, и для каждого из них был написан специальный код для формирования иного массива полей для GROUP BY в случае работы с SQL Server.
Различия в поддержке различных типов курсоров. Как оказалось, Informix и SQL Server имеют некоторые различия при обработке запросов с различными типами курсоров. Так, например, для использования свойств Statement.RowCount, Statement.MoveFirst, Statement.MoveNext и некоторых других, 32-разрядный ODBC-драйвер Informix 3.33 требует тип курсора Dynamic, а ODBC-драйвер SQL Server 2000.80.380.00 хочет только Static. В противном случае, например, в RowCount возвращается 0.
Реализация задач для проведения регламентных работ
В процессе работы системы требуется проведение ряда «регламентных» работ: очистка таблицы глобальных переменных FE_GLOBALVAR_VALUE, таблицы текущих значений автоинкрементных полей FE_SERIAL_HEAP от «старых» значений и т.д. Эти задачи решают специально созданные задачи (jobs), выполнением которых занимается SQL Server Agent. В его планировщик внесены две задачи:
1. FeRecompileObjects_имя_базы_данных
Перекомпиляция предствлений, триггеров и процедур. Для всех объектов баз данных таких типов выполняется команда exec sp_recompile имя объекта.
2. FeClearTables_имя_базы_данных
Эта задача состоит из выполнения нескольких скриптов.
- FE_global_variables_cleaner удаляет из таблицы глобальных переменных записи, не соответствующие текущим сеансам базы данных, а также «старые» значения глобальных переменных для текущих сеансов.
- FE_serial_heap_cleaner удаляет из таблицы текущих значений автоинкрементных полей FE_SERIAL_HEAP записи о значениях счетчиков, кроме максимальных для каждой таблицы.
- FE_balance_cleaner удаляет из промежуточных таблиц, использующихся процедурой расчета баланса, возможный «мусор» от некорректно завершившихся сеансов.
- FE_update_statistics обновляет статистику, используемую оптимизатором.
Скрипт, создающий задачи для базы данных, внесен в систему контроля версий CA ModelMart и выполняется при каждой генерации новой базы. Таким образом, каждой базе на сервере разработки системы FinExpert соответствуют две задачи.
Выводы
Компания IDM и ее заказчики, инициировавшие процесс перевода системы FinExpert на SQL Server, были удовлетворены его результатами (рис. 3).
Уже первые тесты системы показали, что на аналогичном оборудовании для ОС Windows 2000, наблюдается выигрыш в скорости, равный 10-15%. Наиболее вероятные причины этого — лучшая интеграция SQL Server 2000 с Windows 2000, и несколько лучшая работа оптимизатора SQL Server. Судя по опыту работы с Informix, в среде ОС Unix эта СУБД традиционно работает лучше, чем в среде Windows. Между тем, на платформе Windows 2000, более стабильной работой отличается SQL Server. К примеру, если СУБД Informix запросила дополнительную память, то «по доброй воле», без перезапуска уже не отдаст ее операционной системе, даже если эта память более не используется. SQL Server освободившуюся память отдает, хотя и не всегда оперативно.
Для улучшения нагрузочных характеристик и масштабируемости, в дальнейшем планируется реализовать в системе FinExpert поддержку COM+, .NET и MS Message Queue.
Литература
- Вадим Муравьев, Алексей Банасевич. Использование технологий Informix в ERP-системе FinExpert 8.0, «Informix Magazine/русское издание», лето 2001
- Вадим Муравьев, Алексей Банасевич. Технологические решения в управлении предприятием, «Корпоративные системы», 2000, № 4
- Материалы совместного семинара компаний IDM, Microsoft и KPMG на выставке «Управление предприятием?2000», 2 ноября 2000, http://idm.kiev.ua/news/index.html
- Функции UDF строят идентификаторы, SQL Server Magazine Online/русское издание, 2001, № 4
- UDFs Provide a New IDENTITY, SQL Server Magazine, http://www.sqlmag.com
- MSDN, артикль Q155818, апрель 2001
Алексей Банасевич (Alex.Banasevich@finexpert.com) — руководитель проекта FinExpert 8.0, Алексей Кудинов (AKudinov@finexpert.com) — ведущий программист компании IDM (Киев).
Система FinExpert 8.0
Разработанная компанией IDM система FinExpert для Windows предназначена для автоматизации крупных предприятий. Основные принципы ее архитектуры достаточно обычны для трехзвенных распределенных систем: максимум бизнес-логики на сервере приложений; минимум зависимости от выбора конкретной СУБД; максимум использования возможностей компонентной объектной модели COM/DCOM по масштабированию.
На момент начала разработки системы в 1998 году заказчиками была избрана платформа Informix On-Line Dynamic Server 7.x /Windows NT. Поскольку поддержки Microsoft Transaction Server для Informix тогда не существовало, часть функциональности, присущей MTS, пришлось реализовывать самостоятельно. В частности, была разработана собственная реализация пула соединений с базой данных. Сервер приложений FinExpert, с одной стороны, принимает N клиентских соединений, а с другой — создает M соединений с базой данных; причем параметр M не зависит от N, а настраивается администратором системы. Клиенту по запросу сервером приложений выделяется свободное соединение для выполнения запросов к базе данных.
Для проектирования и разработки схемы данных применяются CASE-инструменты CA ERwin и репозиторий ModelMart 3.0.2. Последний инструментарий позволяет вести коллективную разработку схемы базы данных, подобно тому, как Visual SourceSafe дает возможность вести коллективную разработку исходного кода программ. При этом ведущий разработчик имеет средства для визирования и контроля работы остальных участников проекта.
