

Чтобы удовлетворить свои потребности в более своевременном и гибком анализе данных, компании могут использовать пошаговый подход при переходе от поддержки детализированной информации к использованию сводных данных.
Эволюция хранилищ данных определялась проектами, в рамках которых разработчики пытались найти компромисс между преодолением технических трудностей и бизнес-функциями системы. Один из таких компромиссов — автоматическое составление сводных данных или моделей данных, ориентированных на одно приложение.
Первоначально компании просто извлекали данные из транзакционных систем и размещали их в другой базе данных, которая, как правило, использовалась для оперативной аналитической обработки. При таком подходе удавалось сохранить возможность проведения более длительных и сложных операций анализа, при этом не препятствуя выполнению более ответственных задач обработки транзакций.
Большинство транзакционных систем хранят данные в нормализованной модели, где определенные правила позволяют устранить избыточность и упростить взаимосвязи между данными. Такая модель оптимальным образом подходит для обработки транзакций, однако может препятствовать использованию тех же самых баз данных для эффективной обработки аналитических запросов.
По мере роста объемов данных в аналитических системах, обработка запросов занимает все больше времени. Поскольку аналитические системы не обязаны поддерживать обработку транзакций, многие начинают применять предварительное планирование с целью подготовки наборов ответов. Предварительное планирование включает в себя:
- создание сводных таблиц предварительно агрегированных данных;
- введение индексов, которые позволяют отказаться от сканирования больших объемов данных;
- денормализация модели — размещение данных в одной таблице, а не в нескольких, которые затем приходится соединять;
- хранение данных в отсортированном порядке, чтобы избежать последующего упорядочивания.
Прежде чем выполнить любое из этих четырех оптимизирующих преобразований, следует очень тщательно разобраться в том, какой именно потребуется анализ и какие для этого необходимы отчеты и служебная информация.
Долгое время эти вопросы не находили отражения при создании хранилищ данных. Их разработчики пытались увеличить производительность за счет манипулирования параметрами баз данных и моделей данных.
По мере расширения рядов пользователей и усложнения запросов, пользователи все чаще не могли определить, какие операции анализа им необходимо проводить. А если они и могли сформулировать задачу, то время, необходимое для обработки и сохранения наборов ответов, становилось неприемлемым. Приходилось снова извлекать данные. Это было время систем оперативной аналитической обработки, которые ориентировались на «сокращение» (slicing and dicing) данных.
Современные задачи
Теперь пользователям необходим не просто более сложный и гибкий анализ, а предельно актуальная информация. Данные должны быть доступны круглосуточно, семь дней в неделю, и многим бизнес-пользователям необходимо иметь возможность получать данные, требуемые для поддержки принятия решений, всего за несколько часов — а порой за несколько минут или даже секунд — после наступления события.
Серьезным препятствием стала необходимость переносить данные на различные платформы, манипулировать наборами ответов и предварительно их планировать, а также заблаговременно формировать набор часто используемых запросов. Вместо того чтобы усложнять архитектуру, разработчикам необходимо понять, как использовать методы хранения данных для создания решений, которые позволяют так упростить системы, чтобы они требовали меньшего перемещения данных и распространения изменений.
В идеале компании должны стремится к тому, чтобы хранить детальные данные на самом низком из возможных уровней в функционально-нейтральной модели данных. Это позволит бизнес-пользователям формулировать запросы самого широкого спектра. Базовая посылка состоит в том, что всегда можно агрегировать детальные данные, однако выполнить декомпозицию сводных данных невозможно. Это вовсе не означает, что никогда не следует использовать таблицы сводных данных. Это значит лишь, что нельзя заменять детальные данные сводными.

|
| Рис. 1. Семь шагов в оптимизации данных. Каждый шаг в этом процессе перехода от детального уровня к уровню сводных данных дает свои результаты. |
Основная причина создания таблиц сводных данных и денормализации данных — желание увеличить производительность. Если бы можно было обрабатывать данные любого объема, чтобы получить ответ на любой вопрос, причем немедленно, то порождать сводные данные не пришлось бы. Эти структуры применяются для того, чтобы обойти другие ограничения. Их существование требует большего дискового пространства, управления данными и времени, которое проходит с момента наступления события и возможностью предпринять необходимые действия.
Оптимизированная производительность
Не следует переходить от детального уровня к уровню сводных данных, если нет четкого представления о последствиях такого шага. Как показано на рис. 1, этот процесс можно разделить на семь шагов. Важно отметить, что если доступная технология не позволяет выполнить даже первый шаг, следует серьезно задуматься над тем, способна ли эта технология удовлетворять требования бизнеса.
Модель, нейтральная к данным
Самый низший уровень предусматривает использование атомарных данных в нормализованной модели, которая не ориентированна на определенную функцию или группу. Данные включают в себя низший уровень детализации, необходимый для поддержки бизнес-целей. Это не обязательно должны быть «сырые» данные о транзакциях, но они должны позволять спускаться на данный уровень по мере изменения требований.
Что касается безопасности и параллельной обработки, то большинство для определения детальных таблиц используют представления доступа. Представления доступа добавляют модификатор блокировки, который дает пользователям возможность выбирать данные из таблицы даже в тот момент, когда другие пользователи добавляют в нее данные. Этот метод называется «чтением без цели» или даже «грязным чтением». Запросы затем выполняются на этих представлениях, а не на базовых таблицах, что позволяет избежать решения многих проблем, обычно возникающих в связи с блокировкой. Представления доступа приемлемы только в том случае, если строго отражают нижележащие детальные таблицы.
Зачастую, чтобы понять, можно ли добиться требуемой производительности, достаточно просто исследовать вопрос об использовании оптимизированного варианта SQL. Во многих ситуациях низкая производительность — результат того, что инструментарий или пользователь не применяют самые эффективные операторы. Для многих успешных проектов использование этого подхода как раз и оказывается залогом успеха.
Представления
Первый шаг на пути к увеличению производительности — реализация табличных представлений и, как следствие, простая навигация. Хотя представления, как правило, не существенно влияют на производительность, они позволяют получить приближенную к видению конкретного пользователя модель данных, достигая эффекта «улучшения» SQL. Поскольку представления можно оптимизировать для конкретной базы данных, нельзя рассчитывать на то, что каждый производитель инструментов переднего плана (front-end) знаком со спецификой каждой базы данных.
Также можно использовать оптимизированные методы соединения в представлениях, не требуя, чтобы каждый инструмент и каждый пользователь были с ними знакомы. Еще одно преимущество такого подхода состоит в том, что он добавляет дополнительный уровень безопасности для таблиц данных. Например, телекоммуникационная компания использует представления для создания логической модели на базе схемы «звезда» при работе конкретного инструментария. Соединения, востребованные нормализованной моделью, были скрыты при определении представления для модели, специфической для этого инструментария; инструментарий «видит» модель данных как схему «звезда», даже несмотря на то, что модель «звезда» физически не существует.
Администратор базы данных может использовать представления таким образом, чтобы предложить каждому бизнес-подразделению свою собственную логическую функциональность. Представления предлагают данные пользователям именно в том виде, на который они рассчитывают, даже если они по-разному определяют один и тот же элемент. Скажем, одно подразделение предпочитает работать с параметром, измеряемым в футах, а другому требуется тот же параметр в дюймах. При использовании представлений данные должны сохраняться лишь однажды, а затем преобразовываться в определение логического представления. Это снижает уровень избыточности данных, гарантирует согласованность данных и упрощает требования к управлению данными.
Дополнительные индексы
Следующий этап — добавление индексов, которые могут быть самыми разными, от простых вторичных индексов, до сложных структур, таких как соединенные или агрегатные индексы. В большинстве случаев индексы добавляются с тем, чтобы увеличить производительность до требуемого уровня. Основное достоинство индексов состоит в том, что система поддерживает их в параллель с таблицами базы данных. Хотя сохранение и автоматическое обновление индексов связано с определенными накладными расходами, наборы ответов всегда будут согласованы с детальными данными. Сравнение с детальными данными часто практикуется при работе с небольшими справочными таблицами, но необходимо тщательно продумать, стоит ли применять эту методику в случае более крупных и чаще обновляемых таблиц.
Расширение системы
Если индексы и представления не решают проблемы производительности, необходимо пересмотреть свою стратегию управления данными и принять определенные решения относительно долговременных требований бизнеса. Следует ответить на два вопроса:
- какой тип расширения понадобиться для того, чтобы удовлетворить требования к производительности?
- какие преимущества в бизнесе можно получить, если эти требования будут удовлетворены?
Если цель состоит в том, чтобы получить хранилище данных реального времени, добавление нисходящих процессов, таких как таблицы сводных данных и дальнейшее извлечение данных или манипулирование ими, создадут барьер на пути достижения этой цели. Если удастся оправдать затраты, одна из возможностей — расширить системную конфигурацию. Этот шаг, однако, существенно зависит от возможностей базы данных. Многие базы поддерживают существенно последовательную обработку ряда операций, таких как соединение, сортировка или агрегирование. Если база данных имеет точки последовательной обработки, расширение, связанное с распараллеливанием, может не привести к росту производительности, поскольку в процессе обработки запросов данное решение этот шаг не ускорит.
Если расширение системы технически неосуществимо или затраты на него неоправданны, можно рассмотреть другие альтернативы, которые требуют обработки извлеченных данных отдельно от детальных данных. Альтернативные подходы требуют решения других вопросов, в том числе оценки затрат, необходимого дискового пространства, управления данными и временных ограничений. Например, одна из крупнейших сетей розничной торговли предпочитает иметь единое хранилище данных без нисходящей обработки. Специалисты компании пришли к выводу, что лучше получать в течение двух минут ответ на запрос, выданный через несколько часов после совершения транзакции, чем получить ответ за несколько секунд, но через неделю после транзакции.
Рациональные сводки и денормализация
Чтобы обеспечить эффективное использование возможностей базы данных, следующие шаги в процессе оптимизации предполагают, что данные физически размещаются на одной и той же платформе, что и детальные данные.
Если вы решились на денормализацию, то это означает, что более высокая производительность для вас приоритетнее гибкости анализа. Чтобы не ограничивать возможности базы данных, важные для бизнеса, необходимо придерживаться стратегии сосуществования, а не замены, т.е. сохранить детальные таблицы для глубинного анализа, добавив к ним денормализованные структуры.
|
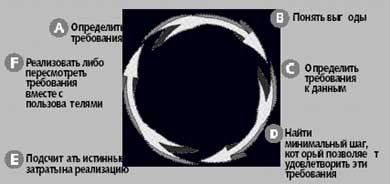
| Рис. 2. Оценка оптимизации производительности. Чтобы понять, насколько далеко следует заходить при добавлении индексов и таблиц сводных данных и денормализации данных, необходимо сопоставить затраты и выгоды как в краткосрочной, так и в долгосрочной перспективе, а также учесть требования конечных пользователей |
На этом шаге таблицы совокупных данных будут не полностью адаптированы к конкретной функции, т.е. специализация будет достигнута, например, на уровне филиала, а не на уровне сводного бюджета, что позволит сохранить ту же самую структуру данных, но на более высоком уровне агрегирования. Это верно и для денормализации. Например, нормализованная модель данных никогда не содержит почтовый индекс, город и штат в одной и той же таблице адреса. Если есть индекс, можно воспользоваться справочной таблицей, чтобы найти город и штат. Когда кто-то ищет почтовый индекс, его, как правило, интересует город и штат; это нужно учесть при определении набора столбцов для такой таблицы, чтобы избежать необходимости выполнения операции соединения.
Рациональные сводки в большей степени призваны удовлетворить типичные требования массы пользователей, чем достичь одной исключительно функциональной цели. В некоторых случаях эти таблицы включаются в исходную модель, поскольку пользователи считают, что они потребуются им для выполнения запросов. Создание рациональных сводок может служить целям различных пользователей и подразделений, тем самым сокращая затраты на управление. И опять-таки, этот подход возможен в относительно небольших и менее часто обслуживаемых справочных таблицах, но по мере роста объема данных и темпов их обновления он вряд ли оправдан.
Иррациональные сводки и денормализация
Если рациональная денормализация не позволяет добиться требуемой производительности, вы можете предпринять «нерациональный» шаг при создании совокупностей и моделей данных, специально ориентированных на определенную функцию. Таблицы будут иметь именно те столбцы, которые необходимы в отчете, но реализация этого подхода означает отказ от гибкости анализа. Работа с такими таблицами также предполагает увеличение затрат времени, необходимого для управления данными, и ресурсов дисковой памяти.
Пример адаптации модели к одной функции возникает в отрасли здравоохранения, а именно, при госпитализации, где задействован очень сложный процесс, призванный сегментировать клиентов. Поскольку такой процесс, как правило, состоит из загадочных бизнес-связей и запутанных правил, мало шансов получить своевременный анализ нормализованных детальных данных.
В некоторых случаях адаптация модели данных в расчете на одну функцию может стать абсолютно иррациональной, затрагивая базовые проблемы. Например, уже упомянутая сеть розничной торговли поддерживает 30 таблиц для клиентской информации, каждая из которых имеет одни и те же столбцы. На вопрос, почему это было сделано, специалисты компании сообщили, что их попросили подготовить систему к формированию 30 различных отчетов, для каждого из которых необходимы одни и те же клиентские данные. Очевидно, что если следовать идеологии полностью настраиваемых под отчеты моделей данных, то система очень быстро может стать чересчур громоздкой.
Экспорт данных
Если добиться приемлемой производительности по-прежнему не удалось, придется принять несколько непростых решений. Систему можно расширить, чтобы увеличить производительность, экспортировав данные из платформы в специальную систему для функционального анализа, или пересмотреть требования к производительности. Все эти варианты требуют довольно больших затрат. Как и раньше, следует соблюдать баланс между бизнес-функциональностью системы и техническими решениями, требующими дополнительных операций по перемещению данных и управлению ими, что необходимо для сохранения согласованности извлеченных и детальных данных.
Обоснованность действий по оптимизации
Чтобы предпринять все эти шаги, необходимо понять, каких затрат требует каждый из них и какие преимущества он дает. Также следует принять решения, которые поддерживают и долговременные, и ближайшие цели. В некоторых случаях можно создать таблицы совокупных данных или добавить денормализованные модели данных, от которых, в конечном итоге, придется отказаться по мере дальнейшего развития функций. Такой подход приемлем до тех пор, пока удаление таблиц не приведет к прерыванию работы или массовым изменениям приложений.
Один из способов определить, насколько оправданны те или иные шаги, — провести анализ в терминах затрат и возможных выгод. Во сколько обойдется управление новым индексом, таблицей совокупных данных или денормализованной моделью данных? Затраты включают в себя физические аспекты, такие как дисковое пространство, ресурсы, необходимые для управления этой структурой, и утраченные возможности из-за временных задержек, связанных с обслуживанием этого процесса. К преимуществам относится более высокая производительность при выполнении запроса и возможность получить при этом более быстрый ответ. Кроме того, можно получить и другие преимущества, в том числе увеличение пропускной способности, уровня удовлетворенности клиентов и производительности, а также более эффективное использование инструментария внешних разработчиков. На рис. 2 показана состоящая из шести шагов типовая процедура для определения приемлемого для предприятия уровня оптимизации производительности.
Существуют и другие важные факторы, которые следует учитывать, в частности, частота запросов и устойчивость производительности. Например, 70% из 1000 запросов, ежедневно генерируемых предприятием, представляют собой запросы уровня сводных, а не детальных данных. При использовании таблицы сводных данных запросы выполняются примерно за 6 секунд вместо 4 минут, т.е. время обработки меньше на 2730 минут. Даже с поправкой на те 105 минут, которые необходимо еженедельно тратить на поддержку таблиц сводных данных, в итоге экономится 2625 минут в неделю, что полностью оправдывает создание таблицы сводных данных. Со временем может случиться так, что большая часть запросов будет обращена не к сводным данным, а к детальным данным. Чем меньше число запросов, использующих таблицу сводных данных, тем проще от нее отказаться, не затрагивая другие процессы.
Однако перечисленные выше критерии не единственные, которые следует учитывать, принимая решение о том, следует ли делать следующий шаг в оптимизации. Необходимо учитывать и другие факторы, в том числе приоритеты бизнеса и потребности конечных пользователей. Пользователи должны понимать, как с технической точки зрения на архитектуру системы влияет требование пользователей, желающих, чтобы все запросы выполнялись за несколько секунд. Проще всего добиться этого понимания — очертить затраты, связанные с созданием таких таблиц и их управлением.
При реализации хранилищ данных их создатели, как правило, ставят своей основной целью увеличение производительности. И в стремлении добиться краткосрочных преимуществ зачастую игнорируют необходимость сохранить в дальнейшем гибкость системы и возможность выполнять более разнообразный анализ. Чтобы удовлетворить первоочередные требования, многие компании быстро переходят на таблицы совокупных данных и функциональные модели. Но если потратить достаточно небольшое время на то, чтобы проанализировать реальные цели и разработать для них корректную основу, это гарантирует долговременность и перспективность хранилища данных.
Именно разработчики, а не пользователи, должны решать, стоит ли предусмотреть таблицы сводных данных или ограничиться функциональной моделью. С другой стороны, пользователи, а не ИТ-персонал, должны определить, какие возможности необходимо предоставить, чтобы добиться целей развития бизнеса. Если нужно проводить анализ детальных данных, использование одних только таблиц совокупных данных будет ошибкой, несмотря на техническую оправданность такого решения. ИТ-специалисты и пользователи должны совместно выяснить, каковы требования бизнеса и что именно позволит удовлетворить эти требования. Чем больше вы манипулируете наборами вычисленных данных, тем менее гибкой становится окружение и тем менее оно оказывается в состоянии удовлетворить новым требованиям.
Роб Армстронг (rob.armstrong@ncr.com) — директор подразделения NCR Teradata Strategic Warehousing and Technologies. Уже более 15 лет он занимается вопросами проектирования и реализации систем управления хранилищами данных.
Rob Armstrong, Seven Steps to Optimizing Data Warehouse Performance. IEEE Computer, December 2001. Copyright IEEE Computer Society, 2001. All rights reserved. Reprinted with permission
